Introduction to machine learning
David Taylor
Senior Data Scientist, R&D, Aviva Canada
prooffreader.com
@prooffreader
What is machine learning?

What is machine learning?
Don't worry, not this.

What is machine learning?
It is the use of algorithms to create knowledge from data.
What is machine learning?
It is the use of algorithms to create knowledge from data.
What's an algorithm?
What is machine learning?
How many of you have done machine learning before?
What is machine learning?
How many of you have done machine learning before?
How many of you have made a best-fit linear regression line in Excel before?
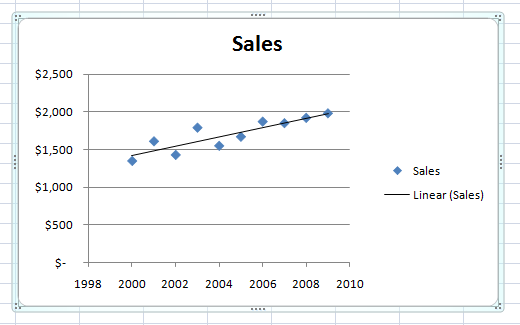
What is machine learning?
"But wait! All I did was push a button in Excel!"
The Black Box...
History of
machine learning
An offshoot of the field of Artificial Intelligence
Examples of machine learning
Autocorrect
Google page ranking
Netflix suggestions
Credit card fraud detection
Stock trading systems
Climate modeling and weather forecasting
Facial recognition
Self-driving cars
Simple data analysis
A note on machine learning nomenclature
The Dataset
'FRUIT'
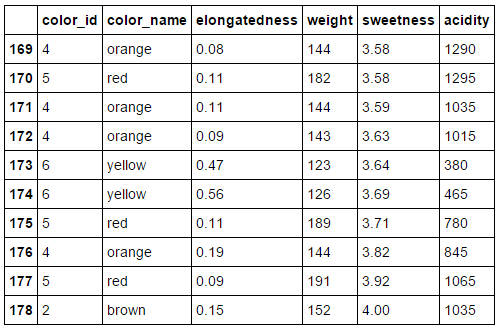
Types of Features
- Numeric
- Interval, e.g. date or time
- Ordinal
- Categorical
Two kinds of
machine learning:
Unsupervised
and Supervised
from my webcomic, prooffreaderswhimsy
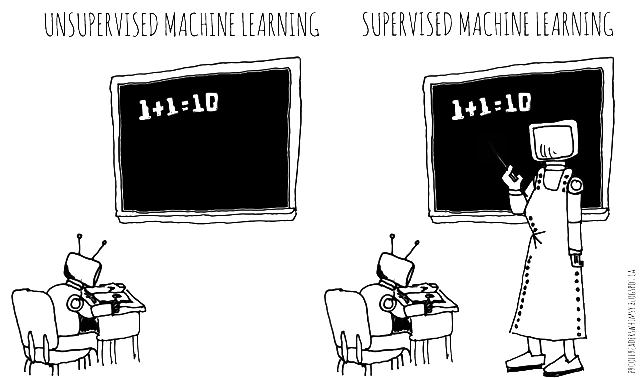
Unsupervised = exploratory
Supervised = predictive
Let's do some
Unsupervised Machine Learning
of our fruit dataset
Clusters
Density & Distance
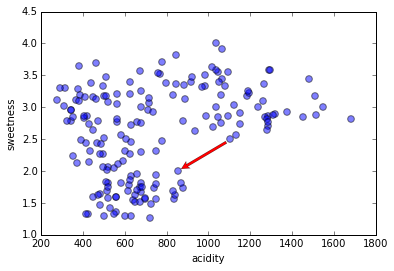
Density & Distance
Euclidean distance
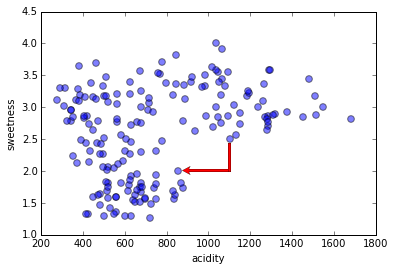
Density & Distance
Manhattan distance
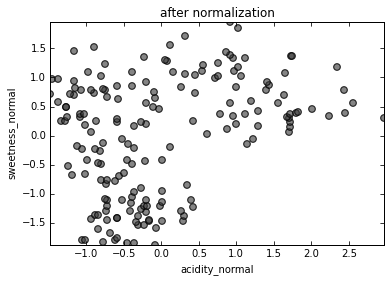
Standardization
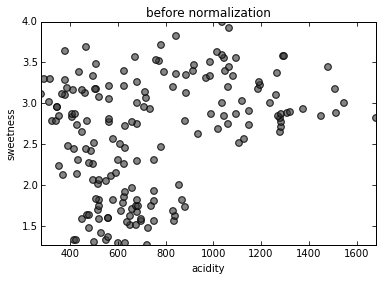
Standardization
The K-Means algorithm
The K-Means algorithm
First, choose number of clusters.
We'll go with 3.
The K-Means algorithm
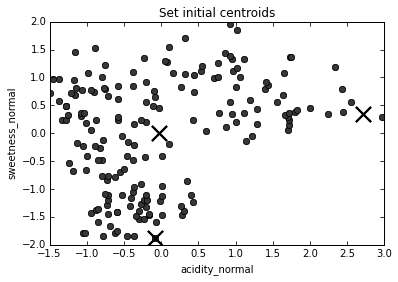
The K-Means algorithm
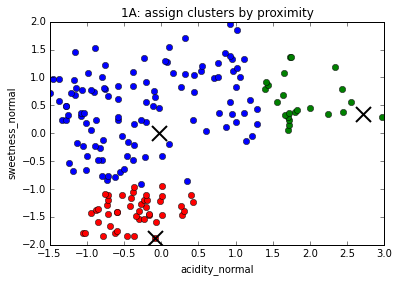
The K-Means algorithm
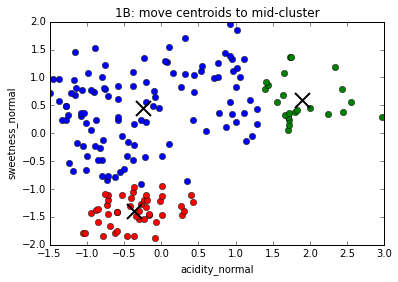
The K-Means algorithm
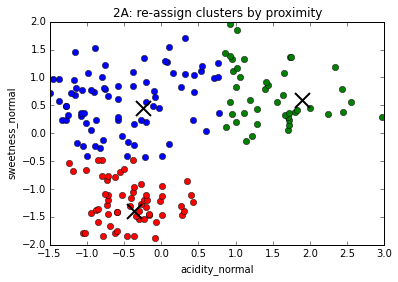
The K-Means algorithm
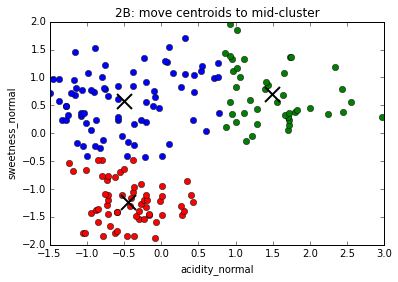
The K-Means algorithm
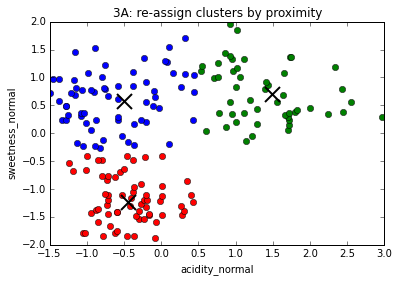
The K-Means algorithm
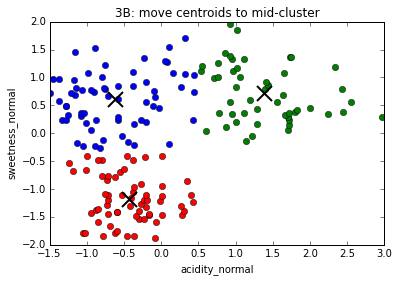
The K-Means algorithm
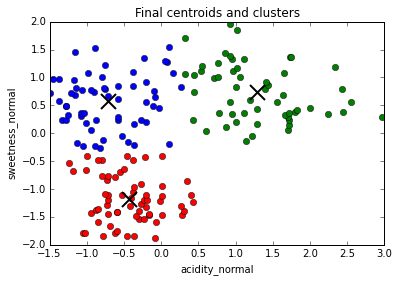
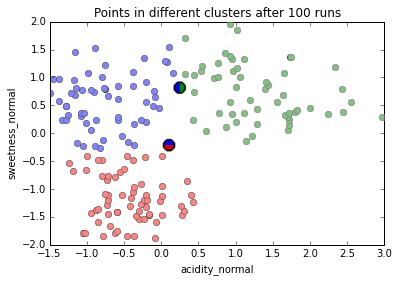
Dependence on initial conditions
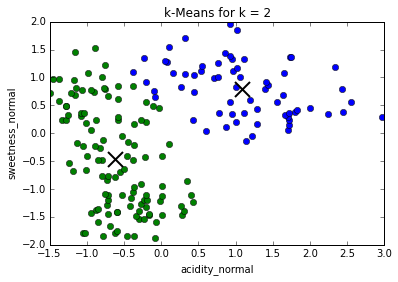
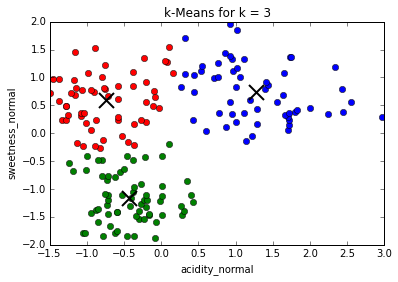
Comparing different values of k
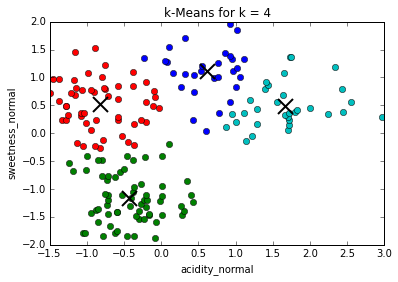
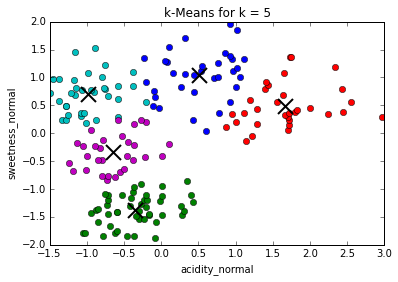
Determining best value for k
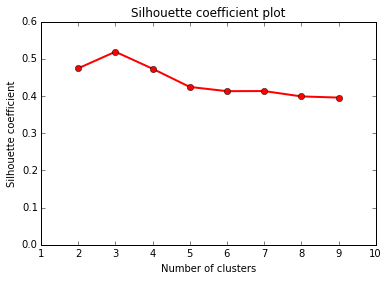
Some other clustering algorithms

Some other clustering algorithms
1) Centroid-based
Some other clustering algorithms
1) Centroid-based
2) Hierarchical
Some other clustering algorithms
1) Centroid-based
2) Hierarchical
3) Neighborhood growers
DBSCAN
Neighborhood Grower example:
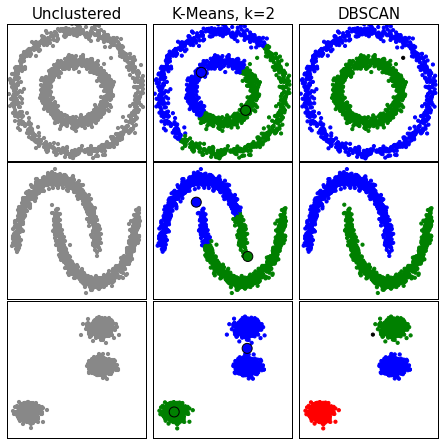
DBSCAN
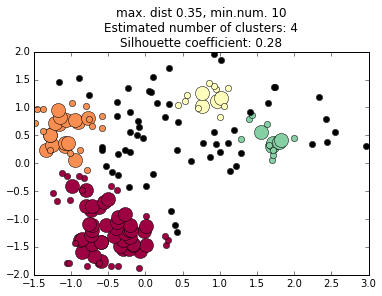
Neighborhood Grower example:
We're done clustering;
Let's do some
Supervised
Machine Learning
of our fruit dataset
... right after we find out what that means!
Unsupervised
There is no "label" associated with clusters.
EXPLORATORY Data Analysis
Supervised
Data starts with labels
PREDICTIVE data analysis
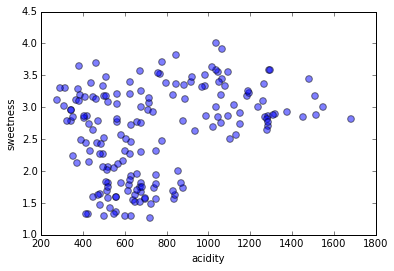
Our fruit dataset
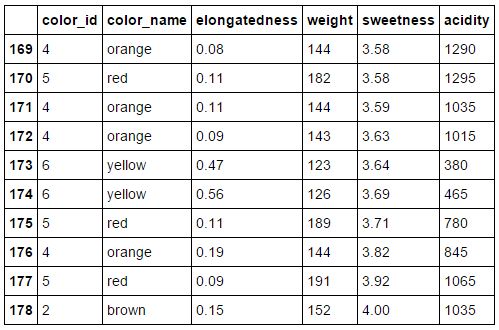

Our fruit dataset + labels
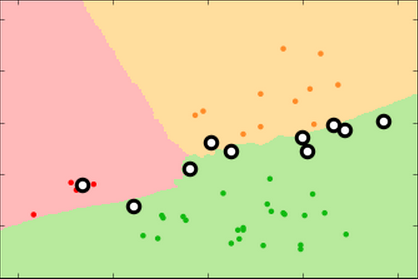
Labels of our fruit and two features
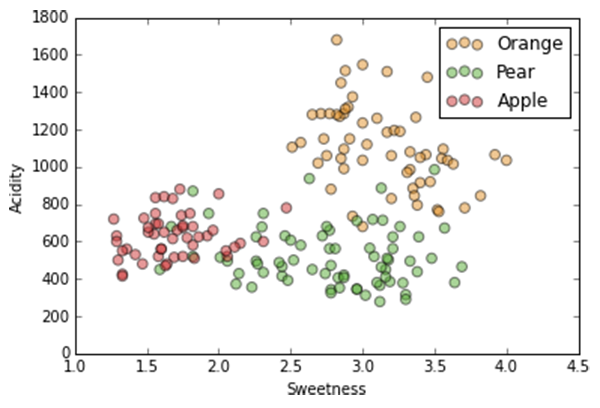
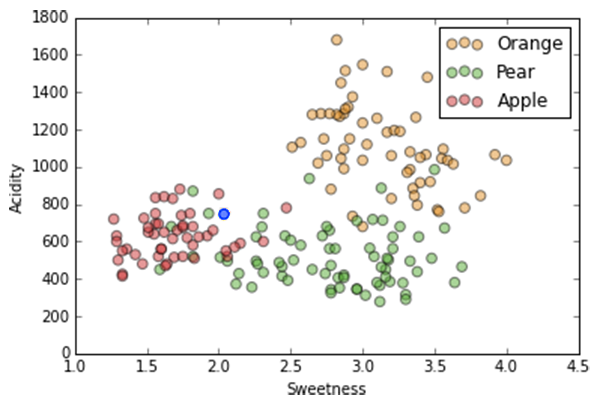
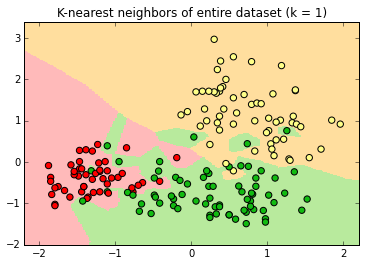
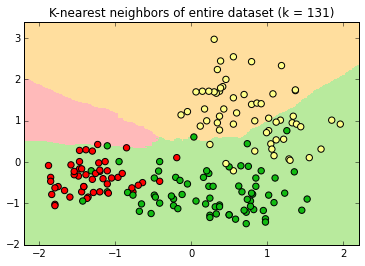
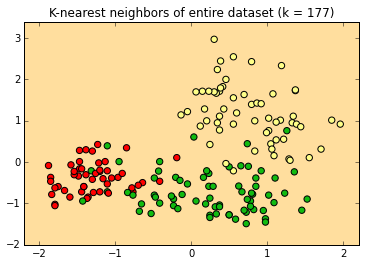
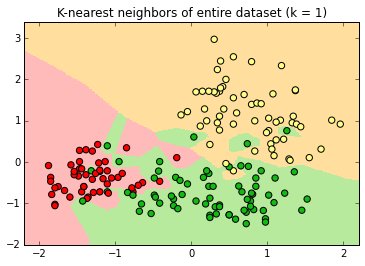
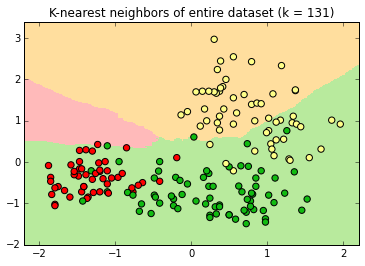
K-Nearest Neighbor
K-Nearest Neighbor

k=1
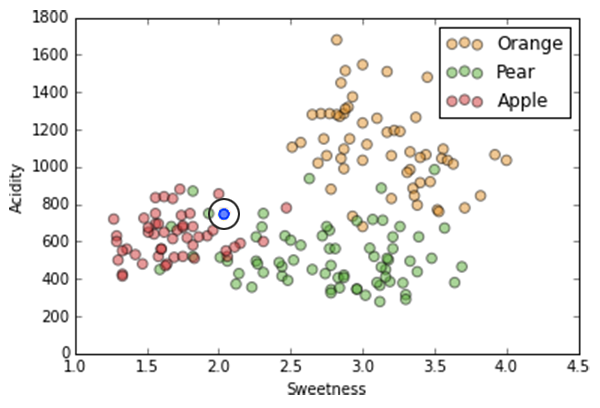
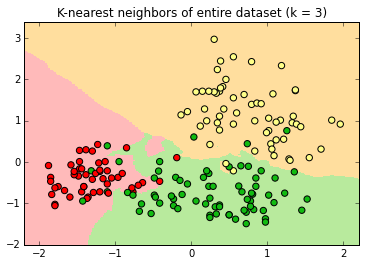
K-Nearest Neighbor
k=3
Decision surfaces
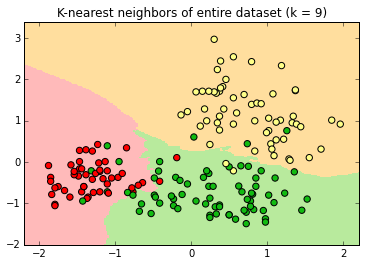
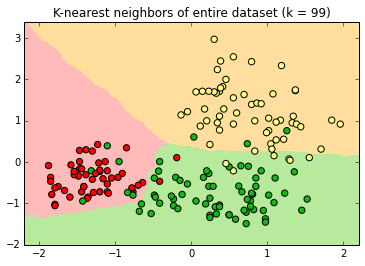
Fitting an algorithm
Fitting an algorithm
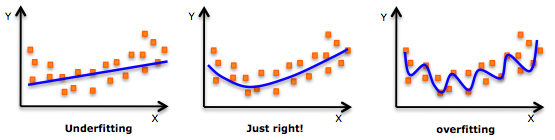
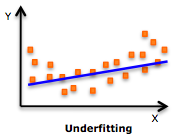
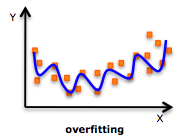
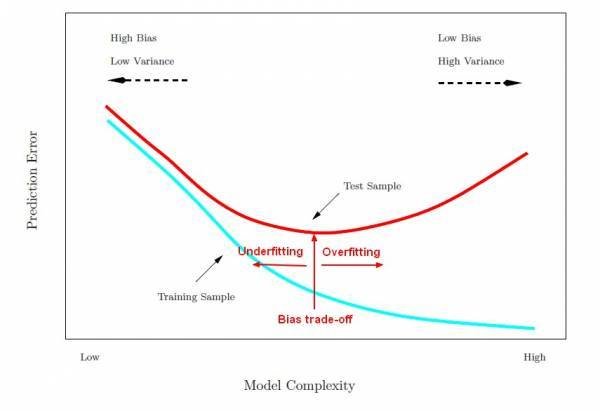
"the bias-variance tradeoff"
underfitting = bias
overfitting = variance
Balance bias and variance by randomly sequestering part of our data as a testing set; the remaining data becomes our training set.
data
training
70%
testing
30%
Don't cheat!
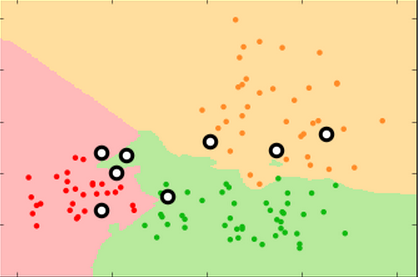
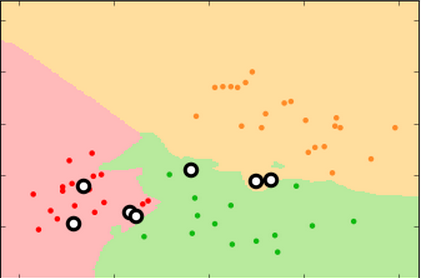
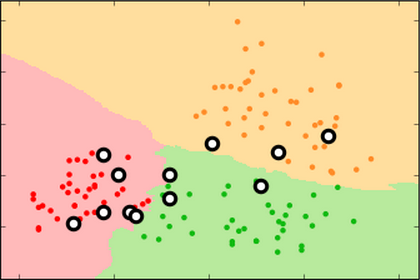
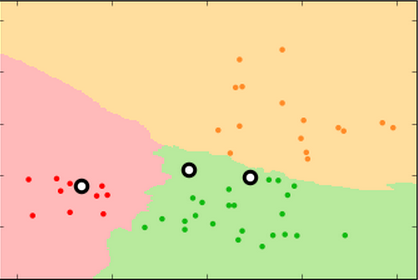
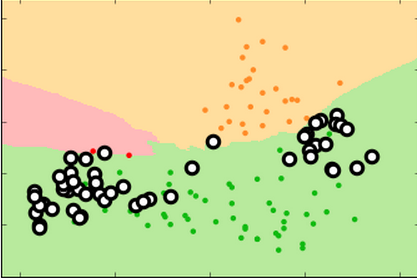
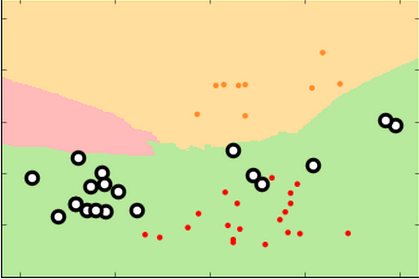
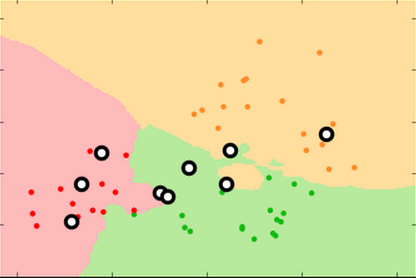
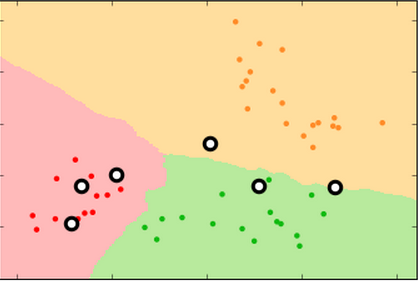
k=99 k=15 k=3
training
set
test
set
k=99 k=15 k=3
training
set
test
set
new
random
test
set
Learning curve
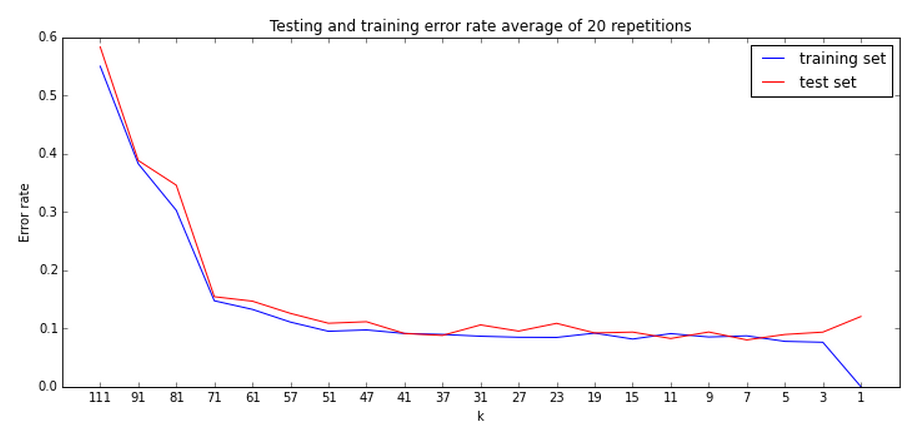
Learning curve
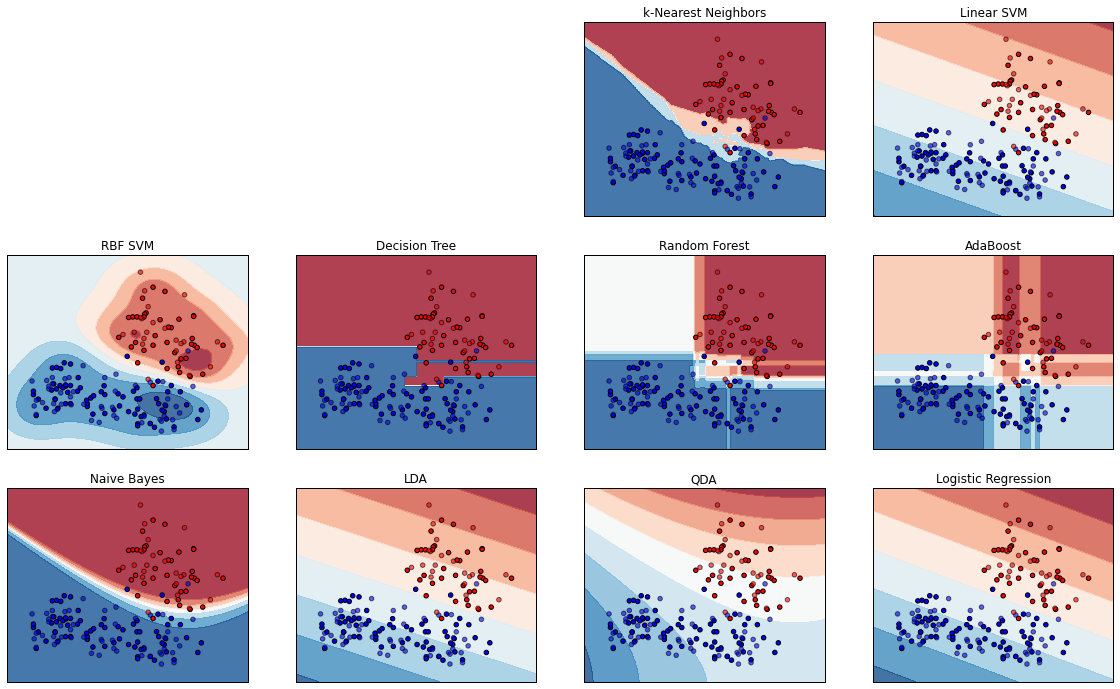
Comparison of classifier algorithms
-
adjust parameters
-
change to more complex algorithm
-
use more features
-
use an ensemble of low complexity algorithms
How to fit an algorithm
to correct underfitting
-
adjust parameters
-
change to less complex algorithm
-
use fewer features or perform dimensionality reduction
-
use an ensemble of high complexity algorithms
-
use more data
How to fit an algorithm
to correct overfitting
We've done k-Nearest Neighbors;
now let's try a different supervised learning algorithm.
Decision trees
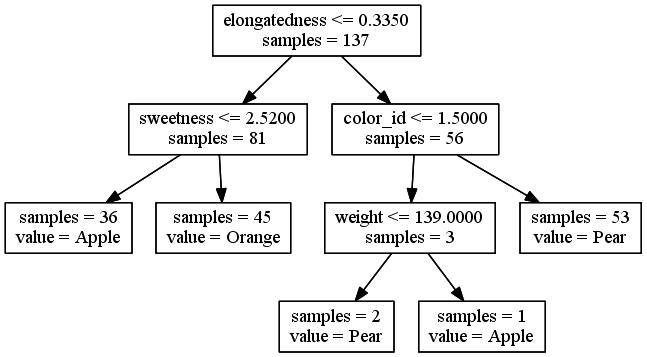
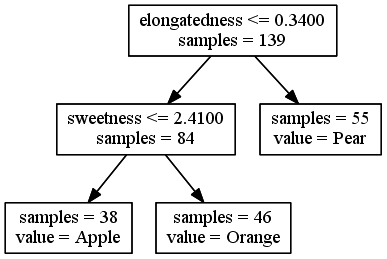
Ensemble methods
Random Forest
An ensemble of decision trees
Random Forest
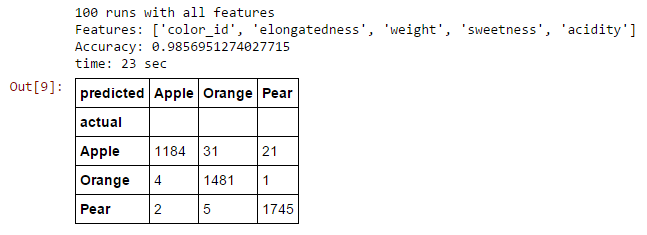
Random Forest
RELATIVE FEATURE IMPORTANCES

The Curse of Dimensionality
Dimensionality Reduction
PCA
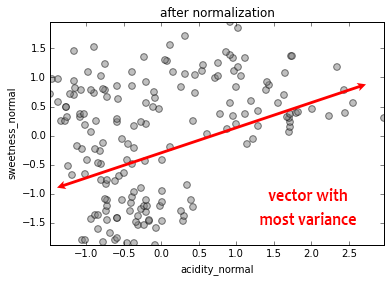
PCA
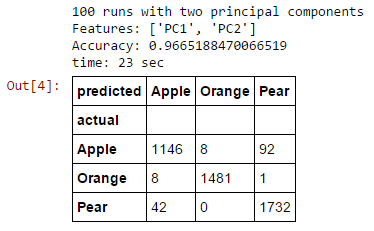
Dimensionality reduction is very handy when you have:
-
1,000 features
-
10,000 features
-
100,000 features
-
1,000,000 features!?!?
- e.g. NLP with n-grams
Cost Function
In what kind of classifier would it be more important to minimize false positives or false negatives?
An adult-content filter for school computers
A book recommendation classifier for Amazon
A genetic risk classifier for cancer
Precision & recall
www.prooffreader.com
"Prooffreader" is misspelled:
that's the joke!