
Занятие №10:
Q-обучение
Основные понятия
Принцип работы
Агент
Среда
действие
At
награда
Rt
Rt + 1
St + 1
состояние
Rt
Алгоритмы ОП
-
Основанные на модели (model-based) и безмодельные (model-free);
-
Основанные на ценности (value-based). Обучите функцию ценности, чтобы узнать, какое состояние более ценно и с помощью этой функции значения предпринять действия, которые к нему приводят;
-
Основанные на политике (policy-based). Обучить политику, чтобы узнать, какие действия следует предпринять в данном состоянии;
-
Единая стратегия (on-policy) и разделенная стратегия (off-policy).
Разница между policy-based и value-based
- Policy-based. Оптимальная политика находится путем непосредственного обучения политике. В качестве политики выступает нейронная сеть;
- Value-based. Поиск оптимальной функции ценности приводит к созданию оптимальной политики. В качестве политики выступает созданная вручную функция.
Методы основанные на ценности
Значение состояния - это ожидаемое дисконтированное вознаграждение, которое агент может получить, если он начнет с этого состояния, а затем будет действовать в соответствии с заданной политикой.
Функция значения
Ожидаемое вознаграждение
Начальное состояние
Примеры
s=1
s=2
s=3
Старт
Конец
Конец
r=1.0
r=2.0
Конец
Старт
Конец
r=2.0
r=3.0
r=-20.0
s=1
s=2
s=3
s=4
Пример №1
- Значение состояния 1 в случае движения агента вправо равно 1.0 (каждый раз, когда он уходит вправо, он получает 1 и эпизод заканчивается);
- Для агента, который идет всегда вниз значение состояния 1 равно 2,0;
- Для агента 50% движение вправо и 50% движение вниз значение составляет 1,0 * 0,5 + 2,0 * 0,5 = 1,5;
- Для агента 10% движение вправо и 90% движение вниз значение составляет 1,0 * 0,1 + 2,0 * 0,9 = 1,9.
Виды функций значений
- Функция состояния-значения (State-Value function);
- Функция действия-значения (Action-Value function).
Значение функции
Ожидаемое вознаграждение
Начальное состояние
Выбранное действие
Различие функций

Два типа методов основанных на ценностях


Функция рассчитывающая ценность (значение) состояния
Функция рассчитывающая ценность для пары состояние-действие
Уравнение Беллмана
Значение функции
Ожидаемое вознаграждение
Дисконтированное вознаграждение следующего состояния
Начальное состояние
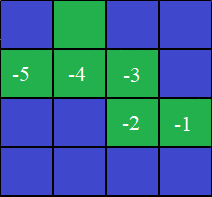
V(St) = (-1) + (-1) + (-1) + (-1) + (-1) = -5
V(St) = Rt+1 + gamma * V(St+1)
V(St) = -1 + 1 * (-6)
V(St) = -7
-1
-1
-1
-1
St
Rt+1
V(St)
V(St+1)
-1
-6
Q-обучение
Q-обучение - это алгоритм обучения с подкреплением без использования моделей, позволяющий узнать ценность действия в определенном состоянии.
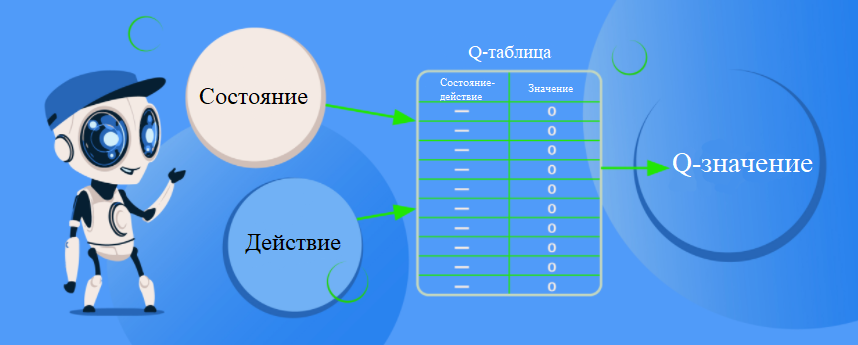
Алгоритм Q-обучение
- Инициализируем Q-таблицу;
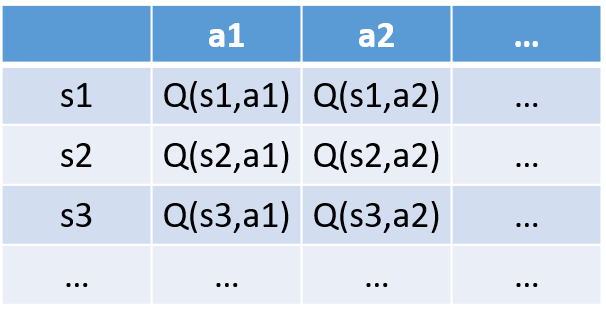
Алгоритм Q-обучение
2. Выбираем действие с помощью Epsilon-жадной стратегии;
3. Выполняем действие At и получаем Rt+1 и St+1;
- 1-Epsilon: исследование (выбираем случайное действие);
- Epsilon: использование (выбираем жадное действие).
Алгоритм Q-обучение
4. Обновляем Q(St, At);
- Монте Карло: обучение в конце эпизода;
- Временное разностное обучение: обучение на каждом шаге.
Новая оценка Q-значения
Прошлая оценка Q-значения
Скорость обучения
Немедленное вознаграждение
Дисконтированная оценка оптимального q-значения следующего состояния
TD целевое значение
Прошлая оценка Q-значения
TD ошибка
Пример
- Скорость обучения равна 0.1;
- Гамма (коэффициент дисконтирования) равен 0.1.



Пример
- Инициализация Q-таблицы
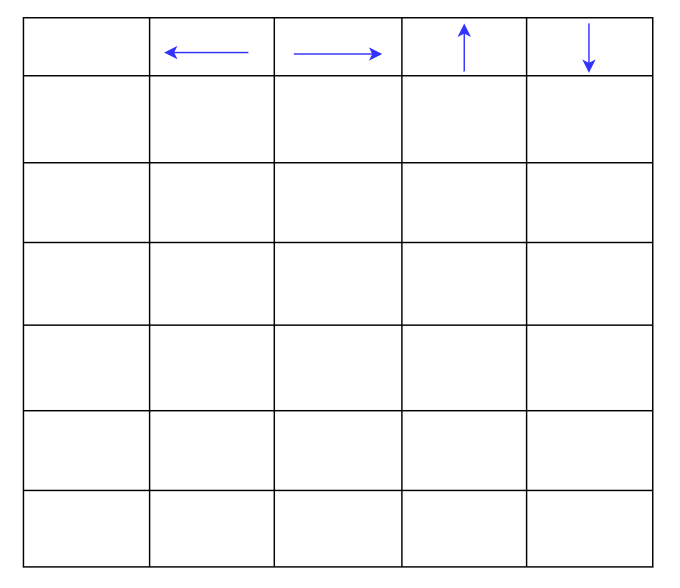
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
Пример
2. Выберите действие с помощью Epsilon-жадной стратегии
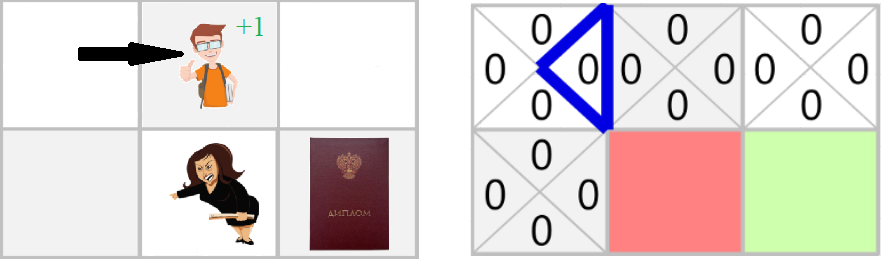
3. Выполняем действие At и получаем Rt + 1 и St + 1
Пример
4. Обновить Q(St, At)
Q(Начальное состояние, вправо) = 0 + 0.1 * [1 + 0.99 * 0 - 0]
Q(Начальное состояние, вправо) = 0.1
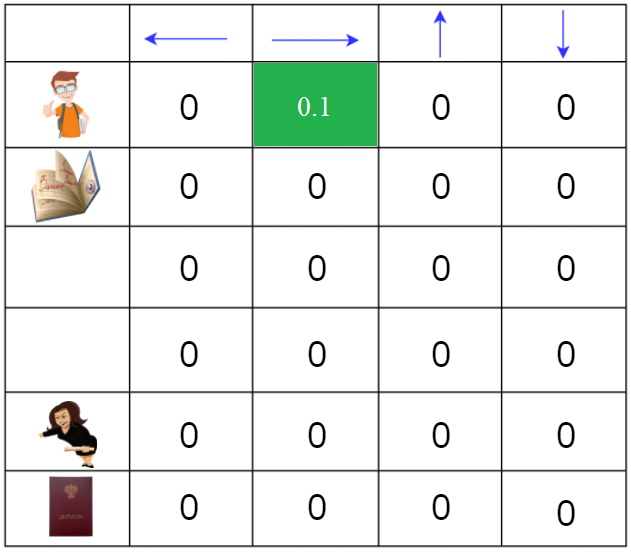
Пример
5. Выберите действие с помощью Epsilon-жадной стратегии
6. Выполняем действие At и получаем Rt + 1 и St + 1
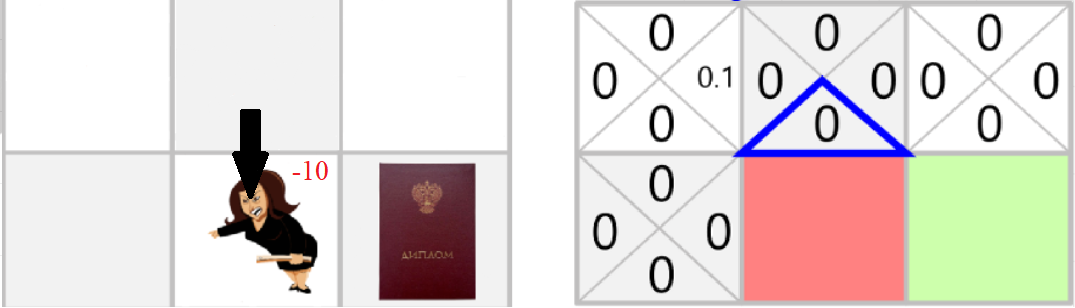
Пример
7. Обновить Q(St, At)
Q(Начальное состояние, вправо) = 0 + 0.1 * [-10 + 0.99 * 0 - 0]
Q(Начальное состояние, вправо) = -1
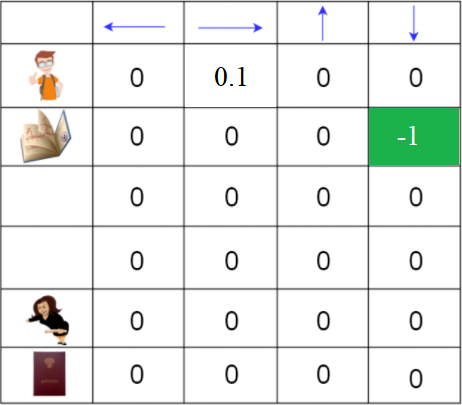
Пример
import numpy as np
import gym
import random
env = gym.make("FrozenLake-v0")
#Инициализируем пространства действий и состояний
action_size = env.action_space.n
state_size = env.observation_space.n
print(action_size)
print(state_size)4
16Пример
qtable = np.zeros((state_size, action_size))
new_qtable = np.zeros((state_size, action_size))
print(qtable)[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]Пример
total_episodes = 70000 # Общее количество эпизодов
max_steps = 99 # Максимальное количество шагов за эпизод
gamma = 0.95 # Коэффициент дисконтирования
epsilon = 1.0 # Скорость исследования
max_epsilon = 1.0 # Вероятность исследования на старте
min_epsilon = 0.01 # Минимальная вероятность исследования
decay_rate = 0.005 # Скорость убыванияПример
rewards = []
for episode in range(total_episodes):
state = env.reset()
y_list = []
done = False
total_rewards = 0
while not done:
# Если это число больше, чем эпсилон,
# то действуем жадно (принимая наибольшее значение Q для этого состояния)
if random.uniform(0, 1) > epsilon:
action = np.argmax(qtable[state,:])
# Иначе делаем случайное действие
else:
action = env.action_space.sample()
# Выполняем действие и получаем новое состояние и награду
new_state, reward, done, info = env.step(action)
y_list.append((state, action))
total_rewards += rewardПример
# Обновляем наше состояние
state = new_state
rewards.append(total_rewards)
for (state, action) in y_list:
new_qtable[state, action] += 1.0
learning_rate = 1.0 / new_qtable[state, action]
# Используем формулу Q(s,a):= Q(s,a) + lr [R - Q(s,a)]
qtable[state, action] += learning_rate * (total_rewards - qtable[state, action])
if episode % 10000 == 0 and episode != 0:
print(str(episode) + "/" +str(total_episodes))
print("Текущее значение точности: " + str(sum(rewards) / episode))
# Уменьшите эпсилон (потому что нам нужно все меньше и меньше исследований)
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)Пример
print ("Итоговое значение точности: " + str(sum(rewards)/total_episodes))
print(qtable)300000/800000
Текущее значение точности: 0.21573333333333333
400000/800000
Текущее значение точности: 0.30615
500000/800000
Текущее значение точности: 0.37506
600000/800000
Текущее значение точности: 0.4260833333333333
700000/800000
Текущее значение точности: 0.4623183673469387
Итоговое значение точности: 0.462872
[[0.61523735 0.20066061 0.18547493 0.20092811]
[0.03192534 0.25148985 0.03369622 0.05453644]
[0.27787067 0.07337181 0.07042254 0.06856634]
[0.0137931 0.05073087 0.0141844 0.01769912]
[0.61703266 0.16654728 0.1974344 0.1896098 ]
[0. 0. 0. 0. ]
[0.15407855 0.11043873 0.29664343 0.04185351]
[0. 0. 0. 0. ]
[0.21678744 0.25853276 0.23751687 0.63372784]
[0.30593979 0.66571034 0.32369478 0.24847251]
[0.61114831 0.36560069 0.31981982 0.20253165]
[0. 0. 0. 0. ]
[0. 0. 0. 0. ]
[0.33352403 0.44183381 0.76425127 0.39171271]
[0.59609375 0.87782031 0.73906486 0.65979381]
[0. 0. 0. 0. ]]
Пример
env.reset()
env.render()
print(np.argmax(qtable,axis=1).reshape(4,4))SFFF
FHFH
FFFH
HFFG
[[1 3 3 3]
[0 0 0 0]
[3 1 0 0]
[0 2 1 0]]Пример
env.reset()
for episode in range(5):
state = env.reset()
step = 0
done = False
print("**********")
print("Эпизод ", episode)
while not done:
env.render()
# Выполните действие (указатель), дающее максимальное ожидаемое будущее вознаграждение
# с учетом этого состояния.
action = np.argmax(qtable[state,:])
new_state, reward, done, info = env.step(action)
state = new_state
env.close()Пример
SFFF
FHFH
FFFH
HFFG
(Right)
SFFF
FHFH
FFFH
HFFG
(Right)
SFFF
FHFH
FFFH
HFFG
(Right)
SFFF
FHFH
FFFH
HFFG
(Right)
SFFF
FHFH
FFFH
HFFG
(Right)
SFFF
FHFH
FFFH
HFFG
(Down)