Distributed Database Experiments with CokcroachDB
Start with Why
Why Distributed Database?
Distributed database is needed to answer at least three problems:
- Scalability
- Availability
- Reliability
Scalability
To handle scale in terms of the size of data and the size of transactions.
Availability
To manage uptime as high as possible.
Reliability
To keep maintain service in the case of faulty in the system.
CokcroachDB
Status Quo
RDBMS
Fully featured with transactions and indexes, but not scalable and fault-tolerant.
NoSQL
Massive horizontal scale, but sacrifice transactions and consistency.
Hosted Services
Vendor lock-in, mostly proprietary, difficult to verify features.
CockroachDB Goals
CockroachDB was designed with the following goals:
- Ease of use
Low-touch and highly automated for operators and simple to reason about for developers. - Consistency on massively scaled deployments
Enabling distributed transactions with synchronous replication instead of eventual consistency. - Flexible deployment
Work with all major cloud providers (AWS, GCP, Azure), container orchestration tools (Kubernetes, Docker Swarm, Mesosphere), and on premise. - Support SQL
Because it's a familiar tools to work with relational data for many developers.
Preparation
Installation
In Mac OS, simply run brew:
brew install cockroachFor other platforms and operating systems, visit this page.
Local Cluster Setup
Start the first node:
cockroach start --insecure --listen-addr=localhostStart two other nodes and join it to the first node:
cockroach start \
--insecure \
--store=node2 \
--listen-addr=localhost:26258 \
--http-addr=localhost:8081 \
--join=localhost:26257
cockroach start \
--insecure \
--store=node3 \
--listen-addr=localhost:26259 \
--http-addr=localhost:8082 \
--join=localhost:26257Experiment 1:
Data Replication
Execute Sample Workload
Run command to generate sample workload in node 1:
cockroach workload init intro \
'postgresql://root@localhost:26257?sslmode=disable'Verify data exists via CockroachDB SQL client:
cockroach sql --insecure --host=localhost:26257
SHOW DATABASES;
SHOW TABLES FROM intro;
SELECT * FROM intro.mytable WHERE (l % 2) = 0;
\qVerify Replication
Verify that sample workload is replicated to two other nodes:
cockroach sql --insecure --host=localhost:26258
SHOW DATABASES;
SHOW TABLES FROM intro;
SELECT * FROM intro.mytable WHERE (l % 2) = 0;
\q
cockroach sql --insecure --host=localhost:26259
SHOW DATABASES;
SHOW TABLES FROM intro;
SELECT * FROM intro.mytable WHERE (l % 2) = 0;
\qExperiment 2:
Fault Tolerance
Simulate Node Failure
To simulate node failure, we will stop node 2 manually:
cockroach quit --insecure --host=localhost:26258Execute Sample Workload
Run command to generate sample workload in node 1:
cockroach workload init startrek \
'postgresql://root@localhost:26257?sslmode=disable'Verify sample workload replicated to node 3:
cockroach sql --insecure --host=localhost:26259
SHOW DATABASES;
SHOW TABLES FROM startrek;
SELECT * FROM startrek.eipsodes WHERE stardate > 5500;
\qRecover Node 2
To simulate node recovery, we re-run and rejoin node 2 to the cluster:
cockroach start \
--insecure \
--store=node2 \
--listen-addr=localhost:26258 \
--http-addr=localhost:8081 \
--join=localhost:26257Verify Data Replication
Verify that data written when node 2 was down is now replicated to node 2 as well:
cockraoch sql --insecure --host=localhost:26258
SHOW DATABASES;
SHOW TABLES FROM startrek;
SELECT * FROM startrek.episodes WHERE stardate > 5500;
\qExperiment 3:
Automatic Load Balancing
Execute Sample Workload
As usual, let's generate sample workload to node 1:
cockroach workload init tpcc \
'postgresql://root@localhost:26257?sslmode=disable'Run Two More Nodes
Run and join two more nodes to the cluster:
cockroach start \
--insecure \
--store=scale-node4 \
--listen-addr=localhost:26260 \
--http-addr=localhost:8083 \
--join=localhost:26257,localhost:26258,localhost:26259
cockroach start \
--insecure \
--store=scale-node5 \
--listen-addr=localhost:26261 \
--http-addr=localhost:8084 \
--join=localhost:26257,localhost:26258,localhost:26259Verify Automatic Load Balancing
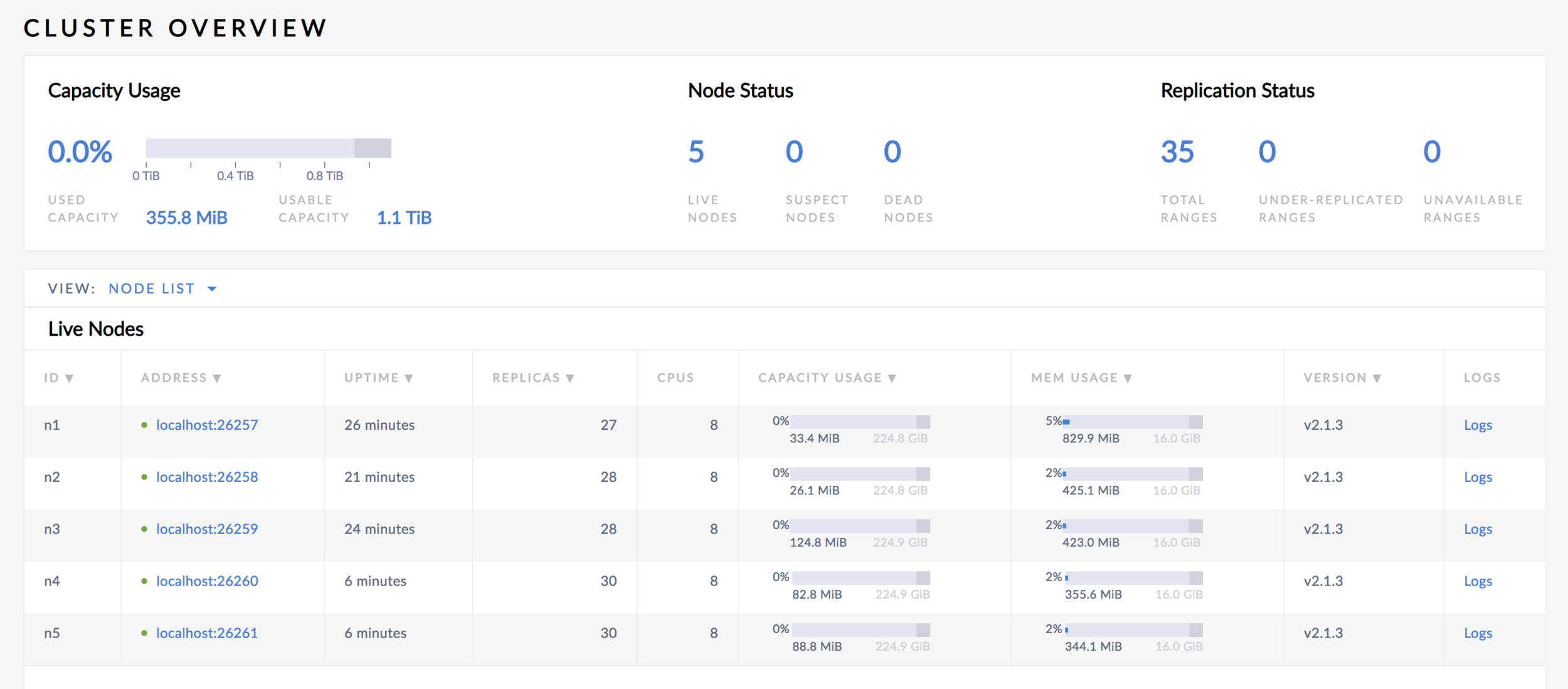
See the number of replicas in new nodes catches up from the dashboard.
Under the Hood
Architectural Diagram
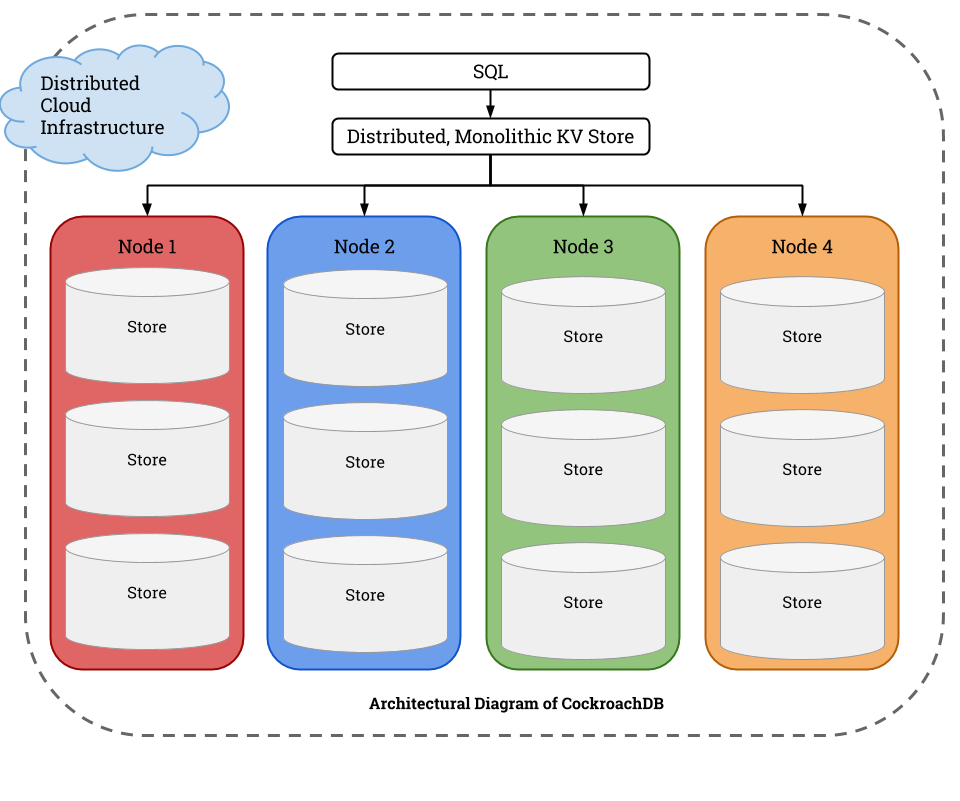
SQL Layer
The highest level of abstraction in the form of SQL API for developers. Provides familiar relational concepts such as schemas, tables and indexes using a derivative of the Postgres grammar with some modern touches.
Data sent to Cockroach DB cluster arrives as SQL statements. Internally, data is written to and read from the storage layer as key-value (KV) pairs. To handle this, the SQL layer converts SQL statements into a plan of KV operations, which it passes along to the transaction layer.
Transaction Layer (1)
To provide consistency, CockroachDB implements full support for ACID transaction semantics in the transaction layer. All statements are handled as transactions (auto commit mode).
Transaction Layer (2)
Phase 1
A transaction record stored in the range where the first write occurs, which includes the transaction's current state (which starts as PENDING, and ends as either COMMITTED or ABORTED).
Write intents for all of a transaction’s writes, which represent a provisional, uncommitted state.
If transaction not aborted, the transaction layer begins executing read operations. If a read only encounters standard MVCC values, everything is fine. If it encounters any write intents, the operation must be resolved as a transaction conflict.
Transaction Layer (3)
Phase 2
Checks the running transaction's record to see if it's been ABORTED; if it has, it restarts the transaction.
If the transaction passes these checks, it's moved to COMMITTED and responds with the transaction's success to the client.
Distribution Layer
CockroachDB stores data in a monolithic sorted map of key-value pairs. This key-space describes all of the data in cluster, as well as its location, and is divided into "ranges".
Ranges are contiguous chunks of the key-space, so that every key can always be found in a single range.
Replication Layer
CockroachDB users a consensus algorithm to require that a quorum of replicas agrees on any changes to a range before those changes are committed.
Because 3 is the smallest number that can achieve quorum (i.e., 2 out of 3), CockroachDB's high availability (known as multi-active availability) requires 3 nodes.
Storage Layer
Each CockroachDB node contains at least one store where the cockroach process reads and writes its data on disk.
This data is stored as key-value pairs on disk using RocksDB. Internally, each store contains three instance of RocksDB:
- One for the Raft log
- One for storing temporary distributed SQL data
- One for all other data on the node