Graph2Seq
Graph to Sequence Learning
with Attention-Based Neural Networks
bAbI 任务 T19
bAbI数据是一些自动生成的逻辑描述
1 The garden is west of the bathroom.
2 The bedroom is north of the hallway.
转换为三元组模式,例如(garden, west, batchroom)
问题
Q: How do you go from the bathroom to the hallway
在这个方法里,所有节点都被编码了,而问题中的开始节点和结束节点赋予了特殊编码START和END,输入图之后,得到一个关于如何寻找最短路径的sequence。
最短路径任务
随机生成数据节点,寻找两个点的最短路径
SP-S 每个图有5个节点
SP-L 每个图有100个节点
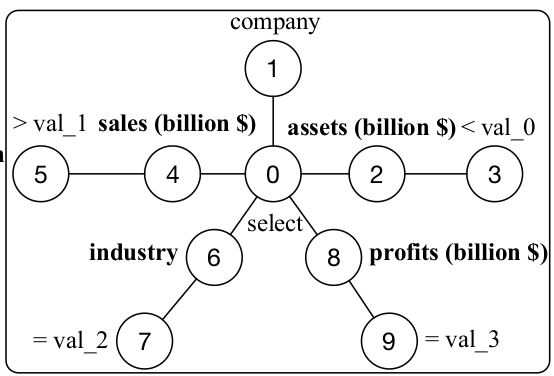
WikiSQL任务
原任务输入:
which company in the val_2 industry has assets (billion $) under val_0, sales (billion $) larger than val_1 and brings in profits (billion $) of val_3 ?
输出
SELECT company
WHERE
assets (billion $) < val_0
sales (billion $) > val_1
industry = val_2
profits (billion $) = val_3
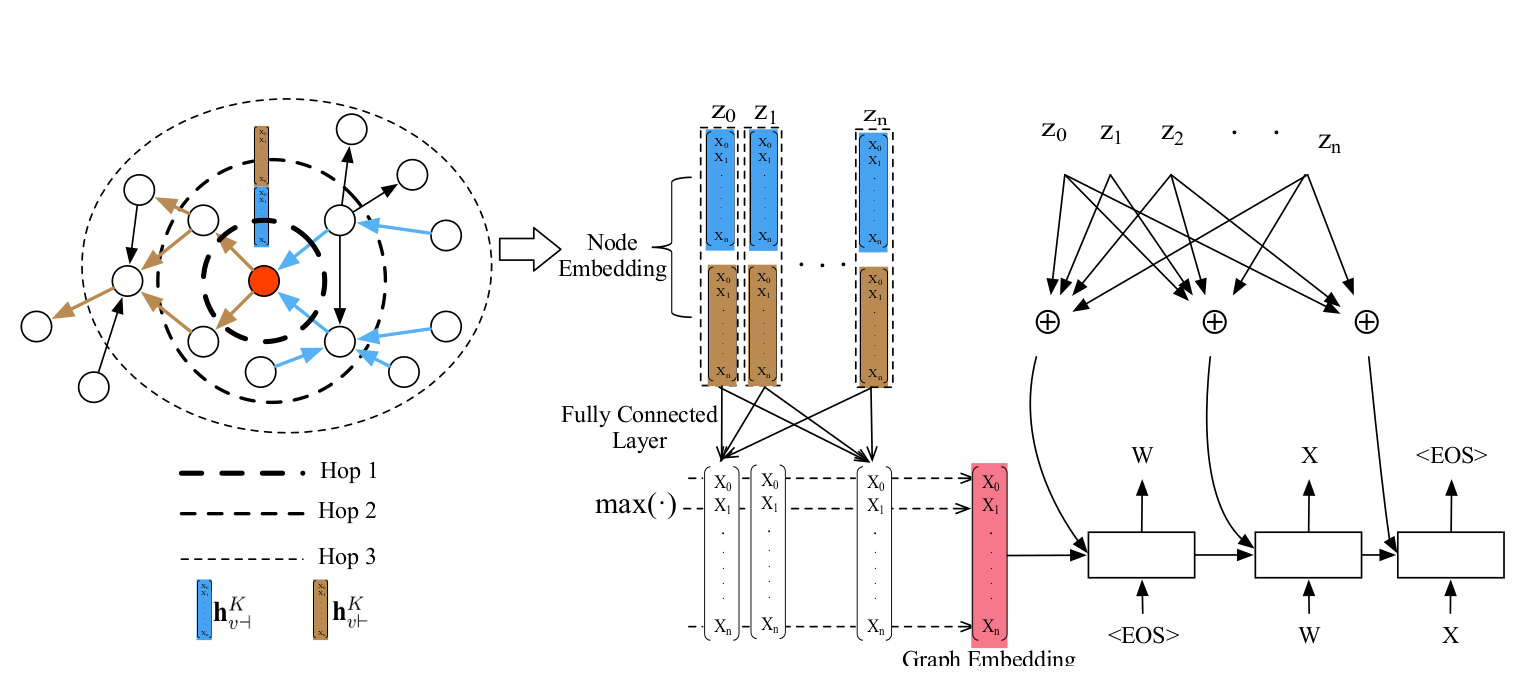
节点嵌入首先分层,以某个节点出发,这个节点自己为零度(零跳)节点开始,
一度(1 hop)即与图直接相连的节点,
两度(2 hops)是与图中间只有一个节点的间接相连。
这样根据从近到远一层一层的把某个节点v开始的节点都编码。

当然一个节点在某一层可能会有1个到N个相邻节点,
这个时候原文提到两种方法,一种是进行基于element-wise的pooling,如max、min、avg。
另一种方法是使用LSTM。
结果来看是max-pooling的结果比较好。
图嵌入
图嵌入有两个方法,一个是把任意多的节点进行element-wise的pooling;
另一种是构造一个超级节点,这个节点与所有节点直接相连,所以理论上这个节点有所有节点的信息,把这个节点的embedding作为图的embedding。
实验结果是pooling方法比较好。
| WikiSQL | BLEU-4 |
|---|---|
| Seq2Seq | 20.91 |
| Seq2Seq + Copy | 24.12 |
| Tree2Seq | 26.67 |
| Graph2Seq | 38.97 |
| bAbI T19 | SP-S | SP-L | |
|---|---|---|---|
| LSTM | 25.2% | 8.1% | 2.2% |
| GGS-NN | 98.1% | 100% | 95.2% |
| Graph2Seq | 99.9% | 100% | 99.3% |
| GCN | 97.4% | 100% | 96.5% |
结论
论文提出了一种图结构嵌入的方法,对比与以前一些将图转换为sequence然后编码的方法,有了明显提高。
这个图的编码方法没有考虑边的嵌入,在论文的任务里边被当做了一种特殊的节点。