Parser Combinators in C++
Outline
- What?
- How?
- Why?
- Conclusion
A little history
A little history
4th BCE: Pannini's description of Sanskrit
A little history
4th BCE: Pannini's description of Sanskrit
1951: Kleene's regular languages
1956: The Chomsky hierarchy of Languages
1960: Backus-Naur Form (BNF): Grammar notation
A little history
4th BCE: Pannini's description of Sanskrit
1951: Kleene's regular languages
1956: The Chomsky hierarchy of Languages
1960: Backus-Naur Form (BNF): Grammar notation
1961: Lucas discovers recursive descent, later known as LL
1965: Knuth discovers LR
A little history
4th BCE: Pannini's description of Sanskrit
1951: Kleene's regular languages
1956: The Chomsky hierarchy of Languages
1960: Backus-Naur Form (BNF): Grammar notation
1961: Lucas discovers recursive descent, later known as LL
1965: Knuth discovers LR
1969: DeRemer: LALR
1975: The C compiler is converted to LALR
1979: Yacc is released
A little history
4th BCE: Pannini's description of Sanskrit
1951: Kleene's regular languages
1956: The Chomsky hierarchy of Languages
1960: Backus-Naur Form (BNF): Grammar notation
1961: Lucas discovers recursive descent, later known as LL
1965: Knuth discovers LR
1969: DeRemer: LALR
1975: The C compiler is converted to LALR
1979: Yacc is released
1974/1984: Lang, Tomita: Generalized LR
A little history
4th BCE: Pannini's description of Sanskrit
1951: Kleene's regular languages
1956: The Chomsky hierarchy of Languages
1960: Backus-Naur Form (BNF): Grammar notation
1961: Lucas discovers recursive descent, later known as LL
1965: Knuth discovers LR
1969: DeRemer: LALR
1975: The C compiler is converted to LALR
1979: Yacc is released
1974/1984: Lang, Tomita: Generalized LR
1992/1995: Hutton, Wadler: Combinator parsing
A little history
4th BCE: Pannini's description of Sanskrit
1951: Kleene's regular languages
1956: The Chomsky hierarchy of Languages
1960: Backus-Naur Form (BNF): Grammar notation
1961: Lucas discovers recursive descent, later known as LL
1965: Knuth discovers LR
1969: DeRemer: LALR
1975: The C compiler is converted to LALR
1979: Yacc is released
1974/1984: Lang, Tomita: Generalized LR
1992/1995: Hutton, Wadler: Combinator parsing
2006: GNU C reverts to hand-written recursive descent‽
A little history
4th BCE: Pannini's description of Sanskrit
1951: Kleene's regular languages
1956: The Chomsky hierarchy of Languages
1960: Backus-Naur Form (BNF): Grammar notation
1961: Lucas discovers recursive descent, later known as LL
1965: Knuth discovers LR
1969: DeRemer: LALR
1975: The C compiler is converted to LALR
1979: Yacc is released
1974/1984: Lang, Tomita: Generalized LR
1992/1995: Hutton, Wadler: Combinator parsing
2006: GNU C reverts to hand-written recursive descent‽
2008: McBride, Paterson: Applicative-based combinator parsing
What?
- Alternative way of working with parsers.
Combinator Parsing:
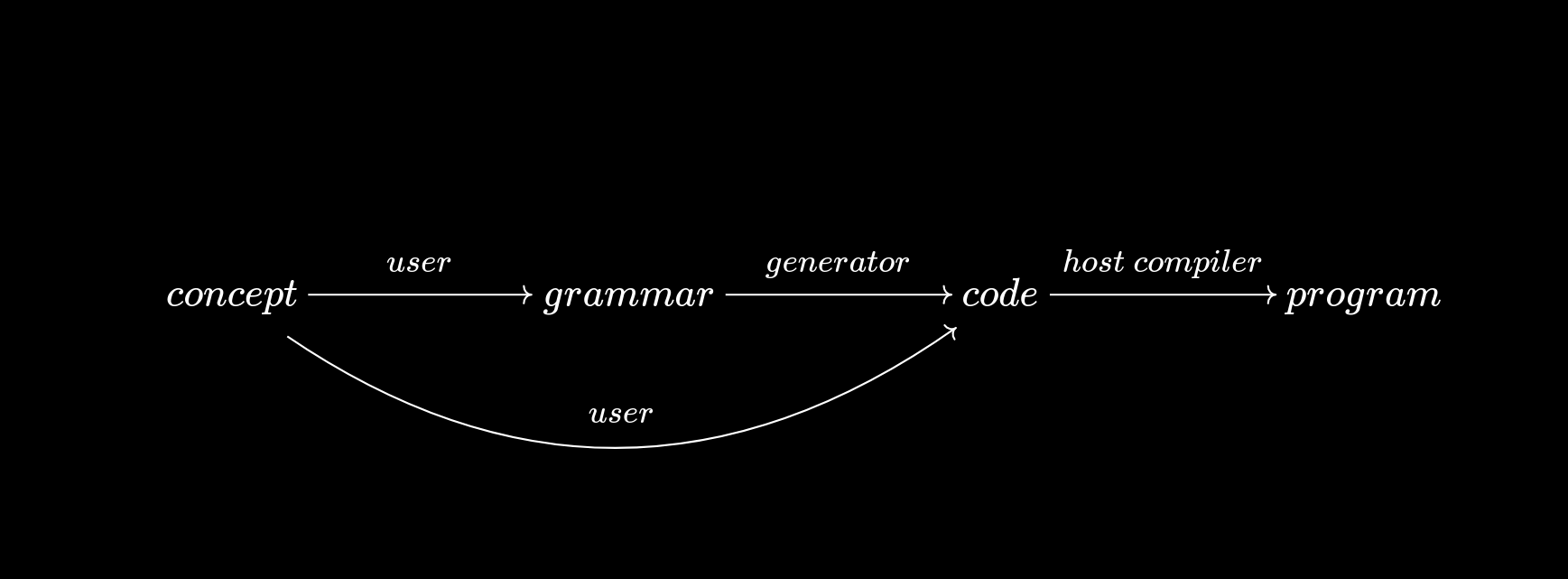

generators:
combinators:
What?
- Alternative way of working with parsers.
- Generators:
- Monolithic grammar file \(\xrightarrow{generate}\) parser code
- Combinators:
- parser + parser = new parser
Combinator Parsing:




How?
Basic idea
-
A parser is a function istream & \(\rightarrow\) T ...
Basic idea
-
A parser is a function istream & \(\rightarrow\) T ...
- ... or rather
istream & \(\rightarrow\) T (on success)
and
istream & \(\rightarrow\) ErrorMessage (on parse failure)
Result<T>
- Contains either a 'T' or an ErrorMessage
- can be modeled as follows:
template <typename T>
struct Result {
bool contains_success = false;
union {
T success_val;
ErrorMessage error_val;
};
Result(T const &val) : contains_success(true), success_val(val) {};
Result(ErrorMessage const &error) : contains_success(false), error_val(error) {};
// NOTE: CopyCons, MoveCons and Destructor ommitted
// But need to be written!
};
Result<T>
- Contains either a 'T' or an ErrorMessage
- can be modeled as follows:
#include <variant>
template <typename T>
struct Result : std::variant<T, ErrorMessage> {
using std::variant<T, ErrorMessage>::variant;
};
Result<T>
- Contains either a 'T' or an ErrorMessage
- can be modeled as follows:
- Adding some extra sugar
#include <variant>
template <typename T>
struct Result : std::variant<T, ErrorMessage> {
using std::variant<T, ErrorMessage>::variant;
/// Shorthand to check for success
explicit operator bool() const {
std::holds_alternative<T>(*this);
}
/// Allow implicit conversions of
/// char -> string
/// T -> vector<T>
/// string -> vector<char>
/// std::tuple<char, char> -> string
/// etc.
template<typename C>
operator Result<C>() const {
if(bool(*this)) {
return convert<C>(std::get<T>(*this));
} else {
return std::get<ErrorMessage>(*this);
}
}
};
Parser:
istream & \(\rightarrow\) Result<T>
Parser:
istream & \(\rightarrow\) Result<T>
#include <functional>
struct Parser : public std::function<Result<T>(std::istream &)> {
using std::function<Result<T>(std::istream &)>::function;
typedef T value_type;
};Basic Idea redux
- A parser is a function...
- ... but still a first-class datatype!
\(\rightarrow\) Write functions returning parsers...
\(\rightarrow\) Write functions taking parsers as params...
\(\rightarrow\) ... or both!
Basic Idea redux
- A parser is a function...
- ... but still a first-class datatype!
\(\rightarrow\) Write functions returning parsers...
\(\rightarrow\) Write functions taking parsers as params...
\(\rightarrow\) ... or both!
Combinators
{
Building blocks:
- Some primitive 'builtin' parsers
- Ways to combine them: combinators
- operator overloading: Domain-Specific Language/Syntactic Sugar
Primitive parsers
constant
template<typename T>
Parser<T> constant(T const &val){
return [=](std::istream &){ return val; });
}
Primitive parsers
char_
/// Parse exactly the character `target`.
Parser<char> char_(char target) {
return [=](std::istream &input) -> Result<char> {
char val = input.peek();
if (val == target) {
input.ignore();
return val;
} else {
return ErrorMessage{std::string{1, target}};
}
};
}
Primitive parsers
satisfy
/// Parse and return any character satisfying `checking_fun`.
/// examples: `satisfy(isspace, "space")`, `satisfy(isdigit, "digit")` etc.
Parser<char> satisfy(std::function<bool(char)> checking_fun, const char *name) {
return [=](std::istream &input) -> Result<char> {
char val = input.peek();
if(checking_fun(val)) {
input.ignore();
return val;
} else {
return ErrorMessage{std::string{"any `"} + name + '`'};
}
};
}
Primitive parsers
digit
/// Parse any decimal digit
Parser<char> digit() {
return satisfy(isdigit, "digit");
}
Primitive parsers
space
/// Parse any single whitespace character
Parser<char> space() {
return satisfy(isspace, "space");
}Primitive parsers
char_ redux
// Or alternatively:
Parser<char> char_(char target) {
return satisfy(
[target](char val) { return val == target; },
std::string{target}.c_str()
);
}
Primitive parsers
string_
/// Parse exactly the string `target`.
/// Note that this implementation allows for backtracking and is inefficient.
/// A more efficient implementation is left as an exercise for the reader ;-)
Parser<std::string> string_(std::string const &target) {
return [=](std::istream &input) -> Result<std::string> {
for(size_t index = 0; index < target.size(); ++index) {
if(input.peek() == target[index]) {
input.get();
} else {
// Restore input:
while(index--) {
input.unget();
}
return ErrorMessage{target};
}
}
return target;
};
}
Primitive parsers:
- constant
- char_
- satisfy
- string_
Combinators:
...
Examples:
- digit
- space
Combinators
transform
/// Transform the result of a parser into another type of result
/// by running a function `fun` on it.
///
/// (Note: The templated arguments allow C++ to do more automatic type-inference
/// than if we'd use `std::function` instead.)
template<typename A, typename F>
auto transform(Parser<A> const &parser, F const &fun)
-> Parser<decltype(fun(std::declval<A>()))>
{
return [=](std::istream &input) -> Result<decltype(fun(std::declval<A>()))> {
Result<A> res = parser(input);
if (!bool(res)) { return std::get<ErrorMessage>(res); }
return fun(std::get<A>(res));
};
}
Combinators
transformError
template<typename A, typename F>
auto transformError(Parser<A> const &parser, F const &fun)
-> Parser<A>
{
return [=](std::istream &input) -> Result<A> {
Result<A> res = parser(input);
if (!bool(res)) { return ErrorMessage{fun(std::get<ErrorMessage>(res))}; }
return res;
};
}
Combinators
sequence (>>)
/// Compose two parsers in sequence: Run `p1` followed by `p2`.
/// Fails when either one fails, only succeeds if both suceed.
template<typename A, typename B>
auto operator >>(Parser<A> const &p1, Parser<B> const &p2)
-> Parser<typename decltype(Result<A>() + Result<B>())::value_type>
{
return [=](std::istream &input) -> decltype(Result<A>() + Result<B>()) {
Result<A> res1 = p1(input);
if(!bool(res1)) { return std::get<ErrorMessage>(res1); }
Result<B> res2 = p2(input);
if(!bool(res2)) { return std::get<ErrorMessage>(res2); }
return res1 + res2;
}
};
}
Combinators
Side note: Adding two results
template <typename A, typename B>
auto operator +(Result<A> const &lhs, Result<B> const &rhs)
-> Result<decltype(wrapInTuple(std::get<A>(lhs), std::get<B>(rhs)))>
{
if(!bool(lhs)) { return std::get<ErrorMessage>(lhs); }
if(!bool(rhs)) { return std::get<ErrorMessage>(rhs); }
return wrapInTuple(std::get<A>(lhs), std::get<B>(rhs));
};
Combinators
alternative (|)
/// Compose two parsers as alternatives: Run `p1` or alternatively `p2`.
/// Fails when both fail, succeeds when either one succeeds.
template<typename A>
Parser<A> operator |(Parser<A> const &lhs, Parser<A> const &rhs) {
return [=](std::istream &input) -> Result<A> {
Result<A> res1 = lhs(input);
if (bool(res1)) { return res1; }
Result<A> res2 = rhs(input);
if (bool(res2)) { return res2; }
return ErrorMessage{
std::get<ErrorMessage>(res1).message +
" or " +
std::get<ErrorMessage>(res2).message
};
};
}
Combinators
choice
template <typename T>
Parser<T> choice(Parser<T> const &parser) {
return parser;
}
template <typename T, typename... Ts>
Parser<T> choice(Parser<T> const &first, Ts... rest) {
return first | choice(rest...);
}
- transform
- transformError
- sequence (>>)
- alternative (|)
Primitive parsers:
- constant
- char_
- satisfy
- string_
Combinators:
Examples:
- digit
- space
Done with the foundation
- From now on, no need to look into the internals of Parser/Result anymore.
- (Sometimes it is still nicer for efficiency, though)
Extending our Toolbox
ignore
/// ignore result of `parser`
/// and just return an empty tuple
/// (which will disappear when this parser is used in sequence with other parsers)
template<typename T>
Parser<std::tuple<>> ignore(Parser<T> const &parser) {
auto discard = [](T const &) { return std::make_tuple(); };
return transform(parser, discard);
}
Extending our Toolbox
maybe
template<typename T>
Parser<T> maybe(Parser<T> elem) {
return elem | constant(T{});
}
Extending our Toolbox
many, many1
template<typename Container>
Parser<Container> many(Parser<typename Container::value_type> element_parser) {
return many1(element_parser) | constant(Container{});
}
template<typename Container>
Parser<Container> many1(Parser<typename Container::value_type> element_parser) {
return element_parser >> many(element_parser);
}
Extending our Toolbox
many, many1
template<typename Container>
Parser<Container> many(Parser<typename Container::value_type> element_parser) {
return many1<Container>(element_parser) | constant(Container{});
}
template<typename Container>
Parser<Container> many1(Parser<typename Container::value_type> element_parser) {
return element_parser >> many<Container>(element_parser);
}
Extending our Toolbox
many, many1
template<typename Container>
Parser<Container> many(Parser<typename Container::value_type> element_parser) {
return lazy(many1<Container>(element_parser)) | constant(Container{});
}
template<typename Container>
Parser<Container> many1(Parser<typename Container::value_type> element_parser) {
return element_parser >> many<Container>(element_parser);
}
#define lazy(parser) [=](std::istream &input) { return (parser)(input); }
Extending our Toolbox
many, many1
template<typename Container>
Parser<Container> many(Parser<typename Container::value_type> element_parser) {
return many1<Container>(element_parser) | constant(Container{});
}
template <typename Container>
Parser<Container> many1(Parser<typename Container::value_type> element_parser) {
using T = typename Container::value_type;
return [=](std::istream &input) -> Result<Container> {
auto first = element_parser(input);
if (!bool(first)) { return std::get<ErrorMessage>(first); }
Container container;
container.push_back(std::get<T>(first));
while (true) {
auto next = element_parser(input);
if (!bool(next)) { return container; }
container.push_back(std::get<T>(next));
}
};
}
Extending our Toolbox
digits
Parser<std::string> digits()
{
return many1<std::string>(digit);
}Extending our Toolbox
uint
Parser<std::string> uint()
{
return transform(digits, std::stoul);
}Extending our Toolbox
int_
Parser<char> sign()
{
return char_('+') | char_('-');
}
Parser<std::string> signed_digits()
{
return maybe(sign) >> digits;
}
Parser<long int> int_()
{
return transform(signed_digits, std::stol);
}Extending our Toolbox
double_
Parser<double> double_() {
Parser<std::string> vals =
signed_digits
>> maybe(char_('.') >> digits)
>> maybe(char_('e') >> signed_digits);
return transform(vals, std::stod);
}
But what about binary expressions?
But what about binary expressions?
Solution:
- chainl1/chainr1, each taking:
- element parser Parser<A>,
- combining parser Parser<A(A, A)>
But what about binary expressions?
Solution:
- chainl1/chainr1, each taking:
- element parser Parser<A>,
- combining parser Parser<A(A, A)>
!!
Extending our Toolbox
chainl1
template<typename A>
Parser<A> chainl1(Parser<A> const &elem, Parser<std::function<A(A, A)>> const &binop) {
using F = std::function<A(A, A)>;
return [=](std::istream &input) -> Result<A> {
Result<A> lhs = elem(input);
if (!bool(lhs)) { return lhs; }
Result<A> res = lhs;
while(true) {
Result<F> binop_res = binop(input);
if (!bool(binop_res)) { return res; }
Result<A> rhs = elem(input);
if (!bool(rhs)) { return res; }
res = std::get<F>(binop_res)(std::get<A>(res), std::get<A>(rhs));
}
};
}
Extending our Toolbox
chainr1
template<typename A>
Parser<A> chainr1(Parser<A> const &elem, Parser<std::function<A(A, A)>> const &binop) {
using F = std::function<A(A, A)>;
return [=](std::istream &input) -> Result<A> {
Result<A> lhs = elem(input);
if (!bool(lhs)) { return lhs; }
Result<A> res = lhs;
Result<F> binop_res = binop(input);
if (!bool(binop_res)) { return res; }
Result<A> rhs = chainr1(elem, binop)(input); // <- recurse!
if (!bool(rhs)) { return res; }
return std::get<F>(binop_res)(std::get<A>(res), std::get<A>(rhs));
};
}
Extending our Toolbox
example
Parser<std::function<double(double, double)>> plus() {
return ignore(char_('+')) >> constant(std::plus());
}
Parser<std::function<double(double, double)>> minus() {
return ignore(char_('-')) >> constant(std::minus());
}
Parser<double> adding_doubles() {
return chainl1(double_, plus | minus);
};
Extending our Toolbox
example
Parser<std::function<Expr(Expr, Expr)>> plus() {
return ignore(char_('+')) >> constant([](auto lhs, auto rhs){ return PlusExpr{lhs, rhs}; });
}
Parser<std::function<Expr(Expr, Expr)>> minus() {
return ignore(char_('-')) >> constant([](auto lhs, auto rhs){ return MinusExpr{lhs, rhs}; });
}
Parser<Expr> adding_example2() {
return chainl1(term, plus | minus);
};
- transform
- transformError
- sequence (>>)
- alternative (|)
- ignore
- many
- many1
- maybe
- chainl
- chainr
Primitive parsers:
- constant
- char_
- satisfy
- string_
Combinators:
Examples:
- digit
- space
- digits
- uint
- int_
- double_
- plus
- minus
- expr
Et Cetera...
How to deal with nested expressions & operator precedence?
How to deal with nested expressions & operator precedence?
Parser<double> term();
Parser<double> expression()
{
return makeExpressionParser(
term,
prefix(neg),
binary_right(exp),
binary_left(mul, divide),
binary_left(plus, minus)
);
}
Parser<double> term()
{
return double_ | parenthesized(expression);
}Separate lexer?
- Possible, but often replaced by just:
we'll get back to this
/// parses `parser` followed by possible whitespace which is ignored.
template<typename T>
Parser<T> lex(Parser<T> parser) {
return parser >> ignore(whitespace);
}
Why?
- Disadvantages
- (Only) as ergonomic as the EDSL
- Relies on the host compiler for efficiency
- Less well-known (around for 'only' 20 years vs. 50 for generators)
- Advantages:
- Small building blocks
- Stay inside the host language
- Parsers are first-class datatypes: tests, highlighting, compiler errors, etc.
- Parsers compose!
LL vs. LR etc...
- Parser Combinators are commonly LL...
- ... but need not be!

LL, LR, Regex, GLR, etc!
LL, LR, Regex, GLR, etc!
Even pretty-printers!
Conclusion
- Promising alternative parsing approach
- Boost.Spirit, Lexy (C++), Parsec and derivatives (Haskell), Nom (Rust), NimbleParsec (Elixir), parsy (Python) ... and many more
Outline
- What?
- How?
- Why?
- Conclusion
Remarks
- Presentation Example code online
- MF1F for simplicity's sake
- Two implementations:
- Simple one you saw during presentation
- semi-optimized one (partially finished) using an IR with CRTP & constexpr.