GaiA
Distributed, planetary-scale AI safety
A seminar on Probably Safe AI
June 13, 2024
Rafael Kaufmann
In this seminar, we will cover:

AIEverything safety
The Metacrisis in a nutshell:
Everything is connected (climate, food, security, biodiv)
× Billions of highly-capable intelligent agents (today's focus)
× Coordination failure ("Moloch")
= Total risk for humanity and biosphere
Schmachtenberger: hypothesized attractors
- Chaotic breakdown
- Oppressive authoritarian control
Before this:
Today's AI Risks: Misspecification + coordination failure = compounded catastrophic risk

Before this:
Today's AI Risks: Misspecification + coordination failure = compounded catastrophic risk
We'll have exponentially more of this:

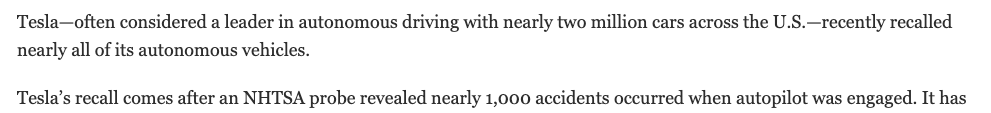



Case study: managing the Risk of AI-ACCELERATED overharvesting and ecosystem collapse

Case study: managing the Risk of AI-ACCELERATED overharvesting and ecosystem collapse

multiple people have had ~the same idea at around the same time

But the devil is in the details
davidad: "Safeguarded AI"

Steve Omohundro:
"Provably safe AI"
World models + guarantees + safeguards

Yoshua Bengio:
"AI scientist"
Case Study:
The obvious idea (ex. Bengio, 2023): Bayesianism!
AI Safety in the real world, Part 1: Modeling
But...
Science: Which candidate world models (hypotheses)? How to weigh them?
Praxis: How to get the right context?
Axiology: What is harm? Binary?
ai safety IN THE REAL WORLD, Part 1: Modeling
Ex: susceptibility to ruin influences risk aversion, discount rates (Ole Peters, ergodicity economics)
"Axiological humility": added layer of variation/uncertainty from outcomes to values/exposures
modeling the axiology of safety
"Preference prior" (ActInf): biased world model
Satisficing preferences.
Not binary (why?)
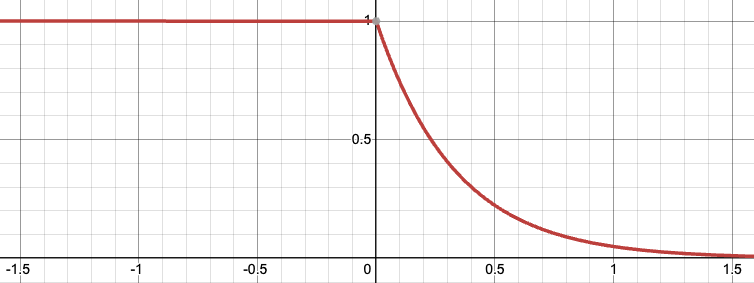
risk Exposure AS free energy
"Free energy of the future" (Millidge et al, 2021) - lower bound on expected model evidence, maximize reward while minimizing exploration
In a fully observable setting this simplifies to:
Cf. conditional expected shortfall (finance), KL control (control theory)
Modeling modeling
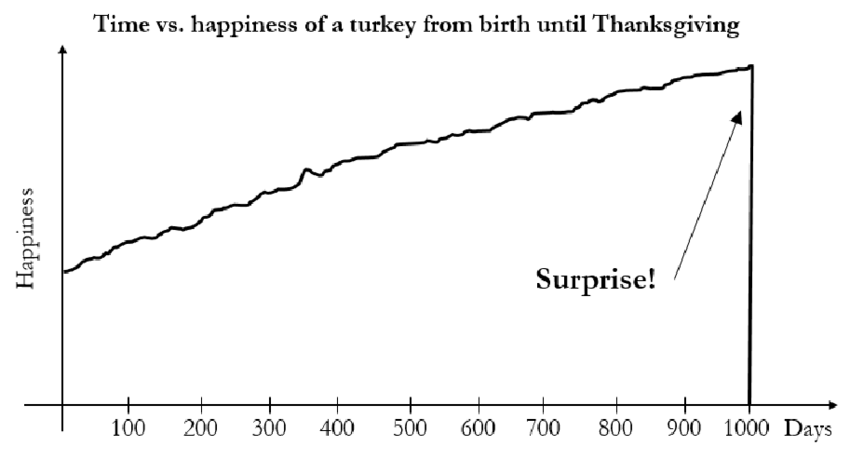
m1 = best fit to data...
until day 1000
m2 = best fit to data
afterwards
"Epistemic humility": model weights depend on context
Model uncertainty matters a lot (ex: Taleb's Turkey)
Estimating small probabilities requires more data than you think
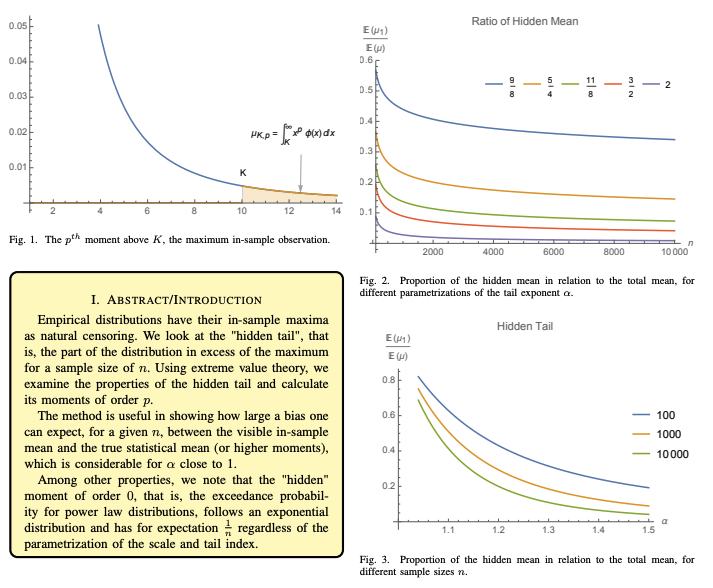
Taleb (2020)
Overfishing Case study
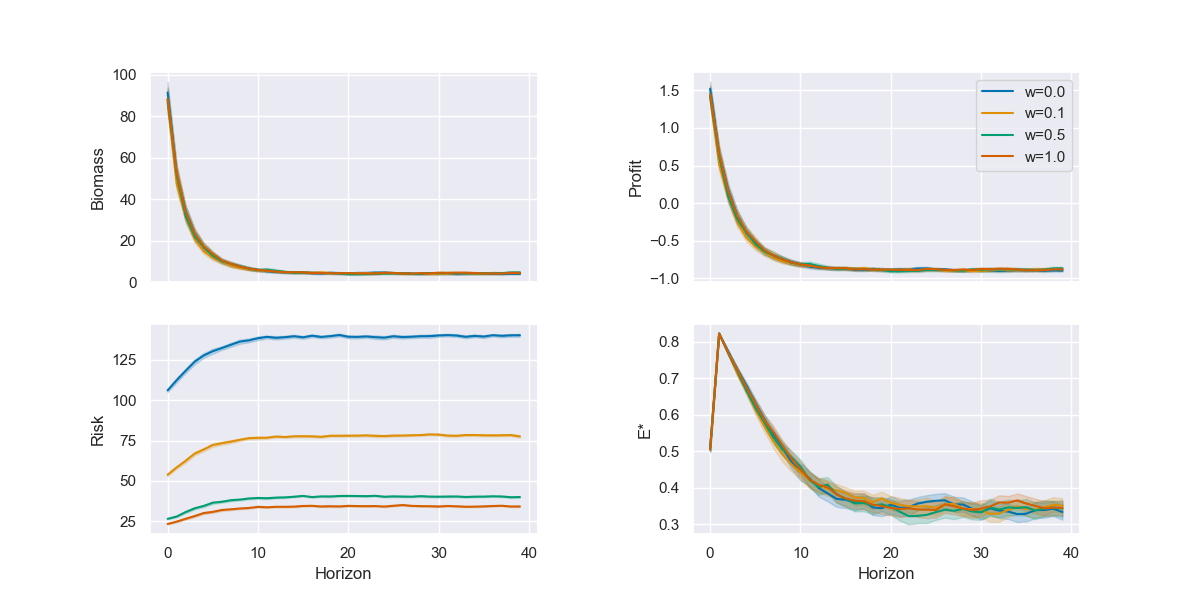
Myopic (single-season) profit-maximizing agents deplete population (and profits)
Less time discounting = higher perceived risk, earlier
ai safety IN THE REAL WORLD, Part 3: SafeguardS
def isSafe(action, context):
return p(harm | action, context, data) < ε
...
class SafeActuator(Actuator):
def perform(self, action):
context = selectContext(...)
if isSafe(action, context):
super.perform(action)
else:
alert("I'm afraid I can't do that")How to compute this (including averaging over models) with high accuracy at high actuation frequencies (potentially GHz)?
Potential attack surface!
Option 1: real-time gatekeeping (Bengio-ish)
ai safety IN THE REAL WORLD, Part 3: SafeguardS
def isSafe(agent, environment):
for C in environment.PossibleInitialConditions:
trajectories = sampleTrajectories(agent, environment, C, \
nTrajectories)
nSafe = len(trajectories.filter(t => isSafe(t)))
if nSafe / nTrajectories < 1 - ε:
return False
return True
...
class SafeDeployer(Deployer):
def deploy(self, agent):
if isSafe(agent, self.environment):
super.deploy(agent)
else:
alert("I'm afraid I can't do that")Need to sample (simulate) trajectories over multiple, complex world models (probability weighed)
How many sample trajectories are needed for comfort?
Option 2: ex ante guarantees (davidad)
For all ("plausible?") initial conditions!
An infinite family
ai safety IN THE REAL WORLD, Part 3: SafeguardS
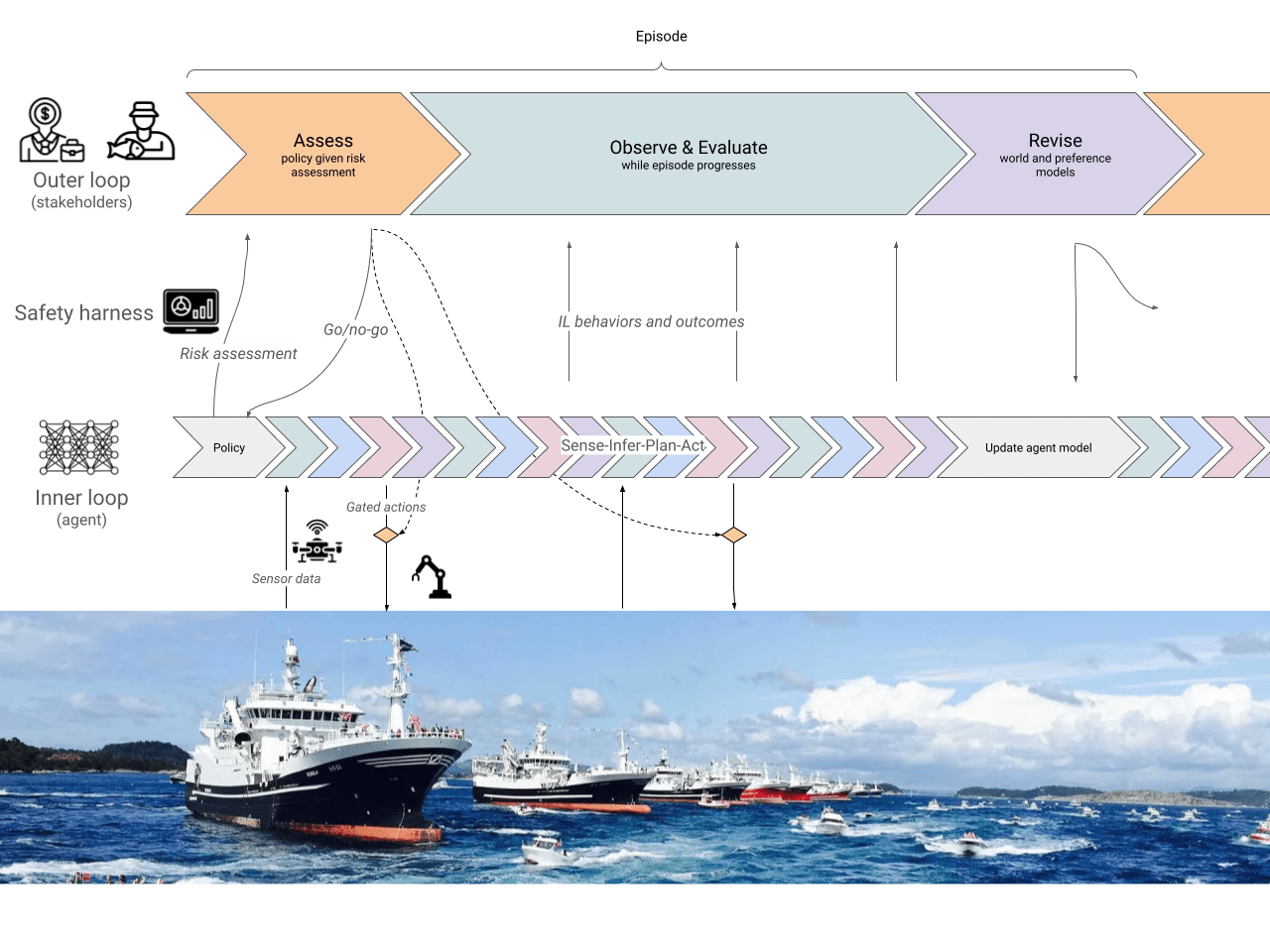
Option 3: risk assessment and oversight (RK / traditional safety engineering)
class SafeHarness(DeploymentHarness):
def constrainPolicy(policy):
R = cumulativeRiskExposure(policy, self.env)
if R < ε:
return policy
else:
policy_, R_ = policySearch(start=policy, \
stop=lambda p: risk(p, self.env) < ε)
if R_ < ε:
return policy_
else:
return self.defaultPolicy
def registerAgentPolicy(self, context):
proposedPolicy = self.agent.proposePolicy(context)
constrainedPolicy = self.constrainPolicy(policy, context)
super.registerAgentPolicy(self, self.agent, constrainedPolicy, context)
def actuate(self, action, context):
if self.registeredPolicy(self.agent, context).contains(action):
super.actuate(action)
else:
alert("I'm afraid I can't do that")Overfishing Case study
Overfishing Case study
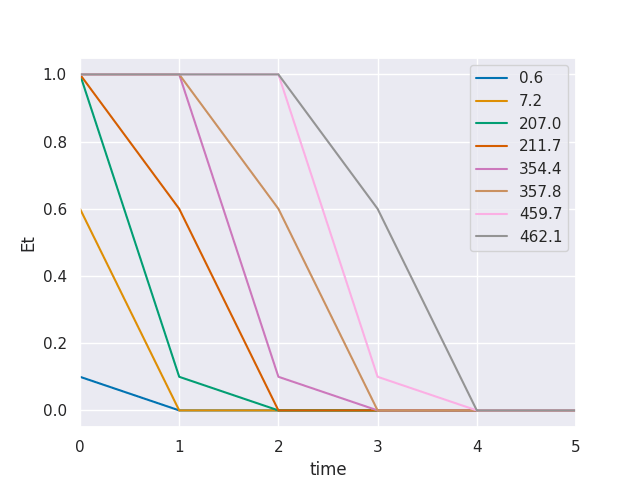
Constrained policy for various ε
ai safety IN THE REAL WORLD, Part 2: Proof
Just kidding: no "proof" in the real world! Map != territory
Alternative: "an auditable proof certificate that the AI satisfies the safety specification relative to the world model" (davidad et al, 2024). Possible, but probably useless (red herring)
The best you can do: lots of induction over a wide variety of models + robustness (decision engineering)

Taleb, 2014
Example: faulty gatekeeper
A bug in the gatekeeper code! With unknown probability p, it allows any action
def actuate(self, action, context):
if self.registeredPolicy(self.agent, context).contains(action):
super.actuate(action)
else:
alert("I'm afraid I can't do that")"Ideal" answer: this shouldn't happen! Prove the entire stack is correct, including dependencies, OS, hardware... (Implicit world model assumptions galore, incl. probabilities of arbitrarily capable adversaries)
Sometimes returns true when it shouldn't 😬
Safety engineer's answer: increase the margin of safety! No assumptions, just act on the exposure
What if ? Then it's time for decision engineering
padded estimate of p
In our framework, the default exposure
is unbounded from below and (globally) concave
Decision engineering
WHEN CAN YOU JUST DO IT? WHEN SHOULD YOU JUST NOT DO IT?
Can we change the environment (rules of the game, payoffs, etc) such that exposure is left semi-convex and, even better, bounded from below?
This makes our system robust: the worse the policy, the slower the exposure accelerates, and eventually it tapers off
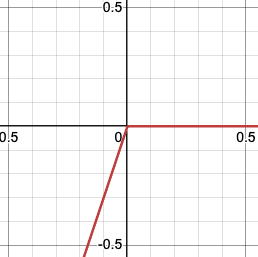
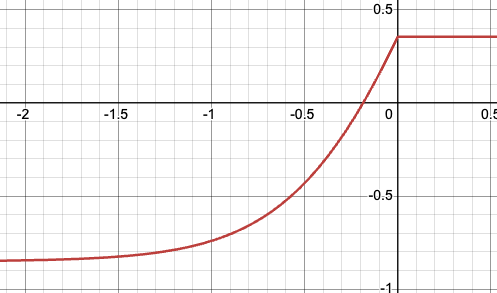
(Formally, adding any delta to the default does the trick. But not always practically possible!)
Back to:
Where do models come from?
How to weigh them?
How to ensure quality?
How to compute this efficiently and correctly?
The Gaia Network
A WWW of world/decision models



Goal: Help agents (people, AI, organizations) with:
-
Making sense of a complex world
-
Grounding decisions, dialogues and negotiations
How: Decentralized, crowdsourced, model-based prediction and assessment
Where: Applications in:
- Safe AI for automation in the physical world (today's focus)
- Climate policy and investment
- Participatory planning for cities
- Sustainability and risk mitigation in supply chains
- Etc
How Gaia works (in a nutshell)
1
"Git for world models"
A distributed repository of statistical models and observational/experimental data
Protocol for P2P model scoring
Based on Bayesian probability theory
2
Querying as distributed simulation/sampling
Full chain of data and analysis, with attribution
3
Dispute resolution through competition on quality
Over time, Gaia converges on the best models, crediting the best contributors
4
Knowledge economy
Incentives for targeted, high-quality data collection, experiment and analysis
5
1
"Git for world models"
Like the Web is made up of websites that host content, Gaia is made up of nodes that host claims (which we call beliefs) about the world.
Beliefs are computed from observational data + probabilistic models.
The dependencies between models form a distributed world model.
Protocol for P2P model scoring
2
Just like a website can host any content, a node can host any beliefs. However, some beliefs are more useful than others: they agree with the available evidence and help predict future data (Bayesian probability theory, “the logic of science”).
Gaia scores beliefs by their usefulness, using the following protocol:
- Nodes score each other on the basis of usefulness = contribution to free energy reduction in decision-relevant beliefs (*)
- Contributions are rated by trustworthiness = cumulative explanatory power compared to alternatives (not authority!)
- Scores “trickle down” the graph, forming a way to account for the value of beliefs.
Nodes with low-usefulness beliefs get attributed low scores by their peers, and tend to become ignored.
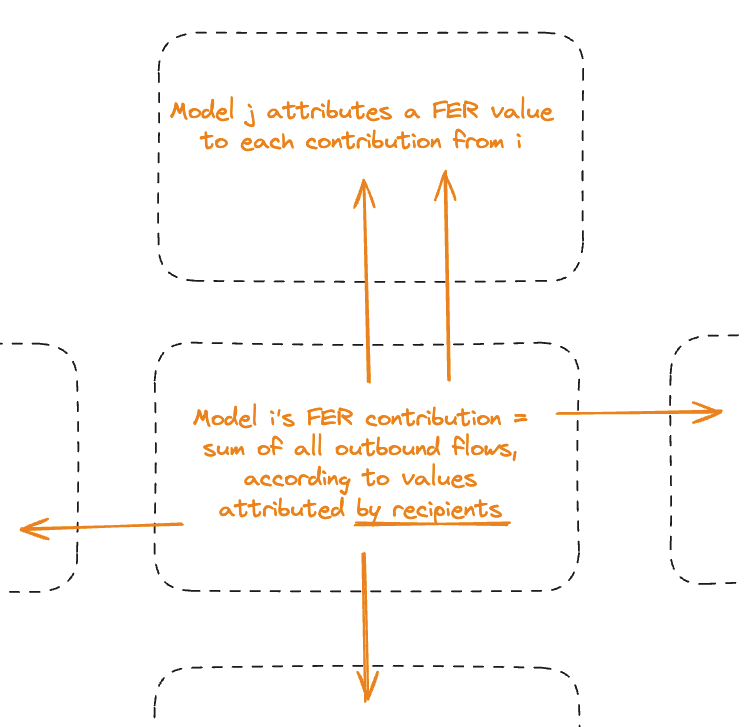
(*) Variational free energy = computable measure of goodness for approximate inference. Decision-relevant = impacts query results, see #3
Querying as distributed simulation/samplin
3
Gaia answers users' pivotal questions in high-stakes decisions: Where to prioritize investments to stabilize the economy in light of climate change? How to value real estate in light of climate and nature risk? Is this autonomous system capable of causing harm?
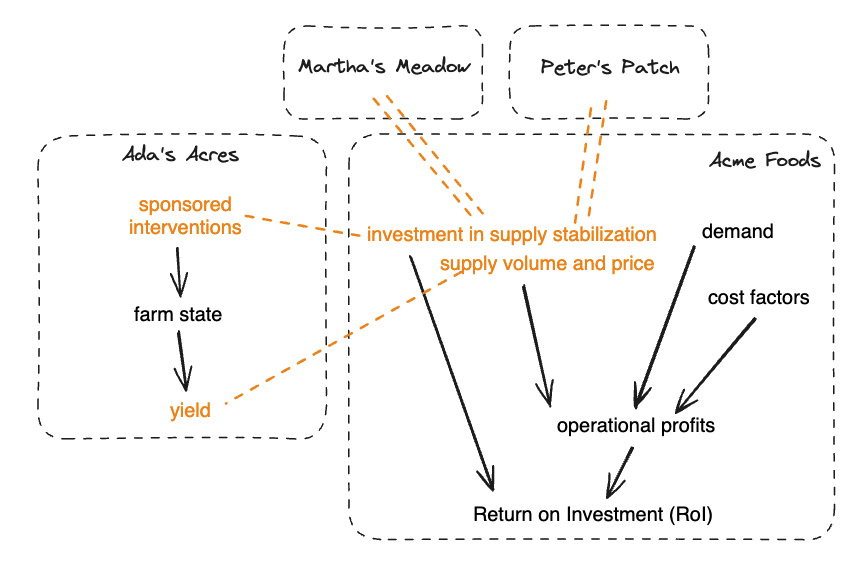
Unlike Google, this computation is distributed across the nodes, simulating thousands of possible scenarios. Then the simulation results get aggregated back at the querying node to form summary beliefs.
Questions are expressed as queries to a Gaia node, which query all the other relevant nodes that it needs in order to intelligently update its beliefs. Just like Google queries knowledge aggregated across billions of sources on the fly to answer user queries.
Dispute resolution through competition on quality
4
If you think the output of a node seems wrong, instead of trying to argue and convince people on Twitter, you just set up your own node using an alternative model and publish its beliefs to the network.
Your peer nodes will compare the alternate models and score them by their usefulness and truthfulness.
This is how Gaia evolves and is resilient to error and misinformation.
Knowledge economy (*)
5
Gaia’s contribution accounting can be used to incentivize users to quickly publish lots of high-quality knowledge.
A Gaia user could pay a node for the value of the information it provides (for instance, by helping reduce risk in a high-stakes investment), and the node would distribute payments upstream to its own information providers, and so on, creating a data value chain.
(*) This part is more speculative: while accounting is straightforward and objective, pricing is intrinsically intersubjective. However, Active Inference theory gives a grounded answer here as well, in the form of expected free energy minimization.
Designing a third attractor
great, but...
Will they use it?
Target opportunity 1: high-stakes complex systems like climate, epidemiology, ecology, infrastructure management and much of public policy, where pivotal questions are often the hardest to answer and controversy is rife.
There’s a strong desire from both knowledge creators and decision-makers to ensure decisions are well-grounded.
But the state of the art is primitive:
- Publishing knowledge: PDF papers and websites
- Turning knowledge into decisions: Google Search + spreadsheets and documents
This knowledge cycle is slow, expensive, non-scalable and prone to bias.
Gaia can help users systematically ground their decisions on all the relevant knowledge, with rationales tracing back to the relevant sources and assumptions, making decisions more efficient, transparent and trustworthy.
Sample App #1
Collaborative climate science to unlock action and direct research.
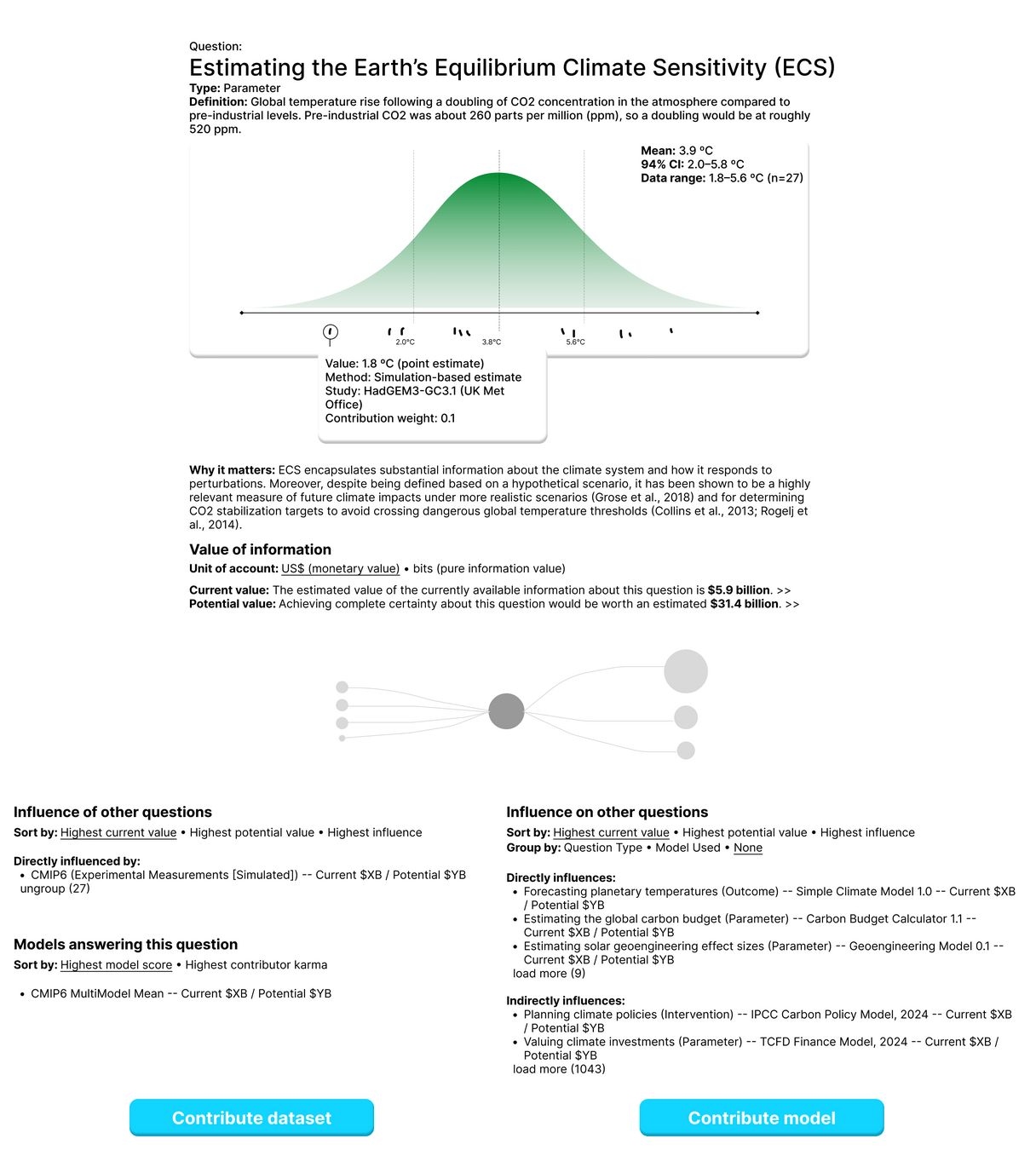
Sample App #2
Analyze and mitigate nature risk to food supply. (Real-world)
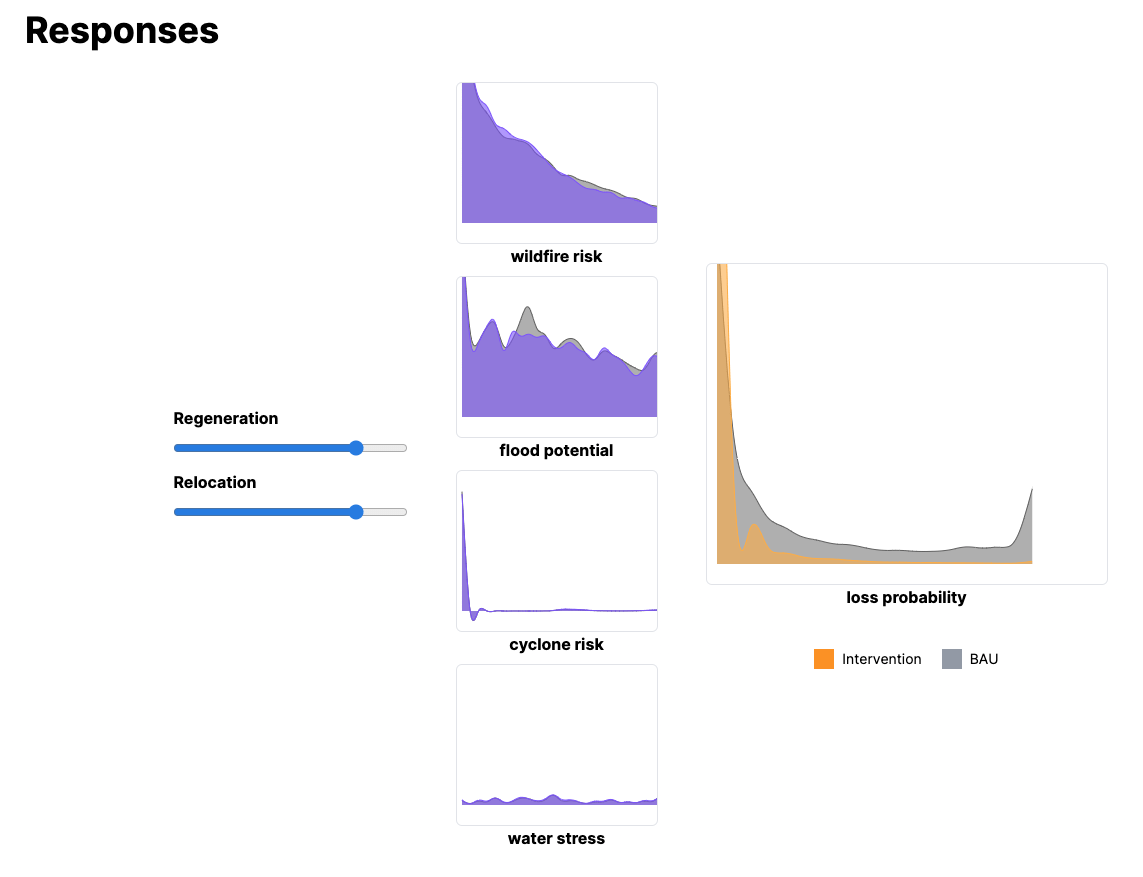



Sample App #3
Estimate and forecast the impact of regeneration projects. (Real-world)
Towards "Everything Safety"
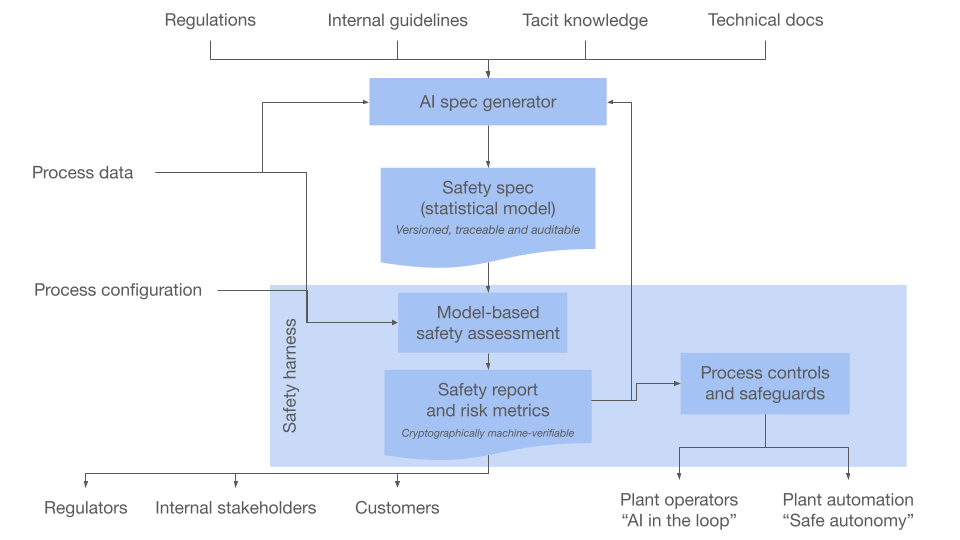
What's next
"The hardest part would be assembling a good initial library of starting models. (...) Bad models, too few models, too narrow a variety of models—these shortcomings will most limit the emerging designs. This hazard will be worst at the beginning." - Brooks, 1995
Solution: AI coder/modeler + human mental models expressed as natural language or formal equations (scraped from the web, interactively inputted by stakeholders, or a mix)
Bootstrapping a model network
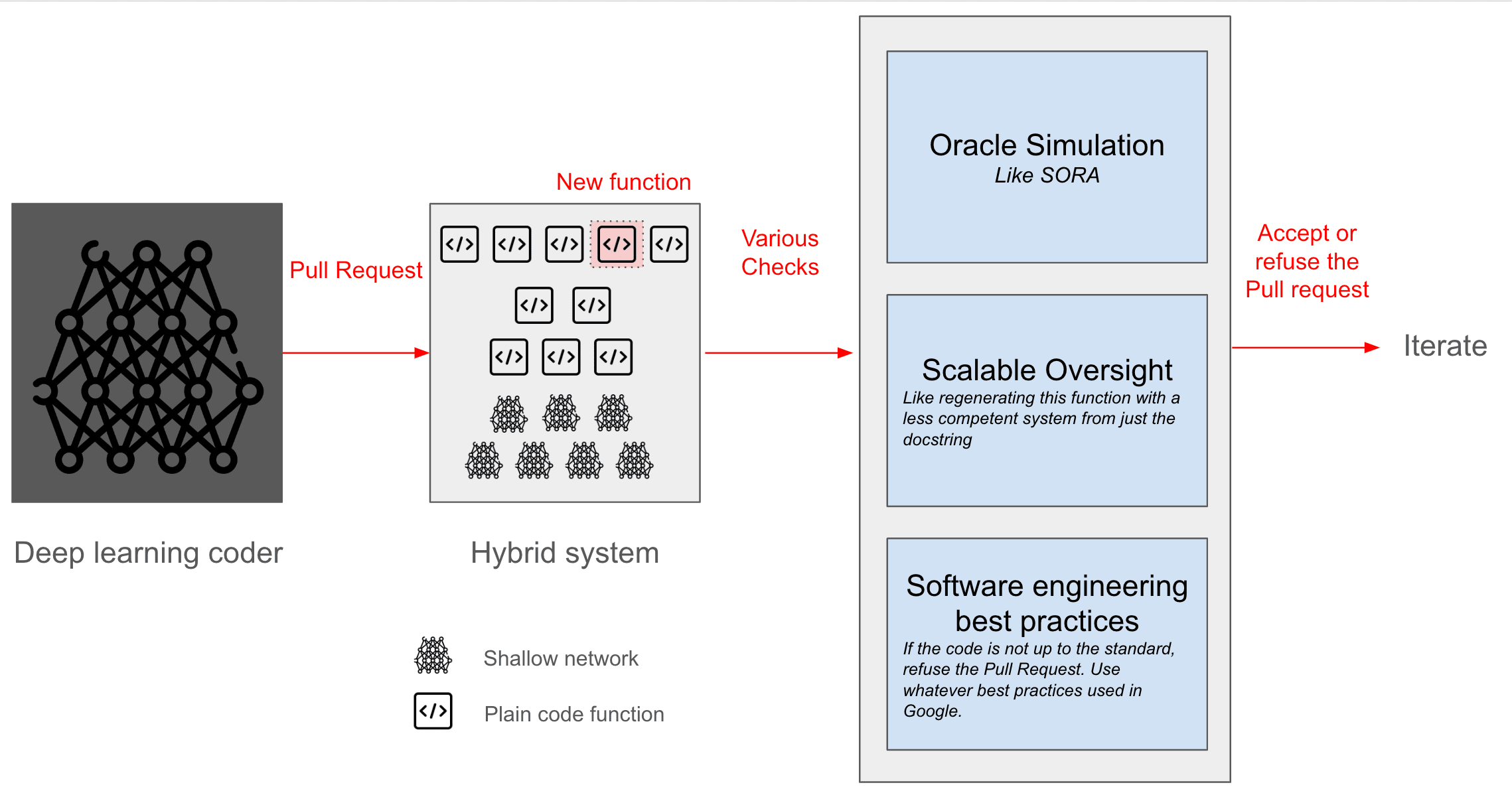
Gédéon and Segerie, 2024
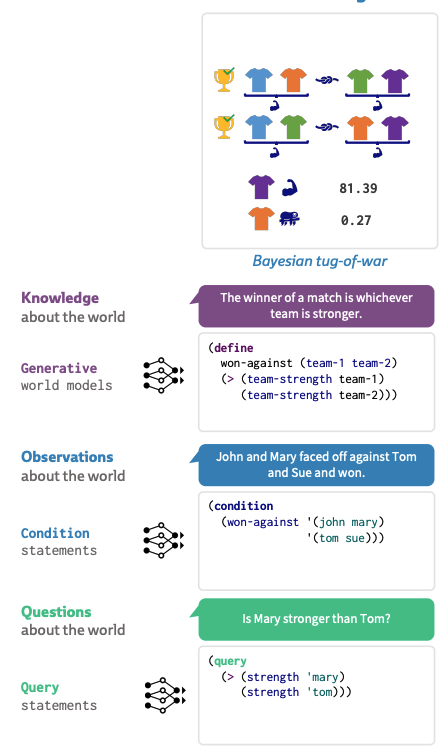
Wong et al, 2023

Gaia team, 2023
General idea (Kaufmann & Leventov, 2023):
- To the extent that contamination can be filtered out or ignored, Gaia will converge towards a truthful body of knowledge (because Gaia implements Bayesian updating)
- To the extent that Gaia has truthful knowledge, it will be economical to filter out or ignore arbitrarily large amounts of contamination (because Bayesian updating is generally reversible and Gaia storage is append-only)
But: "in the long run we're all dead" (Keynes, 1923). "Good enough" in practice: requires good meta-analysis and measurement models, trust/network models, a liquid knowledge economy...
"Good-enough" credit assignment and economics
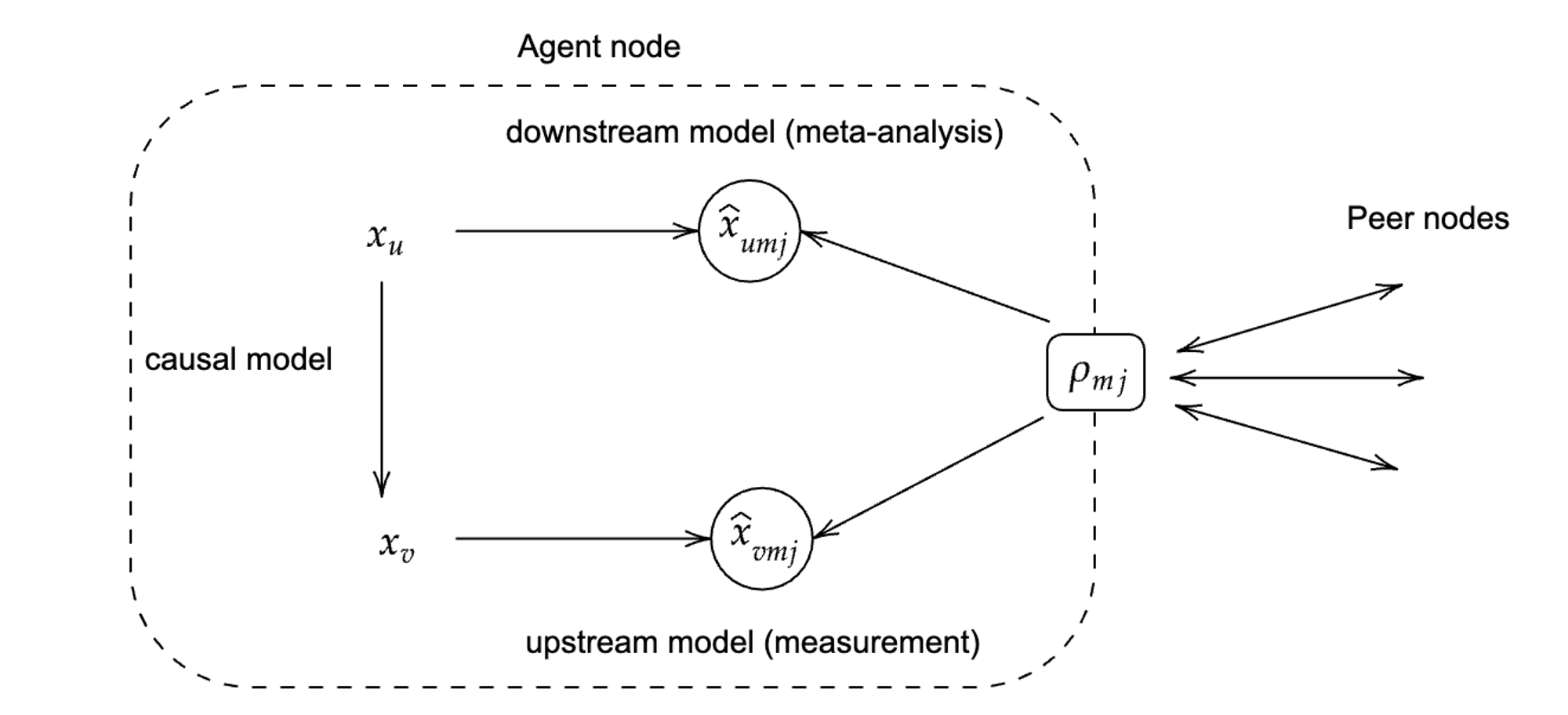
Gaia team, 2023
Problem: What's Gaia's equivalent of PageRank? Without it, worst-case network load is O(n^2) in a strongly coupled system (aka the real world)
General idea (unpublished and untested): Use GFlowNets (Bengio et al) to amortize inference. Each node maintains a neural surrogate of itself + "everything" it needs to know about the rest of the world to answer queries about itself. Nodes amortize the costs of keeping this surrogate, in exchange for keeping network compute load at O(1)
Note: We can look at the different GFlowNet training objectives (detailed balanced, trajectory balance, sub-trajectory balance...) as encoding market equilibria in a knowledge economy (previous slide). Lots of interesting theory here!
Scalable distributed inference
Gaia team, 2023
Problem (Taleb, 2014): Fat tails disguise as thin tails, for ~indefinitely long, and their effect is ~arbitrarily large
General idea (also Taleb): Agents that are aware of this and harden their decisions against model error, instead of naively assuming their model is good enough/can be made good enough with enough data
Not just good advice for humans, but also for AIs! Hierarchical Active Inference
What about model error?
Taleb, 2007
- More real-world use cases
- Generalize existing infrastructure
- Complete development
What else?
Some of Our contributors (so far)!









Help us build the planetary web of models and create safe aieverything
rafael.k@digitalgaia.earth