Rafael monteiro
Fundamentos estatísticos
Desafio
Você recebeu a tarefa de de apresentar, para a diretoria, os dados e insights contidos na base de vendas de 2023.
| Cliente | Produto | Valor unitário | Unidades | Valor total | Data da venda |
|---|---|---|---|---|---|
| AB-1 | Refrigerante | R$ 8,00 | 100 | R$ 800,00 | 02/01/2023 |
| BA-5 | Cerveja | R$ 12,00 | 1000 | R$ 12.000,00 | 10/01/2023 |
| CD-3 | Suco | $ 9,50 | 250 | R$ 2.375,00 | 14/01/2023 |
| DD-15 | ... | ... | ... | ... | ... |
É preciso resumir esses dados!
Mas como???

Estatística!
- Média
- Mediana
- Moda
- Variância
- Desvio padrão
- etc...
Média
Qual o valor usual de uma venda realizada em janeiro?
| Cliente | Produto | Valor unitário | Unidades | Valor total | Data da venda |
|---|---|---|---|---|---|
| AB-1 | Refrigerante | R$ 8,00 | 100 | R$ 800,00 |
02/01/2023 |
| BA-5 | Cerveja | R$ 12,00 | 1000 | R$ 12.000,00 | 10/01/2023 |
| CD-3 | Suco | $ 9,50 | 250 | R$ 2.375,00 | 14/01/2023 |
| DD-15 | Água | R$ 4,00 | 5000 | R$ 20.000,00 | 01/02/2023 |
| EB-76 | ... | ... | ... | ... | ... |
Soma todos os elementos
Divide pela quantidade de elementos
Média
Qual o valor usual de uma venda realizada em janeiro?
| Cliente | Produto | Valor unitário | Unidades | Valor total | Data da venda |
|---|---|---|---|---|---|
| AB-1 | Refrigerante | R$ 8,00 | 100 | R$ 800,00 |
02/01/2023 |
| BA-5 | Cerveja | R$ 12,00 | 1000 | R$ 12.000,00 | 10/01/2023 |
| CD-3 | Suco | $ 9,50 | 250 | R$ 2.375,00 | 14/01/2023 |
| DD-15 | Água | R$ 4,00 | 5000 | R$ 20.000,00 | 01/02/2023 |
| EB-76 | ... | ... | ... | ... | ... |
Soma todos os elementos
Divide pela quantidade de elementos
Média
Quanto, em média, é o valor de cada venda realizada em janeiro?
| Cliente | Produto | Valor unitário | Unidades | Valor total | Data da venda |
|---|---|---|---|---|---|
| AB-1 | Refrigerante | R$ 8,00 | 100 | R$ 800,00 |
02/01/2023 |
| BA-5 | Cerveja | R$ 12,00 | 1000 | R$ 12.000,00 | 10/01/2023 |
| CD-3 | Suco | $ 9,50 | 250 | R$ 2.375,00 | 14/01/2023 |
| DD-15 | Água | R$ 4,00 | 5000 | R$ 20.000,00 | 01/02/2023 |
| EB-76 | ... | ... | ... | ... | ... |
Soma todos os elementos
Divide pela quantidade de elementos
Média
Quanto, em média, é o valor de cada venda realizada em janeiro?
| Cliente | Produto | Valor unitário | Unidades | Valor total | Data da venda |
|---|---|---|---|---|---|
| AB-1 | Refrigerante | R$ 8,00 | 100 | R$ 800,00 |
02/01/2023 |
| BA-5 | Cerveja | R$ 12,00 | 1000 | R$ 12.000,00 | 10/01/2023 |
| CD-3 | Suco | $ 9,50 | 250 | R$ 2.375,00 | 14/01/2023 |
| DD-15 | Água | R$ 4,00 | 5000 | R$ 20.000,00 | 01/02/2023 |
| EB-76 | ... | ... | ... | ... | ... |
Soma todos os elementos
Divide pela quantidade de elementos
Média - definição
A média é uma medida de tendência central, agindo como um centro de massa de um conjunto de dados. Ela resume esse conjunto em um único número representativo.
O caso geral é dado pela equação abaixo:
Média - Visualização
Barras vermelhas indicam o quanto cada cliente comprou.
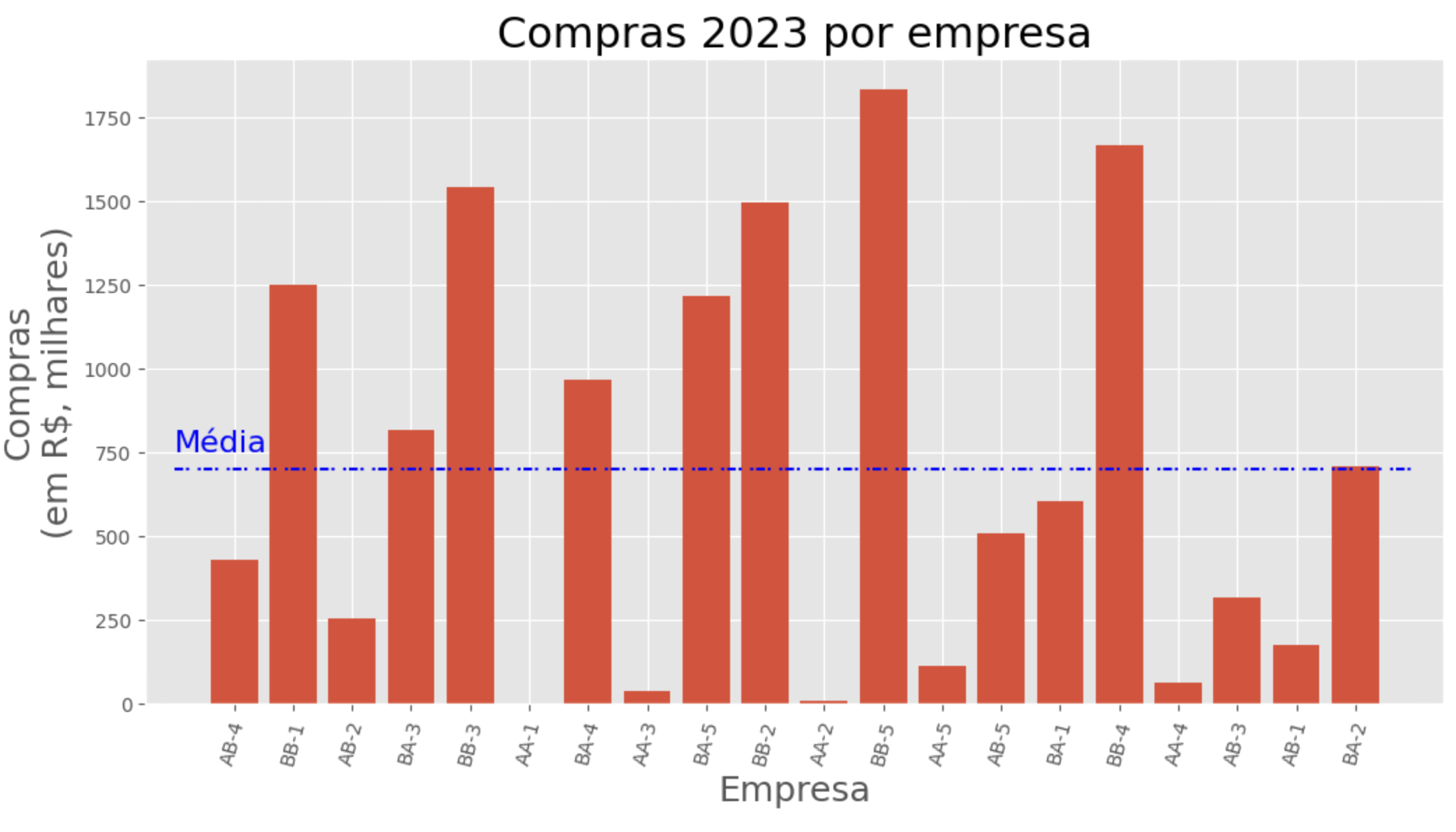
Média - Peculiaridades
A média resume valores, mas é incapaz de capturar variações entre eles.
Média - peculiaridades
É fortemente influenciada por valores muito discrepantes (outliers).
| Cliente | Produto | Valor unitário | Unidades | Valor total | Data da venda |
|---|---|---|---|---|---|
| AB-1 | Refrigerante | R$ 8,00 | 100 | R$ 800,00 |
02/01/2023 |
| BA-5 | Cerveja | R$ 12,00 | 1000 | R$ 12.000,00 | 10/01/2023 |
| CD-3 | Suco | $ 9,50 | 250 | R$ 2.375,00 | 14/01/2023 |
| DD-15 | Whisky | R$ 1.500,00 | 1500 | R$ 2.250.000,00 | 30/01/2023 |
| EB-76 | ... | ... | ... | ... | ... |
Mediana - definição
Também é uma medida de tendência central que representa o valor que separa um conjunto de dados ordenado em duas partes de mesmo tamanho.
| Cliente | Produto | Valor unitário | Unidades | Valor total | Data da venda |
|---|---|---|---|---|---|
| AB-1 | Refrigerante | R$ 8,00 | 100 | R$ 800,00 | 02/01/2023 |
| BA-5 | Cerveja | R$ 12,00 | 1000 | R$ 12.000,00 | 10/01/2023 |
| CD-3 | Suco | $ 9,50 | 250 | R$ 2.375,00 | 14/01/2023 |
| DD-15 | Whisky | R$ 1.500,00 | 1500 | R$ 2.250.000,00 | 30/01/2023 |
| EB-76 | Cerveja | R$ 10,90 | 1200 | R$ 13.080,00 | 31/01/2023 |
Dados desordenados
Mediana - número ímpar de dados
Também é uma medida de tendência central que representa o valor que divide um conjunto de dados ordenado em partes iguais.
| Cliente | ... | Valor Total |
|---|---|---|
| AB-1 | ... | R$ 800,00 |
| BA-5 | ... | R$ 12.000,00 |
| CD-3 | ... | R$ 2.375,00 |
| DD-15 | ... | R$ 2.250.000,00 |
| EB-76 | ... | R$ 13.080,00 |
- Ordena-se os dados
[800; 2.375; 12.000; 13.080; 2.250.000,00];
- Pega-se o elemento do meio;
[800; 2.375; 12.000; 13.080; 2.250.000,00]
Valor da mediana
Mediana - NÚMERO PAR DE DADOS
No exemplo anterior a quantidade de valores da base de dados era ímpar (5 dados). Agora vamos supor que nós tivéssemos 6 dados no conjunto, como que se calcula a mediana?
| Cliente | ... | Valor Total |
|---|---|---|
| AB-1 | ... | R$ 800,00 |
| BA-5 | ... | R$ 12.000,00 |
| CD-3 | ... | R$ 2.375,00 |
| DD-15 | ... | R$ 2.250.000,00 |
| EB-76 | ... | R$ 13.080,00 |
| FV-26 | ... | R$ 26.000,00 |
- Ordena-se os dados:
[800; 2.375; 12.000; 13.080; 26.000,00; 2.250.000,00] - Pega-se os elementos do meio:
[800; 2.375; 12.000; 13.080; 26.000,00; 2.250.000,00] - Faz a média dos 2 elementos centrais:
(12.000 + 13.080) / 2 = 12.540
Valor da mediana
MEDIANA - Visualização
Barras vermelhas indicam o quanto cada cliente comprou.
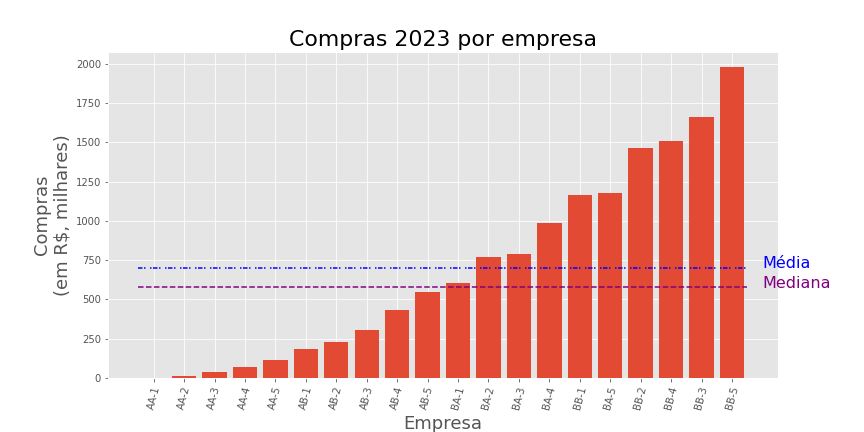
outra medida de tendência central que pode ser usada é a moda
Moda:
Útil para dados nominais, resistente a outliers, porém ela não representa dados uniformemente e é ineficaz com distribuições multimodais.
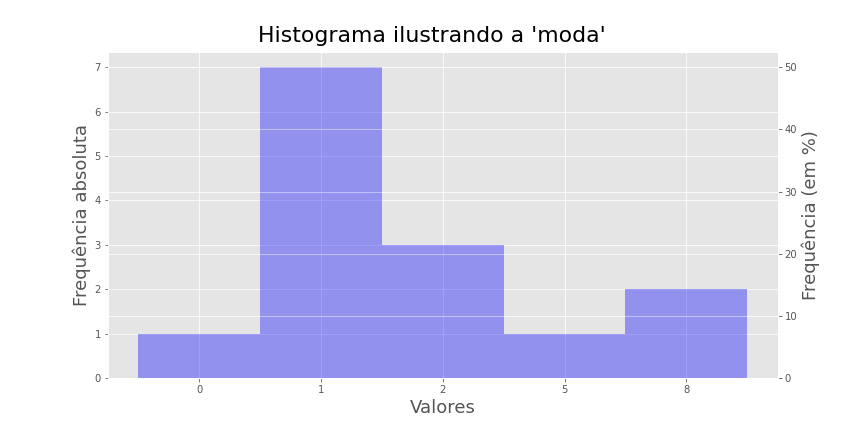
exemplo utilização da moda
Por exemplo, se fizermos um gráfico de frequência dos seguintes dados:
0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 5, 8, 8
Quando usar a média e quando usar a mediana?
Média
A média é mais sensível a outliers. Na presença deles, pode haver distorção.
Média
A média é mais sensível a outliers. Na presença deles, pode haver distorção.
Mediana
A mediana por sua vez desconsidera os outliers (mas requer ordenação).
Quantificando a dispersão dos dados
variância e desvio padrão
Indica dispersão dos valores numéricos em torno da média.
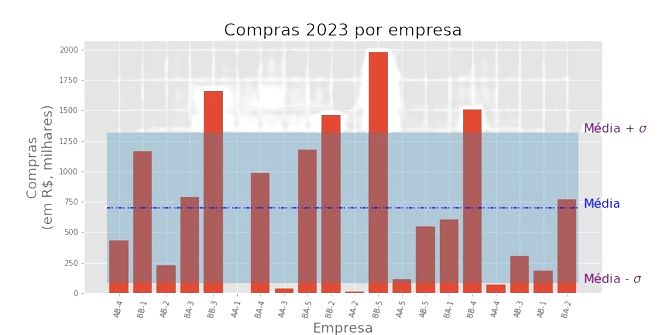
variância e desvio padrão
Indica dispersão dos valores numéricos em torno da média.
VARIÂNCIA E DESVIO PADRÃO
Indica dispersão dos valores numéricos em torno da média.
Variância baixa indica dados concentrados ao redor da média.
Variância alta indica dados dispersos. O mesmo se aplica ao desvio padrão.
Intervalos interquartis
Quantifica dispersão dos dados ao redor da mediana. Para entendê-los precisamos da ideia de percentis.
Intervalos interquartis
Quantifica dispersão dos dados ao redor da mediana. Para entendê-los precisamos da ideia de percentis.
Quando os dados são ordenados, chamamos de percentis as faixas de corte que separam os dados em x% dos valores mais baixos.
Os valores de x mais utilizados são:
-
25% (o primeiro quartil, ou Q1);
-
50% (segundo quartil, ou mediana); ou
-
75% (terceiro quartil, ou Q3).
Intervalos interquartis
Quantifica dispersão dos dados ao redor da mediana. Para entendê-los precisamos da ideia de percentis.
Quando os dados são ordenados, chamamos de percentis as faixas de corte que separam os dados em x% dos valores mais baixos.
Os valores de x mais utilizados são:
-
25% (o primeiro quartil, ou Q1);
-
50% (segundo quartil, ou mediana); ou
-
75% (terceiro quartil, ou Q3).
O intervalo interquartil (IIQ) é dado pela diferença Q3 - Q1.
Diante dessas definições, podemos construir boxplots.
OUTLIERS E BOXPLOT
Com o boxplot é possível visualizarmos a dispersão dos dados ao redor da mediana.
Boxplots também são usados para identificarmos outliers, cuja caracterização dependerá do contexto.
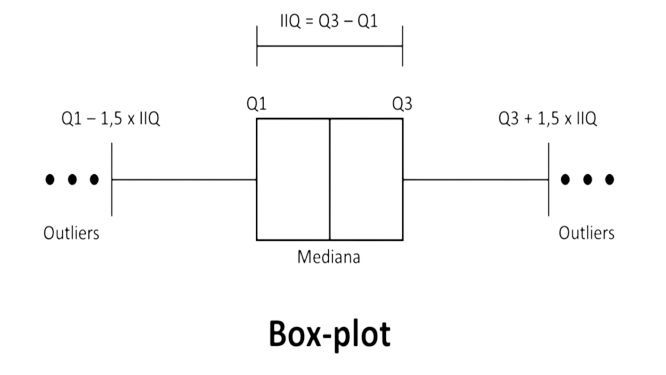
outliers e boxplot
No nosso caso, temos o seguinte:
Não temos outliers, porém temos valores distantes da média e mediana
O que Fazer Quando outliers são
"um problema"?
Muitas vezes, outliers podem distorcer uma estatística (como vimos, no caso da média).
Em caso como este, não é incomum:
Muitas vezes, outliers podem distorcer uma estatística (como vimos, no caso da média).
Em caso como este, não é incomum:
- Ignorarmos os outliers;
- Substituirmos outliers por valores mais significativos (como a média ou mediana);
- Separarmos os outliers do restante dos dados e tratá-los à parte.
exemplos extras e recomendações
Recebi ofertas de emprego de duas empresas com mesma média salarial!
Recebi ofertas de emprego de duas empresas com mesma média salarial!
-
Sou um estagiário?
-
SOU UM CEO?
SE LEVARMOS EM CONTA SOMENTE A REMUNERAÇÃO, COMO USAR A VARIÂNCIA DE SALÁRIO (SE ALTA OU BAIXA) PARA DECIDIR EM QUAL DELAS É MELHOR TRABALHAR SE:
Recebi ofertas de emprego de duas empresas com mesma média salarial!
-
Sou um estagiário?
-
SOU UM CEO?
SE LEVARMOS EM CONTA SOMENTE A REMUNERAÇÃO, COMO USAR A VARIÂNCIA DE SALÁRIO (SE ALTA OU BAIXA) PARA DECIDIR EM QUAL DELAS É MELHOR TRABALHAR SE:
Var. baixa é melhor!
Recebi ofertas de emprego de duas empresas com mesma média salarial!
-
Sou um estagiário?
-
SOU UM CEO?
SE LEVARMOS EM CONTA SOMENTE A REMUNERAÇÃO, COMO USAR A VARIÂNCIA DE SALÁRIO (SE ALTA OU BAIXA) PARA DECIDIR EM QUAL DELAS É MELHOR TRABALHAR SE:
Var. baixa é melhor!
Var. alta é melhor!
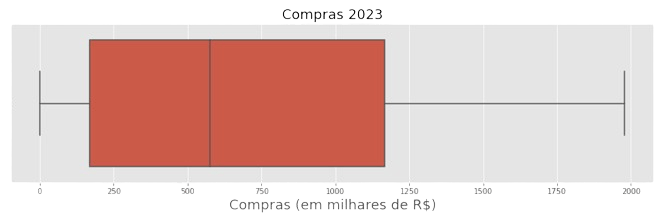
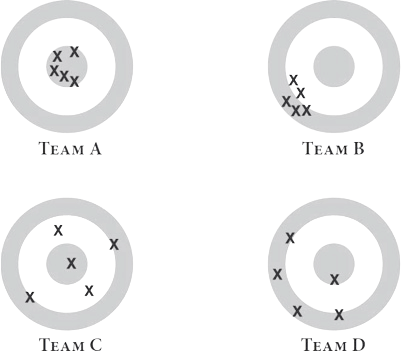
qual a diferença entre os alvos de cima e os de baixo?
Livro:
“Noise, a flaw in human judgement”,
Kahneman, Sibony, e Sunstein, 2021
qual a diferença entre os alvos de cima e os de baixo?
Maior Variância
Livro:
“Noise, a flaw in human judgement”,
Kahneman, Sibony, e Sunstein, 2021
qual a diferença entre os alvos de cima e os de baixo?
Maior Variância
Maior Viés
Livro:
“Noise, a flaw in human judgement”,
Kahneman, Sibony, e Sunstein, 2021
Em um relatório de apresentação de resultados encontramos a seguinte frase:
“... constatamos que depois da contratação do novo serviço de cantina, a média de espera em fila caiu em mais de 20 minutos: na média, hoje espera-se 5 minutos em fila, com variância 4 minutos².”
Existe algum erro nessa frase?
variância ou desvio padrão?
variância ou desvio padrão?
Em um relatório de apresentação de resultados encontramos a seguinte frase:
“... constatamos que depois da contratação do novo serviço de cantina, a média de espera em fila caiu em mais de 20 minutos: na média, hoje espera-se 5 minutos em fila, com variância 4 minutos².”
Existe algum erro nessa frase?
Sim, pois a medida da variância está diferente da medida da média. Portanto precisamos tirar a raíz para termos o DESVIO PADRÃO
curiosidade - curva de pareto
É muito comum na área de negócios utilizarmos os dados ordenados (do maior para o menor) e acumulados para gerarmos uma curva, conhecida como curva de Pareto.
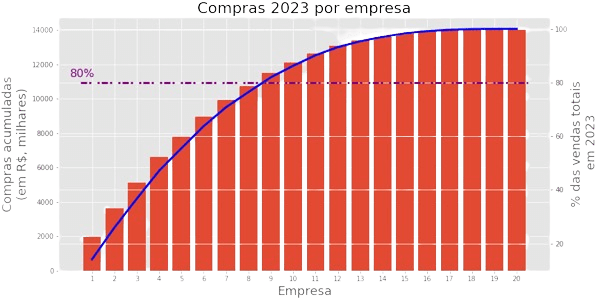
8 empresas sozinhas “fizeram” 80% das vendas de 2023.
histograma
Histogramas são gráficos de barras, onde o eixo horizontal representa (faixas de) valores coletados, enquanto o eixo vertical denota a frequência dos valores obtidos.
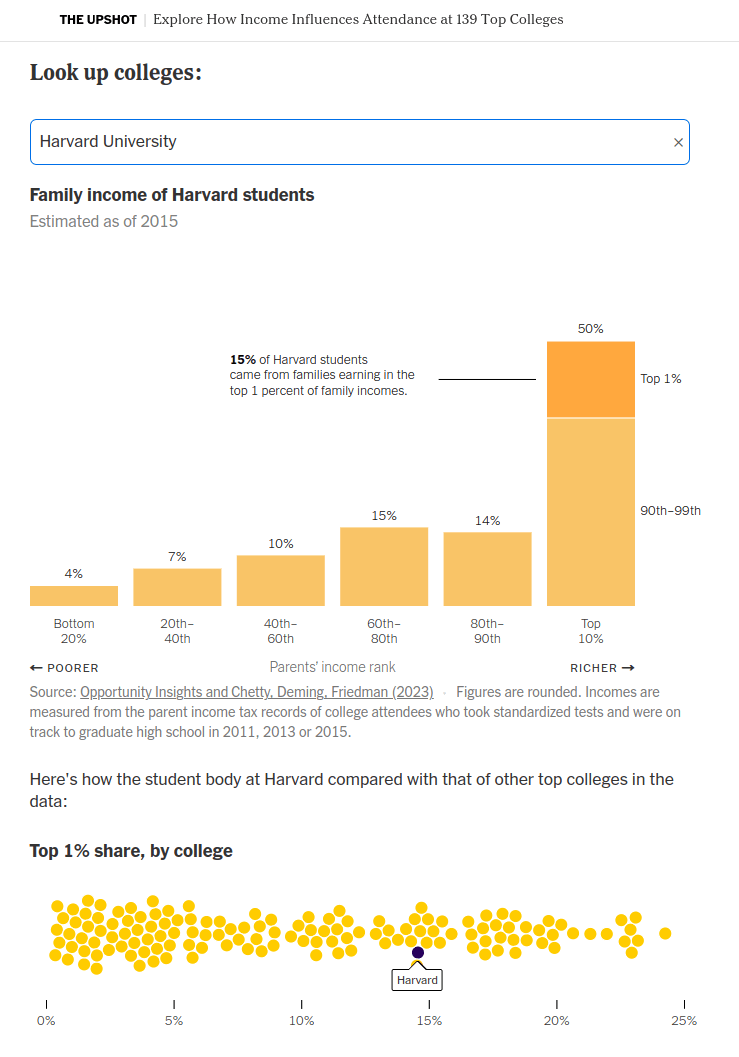
Explore How Income Influences Attendance at 139 Top Colleges, New York times, 11 de Setembro de 2023
até agora vimos tudo com apenas 1 variável. mas e se precisarmos realizar estudos com 2 ou mais variáveis
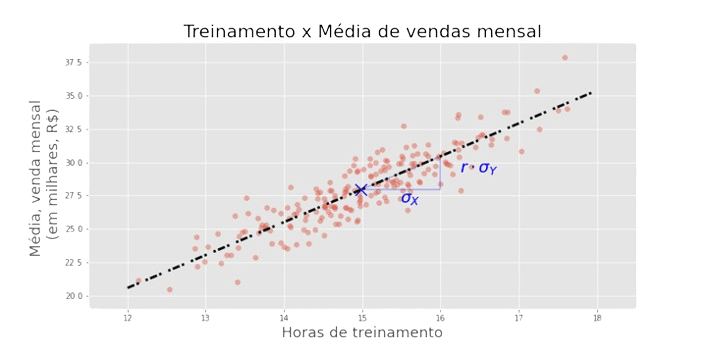
Por exemplo, uma pergunta que poderíamos tentar responder: o número de horas de treinamento de um vendedor impacta na sua média mensal de vendas?
gráfico de dispersão
Imaginem o seguinte gráfico para o ano de 2023
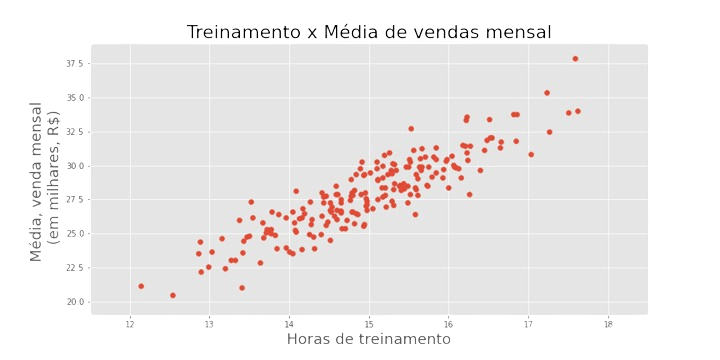
Aparentemente as horas de treinamento impactam a média de vendas positivamente.
correlação é um número que aponta a associação entre 2 variáveis
onde cov denota a covariância entre x e y, calculada como
Correlação varia entre -1 e 1. Quanto mais próximo desses extremos, mais uma variável pode ser usada para explicar o comportamento médio da outra.
reta da equação de regressão
No caso estudado, temos:
Primeiramente, calculamos o centro médio da nuvem de pontos.
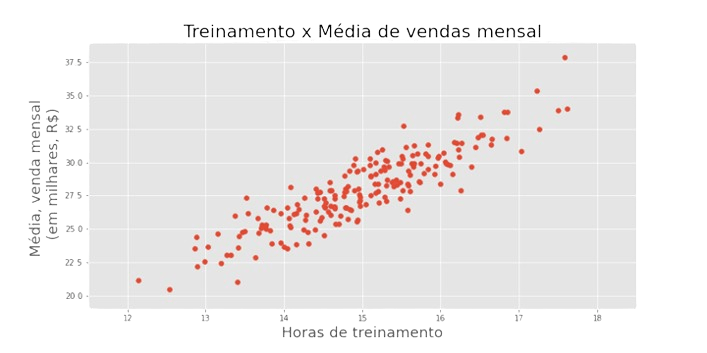
Se calcularmos correlação (denotada como r), variâncias amostrais em x e y, podemos traçar uma “tendência” dos dados a partir do seu centro médio.
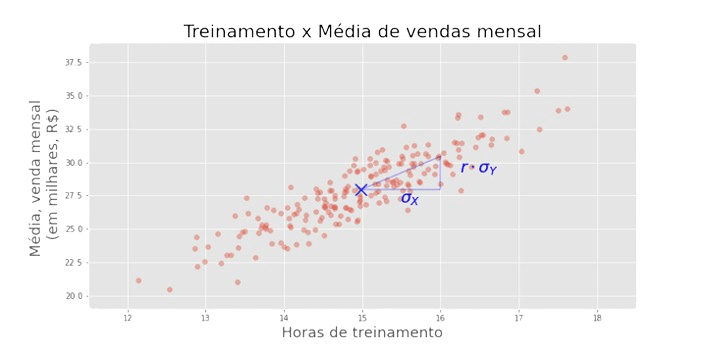
No caso estudado, temos:
reta da equação de regressão
Para os dados que temos, obtivemos correlação r = 0.89.
Como interpretar esse índice?
No caso estudado, temos:
reta da equação de regressão
A leitura que se faz é a seguinte: associado a um aumento de 𝜎x em x, há um aumento médio de r 𝜎y em y.
No caso estudado, temos:
reta da equação de regressão
A reta que traçamos é conhecida como reta de regressão de y em x.
No caso estudado, temos:
reta da equação de regressão
Probabilidade
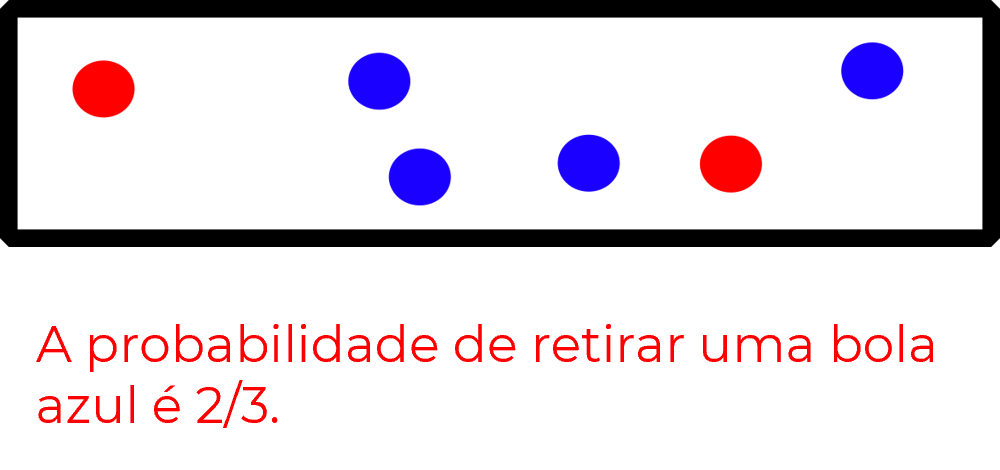
De certa maneira, todos nós temos uma ideia intuitiva de como se calcula a probabilidade de alguns eventos.

Por exemplo: se retirássemos uma bolinha aleatoriamente da caixa acima, qual a probabilidade dela ser vermelha?
De certa maneira, todos nós temos uma ideia intuitiva de como se calcula a probabilidade de alguns eventos.
Por exemplo: se retirássemos uma bolinha aleatoriamente da caixa acima, qual a probabilidade dela ser vermelha?
Evento Aleatório
situação ou acontecimento no qual há incerteza não podendo ser previsto com certeza.
PREVISÃO DO TEMPO, LOTERIAS, JOGOS DE FUTEBOL, CARA-COROA, LANÇAMENTO DE DADO.
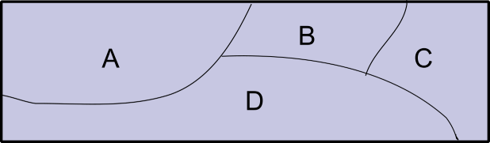
espaço amostral
Conjunto de todos os possíveis resultados de um evento aleatório.
Os subconjuntos do espaço amostral são chamados “eventos.” Visualmente, podemos entendê-los como divisões de um terreno de área total 1.
probabilidade
Dado que temos um espaço amostral com eventos que o constituem, podemos quantificar a ideia de incerteza introduzindo a noção de probabilidade.
Probabilidade: é uma função avaliada em subconjuntos de um espaço amostral E, de tal forma que
Variável aleatória (v.a.): é uma função X que assume valores seguindo uma lei probabilistica:
Exemplo:
Um dado não viciado modela a seguinte Variável aleatória (v.a.):
Variável aleatória (v.a.): é uma função X que assume valores seguindo uma lei probabilistica:
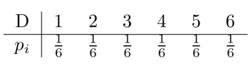
Exemplo:
Um dado não viciado modela a seguinte Variável aleatória (v.a.):
Ou seja:
Variável aleatória (v.a.): é uma função X que assume valores seguindo uma lei probabilistica:
variáveis independentes
Um outro conceito muito importante é o de independência de eventos.
Eventos independentes: dois eventos A e B são independentes quando a seguinte propriedade é válida:
qual a probabilidade de jogarmos dados 2 vezes e tirarmos os Números 1 e 2 (Em qualquer ordem)?
qual a probabilidade de jogarmos dados 2 vezes e tirarmos os Números 1 e 2 (Em qualquer ordem)?
Chance
de tirarmos
1 e 2
qual a probabilidade de jogarmos dados 2 vezes e tirarmos os Números 1 e 2 (Em qualquer ordem)?
Chance
de tirarmos
1 e 2
Chance
de tirarmos
2 e 1
qual a probabilidade de jogarmos dados 2 vezes e tirarmos os Números 1 e 2 (Em qualquer ordem)?
Chance
de tirarmos
1 e 2
Chance
de tirarmos
2 e 1

Dado que numa corrente a probabilidade de um elo quebrar é de 1%, qual é a chance de uma corrente com 50 elos independentes se romper?
(*)
Sabemos que
Dado que numa corrente a probabilidade de um elo quebrar é de 1%, qual é a chance de uma corrente com 50 elos independentes se romper?
(*)
Por independência, temos que
Sabemos que
Dado que numa corrente a probabilidade de um elo quebrar é de 1%, qual é a chance de uma corrente com 50 elos independentes se romper?
Dado que numa corrente a probabilidade de um elo quebrar é de 1%, qual é a chance de uma corrente com 50 elos independentes se romper?
Logo, por (*), a chance de rompimento é de quase 30%!
(*)
Por independência, temos que
Sabemos que
Algumas distribuições
Distribuição Uniforme (discreta):
U é distribuída com pesos iguais para todo possível resultado
Distribuição Bernoulli:
Y é variável aleatória com dois possíveis valores, por ex, 0 e 1.
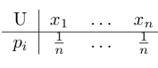

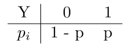
Algumas distribuições
Distribuição Uniforme (discreta):
U é distribuída com pesos iguais para todo possível resultado
Distribuição Bernoulli:
Y é variável aleatória com dois possíveis valores, por ex, 0 e 1.
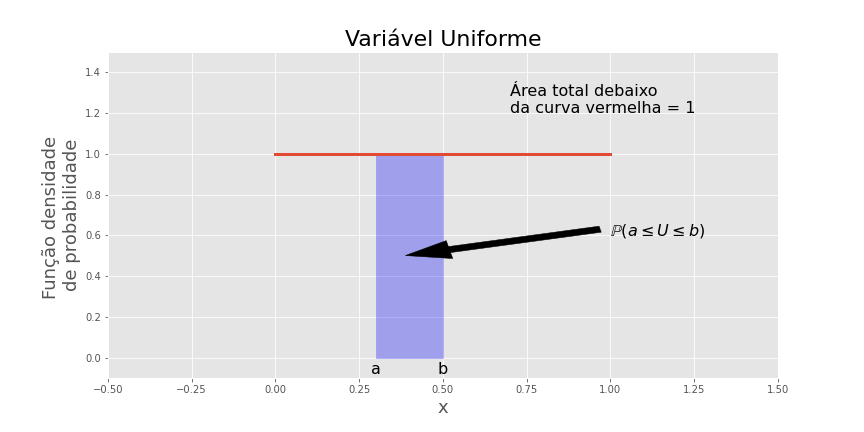
Distribuição Uniforme (contínua)
U é distribuída com pesos iguais para todo possível intervalo de mesmo tamanho
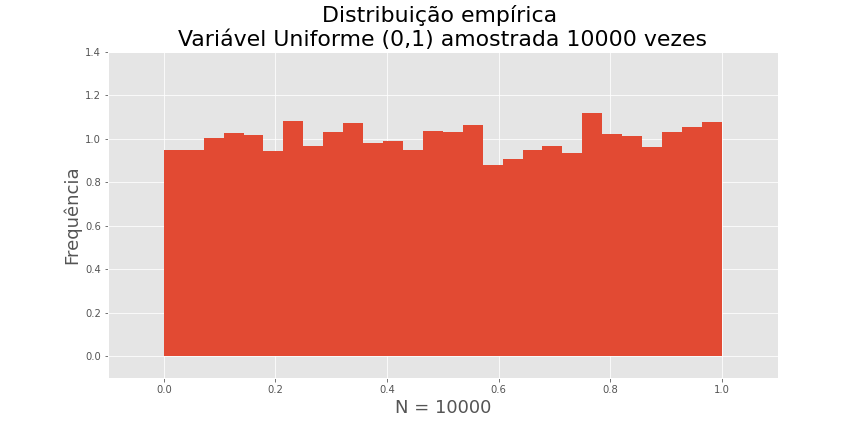
Distribuição Uniforme (contínua)
Curiosamente, se geramos um grande número de variáveis uniformes independentes e plotarmos o histograma, obtemos uma curva parecida com a função densidade de probabilidade.
Distribuição exponencial
Y é variável aleatória que assume valores não-negativos, com alta probabilidade de valores próximos a zero e baixa probabilidade de valores altos.
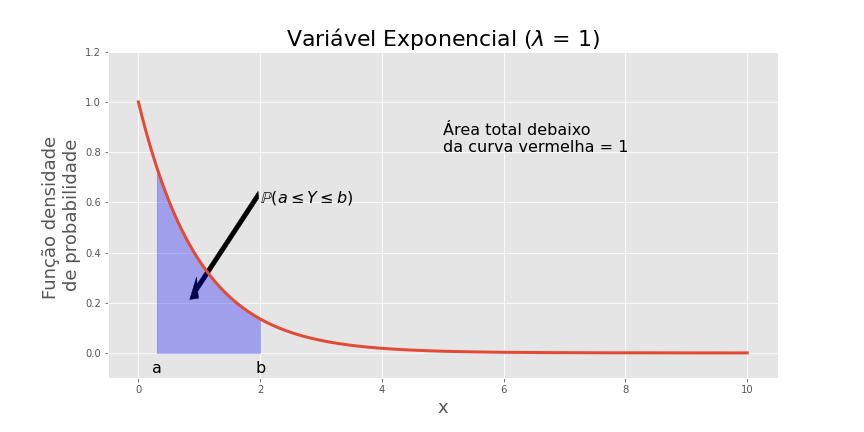
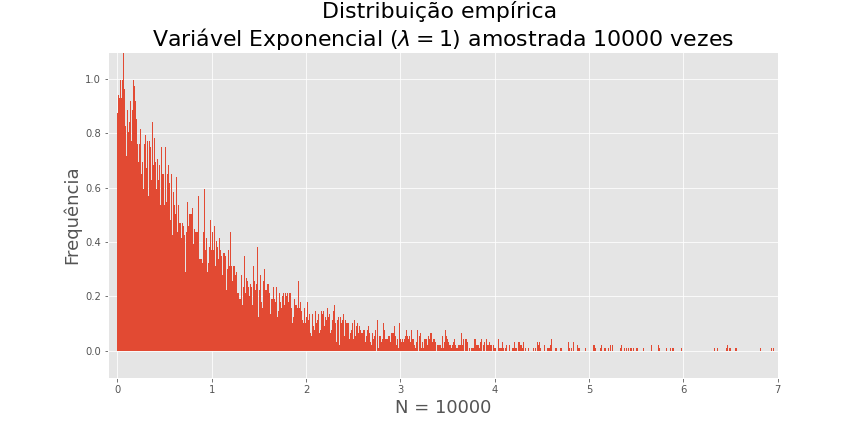
Distribuição exponencial
Como no caso anterior, se geramos um grande número de variáveis uniformes independentes e plotarmos o histograma, obtemos uma curva parecida com a função densidade de probabilidade.
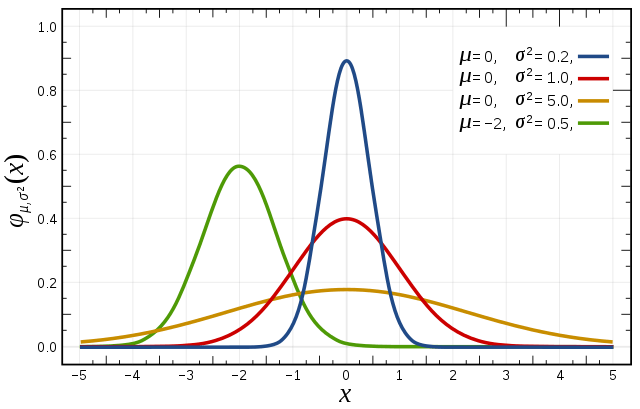
Distribuição normal
A mais utilizada. Modela diversos fenômenos: taxa de crescimento de uma ação com relação ao dia anterior, distribuição de estaturas numa população etc.
Probabilidades
são calculadas por
onde
O teorema central do Limite
O maior motivo pelo qual a distribuição normal é utilizada é o seguinte

O teorema central do Limite
O maior motivo pelo qual a distribuição normal é utilizada é o seguinte
média
amostral
desvio padrão amostral
O teorema central do Limite
Por exemplo: se plotarmos o histograma de em amostras de
tamanho n, onde Xi foi extraído de uma uniforme (0,1), obtemos as seguintes visualizações
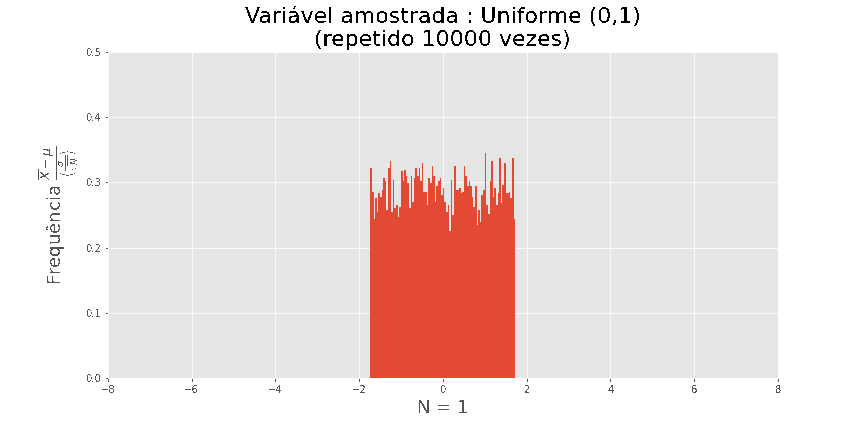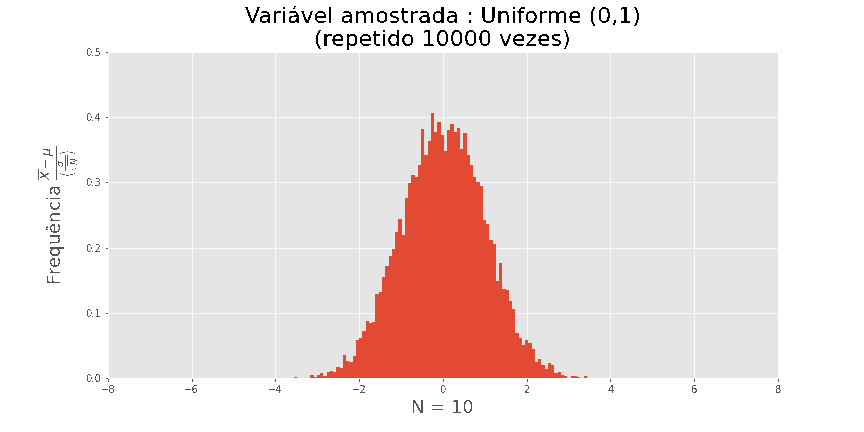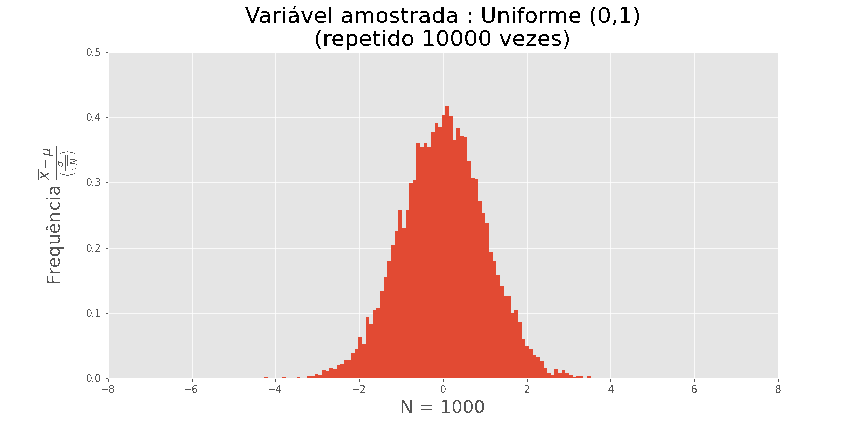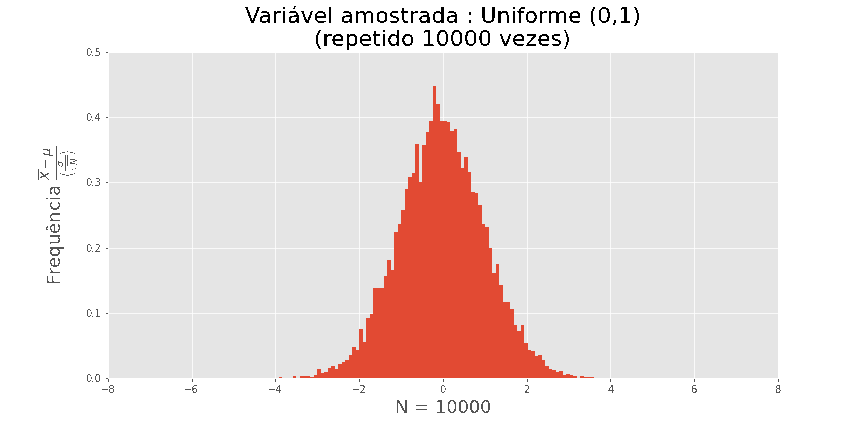
O teorema central do Limite
Por exemplo: se plotarmos o histograma de em amostras de
tamanho n, onde Xi foi extraído de uma exponencial, obtemos as seguintes visualizações
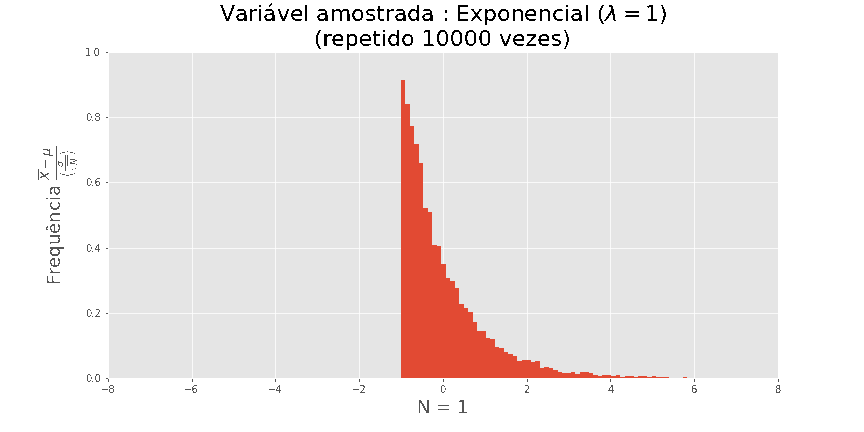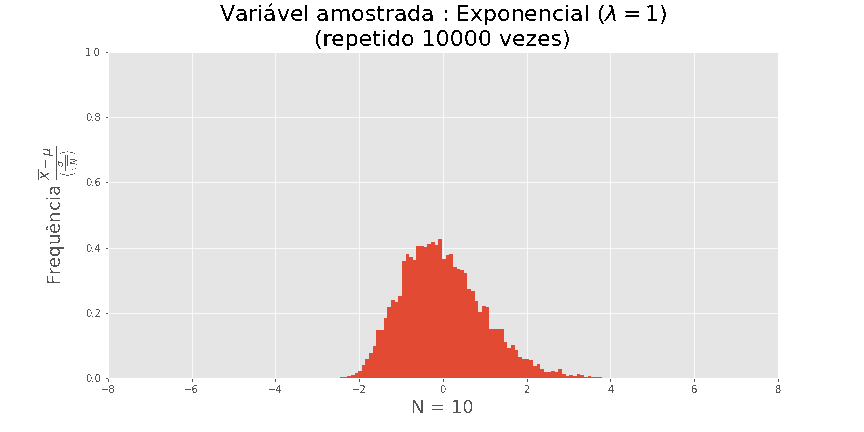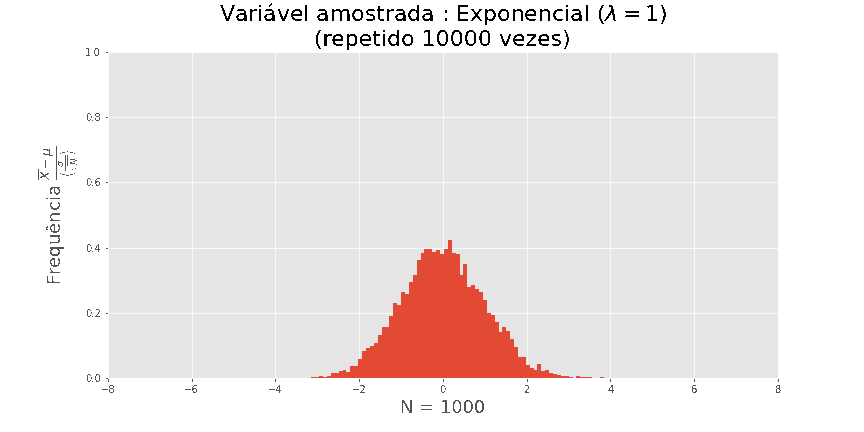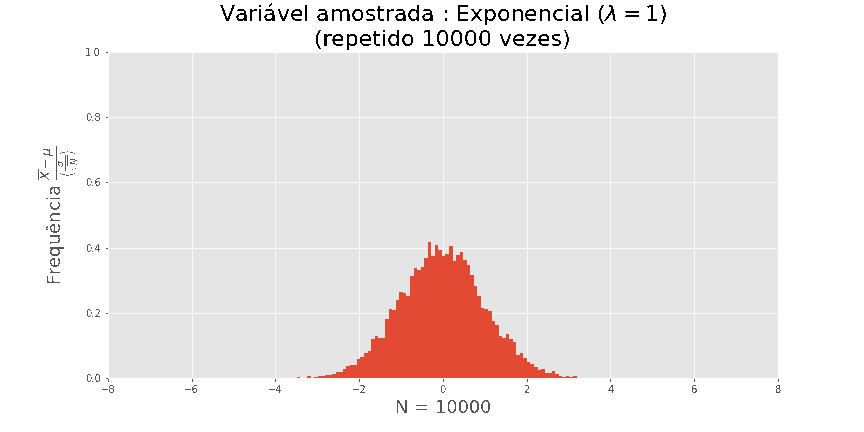
O teorema central do Limite
Em resumo
Quanto maior N, melhor a aproximação.
Acima de tudo, este resultado é universal, não dependendo da distribuição de X.
Exemplo de uso do teorema central do Limite
A empresa resolveu fazer uma promoção em suas bebidas, atribuindo tampas premiadas aleatoriamente a 10% da sua produção.
Em um engradado com 50 garrafas, qual é a chance de termos 10 ou mais delas premiadas?
Exemplo de uso do teorema central do Limite
Podemos modelar o problema da
seguinte forma:
uma garrafa é uma variável aleatória de valor 1 se premiada,
ou valor 0 caso contrário.
Exemplo de uso do teorema central do Limite
Note que a pergunta que foi feita é equivalente à seguinte:
Exemplo de uso do teorema central do Limite
Note que a pergunta que foi feita é equivalente à seguinte:
Ou seja, podemos calcular a probabilidade da média amostral ser maior que
(a média amostral observada).
Exemplo de uso do teorema central do Limite
Note que a pergunta que foi feita é equivalente à seguinte:
Ou seja, podemos calcular a probabilidade da média amostral ser maior que
(a média amostral observada).
Agora, usamos o TCL:
Exemplo de uso do teorema central do Limite
Note que a pergunta que foi feita é equivalente à seguinte:
Ou seja, podemos calcular a probabilidade da média amostral ser maior que
(a média amostral observada).
Agora, usamos o TCL:
Exemplo de uso do teorema central do Limite
Note que a pergunta que foi feita é equivalente à seguinte:
Ou seja, podemos calcular a probabilidade da média amostral ser maior que
(a média amostral observada).
Agora, usamos o TCL:
(aprox.) Normal com média 0 e variância 1
Exemplo de uso do teorema central do Limite
Note que a pergunta que foi feita é equivalente à seguinte:
Ou seja, podemos calcular a probabilidade da média amostral ser maior que
(a média amostral observada).
Agora, usamos o TCL:
(aprox.) Normal com média 0 e variância 1
Recomendações
Quem é
Rafael Monteiro é formado em Matemática Aplicada pela USP, SP.
Passou alguns anos morando no RJ para fazer um mestrado em modelagem matemática e computacional no IMPA, de onde seguiu para um PhD na Indiana University, nos EUA.
Seguiu na área acadêmica por alguns anos, até chegar no mundo industrial, onde trabalha com data science & data analytics, além de atuar como consultor.
Você pode encontrá-lo no linkedin.
