Mistral AI

What's the Hype?
Apart from their logo
-
A LOT of money has been raised
-
Seed: $112M
-
Series A: $415M
-
-
European Rival to OpenAI
-
Focus on being truly "Open"
Mixtral 8*7
-
Flagship Open Source model
-
Decoder Only Transformer
-
Released under Apache license
-
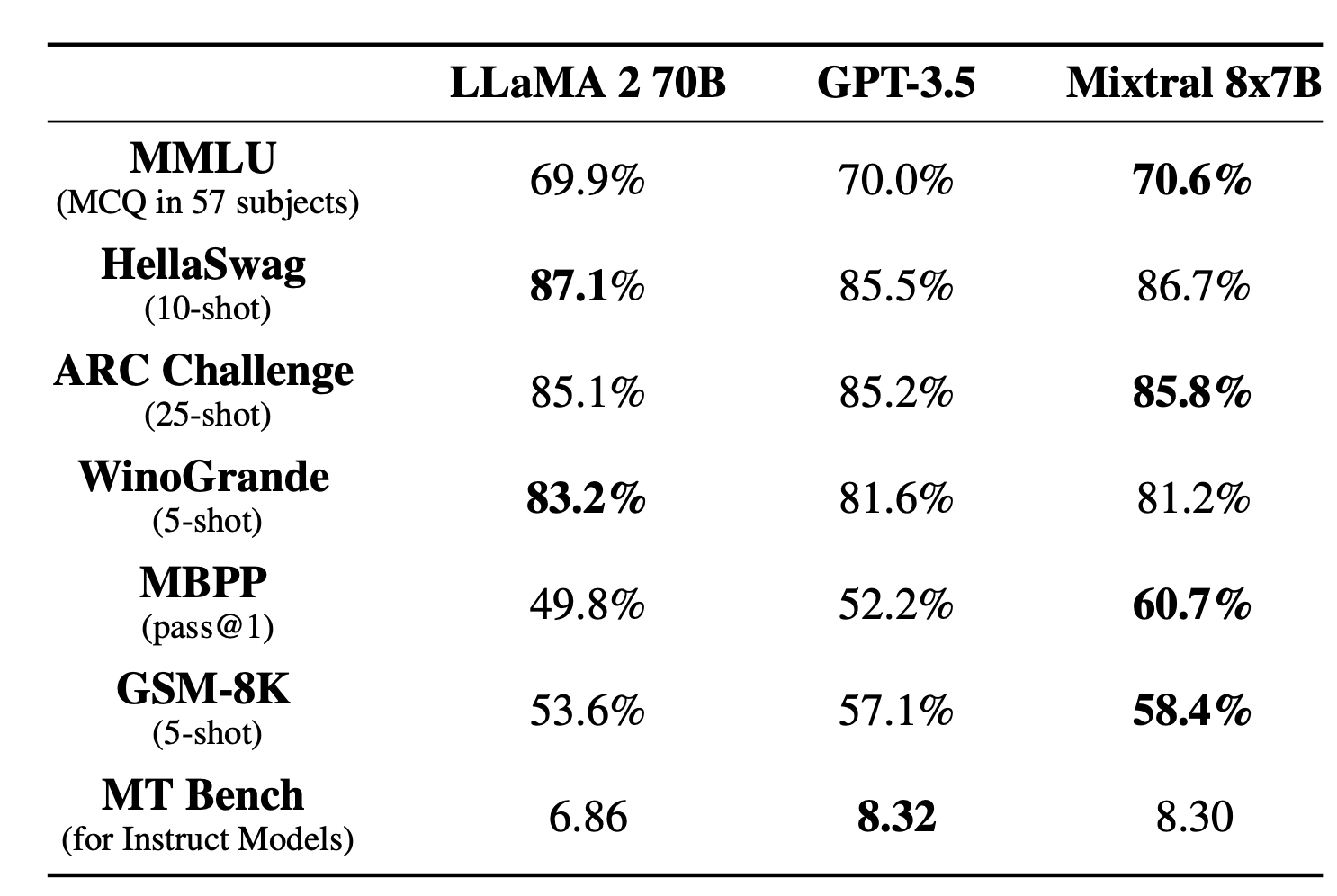
Outperforms Llama 2 and GPT 3.5 on most tasks
-
Instruction Tuned
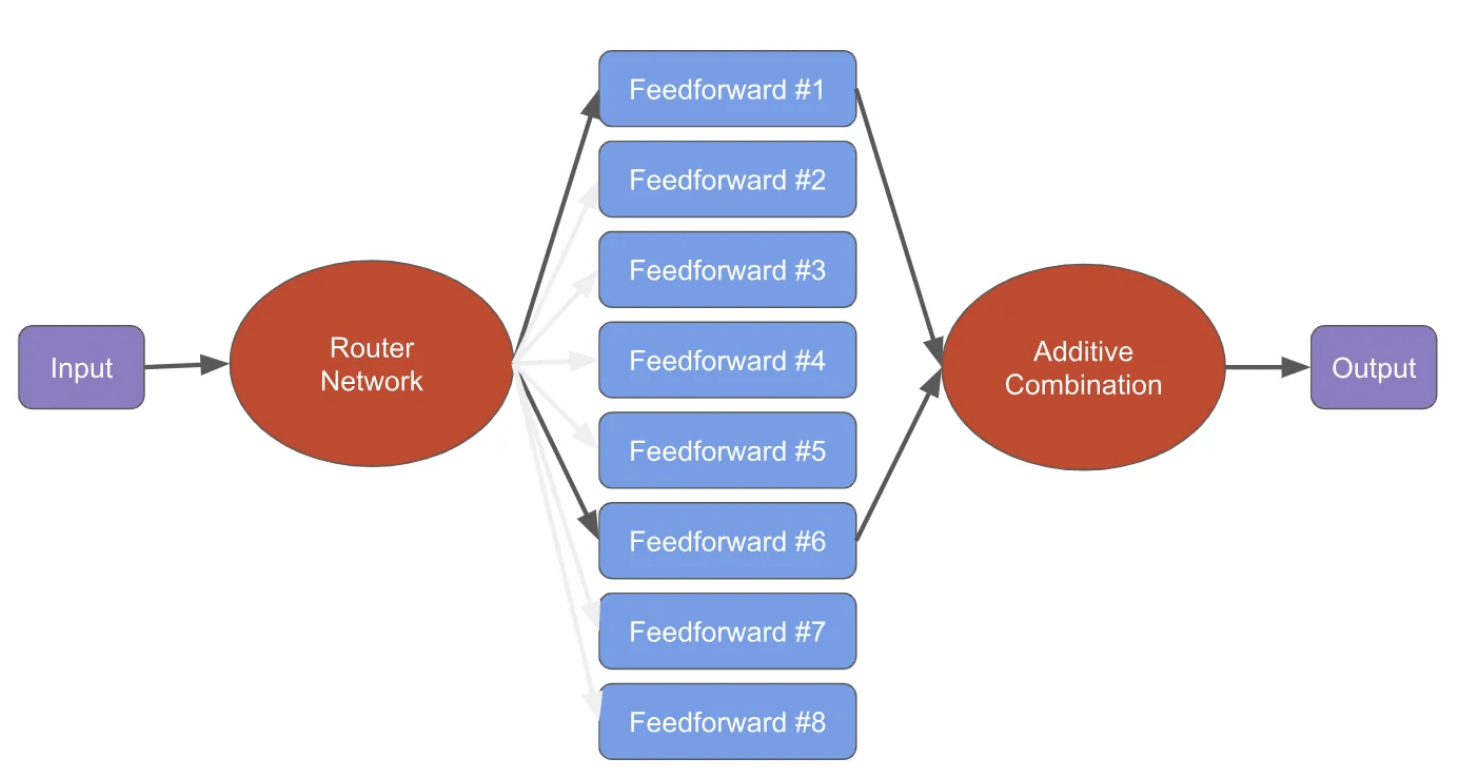
Sparse Mixture of Experts
-
At the core is MoE.
-
It uses 8 experts.
-
Model is 7B.
-
Hence, 8*7.
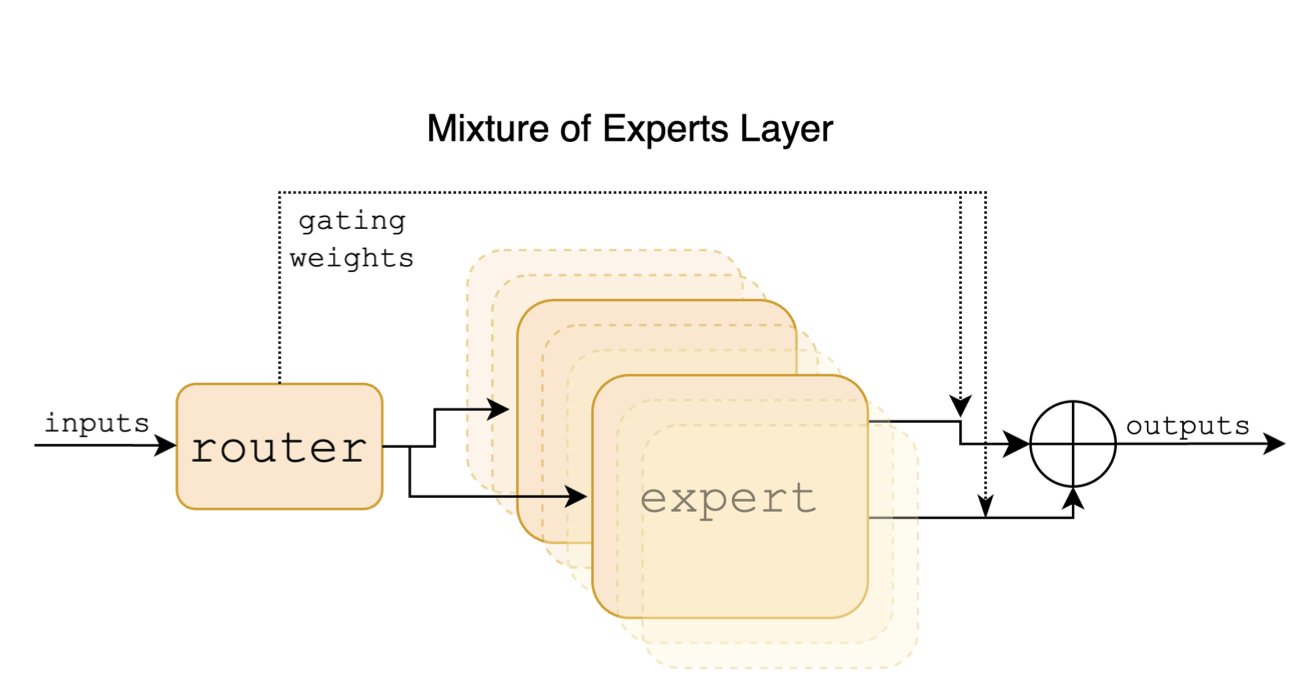
Sparse Mixture of Experts
-
Uses gating mechanism for routing.
-
Router is simply a softmax layer.
-
Top K where K = 2.
-
Has a total of 46.7B parameters but has an active count of 13B
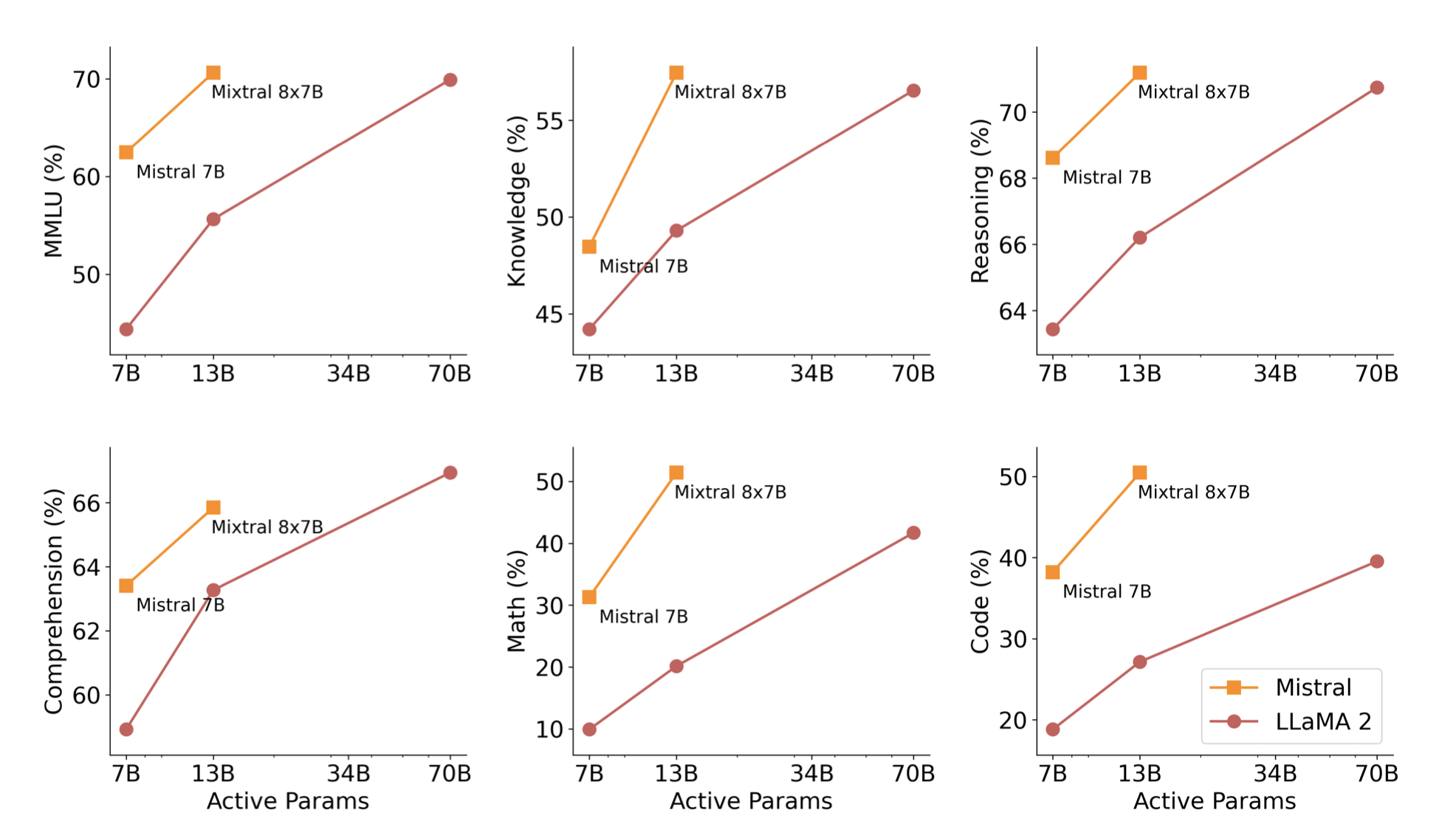
Performance
-
Comparisons primarily against Llama 2 - 70B and GPT 3.5
-
Much lower parameter count of 13B active parameters lends to faster inference