
學長真的不教指標嗎
Pointer & Reference
臣亮言 @ NTU CSIE
May 24, 2025
Sprout 資訊之芽北區 C 班
在開始之前......
Slido #Pointer

References not reference
Pointer & Reference
指標 Pointer
參考 Reference
動態配置記憶體 Dynamic memory allocation
OOP with pointer
Application: Dynamic Array
Application: Linked list
Pointer
Pointer〉
1
What is pointer?
還記得階段考前教的記憶體嗎?
不記得就算了啊我真的沒關係
變數的值存在記憶體之中,可以想像成放在某個格子裡
並且每種變數所佔的記憶體大小(多少 byte)都不一樣
long long
char
int
寫程式便是透過操作這些記憶體來達到目的
Pointer〉
1
What is pointer?
long long
char
int
| 0x3FA00 | 0x3FA01 | 0x3FA02 | 0x3FA03 | 0x3FA04 | 0x3FA05 | 0x3FA06 | 0x3FA07 |
|---|
| 0x3FA08 | 0x3FA09 | 0x3FA0A | 0x3FA0B | 0x3FA0C | 0x3FA0D | 0x3FA0E | 0x3FA0F |
|---|
這些記憶體都有他們各自的位址
像地址一樣:羅斯福路一段 1 號、羅斯福路一段 1 號
指標(Pointer)便是紀錄記憶體位址的變數
透過指標,我們就可以對記憶體作神秘的操作(上門查水表)
Pointer〉
1
What is pointer?
2
指標的宣告
int* iptr; //int ptr
char *cptr; //char ptr
int** pptr; //int ptr ptr指標並非一個單一的變數型別
指標的宣告需要指向一個型別
因此指標變數實際上是指向<type>的指標
宣告方式為 <type>* name / <type> *name
指標可以指向任意型別
甚至指向某種指標也可以
* 代表宣告為指標,並不屬於變數名稱
上述的兩個宣告方法等價
但要注意 * 只會作用於其後的第一個變數
int* a, b;
int *c, *d;看似把 a, b 都設為指標
實際上只有 a 會是指標
b 仍然是一個整數
c, d 則都是指標
Pointer〉
2
指標的宣告
3
取值/取址運算子 ( * / & )
剛剛說指標實際上存的是記憶體位址
那我們該怎麼得到記憶體位址呢?
int a
0x2F04
1024
值(a : 1024)
位址(&a : 0x2F04)
取址運算子 &
加在變數前,對變數取址
可以得到該變數在記憶體中的位址
int a = 1024;
int *ptr = &a;把位址賦值給指標 ptr
ptr 就是指向 a 的指標
Pointer〉
3
取值/取址運算子 ( * / & )
int a
0x2F04
1024
int a
0x2F04
1024
int a
0x2F04
1024
int* ptr
0x4DA8
0x2F04
那要怎麼透過指標對記憶體作存取與操作呢?
(得到地址後要怎麼查水表?)
ptr = &a
取值運算子 *
加在指標前,對指標(地址)取值
可以得到該指標所存地址紀錄的值
藉此直接存取、更改該地址所存的值
*ptr
Pointer〉
3
取值/取址運算子 ( * / & )
int a
0x2F04
1024
int a
0x2F04
1024
a
&a
ptr = &a
&ptr
pptr = &ptr
&pptr
*ptr
*pptr
**pptr
既然指標紀錄的是記憶體位址
為什麼指標需要指向某個型別呢?
int* ptr
0x4DA8
0x2F04
int** pptr
0x501B
0x4DA8
Pointer〉
3
取值/取址運算子 ( * / & )
int a
0x2F04
1024
int a
0x2F04
1024
int** pptr
0x501B
0x4DA8
a
&a
ptr = &a
&ptr
pptr = &ptr
&pptr
*ptr
*pptr
**pptr
long long
char
int
| 0x3FA00 | 0x3FA01 | 0x3FA02 | 0x3FA03 | 0x3FA04 | 0x3FA05 | 0x3FA06 | 0x3FA07 |
|---|
| 0x3FA08 | 0x3FA09 | 0x3FA0A | 0x3FA0B | 0x3FA0C | 0x3FA0D | 0x3FA0E | 0x3FA0F |
|---|
int* ptr
0x4DA8
0x2F04
記憶體紀錄的是單純的二進位制資料
而且每個型別所佔的記憶體不同
我們需要指向的型別才知道要讀取多長的記憶體(尤其等等提到陣列)
以及要怎麼解讀記憶體中的資料
由於指標指的都是記憶體位址
因此所有型別的指標都佔 8 bytes
Pointer〉
3
取值/取址運算子 ( * / & )
4
空指標(nullptr)
這裡再提到一個觀念:空指標(nullptr)
記得之前有說過變數宣告後不賦值
我們無法預測這些變數中到底存著什麼
而指標也是同個道理
尤其指標涉及對記憶體直接操作
如果沒適當處理會很可怕(亂戳記憶體)
因此在 C++ 中,我們利用空指標來初始化指標的值
有點像是 default 值,避免還沒賦值就亂用到指標
在對 nullptr 取值時,系統就會報錯
Pointer〉
4
空指標(nullptr)
int *ptr = nullptr; //null pointer其實 nullptr 更常用來維護資料結構
像是最後面的 Linked-list
不過我們不是算法班
暫時很難看到 nullptr 的用途
不過在賦值前宣告為 nullptr 仍是重要的習慣
int *ptr = NULL;另外 nullptr 其實是 C++ 才有的東西
C 語言中我們使用 NULL
但這東西在 C/C++ 中的定義不一樣
NULL 在 C++ 裡會有問題
因此我們通常寫 nullptr
詳細可以參考這篇文章
Pointer〉
4
空指標(nullptr)
5
陣列與指標
之前在一維陣列的最後(或補充資料)有提到
陣列在記憶體中實際上是一段連續記憶體
例如: int a[10];
| 0x6C20 | 0x6C24 | 0x6C28 | 0x6C2C | 0x6C30 | 0x6C34 | 0x6C38 | 0x6C3C | 0x6C40 | 0x6C44 |
|---|
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
a[8]
a[9]
陣列可以當成一種指標指向連續記憶體的起點,再透過 [] 運算子取值
int* a
0x4DA8
0x6C20
每一個 int 佔 4 bytes,因此每向右平移四格
就可以得到陣列下一個值的位址
那要怎麼做到位址的平移呢?其實就是加法
Pointer〉
5
陣列與指標
| 0x6C20 | 0x6C24 | 0x6C28 | 0x6C2C | 0x6C30 | 0x6C34 | 0x6C38 | 0x6C3C | 0x6C40 | 0x6C44 |
|---|
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
a[8]
a[9]
int* a
0x4DA8
0x6C20
a
a+1
a+3
a+2
a+4
a+5
a+6
a+7
a+8
a+9
Ok,現在我們會用位址的平移(加法)來得到每個值的位址了(%%%%%
距離得到陣列的值只差一步
Pointer〉
5
陣列與指標
| 0x6C20 | 0x6C24 | 0x6C28 | 0x6C2C | 0x6C30 | 0x6C34 | 0x6C38 | 0x6C3C | 0x6C40 | 0x6C44 |
|---|
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
a[8]
a[9]
int* a
0x4DA8
0x6C20
a
a+1
a+3
a+2
a+4
a+5
a+6
a+7
a+8
a+9
*(a+0)
*(a+1)
*(a+2)
*(a+3)
*(a+4)
*(a+5)
*(a+6)
*(a+7)
*(a+8)
*(a+9)
再加上取值運算子,就可以得到陣列的值
因此 a[i] 與 *(a+i) 實際上是等價的
其實也和 i[a] 是等價的
for(int i = 0; i < n; i++)
cout << a[i] << ' '; //*(a + i)
cout << '\n';
for(int i = 0; i < n; i++)
cout << i[a] << ' '; //*(i + a)
cout << '\n';Pointer〉
5
陣列與指標
| 0x6C20 | 0x6C24 | 0x6C28 | 0x6C2C | 0x6C30 | 0x6C34 | 0x6C38 | 0x6C3C | 0x6C40 | 0x6C44 |
|---|
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
a[8]
a[9]
int* a
0x4DA8
0x6C20
a
a+1
a+3
a+2
a+4
a+5
a+6
a+7
a+8
a+9
再觀察一下,這些值之間位址其實是差 4
這是因為每個 int 佔 4 bytes
那為什麼對位址 + i 可以得到 a[i] 的位址?
這要歸功於指標的型別 int*
他可以讓每個平移都會自動跳 4 bytes
而不用我們再幫他乘 sizeof(int)
所以指標的型別才那麼重要
Pointer〉
5
陣列與指標
| 0x6C20 | 0x6C24 | 0x6C28 | 0x6C2C | 0x6C30 | 0x6C34 | 0x6C38 | 0x6C3C | 0x6C40 | 0x6C44 |
|---|
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
a[8]
a[9]
a
a+1
a+3
a+2
a+4
a+5
a+6
a+7
a+8
a+9
這要歸功於指標的型別 int*
他可以讓每個平移都會自動跳 4 bytes
而不用我們再幫他乘 sizeof(int)
所以指標的型別才那麼重要
int a[10];
for(int i = 0; i < 10; i++) cout << a + i << ' ';
cout << '\n';
long long *b = (long long*) a;
for(int i = 0; i < 5; i++) cout << b + i << ' ';
cout << '\n';這裡會輸出什麼?
Pointer〉
5
陣列與指標
Exercise
Pointer〉
4
空指標(nullptr)
5
陣列與指標
| a[0][0] | a[0][1] | a[0][2] | a[0][3] |
| a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| a[2][0] | a[2][1] | a[2][2] | a[2][3] |
那多維陣列呢?這裡拿二維陣列舉例(int a[3][4])
我們通常把二維陣列視覺化為矩陣的樣貌
就像座位是第幾排、第幾列的樣子
不過實際上他們是一整列串接起來的記憶體
| a[0][0] | a[0][1] | a[0][2] | a[0][3] |
| a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| a[2][0] | a[2][1] | a[2][2] | a[2][3] |
Pointer〉
5
陣列與指標
| a[0][0] | a[0][1] | a[0][2] | a[0][3] |
| a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| a[2][0] | a[2][1] | a[2][2] | a[2][3] |
a[0], a[1], a[2] 都是長度為 4 的一維陣列
可以想像成他們是 int* (int[4])
那 a 又是什麼?
a[0]
a[1]
a[2]
既然 a[i] 是長度為 4 的一維陣列
那 a 就能當成指向 int[4] 的指標
int *ptr1[4];
//an array of 4 int pointer
int (*ptr2)[4];
//a pointer points to an array of 4 int會這樣跟 C 的設計有關係
但我們不太會用到,這裡就不贅述了
可以去問 GPT 我覺得他說得很好
Pointer〉
5
陣列與指標
| a[0][0] | a[0][1] | a[0][2] | a[0][3] |
| a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| a[2][0] | a[2][1] | a[2][2] | a[2][3] |
a[0]
a[1]
a[2]
經過一點計算,可以發現 a[i][j] == *(a + i * 4 + j)
更廣義來說,對於二維陣列 arr[n][m]
arr[i][j] == *(&(arr[0][0]) + i * m + j)
對於三維陣列 arr[x][y][z]
arr[i][j][k] == *(&(arr[0][0][0]) + (i * y + j) * z + k)
但這些其實也沒很重要
我們就乖乖用陣列就好
(%%%%%)
Pointer〉
5
陣列與指標
6
Pass by pointer
嘗試實做一個函式:swap
作用是把兩個傳入變數的值交換
先不寫成函式,一般會怎麼寫?
int a = 1, b = 2;
a = b;
b = a;
// a:2, b:2?a 在進第三行的時候已經被改成 b 了
我們需要第三者幫我們暫存 a 的值
int a = 1, b = 2;
int tmp = a;
a = b;
b = tmp;
//a:2, b:1!這樣就完成了!
int a = 1, b = 2;
a ^= b ^= a ^= b;或著你可能記得我有教過......
不管怎樣,現在來把他包成函式吧
Pointer〉
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
int main(){
int x = 1, y = 2;
swap(x, y);
cout << x << ' ' << y;
}void swap()
int main()
但實際用過以後
會發現執行完函式並不會交換到 x, y 的值
Pointer〉
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
int main(){
int x = 1, y = 2;
swap(x, y);
cout << x << ' ' << y;
}void swap()
int main()
int x
1
int y
2
但實際用過以後
會發現執行完函式並不會交換到 x, y 的值
Pointer〉
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
int main(){
int x = 1, y = 2;
swap(x, y);
cout << x << ' ' << y;
}void swap()
int main()
int x
1
int y
2
int a
1
int b
2
但實際用過以後
會發現執行完函式並不會交換到 x, y 的值
Pointer〉
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
int main(){
int x = 1, y = 2;
swap(x, y);
cout << x << ' ' << y;
}void swap()
int main()
int x
1
int y
2
int a
1
int b
2
int tmp
1
但實際用過以後
會發現執行完函式並不會交換到 x, y 的值
Pointer〉
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
int main(){
int x = 1, y = 2;
swap(x, y);
cout << x << ' ' << y;
}void swap()
int main()
int x
1
int y
2
int a
2
int b
2
int tmp
1
但實際用過以後
會發現執行完函式並不會交換到 x, y 的值
Pointer〉
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
int main(){
int x = 1, y = 2;
swap(x, y);
cout << x << ' ' << y;
}但實際用過以後
會發現執行完函式並不會交換到 x, y 的值
void swap()
int main()
int x
1
int y
2
int a
2
int b
1
int tmp
1
Pointer〉
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
int main(){
int x = 1, y = 2;
swap(x, y);
cout << x << ' ' << y;
}但實際用過以後
會發現執行完函式並不會交換到 x, y 的值
void swap()
int main()
int x
1
int y
2
int a
2
int b
1
int tmp
1
1 2
Pointer〉
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
int main(){
int x = 1, y = 2;
swap(x, y);
cout << x << ' ' << y;
}void swap()
int main()
int x
1
int y
2
int a
2
int b
1
int tmp
1
這是因為函式的呼叫實際上是在一開始給參數賦予傳入值
因此參數只是繼承了傳入變數的值,就像建立分身
並不會動到傳入的變數
(且由於可視域的關係,在函式內也動不到傳入的變數)
這時我們就可以利用指標
把地址給函式,再讓他去查水表!
Pointer〉
5
陣列與指標
6
Pass by pointer
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
swap(x, y);void swap(int* a, int* b){
int tmp = *a;
*a = *b;
*b = tmp;
}
//...
swap(&x, &y); //記得要傳位址Pass by value
Pass by pointer
藉由指標紀錄傳入變數的地址
進而直接修改可視域外變數的記憶體
參數的變動不會反映在傳入變數上
適合只需要拿傳入值來計算的函式
適合需要對變數本體操作的函式
Reference
CHECK POINT
Reference
Reference〉
1
What is reference?
參考 (reference) 是 C++ 特有的變數型別
和指標類似,他們都依附一個原始型態<type>
宣告的方式也很像:<type>& name / <type> &name
透過剛剛的實作可以發現
指標其中一大用途便是透過傳遞位址
讓函式得以透過位址找到原始變數
進而實現原始變數的讀取與改動
不過剛剛那樣要傳地址進去
要使用變數還得先取值
有時候函式內只會對值操作
每次又要 & 又要 * 其實不太方便
int a;
int &ref = a;我們直接把 a 賦值給 reference
不需要加任何取值或取址運算子
Reference〉
1
What is reference?
int a;
int &ref = a;參考就像給變數取個外號
而不像一般的變數只是互相賦值
參考 (ref) 和賦值給他的原始變數 (a) 綁定
參考 (ref) 帶著原始變數 (a) 的值
而對參考 (ref) 改動同時也會在原始變數 (a) 生效
這是楊晉宇
&養金魚 = 楊晉宇
&楊進與 = 楊晉宇
&老闆 = 楊晉宇
&欸那個P4怎麼寫 = 楊晉宇
之後對老闆、養金魚、楊進與、欸那個P4怎麼寫
操作與取值,都會連動影響到楊晉宇本人
Reference〉
1
What is reference?
int a = 1;
int &ref = a; //ref = a = 1
a = 2; //ref = a = 2
ref = 3; //ref = a = 3你也可以想成參考是把指標的取值取址行為包起來
紀錄地址並對值操作的一種變數型別
「自從學會參考後,我考試都考 100 分」
Reference〉
1
What is reference?
2
Pass by reference
既然參考是把指標包裝起來的操作
他當然也可以幫忙把變數送進函式,在可視域外對記憶體操作
void swap(int* a, int* b){
int tmp = *a;
*a = *b;
*b = tmp;
}
//...
swap(&x, &y); //記得要傳位址Pass by pointer
void swap(int &a, int &b){
int tmp = a;
a = b;
b = tmp;
}
//...
swap(x, y); //傳本人就好Pass by reference
void swap(int a, int b){
int tmp = a;
a = b;
b = tmp;
}
//...
swap(x, y);Pass by value
Pass by reference 可以直接對變數操作
函式本體幾乎跟 Pass by value 一樣
寫起來更直覺也更精煉!
Reference〉
2
Pass by reference
3
陣列遍歷
之前迴圈放在補充教材,現在可以來好好講講了
動態配置記憶體
CHECK POINT
動態配置記憶體
動態配置記憶體〉
1
動態配置記憶體?
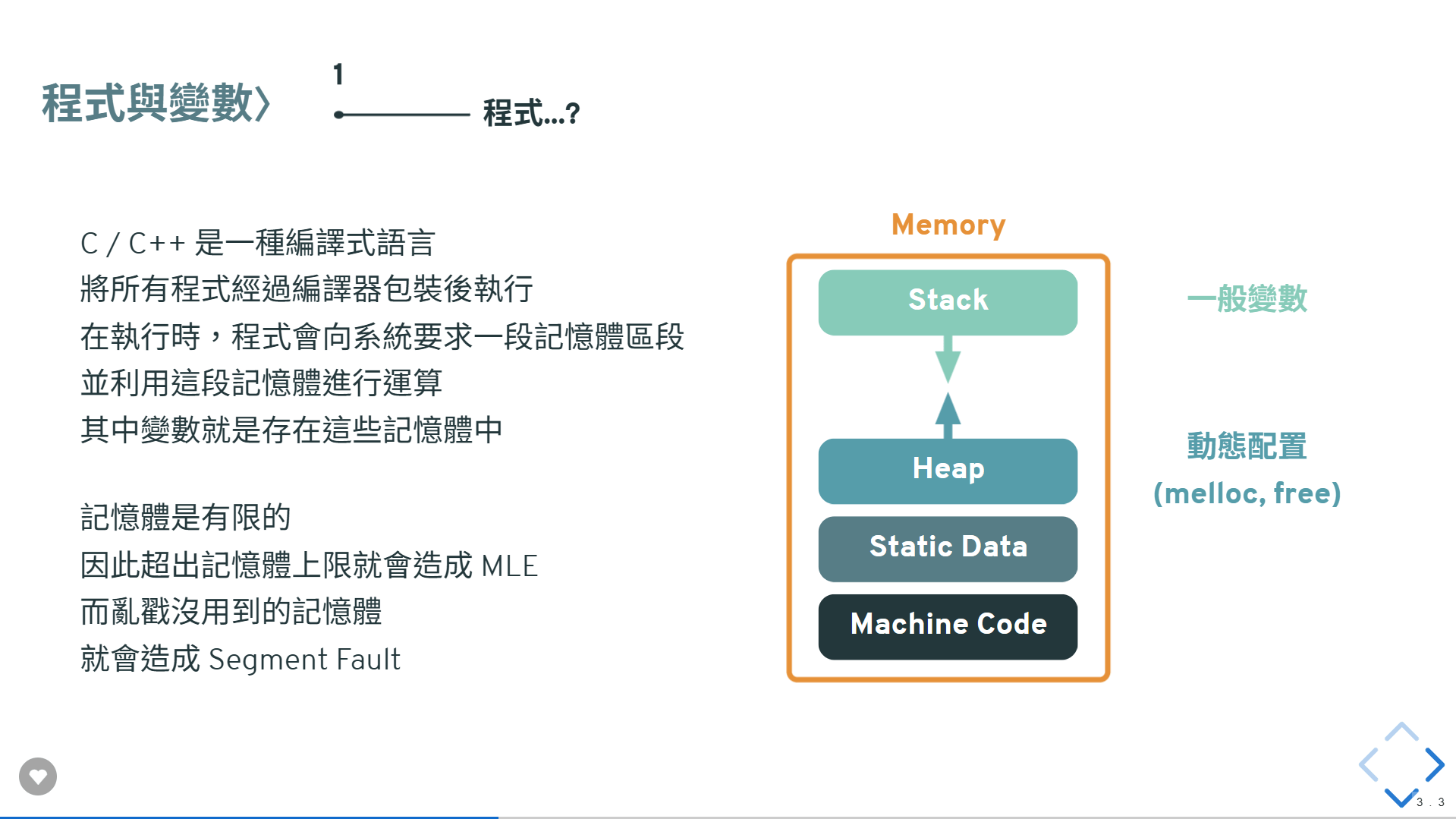
還記得階段考前 ......
所謂動態配置記憶體,就是在程式運行過程中
主動向系統要求記憶體使用,並且適時歸還
就像水循環一樣
比如在解題中為了方便把陣列直接開到輸入上限
但這樣其實很浪費空間
又或著某些變數只是為了短暫需要
使用完後不丟掉也會浪費空間
更甚者有時候你也無法預測會有多少東西出現
固定大小的陣列也無法適配這種情況
這時候我們就需要動態配置記憶體
動態配置記憶體〉
1
動態配置記憶體?
2
(C) malloc / free
因為 C++ 有更好用的函式所以這裡快速帶過
<type> *ptr = (<type>*) malloc(number of bytes);malloc / free 是 C 語言中一套動態配置記憶體的函式,需要 #include <stdlib.h>
malloc 是向系統取得記憶體的函式
malloc 回傳的是 void*,是系統動態配置的連續記憶體位址(開頭)
void* 不帶有指向型別,因此要轉型為目標的指標型別
malloc 的傳入值是所要求的 byte 數量
通常就是準備使用之變數型別的 byte 數量(陣列的話就整數倍)
因為我們不可能手算所有型別的大小(想想還有 struct, class...)
我們會用 sizeof(<type>) 來獲得該型別單一變數所佔的記憶體大小
int *iptr = (int*) malloc(sizeof(int));
char *cptr = (char*) malloc(sizeof(char));
int *arr = (int*) malloc(sizeof(int) * n);
// arr: an array of length = n配置後指標指向被配置的位址
就可以利用 *ptr 操作這段記憶體
同理配置的陣列也能用 arr[i] 來操作
動態配置記憶體〉
2
(C) malloc / free
因為 C++ 有更好用的函式所以這裡快速帶過
malloc / free 是 C 語言中一套動態配置記憶體的函式,需要 #include <stdlib.h>
free 是向系統歸還記憶體的函式
free(ptr);把方才紀錄 malloc 的指標(向系統取得的記憶體位址)放入 free 函式
就是把記憶體歸還給系統,指標所存的位址就會失效
向系統要求的記憶體生命週期便是從 malloc 到 free 為止
與大括號等等無關(當然整個程式結束記憶體還是會被回收)
也因為我們紀錄的是指標(記憶體位址),只要做好指標管理
我們就能在任意位置操作這段記憶體而不受任何作用域影響
但也正因為我們只能透過指標操作這段記憶體
一旦位址遺失,就會發生記憶體洩漏 (Memory Leak)
我們沒有任何途徑能存取這段記憶體,也無法釋放
形成一個用不了也丟不掉的垃圾記憶體堆積在旁
造成空間的浪費
動態配置記憶體〉
2
(C) malloc / free
3
(C++) new / delete
觀察一下剛剛 malloc 的語法
int *iptr = (int*) malloc(sizeof(int));
char *cptr = (char*) malloc(sizeof(char));
int *arr = (int*) malloc(sizeof(int) * n);
// arr: an array of length = n感覺寫太多次重複的型別了
其實真的極少會有這些型別不重複的時間
所以 new / delete 誕生了
動態配置記憶體〉
3
(C++) new / delete
<type> *ptr = (<type>*) malloc(sizeof(<type>));<type> *ptr = new <type>;malloc (C)
new (C++)
new 顯然清爽許多,只要在後面加上型別就好
動態配置記憶體〉
3
(C++) new / delete
<type> *ptr = new <type>;
<type> *arr = new <type>[size];new (C++)
除此之外,new 還有幾個特殊的用法
int *ptr = new int;
int *ptr2 = new int(342);
int *arr1 = new int[3];
int *arr2 = new int[5]{1, 2, 3, 4, 5};
int *arr3 = new int[10]{};可以在後面加入 (val) 來初始化記憶體存的值
剛剛直接擴展記憶體大小來實現陣列的方法
也可以用更直觀的 [size] 來取得連續記憶體
而且動態配置陣列同樣支援以 {...} 初始化
此外 class 的動態配置也同樣可以呼叫建構子
動態配置記憶體〉
3
(C++) new / delete
delete ptr;
delete [] arr;delete (C++)
free(ptr);free (C++)
在歸還記憶體的部分,delete 就與 free 差不多了
只差在 delete 如果是動態配置的陣列需要加上 []
因為 C 不需要區分一段記憶體是陣列還是一個很大的結構
而 C++ 是物件導向,需要區分記憶體的使用方法
若是物件陣列則需要對每個元素呼叫解構子
動態配置記憶體〉
3
(C++) new / delete
4
動態配置陣列
剛剛我們學到可以利用 new <type>[size] 來動態配置一維陣列
那更高維度的陣列怎麼辦?
再拿二維陣列舉例
如果需要達成這樣的效果,我們希望 a[0], a[1], a[2] 都是陣列
剛剛我們提到在一般宣告中,a 會是指向 int[4] 的指標
也就是 int*[4]
| a[0][0] | a[0][1] | a[0][2] | a[0][3] |
| a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| a[2][0] | a[2][1] | a[2][2] | a[2][3] |
動態配置記憶體〉
3
(C++) new / delete
4
動態配置陣列
如果需要達成這樣的效果,我們希望 a[0], a[1], a[2] 都是陣列
剛剛我們提到在一般宣告中,a 會是指向 int[4] 的指標
也就是 int*[4]
但之所以會是這樣,是因為宣告的時候系統是取連續的記憶體
也為了維護 pointer 地址平移的性質
| a[0][0] | a[0][1] | a[0][2] | a[0][3] |
| a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| a[2][0] | a[2][1] | a[2][2] | a[2][3] |
仔細想想,陣列可以當作指標,而原型中是指向陣列的指標
其實我們需要的是指向指標的指標
動態配置記憶體〉
3
(C++) new / delete
4
動態配置陣列
| a[0][0] | a[0][1] | a[0][2] | a[0][3] |
| a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| a[2][0] | a[2][1] | a[2][2] | a[2][3] |
int* a[0]
int* a[1]
int* a[2]
int** a
int** a = new int*[3]; // a is an array of 3 int pointer
for(int i = 0; i < 3; i++)
a[i] = new int[4]; //a[i] is an array of 4 int如此一來雖然得到的不是連續記憶體
我們仍然利用指標的存取規則構造出了多維陣列
動態配置記憶體〉
3
(C++) new / delete
4
動態配置陣列
| a[0][0] | a[0][1] | a[0][2] |
| a[1][0] | a[1][1] | a[1][2] | a[1][3] |
| a[2][0] | a[2][1] | a[2][2] | a[2][3] | a[2][4] |
int* a[0]
int* a[1]
int* a[2]
int** a
int** a = new int*[3]; // a is an array of 3 int pointer
a[0] = new int[3]; //a[0] is an array of 3 int
a[1] = new int[4]; //a[1] is an array of 4 int
a[2] = new int[5]; //a[2] is an array of 5 int此外我們也能根據需求
調整每個指標元素指向的陣列大小
動態配置記憶體〉
3
(C++) new / delete
4
動態配置陣列
int** a = new int*[3]; // a is an array of 3 int pointer
a[0] = new int[3]; //a[0] is an array of 3 int
a[1] = new int[4]; //a[1] is an array of 4 int
a[2] = new int[5]; //a[2] is an array of 5 int不過在歸還記憶體時較記得從最小的開始
由內往外慢慢刪掉
for(int i = 0; i < 3; i++) delete [] a[i];
delete [] a;OOP with pointer
CHECK POINT
OOP with pointer
OOP with pointer〉
1
struct / class with pointer / reference
剛剛在談到指標(與參考)的時候一個很重要的觀念就是他們的型別
指標必須宣告為指向 <type> 的指標(同理參考是宣告為 <type> 的參考)
而這裡的 <type> 並不限於內建的型別,也包括我們自己定義的 struct 與 class
struct S{/*...*/};
class C{/*...*/};
S s1;
C c1;
S* sptr = &(s1);
C* cptr = &(c1);
S& sref = s1;
C& cref = c1;由於參考是取外號
操作跟使用 struct / class 本體一樣
那指標呢?
OOP with pointer〉
1
struct / class with pointer / reference
struct Student{
int id;
string name;
};
//...
Student* S1 = new Student;
(*S1).id = 1024;
(*S1).name = "I want to SLEEP";直覺上,對指標取值可以得到結構本身
這時再透過 .member 就能取得裡面的變數與函式
但這樣寫顯然很冗
struct Student{
int id;
string name;
};
//...
Student* S1 = new Student;
S1 -> id = 1024;
S1 -> name = "I want to SLEEP";C/C++ 中有一種特別的訪問運算子:-> member
協助指標訪問成員
我們可以直接在指標後加上 -> member
來達到存取該成員的效果
與 (*ptr).member 等價
OOP with pointer〉
1
struct / class pointer / reference
2
class with dynamic memory allocation
其實有了參考以後,指標好像就沒必要了......嗎?
剛剛的動態配置記憶體中,我們透過 new / delete 產生的都是指標
並且透過 -> 來存取省去很多惱人的取值 / 取址
如果我們從頭到尾都動態配置記憶體
換句話說:你操作的一直都是指標
那麼實際用起來跟宣告一般的 class 變數沒什麼不同
OOP with pointer〉
1
struct / class pointer / reference
2
class with dynamic memory allocation
在 class 之中我們可以定義虛擬函式 (virtual)
來讓有繼承關係的物件們通用函式
也就是上節課講的多型 (Polymorphism)

上禮拜因為還沒教到指標暫時使用參考
但在動態配置後透過指標可以更靈活的操作物件
OOP with pointer〉
2
class with dynamic memory allocation
void what_does_it_say(Animal* a){
a -> say();
}
int main(){
Animal* zoo[2];
zoo[0] = new Dog();
zoo[1] = new Fox();
what_does_it_say(zoo[0]);
//> Bark!
what_does_it_say(zoo[1]);
//> Gering-ding-ding-ding-dingeringeding!
}宣告一個父類別的指標陣列
其元素 (Animal*) 便可利用 new 來動態配置
並且可以 new 子類別
實現在同一個陣列裡放入不同的物件
用指標實作 vertual 函式的外部呼叫
也能利用父類別參數達成的多型
而不需要為每個子類別撰寫函式
OOP with pointer〉
2
class with dynamic memory allocation
class Animal{
public:
Animal(){cout << "Animal created\n";}
virtual ~Animal(){cout << "Animal deleted\n";}
};
class Fox: public Animal{
public:
Fox(){cout << "Fox say hello\n";}
~Fox(){cout << "Fox sar goodbye\n";}
};
int main(){
Animal* a = new Fox();
//> Animal created
//> Fox say hello
delete a;
//> Fox say goodbye
//> Animal deleted
}同時剛剛也有提到:
new / delete 可以幫忙呼叫建構子 / 解構子
要特別注意的是建構是從父到子(先長根再長葉子)
而解構是從子到父(先剪枝葉再除根)
但是函式執行都是先以父親為主
如果有 virtual 再以子類為主
因此建構子的設計不能使用多型
由父到子依序呼叫建構子,先長根再長葉子
而解構子則需要利用 virtual 函式形成多型
由外到內一層一層解構
OOP with pointer〉
2
class with dynamic memory allocation
3
class: this
在 class 之中,除了我們宣告的成員以外
還有一個隱形成員:this
this 是一個指向自己的 class pointer
用處就是在 class 裡面定義函式的參數時
可能會用到與成員相同的變數名稱
(或著說另外取一個變數名稱也不直覺)
這時透過 this 指標訪問自己的成員
就能避開變數重複定義的問題
就算名稱不重複也能更清楚在對什麼變數操作
class Animal(){
public:
string name;
int height, weight;
Animal(string name, height, weight){
this -> name = name;
this -> height = height;
this -> weight = weight;
}
};Dynamic Array
CHECK POINT
Dynamic Array
Dynamic Array〉
1
動態陣列
還記得 STL 教的 vector 嗎?
有很多人學會 vector 以後就不會再用 array 了
那 vector 究竟比 array 好在哪?
- 物件化,可以輕鬆賦值
- 操作模組化,不用自己維護性質
- 支援隨機存取,跟使用 array 的感覺差不多
- 動態長度陣列,不用一開始就把長度寫死
Dynamic Array〉
1
動態陣列
- 物件化,可以輕鬆賦值
- 操作模組化,不用自己維護性質
- 支援隨機存取,跟使用 array 的感覺差不多
- 動態長度陣列,不用一開始就把長度寫死
當然要求有點實作一模一樣的 vector 有點過分,我們簡化一下要求
請你實做一個 int 型別的動態長度陣列,支援以下函式操作:
-
get(int id) // return the value of index id
-
modify(int id, int val) //modify the value of index id to val
-
push_back(int val) //add the value to the back of the array
-
size() //return the size of array
-
empty() //return whether the array is empty or not
Dynamic Array〉
1
動態陣列
再特別對動態長度陣列的部分作說明
class vector{
private:
//...
public:
vector();
~vector();
get(int id);
modify(int id, int val);
push_back(int val);
size();
empty();
}你的 class 架構大致上長成這樣
為了動態長度,我們需要動態配置記憶體
依據需求產出適當長度的記憶體來使用
實作上我們常常用倍增的方式
也就是在用到容量上限的時候擴容成 2 倍
再把原始陣列的元素一個個複製到新陣列上
那要怎麼利用剛剛學的動態陣列實作呢
Dynamic Array〉
1
動態陣列
Ans:
Dynamic Array〉
1
動態陣列
2
使用 [] 取值(運算子多載)
在 vector 中我們能直接對物件用 [] 取值,這是為什麼?
多型是 OOP 中重要的特徵
支援不同型別或類別使用同一種操作
我們之前看到的都是函式
而這裡再介紹另外一個:運算子多載
白話文:運算子多載就是在一般的運算子上做多型
在 C++ 中我們可以對 class 重新定義運算子的操作邏輯
進而簡化我們的實作邏輯與語法
Dynamic Array〉
1
動態陣列
2
使用 [] 取值(運算子多載)
在 C++ 中我們可以對 class 重新定義運算子的操作邏輯
進而簡化我們的實作邏輯與語法
class vector{
private:
int* arr_;
//...
public:
//...
int& operator[](size_t id){
return arr_[id];
}
};透過回傳該位值的參考
我們就能在外部對該索引值的變數進行存取與修改
Dynamic Array〉
2
使用 [] 取值(運算子多載)
3
Template
Linked list