ORIGEN
Apache Mahout inicio en el año 2008 como un sub-proyecto de Apache Lucene. En 2010 se convirtio en un proyecto de primer nivel de Apache.
QUE ES APACHE MAHOUT
Mahout es un marco de trabajo (framework) de código abierto, que permite el procesamiento y almacenamiento de grandes datos en un ambiente distribuido a través de cluster de computadores, utilizando modelos de programación simples.
PRINCIPALMENTE ES USADO PARA....
Crear algoritmos de aprendizaje maquina escalables, implementando técnicas como:
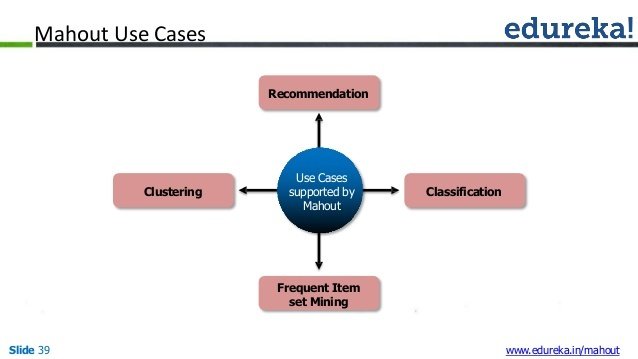
- Algoritmos de clasificación
- Sistemas de recomendación
- Clustering (agrupación de vectores en base a ciertos criterios).
CARACTERÍSTICAS
- Los algoritmos de Mahout están escritos sobre Hadoop, por lo tanto trabajan correctamente en ambientes distribuidos, escalando con eficiencia en la nube.
- Mahout ofrece al programador un marco de trabajo listo para usarse en tareas de minería de datos sobre grandes volúmenes.
- Mahout permite a las aplicaciones analizar grandes conjuntos de datos de manera efectiva y en corto tiempo.
- Incluye algunas implementaciones para clusterizar con MapReduce tales como: kmeans, fuzzy k-means, Canopy, Dirichlet, and Mean-Shift.
- Soporta Clasificadores Bayesianos simples y compuestos distribuidos (Naive Bayes)
- Funciones de adaptabilidad distribuida para programación evolutiva.
- Incluye bibliotecas de matrices y vectores.
CARACTERÍSTICAS
APLICACIONES
- Foursquare Motor de recomendaciones.
- Twitter Modelado de intereses de usuario.
- Yahoo! Minería de patrones.







Líneas de aplicación
MACHINE LEARNING
Rama de la ciencia que se enfrenta a problemas de programación que requieren aprendizaje automático y mejorar con la experiencia.
Por aprendizaje entendemos el reconocimiento y entendimiento de datos de entrada y la toma de decisiones optimas basadas en los datos suministrados
Los algoritmos de Machine Learning son la base de aplicaciones como:
- Procesamiento de visión
- Procesamiento de lenguaje
- Estudios de comportamiento de mercado
- Reconocimiento de patrones
- Juegos
- Minería de datos
- Sistemas expertos
- Robotica
APLICACIONES
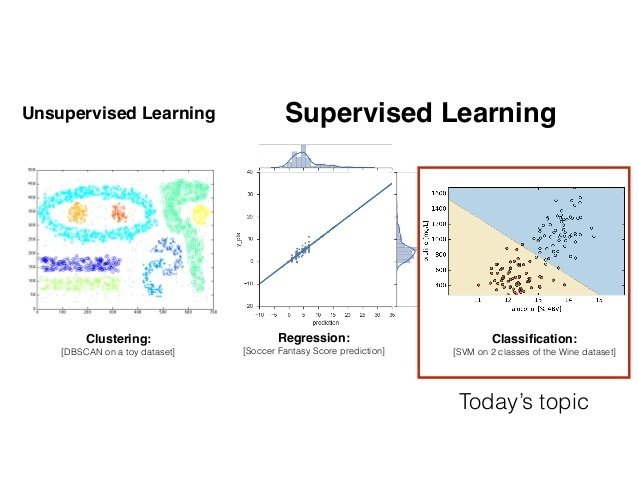
El aprendizaje supervisado busca entrenar un algoritmo con información disponible. Dicho algoritmo supervisado analiza los datos de entrenamiento y produce una función de inferencia, que puede ser usada para realizar el mapeo de nuevas muestras.
- Clasificación de spam en e-mails
- Etiquetado de sitios web, basándose en su contenido
- Reconocimiento de voz
APRENDIZAJE SUPERVISADO

Le da sentido a datos no etiquetados, sin tener ningún entrenamiento previo. El aprendizaje no supervisado es una herramienta extremamente poderosa para analizar datos disponibles y buscar patrones y tendencias.
- k-means
- Mapas auto-organizados
- Agrupación jerárquica (clustering)
APRENDIZAJE NO SUPERVISADO

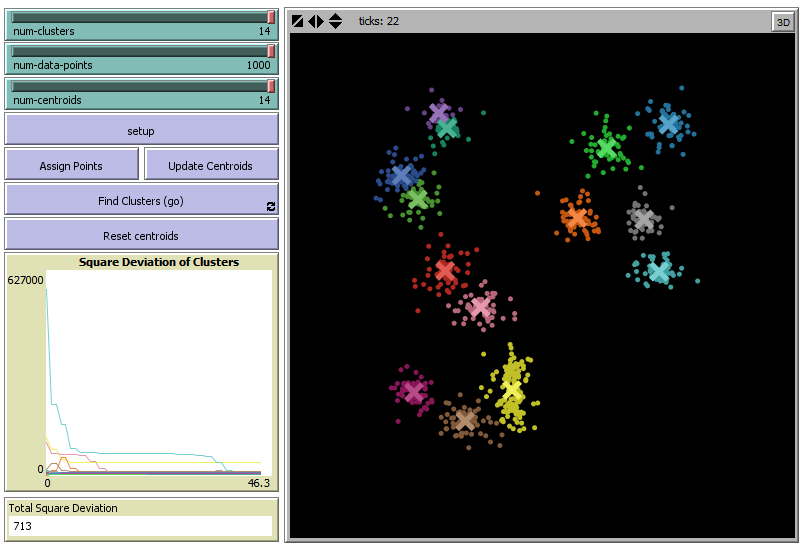
CLUSTERING
(No supervisado)
Clasifica un dato de entrada según sus características en un grupo determinado
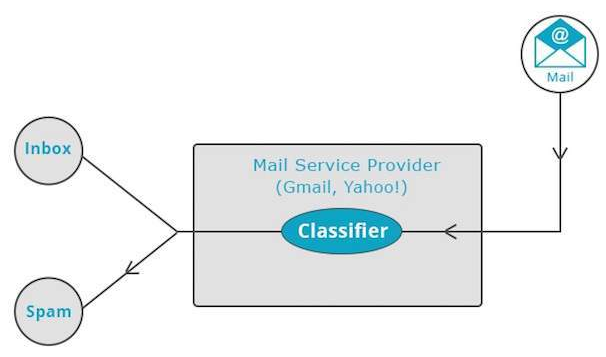
CLASIFICADOR
(Supervisado)
RECOMENDACIÓN
REQUERIMIENTOS
1- SSH (Secure SHell) y llave generada.
2- Java 1.6.x o superior.
3- Hadoop.
4- Maven 3.x para construir el código fuente.
INSTALACIÓN
Usar MAVEN para inyectar las siguientes dependencias:
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-core</artifactId>
<version>0.9</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-math</artifactId>
<version>${mahout.version}</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>${mahout.version}</version>
</dependency>CLUSTERING
PROCEDIMIENTO PARA CLUSTERING
PASO 1. Inicializando el servidor de Hadoop
$ cd HADOOP_HOME/bin
$ start-all.shPASO 2. Preparando los directorios para los archivos de entrada
$ hadoop fs -p mkdir /mahout_data
$ hadoop fs -p mkdir /clustered_data
$ hadoop fs -p mkdir /mahout_seq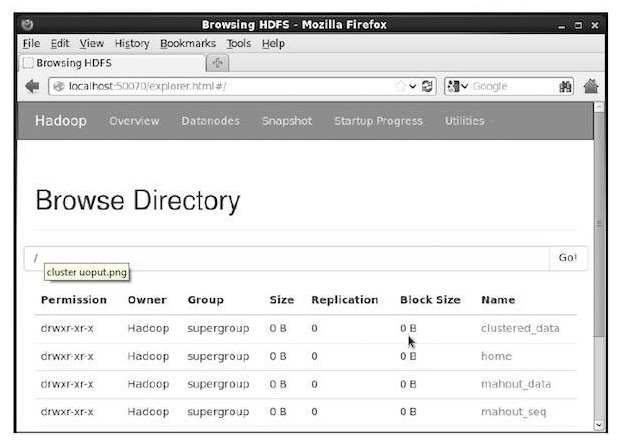
PASO 2. Preparando los directorios para los archivos de entrada
PASO 2. Copiando los archivos de entrada al sistema de archivos de Hadoop
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/PASO 3. Preparando el archivo de secuencia

Archivo de entrada con los datos originales
Archivo de salida con los formato secuencial
mahout seqdirectory -i <input file path> -o <output directory>
PASO 4. Ejecutando un algoritmo de clustering disponible
Dos de los algoritmos mas importantes de clustering:
- Canopy Clustering
- K-means Clustering
4.1 CANOPY CLUSTERING
mahout canopy -i <input vectors directory>
-o <output directory>
-t1 <threshold value 1>
-t2 <threshold value 2>En Canopy los objetos son tratados como puntos en un espacio plano y esta tecnica es usada como paso inicial de otros algoritmos
Ejemplo:
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq
-o hdfs://localhost:9000/clustered_data
-t1 20
-t2 30 Paso 3. Archivo Secuencial
4.2 K-MEANS CLUSTERING
mahout kmeans -i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-dm <Distance Measure technique>
-x <maximum number of iterations>
-k <number of initial clusters>En K-means los objetos son tratados como vectores en un espacio y esta tecnica es usada como paso inicial de otros algoritmos
- Creando los archivos de vectores
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.RECOMENDACIÓN
PROBLEMA
Considerar un sitio web que vende productos como dispositivos móviles y accesorios tecnológicos. Si queremos implementar un sistema de recomendación que analice las compras pasadas de los usuarios y recomiende nuevos productos basadas en ellas.
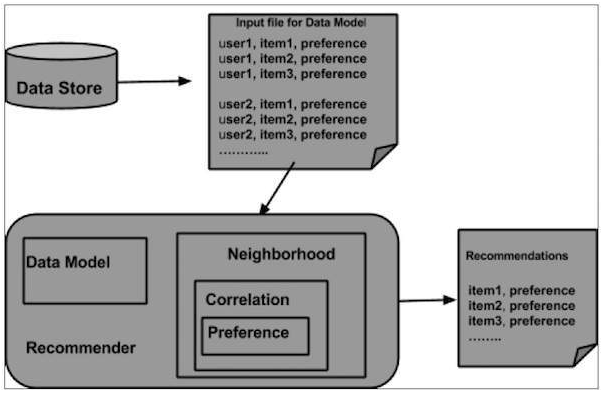
Para esto Mahout proporciona los siguientes componentes
- DataModel
- UserSimilarity
- ItemSimilarity
- UserNeighborhood
- Recommender
ARQUITECTURA DEL SISTEMA DE RECOMENDACIONES
PASO 1. Creando el modelo de datos
DataModel datamodel = new FileDataModel(new File("input file"));1,00,1.0
1,01,2.0
2,00,1.0
2,01,2.0
input file
PASO 2. Crear el objeto UserSimilarity
UserSimilarity similarity = new PearsonCorrelationSimilarity(datamodel);PASO 3. Crear el objeto UserNeighborhood
NearestNUserNeighborhood: Consiste en encontrar los vecinos mas cercanos de un usuario dado y la cercanía esta dada por el objeto UserSimilariry.
ThresholdUserNeighborhood: Consiste en encontrar todos los vecinos cuya similaridad al usuario dado cumple o excede con un umbral determinado, la similaridad es definida por el objeto UserSimilarity
PASO 3. Crear el objeto UserNeighborhood
UserNeighborhood neighborhood = new ThresholdUserNeighborhood(3.0, similarity, datamodel);Limite del umbral de preferencia
Perfil de similaridad de usuarios (Paso 2)
Modelo de datos de usuarios (Paso 1)
PASO 4. Crear el objeto Recommender
UserBasedRecommender recommender = new GenericUserBasedRecommender(datamodel, neighborhood, similarity);Vecindario (Paso 3)
Perfil de similaridad de usuarios (Paso 2)
Modelo de datos de usuarios (Paso 1)
PASO 5. Recomendar productos a un usuario
List<RecommendedItem> recommendations = recommender.recommend(2, 3);
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}Identificador del usuario al que se le haran las recomendaciones
Cantidad de elementos que se recomendaran al usuario
Esto produce la siguiente salida
RecommendedItem [item:3, value:4.5]
RecommendedItem [item:4, value:4.0]CLASIFICACIÒN
Cómo trabaja?
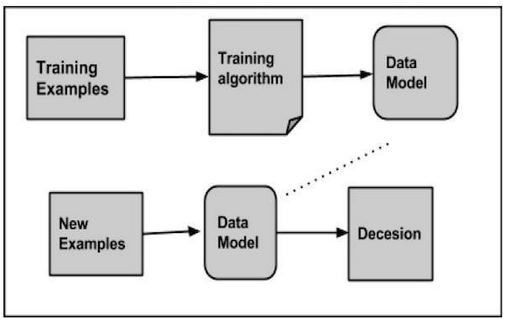
PASO. 1 Generar datos de ejemplo
$ mkdir classification_example
$ cd classification_example
$tar xzvf 20news-bydate.tar.gz
wget http://people.csail.mit.edu/jrennie/20Newsgroups/20news-bydate.tar.gz PASO. 2 Crear archivos secuenciales
mahout seqdirectory -i <input file path> -o <output directory>PASO. 3 Conversión de archivos secuenciales en vectores
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.PASO. 4 Entrenar los vectores
mahout trainnb
-i ${PATH_TO_TFIDF_VECTORS}
-el
-o ${PATH_TO_MODEL}/model
-li ${PATH_TO_MODEL}/labelindex
-ow
-cPASO. 5 Probar los vectores
mahout testnb
-i ${PATH_TO_TFIDF_TEST_VECTORS}
-m ${PATH_TO_MODEL}/model
-l ${PATH_TO_MODEL}/labelindex
-ow
-o ${PATH_TO_OUTPUT}
-c
-seq