
Web Audio API
How to transmit data over sound
Robert Rypuła
2018.05.17

Presentation overview:
- What is sound wave and how to store it?
- Web Audio API overview
- Generate sound - speakers
- Hear the sound - microphone
- AnalyserNode
- Modulation techniques
- Spectral Waterfall
- Physical Layer
- Data Link Layer
- Where to find more?
What is sound wave and
how to store it?
Speed of sound: 320 - 350 m/s (~ 1200 km/h)
Radio wave is almost milion times faster!
- 50 Hz --> 6.7 m
- 1 000 Hz --> 33.5 cm
- 15 000 Hz --> 2.2 cm
Sound wave in air travels as local changes in pressure
Wave length examples:
Speaker and mic needs to have moving part




Human hearing range: 20 Hz - 20 kHz
FM radio: 30 Hz - 15 kHz
Text
Whistling: 1 kHz - 2.5 kHz
Enough for voice: 300 Hz - 3400 Hz
Web Audio API + mobile phone: 150 Hz - 6000 Hz
0 Hz
10 kHz
20 kHz
Common Sampling Rates:
Text
- 44.1 kHz
- 48.0 kHz (almost all phones)
Common sample value precision: 16 bit signed integer
Range: -32768 do 32767
In Web Audio API it's normalized to: -1, +1
How to store sound wave?
Take a sample in constant interval
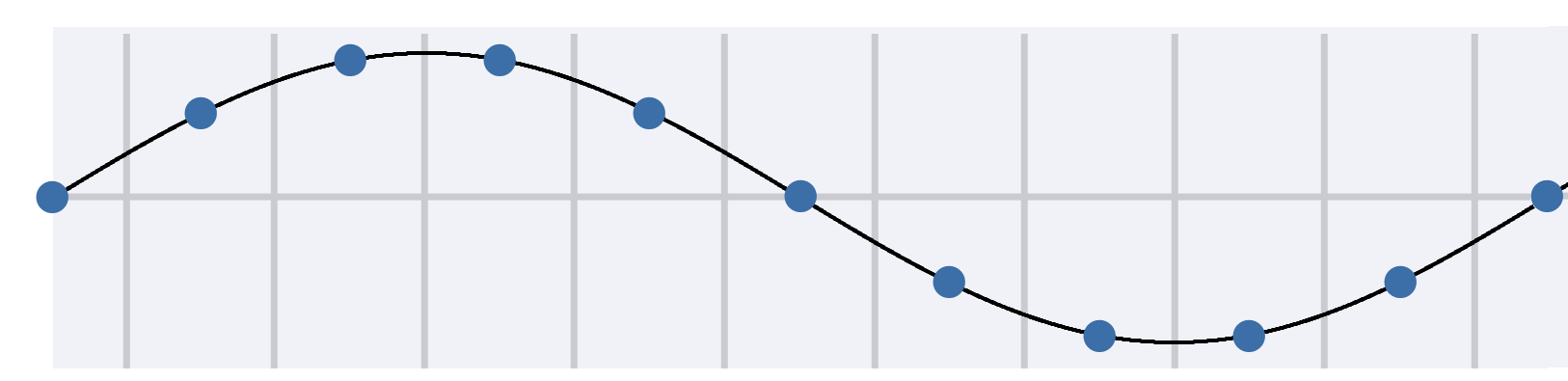
Text
Humans hear up to 20 kHz!
Why we use such high sampling rate?
Sampling frequency needs to be at least 2x higher than maximum frequency in the signal
44.1 kHz / 2 = 22 050 Hz (2 050 Hz for filtering)
48.0 kHz / 2 = 24 000 Hz (4 000 Hz for filtering)
0 Hz
20 kHz
44.1 kHz
48 kHz
?
Text
Text
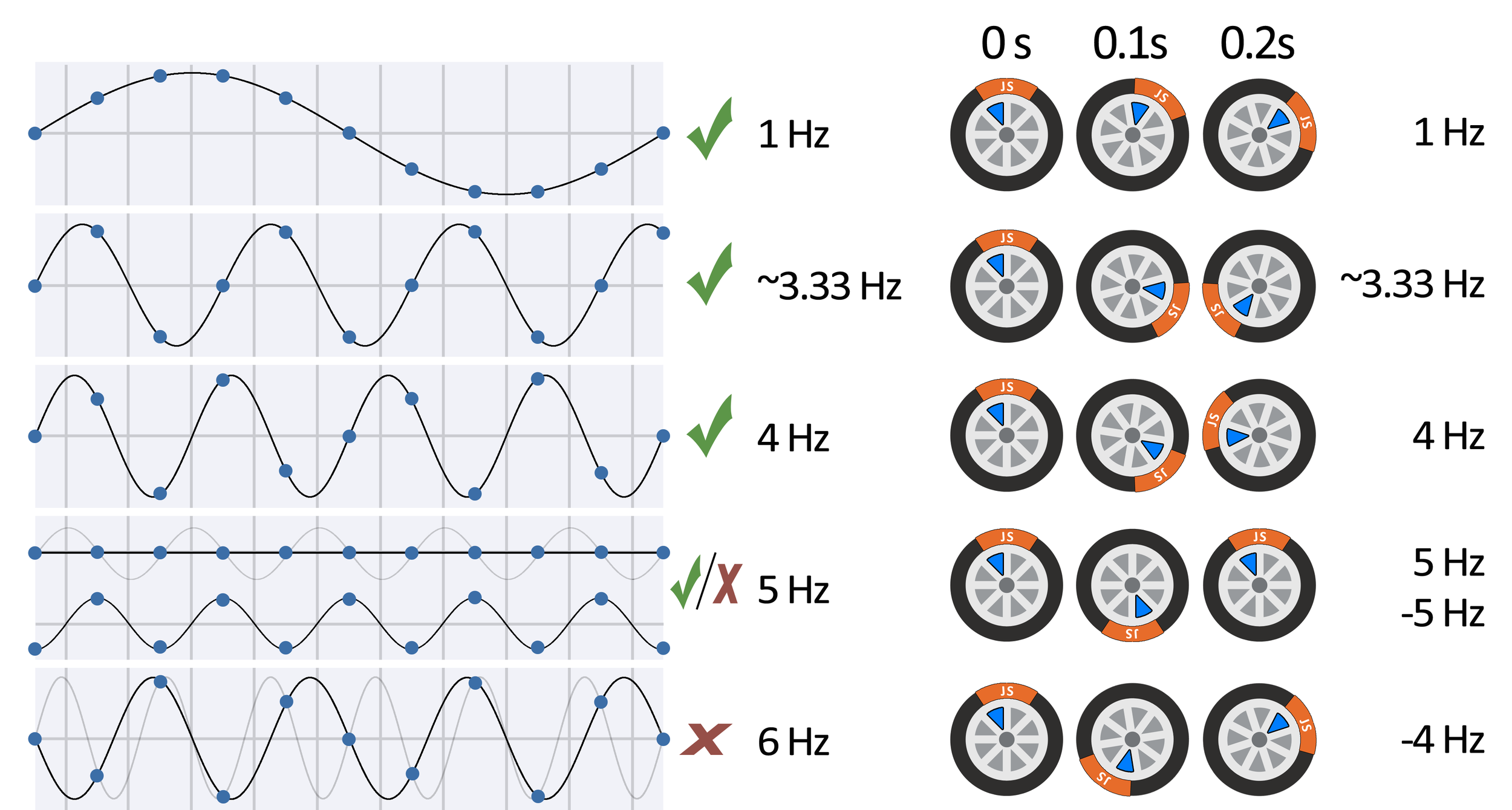
first 3 frames
out of 10
light line - what we want to store
dark line - what we will recover
fake frequencies
real frequencies
Text
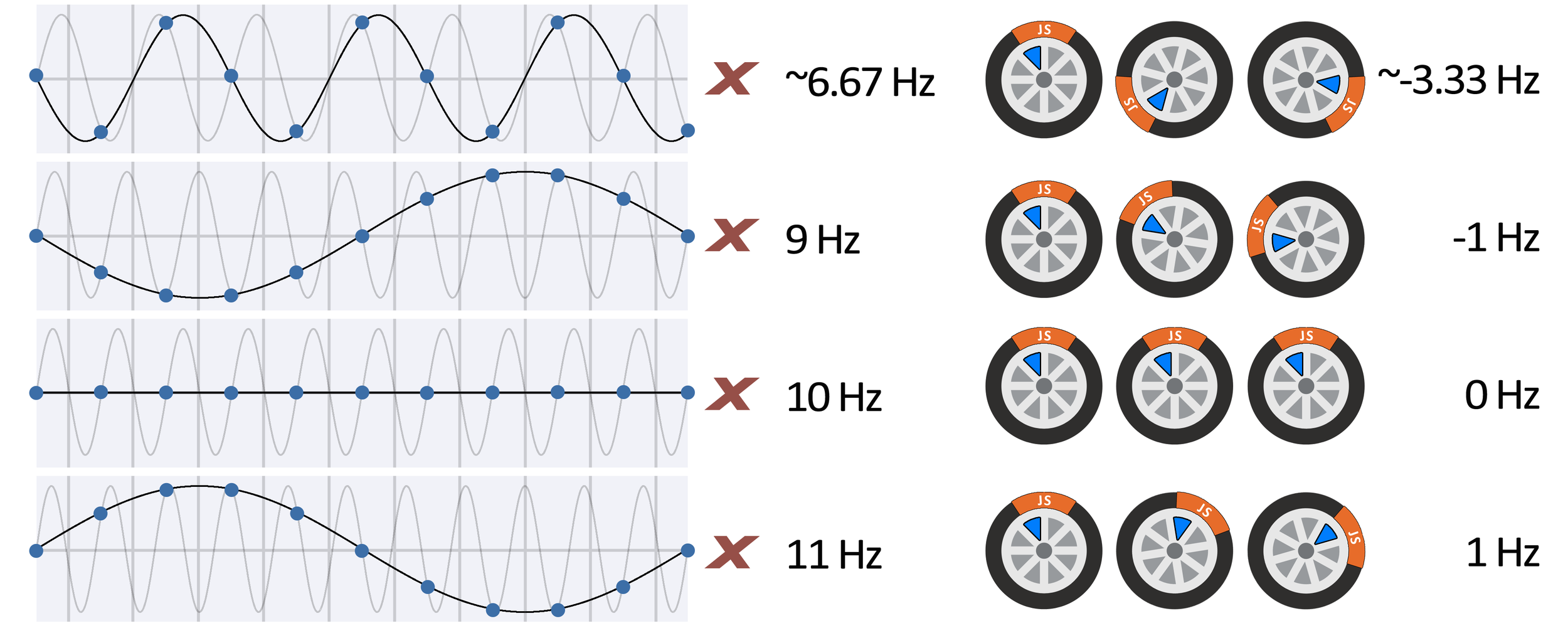
Sample rate assumed in those two slides: 10 Hz
Maximum frequency: 5 Hz
Web Audio API
overview
Audio Nodes live inside Audio Context
Very elastic - we are just connecting nodes as we like
AudioContext
AudioContext
Input nodes:
-
OscillatorNode
Example: generates waves -
AudioBufferSourceNode
Example: reading audio files -
MediaStreamAudioSourceNode
Example: access microphone stream
Output node:
-
AudioDestinationNode
Example: final node that represents speakers
~
10111
00101
Effect nodes:
-
BiquadFilterNode
Filters: lowpass, high pass, bandpass -
DelayNode
Add delay to the stream -
GainNode
Volume control
Visualization/processing nodes:
- AnalyserNode
gives time/frequency domain data -
ScriptProcessorNode
gives arrays of subsequent samples
DSP
DSP
DSP
FFT
freqDomain
timeDomain
your code
Generate sound - speakers
OscillatorNode
oscNode = audioContext.createOscillator();
GainNode
gainNode = audioContext.createGain();
AudioDestinationNode
adNode = audioContext.destination;
connect()
connect()
AudioContext
audioContext = new AudioContext();
oscillatorNode = audioContext.createOscillator();
gainNode = audioContext.createGain();
oscillatorNode.start(); // <-- required!
oscillatorNode.connect(gainNode);
gainNode.connect(audioContext.destination);
<input
type="range" min="0" max="20000" value="440"
onChange="oscillatorNode.frequency
.setValueAtTime(this.value, audioContext.currentTime)"
/>
<input
type="range" min="0" max="1" value="1" step="0.01"
onChange="gainNode.gain
.setValueAtTime(this.value, audioContext.currentTime)"
/>Hear the sound - microphone
To access microphone we need to have
user permission
Only websites served
via https can access microphone
MediaStreamSourceNode
micNode = audioContext.createMediaStreamSource(stream);
GainNode
gainNode = audioContext.createGain();
AudioDestinationNode
adNode = audioContext.destination;
connect()
connect()
AudioContext
navigator.mediaDevices.getUserMedia(constraints) .then(function (stream) { });
var microphoneNode; // <-- IMPORTANT, declare variable outside promise
function connectMicrophoneTo(audioNode) {
var constraints = {
video: false,
audio: true
};
navigator.mediaDevices.getUserMedia(constraints)
.then(function (stream) {
microphoneNode = audioContext.createMediaStreamSource(stream);
microphoneNode.connect(audioNode);
})
.catch(function (error) {
alert(error);
});
}
// ...
function init() {
audioContext = new AudioContext();
gainNode = audioContext.createGain();
connectMicrophoneTo(gainNode);
gainNode.connect(audioContext.destination);
// ...
}WARNING:
Microphone connected to speakers. Audio feedback
may occur!!
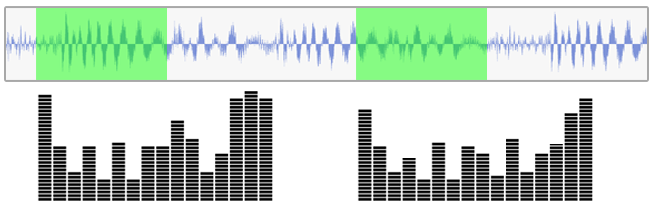
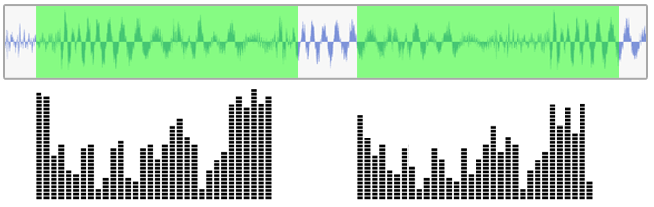
AnalyserNode
Allows to look at the same audio signal in
two different ways
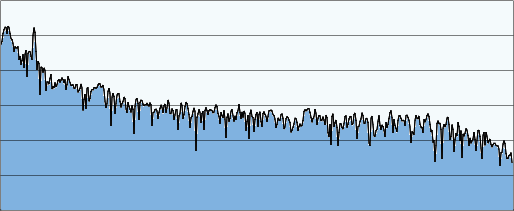
Frequency Domain:

'fftSize' values
'fftSize/2' values
Time domain:
Here it is!!
It looks like signal has one dominant frequency
0 dB
-20 dB
-40 dB
-60 dB
-80 dB
-100 dB
-120 dB
'0.5*fftSize' frequency bins
Frequency domain:
AnalyserNode performs Discrete Fourier Transform (Fast Fourier Transform, FFT)
'X' time domain samples are transformed into 'X/2' frequency bins
Frequency bin is expressed in decibels: every 20 dB we have 10x difference in amplitude
MediaStreamSourceNode
micNode = audioContext.createMediaStreamSource(stream);
AnalyserNode
analyserNode = audioContext.createAnalyser();
connect()
AudioContext
navigator.mediaDevices.getUserMedia(constraints) .then(function (stream) { });
function init() {
audioContext = new AudioContext();
analyserNode = audioContext.createAnalyser();
analyserNode.fftSize = 1024; // <--- fftSize, only powers of two!
analyserNode.smoothingTimeConstant = 0.8;
connectMicrophoneTo(analyserNode);
}
function getTimeDomainData() {
var data = new Float32Array(analyserNode.fftSize);
analyserNode.getFloatTimeDomainData(data);
return data; // ----> array length: fftSize
}
function getFrequencyData() {
var data = new Float32Array(analyserNode.frequencyBinCount);
analyserNode.getFloatFrequencyData(data);
return data; // ----> array length: fftSize / 2
}
How to use Analyser Node
- better resolution -> bigger fftSize
- bigger fftSize -> more time domain samples
- more time domain samples -> longer it takes to collect them
fftSize
fftSize
interval length

function getTimeDomainDuration() {
return analyserNode.fftSize / audioContext.sampleRate; // [ms]
}
function getFftResolution() {
return audioContext.sampleRate / analyserNode.fftSize; // [Hz/freqBin]
}
function getFrequency(fftBinIndex) {
return fftBinIndex * getFftResolution(); // [Hz]
}
Frequency domain output interpretation
is based on sampleRate as well
My tests:
Slowest mobile device was able to deliver 4 unique frequency domain outputs per second.
The best fit is fftSize = 8192

Discrete Fourier Transform sandbox ;)
Modulation techniques
Let's assume we want to send 4 different symbols
How to use wave properties to send them?
?
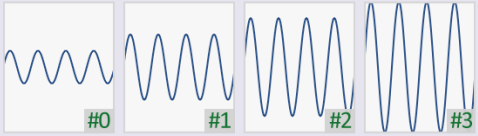
Amplitude-Shift Keying
Good only for few symbols
With more symbols they will be to
close to each other
Phase-Shift Keying
Phase data not available in Web Audio API
Not so many symbols per carrier wave
Requires custom-made DSP code
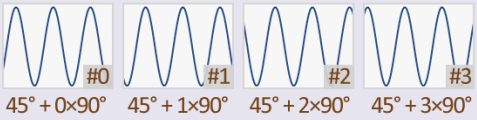
Frequency-Shift Keying
Out of the box with Analyser Node
More symbols?
- Expand the bandwidth!
- Increase FFT resulution!

Spectral Waterfall
How to show frequency domain changes in one row?
Add colors!
0 dB
-40 dB
-80 dB
-120 dB
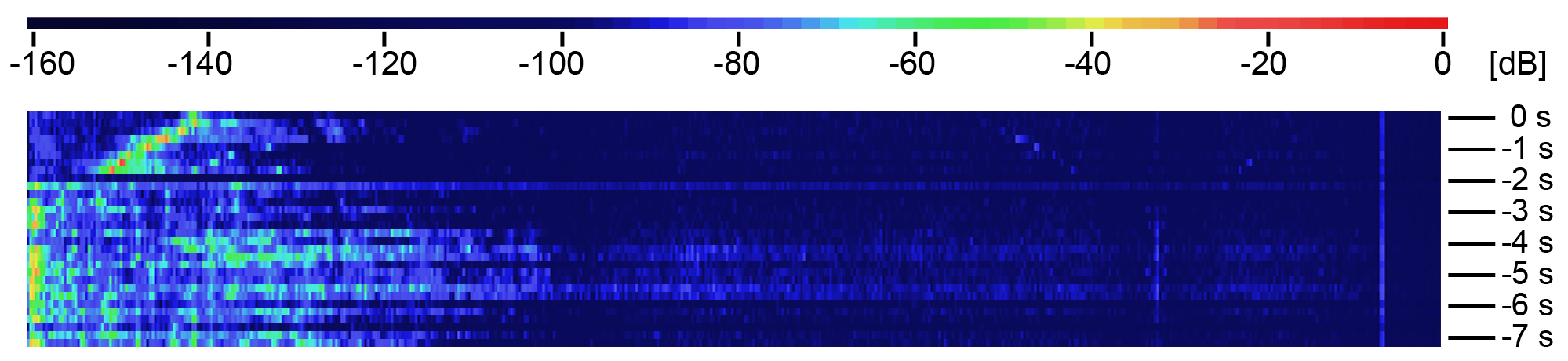
Desktop vs mobile
Most mobile devices blocks all frequencies above 8 kHz
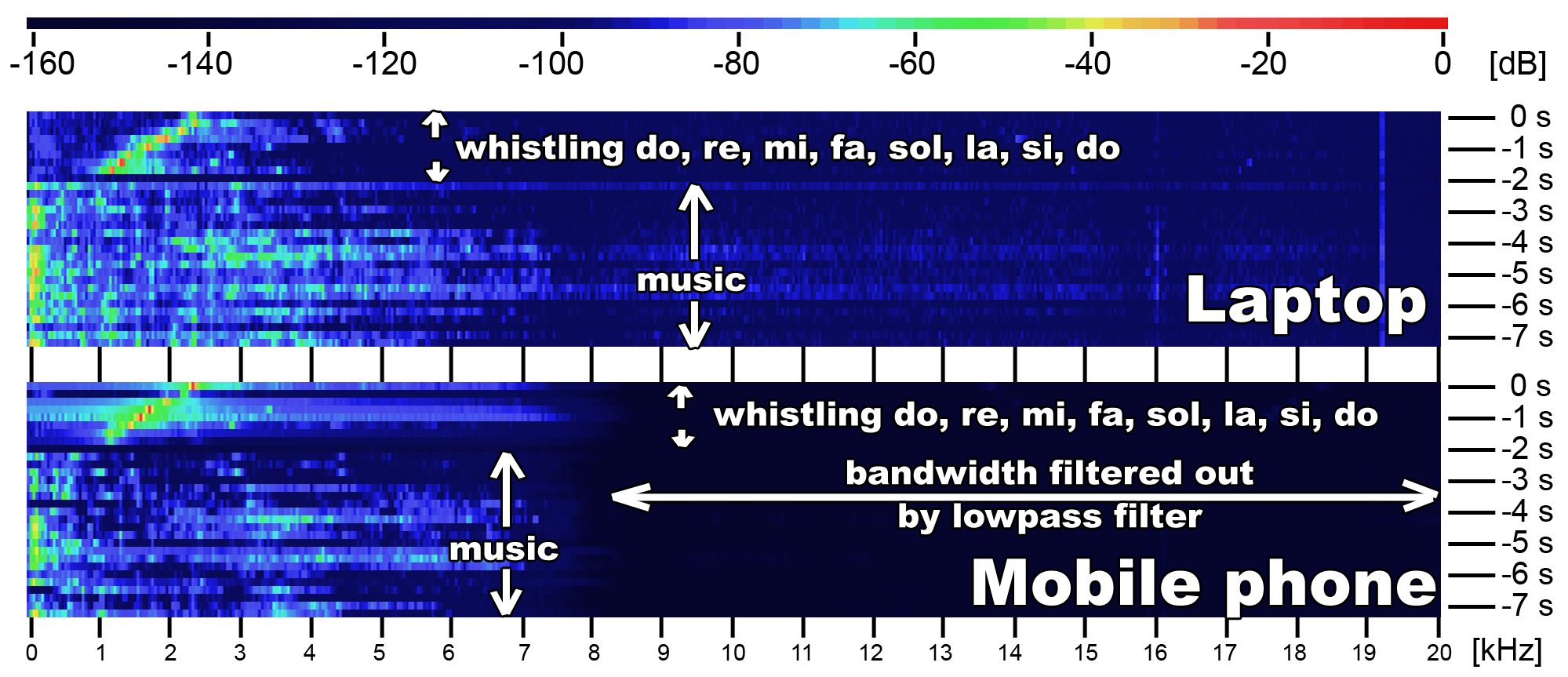



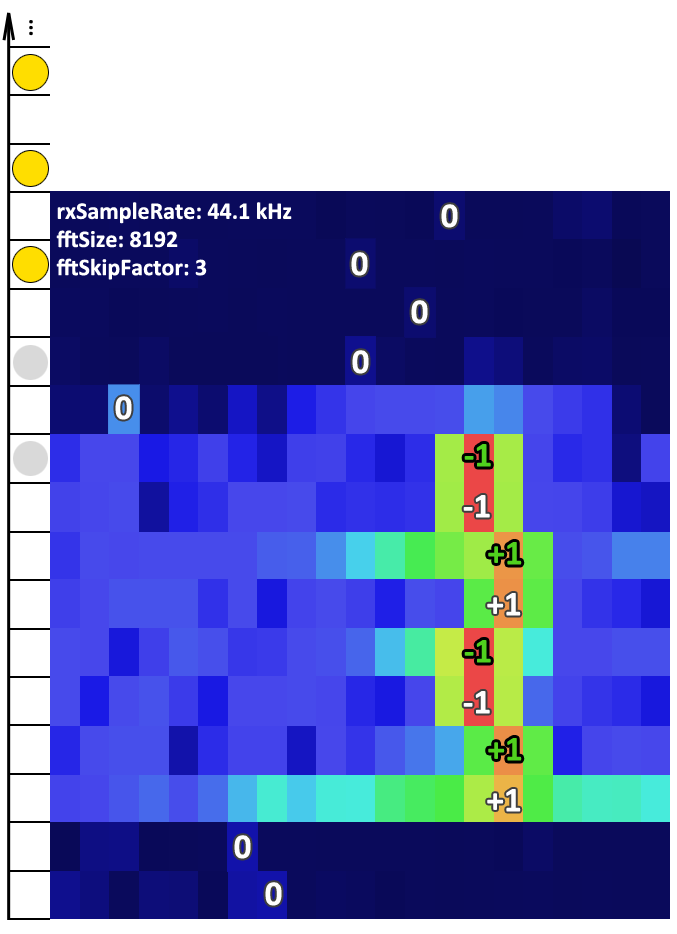
Skip factor 3
Skip factor 5
How to make single frequency more visible?
Merge frequency bins by finding max in each group
Where to allocate our symbols?
0 Hz
10 kHz
20 kHz
filtered out by most mobile phones
too low for mobile phone speaker
~800 frequency bins
Assume fftSize equal 8192
skip factor 3 (3 bins merged into 1)
~265 frequency bins
One byte

Summary
- Modulation: Frequency-Shift Keying
- FFT size: 8192
- Window duration: 186 ms or 171 ms
- Smoothing: disabled
- Freq. bins skiping: 3 merged into 1
- Bandwidth: from ~1.5 kHz to ~6.0 kHz
- Symbols: ~256 (1 byte per each FFT)
- Raw symbol rate: 4 FFTs/s
Works on most devices and browsers
Physical Layer
We can get 4 FFTs per second, each containing 1 byte
Unfortunately useful symbol rate will be only 2 bytes / s
H
e
l
l
o
Why?
Rx1
Rx2
0 s
0.5 s
1.0 s
1.5 s
2.0 s
2.5 s
Rx3
Tx
Synchronization process
Sync in
progress
Waiting
for sync
Sync OK
0 s
1 s
2 s
3 s
4 s
Goal:
Find "sync" sequence
with highest
signal strength
Physical Layer synchronization example:
0 Hz
10 kHz
20 kHz
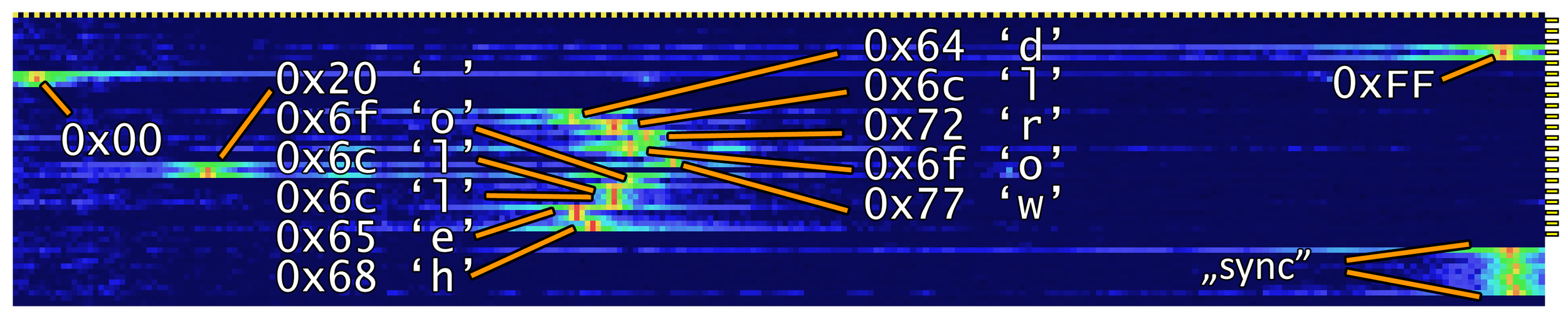
It takes 5.5 seconds to send "hello world"
ASCII range
256 data symbols + 2 sync symbols
More Physical Layer examples:
Data Link Layer
Physical Layer is not checking errors
Solution - pack chunks of data into frames!
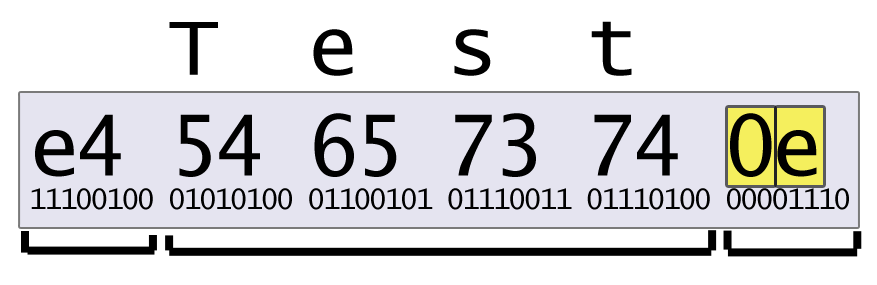
Payload
Header
Checksum
Fletcher-8 checksum sum0 = (sum0 + halfOfByte) % 0x0F; sum1 = (sum1 + sum0) % 0x0F;
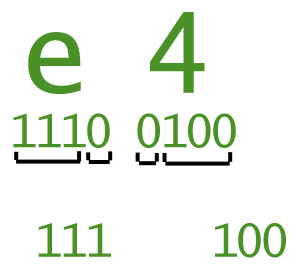

Header
"marker"
Header
length
Data Link example:
Where to find more?

Part 1/3
Discrete Fourier Tranform


Part 2/3
Web Audio API

Part 3/3
Self-made network stack


If you liked it please give
a star on Github here
Audio Network
project website
Thanks for watching!
the end