Combinação de modelos
Otimizando e reduzindo operações em deep-learning
Problema
Modelos e redes neurais complexas são custosas computacionalmente, porém são extremamente robustos.

Problemas de classificação e reconhecimento de padrões são vastos, e, nem sempre possuem poucos parâmetros.
Ideia
Uma abordagem Deep-learning para a classificação de documentos impressos.
Inception v3
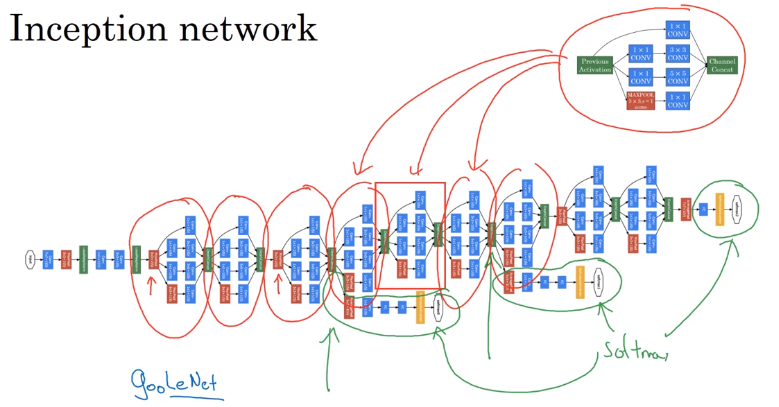

Solução
Utilizar redes menores para o processo de extração de características

FERREIRA, A. et al. Data driven approaches for laser printer attribution. 2017
Arquitetura
Fase 1 - Aprendizado de representação
Fase 2 - Classificação
Fase 3 - Análise
- Early-fusion
- Late-fusion
Fase 1 - Aprendizado de Representação
A ideia do aprendizado de representação é compreender padrões e características do dados, tendo como objetivo criar uma representação que seja simplificada, porém fiel ao dado original
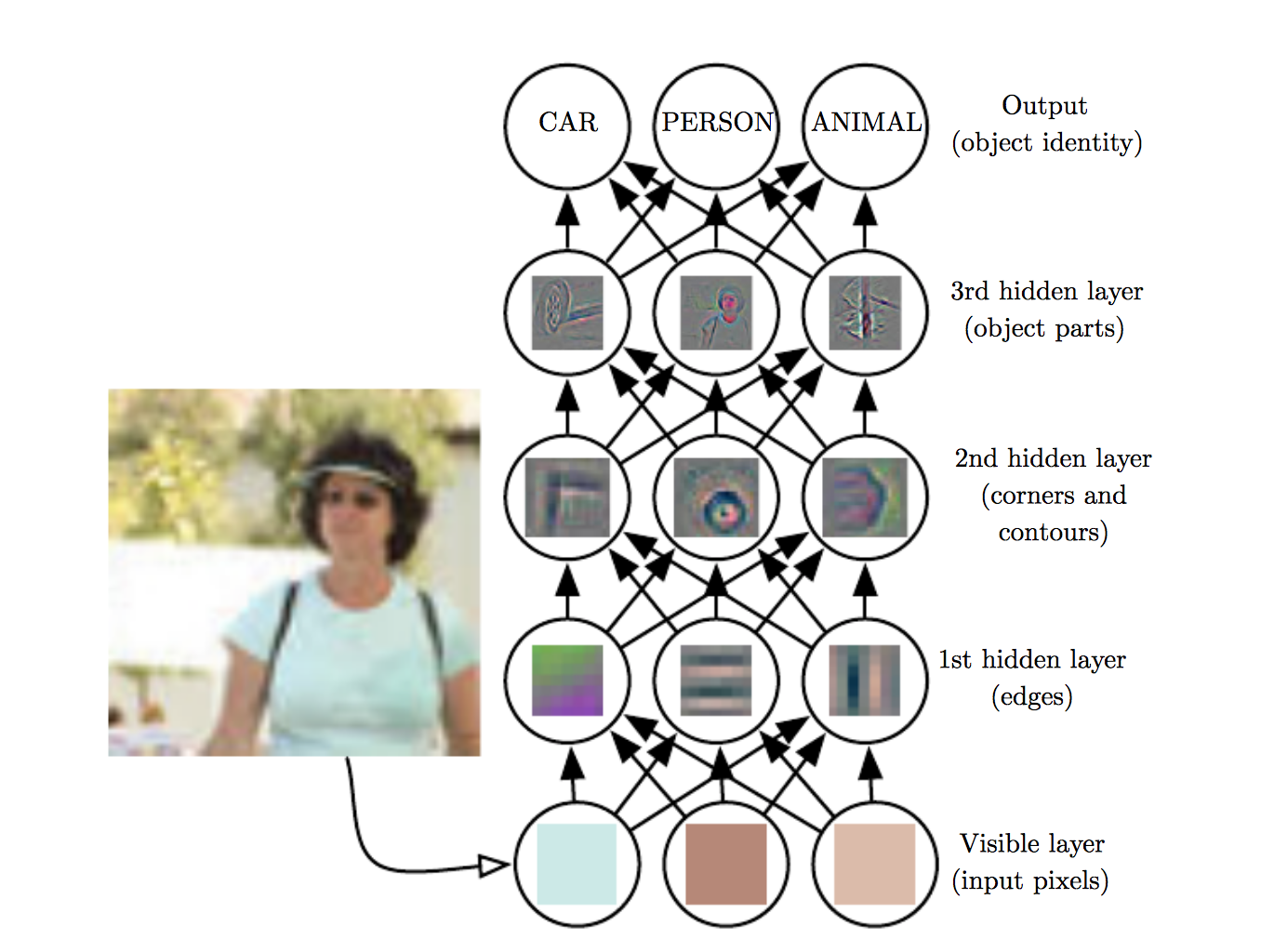
MAtematicamente...
Consecultivas operações de convolução e redução.
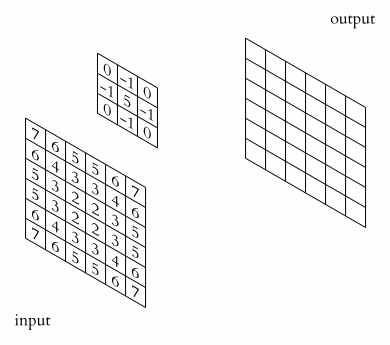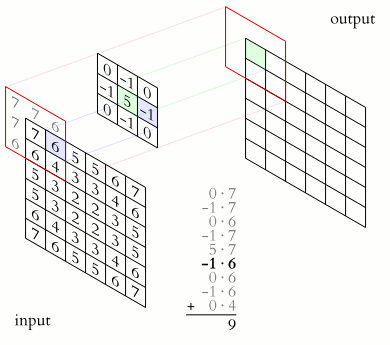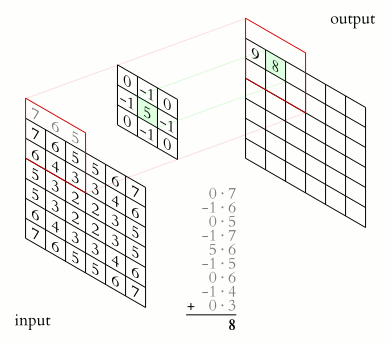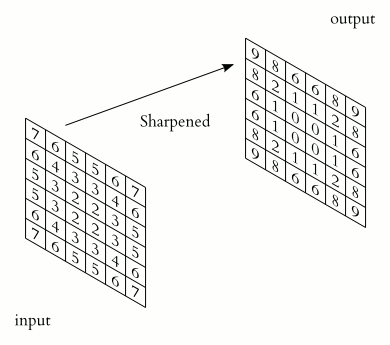
MAtematicamente...
Multiplas representações de dados, gerando uma maior massa operacional.
- Mediana residual
- Média residual
- Dados brutos
Resumo das operações
- 1ª convolução - 20 filtros 5 x 5
- 2ª convolução - 50 filtros 5 x 5 x 20
A saída final desse processo:
Fase 2 - Classificação
Utilizamos a SVM, um modelo conhecido e bem estabelecido.
- SVM é robusta, porém custosa;
A entrada para a SVM é a concatenação dos vetores de características adquiridos pelo processo de aprendizado de representação.
Early-fusion
Late-fusion
Fase 3 - Análise
Verificações são feitas no resultado do algoritmo de votação, e correções necessárias são aplicadas.
A classificação será diretamente relacionada ao quão boa foi a extração de características realizada.
Pontos a considerar
- Inicialização
- Diversidade de dados
- A redução de dimensionalidade
- Diferentes classificadores
https://github.com/Handwritten-Equation-Solver/Handwritten-Equation-Solver