Algorithmique: Les tables de hachage
I
Pourquoi le hachage ?
Les listes (tableaux) sont un mécanisme très puissant pour classer les informations en Python comme dans d'autres langages.
Ceci dit elles ont un gros défaut: Lorsqu'on souhaite lire ce qu'elles contiennent il n'est pas possible d'accéder à un élément dont on ne connaît pas l'indice, en une seule étape.
Il faut parcourir la liste en avançant d'élément en élément jusqu'à trouver celui qu'on recherche. Cela pose des problèmes de performance dès que la liste devient volumineuse.
- Imaginez une liste de 1 000 000 éléments où celui que l'on recherche est tout à la fin...
Pourquoi le hachage ? (2)
Imaginons une liste qui contienne des informations sur des élèves : leur nom, leur âge et leur moyenne. Chaque élève sera représenté par une sous-liste.
Si on veut retrouver les informations sur Luc Doncieux dans la figure suivante, il va falloir parcourir toute la liste pour se rendre compte qu'il était à la fin !

Pourquoi le hachage ? (3)
Bien entendu, si on avait cherché Julien Lefebvre, cela aurait été beaucoup plus rapide puisqu'il est au début de la liste. Néanmoins, pour évaluer l'efficacité d'un algorithme, on doit toujours envisager le pire des cas.
Et le pire, c'est Luc.
Ici, on dit que l'algorithme de recherche d'un élément a une complexité en O(n), car il faut parcourir toute la liste pour retrouver un élément donné, dans le pire des cas où celui-ci est à la fin. Si la liste contient 9 éléments, il faudra 9 itérations au maximum pour retrouver un élément.
Pourquoi le hachage ? (4)
Dans cet exemple, notre liste chaînée ne contient que quatre éléments. L'ordinateur retrouvera Luc Doncieux très rapidement.
Mais imaginez maintenant que celui-ci se trouve à la fin d'une liste contenant 10 000 000 éléments. Ce n'est pas acceptable de devoir parcourir jusqu'à 10 000 000 éléments pour retrouver une information. C'est là que les tables de hachage entrent en jeu.
Tables de hachages et tableaux
Dans un tableau les cases sont identifiées par des numéros qu'on appelle des indices. Le fait de demander à l'ordinateur : « Dis-moi quelles sont les données qui se trouvent à la case "Luc Doncieux" » n'est pas possible dans tous les langages de programmation.
Des langages de programmation comme le Python ou le PHP ont des structures de données qui permettent de retrouver des valeurs en ayant pour "indice" des chaînes de caractères. On les appelle dictionnaires ou tableaux associatifs.
Mais d'autres langage comme C ou C++ sont dépourvus de telles structures.
Quelle structure de données ?
En Algorithmique on essaie de résoudre les problèmes en essayant le plus possible de se passer des "facilités" offertes par des langages de programmation particuliers.
On considèrera donc que les dictionnaires n'existent pas. Notre pseudo code pourra ainsi s'adapter à tous les langages de programmation.
Quelle structure de données ? (2)
Les dictionnaires ?
Quelle structure de données ? (2)
Les dictionnaires ?
Peu généralisables en dehors de langages particuliers (PHP, Python) ou de librairies externes (Java et la classe HashMap). De plus, comment être sûr de la complexité algorithmique des opérations ?
Quelle structure de données ? (2)
Les dictionnaires ?
Peu généralisables en dehors de langages particuliers (PHP, Python) ou de librairies externes (Java et la classe HashMap). De plus, comment être sûr de la complexité algorithmique des opérations ?
Les tableaux, oui mais:
Quelle structure de données ? (2)
Les dictionnaires ?
Peu généralisables en dehors de langages particuliers (PHP, Python) ou de librairies externes (Java et la classe HashMap). De plus, comment être sûr de la complexité algorithmique des opérations ?
Les tableaux, oui mais:
- Si les indices ne sont pas des entiers ?
Quelle structure de données ? (2)
Les dictionnaires ?
Peu généralisables en dehors de langages particuliers (PHP, Python) ou de librairies externes (Java et la classe HashMap). De plus, comment être sûr de la complexité algorithmique des opérations ?
Les tableaux, oui mais:
- Si les indices ne sont pas des entiers ?
- Si les données sont éparpillées ?
Quelle structure de données ? (3)
Les listes ou apparenté ?
- Oui mais il reste ce problème de la recherche séquentielle
Quelle structure de données ? (3)
Les listes ou apparenté ?
- Oui mais il reste ce problème de la recherche séquentielle.
- La recherche dichotomique quant à elle ne marche que pour les listes triées...
En résumé
On cherche une structure de données capable d'organiser des couples de données clé/valeur pour lesquels on souhaite faire des opérations:
- d'ajout
- de recherche
- de suppression (optionnellement)
Et ce, de manière très efficace.
L'exemple de l'annuaire
Problème: Imaginons qu'on veuille créer un annuaire qui permette
de retrouver facilement le numéro de téléphone d'une personne en fonction du nom (on suppose qu’il n’y a pas d’homonymes).
Solution proposée : Avoir un tableau indicé par les noms
(chaînes de caractères) et y stocker le numéro de téléphone.
Difficulté: On se sait pas créer des tableaux indicés par des chaînes de caractères.
Solution: Transformer, à l'aide d'une fonction f chaque nom en nombre et stocker le numéro de téléphone dans un tableau indicé par ces nombres.
f(nom) = ???
Tables de hachage
Une table de hachage est une structure de données qui permet:
- L'association d'une valeur à une clé. Dans l'exemple de l'annuaire les clés sont des noms et les valeurs sont les numéros de téléphone.
- L'accès rapide à la valeur à partir de la clé (comme un tableau).
- L'insertion rapide d'un nouvel élément.
Vocabulaire
- Clé: L'objet de départ. C'est lui dont on cherche la valeur.
- Valeur: L'objet que l'on souhaite stocker.
- Table: La structure dans laquelle sont stockées les paires <clé, valeur> (à des indices).
- Alvéole: Case d'une table de hachage présente à un indice.
- Fonction de hachage: Transforme une clé en indice de tableau.
Application à l'exemple
Dans l'exemple de l'annuaire:
- clé = Nom
- valeur = numéro de téléphone
- fonction de hachage:
h(k) = f(k) mod M
Avec M la capacité de la table et mod l'opération mathématique du modulo.
Ecrire une fonction de hachage
Toute la difficulté consiste à écrire une fonction de hachage correcte. Comment transformer une chaîne de caractères en un nombre unique ?
Tout d'abord, mettons les choses au clair : une table de hachage peut contenir plusieurs dizaines de milliers voire pusieurs centaines de milliers de cases. Cependant, peu importe la taille du tableau, la recherche de l'élément sera aussi rapide.
Ecrire une fonction de hachage (2)
On dit que la complexité de l'accès à une table de hachage est en O(1) car on trouve directement l'élément que l'on recherche.
En effet, la fonction de hachage nous retourne un indice : il suffit de « sauter » directement à la case correspondante du tableau. Plus besoin de parcourir toutes les cases !
Utilisation d'une table de hachage
Imaginons qu'on veuille utiliser la structure des tables de hachage pour stocker 100 noms.
Nous devons écrire une fonction qui, à partir d'un nom, génère un nombre compris entre 0 et 99 (les indices du tableau).
C'est là qu'il faut être inventif. Il existe des méthodes mathématiques très complexes pour « hacher » des données, c'est-à-dire les transformer en nombres.
Utilisation d'une table de hachage (2)
Certains algorithmes comme MD5 et SHA1 sont des fonctions de hachage célèbres, mais nous allons mettre en place des techniques pour écrire nos propres fonctions de hachage.
Utilisation d'une table de hachage (3)
Ici, pour faire simple, on vous propose tout simplement d'additionner les valeurs ASCII de chaque lettre du nom, c'est-à-dire pour Bob faire la somme suivante :
code ascii de B + code ascii de o + code ascii de b
C'est quoi l'ascii ?
Le code ASCII est l'un des plus anciens codes toujours utilisés pour représenter des caractères latins. Il utilise pour chaque caractère une suite de 8 bits qui forment un octet (cf analyse numérique)
- le caractère A est représenté sous la forme d'un octet (suite de 8 bits) ayant pour valeurs: 0 1 0 0 0 0 0 1 en binaire ou 65 en décimal
- le caractère B est représenté sous le forme d'un octet (suite de 8 bits) ayant pour valeurs: 0 1 0 0 0 0 1 0 en binaire ou 66 en décimal
...etc...
C'est quoi l'ascii ? (2)
Bob en codage ASCII donne la suite d'octets suivants:
- 01000010 = B représenté par le code ASCII ayant pour valeur 66
- 01101111 = o représenté par le code ASCII ayant pour valeur 111
- 01100010 = b représenté par le code ASCII ayant pour valeur 98
Utilisation d'une table de hachage (4):
Rappel du problème: On veut stocker 100 prénoms dans une table de hachage qui a capacité de 100 éléments.
On va toutefois avoir un problème avec Bob : La somme de ses caractères ascii dépasse 100 ! Comme notre tableau ne fait que 100 cases, si on s'en tient à ça, on risque de sortir des limites du tableau.
On rappelle que chaque lettre dans la table ASCII peut être numérotée jusqu'à 255. On a donc vite fait de dépasser 100.
Utilisation d'une table de hachage (5):
Pour régler le problème, on peut utiliser l'opérateur modulo %. Il donne le reste de la division.
Si on fait le calcul :
sommelettres % 100… on obtiendra forcément un nombre compris entre 0 et 99.
Par exemple, si la somme fait 3428, le reste de la division par 100 est 28. La fonction de hachage retournera donc 28.
Le modulo est très pratique pour "tourner en rond" parmi un ensemble de valeurs.
Utilisation d'une table de hachage (6):
Grâce à cette fonction de hachage, vous savez donc dans quelle case de votre tableau vous devez placer vos données.
Lorsque vous voudrez y accéder plus tard pour récupérer les données, il suffira de hacher à nouveau le nom de la personne pour retrouver l'indice de la case du tableau où sont stockées ses informations.
Autre exemple de hachage
La numérotation ascii est un exemple parmi d'autres pour représenter les lettres de l'alphabet latin de manière chiffrée mais on aurait pu utiliser une autre technique:
L'ordre ordinal.
Nous allons illustrer cet exemple dans la page suivante.
Autre exemple de hachage (2)
Soit E un ensemble de noms, supposons que la clé est le nom lui-même et que l'on associe à chaque élément x de l'ensemble E, un nombre h(x) compris entre 0 et 8 en procédant comme suit :
- Attribuons aux lettres a, b, c, ..., z leur valeur ordinale respective, soit 1, 2, 3, ..., 26
- Additionnons les valeurs des lettres.
- Ajoutons au nombre obtenu le nombre de lettres composant la clé.
- Calculons le modulo 9 de ce dernier pour obtenir h(x) [0,8]
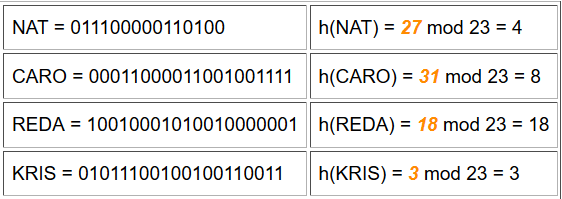
Autre exemple de hachage (3)
Pour l'ensemble E = { nathalie, caroline, arnaud, reda, mathieu, jerome, nicolas }, on obtient les valeurs de hachage suivantes :

En résumé
On peut constater que la restriction de h à E est injective et que l'on peut donc ranger chaque élément x de E dans l'élément d'indice h(x) du tableau.
Si l'on désire ajouter un élément x et que celui-ci présente une valeur de hachage déjà utilisée par un élément y, h n'est plus injective (on aurait x != y et h(x) = h(y)) et l'on dit qu'il y a collision primaire entre x et y.
Valeur de hachage primaire
Pour toute clé x de la collection:
h(x) (valeur de hachage primaire) donne l'indice de x dans le tableau de hachage.
Cela nous permet de le rechercher, l'ajouter ou le supprimer. Le choix de la fonction de hachage est fondamental, celle-ci doit être :
- uniforme: c'est à dire que tous les éléments sont répartis le plus uniformément possible dans le tableau,
- facile et rapide à calculer : le but étant de ne pas affaiblir la méthode par un calcul long et fastidieux,
- Déterministe : renvoyer toujours le même résultat.
A propos des collisions
Quoi qu'il en soit, et aussi performante que soit la fonction de hachage, nous ne pouvons pas éviter les collisions. Dès lors, nous devons savoir les gérer.
Il existe, pour cela, deux classes de méthodes que nous verrons plus tard, les méthodes de résolution des collisions par chaînage (méthodes indirectes) et les méthodes de résolution de collision par calcul (méthodes directes).
Nous verrons la résolution des collisions par la suite...
Fonctions de hachage
Nous allons donner maintenant quelques principes de construction de fonction de hachage basiques. Nous supposerons pour les exemples que les clés sont des mots binaires.
Remarque : L'intérêt pour l'algorithmique est qu'il n'y a pas besoin de fonction intermédiaire pour traduire leur valeur comme par exemple le ferait fonction en python ord() pour l'ascii ou bin() pour la valeur binaire...
Nous devons ensuite réduire les valeurs obtenues à l'intervalle [0,m-1] car notre table de hachage aura une taille de m.
Fonctions de hachage (2)
Pour simplifier, nous utiliserons des caractères codés en binaire sur 5 bits et en progression croissante selon l'ordre ordinal, soit :
Pour obtenir le codage d'un mot on concatène les codages de chacune de ses lettres
Dès lors le but sera de construire la fonction de hachage h suivante:

A = 00001 (1) ; B = 00010 (2) ; C = 00011 (3) ; D = 00100 (4) ; E = 00101 (5)
F = 00110 (6) ; G = 00111 (7) ; H = 01000 (8) ; I = 01001 (9) ; J = 01010 (10)
K = 01011 (11) ; L = 01100 (12) ; M = 01101 (13) ; N = 01110 (14) ; O = 01111 (15)
...
Extraction
Cette méthode consiste à extraire un certains nombre de bits de la chaine de départ. Si on extrait p bits, l'intervalle de travail se ramène à :
[0, 2^p - 1]
Pour l'exemple, effectuons l'extraction des bits 2, 7, 12 et 17 en commençant à gauche et en complétant par des zéros. Cela donne :
Si m = 2^p, le mot obtenu formé des p bits donne directement une valeur d'indice dans le tableau. Problème: L'utilisation partielle d'une clé ne donne pas de bons résultats...

Compression
Dans cette méthode, nous utilisons tous les bits de la représentation que l'on découpe en sous-mots d'un nombre égal de bits égaux, que l'on combine à l'aide d'une opération.
Cette opération c'est le OU exclusif. Pour cet exemple, nous utiliserons des sous-mots de 5 bits, Ce qui donne :
Le problème de cette méthode est de "hacher" de la même manière tous les anagrammes d'une clé, par exemple :


Division
Cette méthode consiste simplement à calculer le reste de la division par m de la valeur de la clé. Supposons que m = 23 et que nous utilisions les valeurs issues du procédé d'extraction pour représenter la clé. Nous obtenons alors :
Cette fonction est très facile à calculer, mais si m est pair, toutes les clés paires (impaires) iront dans des indices pairs (impairs).
La solution consiste à prendre un m premier. Mais là encore, il peut y avoir des phénomènes d'accumulation.
Multiplication (1)
Soit un nombre réel θ, tel que 0 < θ < 1, on construit la fonction de hachage suivante :
- e est la clé de départ (ici un mot binaire).
- x est la valeur obtenue à partir de e en utilisant l'extraction expliquée dans les slides précédents.

Multiplication (2)
Soit un nombre réel θ, tel que 0 < θ < 1, on construit la fonction de hachage suivante :
La valeur obtenue est la partie décimale du produit de x par θ, que l'on multiplie par m (taille du tableau) et dont on garde la partie entière (est-ce clair? 😄).
Ce qui pour θ = 0.5987526325, m=27 et l'utilisation des valeurs d'extraction précédentes des clés, donne :

Multiplication (3)
Rappel: En faisant le modulo d'un nombre par 1 on obtient sa partie décimale.
Avec cette méthode, la taille du tableau est sans importance, mais il faut éviter de prendre des valeurs de θ trop près de 0 ou de 1 pour éviter les accumulations aux extrémités du tableau de hachage.
Les deux valeurs de θ les plus uniformes sont statistiquement:

Conclusion
Il n'existe pas de fonction de hachage universelle. Chaque fonction de hachage doit être adaptée aux données qu'elle doit manipuler et à l'application qui les gère. Nous n'oublierons pas qu'elle doit aussi être uniforme et rapide.