Lambda Architecure
Origins
- Nathan Marz
- formerly of Twitter and Backtype
- creator of Storm, Cascalog and ElephantDB
- detailed in Big Data book

Requirements
- fault-tolerant of hardware failures and human error
- support multiple use cases that require low-latency queries as well as updates
- linear scale out
- extensible -- can accommodate new features easily
Definitions
- latency - the amount of time it takes for a request to be responded to
- information - collection of knowledge relevant to your system
- data - information that cannot be derived from anything else -- raw, immutable, perpetual
- view - information derived from the data
- queries - questions you ask of your data
- master data set - source of truth, cannot withstand corruption
- semantic normalization - process of reshaping free-form information into a structural form of data
- schema - function that takes a piece of data and determines if it is valid or not
Fact
- atomic
- time coded, true as-of this time code
- uniquely identifiable
- identifiers are used to weed out duplicate facts
- could be a random identifier
- could be a content-addressable identifier, SHA or MD5
CAP Theorem
- also known as Brewer's Theorem
- in the face of a network partition
- a distributed system be either
- available
- or consistent
- not both
Compatible
- backwards - newer code can read data generated by older code
- forwards - older code can read data generated by newer code
- Apache Avro is a data codec good at versioning
{
"type": "record",
"name": "User",
"namespace": "avro.example",
"doc": "http://docs.example.com/",
"aliases": ["Logan", "Devan"],
"fields": [
{"name": "nullValue", "type": "null", "doc": "some-pointer", "default": null },
{"name": "booleanValue", "type": "boolean", "doc": "some-pointer", "default": true },
{"name": "intValue", "type": "int", "doc": "some-pointer", "default": 10 },
{"name": "longValue", "type": "long", "doc": "some-pointer", "default": 100 },
{"name": "floatValue", "type": "float", "doc": "some-pointer", "default": 1.0 },
{"name": "doubleValue", "type": "double", "doc": "some-pointer", "default": 2.0 },
{"name": "byteValue", "type": "bytes", "doc": "some-pointer", "default": "\uFFFF" },
{"name": "stringValue", "type": "string", "doc": "some-pointer", "default": "Zuul" }
]
}The Idea
- extremely simple
- batch view = function( all data )
- real-time view = function( real-time view, new data )
- query = function( batch view, real-time view )
- all the data is run through batch computations to create new views of the data
- batch views are high latency (have to wait for the batch process to complete)
- new incoming data is run through computations to produce views that are quickly available
- queries are run against both views
- information in the real-time views is replaced with information contained in the batch views
- rinse and repeat
The Idea
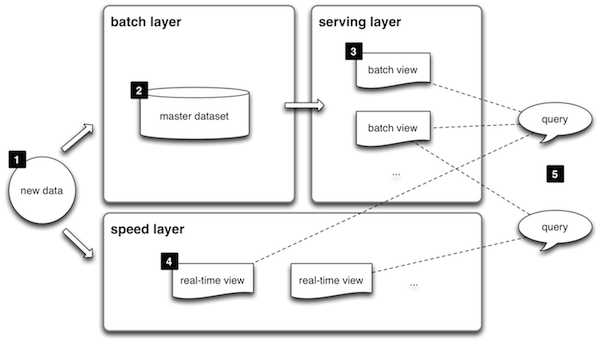
Batch Layer
- slow to compute since the functions are applied to the master data set
- results are likely to be more accurate than those calculated in the Speed Layer
- prefers availability over consistency
- both full and incremental computation can be used
- full computation will correct defects in an algorithm from a prior run
Speed Layer
- fast to compute since the functions are applied to new, incoming data only
- results are likely to be less accurate than those calculated in the Batch Layer
- approximation algorithms are often used to increase the speed of the calculations
- temporary errors will be corrected when the Batch Layer runs against the new data
Serving Layer
- contains the views generated by the Batch Layer
- may apply multi-view "joins" to gather the necessary information
- prefers availability over consistency
- the views are often "binned" by date ranges, such as year, month, week, day, hour and minute
- the Serving Layer understands how the views are structured and knows how use combine the appropriate views to fulfill the query
- allows for reuse of views to meet new query requirements
Implementation
- store data in a distributed file system
- use vertical partitioning to make it easier to locate data
- year/month/day/hour
- one folder per day
- 2015/12/31/23/data.avro
- use Avro as the codec allows the format to evolve over time -- backwards compatibility
Implementation
- ingest new data
- normalize the data
- remove duplicates
- create batch views
- JCascalog is recommended for the Batch Layer due to its composability
- Storm for the Speed Layer since it is a real-time stream processor
- ElephantDB for the Serving Layer
- Spark Streaming (why?)