Unified Log Stream
Ron Kurr
06/18/2016
What/Why/How
We'll be examining the notion of designing systems around a distributed, unified log stream. The concept isn't new and is gaining traction as enabling technologies mature and solutions become increasingly complex. We'll define terms, provide an overview of the concepts and explore a possible application.
Source Material



Definition
- Event: an immutable record of something that has happened. It is a historical fact that cannot be changed.
- Raw Events: immutable facts and are the source of truth.
Kirk fired phasers at target designate Zulu on Stardate 102435.4
Definition
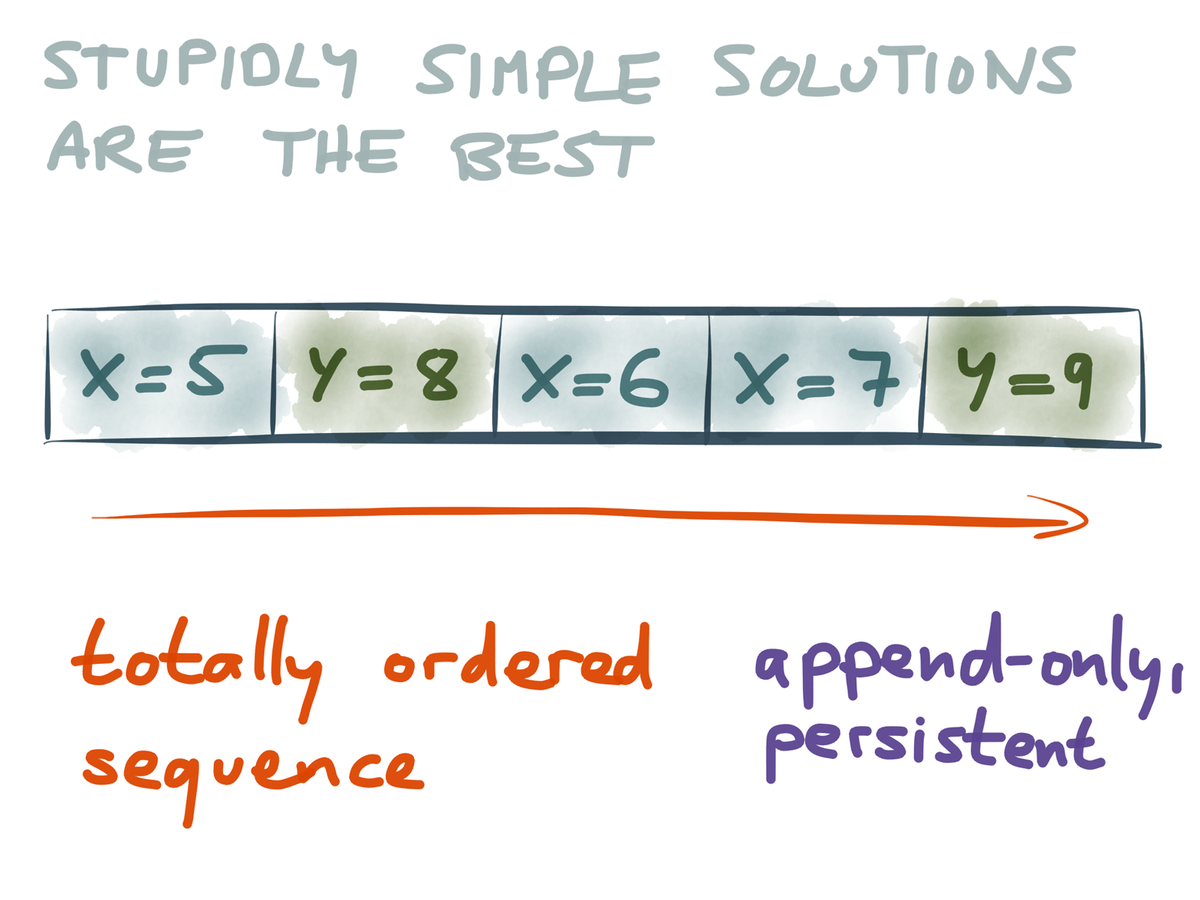
- Event Log: append-only fixed sequence of immutable events
- Event Stream: un-terminated succession of individual events.
- Streaming Aggregation: multiple consumers evaluate the same stream of events.
- Command: imperative, usually implies a state change
Update user Skywalker's e-mail address to luke@disney.com
Definition
- Aggregated Data: derived, denormalized information.
- Unified in this context means using one technology to manage and process the stream, such as Kafka or Kinesis.
- Distributed means running across a cluster of machines.
- Ordered means that events are stored using a sequential ID unique to the particular stream.
What If
What if we built solutions based on an append-only stream of immutable events?
Possibilities include:
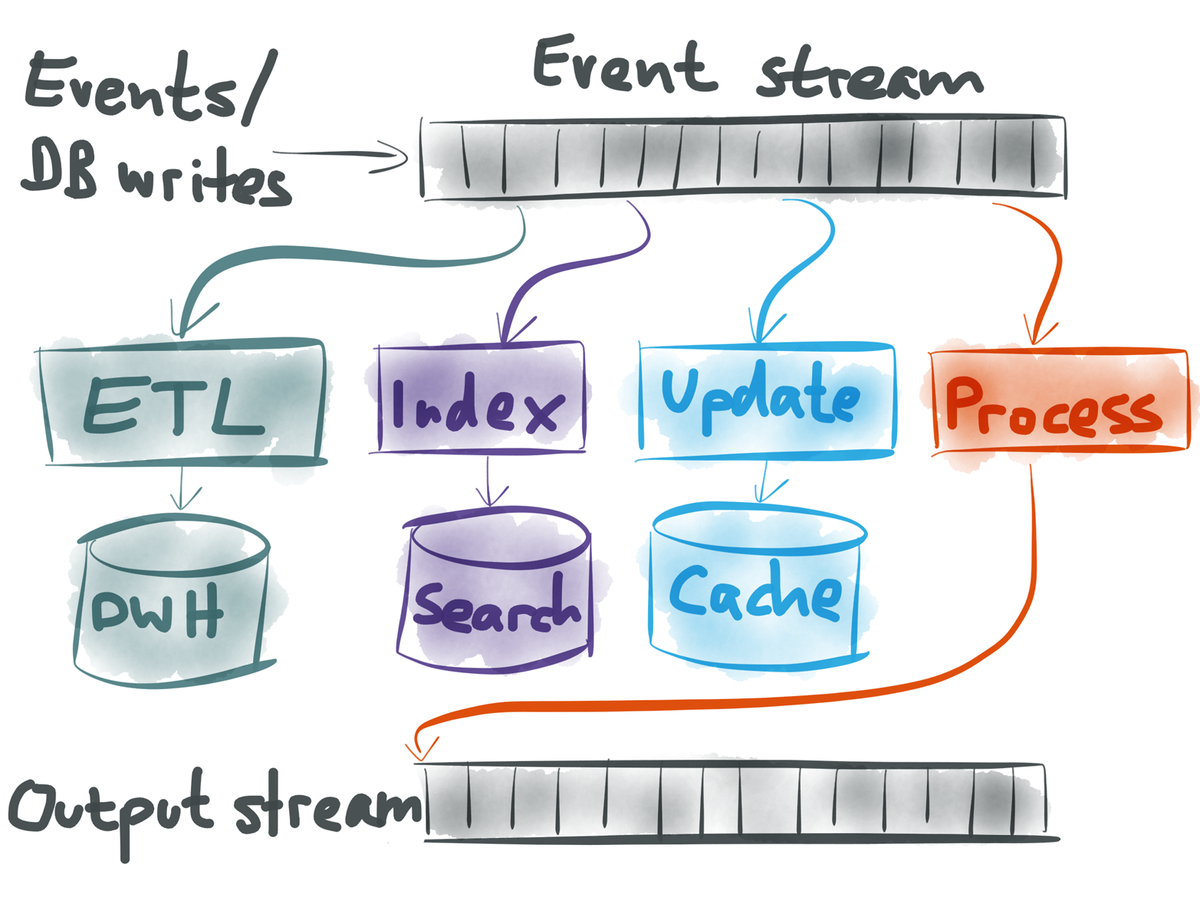
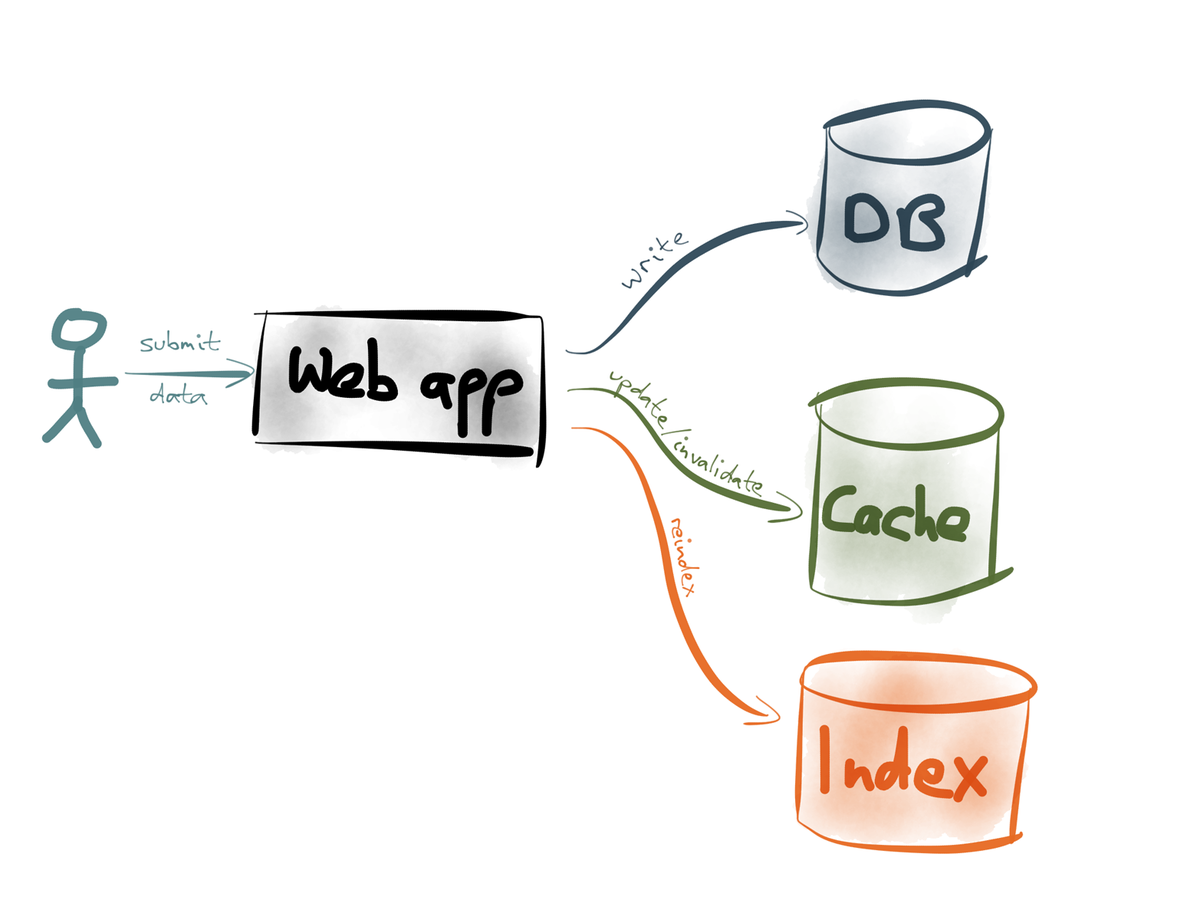
- transformation of raw events
- update search indexes
- refill/invalidate caches
- create a new output stream for use as input elsewhere
Benefits include:
- loose coupling
- increased read/write performance
- scalability
- flexibility
- auditing/error recovery
Use an Event Log
- Event Logs are already being used in database storage engines, database replication engines and distributed consensus algorithms.
- Apache Kafka and Amazon Kinesis are examples of distributed logs.
- AMQP can deliver messages out of order due to the way acks and redelivery works but Kafka and Kinesis maintain ordering. Use AMQP when ordering does not matter, such as when processing a Command.
Use an Event Log
- Only append events to the log and let consumers process events at their own pace.
- Consumers keep an index so that they can pick up where they left off in the event of a crash
- Can use the log to bootstrap a cache, index or an alternate system (think blue/green deployments)
Use an Event Log
Benefits of Event Streams
- fresher insights
- single version of truth
- faster reactions
- simpler architectures
- low latency reads
- multiple consumers reading at their own pace
Advice
- accrete events from disparate sources
- store events in a unified, distributed log
- perform data processing off of the stream
- systems should communicate via the log unless latency or transaction concerns are present
Advantages to Log Communication
- single version of truth
- truth is upstream of data warehouse
- point-to-point communications are mostly unraveled -- we no longer need them
Application of Events
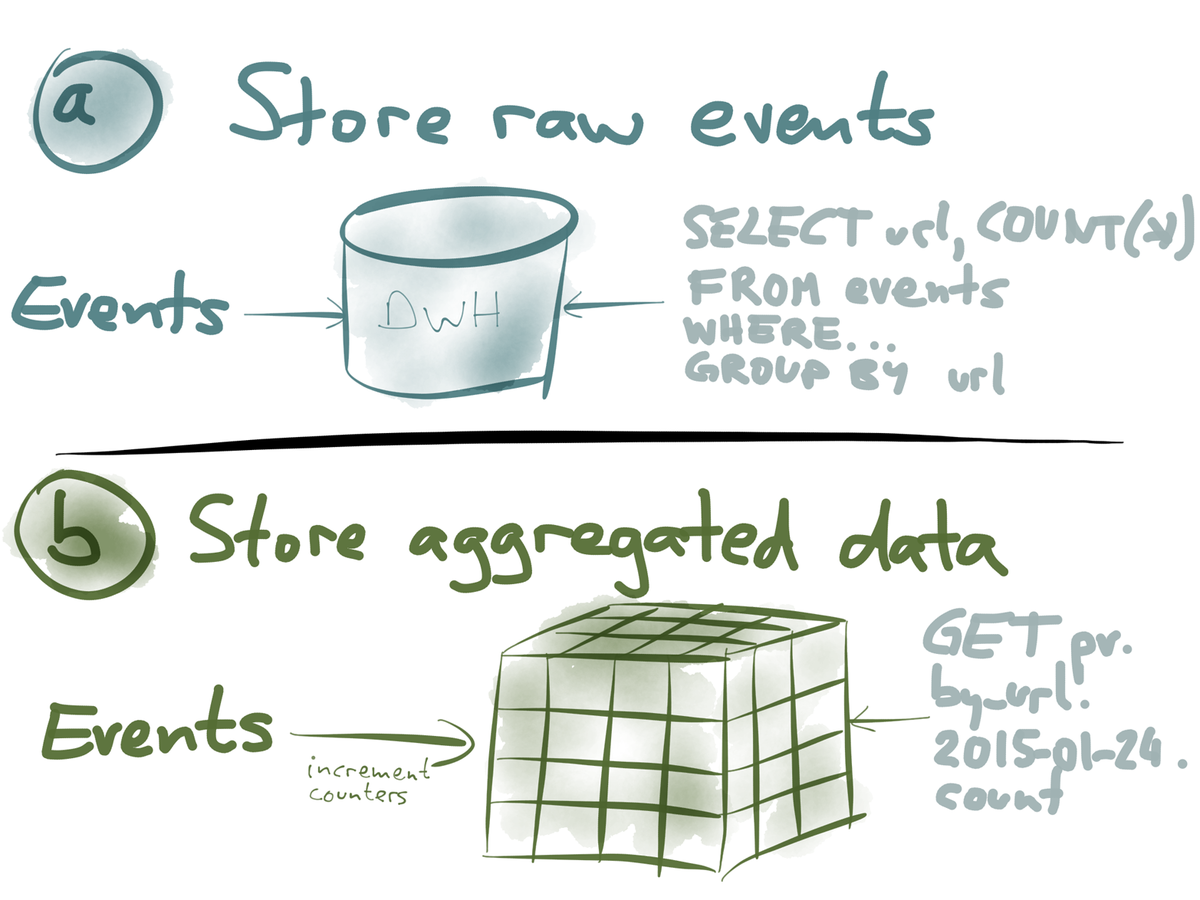
Option A: store raw event data. Great for off-line, high latency processing. You are free to ask almost any question you can imagine. Processing power required to answer questions is large so the number of concurrent questions you can ask is limited.
Option B: aggregate the data immediately. Great for low-latency queries, alerting and monitoring. Questions that can be asked are limited but required processing power is low so many concurrent questions can be handled.
Application of Events
All Writes Through The Log
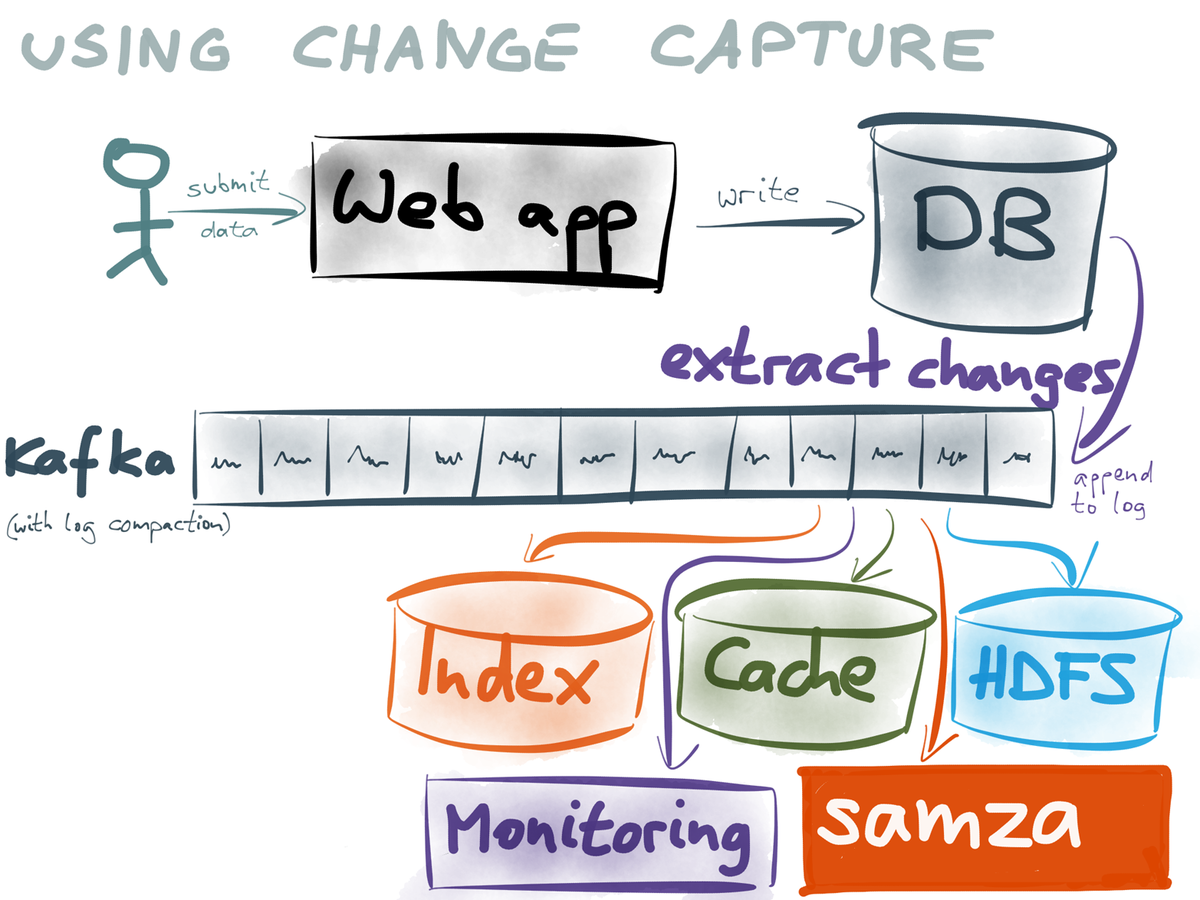
- Change Data Capture (CDC): uses a conventional database but transforms inserts, updates and deletes into events.
- Change Data Capture is for use in existing systems which cannot change.
- Tools like Kafka Connect exist and query the database to obtain the changes.
- Tools also exist that transform a database snapshot into a stream of events.
- Currently a hard problem to solve but some databases are based strictly on an event log.
- Mongo Connector is an MongoDB Op Log tail that can emit changes to Solr, Elasticsearch and MongoDB.
All Writes Through The Log
Change Data Capture
Definitions
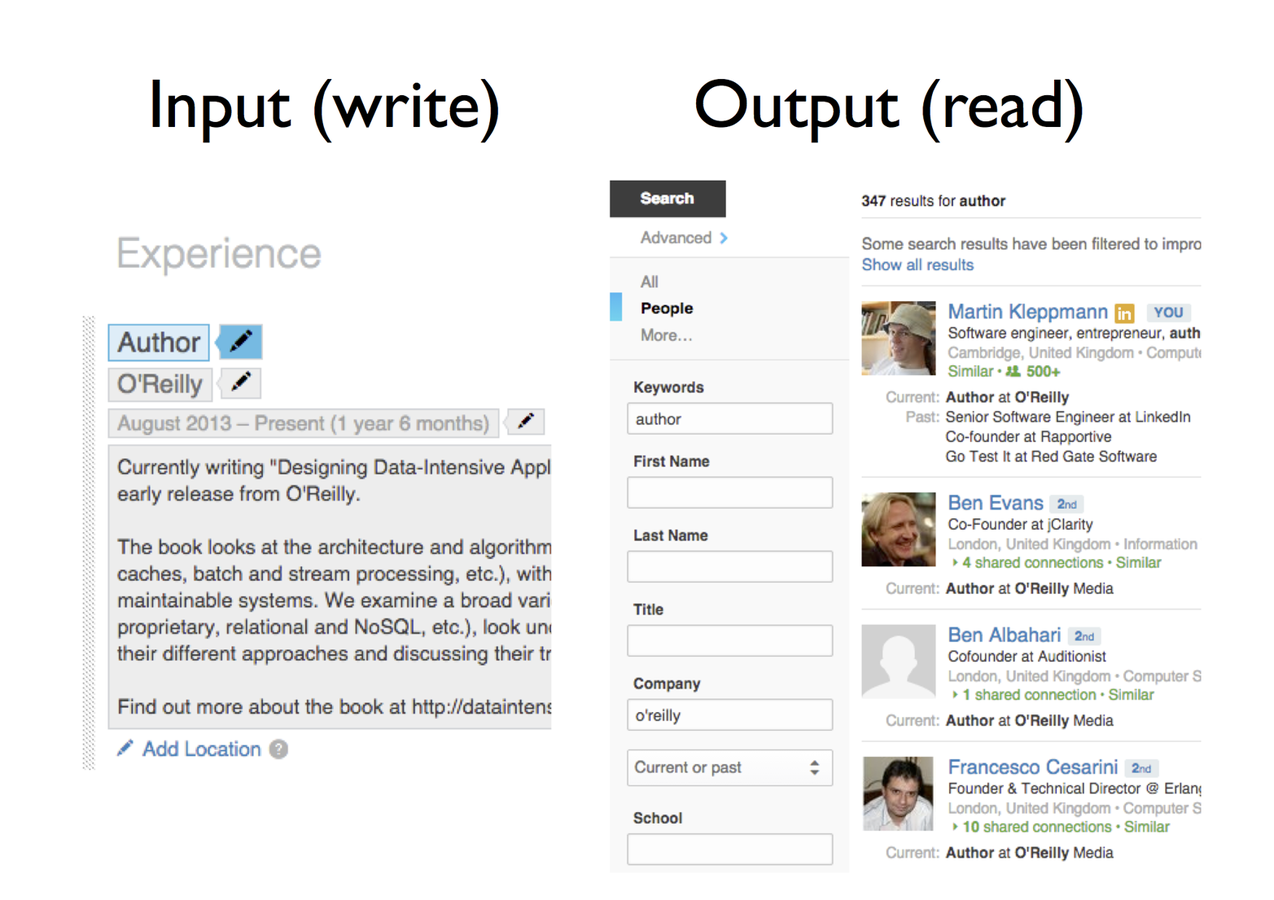
- Materialized View: a pre-computed alternative form of the data, usually denormalized and comprised of multiple sources. Brand new views can be built by consuming events since the beginning of time.
- A search index is a form of denormalized data. SQL encourages normalized writes to minimize the effects of changes but denormalized reads are often faster.
- Data Integration: making sure the data ends up in the right places.
Definitions
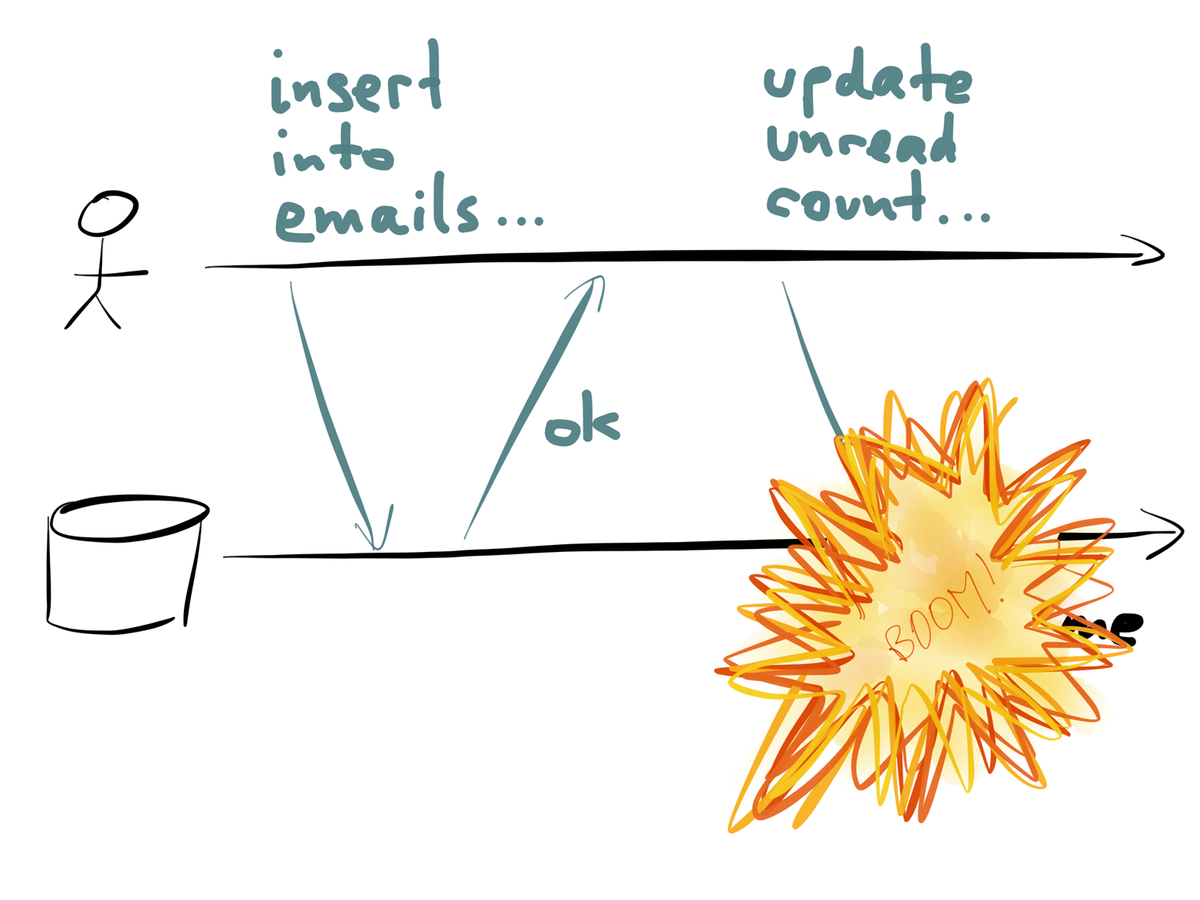
- Dual Writes: the application is responsible for writing data to all the downstream interested parties.
- In Dual Writes, you can have issues with race conditions, transforming to alternate forms and inconsistent data when one of the writes fails.
-
The same data can take different forms and must be handled:
- denormalized views
- indexes
- caching
- aggregations
Dual Writes
Dual Writes
Log-centric Architecture
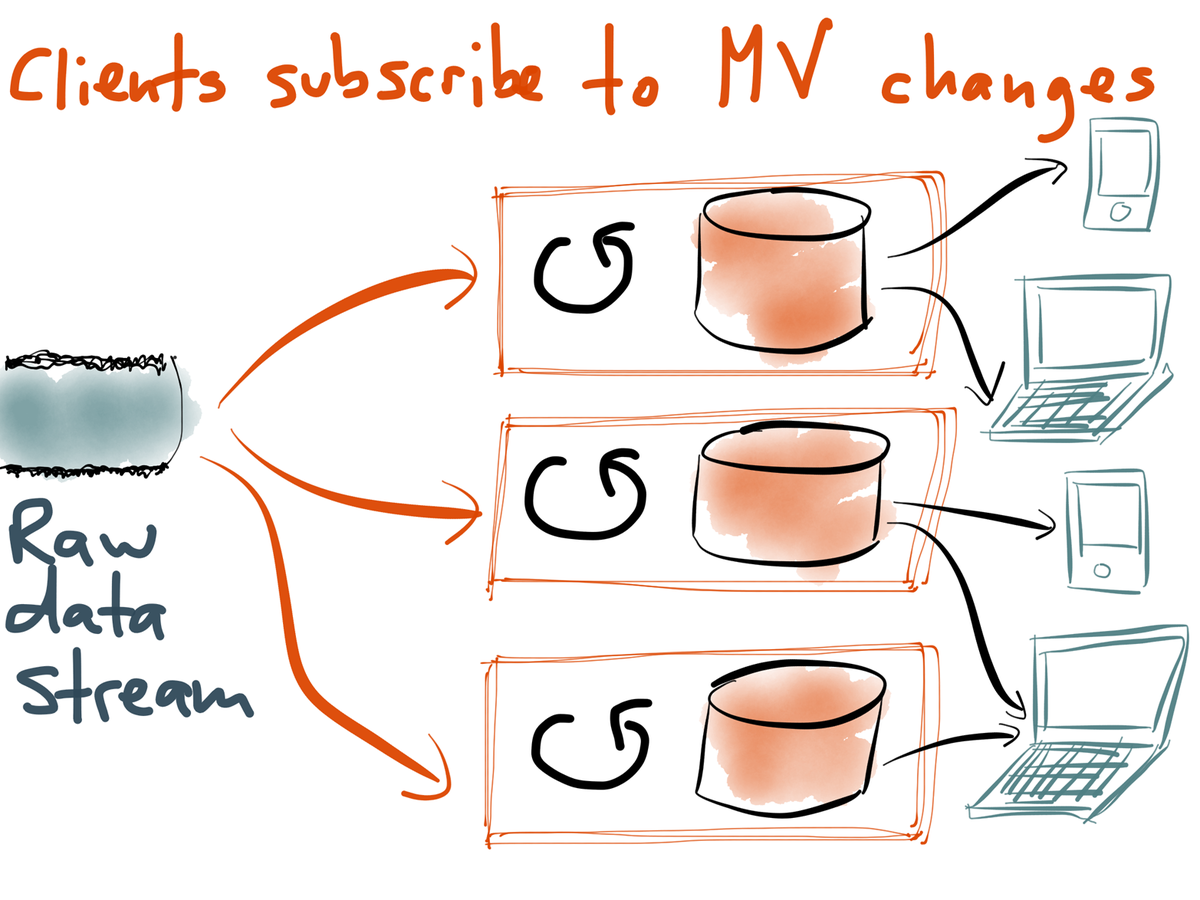
- UI can subscribe to materialized view changes via Web Sockets or Server Sent events
- RethinkDB is one of a few database that can send chainges directly to the UI
- Instead of request/reply, think subscribe/notify
Definitions
- Event Sourcing: constructing current state by evaluating past events. Every write is recorded as an immutable event.
- CQRS: splits the read form of the database from the write form.
- Often the shape of the data optimal for reads is different from the shape of the data optimal for writes.
- UI Button = raw event (database write)
- UI Screen = aggregated data (database read)
Log-centric Architecture
Log-centric Architecture
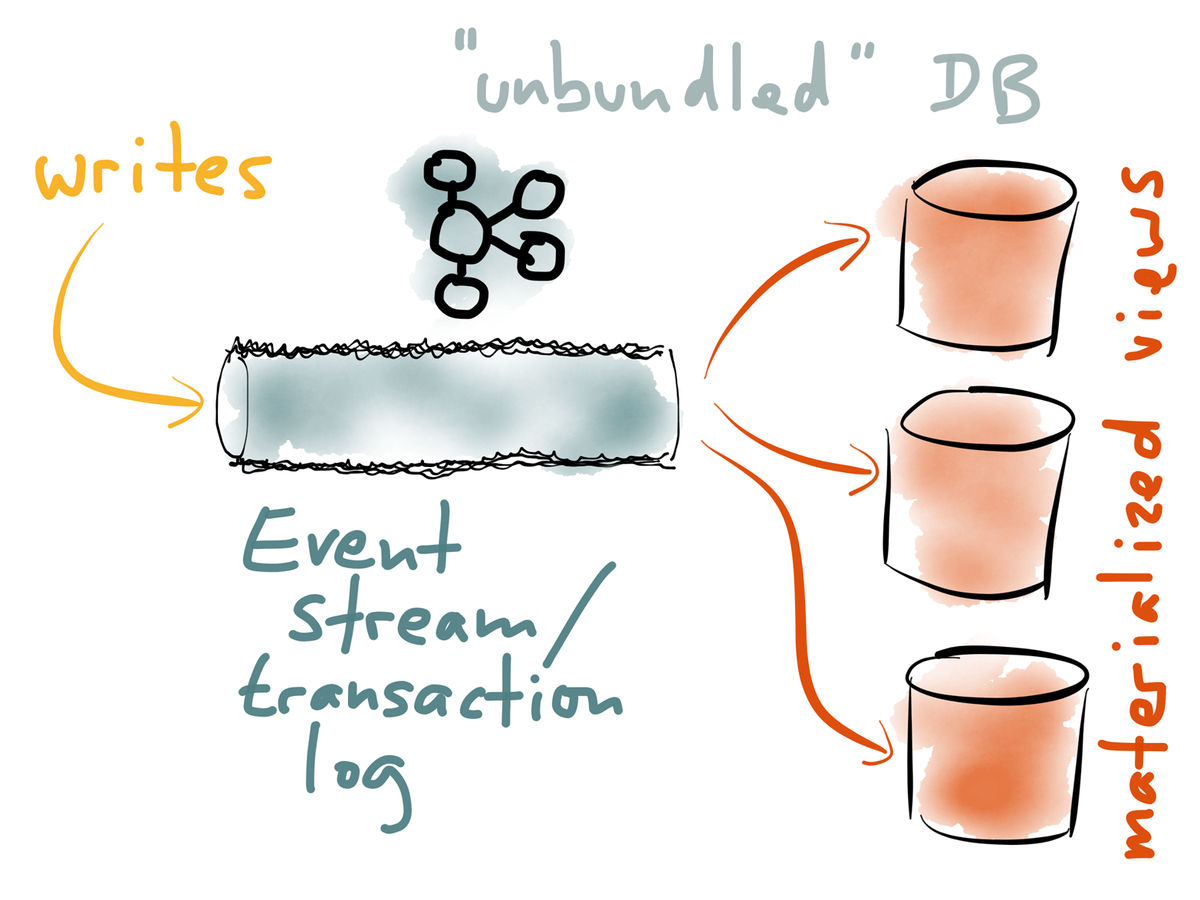
Log-centric Architecture
Advice
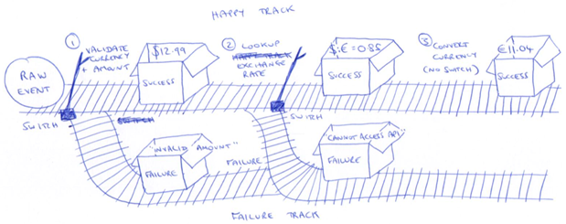
Read from one stream and write to another, either the happy path stream or the failure stream. Since we are using events and streams for both normal and failure processing, existing tooling still apply.
At 2015-07-03T12:01:35Z , in our production environment, SimpleEnricher v1 failed to enrich InboundEvent 428 because it failed Avro schema validation.
Instead of throwing an exception, return a failure object.
Railway Oriented Processing
- happy path becomes happy track
- sad path becomes failure track
- defer expensive operations until later in the sequence
- let cheap validations go first
Railway Oriented Processing
Benefits of ROP
- composes failures and still fails fast
- existing stream tooling still works
- possibility of retrying failed operations
- success type can change between steps
- failure type must remain the same
- make sure to flatten the final failure result because nested objects are a pain to deal with
Implementing ROP
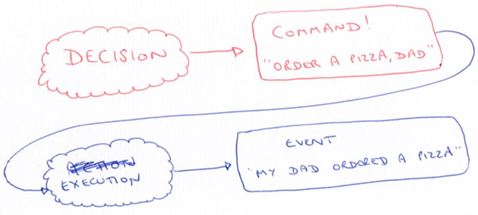
- Command: instruction to be performed in the future
- Event: something that has happened in the past
- execution of a Command results in an Event
- use Avro to encode your Commands and Events
- Commands can have priority
Implementing ROP
- make a decision
- emit the command
- execute the command
- emit event
The separation of concerns makes it easier to test. You can have one process make the decision and write to the command stream and another process that consumes the command and runs them.
Implementing ROP
Command Processing
- Slow Commands can be copied to a queue and run in parallel
- Each Priority Command gets its own executor, running independent of the lower priority Commands
- Can have a Command hierarchy (taxonomy) to help categorize and route Commands
Command Processing
Command Should Be:
- shrink wrapped - contain everything needed to run the command
- fully baked - exactly define what is to be performed. The business rules should have already been applied.
Command Processing
- a command executor could be general purpose
- a command stream allows running an experimental version alongside a production version
- one stream per command type
- one command stream and each command contains a mime type header
- mime type with priority based streams
Error Handling
- Terminate the job if an unrecoverable error is encountered during start up or
- a novel error is encountered during processing
- A novel error is one you haven't seen before.
Unrecoverable but expected errors are handled by:
- out-of-band failure path
- entry contains reason for failure in a well structured form
- entry must contain original input data so we can replay if necessary
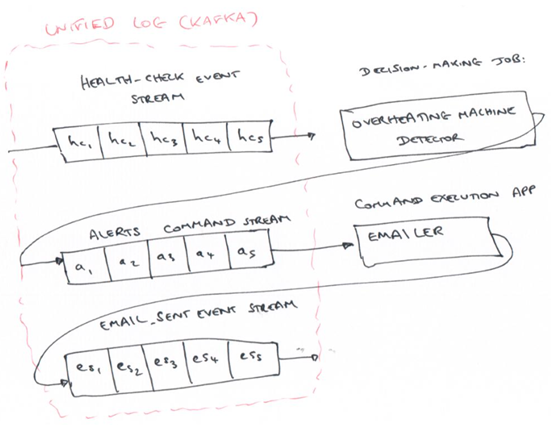
Definition
Apache Kafka: distributed event log
Apache Samza: a stream processing framework that works well with Kafka
Actor frameworks, like Akka, use immutable events to control concurrency. Reactive programming brings event streams to the UI.
RabbitMQ
The AMQP protocol does not guarantee ordering so RabbitMQ is not appropriate as an event log.
put rabbit ordering image here
Challenge
Integrity Check: reserving a username
One Solution:
- username claimed event generated
- consumer does the validation and writes either a success or failure event to the registrations stream
- system that issued the claim event watches the registrations stream and reacts appropriately
Another Solution: assume success, correct and apologize afterwards
Uniform Event Form
- composability requires a uniform interface
- use Apache Avro as your storage format because of its excellent schema support
Add Avro example
Idea
Most distributed logs and messaging systems provide at-least-once semantics which means your system has to deal with duplicates. Maybe store the event id in the database along with the data and do a conditional update only if the event has not been seen already.
Events should have an "effective date" fields which can be used to reorder history when synthetic events are injected into the stream to compensate for some sort of bad data or defect in the code.
Benefits
- only a limited window of events are held, typically a week, and are archived to S3
Use Cases
- customer feedback loops
- holistic system monitoring
- hot swapping application versions
Advice
- Send different events to different streams.
- Stream is append-only
Advice
Describe events using subject-verb-object convention.
Shopper viewed a product at time X.
- subject is Shopper
- verb is viewed
- direct object is product
Log implementations store raw bytes and do not care about the event format.
Example
{
"event": "shopper_viewed_product",
"shopper": {
"id": 1234,
"name": "Jane"
}
"product": {
"id": 456,
"name": "iPad Pro"
}
"timestamp": "2015-07-03T12:01:035Z"
}Another way to look at it:
- meta-data (event type & timestamp)
- business entities (shopper & product)
Implementation
- In Kafka a stream is a Topic
- In RabbitMQ, messages that are read are gone forever
Definition
Event Stream Processing: watching one stream and transforming it into another stream
Single Event Processing: a single event results in one or more data points or events.
Multiple Event Processing: multiple events collectively produce one or more data points or events.
Examples
- validating events (SEP)
- enriching events (SEP)
- filtering events (SEP)
- aggregations (MEP)
- pattern matching (MEP)
- sorting (MEP)
Multi-Event Processing
- stateful stream processing
- usually use a framework, such as Samza
- state located in-process memory, local store or remote store
Definition
Processing Window: bounding the continuous stream, usually by time or count.
Streams are divided into Shards or Partitions.
A Shard Key is used to direct an event to a particular Shard. A Shard Key should use a property available on all events and is evenly distributed.
Implementation (Kinesis)
- Uses Shards where Kafka uses Topics
- Kinesis Streams consist of Shards where Kafka Topics are made of Partitions.
- 10 shards per region
- read 10 mb of data per minute per shard
- 5 read transactions per second
- per shard, write 1 mb per per minute up to 1,000 records per second
- 24 hour horizon after which events get dropped
- can pay to have the horizon extended to 7 days
Implementation (Kinesis)
- AWS CLI
- AWS SDK
- AWS KCL (Kinesis Client Library)
- AWS Lambda
- Apache Storm
- Apache Spark
Consumer Options:
Definitions
Resilience: resistant to failure.
Reprocessing: replay the entire stream.
Refinement: transformation due to:
- late arriving data
- approximations
- framework limitations
Advice
Archive the rawest events possible as far upstream as possible.
- Amazon S3
- Azure Blob Storage
- HDFS
- OpenStack Swift
- Riak Storage
- Tachyon
- Google Cloud Storage
Archiving Tools
- Camus
- Flafka
- Bifrost
- Secor
- Kinesis-S3
- Amazon Kinesis Firehose
Batch Processing
- Disco
- Apache Flink
- Apache Hadoop
- Apache Spark
- Amazon Elastic Map Reduce
Batch processing expects a terminated set of records.
Failure Object Implementation
Book used Scalaz but it looks a lot like the functional Either object where the instance can contain either the result or the failure, not both. The failure object needs to be composable and "flattened" so you don't get lists of lists of lists. Use a convenience routine that can combine a stream of Eithers based whether or not a failure is in the chain.
code example
Analytics On Read
- store first, ask questions later
- high latency
- support few users
- less available
Analytics On Write
- pre-calculate answers to questions
- low latency
- support lots of users
- highly available
AWS Lambda
- expected volatility should be modeled using eager joins (denormalized)
- Lambda is a micro-batch framework -- you get a list of events to work on
- Can optimize by processing the whole batch and then storing state remotely. Groovy inject()?
- DynamoDB supports conditional writes to help deal with duplicate messages
Apache Kafka
- messages are uninterpreted bytes which contain a key (bytes) that is used to route the message to a particular partition (shard)
- messages are written in batches
- use Apache Avro to encode messages
- a Topic is similar to a database table or folder on a file system
- a Topic is sub-divided into Partitions (shards)
- ordering is only guaranteed within a Partition (shard)
- producers write to a Topic
Apache Kafka
- consumers read from 1 or more Partitions (shards)
- consumers read at their own pace
- a Consumer Group is a collection of consumers that work together to consume all messages of a Topic
- Kafka ensures that only one consumer from the group is responsible for a Partition (shard)
- message retention is specified by time or disk usage
- use sophisticated clustering technology
- can send messages either synchronously or asynchronously
- Avro is good with dealing with schema changes but there are limits to what it can handle
Apache Kafka
- use a schema registry instead of embedding the schema
- no point in having more consumers in a Consumer Group than there are Partitions (shards)
- use multiple Consumer Groups if you need multiple readers of a Partition
- rebalances due to a crash are a big deal
- readers can acknowledge either synchronously or asynchronously
- readers poll at their own pace
- Kafka has built in integration with Avro
- there are connections to get data in and out of Kafka -- PostgreSQL for example