Streams para MUITOS dados
Ronie Uliana | @ronie
Sobre o que vou falar?
Nosso experimento com uma arquitetura distribuída para processar um grande volume de dados.
E daí?
O resultado foi muito bom,
e talvez a experiência dê ideias interessantes.
Quem sou eu?
Meu nome é

Ronie
Escovando bits desde "faz tempo" (~1990)
O que faço?
- Arquiteto de Software
- Cientista de Dados Aprendiz :P
- co-fundador do falecido RubyOnBr
Trabalho na VAGAS.com
Empresa de RH
TECNOLOGIA
#NOBOSS
Não temos chefes
"Radicalmente Horizontal"
Raul Seixas & Papai Noel :p
Sidney Monreal & Mário Kaphan ^_^

Fundadores e ótimos amigos!
Nosso negócio é...
Empresas encontrando as melhores pessoas,
Pessoas encontrando as melhores empresas.
Alguns de nossos números
- Cerca de 10 Milhões de currículos
- 3k+ empresas clientes
-
Trafego respeitável!
- 150 milhões de pageviews no mês
- 400 mil visitantes únicos por dia
- 6 milhões de visitantes únicos por mês
- ~3 TB de dados e mais de 80k tabelas
Nós construímos algo muito interessante...
...processando esses milhões de dados.
vagas.com/mapa-de-carreiras
Panorama do Mercado de Trabalho
A parte interessante
Não é o opinião de algum especialista.
É o que as pessoas escrevem.
10.000.000
currículos
É muita informação
Mas é Big Data?
Não importa...
É mais do que cabe na memória da minha máquina >_<
É mais do que minha paciência aguenta esperar :p
O que precisamos,
na real?
- Uma tática para usar pouca memória (Streams)
- Escalonamento (Comunicação interprocessos)
- Poder usar ferramentas prontas (R, Python, ?)
- Trocar partes facilmente (Componentes)
Usamos o S.O. como parte do sistema
Scheduler, Processos, Pipes, Sockets
"Pipes and Filters"
Como?
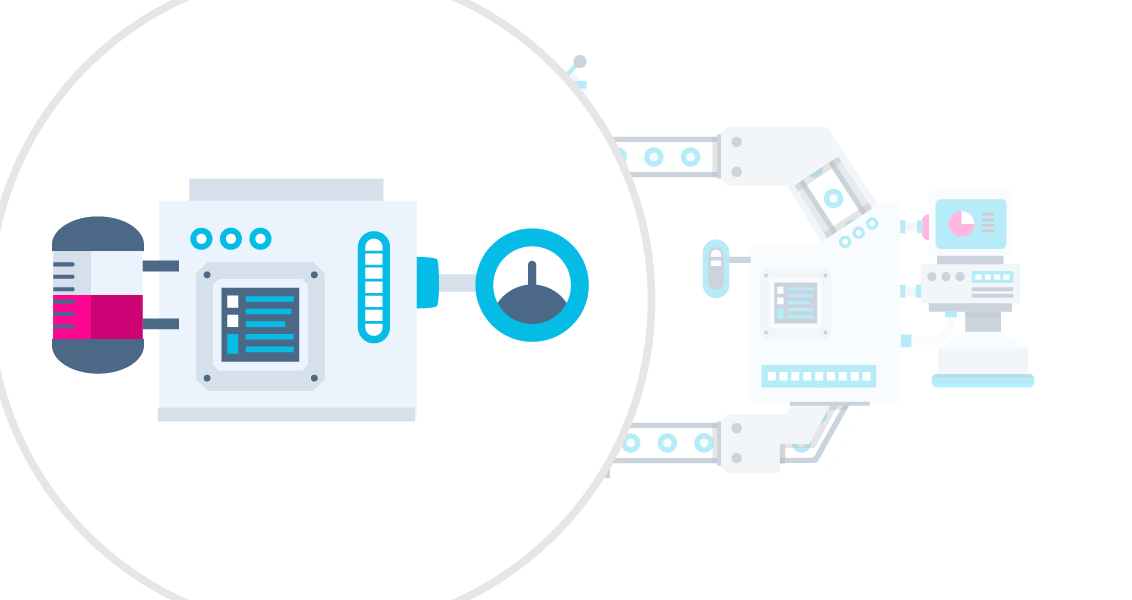
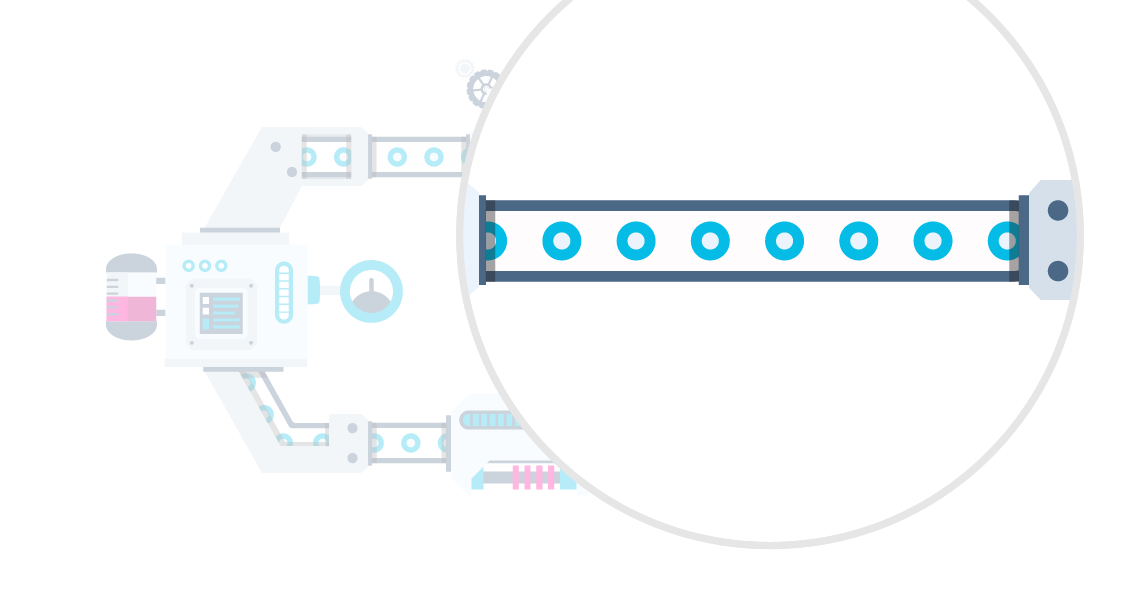
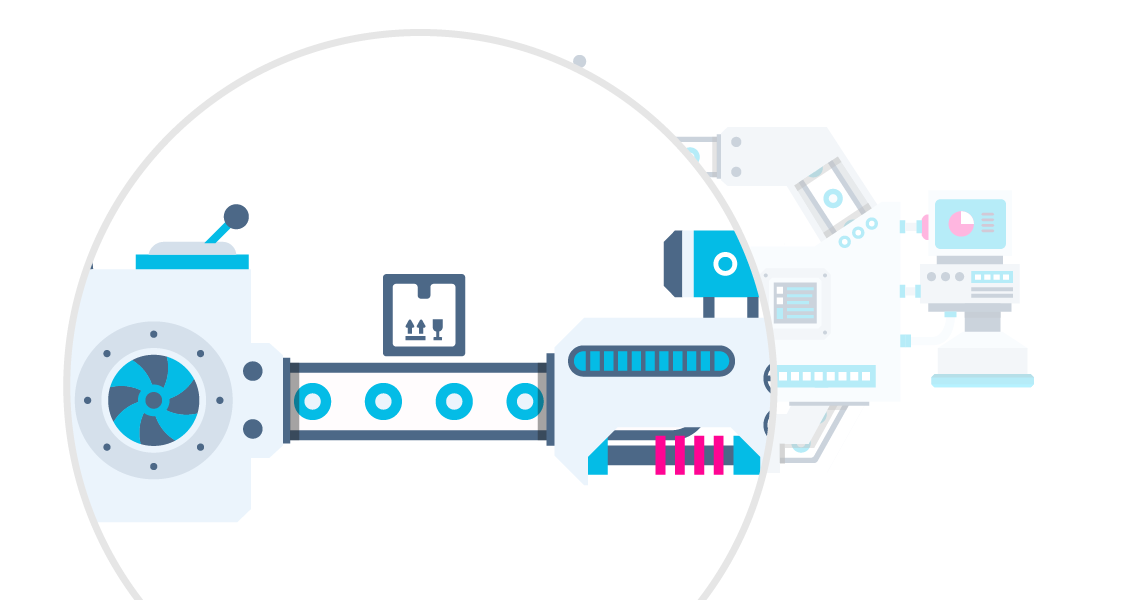
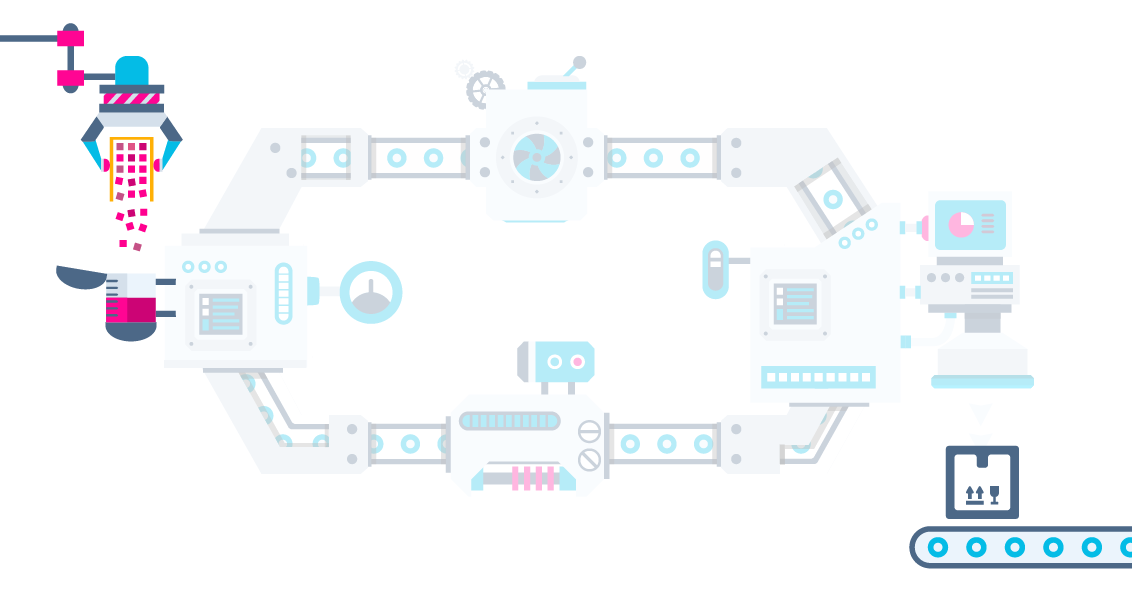
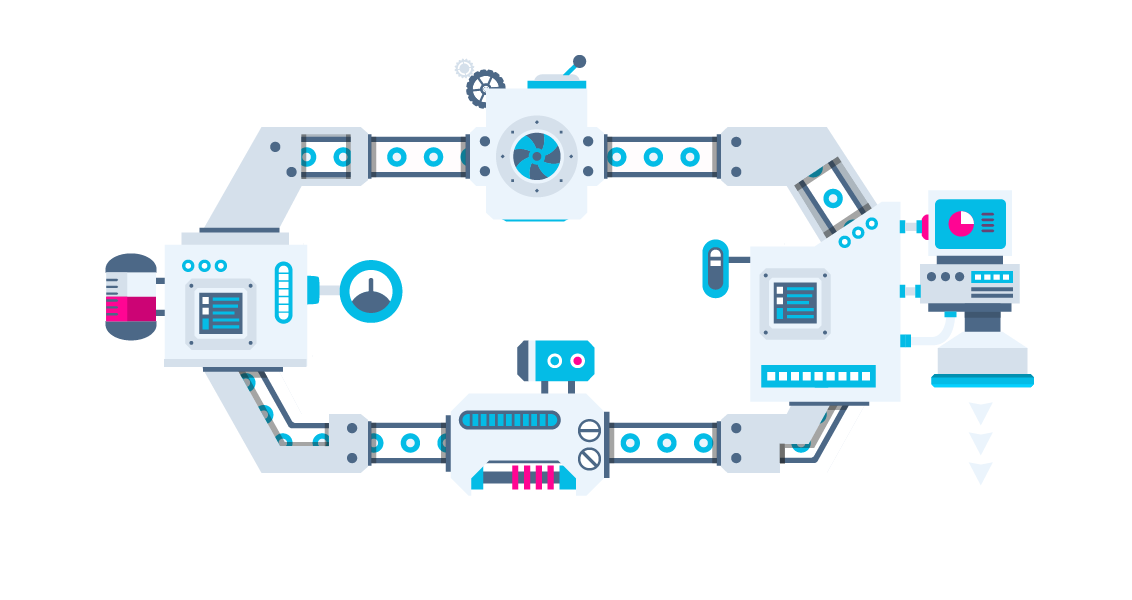
Orquestrador
github.com/VAGAScom/deadly_serious
Só para facilitar o trabalho ^_^
Os resultados foram muito bons
Tempo?
6 horas de processamento em um i7 (8 cores) 16Gb RAM
Salários: ~6.000.000 salários x bootstrap(1.000)
=
~6.000.000.000 operações
Memória?
Ruby 2.0: Copy-on-Write Memory on Fork
Varia de acordo com o tamanho da mensagem
Maior nos acumuladores (como cálculo de TF-IDF)
No geral, muito baixa ^_^
Escalonamento?
Cada componente:
...roda no seu próprio tempo
...pode habitar outras máquinas
Raras as situações de deadlock
(peguei só uma até agora)
Bem simples
Ferramentas prontas?
Dá para usar qualquer coisa que leia e grave em arquivos
Qualquer linguagem
Qualquer comando linux
Qualquer programa (MCL, por exemplo)
O que for necessário \o/
Trocar partes facilmente?
Qualquer componente pode ser substituído
Qualquer "subpipeline" pode ser substituída
Tranquilo evoluir e experimentar
Bonus track
Muito fácil testar cada componente
Fácil processar "por partes"
Nem tudo
são flores =/
- "Sort" é importante
- Sobram zumbis em alguns crashs (my bad)
- Difícil testar o "montador de pipelines"
- "Freezes" são um porre >_<
- Adicionar mais um campo (e preservá-lo)
- Overhead na serialização e desserialização
O que dá para levar disso?
Duas fontes
Flow Based Programming

http://www.jpaulmorrison.com/fbp/
The Unix Philosophy
"This is the Unix philosophy: Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface." - Doug McIlroy
Command-line tools can be 235x faster
than your Hadoop cluster
"...often people use Hadoop and other so-called Big Data (tm) tools for real-world processing and analysis jobs that can be done faster with simpler tools and different techniques."
http://aadrake.com/
command-line-tools-can-be-235x-faster-than-your-hadoop-cluster.html
Nós criamos sistemas complexos demais
>_<
Obrigado!
Se tiver dúvidas, perguntas, vontade de trabalhar conosco ou só quiser trocar uma idéia:
Ronie Uliana
@ronie | +RonieUliana
ronie.uliana@vagas.com.br