Interim Demonstration
Rory Powell - 40081529
7th December 2015

Project Supervisor: Professor Weiru Liu
Technical Advisor: Ryan McConville
Introduction
What is it?
-
Graph mining the block chain
- The public transaction ledger of all bitcoin transactions
Why?
-
For community detection and analysis
- Transactions made using bitcoin are anonymous, only a public id is exposed
How?
- Querying an existing block chain data set
- The results are plotted as nodes on a graph and their relationships highlighted
Method
The data set (a collection of hexadecimal files) is parsed into a usable format using bitcoinj
A java library for handling bitcoin

As the data set is being parsed, the inputs and outputs of each transaction are extracted and written to disk in the form of a CSV file

Finally the CSV file is loaded in Gephi and manipulated as desired to highlight the communities present
Challenges Faced
Obtaining a data set is not as straightforward as it seems, I had to use a bitcoin wallet that pulled down 5 years of history over a peer to peer network
As it turns out, that history is huge. Parsing the data set into memory as I had originally intended quickly became impossible after several attempted workarounds

Extracting the addresses from parsed data on the fly was much more suitable, however this was a challenge in itself as the API is a work in progress and does not handle auto-generated coins very well
My Expectations
Bitcoin addresses are not like bank accounts, any one person can have any amount of addresses at a given time
In fact as a general guideline users are encouraged to use a single address for a single transaction
This does not bode well for community detection, if everyone is using a new address every time, there are no communities
Fortunately, people are lazy

- Not everyone will create a new address every time
- Some will regularly use the same address over again
- And, public donation addresses will need to be kept static
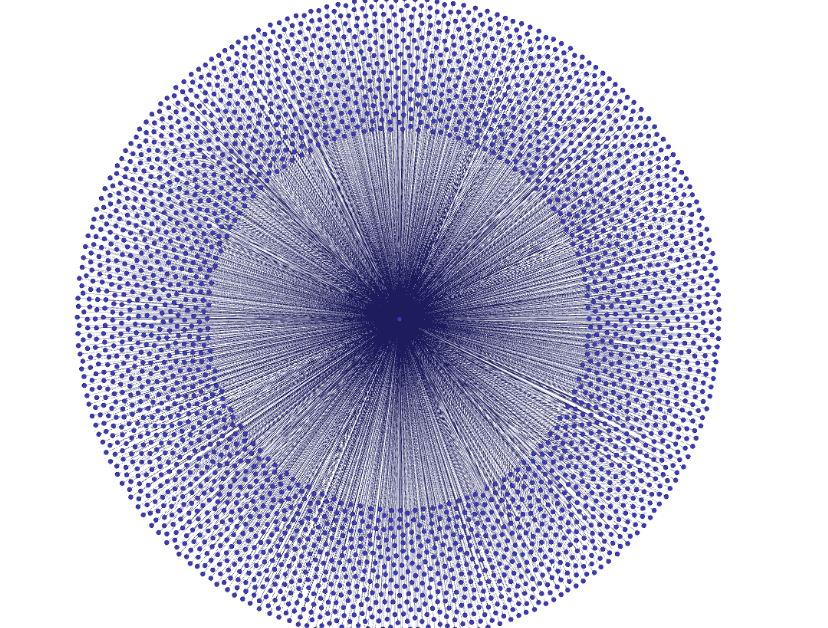
Results
As a first attempt the results have been promising, however there is a clear limitation on the load that Gephi can handle
A single .dat file (out of a few hundred I have available) produced 503, 794 lines of relational indicators, I have been thus far been able to make Gephi work reliably with just up to 7,000 lines. The application becomes unusable at higher counts
Some Statistics
| .dat file # | csv line count | csv line count including coin base |
|---|---|---|
| blk00000 | 297,821 | 300,672 |
| blk00080 | 491,387 | 491,930 |
| blk00160 | 503,485 | 503,794 |






The Algorithm
The underlying algorithm in use within Gephi is the Louvain method for community detection in large networks
It is today one of the most widely used method for detecting communities in large networks
Going forward
I will make use of the Louvain algorithm directly instead of using Gephi as well as other community detection algorithms
Investigate other visualization tools available
Combat performance issues
Analysis results from this demonstration and try to identify trends from the data
The End