Is Python Enterprise Ready?
Ryan Stuart
Who am I?
- Software Engineer
- CTO of Kapiche
- Writing Python for 7 years
- Previously: Java
- Also write JS (😭), C, other web things....
- Interests: Distributed Computing, Database Design, + others...
@rstuart85

rstuart85

This Talk
- What is enterprise software?
- History of enterprise tools.
- Specific issues examined:
- Static vs Dynamic Typing
- Speed of Python
- Scaling Python
- A case study: A database written in Python
- Questions
Enterprise Software
What is it?
- Developed for an organisation rather than individuals.
- High chance it will need to interact with legacy systems and integrate with some sort of authentication system (LDAP, AD etc.)
- Design goals can be driven by extremely varied and come from many parts of the organisation (management....)
- The complexity from many stakeholders and complex requirements will often lead to a massive budget, long running projects and scrutiny from non-technical people.
- Sometimes the non-technical people put undue emphasis on the programming language chosen.

History
- In the 80s and 90s, Microsoft, Sun & Oracle pushed the marketing message of "enterprise grade" tools.
- Traditionally these were statically typed languages.
- Other languages weren't considered sophisticated enough to solve these "hard" enterprise problems.
- This was true in part. Scripting languages like Ruby, Perl and Python weren't very sophisticated. The standard libraries were not nearly as complete as today.
- Nor were the quality and quantity of 3rd party libraries/frameworks.
- But come 2000s, things change. Also, the web happened.
Python in the Enterprise
Batteries Included
- Python has long been acknowledged as one of the best "glue" languages available.
- The Python Standard Library is arguably one of the best available today.
- When you include the 3rd party tools, especially around science, data and web frameworks, hard to ignore Python in the enterprise.
- So what are the barriers to using Python in the enterprise today?

Dynamically Typed
- One of those philosophical debates in the CS world.
- Static Typing:
- Bugs caught earlier/easier to catch.
- Easier to read/undertand code.
- Ergo, better for large teams.
- Dynamic Typing:
- Faster to write code but need to write more.
- Or, be lazy and catch bugs later.
- Harder to read/understand code.
- Easier for beginners.
- Python can do static typing of sorts.
- MyPy / PEP 484
Type Hints
from typing import Iterator
def fib(n: int) -> Iterator[int]:
a, b = 0, 1
while a < n:
yield a
a, b = b, a+b...or Optional Static typing
MyPy [1]
from typing import Iterator
def fib(n: int) -> Iterator[int]:
a, b = 0, 1
while a < n:
yield a
a, b = b, a+bPEP 484 [2]
Also includes:
- Type alisas
- Generics
- Unions
[1] http://mypy-lang.org/
[2] https://www.python.org/dev/peps/pep-0484/
PEP 484 is NOT a static type checker! Unlike MyPy.
...if you are worried that this will make Python ugly and turn it into some sort of inferior Java, then I share you concerns, but I would like to remind you of another potential ugliness; operator overloading.
C++, Perl and Haskell have operator overloading and it gets abused something rotten to produce "concise" (a.k.a. line noise) code. Python also has operator overloading and it is used sensibly, as it should be. Why? It's a cultural issue; readability matters.
Mark Shannon, PEP 484 BDFL-Delegate
Speed
- Python is an interpreted language and hence can be slower to run.
- Somewhat compounded by the GIL.
- This is a multi faceted problem:
- Python is FAST to develop.
- BUT Python can be slow for CPU bound tasks.
- When you need more speed, you have many choices!

Which is Cheaper?

CPU Cycles
OR

Developers
Time to develop/maintain software matters!
Python Interpeters
CPython isn't the only kid on the block!


C-Extensions
- Chances are you aren't the only person that needs code that performs a particular function to go fast.
- There are LOTS of Python packages that are actually C-Extensions.
- Even large parts of the standard library are implemented in C!
- For example:
- builtin functions, pickle, cProfile, itertools, re...
- numpy, simplejson, lxml, Pillow....
- Writing C-Extensions isn't hard!
Cython
def fib(n):
if n < 2:
return n
return fib(n-2) + fib(n-1)def fib(int n):
return fib_in_c(n)
cdef int fib_in_c(int n):
if n < 2:
return n
return fib_in_c(n-2) + fib_in_c(n-1)Pure Python
Cython
x72 faster
And you can do cool things!
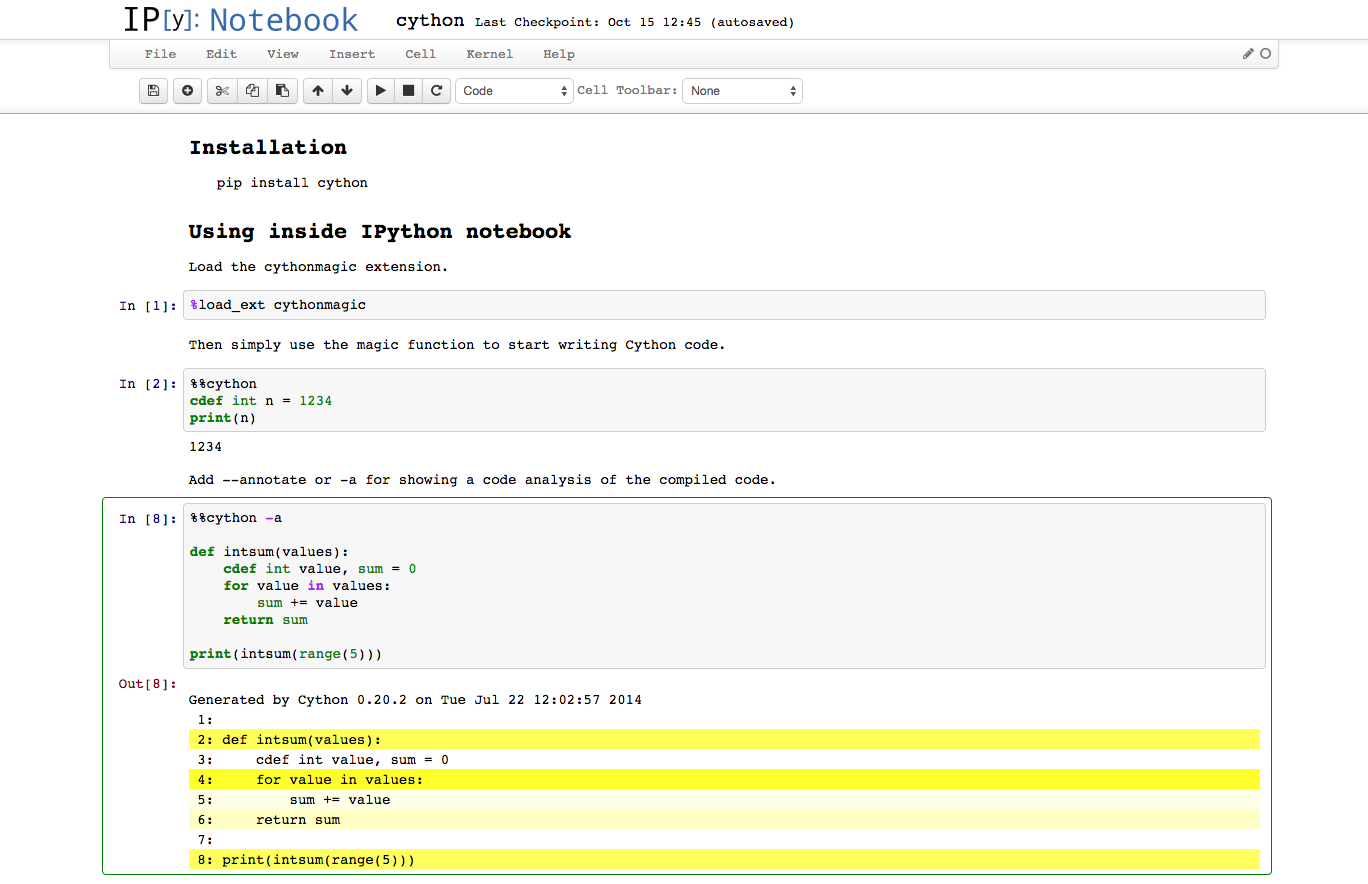
Plus Others
- Cython isn't your only option!
- Numba
- Nuitka
- Pyston
- Pythran
- Theano
- And others still...
- Is speed really a problem?
- Then choose your weapon...
Scaling Python
- Scaling has lots of dimensions, but in the instance, we are going to talk about the GIL.
- There seems to be a subset of developers that use the GIL as justification for "Python has bad concurrency support".
- In my opinion, that is just plain wrong.
- CPython is one of the most consistent runtimes available.
- How often do you hear people complaining about application startup times or garbage collection pauses?
- Part of that is down to simplicity and the GIL has a role to play in that.
GIL isn't a Bottleneck
- The GIL doesn't block for I/O.
from concurrent.futures import ThreadPoolExecutor
import time
def worker(name):
print("%s: Hi, time to start work!" % name)
time.sleep(2)
print("%s: My work here is done. Bye!" % name)
with ThreadPoolExecutor(max_workers=2) as pool:
pool.map(worker, ['A', 'B'])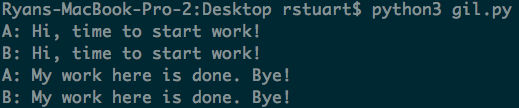
GIL isn't a Bottleneck...
The GIL does block for CPU bound tasks.
import concurrent.futures, math
PRIMES = [
112272535095293, 112582705942171, 112272535095293,
115280095190773, 115797848077099, 1099726899285419,
]
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
with concurrent.futures.ThreadPoolExecutor(max_workers=6) as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))Change to ProcessPoolExecutor for a ~75% reduction in run time.
The GIL can Disappear
cdef long long fsum(long long n):
cdef long long i, r
r = 1
with nogil:
for i in range(n):
r *= i + 1
return r
def job():
print(fsum(2<<10))Cython can just side-step the GIL
j = [threading.Thread(target=fsum.job) for core in range(6)]
[jj.start() for jj in j]
[jj.join() for jj in j]Concurrency is Easy...
- ...well easier than it is in other languages.
- The coding constructs are simple.
- Yes, the GIL is a thing.
- No, it isn't something to get worried about.
- Can almost be considered a feature for beginners.
- For me, the GIL means you need to actually think about the mechanics involved with concurrency and not just spawn a whole bunch of Threads.
- And personally, I think that is a very good thing.
Summary
- Python is an extremely flexible language.
- The size and scope of its Standard Library + 3rd party frameworks means it's very difficult for Enterprise to ignore. And indeed, they aren't
- Its syntax, strong opinions on style & Dynamic Typing make it very quick to write code.
- If your codebase grows you can switch over to Static Typing where it would make sense.
- If speed becomes an issue, you have a large number of options ranging from alternative interpreters to JITs and compilers.
- Scaling Python to multiple cores is demonstrably easy while maintaining a degree of safety for beginners.
Case Study: Caterpillar
What is Caterpillar?
- Put simply: A search engine.
- More in depth: A Text Indexer built for Information Retrieval & Qualitative analytics.
- Maintains data structures required to do Topic Modelling of text.
- Supports plugins. Right now, 1 open source plugin to do LSI.
- Kapiche has closed source plugins to do our own Topic Modelling and Sentiment Analysis.
Why Python?
- Development started with a lot of our own research using academic literature.
- Python let us prototype very quickly.
- After we figured how our Topic Modelling was going to work, we had to decide how to implement it.
- We stuck with Python because:
- It let us iterate fast.
- Dynamic Typing meant we decided to go with 100% test coverage enforced by CI.
- When it came to try and make things faster, the tools available were fantastic.
- Implementing existing indexers was daunting.
- We were confident we could extract more speed when required.
Current Status
- Still running CPython.
- No C-Extensions (of our own).
- When indexing Wikipedia, runs at 1/6th the speed of Apache Lucene.
- This is without any real optimisation.
- Used it to write a Semantic Search Engine of Wikipedia.
- Confident of getting close to Lucene in the not too distant future.
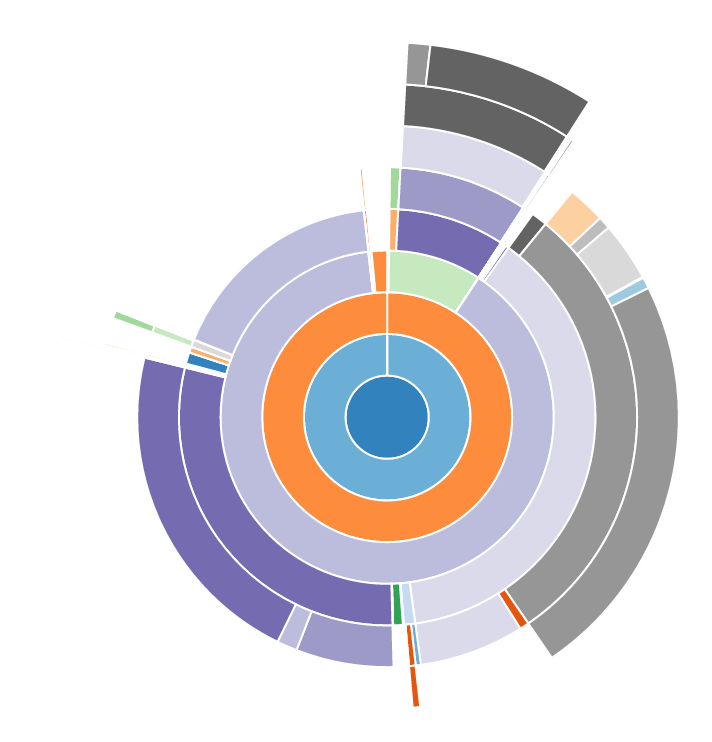
Profiling is Easy!
(snakeviz)
API is Neat
from caterpillar.processing.index import IndexWriter, IndexConfig
from caterpillar.processing.schema import Schema, TEXT, CATEGORICAL_TEXT
config = IndexConfig(
SqliteStorage,
Schema(
title=TEXT(indexed=False, stored=True),
text=TEXT(indexed=True, stored=True),
url=CATEGORICAL_TEXT(stored=True)
)
)
with IndexWriter('/tmp/cat-index', config) as writer: # Create index
for article in articles:
writer.add_document(title=article[1], text=article[2])Comparatively Speaking...
import lucene
from java.io import File
from org.apache.lucene.analysis.standard import StandardAnalyzer
from org.apache.lucene.document import Document, Field, FieldType
from org.apache.lucene.index import FieldInfo, IndexWriter, IndexWriterConfig
from org.apache.lucene.store import SimpleFSDirectory
from org.apache.lucene.util import Version
store = SimpleFSDirectory(File(index_dir))
analyzer = StandardAnalyzer(Version.LUCENE_CURRENT)
config = IndexWriterConfig(Version.LUCENE_CURRENT, analyzer)
config.setOpenMode(IndexWriterConfig.OpenMode.CREATE)
writer = IndexWriter(store, config)
title = FieldType()
title.setIndexed(True)
title.setStored(True)
title.setTokenized(False)
title.setIndexOptions(FieldInfo.IndexOptions.DOCS_AND_FREQS)
text = FieldType()
text.setIndexed(True)
text.setStored(True)
text.setTokenized(True)
text.setIndexOptions(FieldInfo.IndexOptions.DOCS_AND_FREQS_AND_POSITIONS)
for article in articles:
doc = Document()
doc.add(Field("title", page[1], title))
doc.add(Field("text", page[2], text))
writer.addDocument(doc)Using Python Means...
-
Our codebase is clear, concise and manageable.
-
Our test coverage is 100%. ⬅ Dynamic Typing
-
Adding/refactoring isn't a massive drag.
-
Because of the great profiling tools, we know exactly where our performance bottlenecks are.
-
Options for increased performance are numerous.
-
Our code is beautiful!!!
PSA
-
Red Hat Enterprise Linux refuses to run without Python.
-
Great talk about Cython tomorrow by Caleb at 11:10am in Roosevet - "Easy wins with Cython".
-
PSF Brochures just outside the door.
-
Sprint on Caterpillar Monday and Tuesday.
Questions
This slide deck: http://bit.ly/1Mymr9r
Caterpillar: https://github.com/Kapiche/caterpillar/
Caterpillar-LSI: https://github.com/Kapiche/caterpillar-lsi
Kapiche: http://kapiche.com
Resources
Thanks!