Speech To Text
Natural Language Processing
Sahand Khaksar
Mahdi Davoodi
How is Our voice Recognized?
Siri, Cortana, Google Nav, Alexa ,and ...
- Mobile Phones
- Tablets
- TV
- and other Gadgets
What we have Today
- Recognize what we say
- If possible, Do what we say
- Can tell a joke, Read a story
- Answer your Questions
Voice Assistants
- Recognize what we say
- Translate what we say to Computer Language
- Give the result in Human Language
How do they Work!?
- Listen to what we say and compare it with it's inner Dictionary
- Understands the words we say
So, what does it do?
Is it enough?
Predicting Statements
And How the Hell Do they Do That?
Acoustic Modeling
Fons and Waves
Hidden Markov Modeling
Modeling beyond Acoustics
- Accent
- Different Pronunciation
what google did:
- Voice Banks from Youtube and it's own Voice Search
- GOOG-141 (2007-2010) Telecomunication
- Language Modeling
- N-Gram
Conclusion
- Compare our recorded speech with database --> Recognizing Words
- Data Trees and Tables --> Recognizing Statements
- Probabilities -->different possible statements
- Language Modeling and Data Analysis --> grammar and accents
- Mathematics and Neural Network --> Meaning
Voice Recognition
Speaker Recognition
determining who is speaking
Speech Recognition
determining what is being said
Speaker Verification
Verifies the identity of a person
Speaker Diarisation
Recognizing when the same speaker is speaking
Simplifies the task of translating speech in systems
Identification
Verification
1:N
1:1
Enrollment
the speaker's voice is recorded and typically a number of features are extracted to form a voice print, template, or model
Verification
a speech sample or "utterance" is compared against a previously created voice print.
Each speaker recognition system has two phases:
Text-Dependant
Enrollment and verification
Text-Independent
speaker identification
Speaker recognition systems fall into two categories:
Technology
- Patter Recognition
- Frequency Estimation
- Hidden Markov Models
- Gaussian Mixture Models
- Pattern Matching
- Neural Network
- Matrix Representation
- Vector Quantization
- Decision Trees
Applications
- 1983: CSELT(Italy) improved noise-reduction
- 1996-1998: Canada-United States Border for the night
- 2013: Barclays Wealth - 30 seconds of normal conversation
developed by Nuance(the company behind Siri)
- 2016: UK HSBC - 15M costumers in biometric banking
Speech Recognition
- automatic speech recognition (ASR)
- computer speech recognition
- speech to text
- Linguistics
- Computer Science
- Electrical Engineering
ASR Applications
- Voice-User Interface
- Domotic (Home Automation)
- Search (Find a podcast where particular words were spoken)
- Simple Data Entry
- STT
Models, Methods, and Algorithms
- Hidden Markov Models
- Dynamic Time Warping
- Neural Network
- Deep Learning
- End-to-end
HMM
Statistical models that output a sequence of symbols or quantities
DTM
measuring similarity between two temporal sequences, which may vary in speed. For instance, similarities in walking could be detected using DTW, even if one person was walking faster than the other, or if there were accelerations and decelerations during the course of an observation
Neural Netwrok
The neural network itself is not an algorithm, but rather a framework for many different machine learning algorithms to work together and process complex data inputs
End-to-end
End-to-end models jointly learn all the components of the speech recognizer. It simplifies the training process and deployment process.
For example, a n-gram language model is required for all HMM-based systems, and a typical n-gram language model often takes several gigabytes in memory making them impractical to deploy on mobile devices.
Applications
- In-Car systems
- Health Care
- Military (Aircrafts)
- Telephony
- Education
- ...
Companies
Founded in 2016, Silicon Valley startup AISense has raised $13 million in funding to develop their “Otter Voice Notes” app, a solution for transcribing long conversations between multiple people. Otter separates and identifies speakers, and allows users to store, search, analyze and share voice conversations. AISense provides the service through a cloud platform that includes storage as well, running their algorithms using Nvidia graphical processors.

Otter is available for consumers through the App Store and Google Play with a free plan that contains up to 600 minutes of transcription a month, or ten times that for $10 a month. Enterprise use cases include call centers, online meetings, and pre-production media content – all priced on a case-by-case basis.
Founded in 2016, Los Angeles startup Behavioral Signals has raised $1.5 million to develop a conversation analytics suite complete with automated transcription and behavioral analytics. Their “callER Analytics Engine” transcribes and analyzes calls while looking at the speakers’ emotional state to come up with a final success score.

Measuring factors like tone, positivity, politeness, or arousal, the engine is well equipped to help sales teams increase revenue by as much as 10% and even reduce agent attrition, the company claims
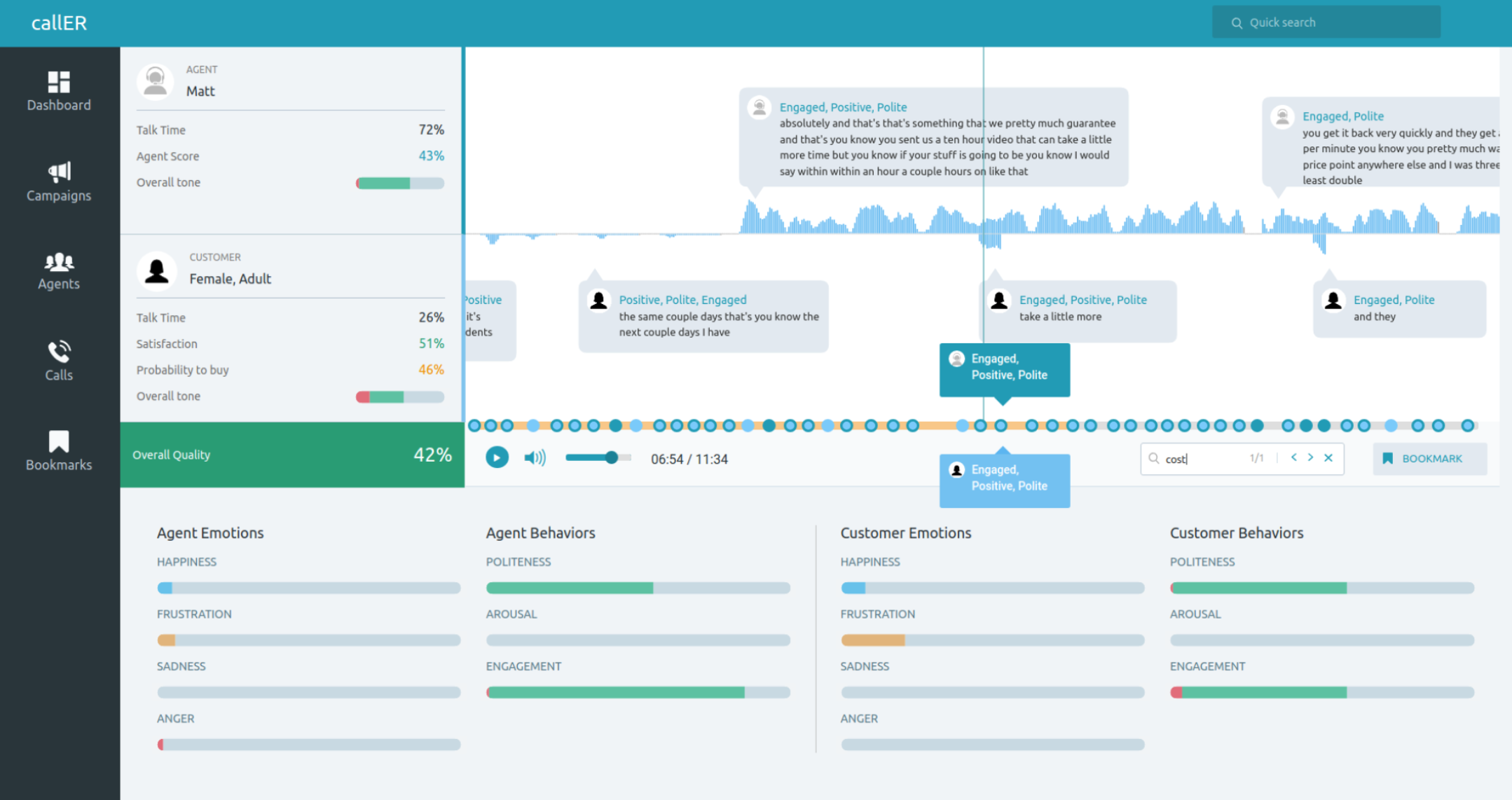
Founded in 2017, Netherlands startup SpeakSee has raised an undisclosed amount of funding to develop a small handheld microphone for real-time transcriptions for people with hearing problems. The company is currently running an Indiegogo campaign which has already exceeded the $50,000 target by 63%. These handheld microphones connect to a smartphone using Wi-Fi and listen in the direction they are pointed at, so background noise is effectively cancelled out.

Data is relayed to their base station, then transmitted to the SpeakSee app. Mics are compatible with conference call systems and televisions as well, and the platform supports more than 120 languages or dialects. (Really?) One mic+dock combo costs $250 and a dock with three mics costs $350 at current early bird rates on Indiegogo.
Homa Web
Persian TTS
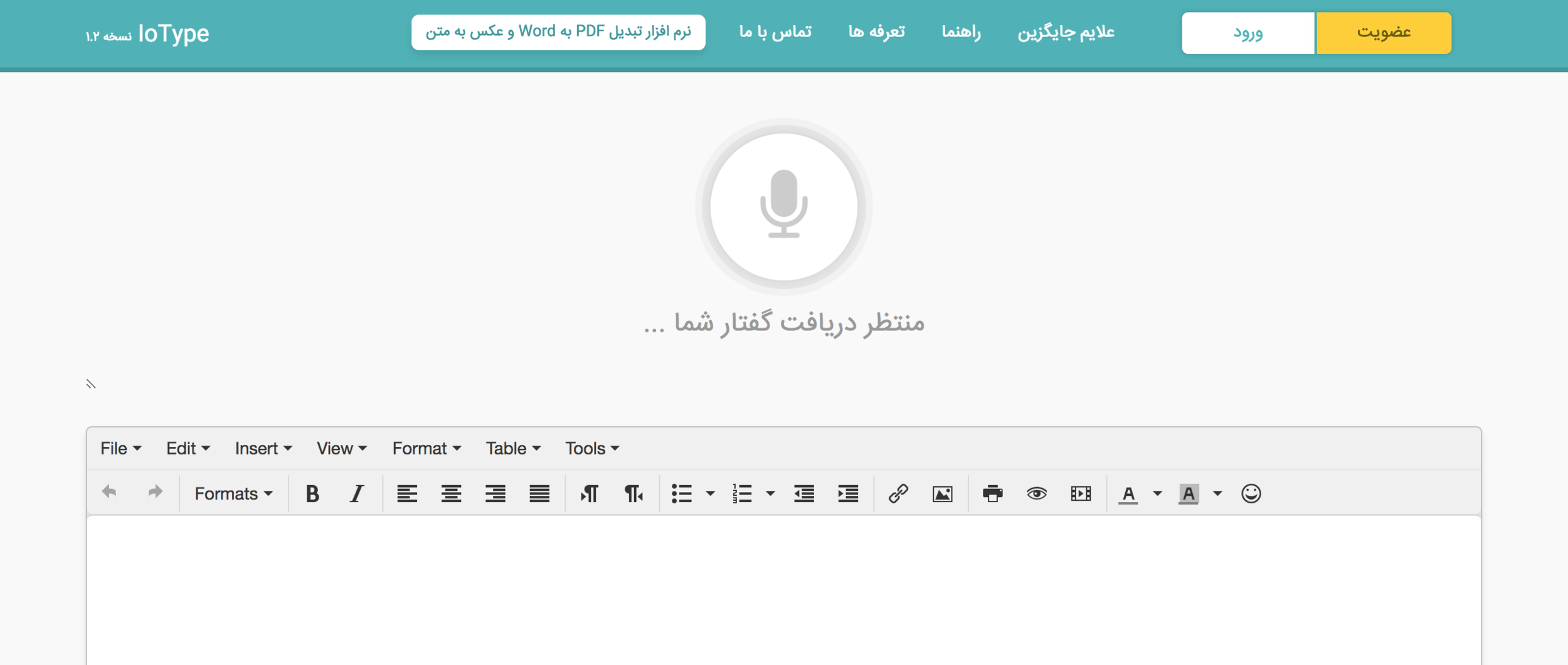
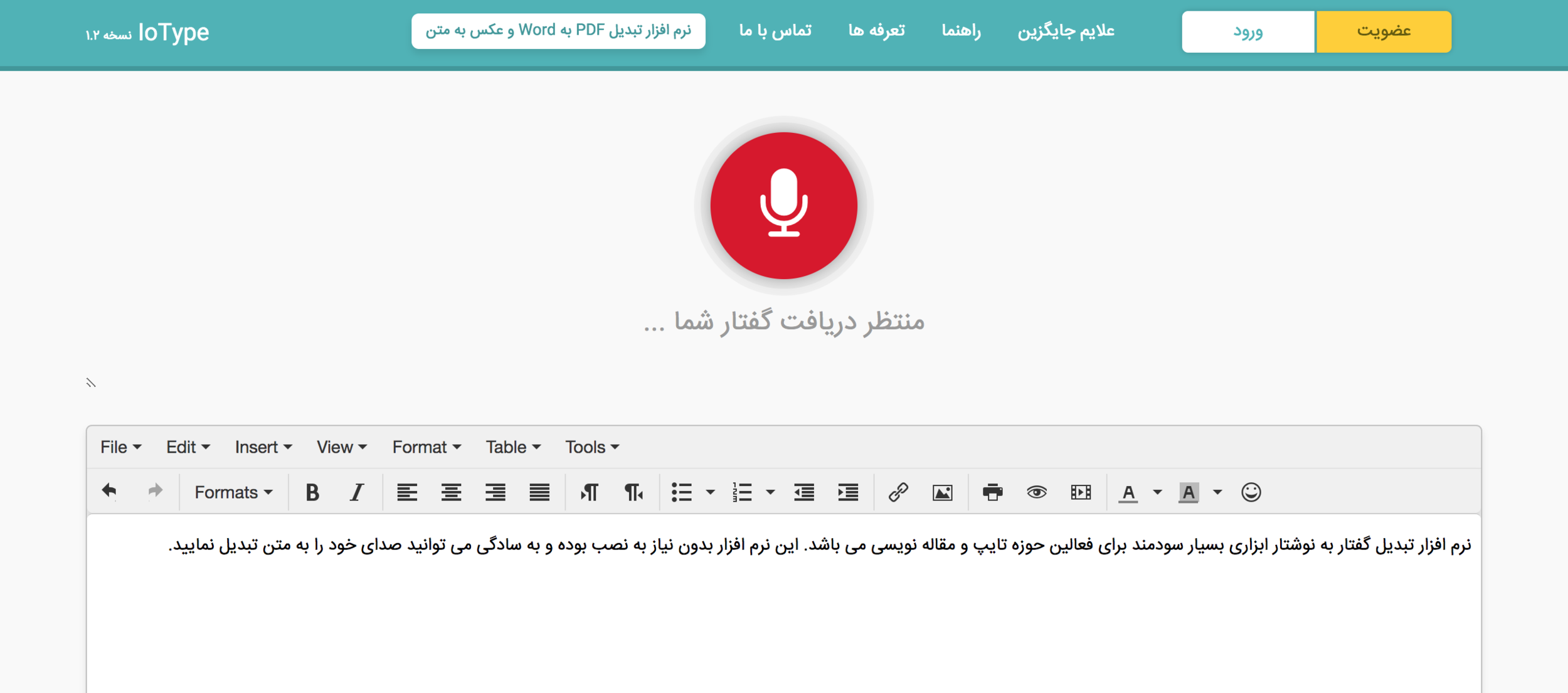
شرکت دانش بنیان عصر گویش پرداز محصولات و خدمات نرمافزاری متنوعی در زمینههای هوش مصنوعی و پردازش سیگنال گفتار ارائه کرده است. یک تیم پژوهشی باتجربه از متخصصان دانشگاه صنعتی شریف در این شرکت فعالیت میکنند. این شرکت مشاوره فروش، نصب و پشتیبانی محصولات خود را توسط افراد مجرب انجام میدهد. عصر گویش پرداز پیشرو در توسعه فناوریهای مبتنی بر گفتار برای زبان فارسی است. از جمله این دستاوردها میتوان به تکنولوژیهای گفتار به نوشتار، متن به گفتار، جستجو در صوت و تشخیص هویت از روی صدا اشاره کرد.




نرم افزار تایپ صوتی نویسا