Dynamic
Programming
UMD Competitive Programming Club Week 4

What is Dynamic Programming
1. Overlapping Subproblems
What is Dynamic Programming
1. Overlapping Subproblems
What is Dynamic Programming
1. Overlapping Subproblems
What is Dynamic Programming
1. Overlapping Subproblems
What is Dynamic Programming
They are same!
1. Overlapping Subproblems
What is Dynamic Programming
int f(int n) {
if (n <= 1) return 1;
else return f(n-1) + f(n-2);
}You will compute some states more than once!!
1. Overlapping Subproblems
What is Dynamic Programming
int dp[MAXN];
int f(int n) {
if (dp[n]) return dp[n];
else if (n <= 1) return dp[n] = 1;
else return dp[n] = f(n-1) + f(n-2);
}Every state will now only be compute once
This is called Memoization
2. Optimal Substructures
What is Dynamic Programming
2. Optimal Substructures
What is Dynamic Programming
There is a stairs with \(n\) levels, there are \(a_i\) coins on each level, you can walk \(1\) or \(2\) steps each time. What is the maximum coins you can get?
Let \(f(n)\) be the maximum coins you get when you get to \(n\)
Two Different Ways
Two Different Ways
Top-Down Approach (Recursion)
Bottom-Up Approach (For Loop)
Two Different Ways
Let's look at Fibonacci again!!!
Two Different Ways
Top-Down (Recursion with Memoization)
int dp[MAXN];
int f(int n) {
if (dp[n]) return dp[n];
else if (n <= 1) return dp[n] = 1;
else return dp[n] = f(n-1) + f(n-2);
}Two Different Ways
Bottom-Up (For Loop)
int dp[MAXN];
dp[0] = dp[1] = 1;
for (int i = 2; i <= n; i++){
dp[i] = dp[i - 1] + dp[i - 2];
}We prefer Bottom-Up since the constant is smaller than recursion
How to Solve DP Problems
How to Solve DP Problems
Define States \(\Rightarrow\) Find The Transition \(\Rightarrow\) Handle Base Cases
The concept is abtract
Let's look at the problems!
Classic DP Problems
Classic DP Problems 1 - Frogs 1

Classic DP Problems 1 - Frogs 1
Define The States
Classic DP Problems 1 - Frogs 1
Find The Transition
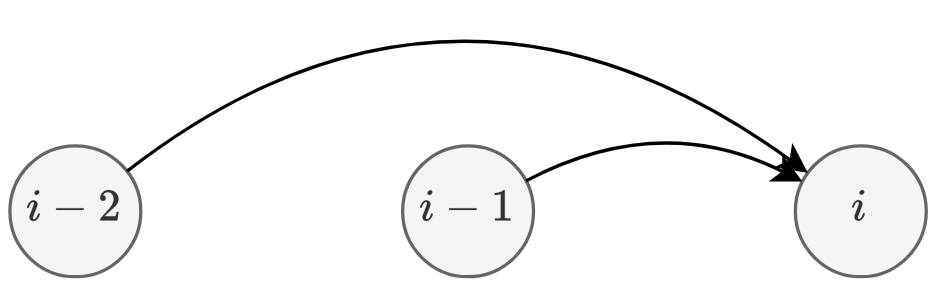
Classic DP Problems 1 - Frogs 1
Base Case
There is no cost for Frog to be at stone \(1\)
Classic DP Problems 1 - Frogs 1
Time complexity
Classic DP Problems 2 - Frogs 2
What if now a frog can jump at most \(k\) step forward?
Each transition is \(\mathcal{O}(k)\)
\(\Rightarrow \mathcal{O}(nk)\)
Classic DP Problems 3 - Vacation
You are on a vacation for \(n\) days,
each day, you can do three activities
- Swim in the sea, and get \(a_i\) happiness
- Catch bugs, and get \(b_i\) happiness
- Do homework, and get \(c_i\) happiness
However, you cannot do same activities on consecutive days
What is the maximum happiness you can have?
Classic DP Problems 3 - Vacation
Define the state!
You want the state to be easy to do transition!
The answer is
Classic DP Problems 3 - Vacation
Find The Transition!
Each transition is \(\mathcal{O}(1)\)
Classic DP Problems 3 - Vacation
Base Case
Time
Classic DP Problems 4 - LCS
You are given two strings \(s,t\)
Output their Longest Common Subsequence (LCS)
Classic DP Problems 4 - LCS
Define the states
You can also think of \(i,j\) as lengths
You can also think of \(i,j\) as lengths
Classic DP Problems 4 - LCS
Find The Transition
Each Transition is \(\mathcal{O}(1)\)
Classic DP Problems 4 - LCS
Base Case
Time
Classic DP Problems 4 - LCS
How to construct answer?
Classic DP Problems 4 - LCS
How to construct answer?
Let \(from[i][j]\) be \(\{x,y\}\) where the value of \(dp[i][j]\) is from
Classic DP Problems 4 - LCS
How to construct answer?
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (s[i-1] == s[j-1]) {
dp[i][j] = dp[i-1][j-1] + 1;
from[i][j] = {i-1, j-1};
}
if (dp[i-1][j] > dp[i][j]) {
dp[i][j] = dp[i-1][j];
from[i][j] = dp[i-1][j];
}
if (dp[i][j-1] > dp[i][j]) {
dp[i][j] = dp[i][j-1];
from[i][j] = dp[i][j-1];
}
}
}Classic DP Problems 5 - MCS
You are given an array with \(n\) integers
Find the maximum sum over all continuous subarray
Classic DP Problems 5 - MCS
Define the states
The answer will be \(\max(dp[i])\) over all \(i\)
Classic DP Problems 5 - MCS
Find The Transitions
Either continue the previous sum, or start a new one
Classic DP Problems 5 - MCS
Base Case
Classic DP Problems 6 - LIS
You are given an array of \(n\) numbers
Find the Longest Increasing Subsequence
Classic DP Problems 6 - LIS
Define The States
Classic DP Problems 6 - LIS
Find Transition
Classic DP Problems 6 - LIS
Base Case
Time
Classic DP Problems 6 - LIS
Can we do better?
Classic DP Problems 6 - LIS
There are two ways to speed this up
- RMQ + Point Update
- Binary Search
We will only talk about 2. here
Classic DP Problems 6 - LIS
Consider the sequence
Let's look at it's DP Table
Classic DP Problems 6 - LIS
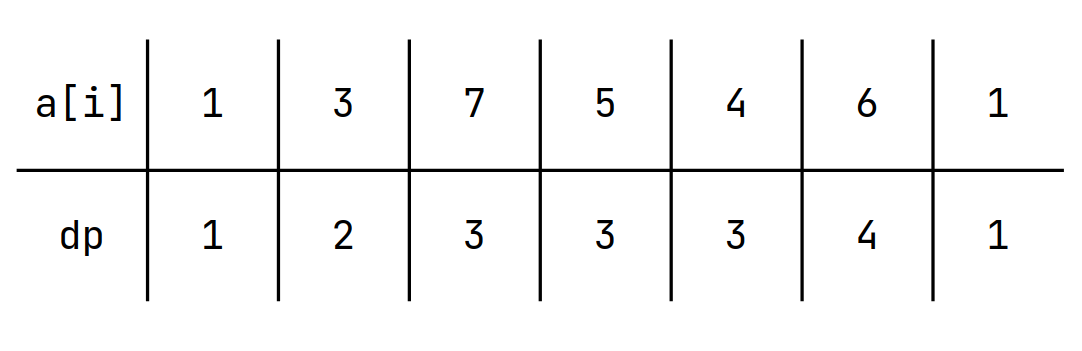
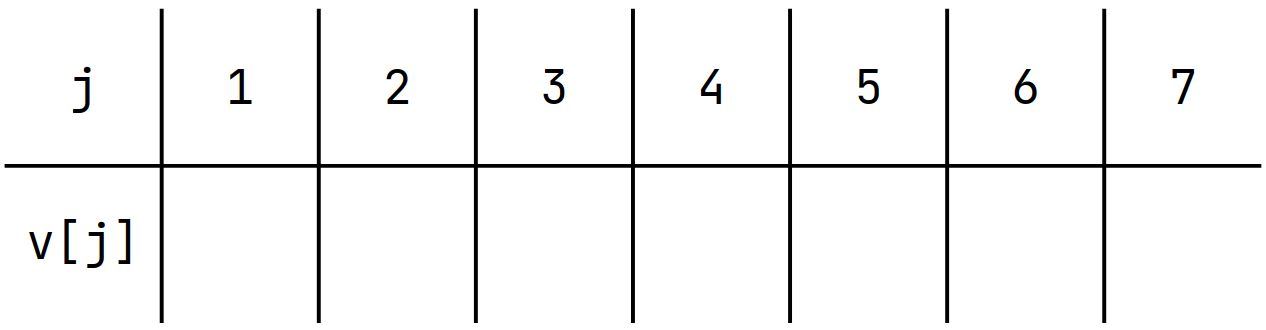
Let's define \(v[j]\) as the Minimum Value \(a_i\) such that \(dp[i] = j\)
Classic DP Problems 6 - LIS
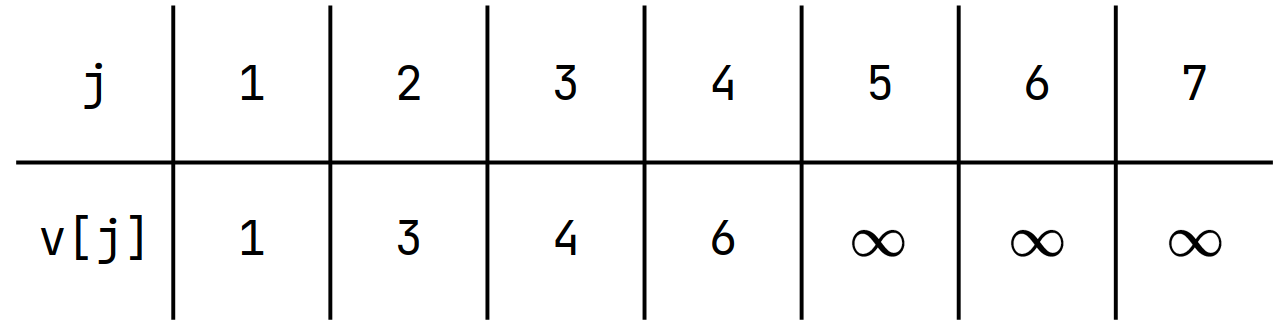
Classic DP Problems 6 - LIS
You can easily prove that \(v\) is increasing
Find the largest number less than \(a_i\)
Binary Search!!
Classic DP Problems 6 - LIS
Classic DP Problems 6 - LIS
Classic DP Problems 6 - LIS
Classic DP Problems 6 - LIS
Classic DP Problems 6 - LIS
Classic DP Problems 6 - LIS
Classic DP Problems 6 - LIS
Classic DP Problems 6 - LIS
Code
int dp[n];
vector<int> v;
for(int i = 0; i < n; i++){
int idx = lower_bound(v.begin(), v.end(), a[i]) - v.begin();
if(idx == v.size()) v.push_back(a[i]);
else v[idx] = a[i];
dp[i] = idx + 1;
}
cout << v.size() << "\n";Knapsack Problem
There are \(n\) items, each has weight \(w_i\) and value \(v_i\)
Now, you have a knapsack with capacity \(C\), find the maximum sum of values of items you can put in the knapsack
Define The States
Answer would be \(dp[n][W]\)
Find The Transition
For each item, you can choose to take or not take
Therefore, we can derive the transition as
Base Case
(This can prevent some border cases)
Do we really need 2D?
NO!
There is a trick called Rolling DP
There is a trick called Rolling DP
We can define the states as this
since every time we do transition from \(i-1\)
Transition becomes
Transition becomes
Actually, we can even get rid of the first dimension!
for(int i = 1; i <= n; i++){
for(int j = W; j >= 0; j--){
if(j >= w[i])
dp[j] = max(dp[j], dp[j-w[i]] + v[i]);
}
}1D Version!
You may ask "Why is \(j\) from \(W\) to \(0\)?"
This is the original transition
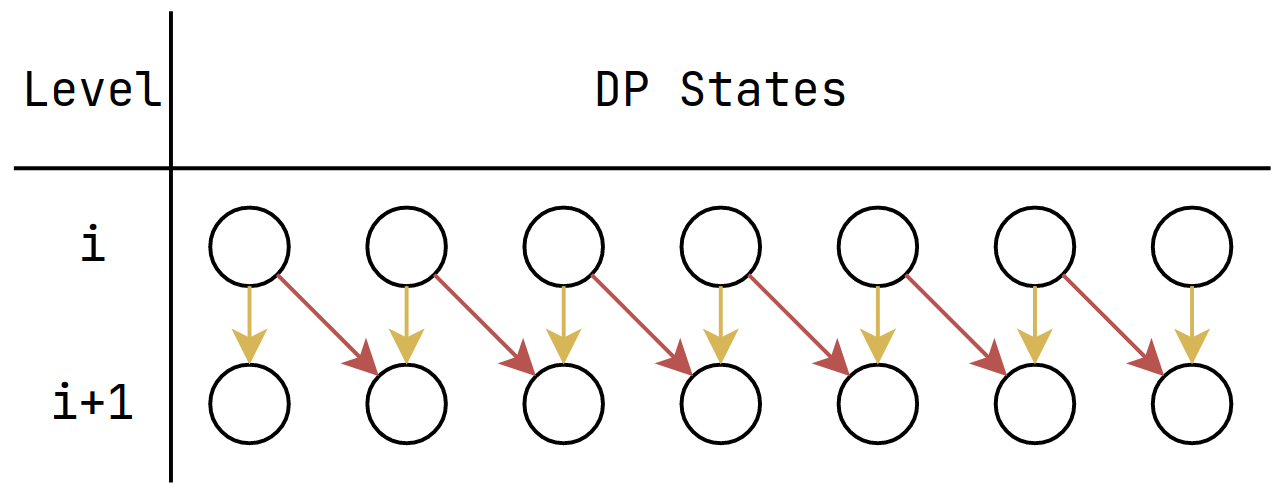
You want the arrows to be exactly once
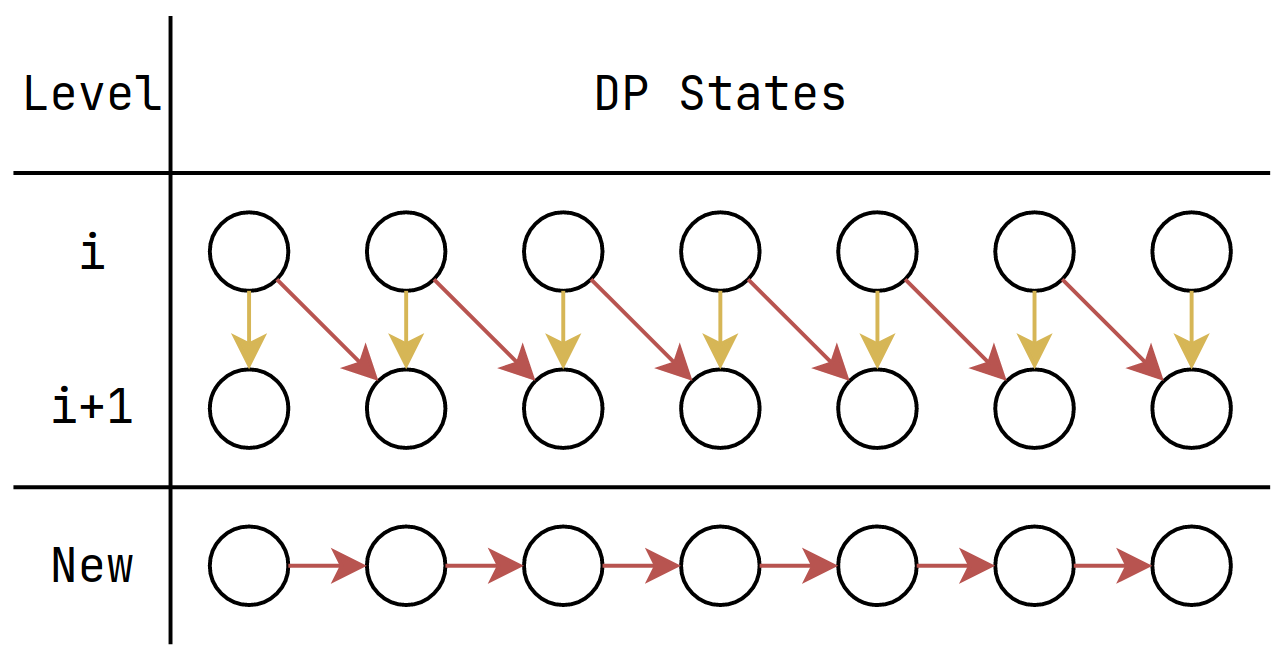
What if every item has infinitely many?
\(k\) from \(0\) to \(W\)!
for(int i = 1; i <= n; i++){
for(int j = 0; j <= W; j++){
if(j >= w[i])
dp[j] = max(dp[j], dp[j-w[i]] + v[i]);
}
}for(int i = 1; i <= n; i++){
for(int j = 0; j <= W; j++){
if(j >= w[i])
dp[j] = max(dp[j], dp[j-w[i]] + v[i]);
}
}for(int i = 1; i <= n; i++){
for(int k = 0; k < num[i]; k++){
for(int j = W; j >= 0; j--){
if(j >= w[i])
dp[j] = max(dp[j], dp[j-w[i]] + v[i]);
}
}
}Can we do better?
Can we do better?
Do we really need to go through \(k\) for each item?
There is actually a faster way in
Range DP
Range DP
There are \(n\) slimes in a line each with a size \(a_i\), every time, you can choose \(2\) adjacent slimes with size \(a,b\) , and combine them into a slime with size \(a+b\), creating a cost of \(a+b\). What is the minimum cost required to combine all slimes?

Range DP
How should we define the state?
Range DP
Let \(dp[i]\) be the minimum cost to combine the first \(i\) slimes?
This will not work!!
Range DP
Define the states
Answer will be \(dp[1][n]\)
Range DP
Find The Transition
Range DP
Find The Transition
Consider this range
Range DP
Either \(10 + 3\) or \(4 + 9\) is possible
Combining \(6+3\), then combine \(4+9\) gives smaller cost!
Range DP
Base Case
(No cost)
Range DP
Runtime
The transition takes \(O(n)\) if you precompute the prefix sum
Therefore, the total time is \(O(n^3)\)
Range DP
Important thing about Range DP!
Let's look at two different codes, and let's vote on which one is correct!
Range DP
for (int l = 1; l <= n; l++) {
for(int r = 1; r <= n; r++) {
for (int k = l; k <= r; k++) {
dp[l][r] = min(dp[l][k] + dp[k][r] + sum(l, r));
}
}
}for (int l = n; l >= 1; l--) {
for(int r = l; r <= n; r++) {
for (int k = l; k <= r; k++) {
dp[l][r] = min(dp[l][k] + dp[k][r] + sum(l, r));
}
}
}Range DP
Why is the first one incorrect?
for (int l = 1; l <= n; l++) {
for(int r = 1; r <= n; r++) {
for (int k = l; k <= r; k++) {
dp[l][r] = min(dp[l][k] + dp[k][r] + sum(l, r));
}
}
}It is possible to use the data from ranges that we have not computed!
Range DP
The order of transition is important for Range DP!
Range DP
The order of transition is important for Range DP!
Range DP

Range DP
Define the states
Range DP
Find The Transition
This is because second player becomes first after first player's operation!
Range DP
Find The Transition
This is because second player becomes first after first player's operation!
Range DP
Base Case
If there is only one stone, then first player takes the stone!
Bitmask DP
Bitmask DP
Travelling Salesman Problem
You are given a weighted graph with \(n\) vertices and \(m\) directed edges. You want to know the minimum sum of weights to start from \(s\), going through all vertices exactly once, then return to \(s\)
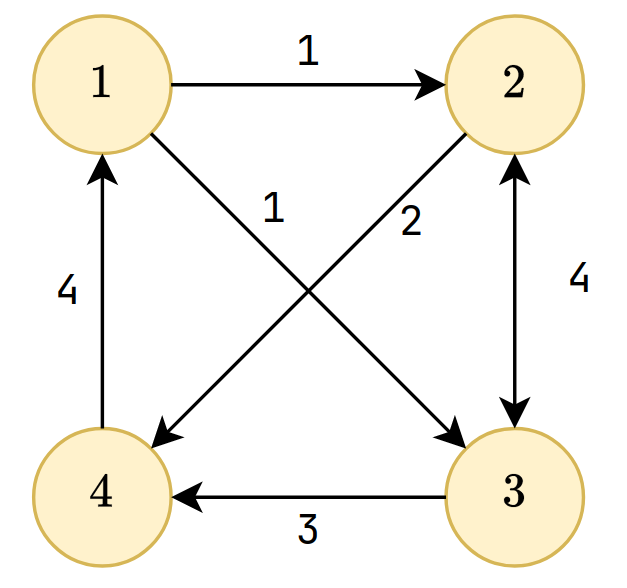
Bitmask DP
Travelling Salesman Problem
Define the states
If there are \(20\) vertices, then it means you have to do 20D DP!
Bitmask DP
Travelling Salesman Problem
Define the states
Compress the \(n\)D into a single integer!
Then answer will be \(\min(dp[i][2^n-1] + dis[i][s])\)
Bitmask DP
Travelling Salesman Problem
Find the transitions
We go through all pairs of vertices for each mask!
Bitmask DP
Travelling Salesman Problem
Base Case
Bitmask DP
Travelling Salesman Problem
Base Case
Bitmask DP
for(int mask = 0;mask < (1<<n);mask++){
for(int u = 0;u < n;u++){
if(mask&(1<<u)){
for(int v = 0;v < n;v++){
if(mask&(1<<v)) continue;
dp[v][mask^(1<<v)] = min(dp[v][mask^(1<<v)], dp[u][mask] + dis[u][v]);
}
}
}
}Some Cool Problems

