Web Scraping with JavaScript
https://github.com/samuelklam/web-scraping
What is Web Scraping?
- A computer software technique used to extract data/information from websites
- Store the data in a local file on your computer or to a database in table
Web Scraping Use Cases
- scrape products from retailer or manufacturer websites
- to show in your own website
- to provide specs/price comparisons
- scrape business profiles and reviews to track online presence and reputation
- scrape news websites
Anatomy of a Scraper

- Document Load
- Parsing
- Extraction
- Transformation
Anatomy of a Scraper
- Load the complete HTML web page, PDF, XML, etc.
- Generally as a string of characters
- For larger documents may involve splitting into multiple pages
1. Document Load
Anatomy of a Scraper
- Interpret the document to make searching it possible
- Parse the HTML, XML, or PDF meta data into a format the script can understand
2. Parsing
Anatomy of a Scraper
- Search the results of the parsed data for particular pieces of information
- movie titles, reviews, etc.
- Separate the data into individual pieces for later processing
3. Extraction
Anatomy of a Scraper
- Convert the data into useful formats (e.g. currency, dates, etc.)
- Change types
- Date string -> Date format
4. Transformation
Tools in JavaScript
Cheerio + Request
Phantom + Casper
- all the steps are simplified as the functionality is already made for us in different modules by other developers
Extract:
- Rank
- Title
- URL
- Site
Hacker News

Set up Your Web Server
Express, Chalk

1. Load the Page
We can use Request - a simple way to make HTTP calls and extract the HTML of the web page


2. Parse the HTML
Cheerio - Cheerio takes raw HTML, parses it, and returns a jQuery object , allowing you to traverse the DOM
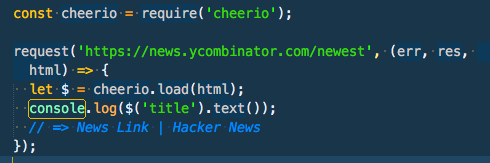
3-4: Extract & Format


Cheerio Limitations
- difficult to handle pages with heavy ajax
- difficult to handle pagination
- works well with static pages

PhantomJS + Casper
- Phantom functions as a headless browser
- great for automating tasks such as:
- testing, screen capturing, page automation and network monitoring
- great for automating tasks such as:
- Casper
- provides useful abstractions over Phantom
- promises-style API


Casper Demo
>> brew install phantomjs
>> brew install casperjs


Grab link results from Google Search for 'javascript' and 'python'
Limitations of Web Scraping
- websites or the page structure may change from time to time
- lengthy scraping sessions can be interrupted, e.g. server crashes, website undergo maintenance
- some websites may be extremely difficult to extract info
Is it Legal?
- reference a website's policies and terms of service
- e.g. Quora strictly disallows scraping and will ban accounts
- if crawling is not at a disruptive rate or breaches any contract nor commit a crime (Computer Fraud and Abuse Act)
- still an area that is being investigated
Links
GitHub
github.com/samuelklam.com/web-scraping
Request
- https://github.com/request/request
Cheerio
- https://github.com/cheeriojs/cheerio
Phantom
- https://phantomjs.org
Casper
- https://casperjs.org
Non-developers
Import.io
https://www.import.io/
Kimono
- acquired by Palantir
- https://www.kimonolabs.com/
ParseHub
- https://parsehub.com/