Introduction to Data Engineering
About me
- ML Engineering @ NCU
- Data Engineering @ Bridgewell

Outline
-
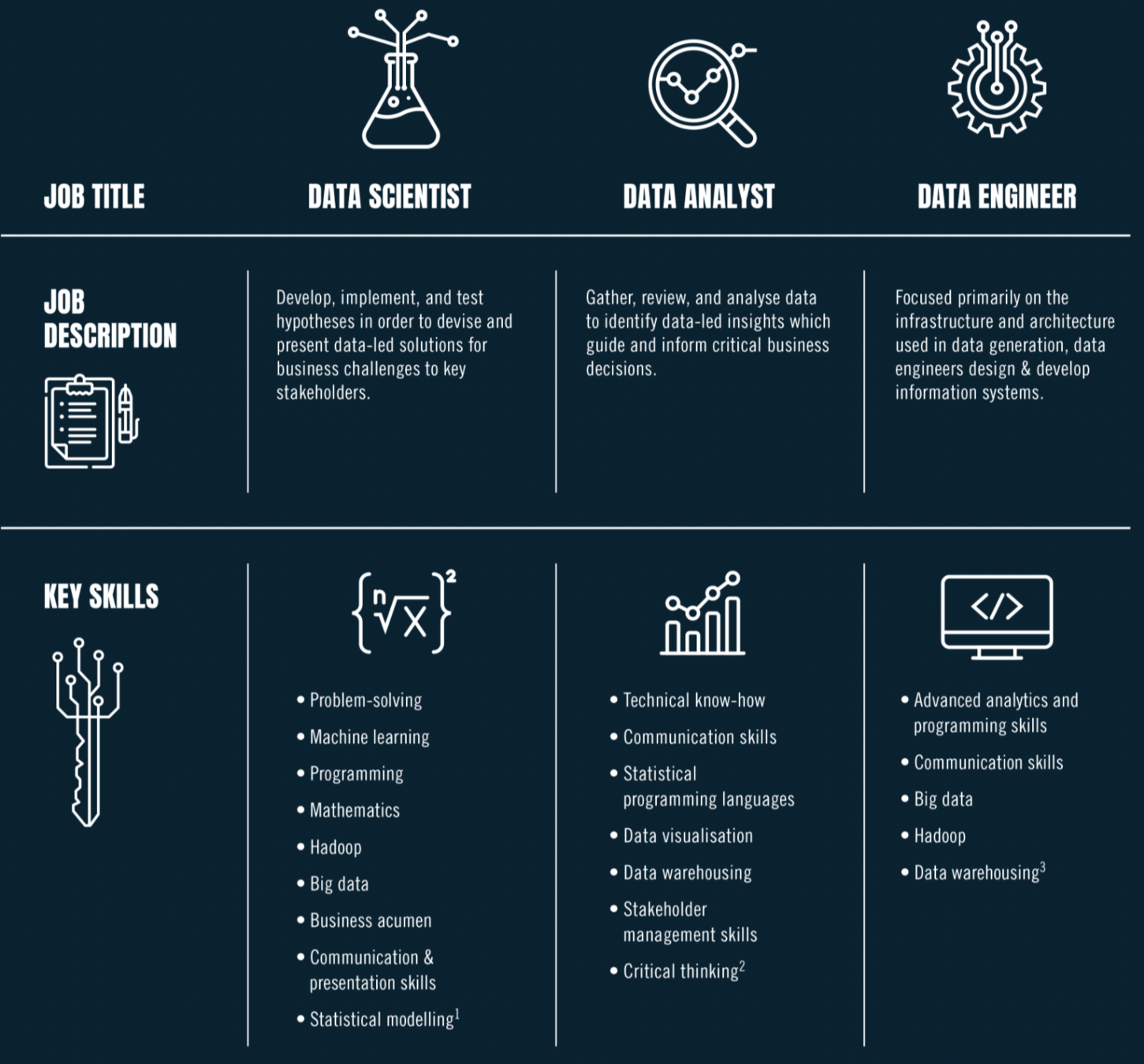
Difference of data scientist and data engineer
-
What a Data Engineer does?
- Skills
- Data Management roles
- Use case
- Workflow management system
- Data Engineer interview
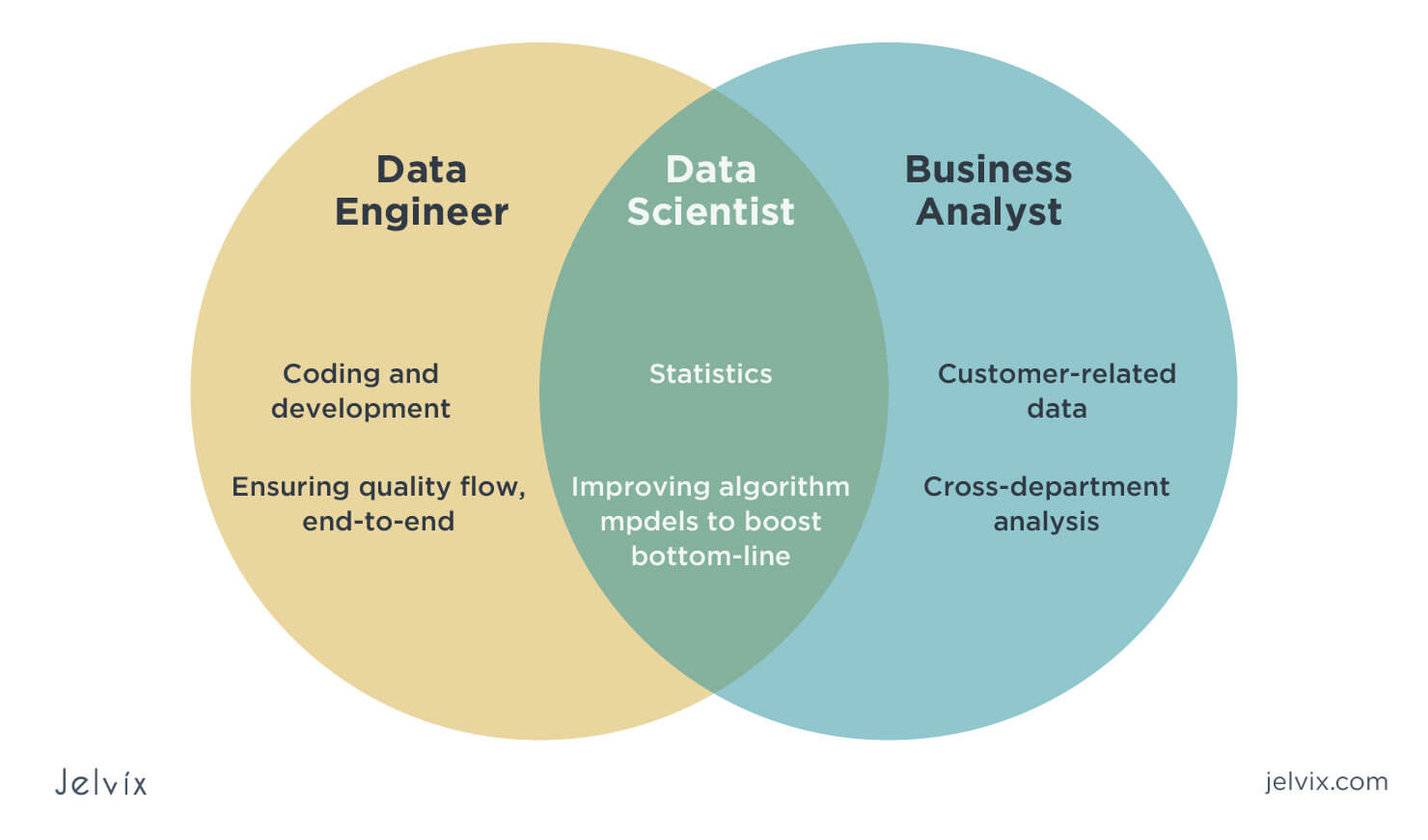
Difference of
data scientist and data engineer
In Taiwan regular company
Data Scientist
+
Data Analyst
+
Data Engineer
=
Data Scientist

JD from Taiwan's company

What a Data Engineer does?
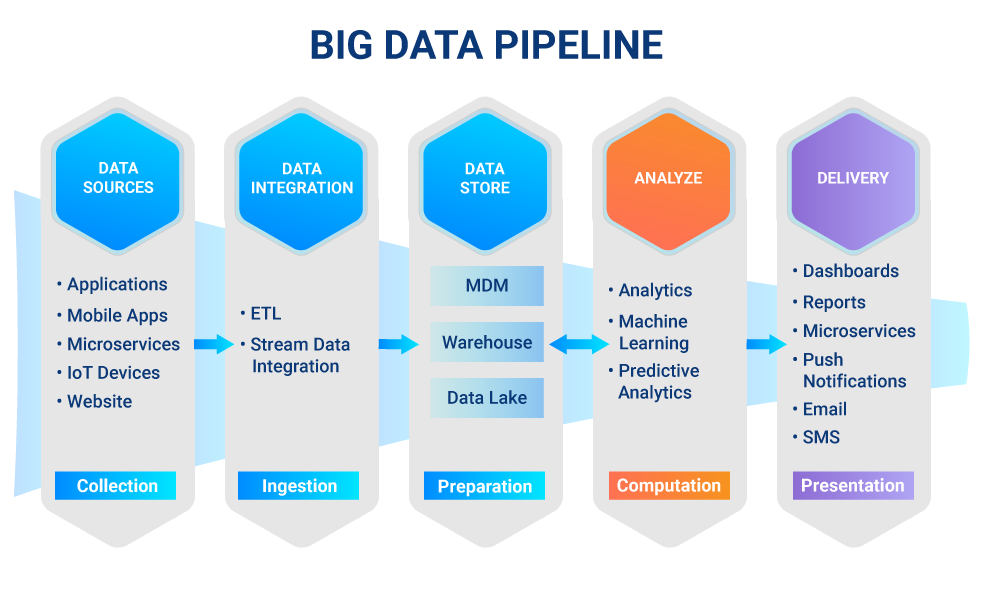
Data pipeline
Series of data processes that extract, process and load data between different systems.
- Batch-driven: Process data by scheduled system.
- Such as Airflow, Oozie, Jenkins or Cron.
- Real-time: Process new data as soon as its available.
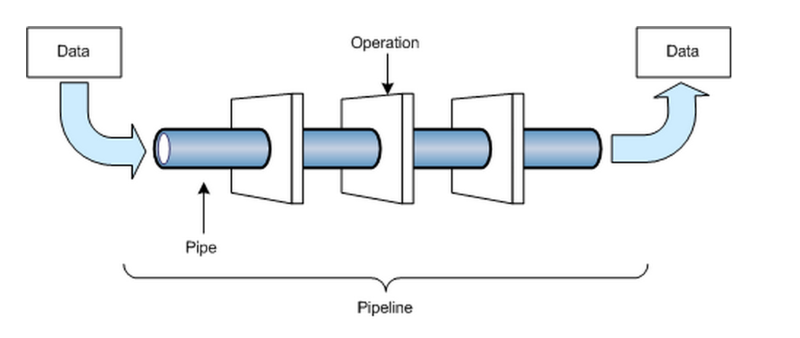
How to distinguish data pipeline and data ETL ?
ETL is part of data pipeline, means Extract, Transform and Load.
- Extract
- Collect data from other upstream API service.
- Consume data from Kafka.
- Get HTTP request from client web pages.
- Transform
- Clean data, transform format etc.
- Load
- Store data to data warehouse or just DB.
Data warehouse
A data warehouse is a type of data management system that is designed to enable and support business intelligence (BI) activities, especially analytics. Data warehouses are solely intended to perform queries and analysis and often contain large amounts of historical data.
- Such as Apache Hive, BigQuery (GCP) and RedShift (AWS)
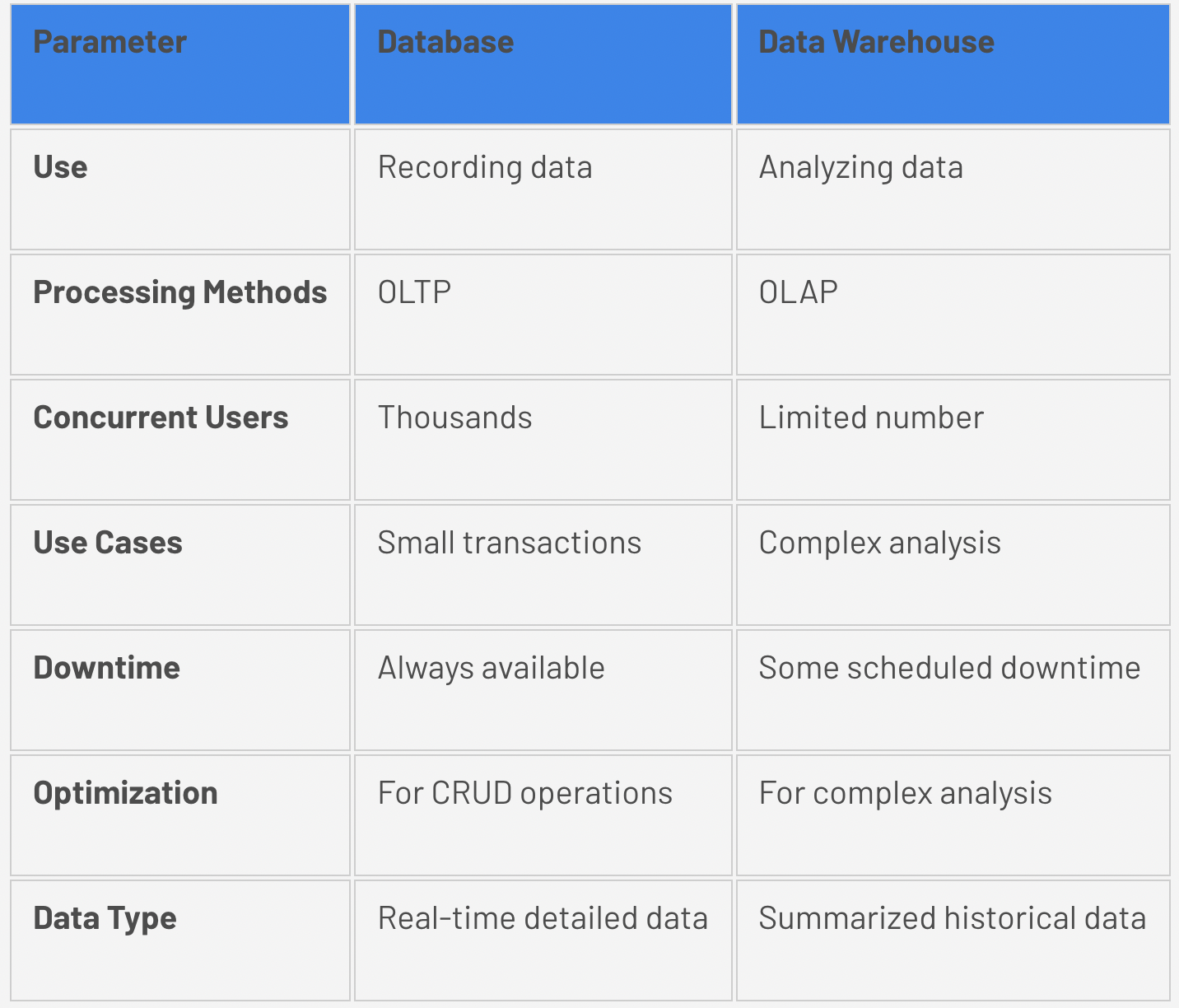
Database vs Data warehouse
Data Report

Google BigQuery + Google Data Studio
Data infra
Data infrastructure of data platform:
The distributed systems that everything runs on top of.
Data Application
Building internal data tools and APIs.
Skills
- General programming concepts
- OOP, data structure and algorithms.
- Databases
- Relational DB
- Key-value stores like Redis or Cassandra
- Document stores like MongoDB or Elasticsearch
- Graph databases like Neo4j
- Distributed systems and cloud engineering
- Hadoop
- Kafka
- AWS, GCP, Azure
Skills
- Monitoring
- Monitoring tools like Graphana/DataDog
- TSDB like influxDB/Prometheus
- Infrastructure
- Ansible
- Docker
- K8s
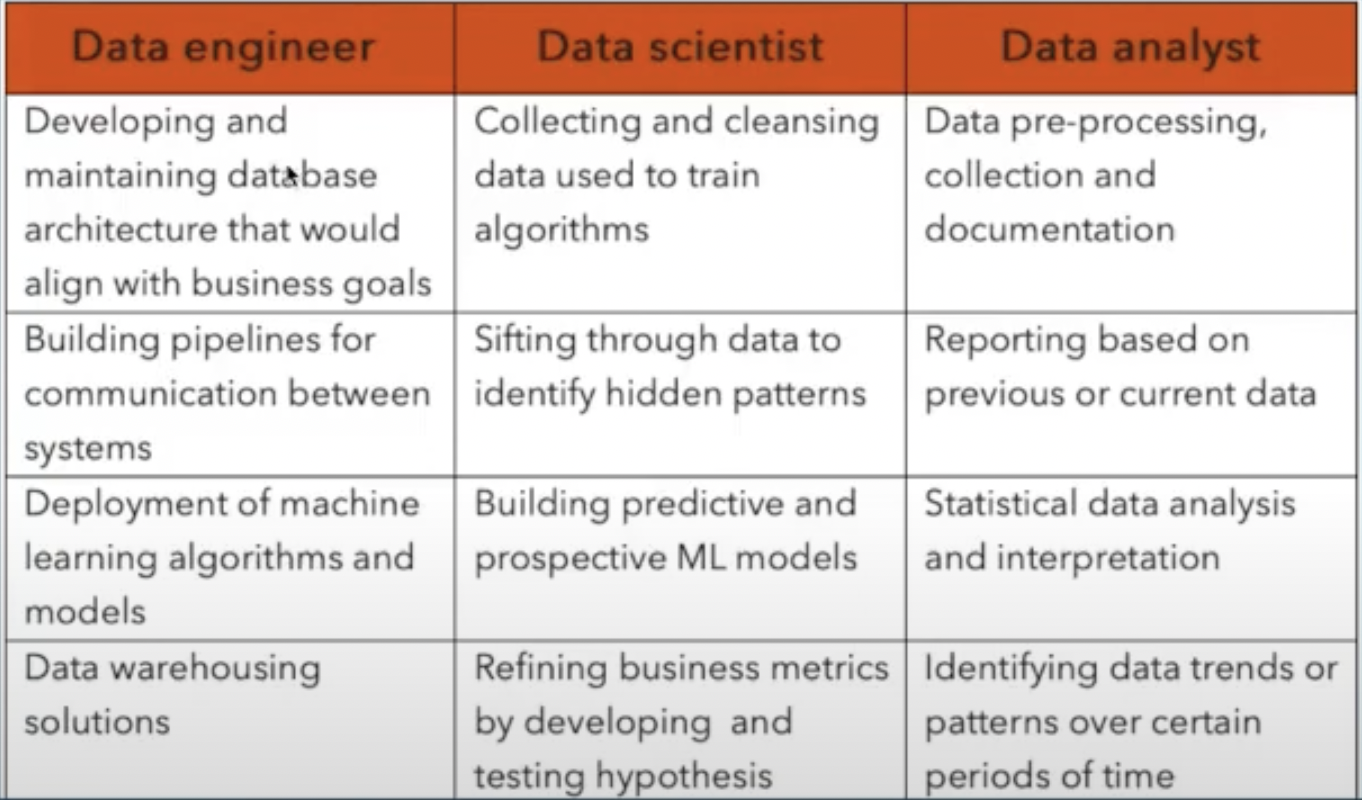
Data Management Roles
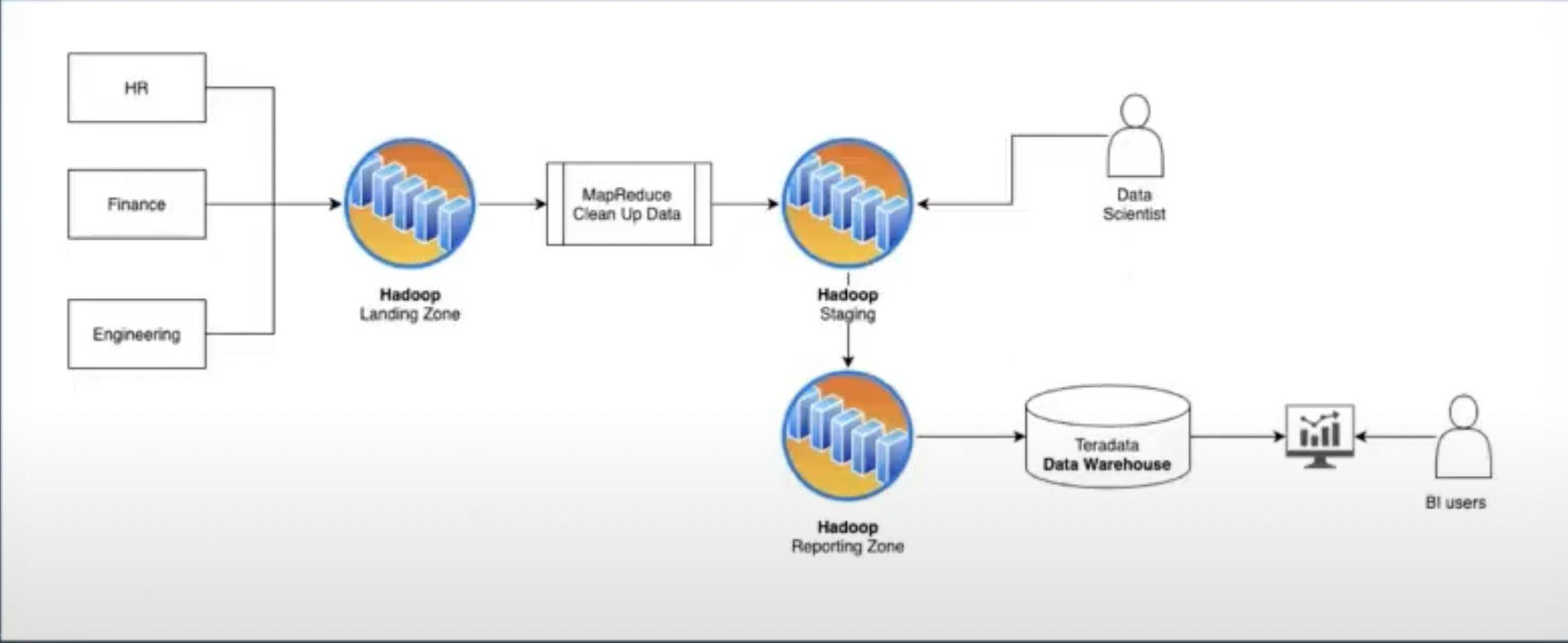
Use case: Batch
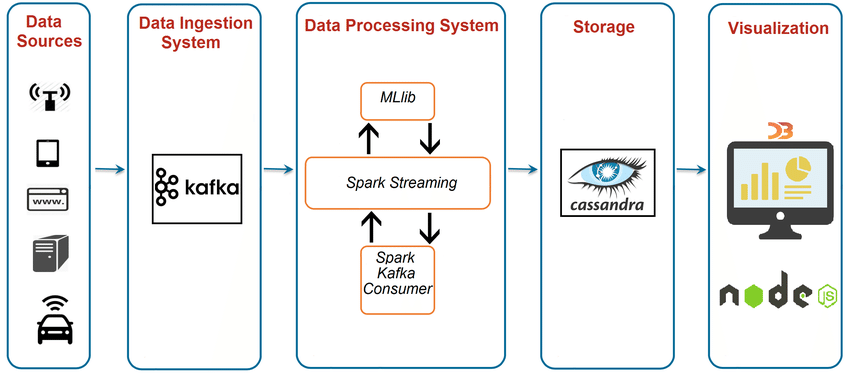
Use case: Streaming
Workflow Management tool
Apache Airflow is a platform to programmatically author, schedule, and monitor workflows.
When workflows are defined as code, they become maintainable, versionable, testable and collaborative.

from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
dag = DAG('tutorial', default_args=default_args, schedule_interval=timedelta(days=1))
# t1, t2 and t3 are examples of tasks created by instantiating operators
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3,
dag=dag)
templated_command = """
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
echo "{{ params.my_param }}"
{% endfor %}
"""
t3 = BashOperator(
task_id='templated',
bash_command=templated_command,
params={'my_param': 'Parameter I passed in'},
dag=dag)
t2.set_upstream(t1)
t3.set_upstream(t1)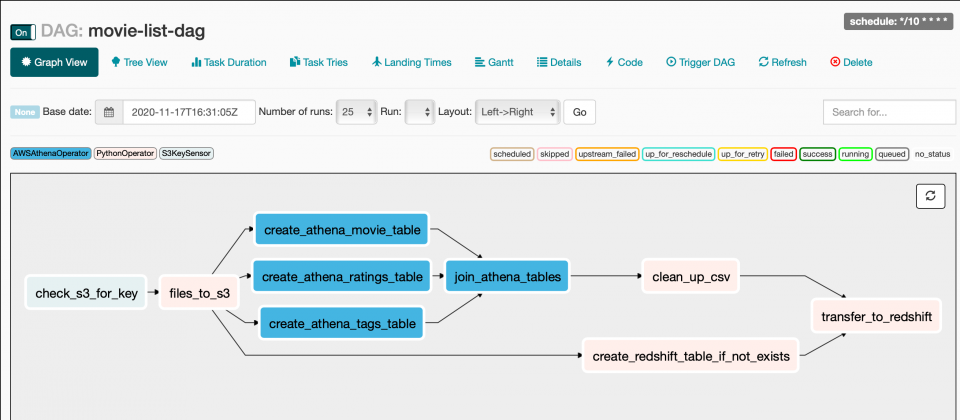
Airflow with AWS tools
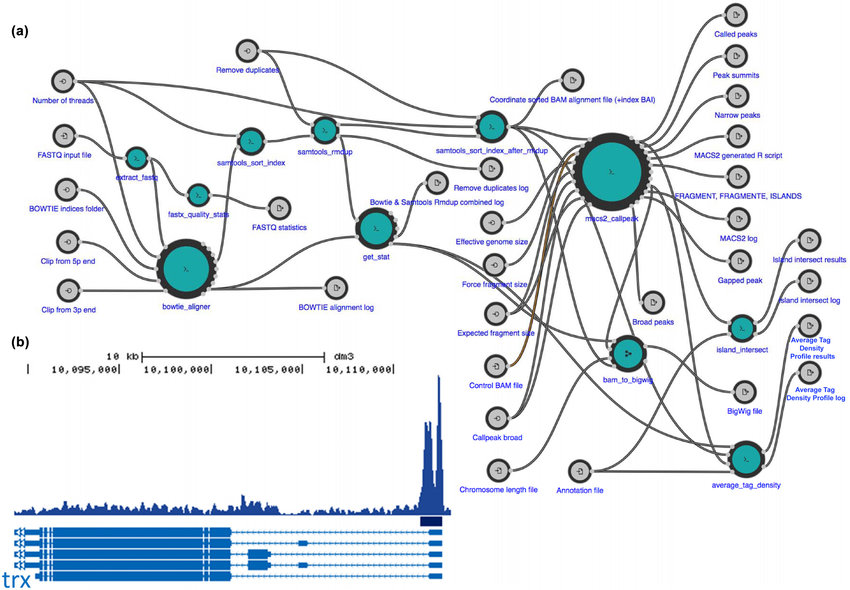
More complex workflow
Data Engineer Interview
Facebook data engineer
- Phone interview with recruiter
- Screening tech interview
- SQL questions
- OA like Leetcode
- Team interview
- Problem solving questions
- SQL programming
- Database design and system design
- Behavior question
Walmart data engineer
- Phone interview with recruiter
- Team interview
- Coding
- Big data system questions
- Data modeling, database design
- Problem solving questions and case study
- ETL and data pipeline
- Math and analytics
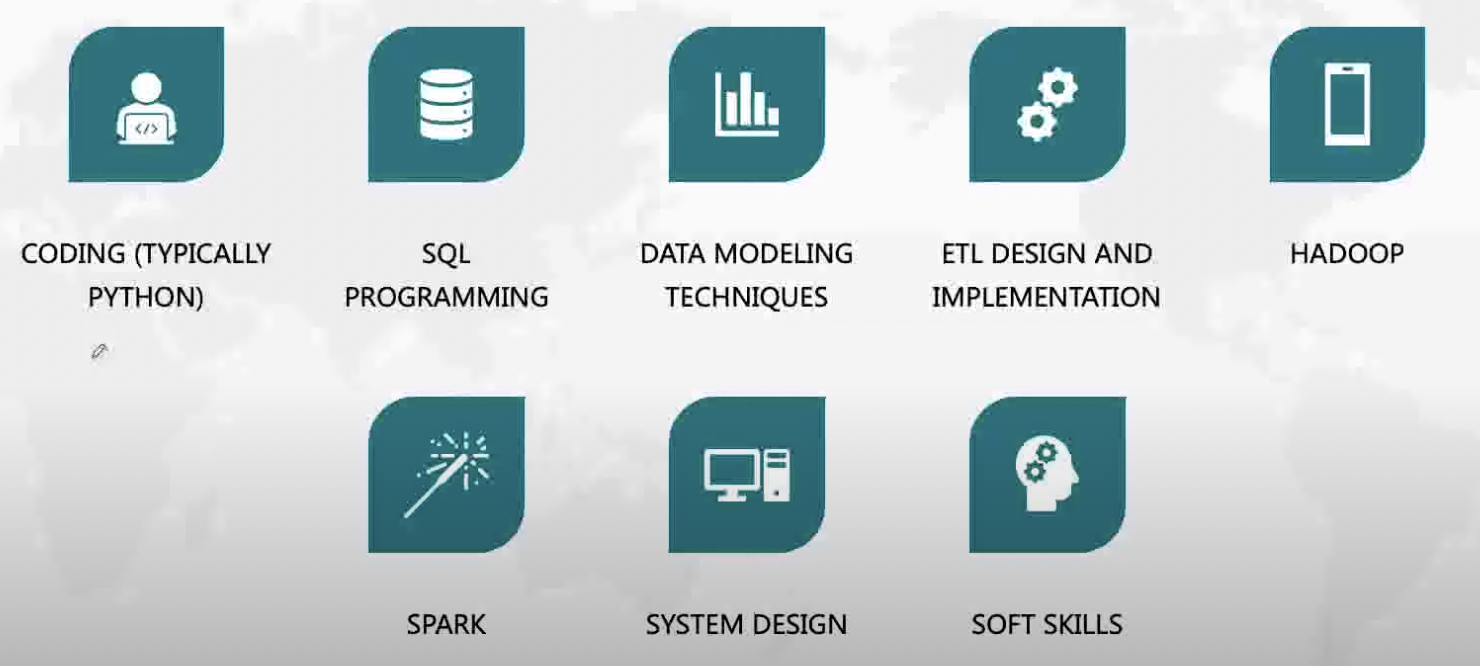
Overview
