Python 網頁爬蟲
- 基礎篇 -
講者:蔡孟軒
日期:2021/5/5
OUTLINE
- 爬蟲介紹
- 爬蟲基本步驟
- 實作
爬蟲介紹
什麼是爬蟲?
- 英文:Web Crawler
- 網際網路 = 蜘蛛網
- 爬蟲 = 蜘蛛
- 幫助抓取網路資料的好幫手
應用
- 比價
- 評價分析
- 趨勢分析
- 各種資料蒐集、分析
你需要有什麼基礎?
- Python 基本語法
- 了解基本網頁架構
- 善用開發人員工具
不厭其煩的心- 應某人要求:請學會看錯誤訊息

爬蟲基本步驟
Install packages
- requests:向網頁伺服器發送請求
- BeautifulSoup4:解析HTML
$ pip install requests
$ pip install beautifulsoup4

傳送請求(requests工作)
回傳 HTML
以 BeautifulSoup4 解析
確認網頁狀態
import requests
url = 'http://www.atmovies.com.tw/movie/new/'
response = requests.get(url)
print(response)- 200 - 請求成功
- 403 - 禁止使用(防爬蟲)
- 404 - 找不到

403應對方法
偽裝成瀏覽器
url = 'https://forum.gamer.com.tw/B.php?bsn=31078'
response = requests.get(url)
print(response)user_agent = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
response = requests.get(url, headers = user_agent)
print(response)
解析HTML
from bs4 import BeautifulSoup #加在程式前面
html_doc = """<html><head><title>Hello World</title></head>
<body><div id="things1">
<h1 id="title">你好</h1>
<a href="#" class="link">This is link1</a></div>
<a href="#link2" class="link">This is link2</a>
<a href="#link3" class="link1">This is link3</a>
</body></html>
"""
# html.parser 的功用就是解析
soup = BeautifulSoup(html_doc, 'html.parser')
# 如果要看解析後整理好的結果
print(soup.prettify())使用抓回來的網站:
13 行 html_doc 改成 response.text
以特定節點(tag)尋找
print(soup.find('title')) # 尋找title標籤的內容
print(soup.find(id = 'title')) # id是title的內容
print(soup.find(href = '#link2')) # href是#link2的內容
print(soup.find('a')) # 尋找第一個a標籤的內容
print(soup.find_all('a', limit=2)) # 尋找a標籤前2個的內容
print(soup.find_all('a')) # 尋找所有a標籤的內容若只要裡面的字在後面加 .text
print(soup.find('title').text)以 CSS selector 尋找
print(soup.select('html')) # 標籤為html的
print(soup.select('h1'))
print(soup.select('a'))
print(soup.select('#title')) # id為title的
print(soup.select('.link')) # class為link的
# 範圍選取class為 things1的div裡面的a
print(soup.select('div.link a'))一樣可以用 limit 控制找到的個數
若只要字一樣在後面加 .text
實作
確認網頁狀態
import requests
url = 'https://artemperor.tw/tidbits'
response = requests.get(url)
print(response)試著自己寫看看吧
解析、取得 HTML
from bs4 import BeautifulSoup #新增在程式上面
response.encoding = 'utf-8' #建議使用怕亂碼
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())with open('example.txt', 'w', encoding = 'utf-8') as f:
f.write(soup.prettify())若要把 html 寫成檔的話,參考如下
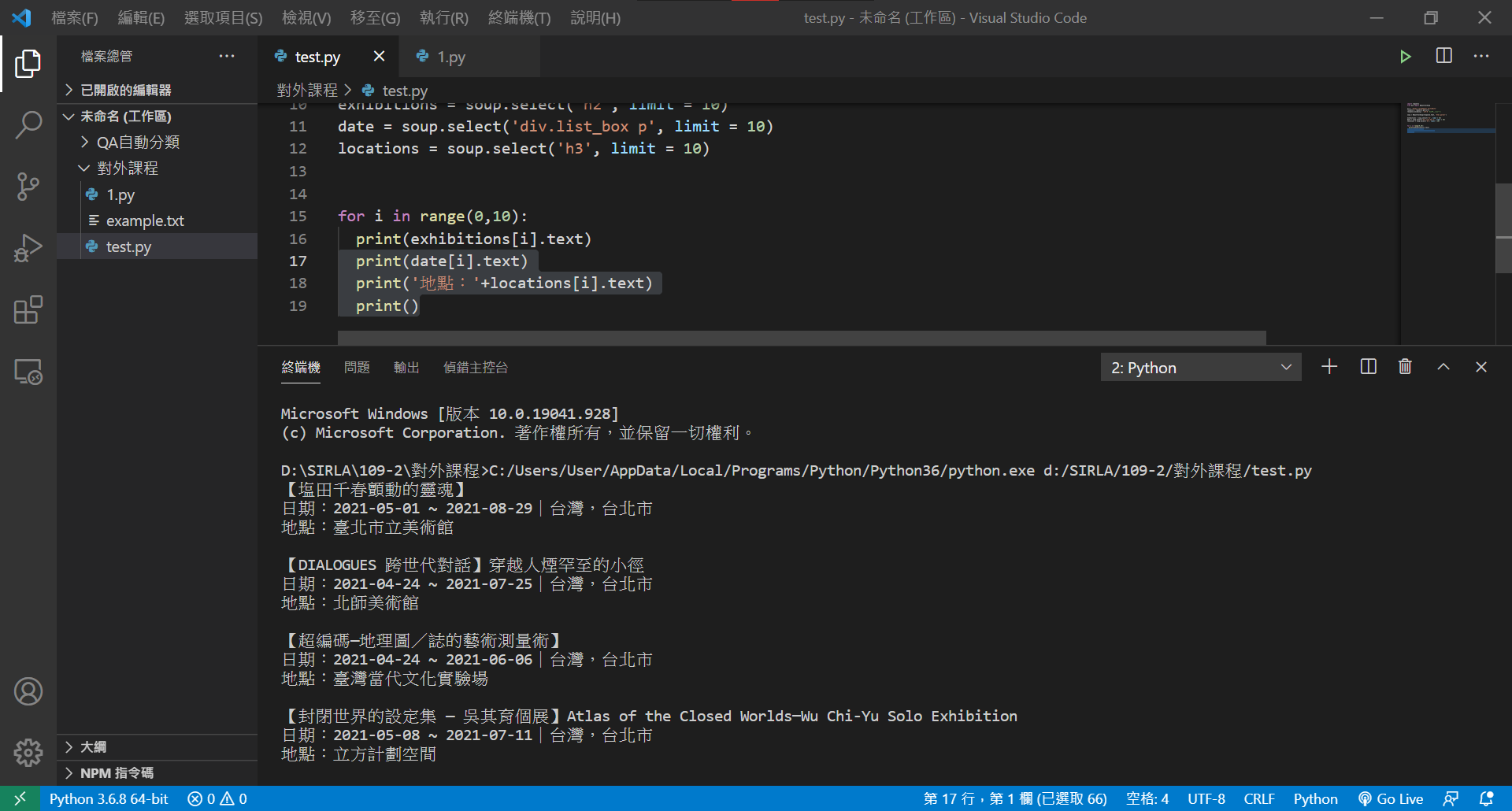
取得展覽名稱
exhibitions = soup.select('h2', limit = 10)
# exhibitions = soup.find_all('h2', limit = 10)
print(exhibitions)
for name in exhibitions:
print(name.text)取得展覽時間、地點
date = soup.select('div.list_box p', limit = 10)
locations = soup.select('h3', limit = 10)
# locations = soup.find_all('h3', limit = 10)
for i in range(0, 10):
...
# 增加
print(date[i].text)
print('地點:'+locations[i].text)
print()試著寫寫看、時間的部分需要注意一下喔
取得網址
href = soup.select('div.list_box figure.tag a', limit = 10)
for i in range(0,10):
...
# 增加
print('詳情:'+ href[i]['href'])
# print('詳情:'+ href[i].get('href'))稍微精簡一下程式
發現剛剛 href 內其實也包含了地點的內容
#刪掉
locations = soup.select('h3', limit = 10)
for i in range(0,10):
...
# 地點那行改成這行
print('地點:' + href[i].h3.text)print(href[0])
# <a href="https://artemperor.tw/tidbits/11245"><h3>臺北市立美術館</h3></a>其實也只少了一行
完整程式碼
import requests
from bs4 import BeautifulSoup
url = 'https://artemperor.tw/tidbits'
response = requests.get(url)
response.encoding = 'utf-8' #建議使用怕亂碼
soup = BeautifulSoup(response.text, 'html.parser')
exhibitions = soup.select('h2', limit = 10)
date = soup.select('div.list_box p', limit = 10)
locations = soup.select('h3', limit = 10)
href = soup.select('div.list_box figure.tag a', limit = 10)
for i in range(0,10):
print(exhibitions[i].text)
print(date[i].text)
print('地點:' + href[i].h3.text)
print('詳情:'+ href[i]['href'])
print()
Reference
- 未具名(2018). Python 使用 Beautiful Soup 抓取與解析網頁資料,開發網路爬蟲教學. Retrieved from: https://reurl.cc/8ymEvo
- 彭彭的課程(2019). Python 網路爬蟲 Web Crawler 基本教學. Retrieved from: https://www.youtube.com/watch?v=9Z9xKWfNo7k
- plusone(2018). Beautiful Soup 解析HTML元素. Retrieved from: https://reurl.cc/raWy3b