C++
IZCC 寒訓 / 星河景中建楓成 - C++


講師
- 建中 225 賴柏宇
- 海之音、小海或其他類似的
- 美術能力見底
- 表達能力差,不懂要問
- INFOR 36th 學術長
這頁是偷來的- 不會C++所以來當C++講師

注意事項
自學 C++ 太苦了 不如 試試女裝


這堂課是來勸退各位的,全名 C++: 從入門到入土
現在轉系還來得及 躺平沒有人會笑你的
寫 C++ 是會越寫越多 Bug 的(確信
Index

const & static
const value, static
常量 const value
- 課堂的一開始先來個簡單的
- const 就是 constant (常數)
- 相對於變數,常量是不可修改的
- 加在變數宣告前面
const int a = 5;- const value 一定要初始化,否則:
const.cpp:4:11: error: uninitialized 'const a' [-fpermissive]
4 | const int a;
|常量 const value
- 除了單純的「不可修改」以外,編譯器也能優化
- 在部分程式語言鼓勵將大部分變數設成常量
- Kotlin 的 val, var 之分
- Rust 的 mut
常量 const value
- 通常我們鼓勵用 const 取代 define 某個值
- 是實際變數,方便 debug
- 反正編譯器如果看你沒取址也會幫你優化
靜態變數 static
- static 關鍵字有好幾個用途,在這邊先講兩種
- 多檔時讓編譯器知道每個 .cpp 檔要有各自的變數
- 作為函數內不消失的變數
靜態變數 static
- 直接看例子:計算函數被呼叫的次數
void func() {
static int cnt = 0;
std::cout << ++cnt << "\n";
}
int main() {
for (int i = 0; i < 10; i++)
func();
}- static 變數不會消失,於是會輸出 1 ~ 10
指標、參考、迭代器
Pointer, Reference, Iterator
指標
- C++ 作為 C 語言的延伸,對記憶體的控制是必要的
- 指標:記憶體的位址,佔八個字節(同 long long)
- 指標看起來的樣子:0xe11b1ff6ec, 0xc78adffafc
- 有些人不喜歡用
運算子
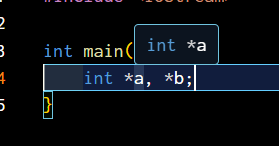
- 宣告:在變數名稱前加上 " * " 表示這是一個指標
int *a, *b;- 之後你看它的型態就會是 int *, char * ...
運算子
- 取址:在一個變數前加 " & ",代表這個變數的位址
int main() {
int a;
std::cout << &a; // 0xbdd19ffe9c
}- 然後聰明你就能想到:可以用指標類的變數存這個
int a;
int *pt_a = &a;運算子
- 取値:在一個指標前面加上 " * "
- 意思是找到該位址儲存的資料
int main() {
int a = 5;
int *pt_a = &a;
std::cout << *pt_a; // 5
}- 要注意第四行的 " * " 和第三行的 " * " 意義不同
- 第三行的 " * ":宣告時代表這是一個指標
- 第四行的 " * ":找到指標儲存的資料
運算子
- 一些注意事項:
- 取址只能對有記憶體位址的東西取
int main() {
int *pt = &5; // compile error
}pointer.cpp:2:20: error: lvalue required as unary '&' operand
2 | int *pt = &5;
|
運算子
- 一些注意事項:
- 不要對指向你不知道地方的指標取值
int main() {
int *pt;
std::cout << pt << "\n"; // 0x8 or something unusual
std::cout << *pt; // runtime error
}運算子
- 一些注意事項:
- 搞清楚乘號與取值符號的分別,必要時用括號
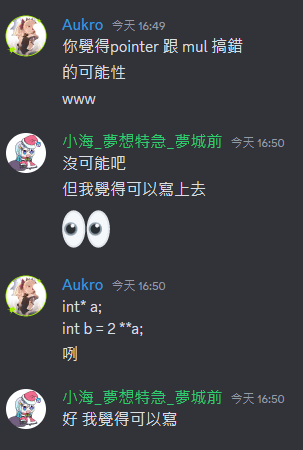
int main() {
int val = 2;
int* a = &val;
int b = 2 * *a;
std::cout << b; // 4
}- 取值符號的優先度大於乘號
小試身手
- 請回答以下程式會輸出什麼
int main() {
int a = 5;
int *pt1 = &a, *pt2 = &a;
std::cout << *pt1 << "\n"; // --- 1.
*pt1 = 1;
std::cout << *pt1 << " " << *pt2 << "\n"; // --- 2.
}- 5
- 1 1
空指標
- NULL (C), nullptr (C++)
- 代表的位置是 0
- 通常代表操作失敗或還沒賦值
int *a = nullptr;
int *b = NULL;指標的...指標?
- 聰明如你,一定想得到既然指標也是一種變數
- 可以拿指標來指另一個指標
- 聽起來很怪
- 宣告方法就像你想的一樣
int main() {
int a = 5;
int *pt_a = &a;
int **pt_pt_a = &pt_a;
std::cout << **pt_pt_a; // 5
}陣列和指標
- 剛剛如果都還能消化,接下來這個也請加油
- 實際上,傳統陣列本身是指標的延伸:
- 陣列是一段連續的記憶體
- 單純使用陣列名字的話相當於陣列頭的指標
int main() {
int a[10];
for (int i = 0; i < 10; i++) a[i] = i;
std::cout << a << "\n"; // 0x1c5d7ff6b0
std::cout << *(a + 5); // 5
}
偷張以前的圖來用
高維陣列
- 聰明如你,一定想得到高維陣列的運作吧
- 二維陣列實際上是一維陣列的陣列
- 二維陣列存的是一堆一維陣列的頭
- 剛剛說一維陣列的頭就是指標
- 二維陣列本身也是指向一維陣列的指標
- 所以二維陣列是指向指標的指標
int main() {
int a[5][5];
for (int i = 0; i < 5; i++)
for (int j = 0; j < 5; j++)
a[i][j] = i * 10 + j;
std::cout << a[2][1] << " " << *(*(a + 2) + 1); // 21 21
}不用特別在乎 反正沒人會這樣用(
運算子
- 指標可以 ++, --, +n, -n
- 會依據指標指向的資料大小決定要移動多少
int main() {
int a;
int *pt_a = &a;
std::cout << pt_a << "\n"; // 0x4ab7fff9c4
std::cout << ++pt_a << "\n"; // 0x4ab7fff9c8
}int main() {
long long a;
long long *pt_a = &a;
std::cout << pt_a << "\n"; // 0x89133ff8d0
std::cout << ++pt_a << "\n"; // 0x89133ff8d8
}void*
- 怪東西
- 前面提到指標只是記憶體的位址
- 不論型別,記憶體的位置形式相同
- 於是這東西就跑出來了
- 可以記錄各種指標,只是型別未定
void*
- 實際來看看怎麼用
int main() {
int a = 8;
void *pt_a = &a;
std::cout << *(int *)pt_a; // 8
}- 取值前須 *顯式* 轉換成對應指標
- 不然編譯器不知道資料怎麼轉換成值

sizeof 運算子
- sizeof 的概念很簡單,告訴你某個變數或者某個類型佔的大小是幾個 char
int main() {
int a;
std::cout << sizeof(a) << "\n"; // 4
std::cout << sizeof(long long) << "\n"; // 8
std::cout << sizeof(void *) << "\n"; // 8
}動態分配空間
- 分配空間在 C++ 有幾種作法
- C: malloc, calloc, realloc (in stdlib.h)
- C++: new (operator)
- 釋放空間也有分
- C: free
- C++: delete
動態分配空間
- 先來看 C 的
- void *malloc(size_t _Size)
- 傳入你需要多少個 char 的空間(搭配 sizeof)
- 回傳一個 void* 指標代表這段空間的開頭
int main() {
int *a = (int *)malloc(sizeof(int));
*a = 5;
std::cout << *a; // 5
int *b;
*b = 5; // runtime error
std::cout << *b;
}- 分配失敗會回傳 NULL
動態分配空間
- calloc 是類似的
- void *calloc(size_t _NumOfElements, size_t _SizeOfElements)
- 傳入需要幾個元素的空間、元素的大小
- 會將空間初始化為 0,常用於分配陣列
int main() {
int *a = (int *)calloc(10, sizeof(int));
std::cout << a[5]; // 0
}- 上面是分配一個大小為 10 的陣列
- 同樣的,分配失敗會回傳 NULL
動態分配空間
- realloc 是指重新分配記憶體
- 如果當前記憶體後面空間還夠分配,就會分配
- 如果不夠會另尋新的記憶體區塊,並把原資料複製並釋放空間
int main() {
int *a = (int *)calloc(10, sizeof(int));
int *b = (int *)realloc(a, sizeof(int) * 20);
if (b == NULL) return 0;
a = b;
}- 通常會建議用一個暫存指標接收重分配後的記憶體指標不然分配失敗就糟糕了
動態分配空間
- 如果你覺得 C 的寫法麻煩,你可以用用看 C++ 的
int *a = new int;- 逆康康,多麼簡潔有力,可讀性大幅提升
- 陣列也是
int *a = new int[10];- 它在做的事情基本上和 malloc, calloc 相同,但
- new 是運算子,可以重載
- new 會呼叫初始化
動態分配空間
- 用完空間記得釋放,不然一直佔著資源不放很麻煩
- 在 C 裡面和 C++ 裡面所使用的方式是類似的:
int *a = (int *)malloc(sizeof(int));
free(a);
int *b = new int;
delete b;- 只用來釋放使用 new 或 malloc 分配的記憶體
pointer.cpp:7:17: warning: 'void operator delete(void*, std::size_t)' called on unallocated object 'a' [-Wfree-nonheap-object]
7 | delete &a;
| ^
pointer.cpp:6:13: note: declared here
6 | int a;
| const
- 指標也是一種變數,它也可以套用 const 關鍵字
- 疑問:指向的對象不能改還是指標不能改?
- 答案是兩種都有,看你怎麼寫
const int val = 5;
const int *ptr_val = &val;
int var;
int* const ptr_var= &var;- 前者是指向對象不可修改
- 後者是指標不可修改
函數指針
- 是,你沒聽錯,函數也是有指針的
int add(int a, int b) {
return a + b;
}
int main() {
int (*func)(int, int) = &add; // & 可省略
std::cout << (*func)(1, 2); // 也可直接呼叫 func(1, 2)
}- 我沒打算細講,因為用這個可讀性是真的差
參考 reference
- 相比指標,單純的參考好理解多了
- C++ 專有
- 變數的「別名」
參考 reference
- 宣告參考:在名字前加上 & 表示這是一個參考
int a = 5;
int &rf_a = a; - 這樣就可以把 rf_a, a 視作同樣的東西了
- 要注意宣告參考時一定要初始化,不加會跳錯

reference.cpp:4:14: error: 'rf_a' declared as reference but not initialized
4 | int &rf_a;
| ^~~~用途
- 只講剛剛那樣聽起來超沒用
- 眾所皆知,C++ 在傳函式參數時不處理會複製參數
- 如果參數資料量大(例如傳一個 vector 進去?)
- 使用參考以避免這個問題
int sum(std::vector<int> &target) {
int result = 0;
for (int i = 0; i < target.size(); i++)
result += target[i];
return result;
}
int main() {
std::vector<int> data(100, 100);
std::cout << sum(data); // 10000
}用途
- 傳過去後視為同一份資料,修改也會動到原本的資料
void modify(int &target) {
target = 5;
}
int main() {
int a = 10;
modify(a);
std::cout << a; // 5
}- 在需要動原資料的情況下,通常選擇參考而非指標
- 可讀性、直覺程度更佳
常量參考 const reference
- 如果不希望不小心戳到原資料,但又不想複製?
- 結合前面說的 const 修飾字,變成常量參考
- 常量參考不只能參考常量,只是代表不能修改而已
int sum(const std::vector<int> &target) {
int result = 0;
for (int i = 0; i < target.size(); i++)
result += target[i];
return result;
}
int main() {
std::vector<int> data(100, 100);
std::cout << sum(data); // 10000
}常量參考 const reference
- 常量參考有一些很神奇的特性
- 可以參考「常量」,包括一般的數字
const int &a = 10;- 看起來很怪異,實際上應該在做以下的事:
const int tmp = 10;
const int &a = tmp;lvalue, rvalue
- 你以為參考只有那樣嗎
- 如果是的話我幹嘛講
- 參考也有分類型,建立在參考對象的類型上
- lvalue: 在 = 左邊的值
- rvalue: 在 = 右邊的值
lvalue, rvalue
- 實際上的分別:identity
- 是否可取址
int a; // a is lvalue
int &b = a; // b is lvalue
a + 1; // a + 1 is rvalue
int func1();
func1(); // func1() is rvalue
int &func2();
func2() = a; // func2() is lvaluervalue reference
- 剛剛講的 reference 只能對左值參考
- 在 C++ 11 以後引入了右值參考 &&
int &&a = 5;- 你說得對,但是有什麼用?
rvalue reference
- 注意到,運算式或者部分函數回傳值也是一種右值
int a = 5, b = 4;
int &&c = a + b;- 當這個回傳值資料量很大時?
std::string a = "very long string";
std::string b = "another very long string";
std::string &&c = a + b;- 這時候,直接參考運算結果就可以省下一次 copy
std::move
- 剛剛講到使用右值參考可以省下 copy 的時間
- std::move 提供將類型強制轉換成右值的方法
int main() {
int a = 5;
int &&b = std::move(a);
b = 1;
std::cout << a; // 1
}- 注意到轉換完後就被視為拋棄了
- 淺層複製
std::move
- 注意 std::move 僅提供移動語意,不包含複製的意味
- 複製到的對象也要支援淺層複製才有用
int main() {
int a = 5;
int b = std::move(a);
b = 1;
std::cout << b << " " << a; // 1 5
}- 像上面這樣實際上還是複製了一次
通用參考 universal reference
- 等等講.jpg
- 這東西通常還會搭配 std::forward
迭代器 Iterator
- 剛剛講完指標,你可能會發現一件事情
- 指標操作起來很麻煩
- 有可能會有危險
- 因此,針對一些情況我們會選用其他東西取代
迭代器
- 迭代器,就是為了存取資料結構內的資料而誕生的
- 同時,因應那些有順序的資料結構,有些也支援++
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
std::vector<int>::iterator it = data.begin();
for (; it != data.end(); it++)
std::cout << *it << " ";
}- STL 的迭代器通常叫 資結類型::iterator
- 不想打那麼長可以用後面提到的 auto
智慧指針
- smart pointer
- Modern C++ 的基礎
- 沒可能講到所以自己加油 owo
物件導向
Object-oriented Programming, OOP
定義及特性
- 具有物件概念的程式設計
- 抽象化 - 對人來說具象化
- 開發時易於維護,可讀性提高
- 擴充功能時更加方便
- 使語意更為清晰
- 減少重複代碼
例子
- 利用程式做一隻貓
- 有身長、體重、毛色...
- 會叫、會吃東西...
- 貓貓會讓人心情變好
- 在不用物件導向的情況下你可能要:

double length, weight, color;
void meow() {
std::cout << "meow";
}
例子
- 一隻還好,如果今天要做十隻呢?
double len1, wei1, color1;
double len2, wei2, color2;
double len3, wei3, color3;
...
void meow() {
std::cout << meow;
}- 沒事,大不了用陣列?
- 我只是想透過這個例子,說明如果不用會有很長的 Code 跑出來而已
一起處理
- 對於這種重複、類似的東西,最好一起處理
- 於是,我們將一隻貓所具備的東西包在一起!
- 這樣,另一個好處就體現出來了
- 如果今天想要多記錄一個屬性,就丟進這個包裡
身長
體重
顏色(R, G, B)
我會喵喵叫而且很可愛喔
貓
具體來說...
- 在比較基礎的物件導向之中,我們有幾個主要概念
- 類(Class):藍圖
- 類別屬性(Class Attribute):設計預定的材料
- 物件(Object):類的實例(Instance)
- 物件屬性(Object Attribute):實際製作的材料
- 類(Class):藍圖
類(Class)
- 藍圖
- 定義了一種物件該具備的特性
- 關鍵字 class
- 直接使用大括號包住各種東西
- 裡面變數稱為類屬性或稱屬性
- 包在裡面的函式稱為方法
- 注意最後要分號
- 習慣首字母大寫
class Cat {
double length;
double weight;
double color;
void meow() {
std::cout << "meow";
}
};
class Dog {
double length;
double weight;
double color;
void bark() {
std::cout << "woof";
}
};物件(Object)
- 實例
- 定義完一個東西怎麼做後,將成品做出來
- 每個成品會分別具有各自的屬性(Member 成員)以及方法(成員函式)
- 將已經定義的類當作一種新的變數型別來用
class Cat {
double length;
double weight;
double color;
void meow() {
std::cout << "meow";
}
};
int main() {
Cat cat1, cat2;
}成員
- 剛剛將物件做出來後,要怎麼調用裡面的成員?
- 在那之前我們需要知道物件導向的特性:封裝
- 一個物件不會希望可以亂動裡面的資料
- 如果自己寫自己動還好,其他人亂動呢?
- 如果動一動出現了不合理的數據?
- 所以成員會有權限上的分別
成員分類
| public: 公有成員 | protected: 受保護 | private: 私有成員 |
|---|---|---|
| 外部可存取 | 外部不可存取 | 外部不可存取 |
| 衍生類可存取 | 衍生類可存取 | 衍生類不可存取 |
- 衍生類等等會講到
- 還有一種特殊的...權限?叫 friend,一樣等等講
- 要使用不能動的資料時會透過函式
寬鬆
嚴格
成員分類
- 在權限關鍵字後到下一個權限關鍵字前都是同一種權限
- 預設是 private
- 要從外部存取成員使用 '.'
class Cat {
private:
double length;
double weight;
double color;
public:
void meow() {
std::cout << "meow\n";
}
};
int main() {
Cat cat;
cat.meow(); // meow
}成員分類
- 如果是指標呢?
- 每次先取值再取成員很麻煩
- 用 -> 運算子
class Cat {
private:
double length;
double weight;
double color;
public:
void meow() {
std::cout << "meow\n";
}
};
int main() {
Cat *cat;
cat->meow(); // meow
}違規存取成員
- 如果違規從外部存取 private 或者 protected 成員會跳錯
- 錯誤訊息 / VScode 偵錯:
cat.cpp: In function 'int main()':
cat.cpp:17:26: error: 'double Cat::color' is private within this context
17 | std::cout << cat.color;
| ^~~~~
cat.cpp:7:16: note: declared private here
7 | double color;
| ^~~~~
內部存取
- 剛剛說外部用 '.' 運算子存取,內部函式怎麼調用?
- 什麼都不用加
class Cat {
private:
double length;
double weight;
double color;
public:
void print_data() {
std::cout << length << " "
<< weight << " "
<< color << "\n";
}
};
int main() {
Cat cat;
cat.print_data();
}this
- 有些人可能覺得剛剛那樣很不直覺
- this: 自己的指標
- 這樣可以用 this->member 有些人看了比較舒服
- 可以拿來判斷是不是在操作自己...之類的
static 成員
- 有時候,類會有一些重複的資訊或者想共用的資訊
- 某些表格、數據之類的
- 類似於函式的 static,我們可以讓變數永久存於類中
class TicTacToe {
static const char self = 'O', opp = 'X';
...
};static 成員
- 然而,由於 C++ 的怪特性
- 你在裡面打了 static 變數,實際上並沒有真的定義
- 需要在 class 外面實際將它定義出來
- 剛剛講了從外部取得物件成員的方法,類怎麼辦?
- 用 ::
class TicTacToe {
static char self = 'O', opp = 'X';
...
};
char TicTacToe::self = 'O', TicTacTor::opp = 'X';static 成員
- 在 C++ 17 以後,可以在宣告那行加上 inline 關鍵字
class TicTacToe {
inline static char self = 'O', opp = 'X';
...
};- 這樣相當於在這行完成宣告 + 定義
:: 範圍解析運算子
- 範圍解析,代表它負責識別不同範圍中可能同名的東西
- 它可以取得「在類中的定義本身」
- 一個有用的例子例如在 class 中開 class
class vector {
class iterator {
...
};
...
};
int main() {
vector<int>::iterator it;
}static 成員
- 除了變數,成員函式也可以用 static
class TicTacToe {
static int use_cnt;
public:
static void print_cnt();
};
int TicTacToe::use_cnt = 0;
void TicTacToe::print_cnt() {
std::cout << TicTacToe::use_cnt << "\n";
}- 這樣可以直接透過 class 呼叫:
int main() {
TicTacToe::print_cnt();
}static 成員
- 當然,這樣做是有限制的
- 沒有 this 可用,因為這屬於 class 本身
- 只能調用 static 成員
const 函式
- 對於 const 物件,如果呼叫成員函式可能會發生什麼?
class A {
int a = 5;
public:
void modify() {
a = 10;
}
};
int main() {
const A const_object;
const_object.modify();
}- 如果函式裡修改到東西,就會產生矛盾
const 函式
- 很顯然,我們的編譯器不會讓這種事情發生
- 既然改了會出事,那就別改好了?
- 因此我們需要 const 函式
class A {
int a = 5;
public:
void print() const {
std::cout << a << "\n";
}
};
int main() {
const A const_object;
const_object.print();
}const 函式
- 除了不能更改物件內部的成員以外沒啥限制
初始化及建構子
- 大多數時候,我們會希望變數有預設的值
- 好辦事
- 好偵錯
- 所以我們會幫變數「初始化」
int a = 5;
int a(5);- 上面兩行等價
- 賦值和初始化在 C++ 裡是兩個不同的概念
初始化及建構子
- 那麼,如何幫一個物件初始化?
- 使用建構子 constructor
- 常見的例子:
std::vector<int> a(5, 0);- 在類裡可以自己定義
- 一個類可以有多種不同的建構子
建構子
- 拿盒子來舉例
- 冒號後面實際上也在做變數的初始化 / 呼叫類的建構子
class Box {
int length;
int width;
int height;
public:
Box(int _l, int _w, int _h)
: length(_l), width(_w), height(_h) {}
Box(int _l)
: length(_l), width(_l), height(_l) {}
};建構子
- 因為是個函式,所以可以做其他事情
class Box {
int length;
int width;
int height;
public:
Box(int _l, int _w, int _h)
: length(_l), width(_w), height(_h) {
std::cout << "Box: "
<< length << ", "
<< width << ", "
<< height << "\n";
}
};解構子
- 有建構子同樣也有解構子
- 在物件消失時呼叫
class Box {
int length, width, height;
public:
~Box () {
std::cout << "A box disappreared.\n";
}
};
int main() {
Box test;
}運算子多載
- 有時候,我們會希望物件也可以有運算子,方便操作
- 舉個簡單的例子:複數、向量、矩陣等
- C++ 提供了實作函式的方法重載運算子的功能
class complex {
double Re, Im;
public:
complex(double _Re, double _Im)
: Re(_Re), Im(_Im) {}
complex operator+(const complex& another) {
return {Re + another.Re, Im + another.Im};
}
};運算子多載
- 一元運算子:只需要一個對象來運算的運算子
- !, ~ 等等
- 二元運算子同理:需要兩個對象運算
- +, -, *, / , %, []...
- 這兩種運算子重載的方法很類似,只有參數數量的區別
運算子多載
- 一元運算子
class complex {
double Re, Im;
public:
complex(double _Re, double _Im)
: Re(_Re), Im(_Im) {}
complex operator-() {
return {-Re, -Im};
}
};- 二元運算子
class complex {
double Re, Im;
public:
complex(double _Re, double _Im)
: Re(_Re), Im(_Im) {}
complex operator-(const complex& another) {
return {Re - another.Re, Im - another.Im};
}
};運算子多載
- ++ 和 -- 稍微特別一點
- 這兩種都有分成前置和後置 (++C, C++)
- 直接看微軟上的教程:

- 差別在於引數的 int 是否存在
- 回傳值是否使用參考通常我們也會設成上面那樣
運算子多載
- 還有另一個很特別的運算子()
- 它讓物件具有函數一般的功能
class Cmp {
public:
bool operator()(int a, int b) {
return a < b;
}
};
int main() {
Cmp cmp;
std::cout << cmp(1, 2);
}友元 (friend)
- 有時候設 private 太嚴格不方便操作,但又不得不設
- 這時候,開放特定函式或者類使用東西是個好方法
- 不可避免地破壞了封裝性
- 但有時候這麼做是必要的
友元 (friend)
- 友元的概念很簡單,只要我認證你是我的朋友,那我的東西都可以給你用
- 朋友之間還是要遵守使用規範
- 因此,在自己的類裡面宣告怎麼用或者誰是朋友
友元 (friend)
- 友元可以分成兩種:class (類) 和 function (函式)
- class 需要在先前被宣告,然後在類裡面宣告為 friend
class Human;
class Bot;
class TicTacToe {
private:
char board[3][3];
public:
friend class Human;
friend class Bot;
};友元 (friend)
- 友元可以分成兩種:class (類) 和 function (函式)
- function 同樣需要在類裡面宣告,但是實作可以在外面
- 需要再將操作目標傳入一次
class complex {
double Re, Im;
public:
complex(double _Re, double _Im)
: Re(_Re), Im(_Im) {}
friend std::ostream& operator<<(std::ostream& out, const complex& target) {
out << target.Re << " + " << target.Im << "i";
return out;
}
};
int main() {
complex a(1, 2);
std::cout << a;
}友元 (friend)
- 然而,與現實世界不同的是,friend 並不是雙向的
- 當 A 宣告 B 為朋友時,A 不一定能直接存取 B 的內容
繼承
- 有時會有很多共通點但是又不一樣的類
- 透過共通特性繼承,可以減少重複的代碼
- 舉個例子:貓和狗都是動物,但行為不同
身長
體重
顏色(R, G, B)
動物
喵喵叫
貓
汪汪叫
狗
繼承
- 「動物」這樣共通的部分稱為基類 (Base Class)
- 「貓」「狗」這樣繼承自基類的類稱為衍生類 (Derived)
- 基類的權限會影響衍生類是否能使用
| public: 公有成員 | protected: 受保護 | private: 私有成員 |
|---|---|---|
| 外部可存取 | 外部不可存取 | 外部不可存取 |
| 衍生類可存取 | 衍生類可存取 | 衍生類不可存取 |
寬鬆
嚴格
繼承
- 繼承也有分 public, protected, private
- 依據繼承類型的不同,基類繼承過來後的權限也會變動
| public: public | protected: protected | private: 無法存取 |
public 繼承
| public: protected | protected: protected | private: 無法存取 |
protected 繼承
| public: private | protected: private | private: 無法存取 |
private 繼承
基類成員權限: 繼承後權限
繼承方式
繼承
class Box {
protected:
int length;
int width;
int height;
};
class Gift_box : public Box {
int gift_type;
};- class 後面冒號加上繼承方式、繼承自誰
多重繼承
- 另外,C++ 是可以多重繼承的
- 不常用
- 過於複雜
- 詳細的繼承原理我不清楚,好像和 bfs / dfs 多少有點關係
class A: public B, private C {
...
};多型
- 繼承的好處是可以把它當作原本的類一樣使用
class Bot {
};
class Bot1 : public Bot {
};
class Bot2 : public Bot {
};
void run(Bot &bot);- 這樣可以傳入不同的類,接受不同的實作
- 以上面為例,傳入的 bot 可以是 Bot1 或 Bot2
多型
- 然而,在用函式時有一些問題存在:
class Bot {
public:
void hello() {
std::cout << "hello, world!";
}
};
class Bot1 : public Bot {
public:
void hello() {
std::cout << "hello, world! I'm bot1\n";
}
};
void run(Bot &bot) {
bot.hello();
}
int main() {
Bot1 test_bot;
run(test_bot);
}- 上面這段程式會輸出什麼?
多型
- 我們知道在函式撞名時會依照參數型別決定使用何者
int add(int a, int b) {
return a + b;
}
std::string add(const std::string &a, const std::string &b) {
return a + b;
}
int main () {
std::cout << add(1, 2) << "\n"; // 3
std::cout << add("apple", "banana") << "\n"; // applebanana
}- 上面就是靠 int, string 的分別來判斷的
多型
- 然而,在我們一開始的情況型別是一模一樣的
- 怎麼判斷?
- 你預期應該要是什麼?
- C++ 預設在實作上對於 method 是儲存函式指針
- Pre-Binding
- 直接看型別呼叫
- 不想要怎麼辦?
虛擬函式 Virtual Funciton
- C++ 透過 Virtual Table 實現了這東西
- Dynamic Binding
- 具體來說,C++ 的虛擬函式會在運行期才綁定,所以可以是衍伸類的函式
class Bot {
public:
virtual void hello() {
std::cout << "hello, world!";
}
};
class Bot1 : public Bot {
public:
virtual void hello() {
std::cout << "hello, world! I'm bot1\n";
}
};
void run(Bot &bot) {
bot.hello();
}
int main() {
Bot1 test_bot;
run(test_bot);
}虛擬函式 Virtual Funciton
- 因為可以留到運型期才綁定,所以誕生了另一個東西
- Pure Virtual Function 純虛擬函式
class Bot {
public:
virtual void hello() = 0;
};- 在基類不實作,衍伸類一定要實作,否則會編譯錯誤
class.cpp:13:14: error: cannot declare variable 'test_bot' to be of abstract type 'Bot1'
13 | Bot1 test_bot;
| ^~~~~~~~
class.cpp:9:7: note: because the following virtual functions are pure within 'Bot1':
9 | class Bot1 : public Bot {
| ^~~~
class.cpp:6:22: note: 'virtual void Bot::hello()'
6 | virtual void hello() = 0;虛擬函式 Virtual Funciton
- 這兩個的用途有點像是提供一個 interface (介面)
- 純虛擬函式:要你實作這個函式,不管你怎麼實作
- 虛擬函式:你可以實作這個函式,不實作就用我的
override
- 然而,這麼做有個小問題
- 手殘怎麼辦
class Bot {
public:
virtual void say(std::string &output) {
std::cout << output << "\n";
}
};
class Bot1 : public Bot {
public:
virtual void say(const std::string &output) {
std::cout << output << "\n";
}
};override
- 我們貼心的 C++ 提供了 override 幫助會在編譯時檢查
class Bot {
public:
virtual void say(std::string &output) {
std::cout << output << "\n";
}
};
class Bot1 : public Bot {
public:
virtual void say(const std::string &output) override {
std::cout << output << "\n";
}
};class.cpp:13:22: error: 'virtual void Bot1::say(const std::string&)' marked 'override', but does not override
13 | virtual void say(const std::string &output) override {
|- 比起手殘或眼殘 這樣顯然好多了
auto, 泛型 / 模板
auto, generic programming / template
強型別
- 眾所周知,C++ 是一種強型別的語言
- 參數的型別必須完全符合才能操作各種東西
- 有時候很麻煩
強型別
- 舉個例子:
int add(int a, int b) {
return a + b;
}
std::string add(const std::string &a, const std::string &b) {
return a + b;
}- 你在做一樣的事,但型別不同,所以必須複製一遍然後把型別改掉
- 不覺得很煩嗎
模板 template
- 於是,模板 template 誕生了
- 用一個假想的類別先替換掉那些我們會用到的類別
template <typename T>
T add(const T& a, const T& b) {
return a + b;
}- 編譯器在編譯時會自動幫我們替換掉型別
- 模板元編程
模板 template
- 以下列程式舉例:
template <typename T>
T add(const T& a, const T& b) {
return a + b;
}
int main() {
std::cout << add<int>(1, 2) << "\n";
std::cout << add<std::string>("apple", "banana") << "\n";
}模板 template
- 等價於:
int add(const int &a, const int &b) {
return a + b;
}
std::string add(const std::string &a, const std::string &b) {
return a + b;
}
int main() {
std::cout << add(1, 2) << "\n";
std::cout << add("apple", "banana") << "\n";
}模板 template
- template<typename T, typename T1, ...>
- template 表示模板列表
- typename 表示後面接的是某個型別
- T, T1 表示某個型別,取名隨便
- 可以丟在函數或類前面
模板 template
- 把 T 當作一般的型別來用就可以了
template <typename T>
class array {
T* data;
public:
T& operator[](int index) {
return *(data + index);
}
};模板 template
- 在實際使用時在後面加上 <實際型別>
int main() {
std::vector<int> array;
}- 有些時候編譯器很聰明可以自己判斷
template<typename T>
T add(T a, T b) {
return a + b;
}
int main() {
std::cout << add(1, 2);
}模板 template
- 除了一般的 typename + 型別,也可以用傳參數進去
template <typename T, const int SIZE>
class array {
T* data;
public:
T& operator[](int index) {
if (index < SIZE && index >= 0)
return *(data + index);
}
};- 不過有些東西又不行,反正很玄(
通用參考 universal reference
- 連結一下前面我們提到的盡量不複製的概念
- 盡可能地寫參考
- 可是用 const reference 常常還是會複製欸
- 所以左值參考和右值參考要寫兩次?
通用參考 universal reference
- 用 const reference 可以參考左值也可以參考右值
- 用 universal reference 也可以
- 寫法和右值引用很像,不過只在 template 等無法確定類型的情況下才是通用參考
template<typename T>
void print(T&& target) {
std::cout << target << "\n";
}
int main() {
int a = 4;
print(a);
print(1);
}通用參考 universal reference
- 不過用 universal reference 會有個小問題
- 完美轉發
class BotData {
};
class Bot {
public:
Bot(const BotData&) {
std::cout << "construct by copy\n";
}
Bot(BotData&&) {
std::cout << "construct by move\n";
}
};
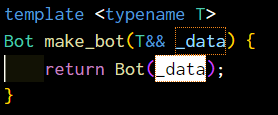
template <typename T>
Bot make_bot(T&& _data) {
return Bot(_data);
}
int main() {
BotData lvalue;
make_bot(lvalue);
make_bot(BotData()); // rvalue
}通用參考 universal reference
- 怎麼會這樣?怎麼會都變成左值?
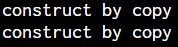
- 參數傳進來,然後使用時就被視為左值了
通用參考 universal reference
- 這種時候,如果要使用原本的型態怎麼辦
- 使用 std::forward
- 如果傳進來是左值,它會將它變成左值
- 如果傳進來是右值,它會將它變成右值
- 蛤?
- 試試就知道
通用參考 universal reference
...
template <typename T>
Bot make_bot(T&& _data) {
return Bot(std::forward<T>(_data));
}
...
int main() {
BotData lvalue;
make_bot(lvalue);
make_bot(BotData()); // rvalue
}- 修改後的 output:
construct by copy
construct by move不定長度引數
- 講到模板,在 C++ 裡面模板能帶的型別可以很複雜
template <typename T>
void print(T&& target) {
std::cout << target;
}
template <typename T, typename... Ts>
void print(T&& target, Ts&&... Args) {
std::cout << target << " ";
print(std::forward<Ts>(Args)...);
}- 順帶一提 ... 是我看過數一數二玄的東西(?
不定長度引數
- 講一點用法就好
- template<typename T, typename... Args>
- typename... 表示剩下的那些參數
- Args 仍然是一種型別
不定長度引數
- 我們可以利用 sizeof... 取得引數長度
template <typename... Ts>
void print(Ts&&... Args) {
std::cout << sizeof...(Args);
}
int main() {
print(1, 2, 3, 4, 5); // 5
}不定長度引數
- 利用 ... 可以「解包」
- 所謂解包,就是將 Args 型態恢復成 a, b, c 的型態
- 所以,可以利用函式遞迴來解包
template <typename T>
void print(T target) {
std::cout << target;
}
template <typename T, typename... Ts>
void print(T target, Ts... Args) {
std::cout << target << " ";
print(Args...);
}不定長度引數
- 這樣寫就可以完美地將東西解包又不複製
template <typename T>
void print(T&& target) {
std::cout << target;
}
template <typename T, typename... Ts>
void print(T&& target, Ts&&... Args) {
std::cout << target << " ";
print(std::forward<Ts>(Args)...);
}
int main() {
print(1, "XD", 3.1416);
}不定長度引數
- 剛剛那樣編譯器實際上做了什麼?
- 編譯器實際上編譯出了以下函式:
- print<int, (const char*, double)>
- print<const char*, (double)>
- print<double>
- 然後在一邊遞迴一邊呼叫對應函式
auto
- auto 實際上是來自 C 的一個關鍵字
- C 中 auto 的定位和 register / static / extern 是類似的
- 如果不特別聲明,所有變數都是 auto
// auto.c
int main() {
auto int a = 5; // 等同 int a = 5;
printf("%d\n", a);
}- 然而,因為沒必要寫出來,所以 C++ 廢物利用了一下
- 上面那段程式放到 C++ 是不會過的,因為字義不同
auto
- C++ 中,auto 代表「自動推斷型別」
- 什麼意思?
int main() {
auto a = 4;
auto b = std::string{} + "apple" + "banana";
std::cout << a << " " << b;
}- 你會發現,a 自動被推斷成 int,而 b 自動被推斷成 std::string 了

auto
- 這東西有什麼用?
- 這東西超好用的好嗎
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
auto it = data.begin();
}- 你會發現 it 的型別應該是 std::vector<int>::iterator
- 現在一個 auto 就可以解決了
- 在編譯器有辦法推斷型別的情況下都能用 auto
auto
- 在 C++20 以後,我們可以使用一些更酷的東西
- 函數回傳值可以用 auto (C++20 以前就可以)
- 函數參數可以用 auto (C++20 新增)
auto add(auto a, auto b) {
return a + b;
}- 實際上背後還是模板
template<typename T1, typename T2>
auto add(T1 a, T2 b) -> decltype(a + b) {
return a + b;
}
auto
- 其他用途像是寫你根本懶得鳥是什麼型別的東西
int add(int a, int b) {
return a + b;
}
int main() {
auto func = add;
}decltype
- 自動推導型別時可以拿來輔助,使語意更清晰
template<typename T1, typename T2>
auto add(T1 a, T2 b) -> decltype(a + b) {
return a + b;
}
宏、標頭檔、命名空間
macro, header file, namespace
宏
- 預處理器登場
- 預處理器大致上就是在處理所有 # 開頭的東西
- #include
- #define
- #ifdef
- #endif
- ...
宏
- 所謂 macro 就是在預處理器裡存在的一種酷東西
- 可以把它當成某種只在預處理器存在的變數
- macro 的操作可以很炫炮,但我不會
#define
- 定義一個宏
- 可以加代表值,可以不加
#define INF 0x7FFFFFFF
#define RANDOM- 如果在程式碼裡有對應的宏會替換掉
#include <iostream>
#define INF 0x7FFFFFFF
int main() {
std::cout << INF;
}#if, #endif
- 就是預處理的 if()
- 可搭配 defined()
- 如果條件成立,#if 底下的程式碼會被編譯
#if defined(X)
...
#endif- 合併一下變成 #ifdef
#ifdef X#elif, #else
- 就是 else if 和 else
- 應該不用我解釋吧
#if __cplusplus >= 202000
do something...
#elif __cplusplus >= 201700
do something...
#else
do something...
#endif#undef
- 註銷前面定義出來的宏
#define X 5
...
#undef X宏
- 然後你就可以玩出這種花樣
- 特別好玩,但我不會

宏
- 除了一般替換掉字詞之外,宏很常用來 debug
#include <iostream>
#define DEBUG
int main() {
int a = 5;
#ifdef DEBUG
std::cout << a;
#endif
}宏
- 宏也可以定義簡單的函數,使語意明確
#include <iostream>
#define lowbit(x) (-x & x)
int main() {
std::cout << lowbit(6);
}標頭檔
- 然而,宏最大的用處是在多檔案時
- 開發專案時,常常會有很多需要重複利用的東西
- 寫在同一個檔案聽起來是個好主意
- 標頭檔 (header file) 就是這樣的產物
標頭檔
- 共用同一個檔案有很多好處
- 修改一處就可以動到所有用到的地方
- 方便溝通和傳遞
- ...
標頭檔
- 將標頭檔的內容引入使用 #include
#include "game_act_type.hpp"- 在 C++20 以後有個酷東西叫 module
- 我也還不熟
- 和標頭檔不太一樣
- 減少編譯時間
.h, .hpp
- 在 C, C++ 中,我們選用 .h 作為標頭檔的副檔名
- 在 C++ 中多了一個 .hpp 檔
- 差別
- .h 檔主要只負責宣告,宣告變數、函式、類...
- .hpp 檔通常還包含實作
- 然而,在多檔案時會有點問題
.h, .hpp
a.hpp
const int a = 5;b.hpp
#include "a.hpp"c.cpp
#include "a.hpp"
#incldue "b.hpp".h, .hpp
In file included from b.hpp:1,
from c.cpp:2:
a.hpp:1:11: error: redefinition of 'const int a'
1 | const int a = 5;
| ^
In file included from c.cpp:1:
a.hpp:1:11: note: 'const int a' previously defined here
1 | const int a = 5;
|- 這是編譯 c.cpp 的結果
- 因為在 a.hpp, b.hpp 中分別有一個 'a',是重複定義
.h, .hpp
- 這麼做看起來就很笨,但想想更複雜的情況
- 好像確實會用到三角形或菱形 #include
- 怎麼辦?
- 用我們前面說的宏
.h, .hpp
- #ifndef
- 其實就是 if not defined
- 我們在 a.hpp 中做點修改:
#ifndef _A_HPP_
#define _A_HPP_
const int a = 5;
#endif- 這樣就不會重複編譯到了
- 通常我們會對每個標頭檔這麼做
命名空間 namespace
- 剛剛既然提到跨檔案就不得不提命名空間
- 熟悉的 std 就是一種命名空間
namespace Sea {
bool is_Sea_weak() {
return true;
}
}- 用來區隔不同領域的函式、類等等
命名空間 namespace
- 舉個例子
- 公司 A, B 可能都有海之音這個人
- 如何確定海之音是來自公司 A 或公司 B?
- A::海之音 或 B::海之音
- 範圍解析運算子又派上用場了
命名空間 namespace
- 命名空間的宣告:
namespace Sea {
}- 因為只是將物件 / 變數 / 函式歸類,操作並不複雜
一些小魔法
other strange things
使用 for 迴圈遍歷
- 你厭倦了只能用 index 對陣列遍歷的寫法嗎
- 我也是
- 所以用更好看的方法吧
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
for (int i : data)
std::cout << i << " ";
}- 基本上 stl 裡你覺得能這樣跑的東西都能這樣做
使用 for 迴圈遍歷
- 如果每一項都很大,或者要修改建議搭配參考
- 如果型別很長建議搭配 auto
int main() {
std::vector<std::vector<int>> graph;
for (auto &v : graph)
v.resize(5);
}解包
- 對於 tuple - like 的物件,可以使用 [ ] 來解包
- 常見例子像是 pair
int main() {
std::pair<int, int> nums(1, 2);
auto [i, j] = nums;
}- 其他例子像是一般物件