Compiladores
Compilador
Compilador
Programa objeto
Errores generados
Programa fuente
- Compilador: programa que toma como entrada un programa escrito en lenguaje fuente, y lo traduce en un programa objeto equivalente.
Durante este proceso, el compilador informa al usuario si hay errores en el programa fuente para su respectivo ajuste.
Estructura del lenguaje fuente
Preprocesador
Contexto de un compilador
Programa fuente
Compilador
Programa objeto en lenguaje ensamblador
Ensamblador
Código de máquina relocalizable
Editor de carga y enlace
Código de máquina absoluto
Biblioteca, archivos objetos relocalizables
Fases del compilador
- Etapa de análisis
- Análisis lineal o léxico o lexicográfico.
- Análisis sintáctico o Jerárquico.
- Análisis semántico.
- Etapa de Síntesis
- Generación de código intermedio.
- Optimización de código.
- Generación de código objeto
Fases del compilador
-
Etapa de análisis
-
Análisis lineal o léxico o lexicográfico:
- La cadena de caracteres que constituye el programa fuente se lee de izquierda a derecha y de arriba hacia abajo.
- Los caracteres leídos se agrupan en componentes léxicos (tokens) que son secuencia de caracteres con un significado colectivo.
- La secuencia de caracteres que forman un token se denomina lexema del token.
- Se eliminan los espacios en blanco, tabulaciones, y comentarios.
-
Análisis lineal o léxico o lexicográfico:
Fases del compilador
-
Etapa de análisis
-
Análisis sintáctico o Jerárquico:
- Los componentes léxicos (tokens) se agrupan jerárquicamente en colecciones anidadas con un significado colectivo.
- Se construye un árbol sintáctico. Si NO se logra construir el árbol, se presenta un error sintáctico.
- Se utilizan reglas recursivas para la construcción jerárquica.
-
Análisis sintáctico o Jerárquico:
Fases del compilador
-
Etapa de análisis
-
Análisis semántico:
- Se realizan revisiones para asegurar que los componentes de un programa se ajustan de un modo significativo.
- Se lleva a cabo la verificación de tipos en el uso de datos y variables.
-
Análisis semántico:
Fases del compilador
-
Etapa de síntesis
-
Generación de código intermedio:
- Representación intermedia del programa fuente.
- Se realizará mediante código de tres direcciones, cada posición de memoria actúa como un registro.
-
Código de tres direcciones:
- Cada instrucción tiene máximo 3 operadores.
- Tiene máximo 1 operador, además de la asignación.
- Se generan nombres temporales para guardar cálculos.
- Algunas instrucciones tienen menos de 3 operandos.
-
Generación de código intermedio:
Fases del compilador
-
Etapa de síntesis
-
Optimización de código:
- Mejora el código intermedio, de tal forma que el código se ejecute más rápido.
- Una forma de mejorarlo es utilizando una instrucción para cada operador en le representación de árbol después del análisis semántico.
- Todas las instrucciones quedan en formato de código de 3 direcciones.
-
Optimización de código:
Fases del compilador
-
Etapa de síntesis
-
Generación de código objeto:
- Generar código de máquina relocalizable o código ensambaldor.
-
Generación de código objeto:
Análisis léxico
- Primera fase de un compilador.
- Proceso en el que se leen los caracteres de entrada suminstrados por un programa fuente y elabora una secuencia de componentes léxicos que toma el analizador sintáctico para hacer el análisis
¿Qué es un análisis léxico?
Analizador Léxico
Analizador sintáctico
Tabla de símbolos
Programa fuente
Ejemplo
Programa fuente
Cáculo del descriminante de una ecuación cuadrática
Errores léxicos:
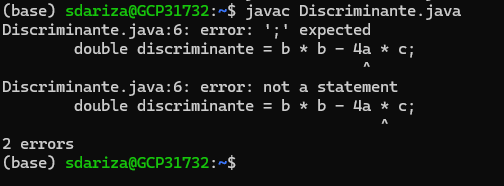

Componetes Léxicos, Patrones y Lexemas
| Componente Léxico | Lexemas de ejemplos | Descripción del patrón o regla |
|---|---|---|
| za1d, xyw_1, user1 | ||
| 45, 4243, 353 | ||
| + | ||
| - | ||
| if | ||
| for | ||
| < |
Especificación de Componentes Léxicos
-
Alfabeto
- Conjunto finito de símbolos
- Denotado por
Ejemplos
Especificación de Componentes Léxicos
-
Cadena
- Secuencia finita de símbolos tomados de un alfabeto
Ejemplos
Especificación de Componentes Léxicos
-
Longitud de una cadena |s|
- Número de apariciones de símbolos en una cadena
Ejemplos
Especificación de Componentes Léxicos
-
Cadena vacía
- Representada por , es una cadena especial de longitud cero. Es decir:
Especificación de Componentes Léxicos
-
Concatenación de dos cadenas
- p y q son cadenas definidas en los alfabetos y o sobre el mismo alfabeto . La concatenación , es la cadena que resulta al añadir q a p.
Especificación de Componentes Léxicos
-
Elemento Identidad de Concatenación
- La cadena vacía es el elemento identidad de la concatenación.
Especificación de Componentes Léxicos
-
Concatenación como producto:
- La concatenación se puede considerar como el producto de cadenas.
Especificación de Componentes Léxicos
-
Exponenciación de cadenas:
- Si p es una cadena definida sobre un alfabeto. Entonces pp, ppp, pppp, etc. También lo estarán.
Si p es una cadena definida en
y q es una cadena definida en
o ambas cadenas están definidas en
a qué será igual
Especificación de Componentes Léxicos
-
Partes de cadenas:
-
Prefijo:
- Cadena obtenida al retirar cero más símbolos desde la derecha de cualquier cadena.
- Cadena obtenida al retirar cero más símbolos desde la derecha de cualquier cadena.
-
Prefijo:
Especificación de Componentes Léxicos
-
Partes de cadenas:
-
Sufijo:
- Cadena obtenida al retirar cero más símbolos desde la izquierda de cualquier cadena.
- Cadena obtenida al retirar cero más símbolos desde la izquierda de cualquier cadena.
-
Sufijo:
Especificación de Componentes Léxicos
-
Partes de cadenas:
-
Subcadena:
- Cadena resultante de eliminar un prefijo y un sufijo de la cadena.
- Todo prefijo y sufijo es una subcadena, pero NO toda subcadena es un prefijo o sufijo.
-
Subcadena:
Especificación de Componentes Léxicos
-
Partes de cadenas:
-
Prefijo, sufijo, subcadena propios de p:
- Cualquier cadena s, donde s no es vacía. Además, s es un prefijo, sufijo o subcadena de p, donde p es diferente de s.
-
Prefijo, sufijo, subcadena propios de p:
Especificación de Componentes Léxicos
-
Partes de cadenas:
-
Subsecuencia:
- Cualquier cadena formada por la eliminación de cero o más símbolos no necesariamente contiguos de una cadena.
-
Subsecuencia:
Especificación de Componentes Léxicos
-
Lenguaje
- Cualquier conjunto de cadenas de un alfabeto
Ejemplos
Especificación de Componentes Léxicos
-
Operaciones sobre lenguajes:
-
Unión
- L y M son lenguajes, su unión se define:
-
Unión
Ejemplo: sean
Especificación de Componentes Léxicos
-
Operaciones sobre lenguajes:
-
Concatenación
- L y M son lenguajes, su concatenación se define:
-
Concatenación
Ejemplo: sean
Especificación de Componentes Léxicos
-
Operaciones sobre lenguajes:
-
Exponenciación
- L es un lenguaje, su exponenciación se define:
-
Exponenciación
Ejemplo: sea
Especificación de Componentes Léxicos
-
Operaciones sobre lenguajes:
-
Cerradura de Kleene
- L es un lenguaje, su cerradura de Kleene se define:
-
Cerradura de Kleene
Ejemplo: sea
Especificación de Componentes Léxicos
-
Operaciones sobre lenguajes:
-
Cerradura positiva de Kleene
- L es un lenguaje, su cerradura positiva de Kleene se define:
-
Cerradura positiva de Kleene
Ejemplo: sea
Especificación de Componentes Léxicos
Quiz
Calcular:
- La equivalencia de
- La equivalencia de
Si L es un lenguaje y además:
en función de
en función de
Especificación de Componentes Léxicos
-
De lo visto anteriormente:
-
Ejercicios:
- Sea p = "holaatodos" calcule |p|
- Indique 2 prefijos propios de "complicado"
- Sean y calcule
-
Sean y calcule
-
-
Ejercicios:
Especificación de Componentes Léxicos
-
Expresiones regulares
- Norma o regla definida sobre un alfabeto y a partir de la cual se generan las cadenas de un lenguaje L.
- Si es una expresión regular definida sobre , entonces L(r) es el lenguaje generado por
Especificación de Componentes Léxicos
-
Expresiones regulares
-
Construcción:
- Se van construyendo a partir de expresiones regulares más simples usando un método inductivo, de esta manera:
-
Construcción:
Caso Base:
- es una expresión regular que representa al lenguaje
- Si es un símbolo del , entonces es una expresión regular que designa al lenguaje
Especificación de Componentes Léxicos
-
Expresiones regulares
- Construcción:
Suposición:
Si y son e.r. definidas en los alfabetos y , o definidas e el mismo ; y además generan los lenguajes y , se induce que:
Paso inductivo:
3. es una e.r que genera
4. es una e.r que genera
5. es una e.r que genera
Especificación de Componentes Léxicos
-
Expresiones regulares
- Construcción:
Ejemplos:
- Construye una e.r que genere los números binarios
- Construye una e.r que genere los números binarios pares.
- Construye una e.r que genere los números binarios impares.
- Para un , construye una e.r que genere las cadenas que finalicen en , sin importar el prefijo de inicio. Ejemplo:
Especificación de Componentes Léxicos
- Definiciones regulares
Una definición regular es darle nombre a una expresión regular con el fin de, por notación y facilidad, usarla en otra expresión regular.
Dado un alfabeto , una definición regular (d.r.) es una secuencia de definiciones de la forma:
: nombre distinto
: es una e.r. con los simbolos de
Especificación de Componentes Léxicos
-
Uno o más casos:
-
Cero o un caso:
- Selección de un carácter del conjunto:
-
Definiciones regulares
- Abreviaturas de la notación
Especificación de Componentes Léxicos
- Definiciones regulares
Ejemplos:
Construye definiciones regulares para:
- Variables de un programa.
- Los números reales positivos.
- La identificación de un archivo, que consta de un nombre alfanumérico de cualquier longitud; seguido por una extensión que contiene un punto(.), y máximo tres caracteres alfanuméricos.
Autómatas finitos
¿Que son autómatas finitos?
Cadena x
Autómata Finito
(Reconocedor)
Si
No
Reconocedor de un lenguaje: Programa que toma como entrada una cadena x y responde “si” si x es una frase que pertenece al lenguaje, y “no”, si no lo es.
A partir de una e.r., se construye un reconocedor utilizando un diagrama de transiciones llamado autómata finito
Autómatas finitos
-
Tipos de autómatas finitos
| Tipo | Memoria | Complejidad | Reconocimiento |
|---|---|---|---|
| Determinístico | Menos | Más complejos | Más rápido |
| No determinístico | Más | Menos complejos | Más lento |
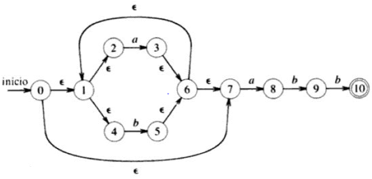
Autómata Finito Determinístico
Autómata Finito No Determinístico
Autómatas finitos
Autómata finito no determinístico (AFN)
Modelo matemático formado por una quíntupla
- : un conjunto de estados.
- : un conjunto de símbolos de entrada (alfabeto).
- : el estado de inicio o inicial.
- : un conjunto de estados de finalización o de reconocimiento.
- : una función de transición que transforma pares estado-símbolos en conjuntos de estados.
Autómatas finitos
Autómata finito no determinístico (AFN)
- Función de transición mueve
Dado un conjunto S, el conjunto se denomina Potencia de S y es el conjunto formado por todos los subconjuntos de S.
Ejemplo:
Autómatas finitos
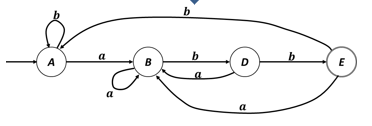
Autómata finito no determinístico (AFN)
Se puede representar mediante un grafo dirigido etiquetado, llamado grafo de transiciones.
Ejemplo:
Autómatas finitos
Autómata finito no determinístico (AFN)
Componentes del autómata
Autómatas finitos
Autómata finito no determinístico (AFN)
Tabla de Transiciones
| Estado | a | b |
|---|---|---|
| 0 | {0,1} | {0} |
| 1 | {} | {2} |
| 2 | {} | {3} |
| 3 | {} | {} |
Autómatas finitos
Autómata finito no determinístico (AFN)
Reconocimiento o Aceptación
Un AFN acepta una cadena de entrada x, si y solo si, existe algún camino en el grafo de transiciones, desde el estado de inicio hacia algún estado de aceptación, de tal forma que las etiquetas de las aristas a lo largo del camino deletreen a x.
El camino se realiza mediante transiciones llamadas movimientos.
Autómatas finitos
Autómata finito no determinístico (AFN)
Reconocimiento o Aceptación
Ejemplo:
Reconoce las cadenas
Autómatas finitos
Autómata finito Determinístico (AFD)
Modelo matemático formado por una quíntupla
- : un conjunto de estados.
- : un conjunto de símbolos de entrada (alfabeto).
- : el estado de inicio o inicial.
- : un conjunto de estados de finalización o de reconocimiento.
- : una función de transición que transforma pares estado-símbolos en conjuntos de estados.
Autómatas finitos
Autómata finito Determinístico (AFD)
- Función de transición mueve
A diferencia del AFN, en el AFD, la función de transición mueve genera un solo estado de S, NO un conjunto.
El AFD se le considera un caso especial del AFN.
Autómatas finitos
Autómata finito Determinístico (AFD)
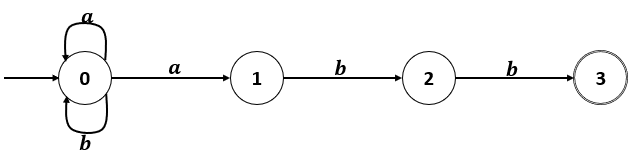
Se puede representar también mediante un grafo de transiciones.
Ejemplo:
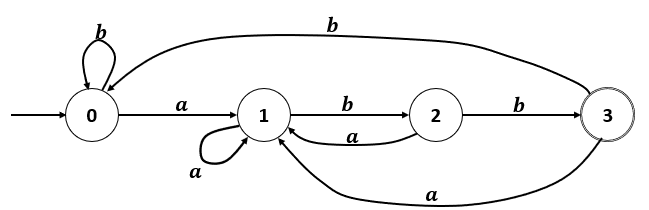
Autómatas finitos
Autómata finito Determinístico (AFD)
Componentes del autómata
Autómatas finitos
Autómata finito Determinístico (AFD)
Tabla de Transiciones
| Estado | a | b |
|---|---|---|
| 0 | 1 | 0 |
| 1 | 1 | 2 |
| 2 | 1 | 3 |
| 3 | 1 | 0 |
Autómatas finitos
Autómata finito Determinístico (AFD)
Reconocimiento o Aceptación
El camino se realiza mediante transiciones llamadas movimientos.
Ejemplo:
Reconoce las cadenas
Autómatas finitos
Diferencias entre AFN y AFD
1. En un AFD, para cada estado s hay como máximo una arista etiquetada con un símbolo de entrada a que sale de s.
2. En un AFN puede haber aristas etiquetadas con la entrada .
AFN
AFD
Autómatas finitos
Paso de una expresión regular a un AFN
Entrada: Una expresión regular definida en un alfabeto .
Salida: Un AFN que acepte el lenguaje
- Método de Thompson
Autómatas finitos
Paso de una expresión regular a un AFN
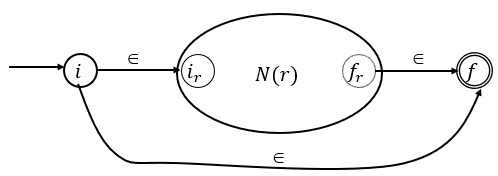
Caso Base:
- Método de Thompson
1. Para la e.r , el AFN es el siguiente:
1. Para la e.r , el AFN es el siguiente:
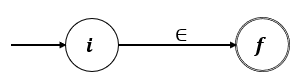
Este AFN reconoce { }
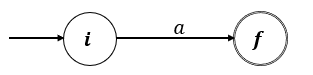
Este AFN reconoce { }
Autómatas finitos
Paso de una expresión regular a un AFN
Suposición:
- Método de Thompson
Si y son AFNs para las e.r y respectivamente; además y son los lenguajes que reconocen respectivamente estas e.r.

Reconoce a
Reconoce a
Autómatas finitos
Paso de una expresión regular a un AFN
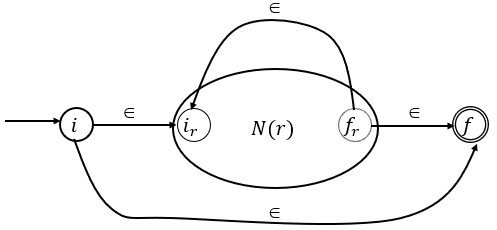
Paso inductivo:
- Método de Thompson
3. Para la e.r , el AFN es el siguiente:
Reconoce a
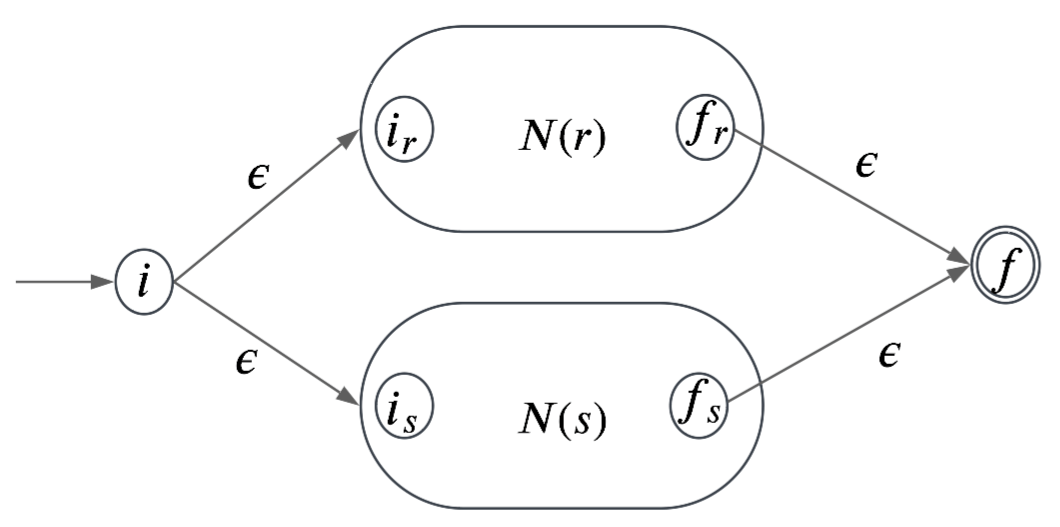
Autómatas finitos
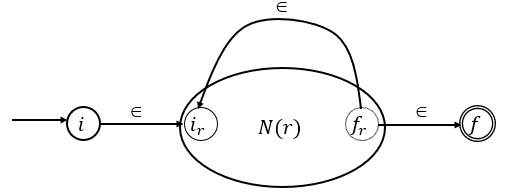
Paso de una expresión regular a un AFN
Paso inductivo:
- Método de Thompson
4. Para la e.r , el AFN es el siguiente:
Reconoce a
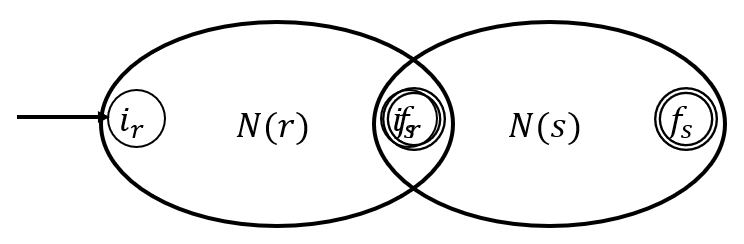
Autómatas finitos
Paso de una expresión regular a un AFN
Paso inductivo:
- Método de Thompson
7. Para la e.r , el AFN es el siguiente:
Reconoce a
Autómatas finitos
Paso de una expresión regular a un AFN
Paso inductivo:
- Método de Thompson
5. Para la e.r , el AFN es el siguiente:
Reconoce a
Autómatas finitos
Paso de una expresión regular a un AFN
Paso inductivo:
- Método de Thompson
6. Para la e.r , el AFN es el siguiente:
Reconoce a
Autómatas finitos
Paso de una expresión regular a un AFN
Ejemplos:
- Método de Thompson
Construir el AFN para las expresiones regulares:
Autómatas finitos
Paso de una expresión regular a un AFN
Ejemplos:
- Método de Thompson
1. AFN para
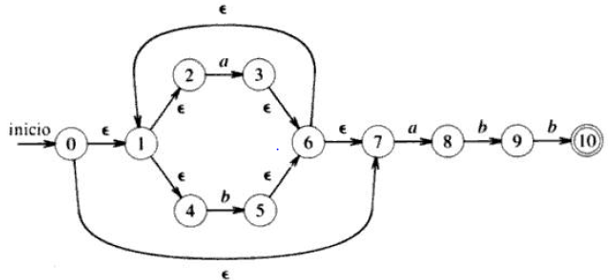
Autómatas finitos
Entrada: Un AFN que acepte el lenguaje
Salida: Un AFD no óptimo que acepte el mismo lenguaje.
- Método de Subconjuntos
Paso de un AFN a un AFD-No Óptimo
Autómatas finitos
Paso de un AFN a un AFD-No Óptimo
Operaciones sobre los estados del AFN.
cerradura- (s): Conjunto de estados del AFN alcanzables desde el estado del AFN con transiciones solamente.
Ejemplo:
- Método de Subconjuntos
Autómatas finitos
Paso de un AFN a un AFD-No Óptimo
Operaciones sobre los estados del AFN.
mueve :Conjunto de estados del AFN hacia los cuales hay una transición con el símbolo de entrada desde algún estado en del AFN.
Ejemplo:
- Método de Subconjuntos
Autómatas finitos
Paso de un AFN a un AFD-No Óptimo
- Método de Subconjuntos
Operaciones sobre los estados del AFN.
cerradura- (T): Conjunto de estados del AFN alcanzables desde algún estado del AFN con transiciones solamente.
Ejemplo:
Autómatas finitos
Paso de un AFN a un AFD-No Óptimo
- Método de Subconjuntos
Algoritmo de Subconjuntos
// Al inicio, cerradura-ε(s0) es el único estado dentro de estadosD y no está marcado
MIENTRAS QUE(haya un estado no marcado T en estadosD) HACER:
marcar T;
PARA cada símbolo de entrada a HACER:
U = cerradura-ε(mueve(T,a));
SI U no está en estadosD:
añadir U como estado no marcado a estadosD;
FIN-SI
tranD[T,a] = U;
FIN-PARA
FIN-MIENTRASQUE| Estado | Símbolo(a) | Símbolo(b) |
|---|---|---|
tranD
| Estado | ||
|---|---|---|
| Marca |
estadosD
Paso de un AFN a un AFD-No Óptimo
- Método de Subconjuntos
Algoritmo de Subconjuntos
// Al inicio, cerradura-ε(s0) es el único estado dentro de estadosD y no está marcado
MIENTRAS QUE(haya un estado no marcado T en estadosD) HACER:
marcar T;
PARA cada símbolo de entrada a HACER:
U = cerradura-ε(mueve(T,a));
SI U no está en estadosD:
añadir U como estado no marcado a estadosD;
FIN-SI
tranD[T,a] = U;
FIN-PARA
FIN-MIENTRASQUE| Estado | Símbolo(a) | Símbolo(b) |
|---|---|---|
tranD
| Estado | ||
|---|---|---|
| Marca |
estadosD
// Al inicio, cerradura-ε(s0) es el único estado dentro de estadosD y no está marcado
MIENTRAS QUE(haya un estado no marcado T en estadosD) HACER:
marcar T;
PARA cada símbolo de entrada a HACER:
U = cerradura-ε(mueve(T,a));
SI U no está en estadosD:
añadir U como estado no marcado a estadosD;
FIN-SI
tranD[T,a] = U;
FIN-PARA
FIN-MIENTRASQUE| Estado | Símbolo(a) | Símbolo(b) |
|---|---|---|
| A | B | C |
| B | B | D |
| C | B | C |
| D | B | E |
| *E | B | C |
tranD
| Estado | A | B | C | D | E |
|---|---|---|---|---|---|
| Marca | - | - | - | - | - |
estadosD
Ejemplo: Hallar el AFD de:
| Estado | Símbolo(a) | Símbolo(b) |
|---|---|---|
| A | B | C |
| B | B | D |
| C | B | C |
| D | B | E |
| *E | B | C |
tranD
AFN
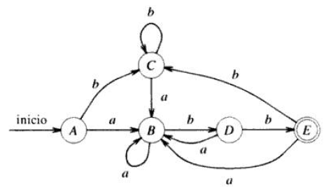
AFD-No Óptimo
Autómatas finitos
Paso de un AFN a un AFD-No Óptimo
- Método de Subconjuntos
Algoritmo de Subconjuntos
Autómatas finitos
Entrada: Un AFD No Óptimo que acepte el lenguaje
Salida: Un AFD Óptimo que acepte el mismo lenguaje.
- Método de Estados Significativos
Paso de un AFD-No Óptimo a un AFD Óptimo
Autómatas finitos
Estado Significativo: Es un estado de un AFN que tiene transiciones de salida diferentes de .
El , si es significativo para algún en .
Ejemplo: En el AFN, cuáles son los estados significativos?
- Método de Estados Significativos
Paso de un AFD-No Óptimo a un AFD Óptimo
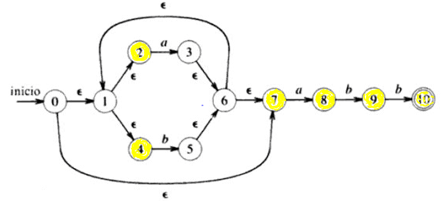
Estados Significativos={2,4,7,8,9,10}
Autómatas finitos
Identificamos los estados significativos para cada subconjunto encontrado en el método anterior y si dos subconjuntos tienen los mismos estados significativos, estos se pueden resumir en un único estado.
- Método de Estados Significativos
Paso de un AFD-No Óptimo a un AFD Óptimo
| Estado | a | b |
|---|---|---|
| A | B | C |
| B | B | D |
| C | B | C |
| D | B | E |
| *E | B | C |
Ejemplo:
Est_Sig(A)={2,4,7}
Est_Sig(B)={2,4,7,8}
Est_Sig(C)={2,4,7}
Est_Sig(D)={2,4,7,9}
Est_Sig(E)={2,4,7,10}
| Estado | a | b |
|---|---|---|
| A | B | A |
| B | B | D |
| D | B | E |
| *E | B | A |
tranD
Autómatas finitos
AFD Óptimo con Estados Significativos
- Método de Estados Significativos
Paso de un AFD-No Óptimo a un AFD Óptimo
| Estado | a | b |
|---|---|---|
| A | B | A |
| B | B | D |
| D | B | E |
| *E | B | A |
tranD
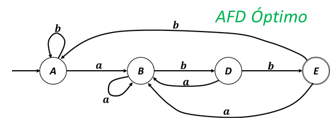
Autómatas finitos
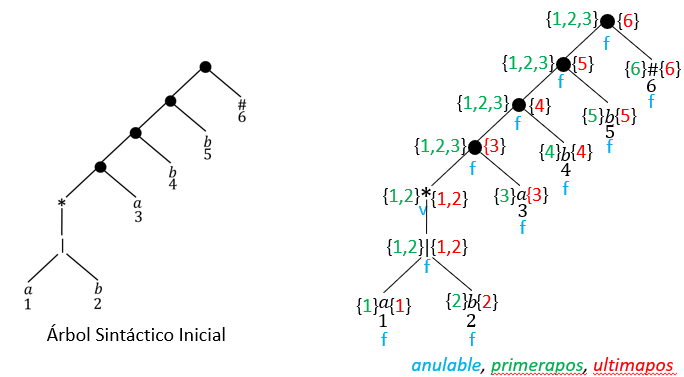
- Construir un árbol sintáctico T para la e.r aumentada r#.
- Construir las funciones anulable, primerapos, ultimapos y siguientepos haciendo recorridos de abajo-arriba en T.
- Construir el conjunto de estados de D (estadosD) y la tabla de transiciones para D (tranD)
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
Autómatas finitos
Al construir el AFN en el método de Thompson, se genera un estado significativo cuando un símbolo del alfabeto aparece en la e.r.
El AFN solo tiene un estado de aceptación, pero este estado no es significativo porque no tiene transiciones de salida.
Por esto se concatena un marcador # a la e.r. r, y se le da al estado de aceptación de r una transición con el símbolo #, convirtiéndolo en estado significativo del AFN para r#.
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
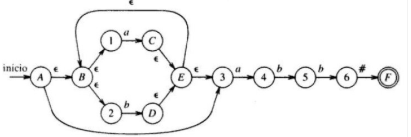
En la imagen, los estados significativos se representan en numeros. Cuando se realiza el reconocimiento, y la construcción está completa, cualquier estado del AFN con una transición en # debe ser estado de aceptación.
Autómatas finitos
Una e.r aumentada r#, se representa mediante un árbol sintáctico con los siguientes tipos de nodos:
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo

Autómatas finitos
A cada hoja no etiquetada con se le asocia una posición, que es un entero.
Un símbolo repetido en una e.r. tiene varias posiciones.
La posición de cada símbolo se puede identificar con la etiqueta del estado significativo en el AFN, como se observa en la figura.
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
1 2 3 4 5 6
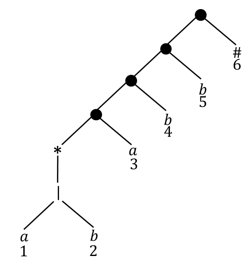
Autómatas finitos
Ejemplo:
Para la e.r. , construye el árbol sintáctico, y señala las posiciones tanto en la e.r como en el árbol.
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
1 2 3
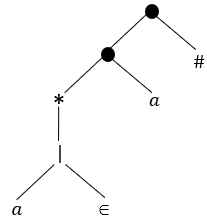
1
2
3
Autómatas finitos
Funciones:
anulable(𝑛): Función booleana sobre un nodo 𝑛. El anulable será Verdadero si al aplicarlo sobre el nodo 𝑛, existe la posibilidad de generar la cadena vacía en algún momento; o Falso si nunca la genera.
Ejemplo:
El anulable de las siguientes expresiones es:
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
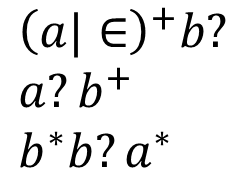
Verdadero: Es posible que la e.r genere la cadena vacía.
Falso: No es posible que sea vacía ya que b se repite 1 o mas veces
Verdadero: Es posible que la e.r genere la cadena vacía.
Autómatas finitos
Funciones:
𝑝𝑟𝑖𝑚𝑒𝑟𝑎𝑝𝑜𝑠(𝑛): Función sobre un nodo 𝑛 que devuelve el conjunto de posiciones que pueden concordar con el primer símbolo de una cadena generada por la sub-expresión regular con raíz en 𝑛.
Ejemplo:
El primerapos de las siguientes expresiones es:
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
1 2 3 4 5
1 2 3 4
1 2 3
1 2 3 4
Autómatas finitos
Funciones:
𝑢𝑙𝑡𝑖𝑚𝑎𝑝𝑜𝑠(𝑛): Función sobre un nodo 𝑛 que devuelve el conjunto de posiciones que pueden concordar con el último símbolo de una cadena generada por la sub-expresión regular con raíz en 𝑛.
Ejemplo:
El ultimapos de las siguientes expresiones es:
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
1 2 3 4 5
1 2 3 4
1 2 3
1 2 3 4
Autómatas finitos
Reglas para resolver las funciones en los nodos
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo

Autómatas finitos
Reglas para resolver las funciones en los nodos
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
Autómatas finitos
Ejemplo:
𝑎𝑛𝑢𝑙𝑎𝑏𝑙𝑒, 𝑝𝑟𝑖𝑚𝑒𝑟𝑎𝑝𝑜𝑠 𝑦 𝑢𝑙𝑡𝑖𝑚𝑎𝑝𝑜𝑠 para
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
Autómatas finitos
Cálculo del siguientepos:
- Si 𝑛 es un nodo-cat con hijo izquierdo e hijo derecho , 𝑖 es una posición dentro de 𝑢𝑙𝑡𝑖𝑚𝑎𝑝𝑜𝑠( ), entonces todas las posiciones de 𝑝𝑟𝑖𝑚𝑒𝑟𝑎𝑝𝑜𝑠( ) están en el 𝑠𝑖𝑔𝑢𝑖𝑒𝑛𝑡𝑒𝑝𝑜𝑠(𝑖).
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
𝑠𝑖𝑔𝑢𝑖𝑒𝑛𝑡𝑒𝑝𝑜𝑠(𝑖) contiene a
𝑠𝑖𝑔𝑢𝑖𝑒𝑛𝑡𝑒𝑝𝑜𝑠(j) contiene a
Autómatas finitos
Cálculo del siguientepos:
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
Dado que ya se calcularon el 𝑝𝑟𝑖𝑚𝑒𝑟𝑎𝑝𝑜𝑠 y 𝑢𝑙𝑡𝑖𝑚𝑎𝑝𝑜𝑠 en el árbol sintáctico para cada nodo, se calcula 𝑠𝑖𝑔𝑢𝑖𝑒𝑛𝑡𝑒𝑝𝑜𝑠 haciendo un recorrido de abajo hacia arriba en el árbol.
| Posición 𝑖 | 𝒔𝒊𝒈𝒖𝒊𝒆𝒏𝒕𝒆𝒑𝒐𝒔(𝒊) |
|---|---|
| 1 | {1,2,3} |
| 2 | {1,2,3} |
| 3 | {4} |
| 4 | {5} |
| 5 | {6} |
| 6 | {} |
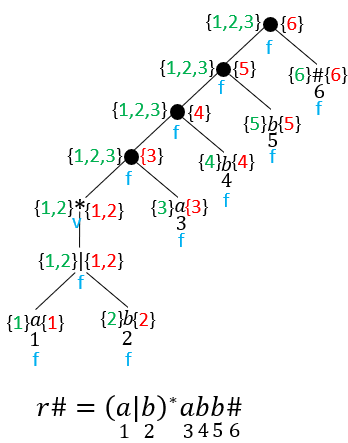
Autómatas finitos
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
// Al inicio, el único estado no marcado en estadosD es primerapos(raiz), donde raiz es la raiz del árbol para (r)#
MIENTRAS QUE(haya un estado no marcado T en estadosD) HACER:
marcar T;
PARA cada símbolo de entrada a HACER:
//sea U el conjunto de posiciones que están en siguientepos(p), para alguna posición en T, tal que el símbolo en la posición p es a;
SI U no está vaciao y no está en estadosD:
añadir U como estado no marcado a estadosD;
FIN-SI
tranD[T,a] = U;
FIN-PARA
FIN-MIENTRASQUE| Estado | Símbolo(a) | Símbolo(b) |
|---|---|---|
tranD
| Estado | ||
|---|---|---|
| Marca |
estadosD
Autómatas finitos
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
// Al inicio, el único estado no marcado en estadosD es primerapos(raiz), donde raiz es la raiz del árbol para (r)#
MIENTRAS QUE(haya un estado no marcado T en estadosD) HACER:
marcar T;
PARA cada símbolo de entrada a HACER:
//sea U el conjunto de posiciones que están en siguientepos(p), para alguna posición en T, tal que el símbolo en la posición p es a;
SI U no está vaciao y no está en estadosD:
añadir U como estado no marcado a estadosD;
FIN-SI
tranD[T,a] = U;
FIN-PARA
FIN-MIENTRASQUEEl estado de inicio del AFD corresponde con la ppos(raiz).
El estado de finalización del AFD contiene la posición de #.
| 𝑖 | 𝒔𝒑𝒐𝒔(𝒊) |
|---|---|
| 1 | {1,2,3} |
| 2 | {1,2,3} |
| 3 | {4} |
| 4 | {5} |
| 5 | {6} |
| 6 | {} |
| Estado | a | b |
|---|---|---|
| A | B | A |
| B | B | C |
| C | B | D |
| *D | B | A |
tranD
Autómatas finitos
- Método del Árbol Sintáctico
Paso de una e.r a un AFD Óptimo
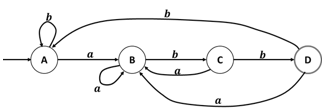
| Estado | a | b |
|---|---|---|
| A | B | A |
| B | B | C |
| C | B | D |
| *D | B | A |
tranD
Autómatas finitos
- Lema de Ardem
Conversión de un AFD a una E.R.
Sistemas de Ecuaciones en E.R.
Ecuación en expresiones regulares: Ecuación lineal donde variables y coeficientes toman la forma de expresiones regulares.
Entrada: Autómata finito , con
Salida: Sistema de ecuaciones donde en determina el lenguaje del AFD.
Método:
- Por cada estado , introducir una variable .
- Si está en F, luego añadir en la parte derecha de la 𝑖-ésima ecuación el término ∈; es decir, =∈.
- Si entonces en la parte derecha de la 𝑖-ésima ecuación aparece el término ; es decir, , con en .
Autómatas finitos
- Lema de Ardem
Conversión de un AFD a una E.R.
Sea una ecuación en expresiones regulares, luego es una solución para la ecuación. Es única si ∈ es generada por 𝑟.
- Dado un sistema de ecuaciones en expresiones regulares, la resolución viene tras aplicar el método de Gauss utilizando el Lema de Arden para reducir.
- Útil para obtener una e.r. a partir de un A.F. o una gramática regular.
- Sistema de ecuaciones en E.R
Autómatas finitos
- Lema de Ardem
Conversión de un AFD a una E.R.
Ejemplo 1:
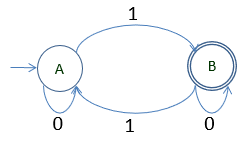
A=1B | 0A (1)
B=1A | 0B | ∈ (2)
Resolviendo
De (1): Aplicando Ardem
A=0*1B (1’)
Remplazando (1’) en (2)
B=10*1B | 0B | ∈
B= (10*1| 0)B | ∈
B= (10*1 | 0)* ∈ Aplicando Ardem
B= (10*1 | 0)* (2’)
Remplazando. (2’) en (1’)
A=0*1 (10*1 | 0)* Expr. Regular Final
Autómatas finitos
- Lema de Ardem
Conversión de un AFD a una E.R.
Ejemplo 2:
A= bA | aB (1)
B= bC | aA | ∈ (2)
C=aC | bB (3)
Resolviendo
De (1): Por Ardem
A=b*aB (1’)
De (3): Por Ardem
C=a*bB (3’)
Rempl (1’) y (3’) en (2)
B=ba*bB | ab*aB | ∈
B=(ba*b | ab*a ) B | ∈
B= (ba*b | ab*a )* ∈ Por Ardem
B= (ba*b | ab*a )* (2’)
Rempl en (1’)
A=b*a (ba*b | ab*a )* Exp. Regular
Análisis léxico
Flex
Analizador Léxico
También llamado scanner, lexer o tokenizer, es un programa que toma como entrada el código fuente de otro programa (una secuencia de caracteres) y genera como salida un conjunto de tokens o símbolos léxicos.
Ejemplo:
"x = 5 + 20"
Reconoces palabras o símbolos significativos del lenguaje según las reglas definidas, ya sea por gramáticas o expresiones regulares.
| Tipo de token | Ejemplo en el código | Descripción |
|---|---|---|
| IDENTIFICADOR | x | nombre de variable |
| OPERADOR_ASIGNACION | = | símbolo de asignación |
| NUMERO | 5, 3 | constantes numéricas |
| OPERADOR_SUMA | + | operador aritmético |
| PUNTO_Y_COMA | ; | delimitador de instrucción |
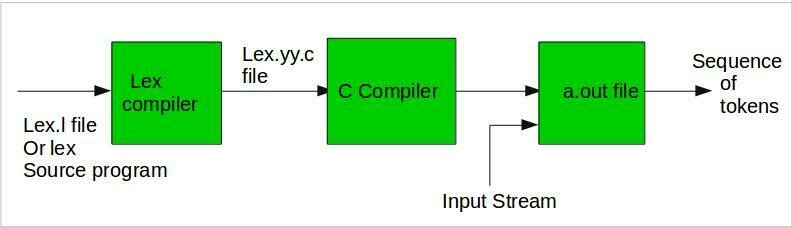
¿Qué es Flex?
- Generador de analizadores léxico - Scanners
- Genera código fuente en C
- Distibuido bajo licencia BSD.
- Source: https://flex.sourceforge.net
Especificación Flex
Flex
lex.yy.c
yylex()
¿Cómo se utiliza Flex?
Especificación del analizador léxico
- Entrada de Flex: Especificación del analizador léxico
- Consta de 3 Secciones:
- Deficiones
- %%
Reglas
%% - Código de usuario
- Texto encerrado entre %{ y %} se copiará a la salida
- Comentarios encerrados entre /* y */
Deficiones
- Son declaraciones de nombres asociados a expresiones regulares.
- <name> <r.e>
- Posteriormente se usará el nombre entre {}
- Ejemplo:
- digito [0-9]
- letraMinuscula [a-z]
Reglas
- Una de las más importantes, ya que se establece las patrones a reconcer en el fichero de entrada
- Contiene reglas de la forma:
- <patrón> <acción>
- Donde:
- <patrón>: expresión regular.
- <acción>: código C que se ejecutará.
- Donde:
- <patrón> <acción>
- Ejemplo:
- {digito} {ECHO;}
Ejemplo Completo
digito [0-9]
%%
{digito} {ECHO;}
{digito}+ {ECHO;}
%%
main(){
yylex();
}Expresiones regulares
| r.e | Reconocimiento |
|---|---|
| x | caracter x |
| . | Cualquier carácter excepto nueva línea |
| [abc] | una 'a' o una 'b' o una 'c' |
| [ab-p] | una 'a' o una 'b' o cualquier letra entre b y p |
| [^A-Z] | Caracteres negados: Cualquier carácter excepto una letra mayúscula. |
| r* | Cero o más ocurrencias de la e.r r |
| r+ | Una o más ocurrencias de la e.r r |
| r|s | r o s (unión) |
| sr | e.r s seguida de la e.r r (concatenación) |
Expresiones regulares
| r.e | Reconocimiento |
|---|---|
| r? | Cero o una ocurrencia de r |
| r{3,6} | De 3 a 6 ocurrencias de r |
| {nombre} | e.r de la definición "nombre" |
| \x | x: 'a', 'b', 'f', 'n', 'r', 't', o 'v' : ANSI-C. Ow: x |
| "[xyz]"\fo" | Cadena literalmente: [xyz]"\fo |
| <<EOF>> | Fin del fichero |
Ejemplos
- Expresión regular Flex para:
- Un dígito:
- [0-9] {printf("He reconocido un dígito")}
- Un número natural:
- [0-9]+ {printf("He reconocido un número natural")}
- La palabra "for"
- for {printf("He reconocido la palabrea for")}
- Un dígito:
Ejemplo Completo
digito [0-9]
nentero {digito}+
nreal {nentero}\.{digito}*
%%
{digito} {ECHO;}
{nentero} {ECHO;}
{nreal} {ECHO;}
. {printf("<<error>>");}
<<EOF>> {yyterminate();}
%%
main(){
yylex();
}Análisis Sintáctico
Análisis Sintáctico
Analizador Léxico
Analizador sintáctico
Tabla de símbolos
Programa fuente
Resto de
Etapa Inicial
Árbol de análisis sintáctico
Analizador Sintáctico: Segunda fase de un compilador. Obtiene una cadena de componentes léxicos del Analizador Léxico, y verifica si la cadena puede ser generada por la gramática del lenguaje fuente. Informa de los errores sintácticos que se presenten.
Los lenguajes de programación poseen una estructura inherentemente recursiva que se define gracias a las Gramáticas Independientes del Contexto (GIC).
Las GIC son un modelo matemático formado por una cuadrupla:
Gramáticas Independientes del Contexto
1. 𝑻: Terminales: Símbolos básicos con los que se forman las cadenas. Componente léxico es sinónimo de terminal.
2. 𝑵: No terminales: Son variables sintácticas que denotan conjuntos de cadenas. Estos definen conjuntos de cadenas que ayudan a definir el lenguaje generado por la GIC.
3. 𝑺: Símbolo Inicial: Es un No terminal, y define a un conjunto de cadenas que representan al lenguaje generado por la GIC.
4. 𝑷: Producciones: Especifican cómo se combinan los Terminales y los No Terminales para formar cadenas. Cada producción consta de dos partes:
Cabecera: Es un No Terminal, seguido por una flecha
Cuerpo: Cadena de Terminales y No Terminales.
Ejemplo: 𝐴→𝛼 es una producción.
Gramáticas Independientes del Contexto
Ejemplo de GIC: Gramática de Operadores Aritméticos
Gramáticas Independientes del Contexto
P son las producciones que se encuentran en el lado izquierdo.
Escritura abreviada
Ejemplo de GIC: Gramática de Operadores Aritméticos
Gramáticas Independientes del Contexto
P son las producciones que se encuentran en el lado izquierdo.
Escritura abreviada
Ejemplo de GIC:
Gramáticas Independientes del Contexto
P son las producciones que se encuentran en el lado izquierdo.
Por convención:
- Los No Terminales se escriben con letras mayúsculas
- El Símbolo Inicial(S) es el primer no Terminal que aparece en las producciones
Derivaciones
Una GIC 𝐺 define un lenguaje 𝐿(𝐺).
Las derivaciones establecen el proceso mediante el cual la GIC define un lenguaje.
Se considera cada producción como una regla de escritura, donde el No terminal a la izquierda es sustituido por la cadena del lado derecho de la producción.
Gramáticas Independientes del Contexto
Derivaciones
Ejemplo:
Derivar la cadena:
Gramáticas Independientes del Contexto
A estas sustituciones se les llama derivación de la cadena
Derivaciones
Reglas y Notaciones:
Dada una GIC 𝐺 con símbolo inicial 𝑆, se utiliza la relación para definir 𝐿(𝐺), el lenguaje generado por 𝐺.
1. Las cadenas en 𝐿(𝐺) pueden contener sólo símbolos terminales de 𝐺; es decir, si 𝜔 está en 𝐿(𝐺), luego 𝜔 es generada por .
2. 𝜔 está en 𝐿(𝐺) sí, y solo sí, 𝑆 𝜔.
Gramáticas Independientes del Contexto
Derivaciones
Reglas y Notaciones:
3. A la cadena 𝜔 se le llama frase de 𝐺.
4. A un lenguaje generado por una GIC, se le denomina lenguaje independiente del contexto (LIC).
5. Dos GIC que generan el mismo lenguaje, se les denomina GIC’s equivalentes. Es decir, si 𝐿(𝐺) = 𝐿(𝐺′), luego 𝐺≅𝐺′.
6. Si 𝑆 𝛼, donde 𝛼 puede contener no terminales, luego 𝛼 es una forma de frase de 𝐺.
7. Una frase es una forma de frase sin no terminales.
Gramáticas Independientes del Contexto
Derivaciones
Ejemplo:
Gramáticas Independientes del Contexto
En la siguiente derivación:
es una frase de la GIC.
son formas de frase de la GIC.
Derivaciones
Tipos de derivaciones
Gramáticas Independientes del Contexto
Derivación 1: Más Izquierda
Derivación 2: Más Izquierda
Derivaciones
Tipos de derivaciones
Gramáticas Independientes del Contexto
Derivación 3: Más Derecha
Derivación 4: Más Derecha
Derivaciones
Tipos de derivaciones
Derivación Más Izquierda
Gramáticas Independientes del Contexto
Se realiza la sustitución del no terminal que se encuentra más a la izquierda de cualquier forma de frase.
𝑤𝐴𝛾 𝑤𝛿𝛾, donde 𝑤 está formada solo de terminales, 𝐴→𝛿 es la producción aplicada y 𝛾 es una cadena de símbolos gramaticales.
Aquí 𝑤𝛿𝛾 es una forma de frase izquierda de la GIC.
Derivaciones
Tipos de derivaciones
Derivación Más Derecha
Gramáticas Independientes del Contexto
Se realiza la sustitución del no terminal que se encuentra más a la derecha de cualquier forma de frase.
𝛾𝐴𝑤 𝛾𝛿𝑤, donde 𝑤 está formada solo de terminales, 𝐴→𝛿 es la producción aplicada y 𝛾 es una cadena de símbolos gramaticales.
Aquí 𝛾𝛿𝑤 es una forma de frase derecha de la GIC.
Derivaciones
Ambigüedad
Una GIC que genera una cadena con más de una derivación del mismo tipo, se considera ambigua.
Analizar ambigüedad de la primera y segunda GIC de Operadores Aritméticos
Gramáticas Independientes del Contexto
Derivaciones
Árbol de análisis sintáctico
Gramáticas Independientes del Contexto
Es una representación gráfica de una derivación que no muestra la elección relativa al orden de sustitución.
Cada nodo interior del árbol se etiqueta con algún no terminal A.
Los hijos de este nodo interior A, se etiquetan, de izquierda a derecha, con los símbolos del lado derecho de la producción por la cual se sustituyó esta A en la derivación.
Las hojas del árbol en cualquier momento se pueden leer de izquierda a derecha y forman una forma de frase, llamada frontera del árbol.
Derivaciones
Árbol de análisis sintáctico
Gramáticas Independientes del Contexto
Ejemplo: Derivación 1: Más Izquierda
Arbol de análisis sintáctico
Derivación final
Derivaciones
Árbol de análisis sintáctico
Gramáticas Independientes del Contexto
Ejercicio: Dada la GIC, construye los AAS correspondientes
Derivación 2: Más Izquierda
Derivación 3: Más Derecha
Derivación 4: Más Derecha
Escritura de una Gramática
Expresiones regulares a GIC
Gramáticas Independientes del Contexto
Toda e.r se puede escribir como una GIC. Con las siguientes reglas:
- Construir un Autómata Finito.
- Para cada estado del AF, crear un símbolo no terminal .
a) Si , se agrega la producción
b) Si , se agrega la producción
c) Si está en F(estado de finalización), se agrega
d) Si es el estado de inicio del AF, luego es el símbolo de inicio de la GIC.
: Si existe un movimiento que sale del estado i con el símbolo a
Escritura de una Gramática
Expresiones regulares a GIC
Gramáticas Independientes del Contexto
Ejemplo: Convertir a una GIC la e.r a partir de AFD óptimo
Escritura de una Gramática
Eliminación de Recursividad Izquierda
Gramáticas Independientes del Contexto
Una GIC es recursiva por izquierda si tiene un no terminal 𝐴 tal que existe una derivación 𝐴 𝐴𝛼 para alguna cadena 𝛼. Es decir que el no terminal tiene producciones con el mismo no terminal a la izquierda.
Los analizadores sintácticos descendentes no pueden manejar gramáticas recursivas por la izquierda.
Escritura de una Gramática
Eliminación de Recursividad Izquierda
Gramáticas Independientes del Contexto
Método Simple:
Dada la GIC , la GIC sin recursividad:
Ejemplo: Dada la GIC, eliminar la recursividad
Escritura de una Gramática
Eliminación de Recursividad Izquierda
Gramáticas Independientes del Contexto
Método Compuesto:
Dada la GIC , la GIC sin recursividad es:
Si , entonces , se convierte en el caso simple y se elimina igual que ese método:
Escritura de una Gramática
Eliminación de Recursividad Izquierda
Gramáticas Independientes del Contexto
Método Compuesto:
Ejemplo: Eliminar recursividad
Escritura de una Gramática
Factorización por Izquierda
Gramáticas Independientes del Contexto
Es otra transformación necesaria de una GIC para utilizarla en un Analizador Sintáctico Descendente.
Dada la GIC
Método:
Se transforma en la GIC equivalente:
Escritura de una Gramática
Factorización por Izquierda
Gramáticas Independientes del Contexto
Ejemplo: Dada la GIC, realiza la factorización izquierda