Athletic Intelligence
for Legged Robots
Shamel Fahmi
June, 2023
"Marc Raibert divided intelligence into Cognitive Intelligence (CI) and Athletic Intelligence (AtI). CI allows us to make abstract plans, and to understand and solve broader problems. AtI allows us to operate our bodies in such a way that we can balance, stand, walk, climb, etc. AtI also lets us do real-time perception so that we can interact with the world around us."

S. Fahmi, On Terrain-Aware Locomotion for Legged Robots, PhD. dissertation, Italian Institute of Technology, 2021.
M. Raibert and S. Kuindersma, Boston dynamics, the Challenges of Real-World Reinforcement Learning Workshop in NeurIPS, 2021.
Athletic Intelligence
for Legged Robots?
Athletic Intelligence allows the robot to take decisions based on the surrounding world using its perception.
decisions
world
perception
decisions
world
perception
Using Optimization and Learning


-
Control
-
State Estimation
-
Planning
-
Proprioception
-
Vision
-
Physical Properties
-
Geometry
STANCE: Whole-Body Control for Legged Robots
ViTAL: Vision-Based Terrain-Aware Locomotion Planning
MIMOC: Reinforcement Learning for Legged Robots

Locomotion Planning
Two ways to deal with locomotion planning:
1. Coupled Planning:
-
Plan the feet & base states simultaneously.
2. Decoupled planning:
-
Separate the plan into feet & base plans.
-
Planning the feet motion ⇒ foothold selection
-
Planning the body motion ⇒ pose adaptation
Vision-Based Foothold Adaptation (VFA)
Villarreal 2019
Barasuol 2015
Foothold Selection
V. Barasuol et al., Reactive Trotting with Foot Placement Corrections through Visual Pattern Classification, IROS, 2015.
O. Villarreal et al., Fast and Continuous Foothold Adaptation for Dynamic Locomotion through CNNs, RA-L, 2019.
Goal: Select footholds based on the terrain information and the robot's capabilities.
Pose Adaptation
-
Goal: find the optimal robot's pose that can:
-
Maximize the reachablity of the given selected footholds.
-
Avoid terrain collision and maintain static stability.
-
-
A pose optimizer to deal with these objectives.
M. Kalakrishnan et al., Learning, planning, and control for quadruped locomotion over challenging terrain, IJRR 2011.
P. Fankhauser et al., Robust Rough-Terrain Locomotion with a Quadrupedal Robot, IROS, 2018.
Kalakrishnan 2011
Fankhauser 2018
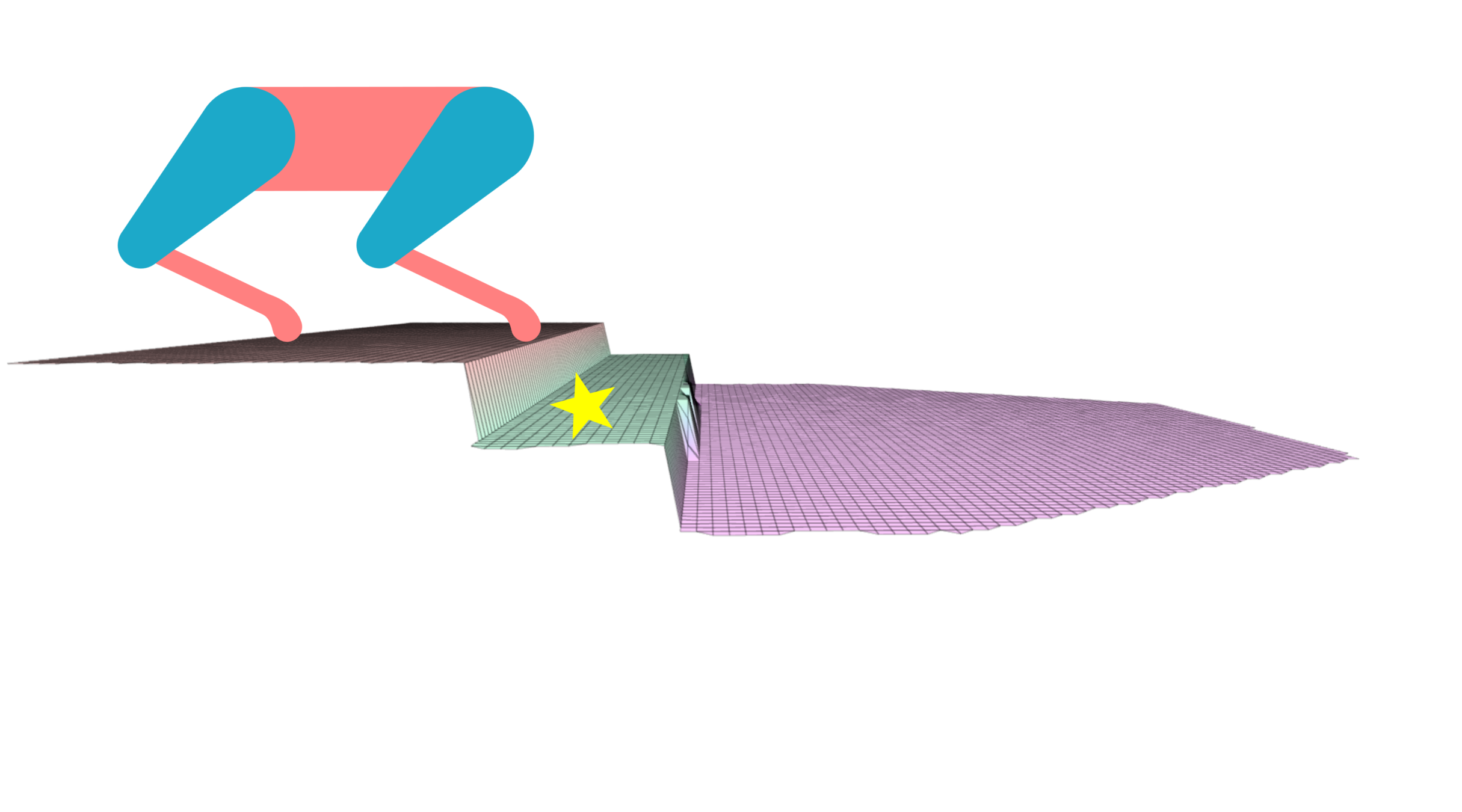
The Problem with Decoupled Planning
-
Current decoupled planning strategies focus on finding one optimal solution based on given selected footholds.
-
First, the footholds are selected.
-
Then, the pose is optimized based on that.
-
If the selected footholds are not reached (the robot gets disturbed), the robot may end up in a state with no reachable safe footholds.
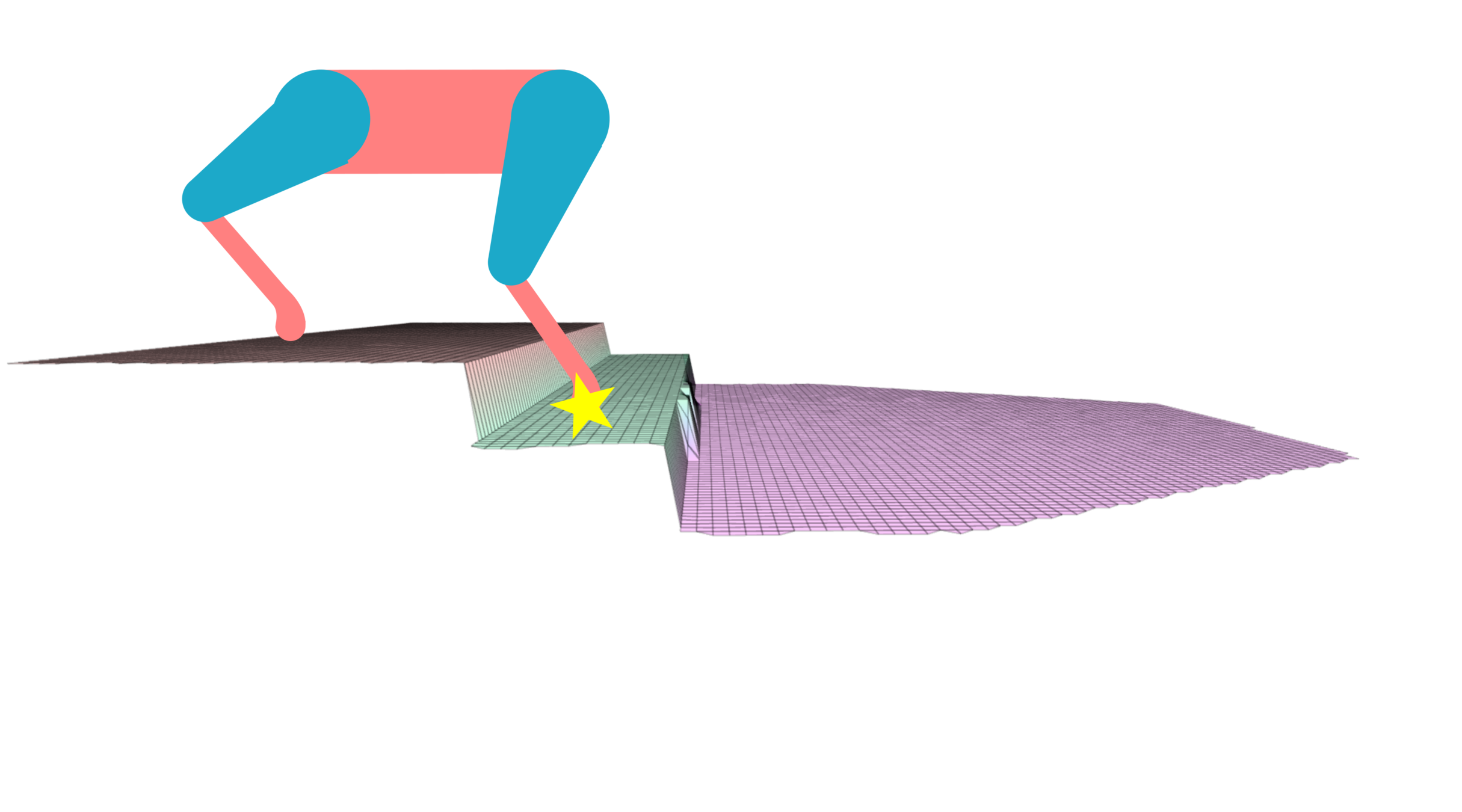
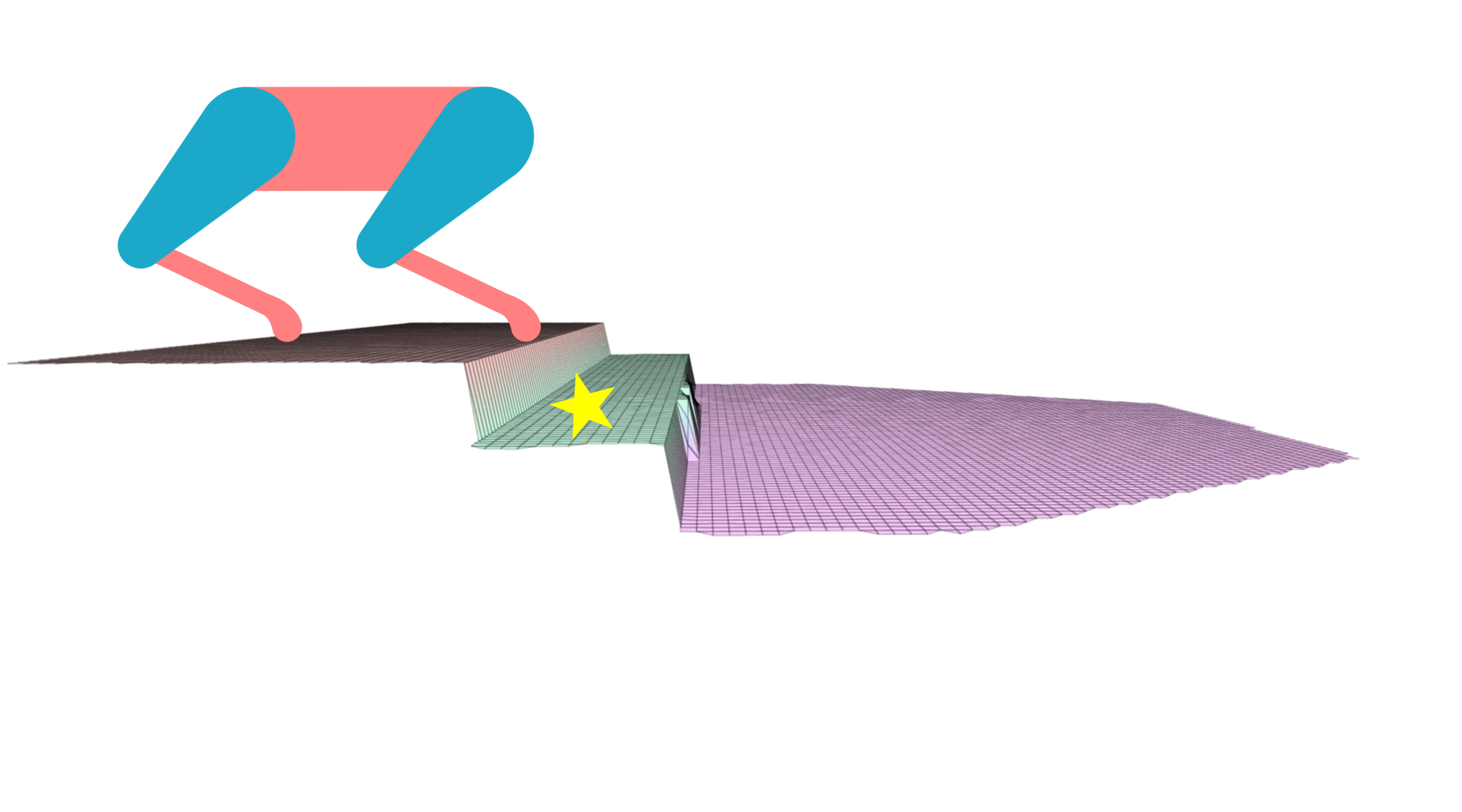
-
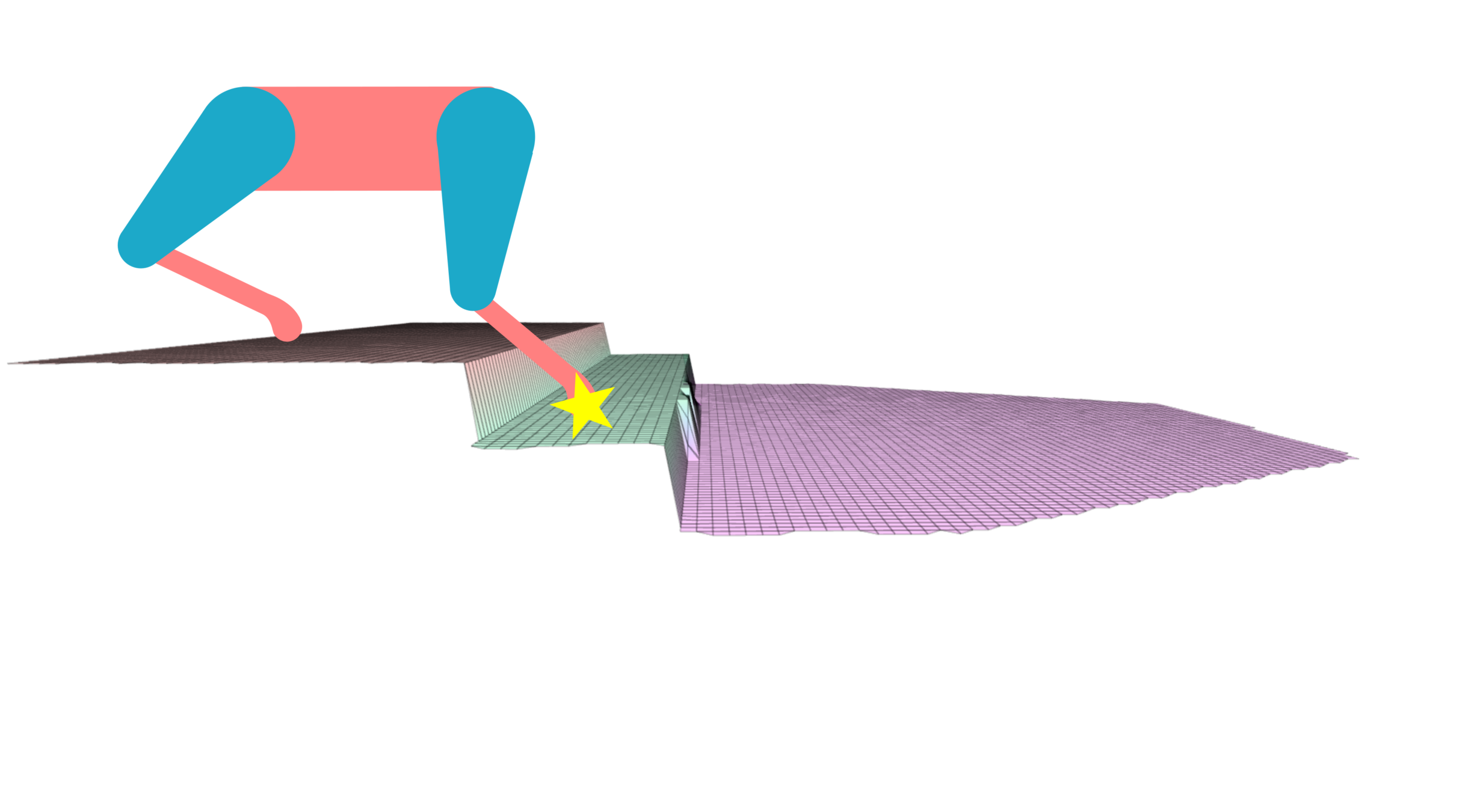
Propose a different paradigm.
-
Instead of finding body poses that are optimal w.r.t given footholds,
-
we find body poses that will maximize the chances of the robot reaching safe footholds.
-
Put the robot in a state that if it gets disturbed, it remains around a set of solutions that are still safe & reachable.
How to Solve This Problem?

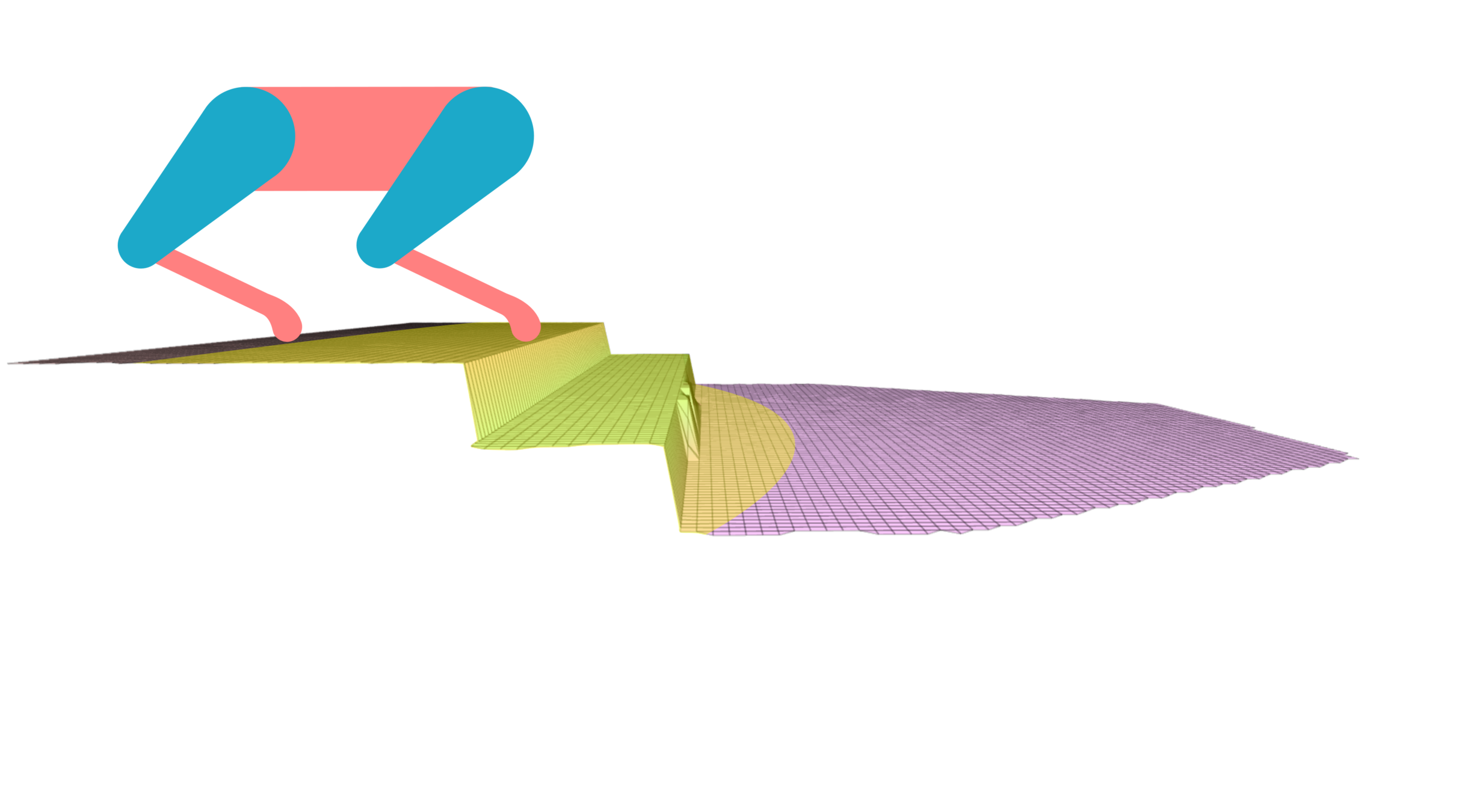
Vision-Based Terrain Aware Locomotion (ViTAL)
- ViTAL is an online vision-based locomotion planning strategy.
- ViTAL selects footholds based on the robot's skills
- Also, find the robot pose that maximizes the chances of success in reaching these footholds.
- The notion of safety & success emerges from skills that characterize the robot's capabilities.
Vision-Based Foothold Adaptation (VFA)
Vision-Based Pose Adaptation (VPA)
Foothold Evaluation Criteria (FEC)


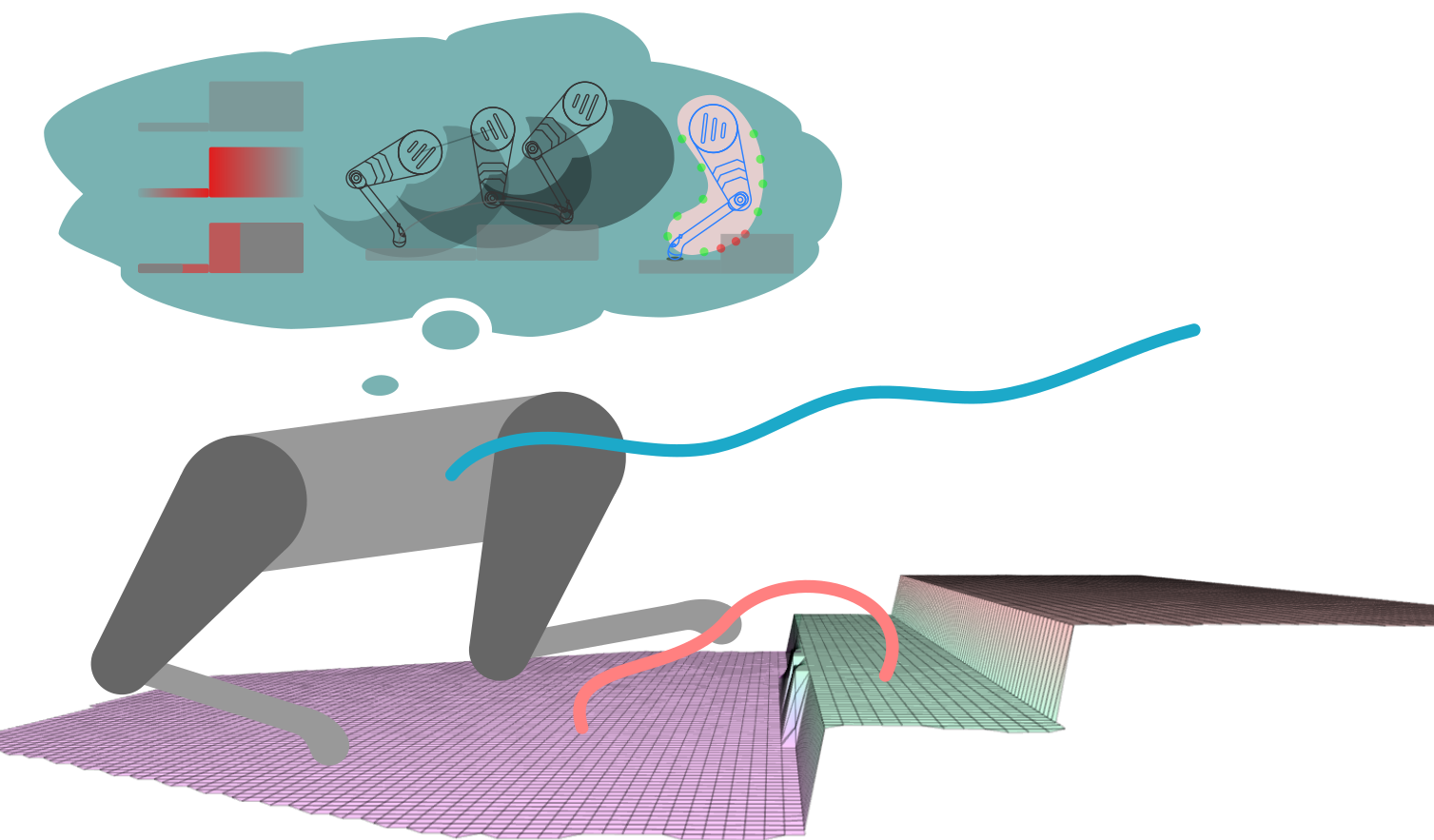
What the robot is capable of doing?
- Avoid edges, corners, gaps, etc.
- Remain with the workspace of the legs.
- Avoid colliding with the terrain.
Foothold Evaluation Criteria (FEC)
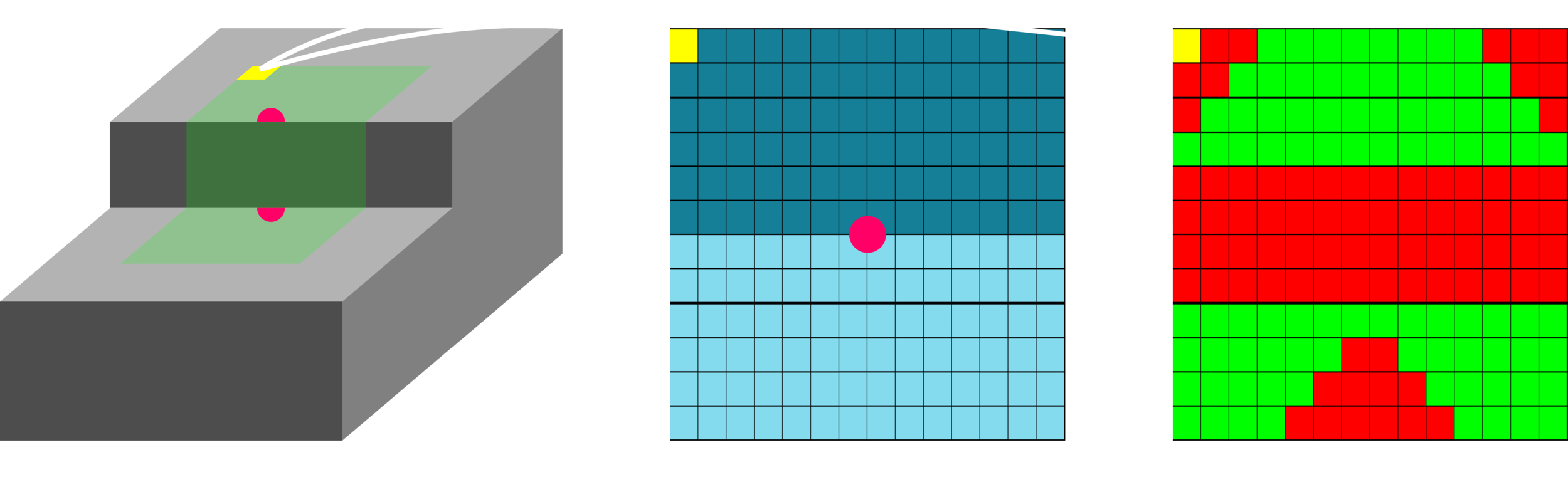
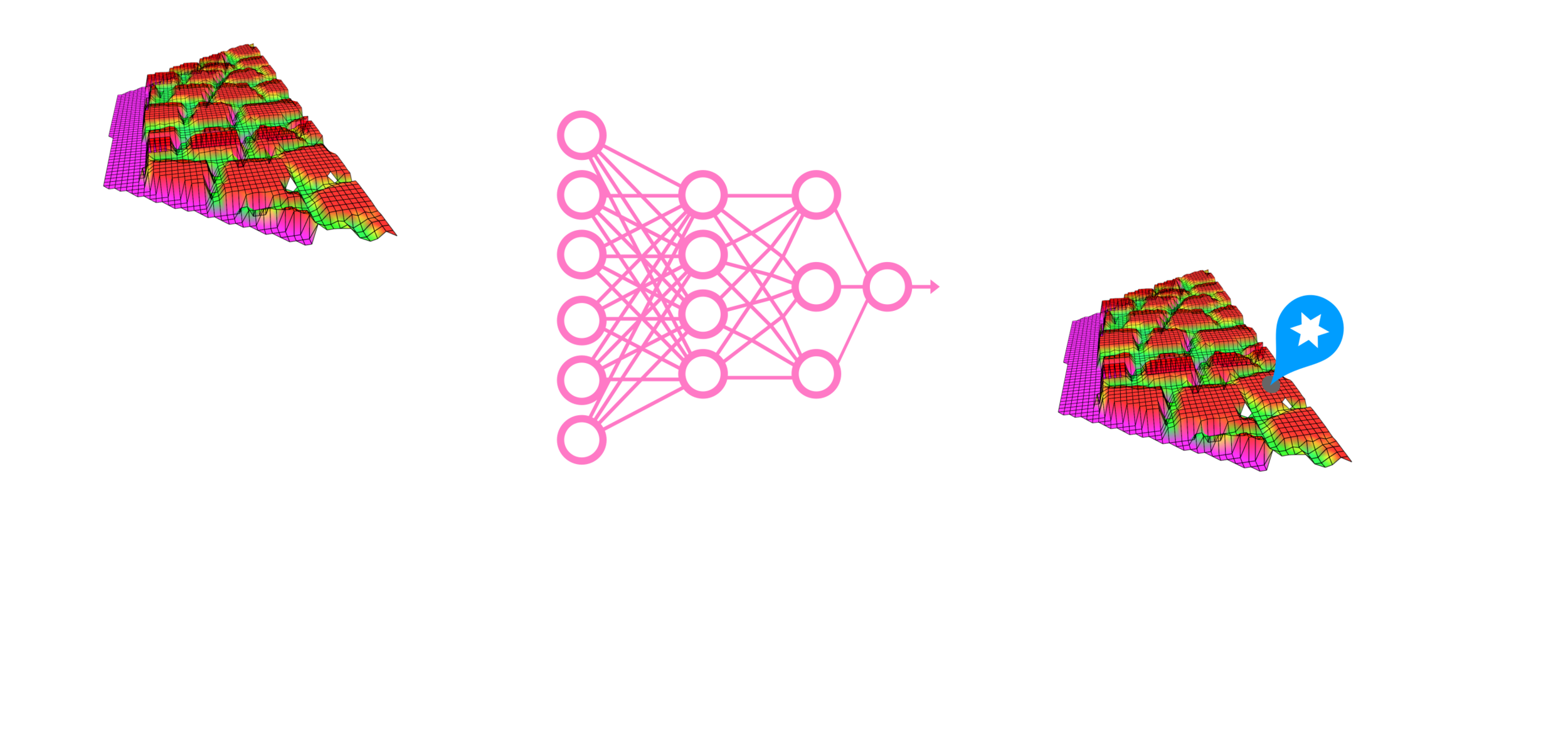
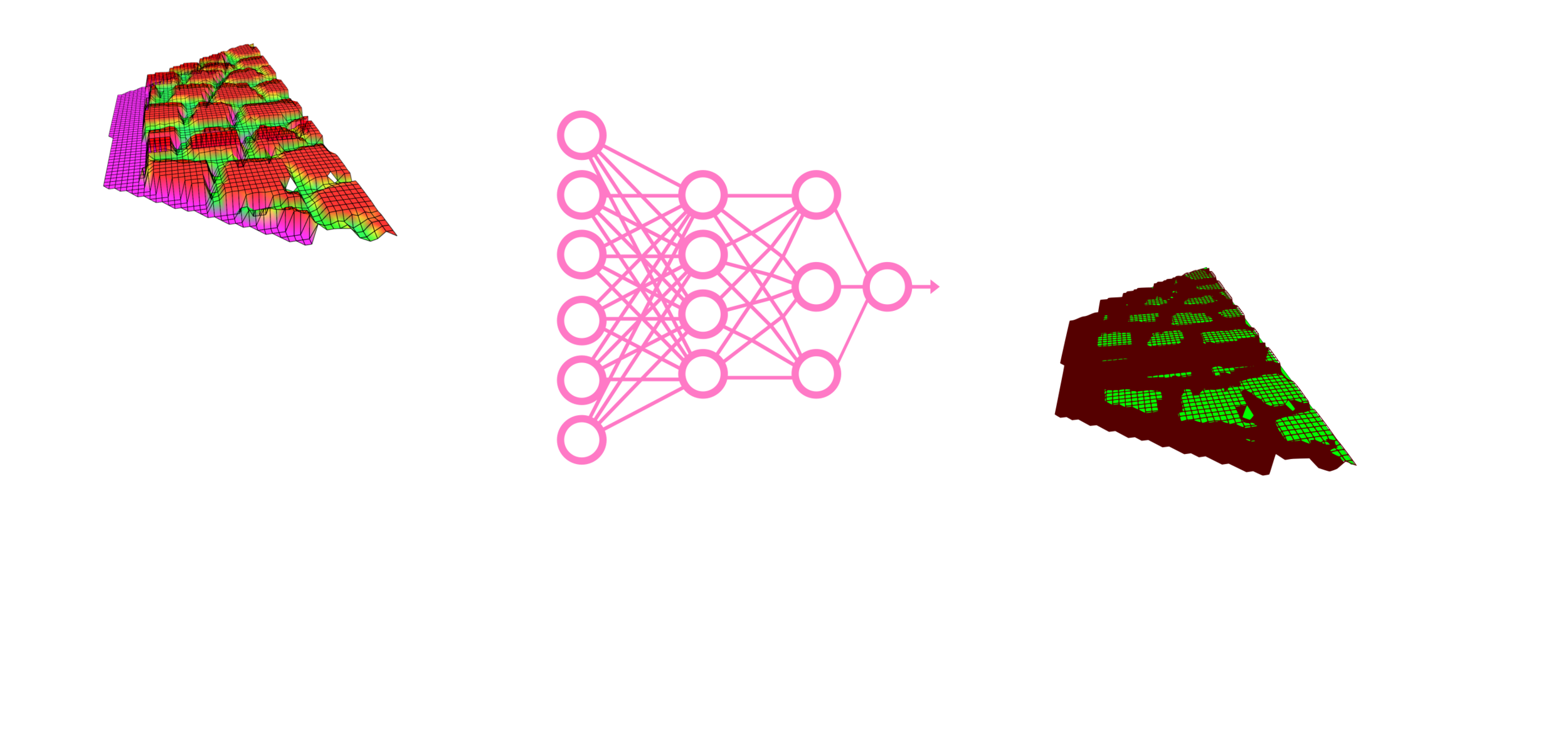
The FEC is a way to evaluate footholds given a heightmap, the leg's hip height, & other robot states.
When the criteria are evaluated, a boolean matrix is given as an output.
Each pixel in the heightmap represents the terrain height corresponding to the pixel's location in the terrain map.
The heightmap is a 2D representation of the terrain.
Each pixel is a candidate foothold for the robot.
The boolean matrix characterizes which pixel (location) in the heightmap is feasible (safe) or not based on the robot's capabilities (the criteria).
Foothold Evaluation Criteria (FEC)
Rejects footholds that cause foot trajectory collision.
- Foot Trajectory Collision (FTC)
Rejects footholds that are outside the workspace during the entire gait phase.
- Kinematic Feasibility (KF)
Rejects footholds that cause leg collision with the terrain.
- Leg Collision (LC)
- Terrain Roughness (TR)
Rejects footholds that are near holes, spikes, edges, and corners.
Vision-Based Foothold Adaptation (VFA)
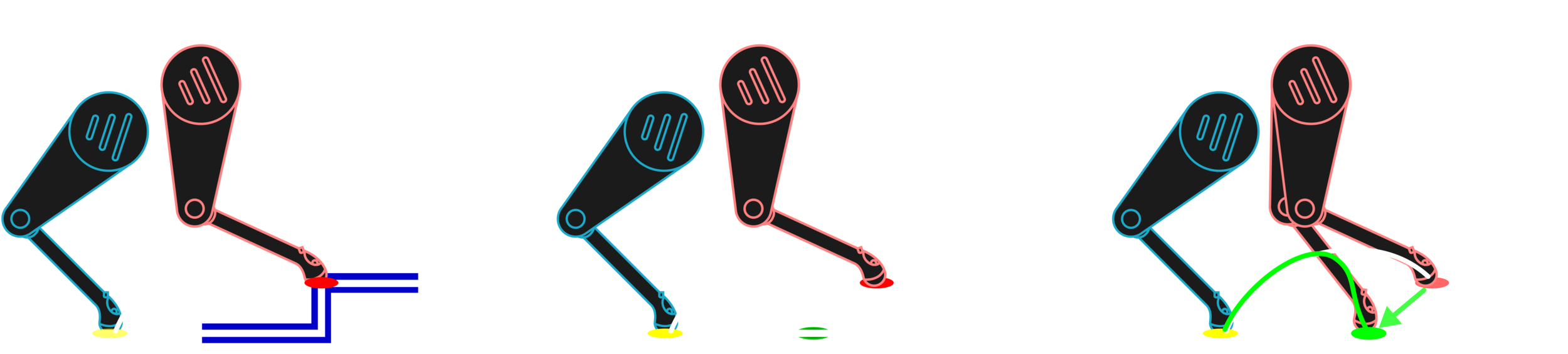

From the VFA to the VPA

First, we extract heightmaps that are centered around the projection of the leg hip location.
Vision-Based Pose Adaptation (VPA)
Then, the pose evaluation stage will evaluate the criteria for all the samples of the hip heights.
The pose evaluation stage will output samples of number of safe footholds.
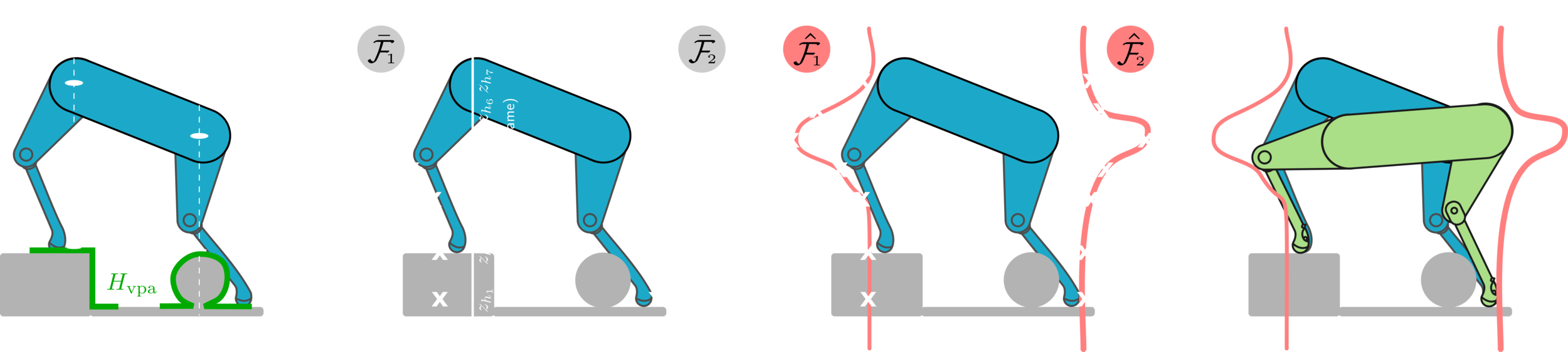
Vision-Based Pose Adaptation (VPA)
The output of the function approximation is
These samples are then used to approximate a continuous function of the number of safe footholds at the function approximation stage.
Vision-Based Pose Adaptation (VPA)
Finally, the pose optimization stage finds the optimal pose that maximizes for all of the legs
Vision-Based Pose Adaptation (VPA)
Find the optimal robot's trunk pose that maximizes the number of safe footholds for all the legs
Height
Roll
Pitch

Pose Optimization
Pose Optimization
front hips rising up
front hips lowering down
hind hips rising up
hind hips lowering down
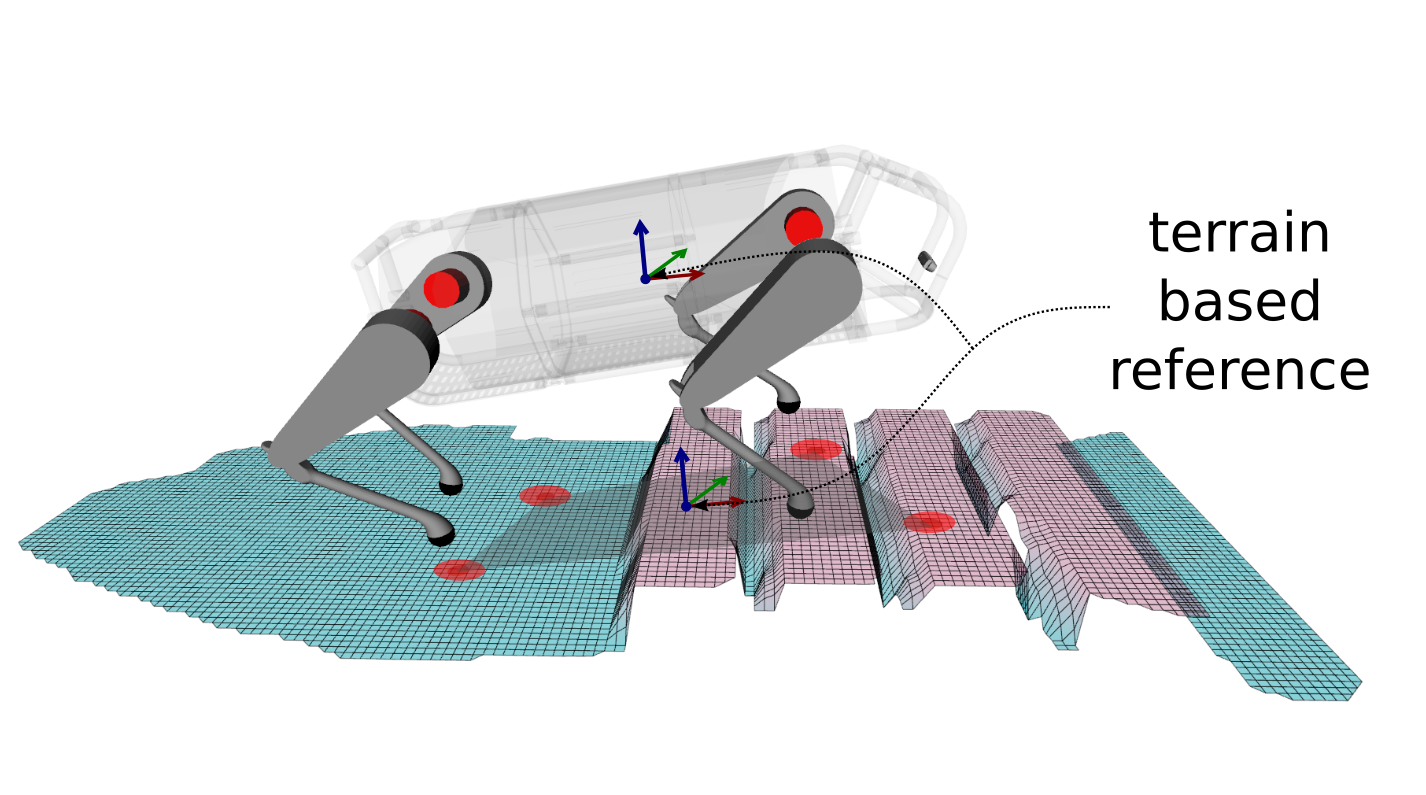
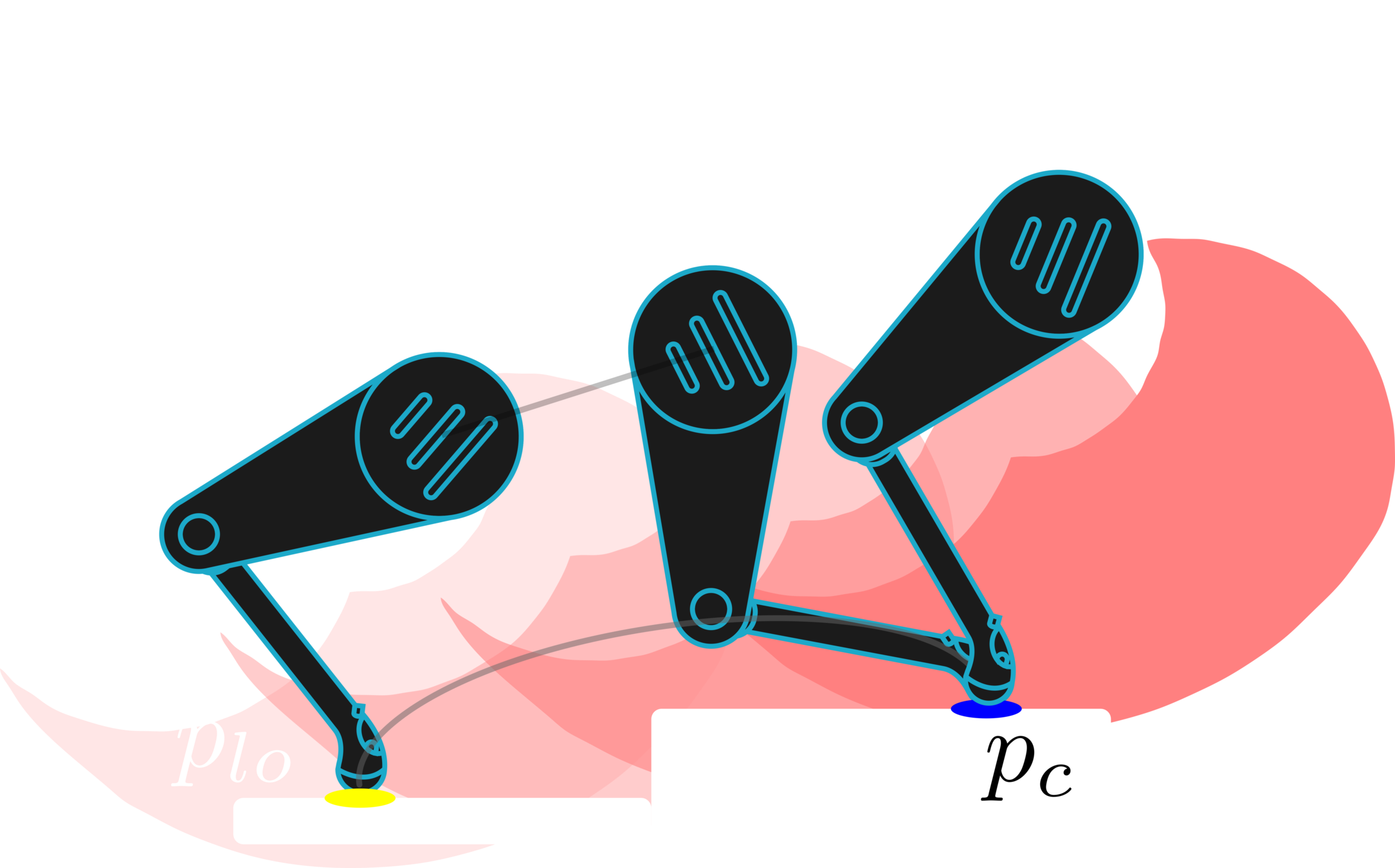
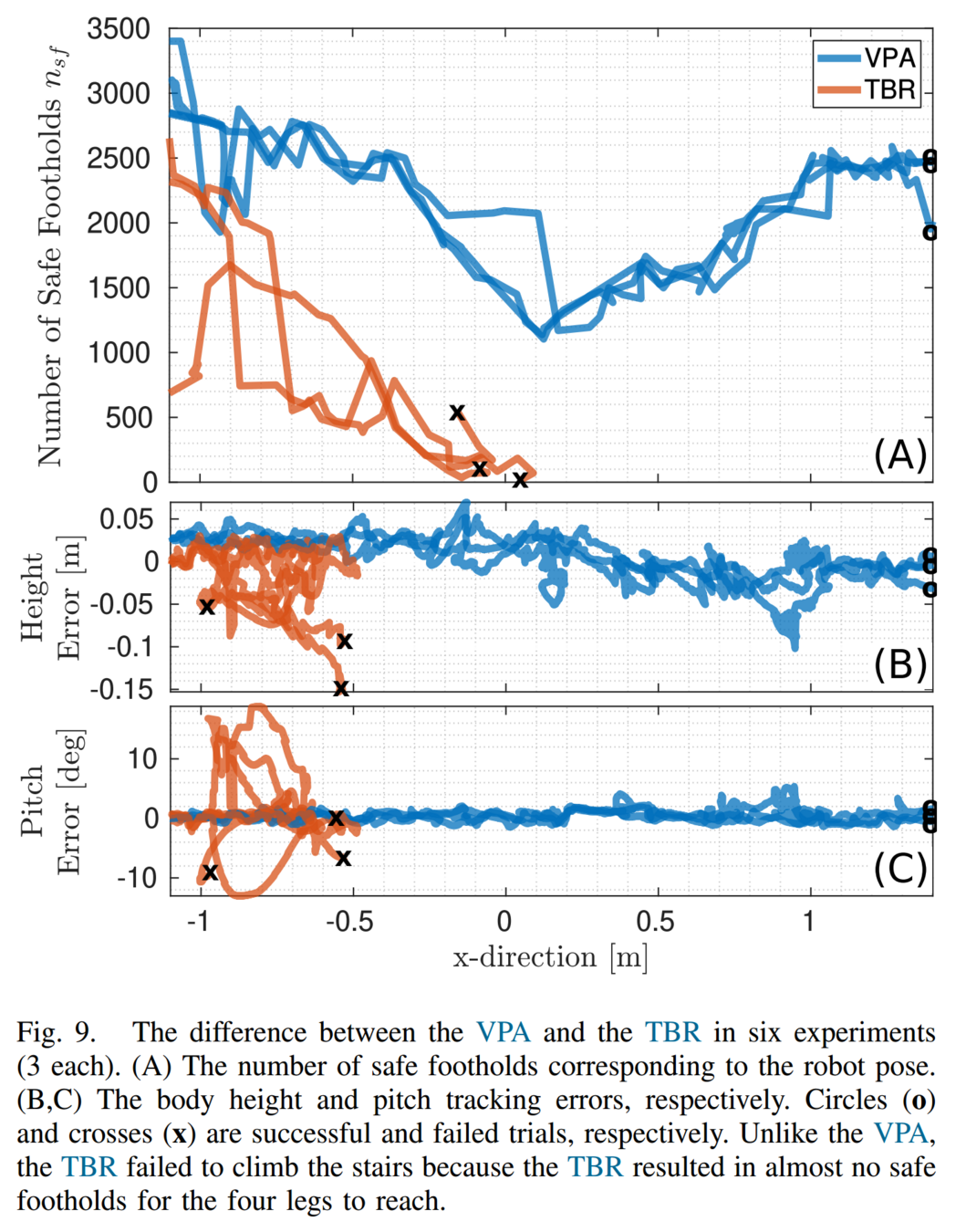
Baseline: Terrain-Based Reference (TBR)
O. Villarreal et al., MPC-based Controller with Terrain Insight for Dynamic Legged Locomotion, ICRA, 2020.
Conclusions: ViTAL
-
We presented ViTAL, a decoupled visual planning strategy
-
ViTAL consisted of :
-
VFA for foothold selection
-
VPA for pose adaptation
-
Introduced a different paradigm in pose adaptation
-
Finds the body poses that maximize the chances of the legs to succeed in reaching safe footholds
-
-
FEC (notion of safety) that characterizes the robot's capabilities
Conclusion: ViTAL
-
ViTAL allows HyQ and HyQReal to traverse a wide variety of terrains under various forward velocities.
-
These terrains included stairs, gaps, etc.
-
Forward velocities varied from 0.2m/s to 0.75 m/s.
-
-
We showed that the VPA resulted in body poses that are aware of the terrain, and of what the robot and its legs can do.
-
The VPA puts the robot in a pose that provides the feet with higher number of safe footholds which allows the robot to succeed unlike the baseline that fails.
Published In:
S. Fahmi, V. Barasuol, D. Esteban, O. Villarreal, and C. Semini,
“ViTAL: Vision-Based Terrain-Aware Locomotion for Legged Robots,” IEEE Trans. Robot. (T-RO), Nov. 2022, doi: 10.1109/TRO.2022.3222958.
Model-Based vs. Reinforcement Learning
-
Model-Based Control
-
Interpretable
-
Based on physics
-
Easier to tune & design
-
-
Reinforcement Learning
-
Model-free
-
Harder to interpret, design, & tune
-
Less sensitive to modeling & state estimation inaccuracies
-
-
Can we combine the best of both worlds?
-
Train an RL policy that tracks (imitates) reference trajectories from model-based optimal controllers?
RL for Legged Robots
[1] N. Rudin et al., Learning to walk in minutes using massively parallel deep reinforcement learning, CoRL, 2021.
[2] G. Ji et al., Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion,” RA-L, 2022.
[3] J. Siekmann et al., Sim-to-real learning of all common bipedal gaits via periodic reward composition, ICRA, 2021
[4] X. B. Peng et al., Learning agile robotic locomotion skills by imitating animals, RSS 2020.
[5] X. B. Peng, et al., Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,” ACM Trans. Graphics, 2018.
-
Heuristic Rewards [1-3]
-
Hand-crafted
-
Requires tedious tuning
-

-
Motion Imitation [4,5]
-
Uses MoCap (or video clips) ⇒ hard to get
-
Motion retargeting ⇒ kinematically inaccurate
-
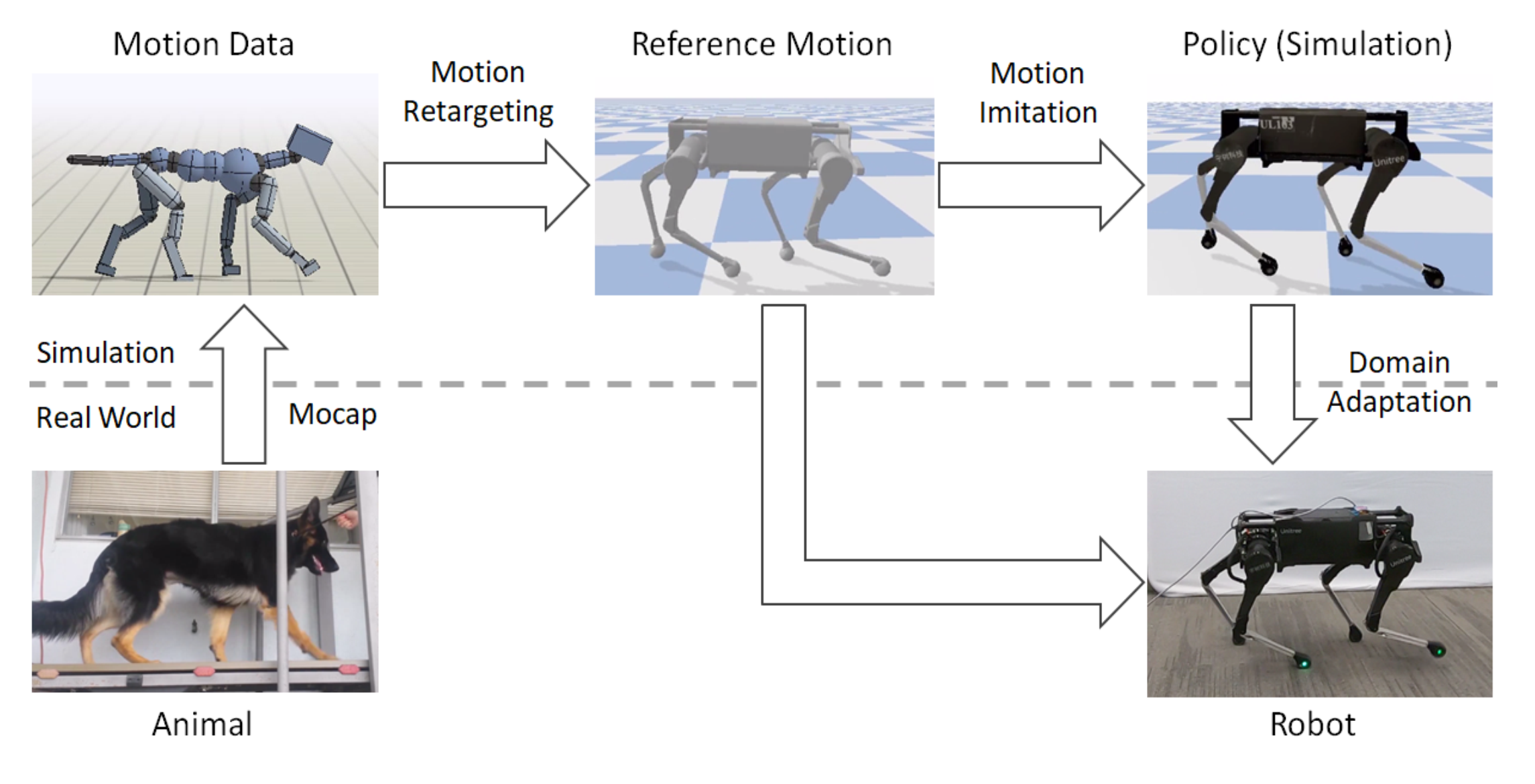
-
PMTGs
GPGs + residuals
Gait dependent
Proposed Approach
-
MIMOC is a locomotion controller that learns from model-based optimal controllers.
-
This is an RL approach via motion imitation.
-
Instead of MoCap, we rely on reference trajectories from model-based optimal controllers.
-
MIMOC: Motion Imitation from Model-based Optimal Control
MIMOC's Contributions
-
Unlike RL via motion imitation (MoCap), our references
-
Consider the robot's whole-body dynamics ⇒ dynamically feasible
-
Do not need motion retargeting (robot-specific) ⇒ kinematically feasible
-
Include torques and GRFs which are crucial for balance
-
-
As a result, compared to RL via motion imitation
-
The sim-to-real gap is significantly reduced
-
No fine-tuning stage and no tedious reward tuning were needed
-
-
Unlike model-based controllers
-
There were no issues with running the policy in real-time
-
The policy is less sensitive to state estimation noise and model inaccuracies
-
MIMOC's RL Framework
-
Inputs: commands, phase (clock), and (some) robot observations
-
Actions: joint set-points going through a PD controller at 100 Hz
-
The references are only used to calculate the rewards
-
The rewards are only tracking rewards, without hand-tuning

MIMOC's RL Framework
-
We used an MPC + WBC for the Mini-Cheetah and the MIT Humanoid
-
We used IsaacGym with the Legged Gym Implementation
D. Kim et al., Highly dynamic quadruped locomotion via whole-body impulse control and model predictive control, ArXiV, 2019.
N. Rudin et al., Learning to walk in minutes using massively parallel deep reinforcement learning, CoRL, 2021.
-
Rewards: only tracking rewards of weighted squared exponentials
-
Observations
-
Actions: PD set-points
-
Domain Randomization: noise, friction, body mass, push robots, and gravity.
MIMOC's RL Framework
Published In:
A.J. Miller, S. Fahmi, M. Chignoli, and S. Kim,
"Reinforcement Learning for Legged Robots: Motion Imitation from Model-Based Optimal Control," ArXiV preprint, May 2023.