NLP 自然語言處理
自然語言相關體系
- 自然語言處理 (Natural Language Processing, NLP)
- 基本斷詞、句子處理、詞性辨識、實體判斷
- 基本斷詞、句子處理、詞性辨識、實體判斷
- 自然語言理解 (Natural Language Understanding, NLU)
- 知識圖譜、語意關聯、上下文理解、意圖判斷
- 知識圖譜、語意關聯、上下文理解、意圖判斷
- 自然語言生成 (Natural Language Generation, NLG)
- 報告生成、影片字幕、回應輸出、文本排版
各式文本
前處理
文本
理解、關聯
文本
編排、輸出
自然語言應用

自然語言理解
理解指令
理解語意
理解邏輯
自然語言理解 - 歷史

自然語言理解 - 技術歷史
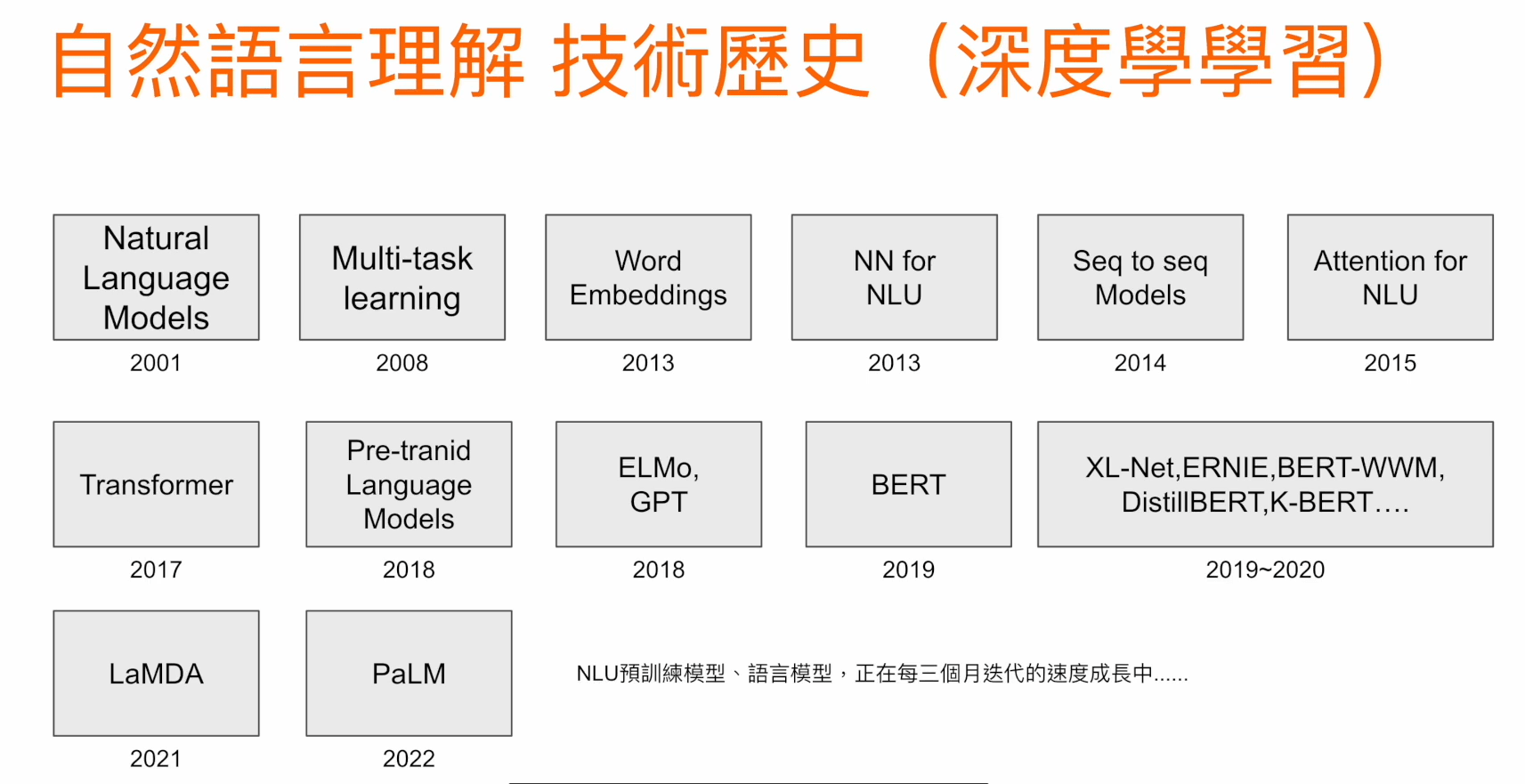
以深度學習為基礎的發展
自然語言
自然語言
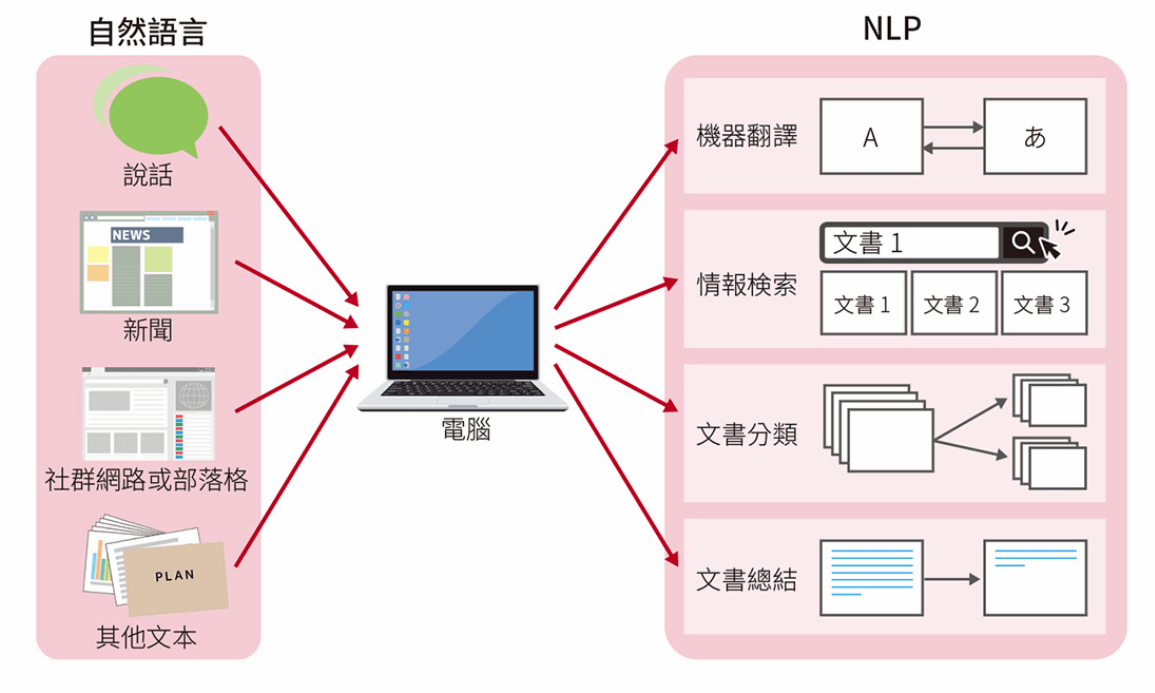
處理日常語言的 NLP
NLP







機器翻譯
資訊檢索

文書分類
文件總結
說話
新聞
社群網站
其他文本
電腦
處理日常語言的 NLP
NLP 之前需準備的資料集

文本資料前處理
套用正確的字詞編碼
字元編碼

文字資料的正規化
將文字資料轉換成一種更標準或統一的格式的過程
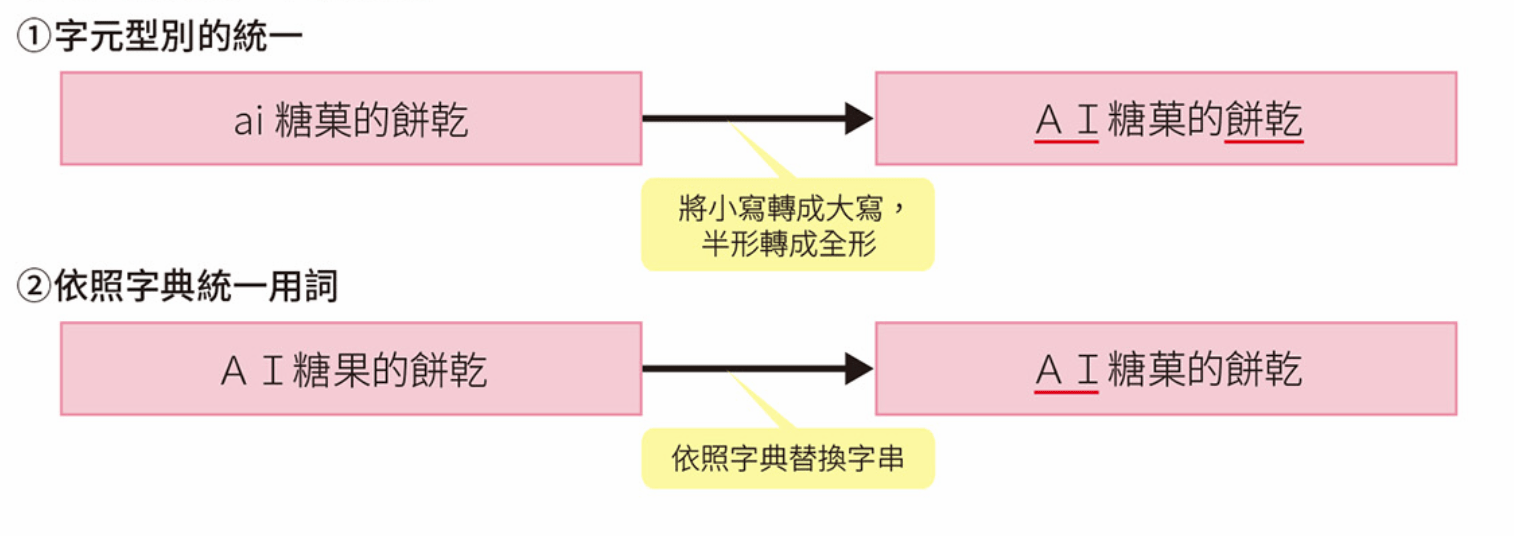
常見的文字資料正規化技術
-
轉換字母大小寫:消除大小寫引起的差異。
-
去除標點符號和特殊字符:可以減少數據的雜亂無章。
-
刪除停用詞:停用詞是指在文本中經常出現但對於理解文本的含義貢獻不大的詞,如“的”、“是”、“在”。刪除這些詞可以幫助減少數據集的大小和複雜性。
-
詞幹提取(Stemming)和詞形還原(Lemmatization):這兩種技術都旨在將詞彙還原到其基本形式。詞幹提取通過刪除詞尾來實現,而詞形還原則考慮了詞的詞性和完整的詞形變化規則 (如 running, runs, ran 都還原成 run)。
-
分詞:對於使用空白字符分隔單詞的語言(如英語),分詞是將文本分解成單個單詞或詞素的基本步驟。
-
統一詞彙:將文本中的同義詞替換為標準詞彙。
-
數字和日期的標準化:將所有數字格式統一,日期和時間也轉換為標準格式,以便於比較和處理。
Tokenizer
斷詞法
將文本分割為較小單位的工具或方法,這些單位可以是單詞、子詞、字元甚至句子,具體取決於應用場景和模型需求。
基於規則的 Tokenizer
通過使用明確的規則(如空格、標點符號等)將文本分割為 Token
- WordNet Lemmatizer:利用WordNet詞典來查找詞元,這是在Python的Natural Language Toolkit(NLTK)庫中使用的一種常見方法。
- spaCy Lemmatizer:spaCy是一個流行的NLP庫,提供了強大的詞形還原功能,並能根據詞的詞性來進行準確的詞形還原。
常用的詞形還原工具
明確化單詞的分界點
- 語素 (morpheme) 是單伺的最小單位
- 語素分析是分析單詞的分界點、所屬詞類、詞形變化等的處理工作。

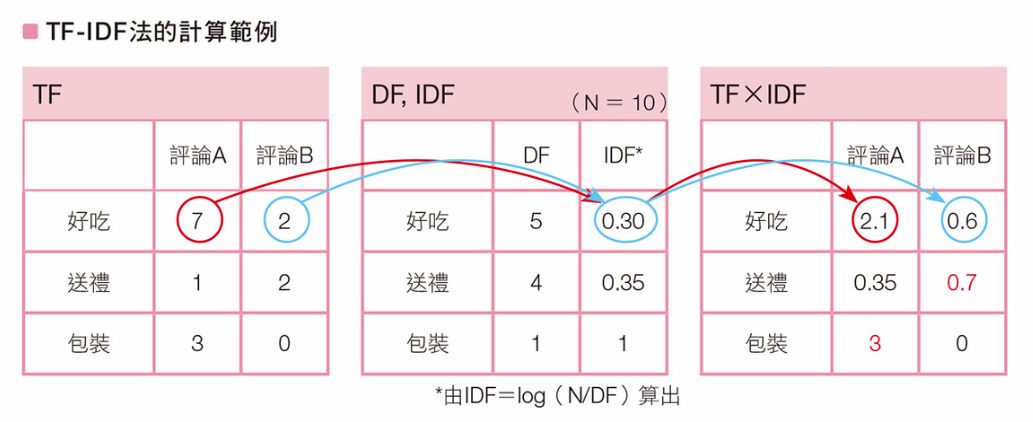
TF-IDF法:提取重要的單詞
TF (Term Frequency) 詞彙頻率
DF (Document Frequecny) 文檔頻率
相當於文字雲中的字體大小
單詞在文檔中出現了多少次
IDF (Inverted Document Frequecny)
逆向文檔頻率
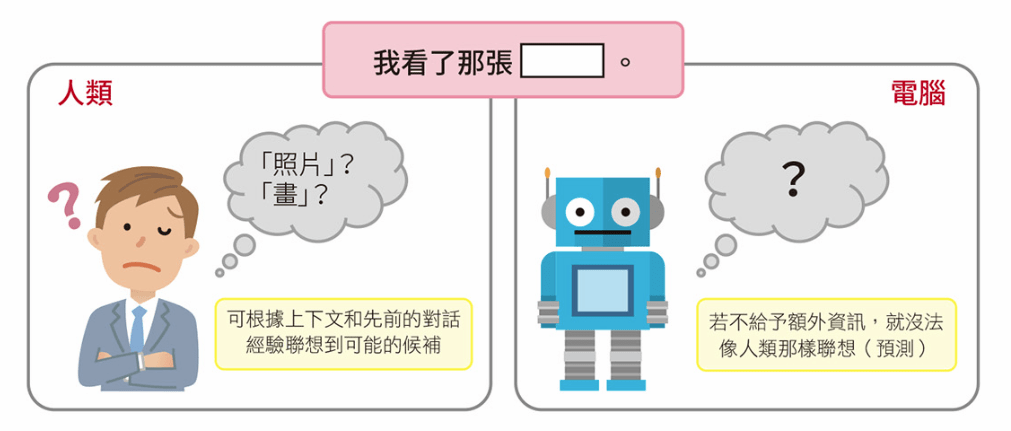
語言模型
預測單詞出現機率的語言模型
語言模型 (Language Model)
二元語言模型 (Bigram Language Model)
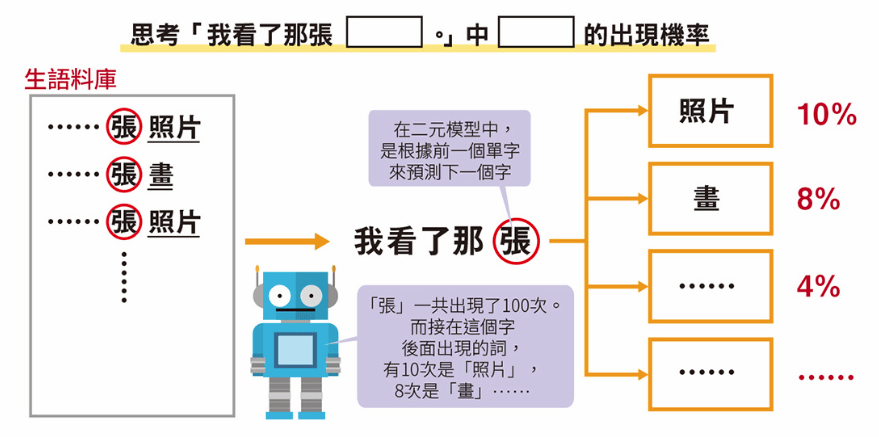
預測下一個單詞出現的機率
將單字轉成向量
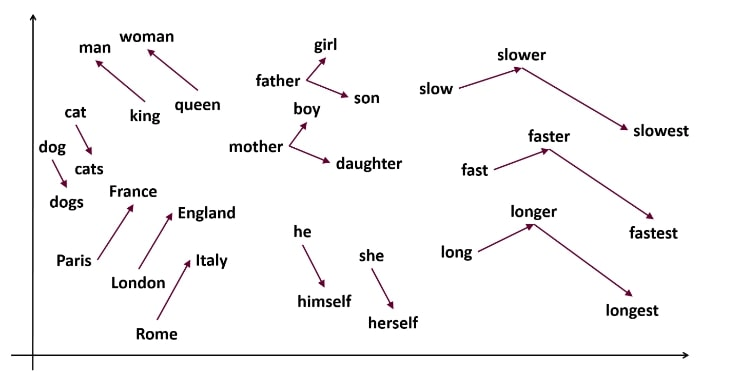
具有相似概念的單字會嵌入在相似的位置中
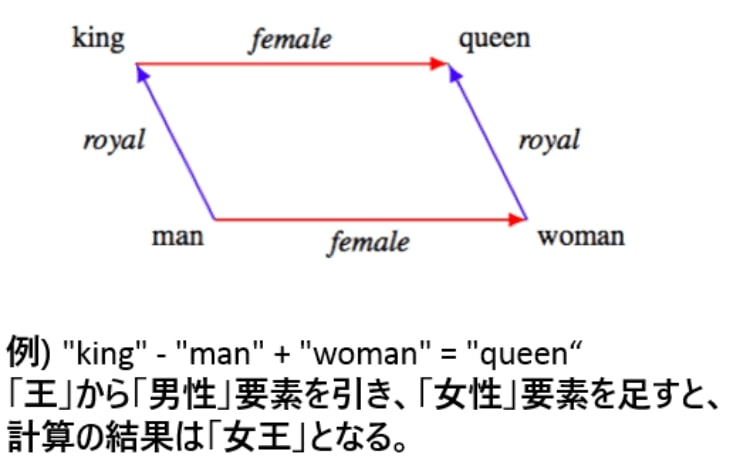
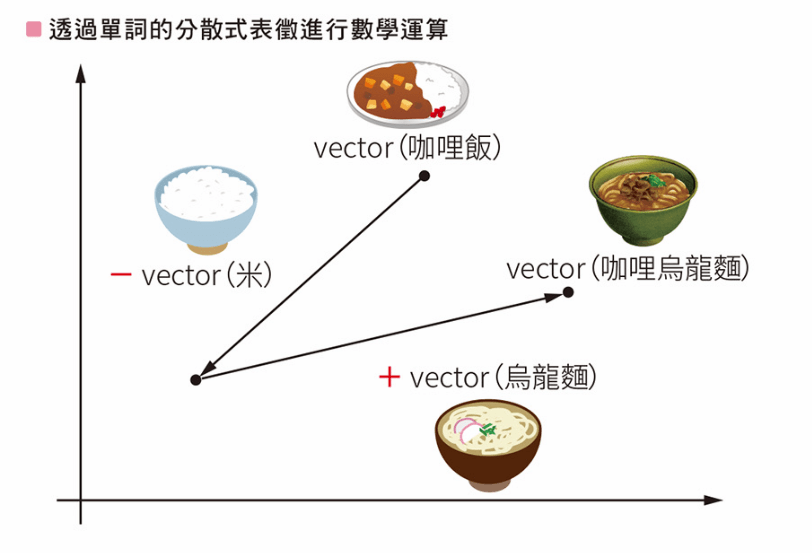
由於每個概念彼此相關,分佈式表示允許在表示不同概念的向量之間進行計算。例如
king - man + woman = queen
用詞向量來表現特徵
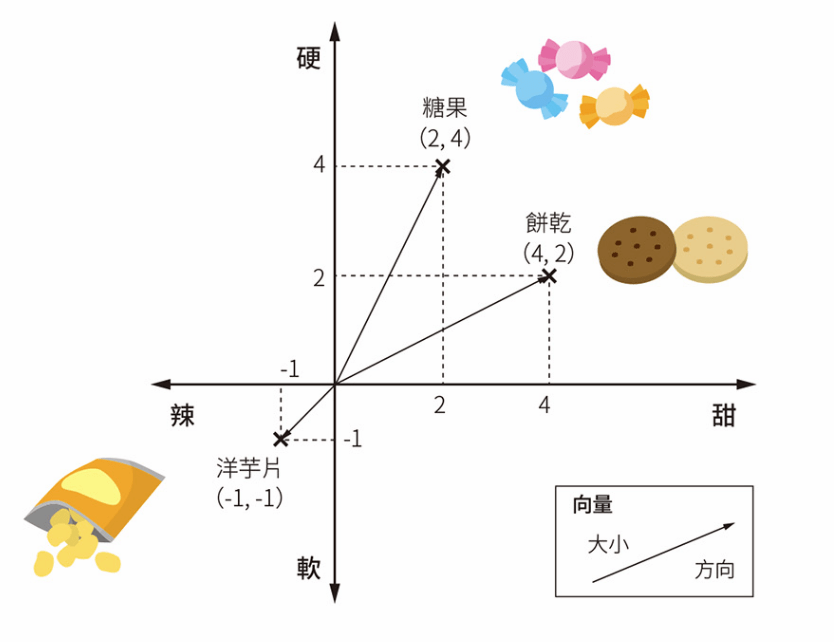
向量具有方向及大小
座標軸即維度
餅乾的維度:甜辣、軟硬。氣味、外觀…
編碼 (Encode)
將字詞依照特定規則轉換
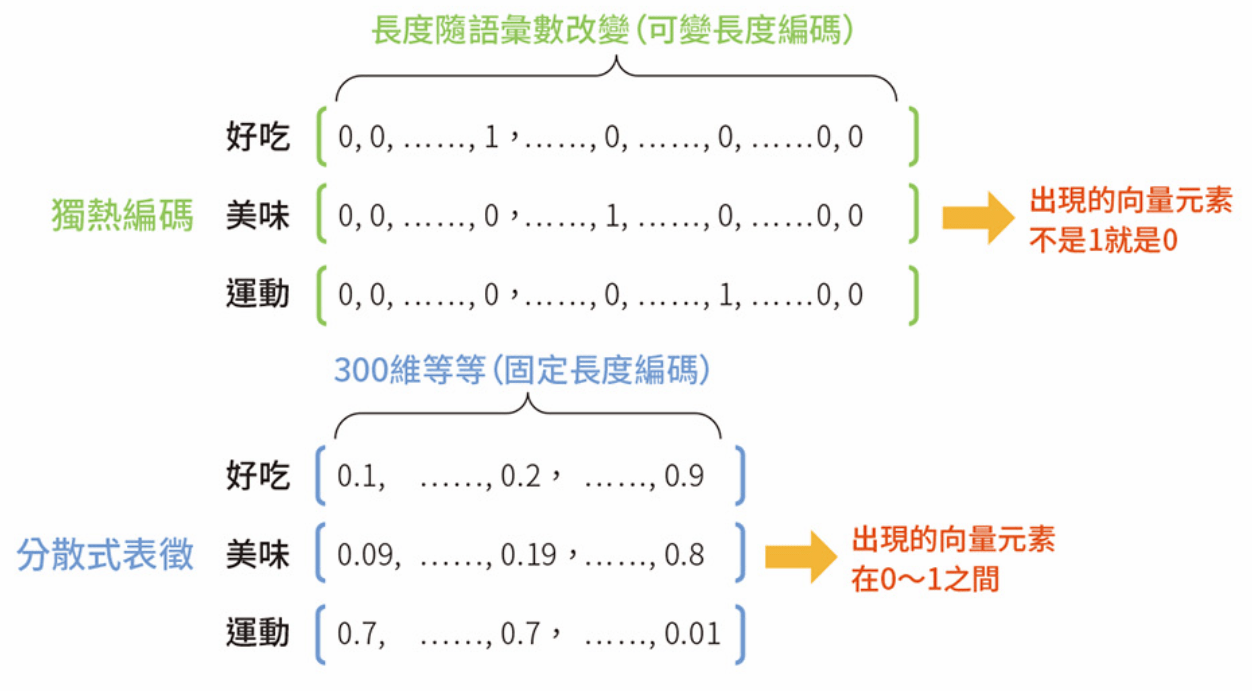
One-hot
Encode
Distributed
Rerpresentation
將單詞嵌入固定長度的向量空間,故又稱為『Word Embedding』
分散式表徵
分散式表徵的理是基於「在相似脈絡中出現的兩個單詞通常擁有相似意義」的「分散假說 (distributional hypothesis)」。
篩選出有出現「美味」或「好吃」的評論時,假如這兩個單詞前後出現的單詞是「非常」和「餅乾」,那麼根據上下文資訊和分散假說,電腦就能推斷「美味」和「好吃」的意義很大機率是一樣的。
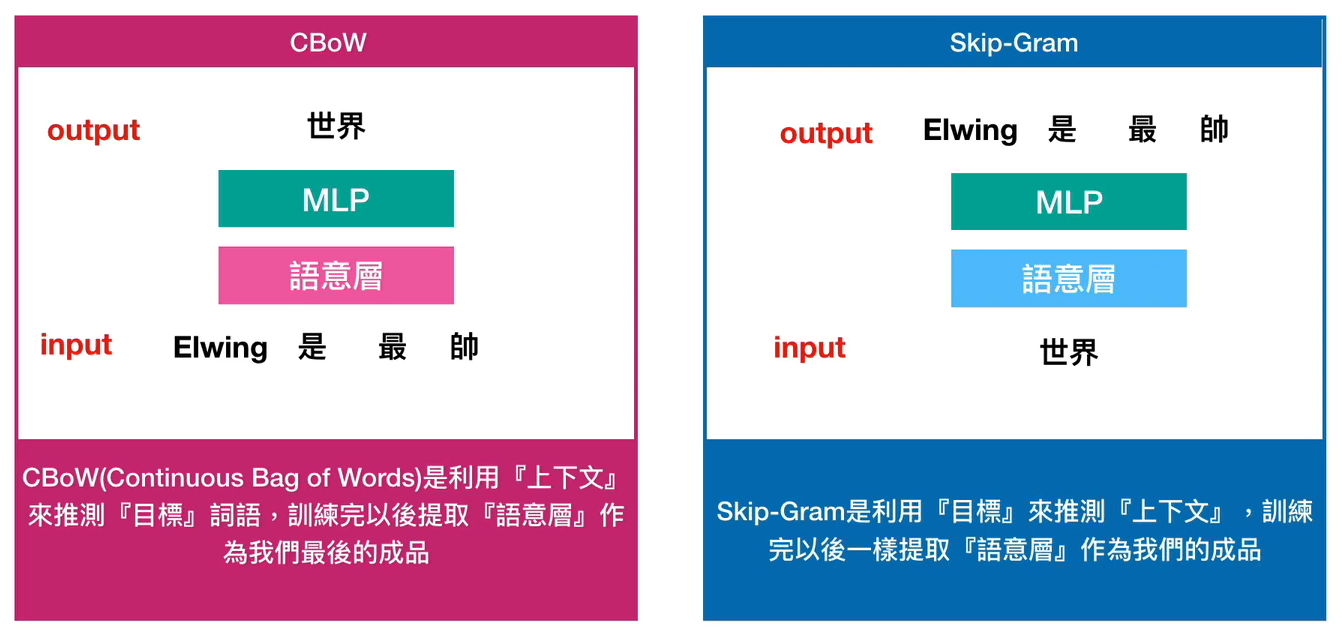
兩個代表模型『CBow』和『連續跳躍式模型』
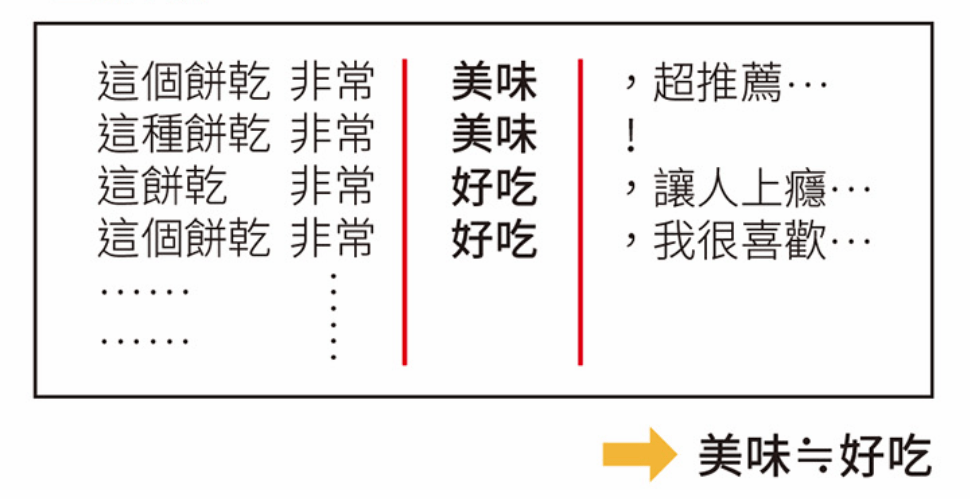
連續詞袋模型
Continuous Bag of Words Model, CBoW
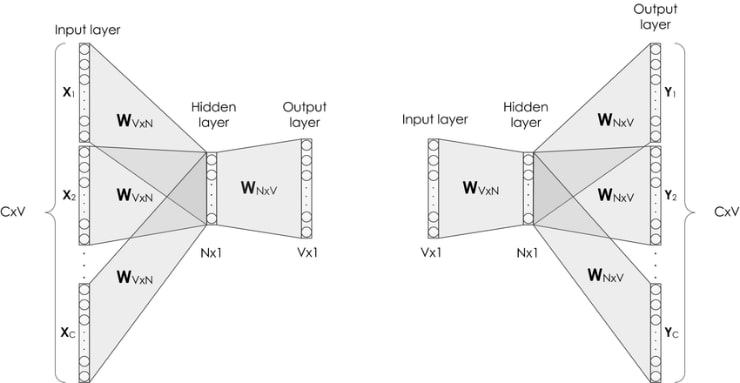
使用神經網路進行學習,取得分散式表徵。
- 輸入層:單詞轉換的 one-hot encode
- 中間層:轉換固定長度編碼的向量。
- 輸出層:各單詞出現機率。
要預測的單詞稱為『目標詞 (target word)』
目標詞附近出現的單詞稱為『語境詞 (context word)』
連續詞袋模型
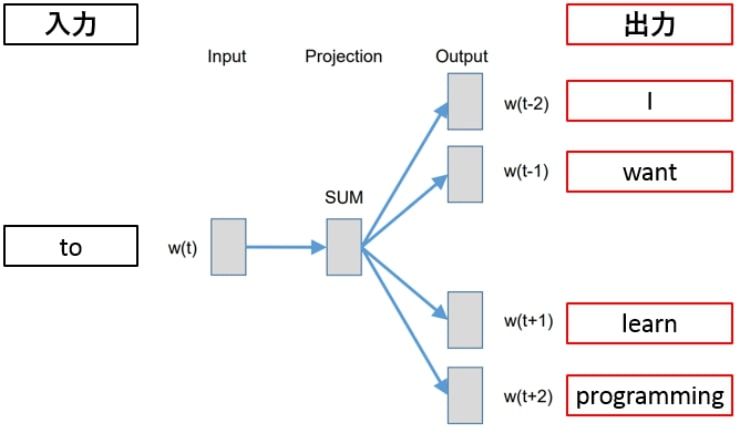
連續跳躍式型
Continuous Skip-Gram Model, Skip-Gram
和CBOW 相反,是用目標詞去推算語境詞出現機率的模型。
Word2Vec
Word2Vec 語意
小明
小明
Word2Vec 語意
目標與上下文的共現性 (共同出現)
兔子 是 一種 ____ 的 生物
在空格裡可以填入的詞可能是
『可愛』『傲嬌』『兇狠』
這些詞轉換成語意就會有一定程度上的相似
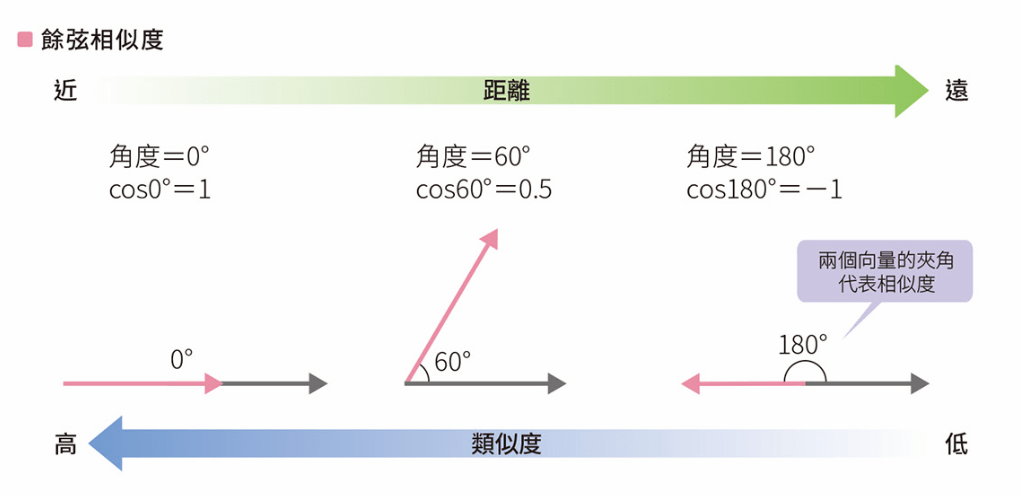
分散式表徵的優點
(1) 可以計算單詞之間的相似度
分散式表徵的優點
(1) 可以用單詞進行數學運算
分散式表徵的優點
(3) 可以作為 NLP 多個任務的輸入資訊

例如:
NLP 的深度學習
2013
運用深度學習的 NLP
word2vec
2014
2017
2018
2020
Seq2seq
Transformer
BERT
GPT-3
透過分散式表徵,模型可以
輸出固定長度的單詞向量
透過注意力機制
使模型能夠平行運算
用龐大的資料進行訓練
成功生成自然的文章
用 Encode-decode 構造的模型提高器翻譯的精度
透過微調在多種任務上
取得高精度的結果
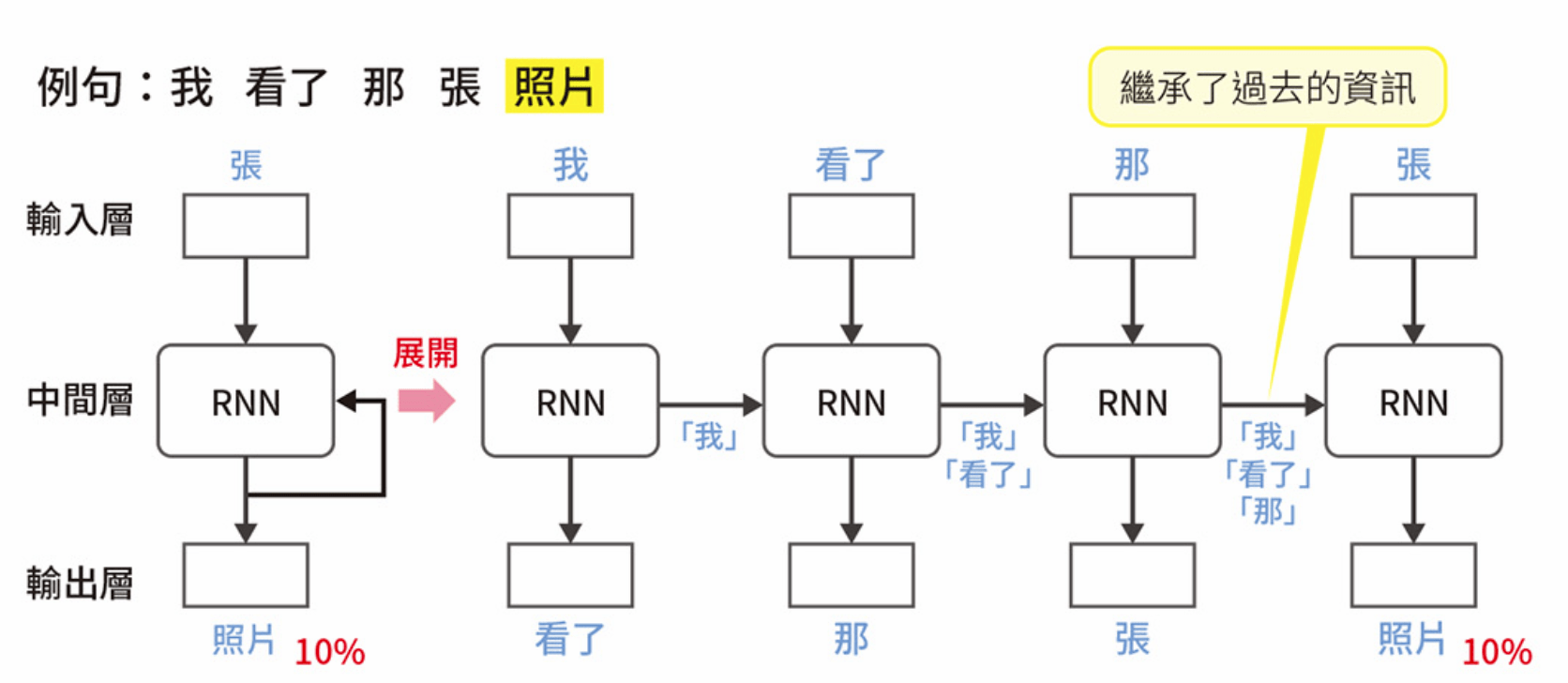
RNN
例句:我 看了 那 張 照片
讓資訊循環進行學習
LSTM, Long Short-Memory
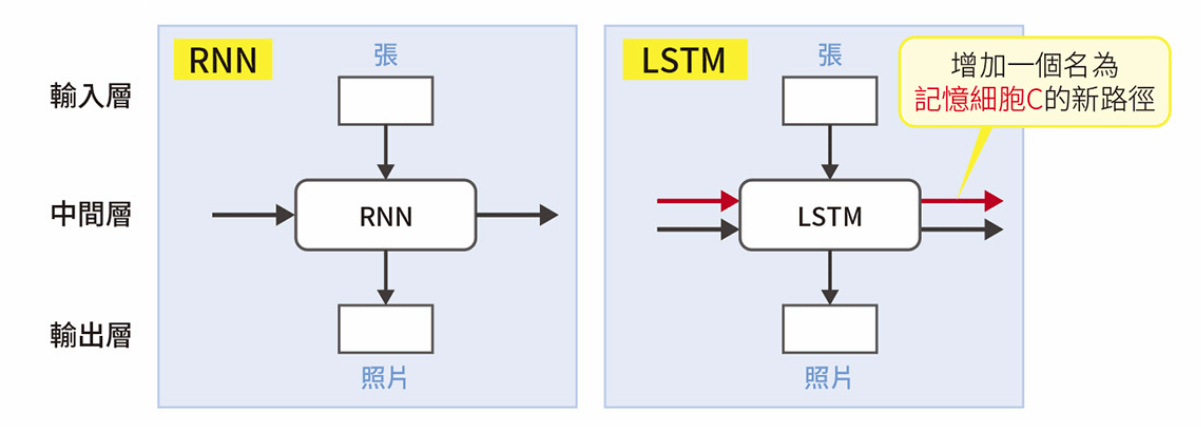
RNN 和 LSTM 的差異
會取捨資訊選擇記憶
LSTM
LSTM 的閘門概念
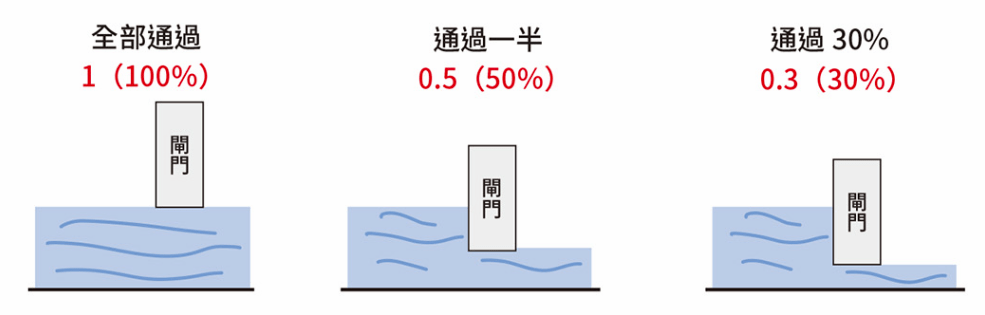
LSTM
LSTM 的構造
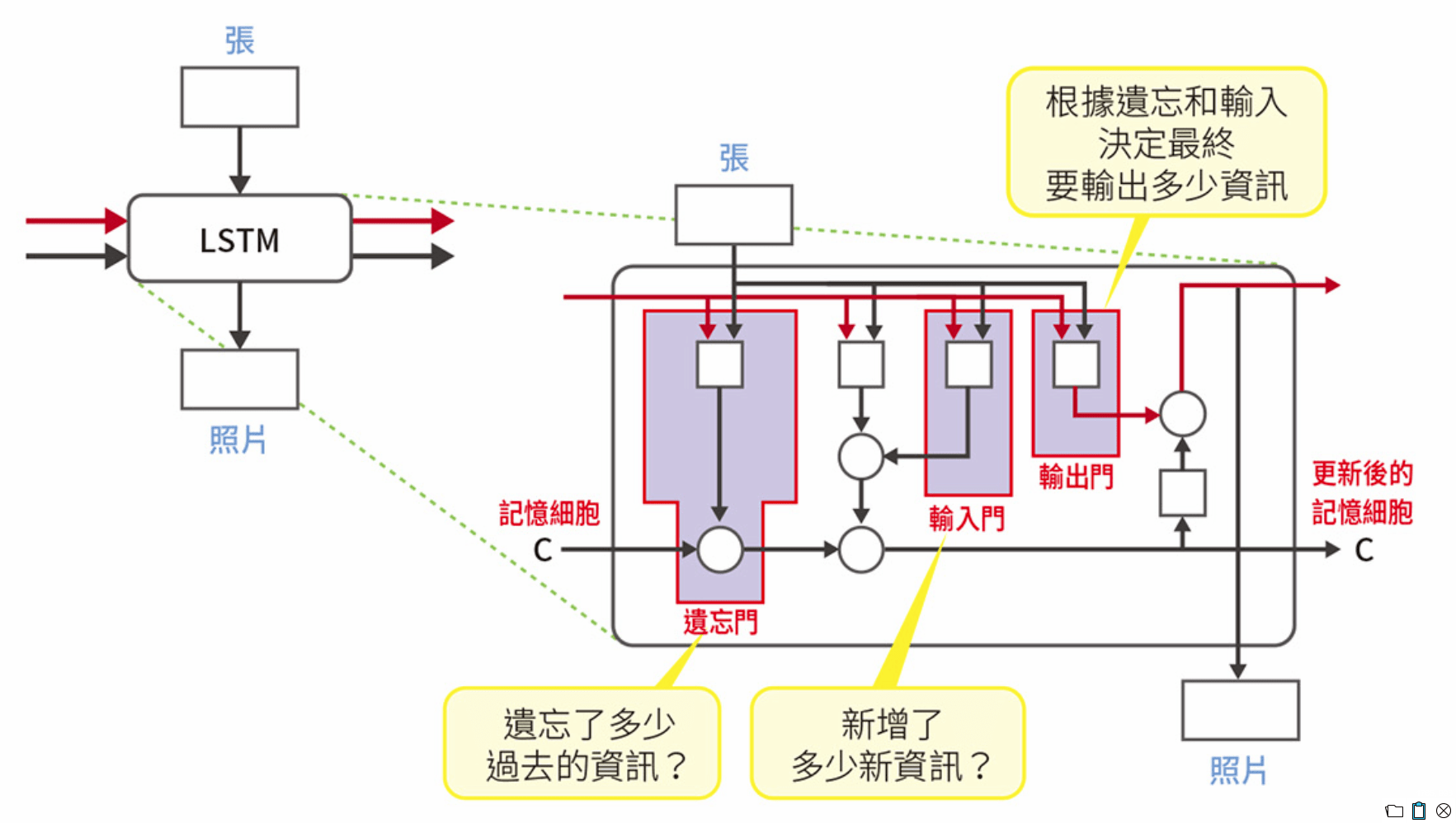
LSTM
LSTM 的三種閘門
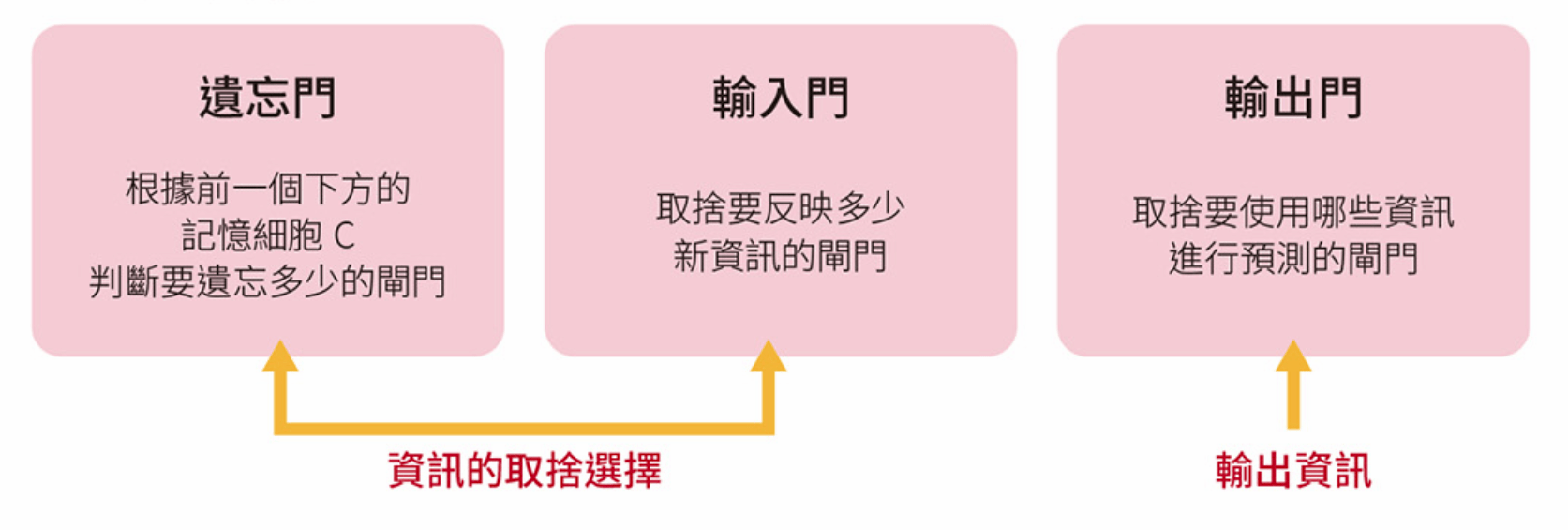
GRU, Gate Recurrent Unit
透過減少閘門數量來縮短計算時間
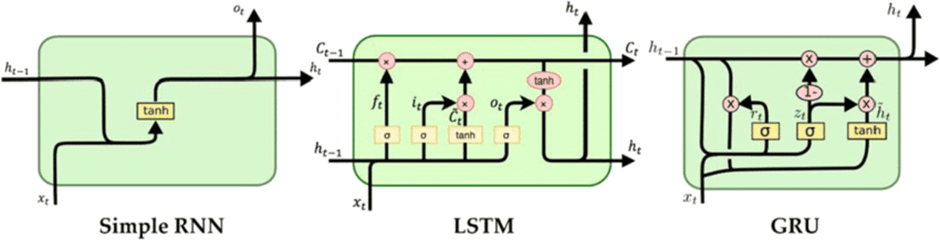
RNN vs LSTM vs GRU
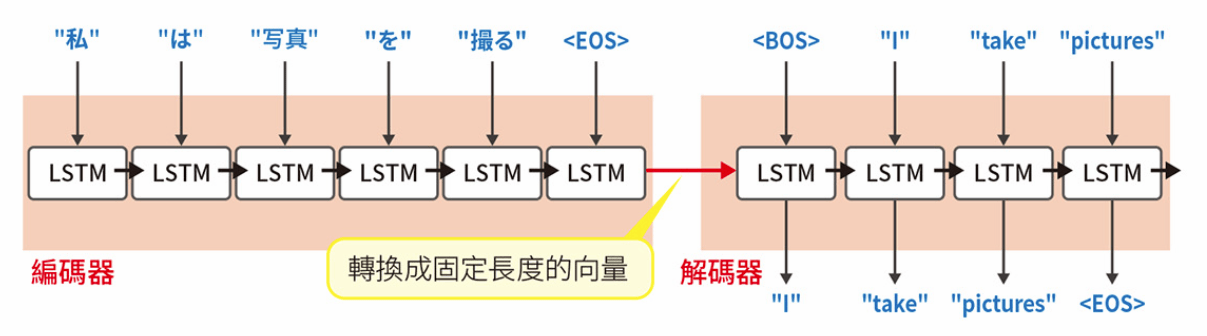
Seq2Seq
輸出的不是單詞,而是序列資料
Sequence to Sequence
又稱為 Encoder-decoder 模型
Seq2Seq (輸出序列資料)
Seq2Seq 的構造
Attention Mechanism
注意力機制
Seq2Seq 的問題
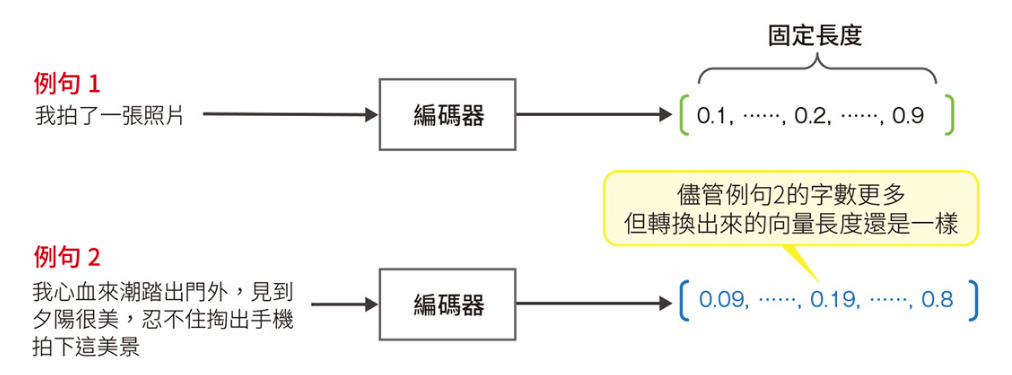
不論輸入的文本是長是短,都會生成固定長度的向量,因此,輸入的文本愈長,模型精度愈低。
注意力機制
Attention Mechanism
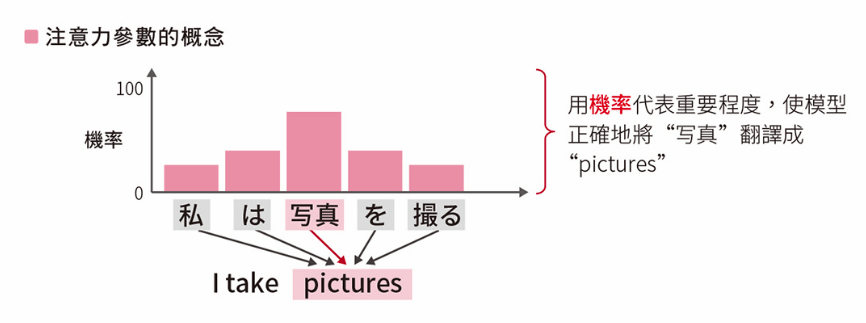
用機率來代表翻譯時用來對照的原始語言中各單字的重要程度
Context Vector 脈絡向量
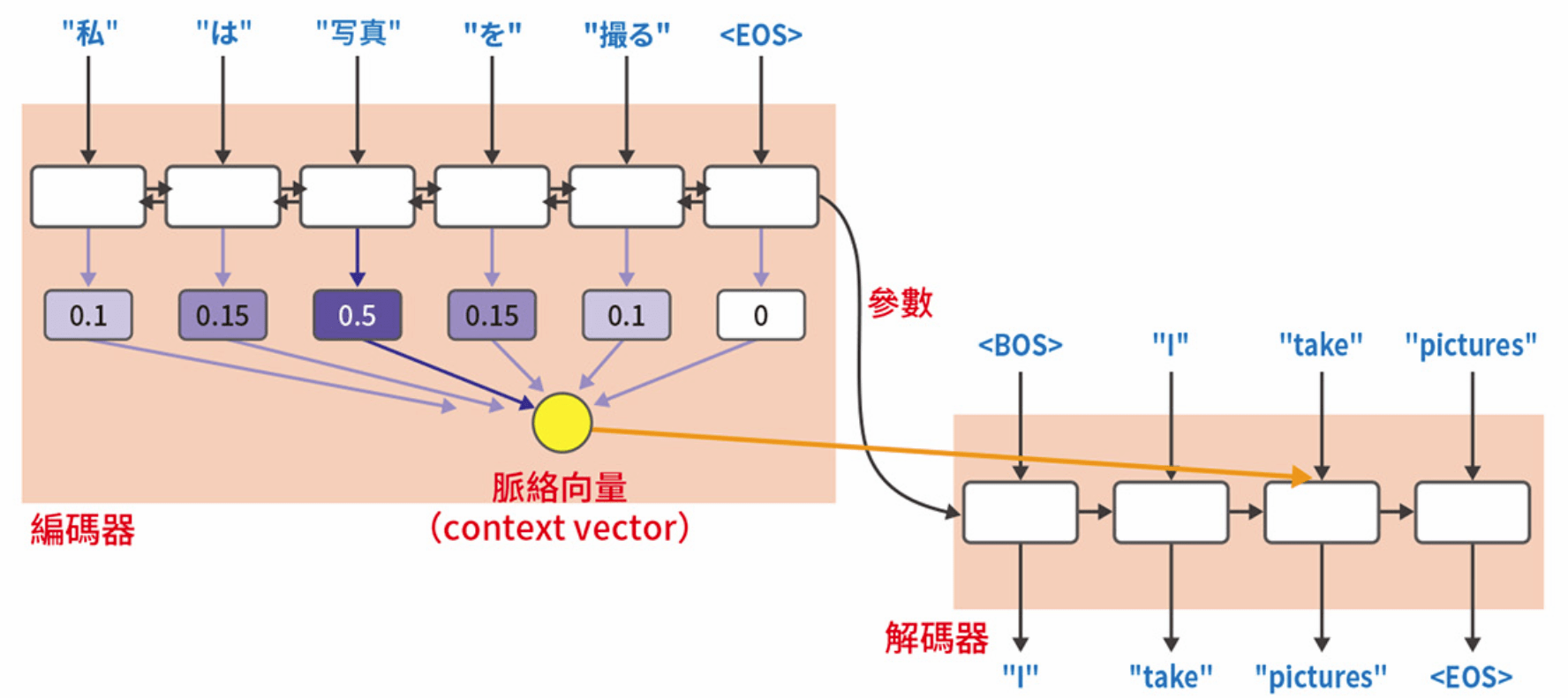
Seq2Seq (輸出序列資料)
加上注意力機制的 Seq2Seq 結構
Transformer
可平行計算的自注意力機制
Seq2Seq 的注意力機制是關注:
原始語言文章和目標語言文章之間的對應關係
自注意力機制
Transformer 使用『自注意力機制』
Self-Attention
關注「自己」文章的對應關係
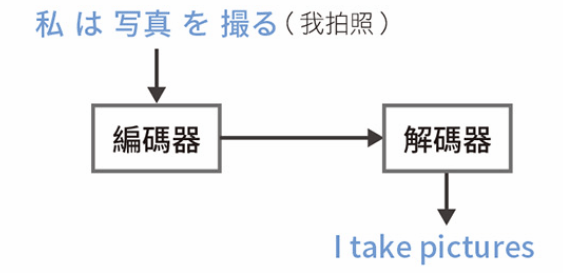
舉例:I take pictures and send them.
(我拍了幾張照片,並把它們發送出去)
自注意力機制
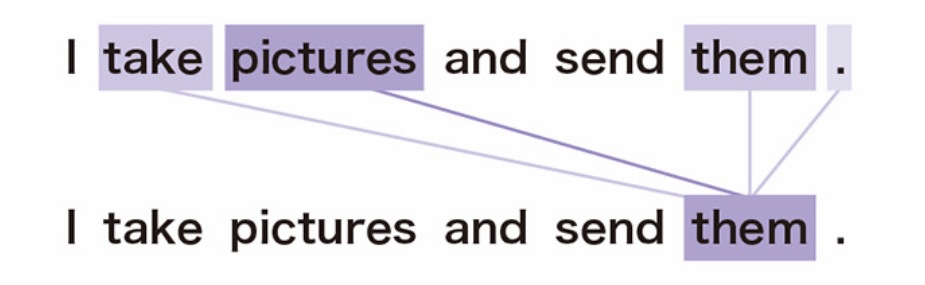
先找出輸入文章的各單詞之間的對應關係
用自注意力計算相似度
可平行計算的自注意力機制
替每個單詞建立 Q (query), K (key) ,V (value) 三個向量
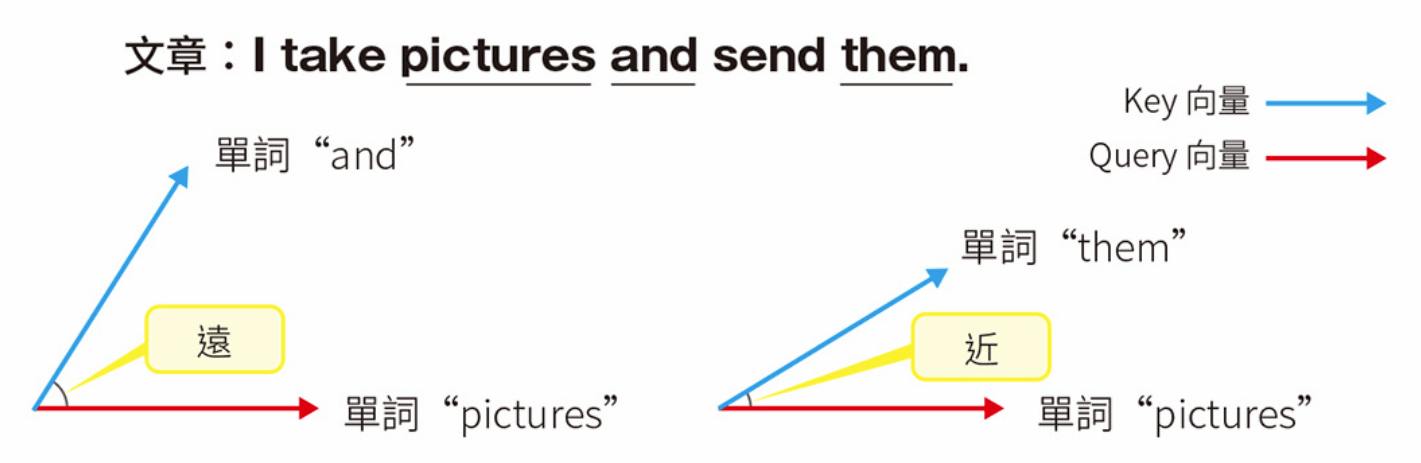
Transformer 透過比較 query 和 key 的向量來計算相似度
Transformer 架構
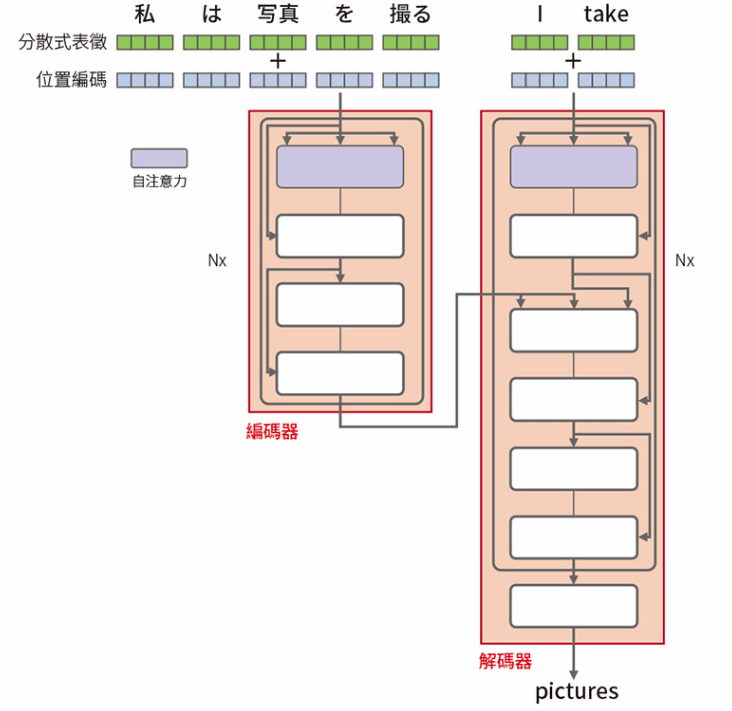
Position Encoding, PE
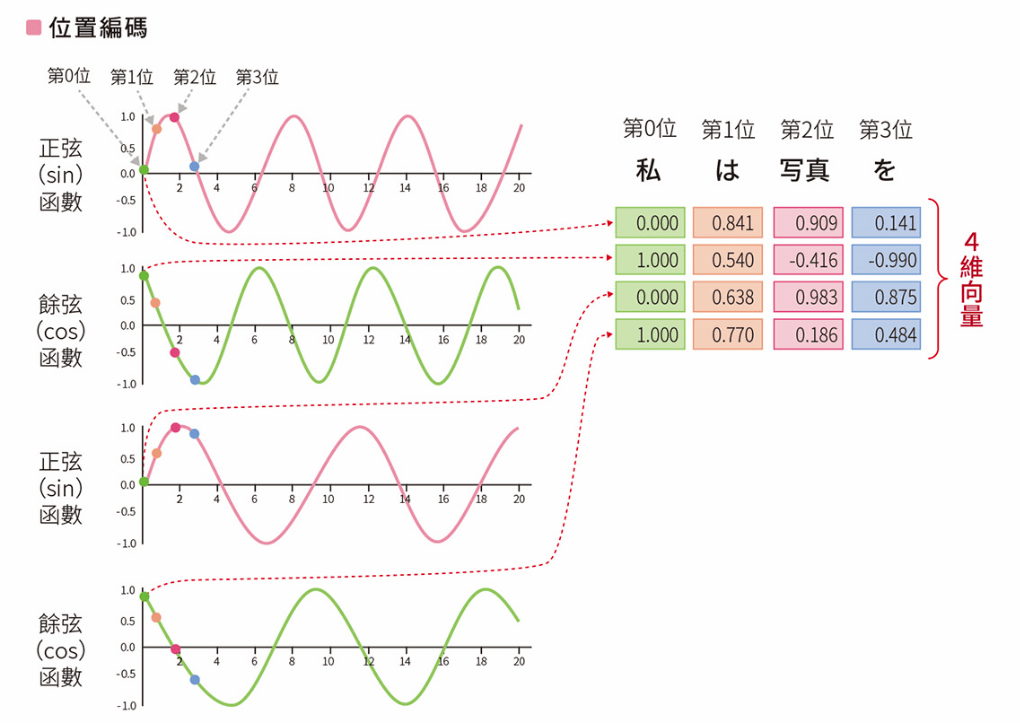
- Transformer 引進位置編碼的機制來處理各單詞的位置資訊
- 利用正弦餘弦函數將文章中的單詞順序向量化
Transformer 主要應用案例
BERT
Bidirectional Encoder Representations from Transformers
(2018, Google)
BERT 的應用案例
- Google:『2019 brazil traveler to usa need a visa』
(2019年巴西遊客到美國需要簽証)
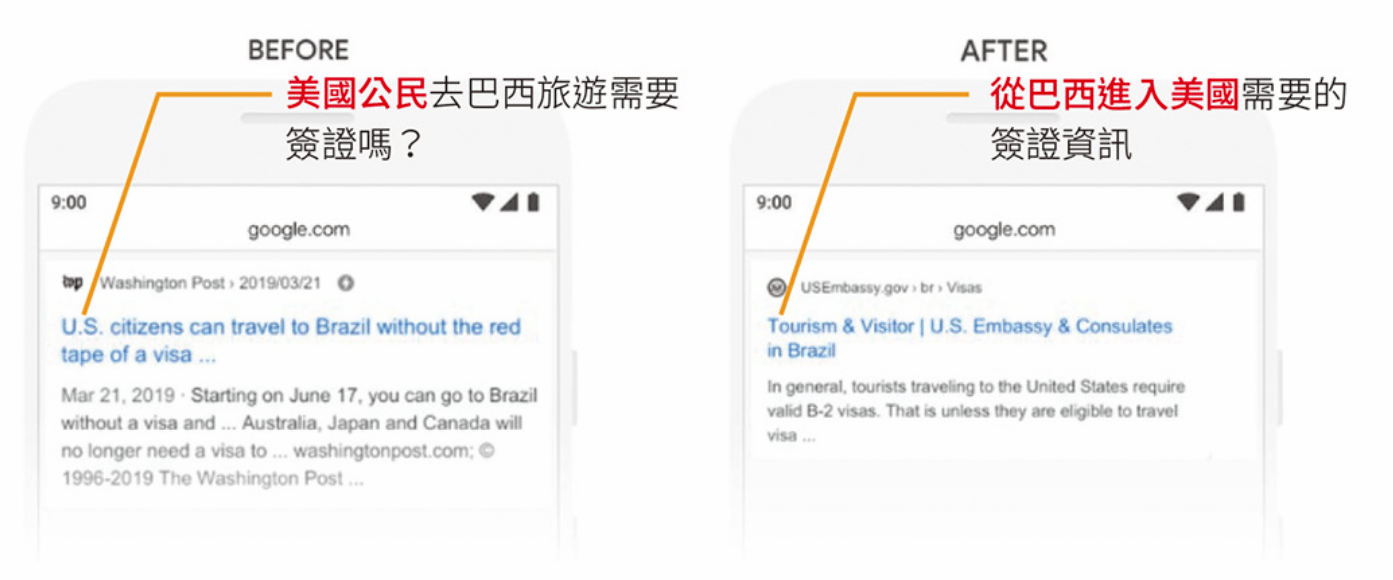
重點在『to』介系詞的重要性
利用預訓練和微調縮短學習時間
- Pre-training
- Fine-tuning
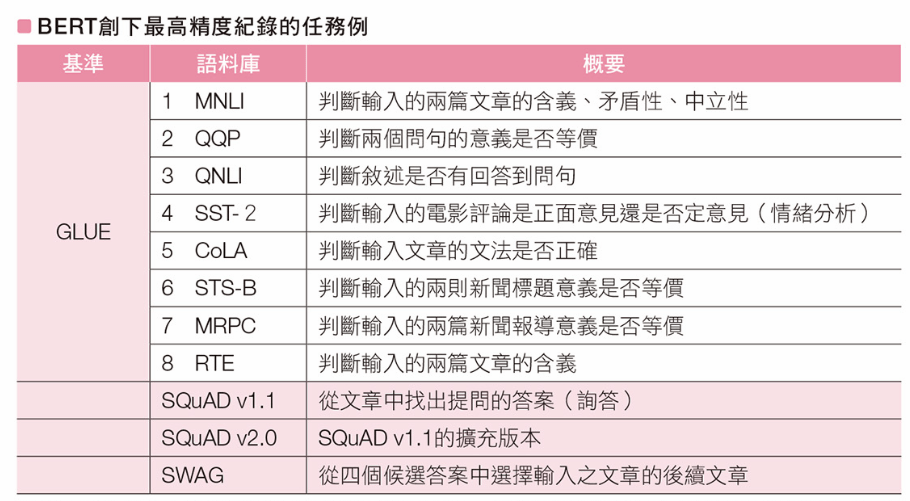
BERT 能表現出較高精度的任務
GLUE (The General Language Understanding Evaluation)
自然語言模型的綜合評價基準
評估語言模型在情緒分析、含義、等價性判斷各方面的性能表現
首次超越人類
的平均正確率
具備雙向性的 BERT
堆疊了 24 層的 Transformer
BERT
BERT 訓練:
- 使用 16GB (3300 萬個單詞) 來進行雙向預測的預訓練
- 解以下兩種問題:
- Masked Language Model (單詞填空)
- Next Sentence Prediction, NSP (下一句預測)
BERT

BERT 微調的概念
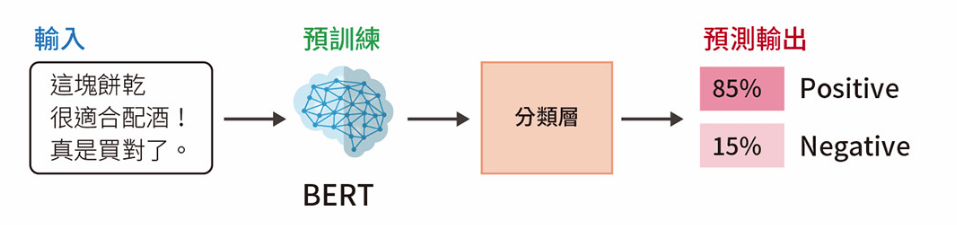
BERT 的應用領域

GPT-3
Generative Pre-Training
OpenAI's GPT-3 may be the biggest thing since bitcoin


易於處理特定任務的三種學習方法

易於處理特定任務的三種學習方法

GTP-3 龐大的參數數量
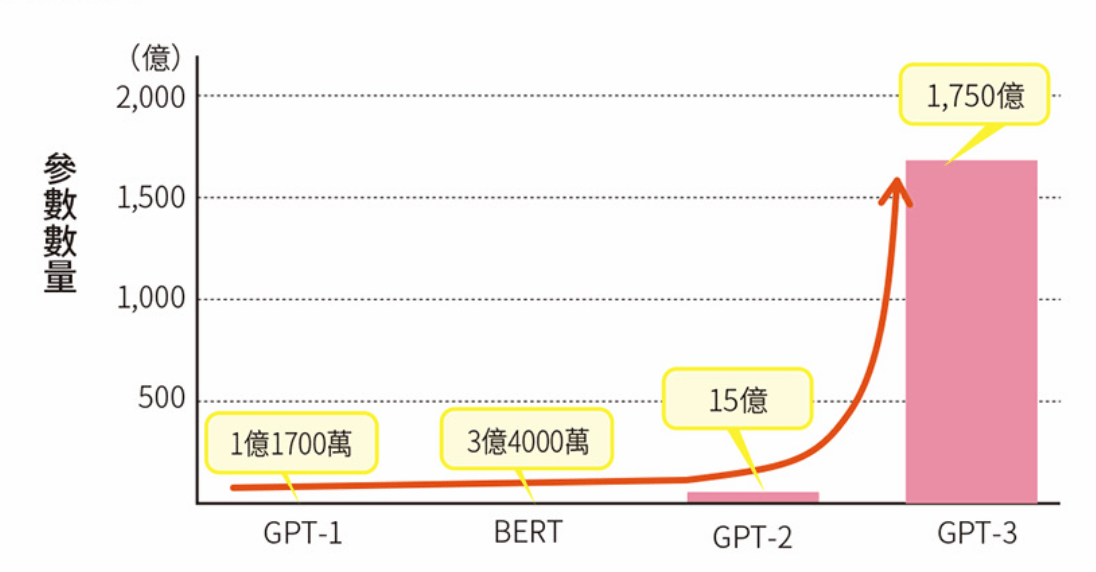
Transformer 層數
12
48
96
GTP-3 生成之文章的品質評價
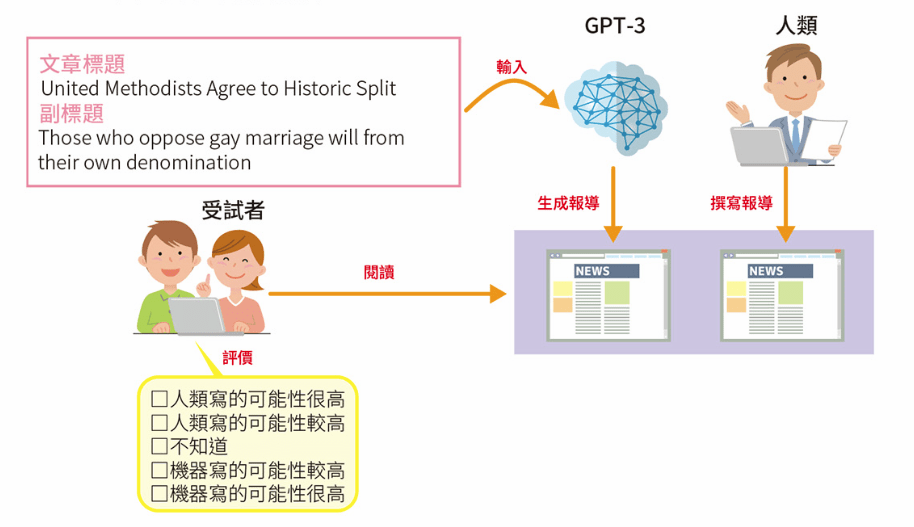
正確判斷出「這是 GPT-3 生成文章」的受試者:52%
改進文字和圖像輸入的趨勢
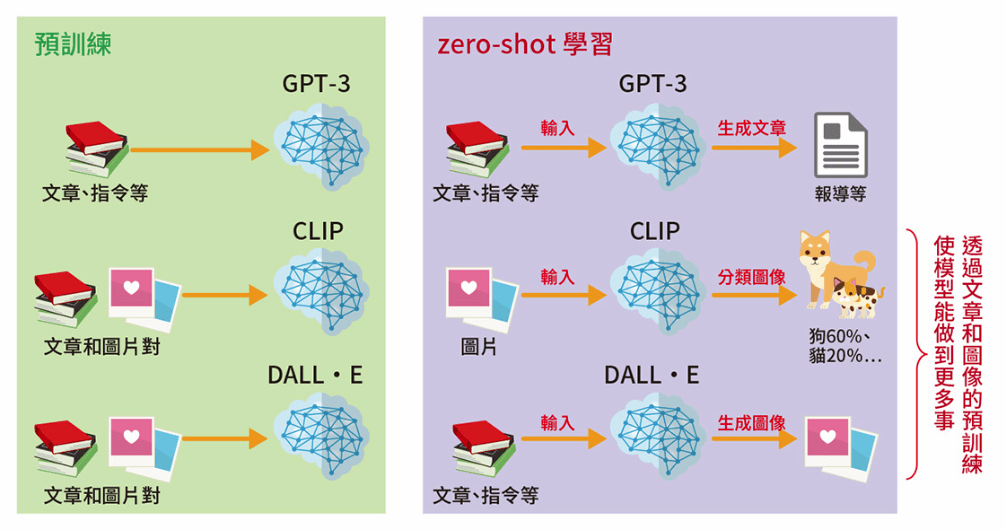
GPT-3 之延伸
- CLIP, Contrastive Language Image Pre-training
輸入圖片後用 zero-shot 對圖片進行分類
- DALL.E
輸文章後用 zero-shot 生成圖片
- 更多模型應用:
- DALL.E2 (四倍的寫實圖片)
- Stable Diffusion
- Midjourney
- Imagen
- ......
生成圖片

a painting of a fox sitting in a field at sunrise in the style of Claude Monet