循環神經網路模型
陳信嘉
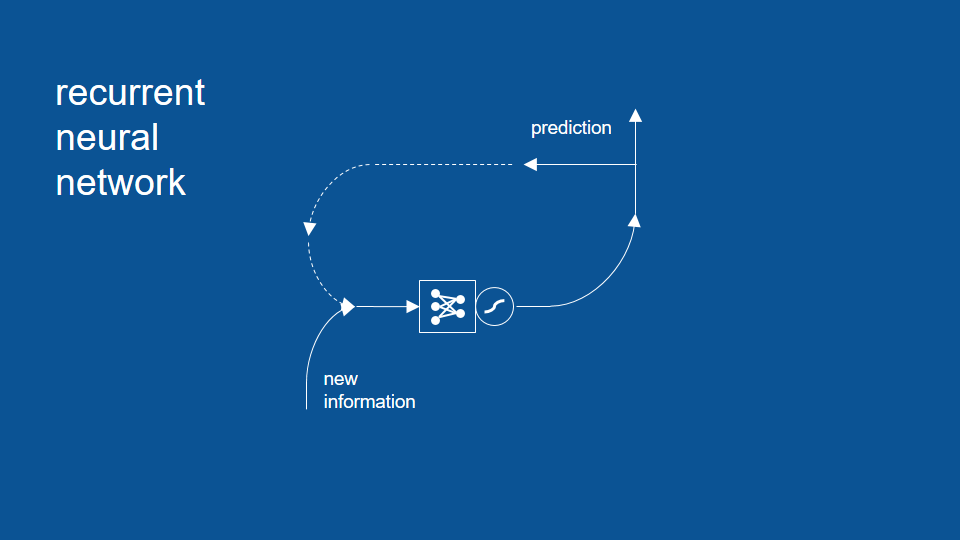
Recurrent Neural Networks
RNN & LSTM
sequence to sequence translation
- Recurrent Neural Network, RNN
遞歸神經網路 - Long Short-Term Memory, LSTM
長短期記憶模型
例如:將語音轉為文字或翻譯不同語言
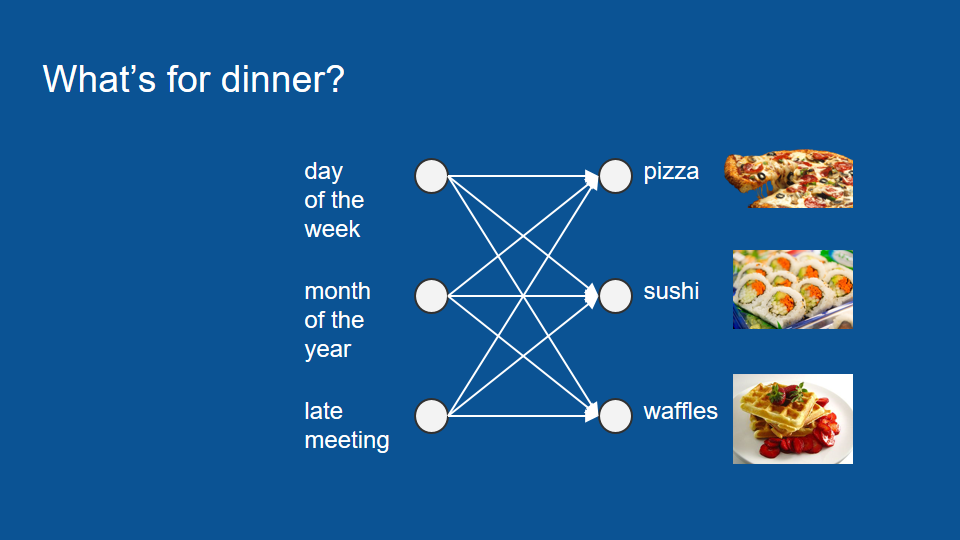
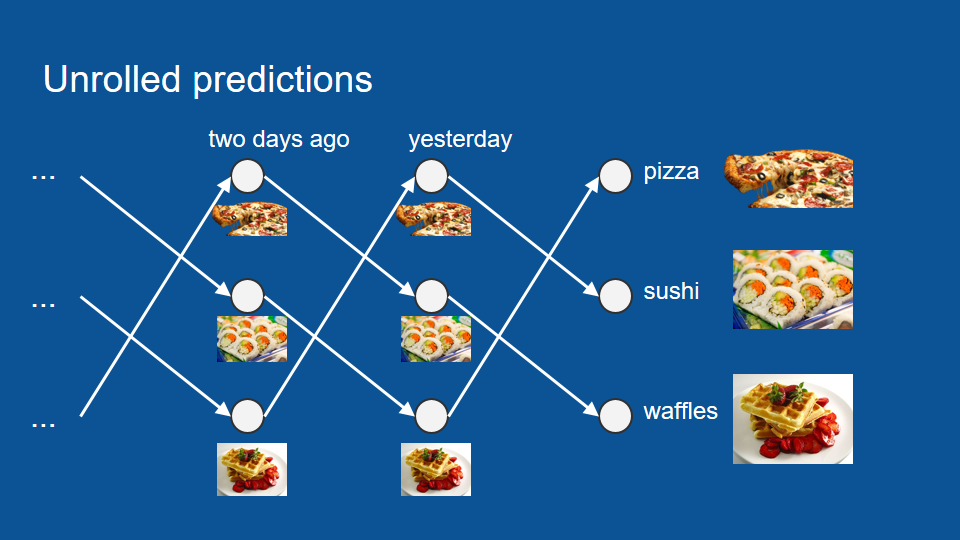
希望能預測某個晚上你會吃什麼
過去的經驗,昨天吃什麼,隔天一定是…
披薩 --> 壽司 --> 鬆餅
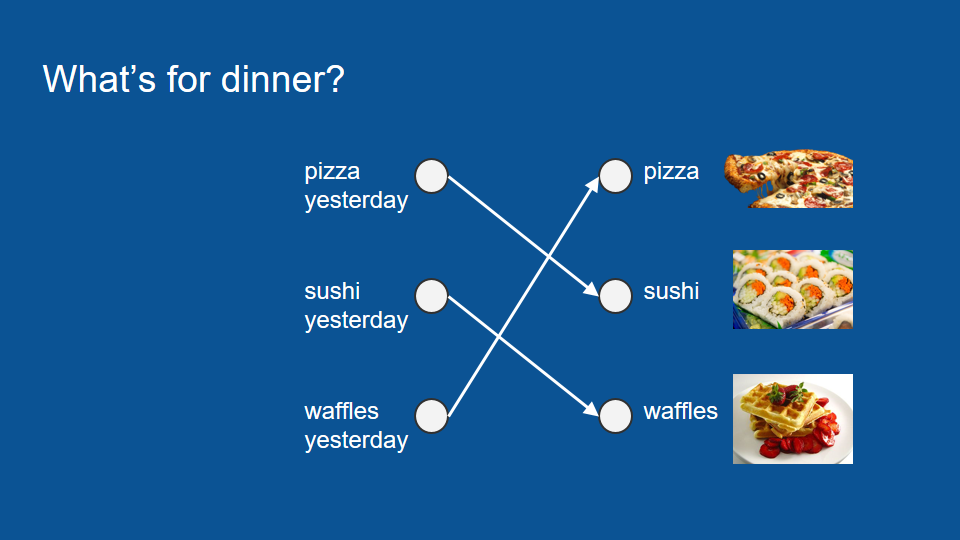
如果某一天不在家,只能從幾天前來預測
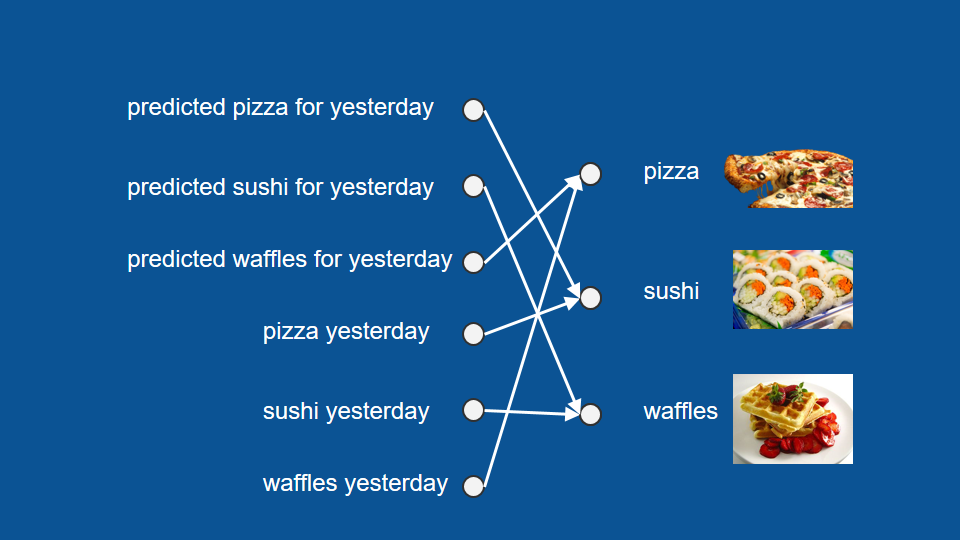
不只能利用昨晚實際吃什麼,也能利用昨晚的預測結果來推測。
One-hot encoding
如何表達資料?某天是星期幾

One-hot encoding
如何表達資料 - 吃什麼
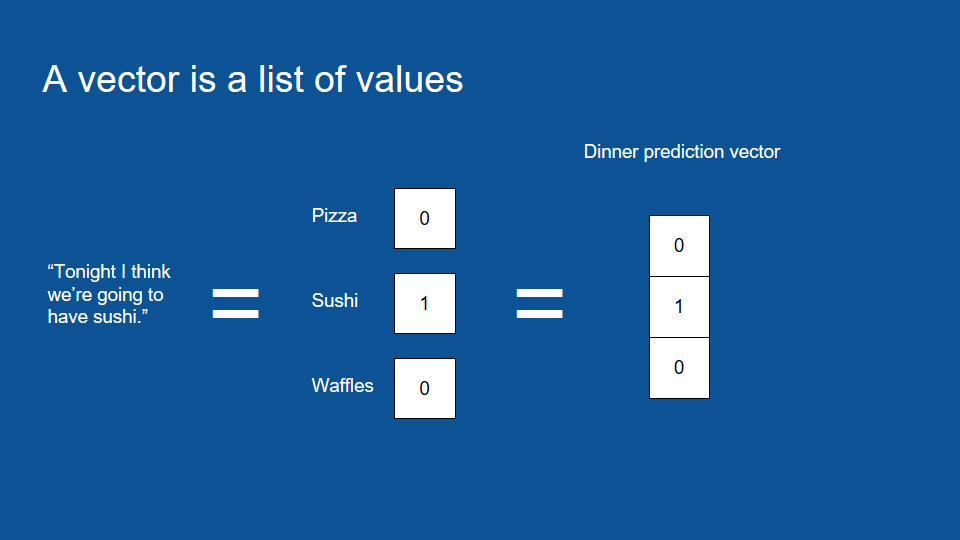
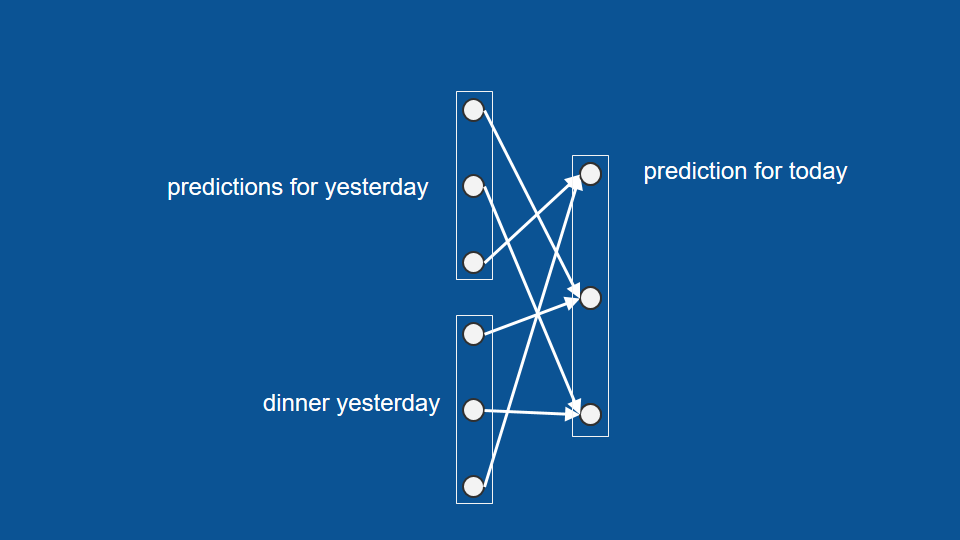
網路架構為每個輸入因素和輸出因素間的關聯 (connection)
三個向量:昨天的預測、昨天的結果、今天的預測
虛線,表示今天的預測結果如何在明天被重新利用,
成為明天的「昨日預測」
加上今日預測結果的回收循環
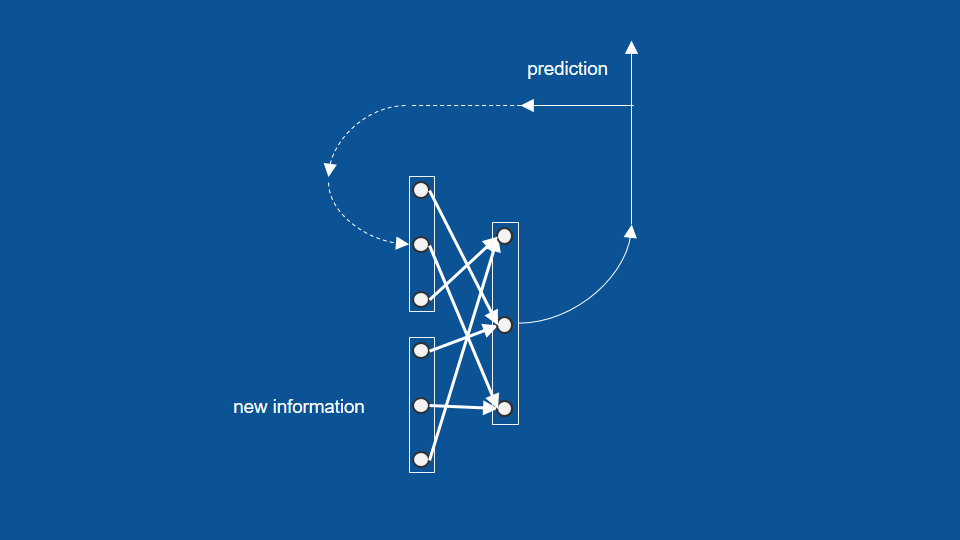
新資訊被忽略後 (昨天不在家),透過之前的資料延伸還是能預測
從最前端一直往過去的資料延伸
另一個例子
一個寫童書的例子

這本童書裡只有三種句子 (含句點)
字彙量很小,只有 Doug、Jane、Spot、saw 以及句號
神經網路的功用在於將這些單字按正確的順序排好,完成一本童書
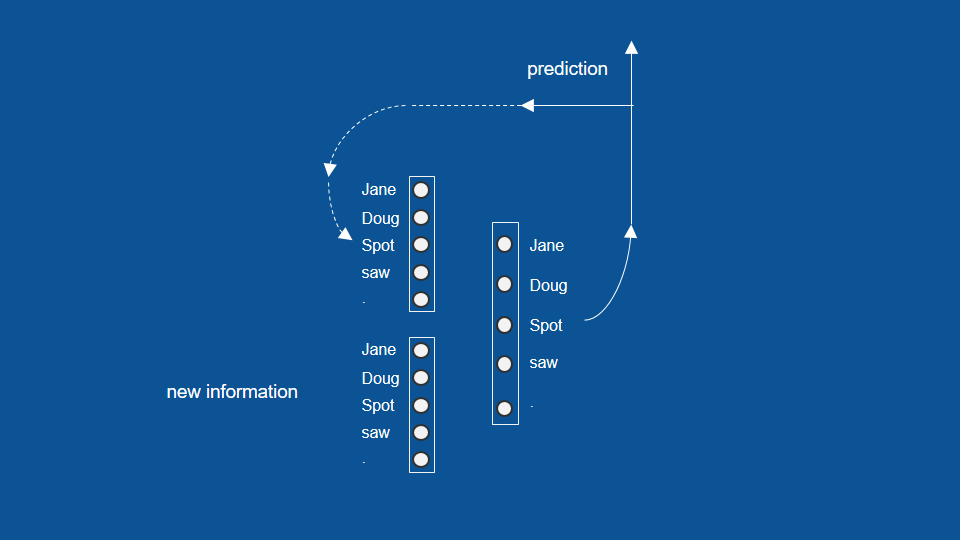
One-hot encoder
經過訓練後,可以看到名字之後可能出現的字
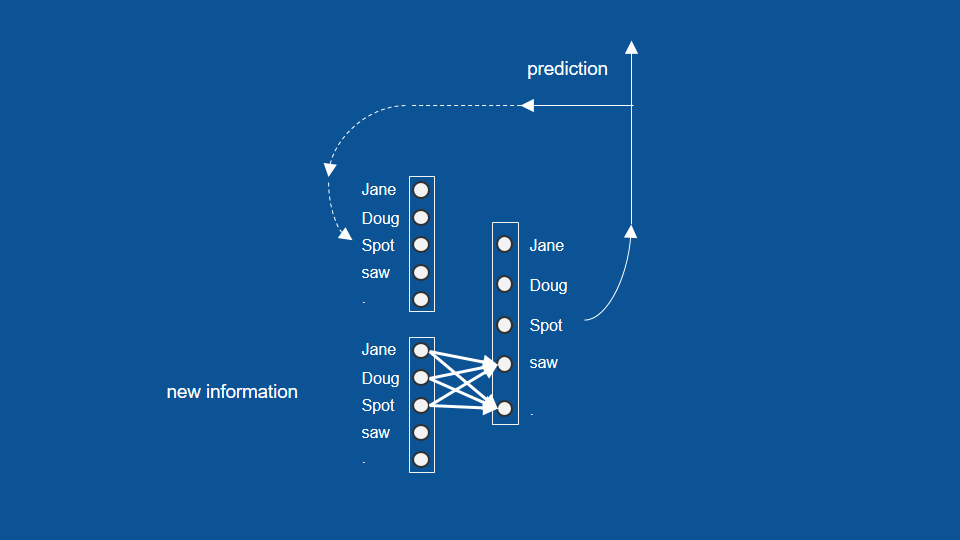
前一次預測了名字,就可以預測接下來的可能
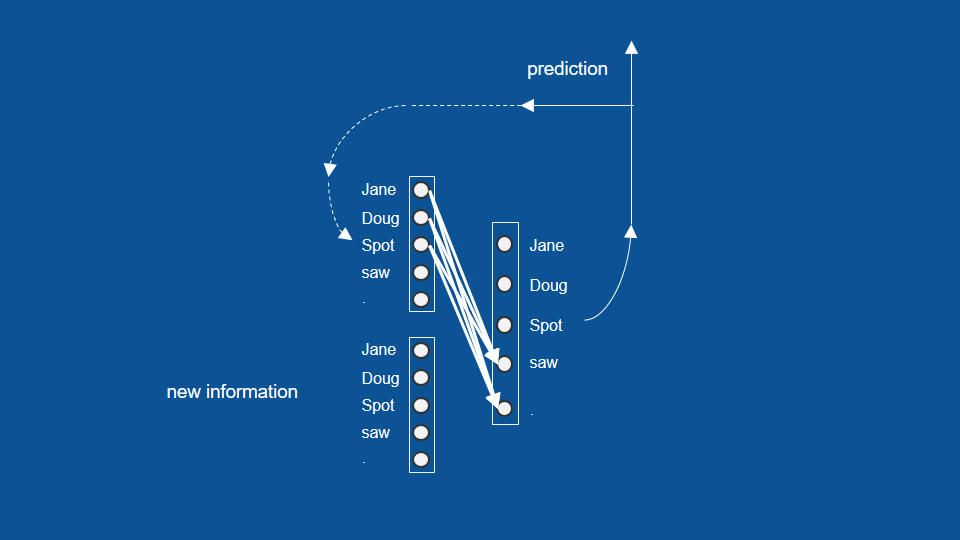
將這個流程和架構即可視為一個 RNN 模型
擠壓函數 (squashing function)
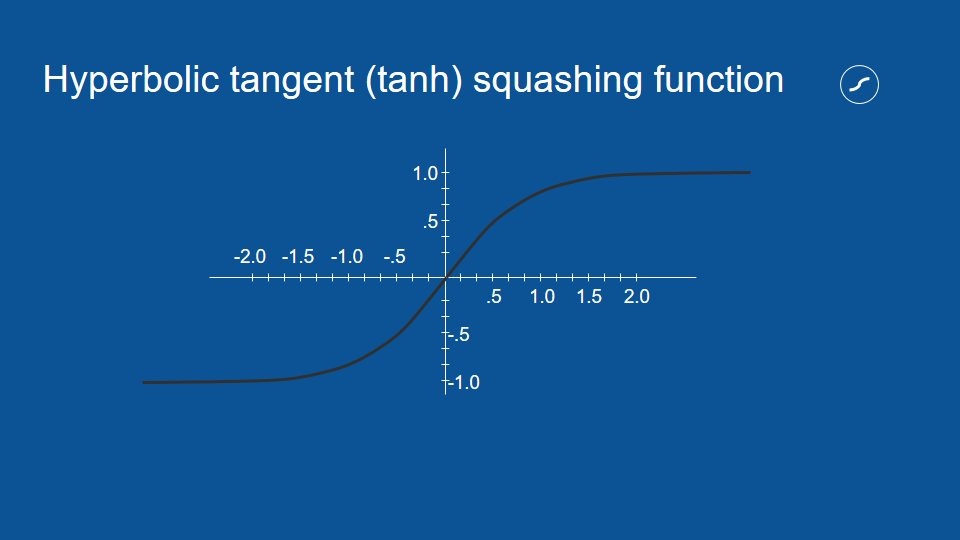
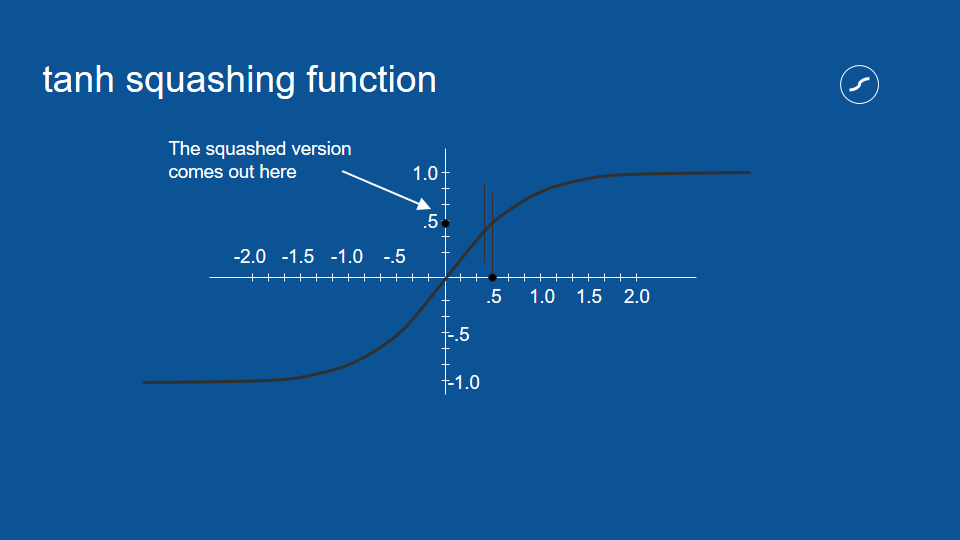
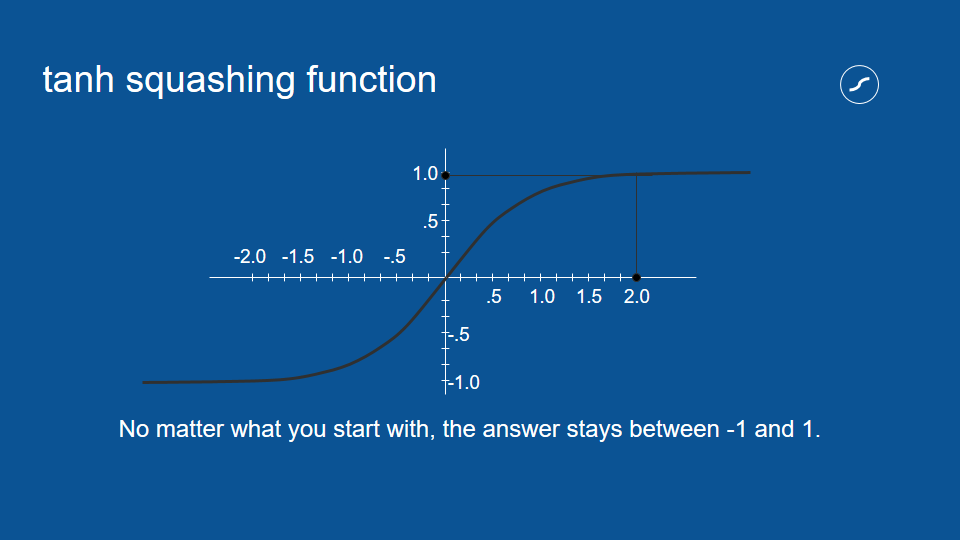
擠壓過後的數值都會介於 1 和 -1 之間
擠壓函數的處理,對於神經網路這種重複運算相同數值的流程非常有用。比方說,如果有個選項每次都得到兩次投票,它的數值也會被乘以二,隨著流程重複,這個數字很容易被放大成天文數字。
藉由確保數值介於 1 和 -1 之間,即使我們將數值相乘無數次,也不用擔心它會在循環中無限增大。這是一種負回饋 (negative feedback) 或衰減回饋 (attenuating feedback) 的例子。
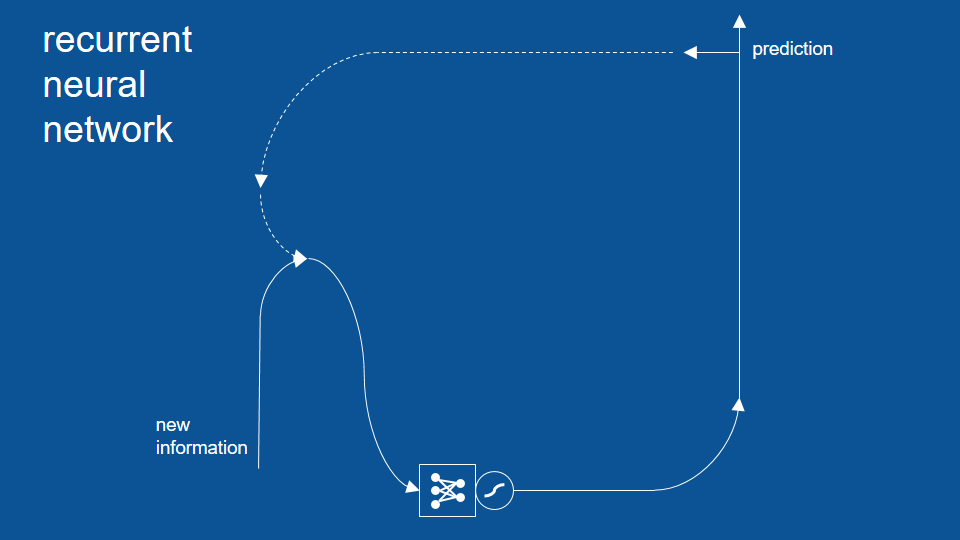
準備擴充的神經網路

這個例子裡的神經網路會出現一些錯誤
這是因為我們的模型有著很短期的記憶,只會參考前一步的結果,所以它不會參考更早之前的資訊
準備在模型中加入更多的內容
加入『記憶/遺忘』路徑
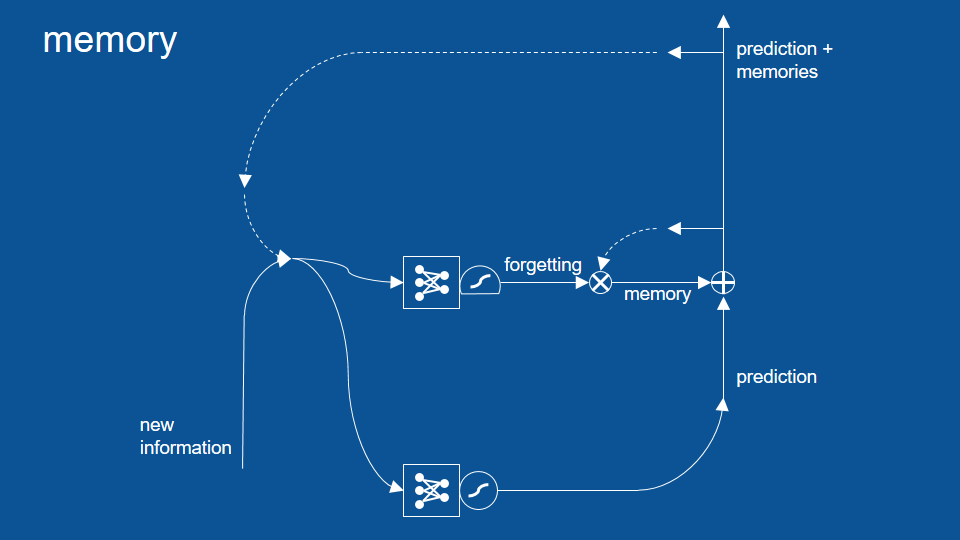
逐元素相加、相乘和閘門
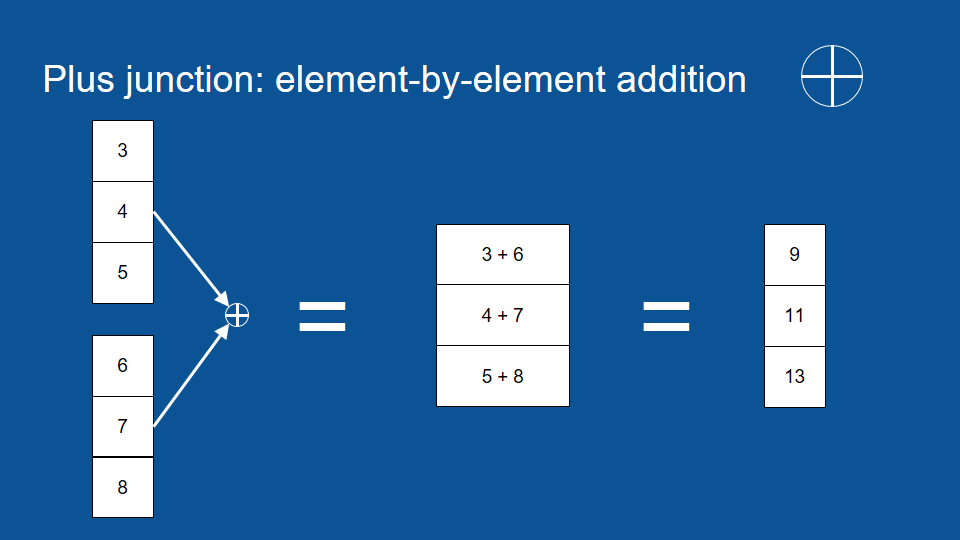
圈圈裡十字符號是 (矩陣) 逐元素加法 (element by element addition)。它的運作原理是將兩個相同長度的矩陣按同位置和順序的元素相加
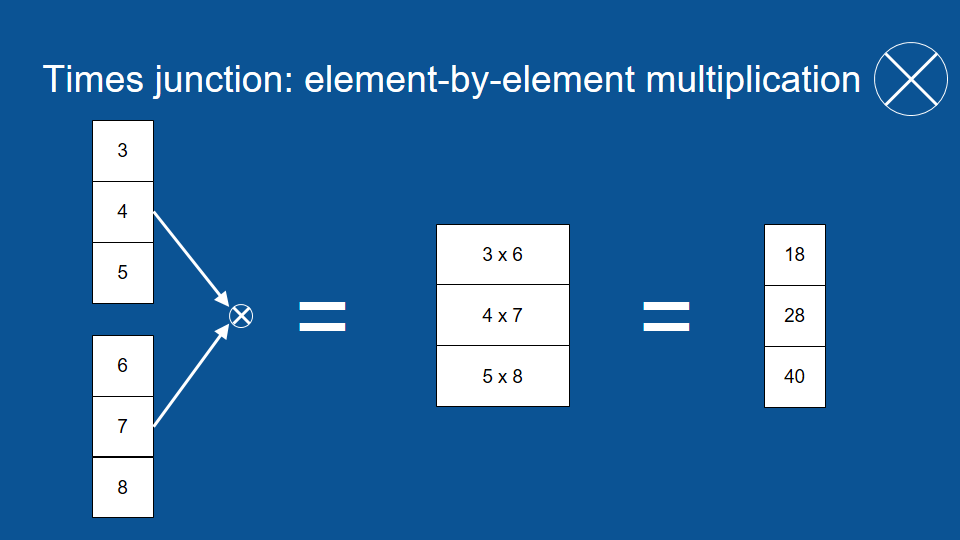
交叉符號是 (矩陣) 逐元素乘法 (element by element multiplication)
我們可以想像有一組訊號,以及一組可以控制水量的水管。
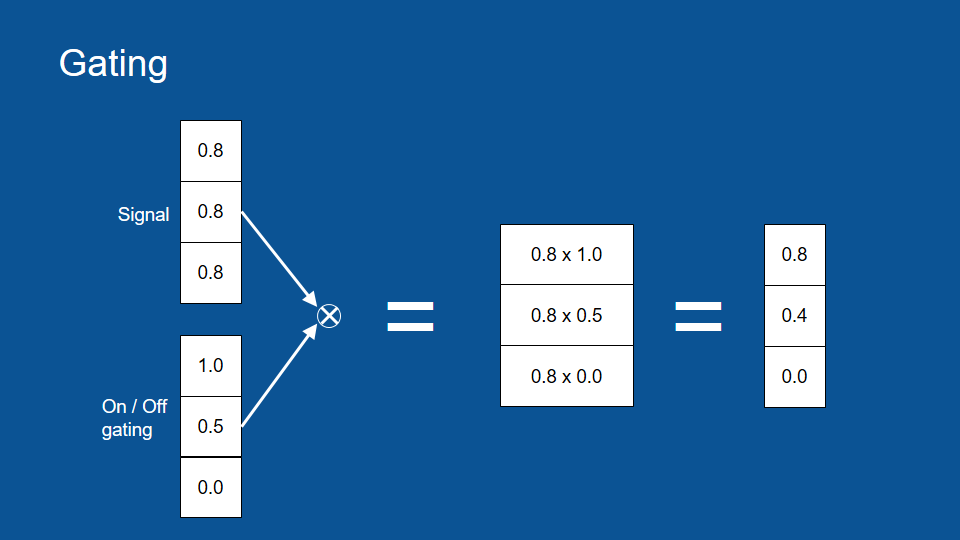
閘門 (gate) 可以讓我們控制訊號的流通與否
擠壓函數 (邏輯函數 logistic function)
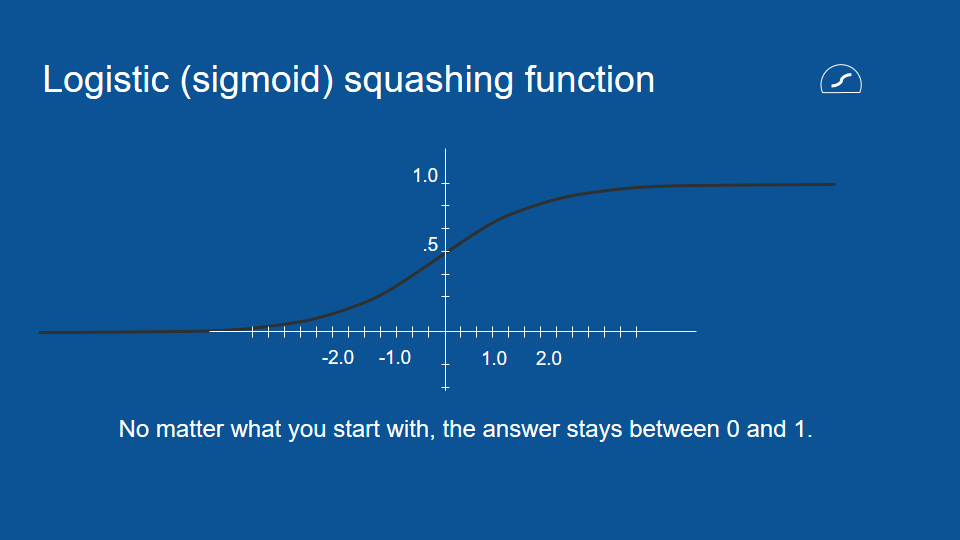
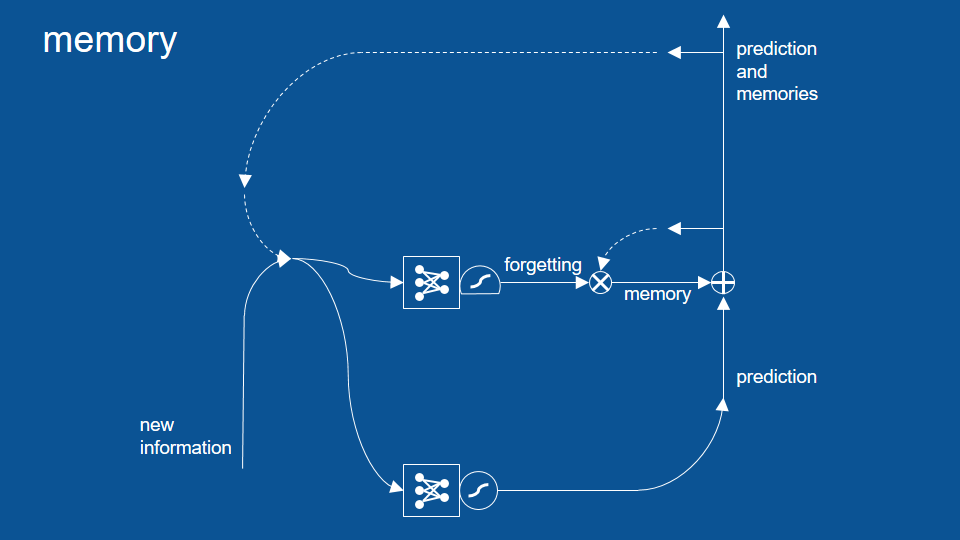
在新的模型裡,這些新預測會通過新路徑。在這條路徑裡,會透過邏輯函數,建立一個回憶或遺忘特定資訊的閘門 (即「圈叉」符號),並將結果加回下次的預測當中 (即圖中的「圈加」符號)
篩選路徑
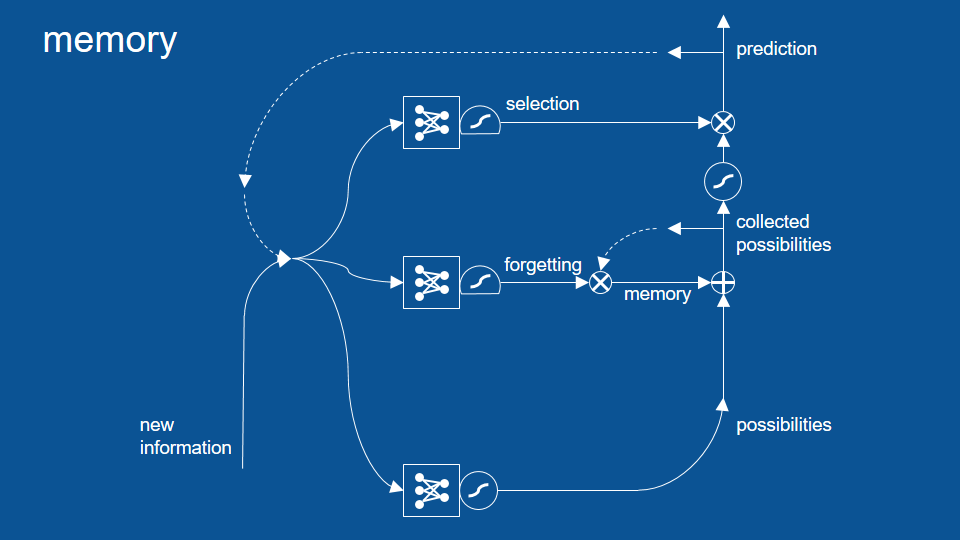
增加一個篩選 (selection) 路徑,將部分預測結果保留在模型中
這個篩選路徑也自成一個神經網路,有自己的投票機制。所以每次循環一開始的新資訊和舊預測,也會用於決定篩選路徑中的閘門大小。這組閘門會決定哪些結果該留在模型中,哪些結果該作為最終預測。
在篩選路徑前,我們可以看到另一個壓縮函數。因為在這之前我們做了一次逐元素相加 (即圖中的「圈加」符號),預測結果可能會比 1 大或比 -1 小,所以這邊的壓縮函數是用來確保數值大小尚在控制範圍中。
於是在上圖中我們可以看到,每當新預測,也就是一組預測結果(possibilities)產生時,我們會將它和過去的回憶結合,並將從中選出特定幾項作為該次循環的預測結果。在這個循環中,每條路徑中的機制都是透過神經網路學習,包括何時該遺忘或將回憶刪除。
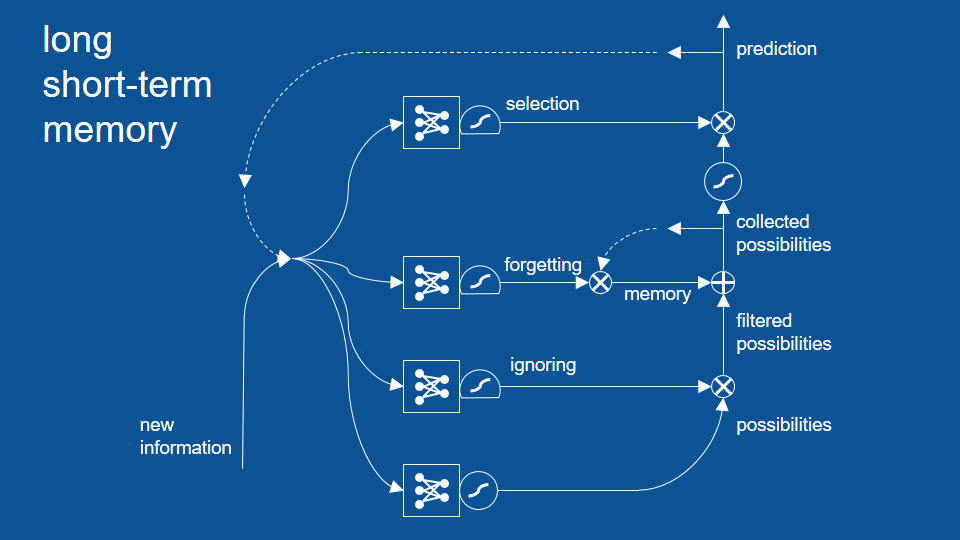
讓近期內不是很相關的結果先被忽視,避免它們影響之後的路徑。
忽視路徑
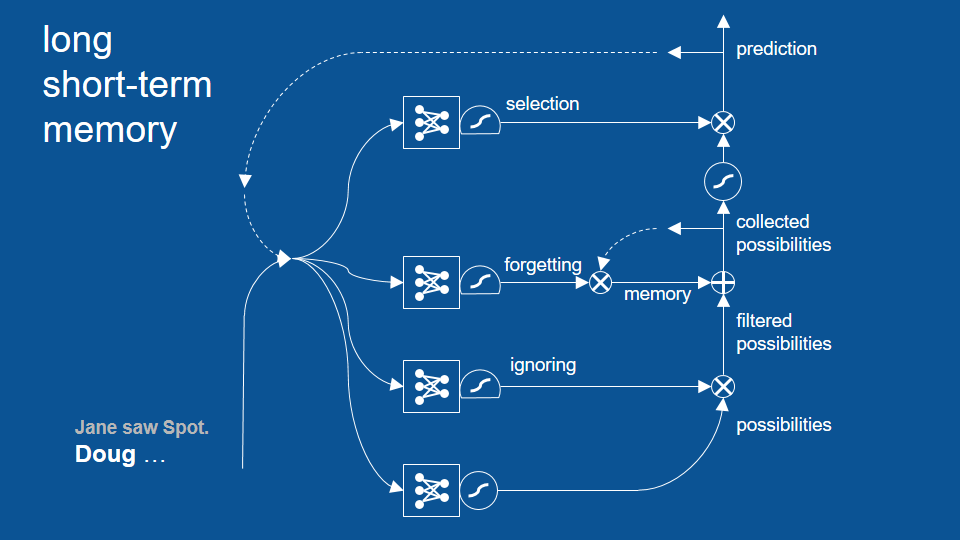
LSTM 模型
句子在 Jane saw Spot. 之後,從 Doug 開始…
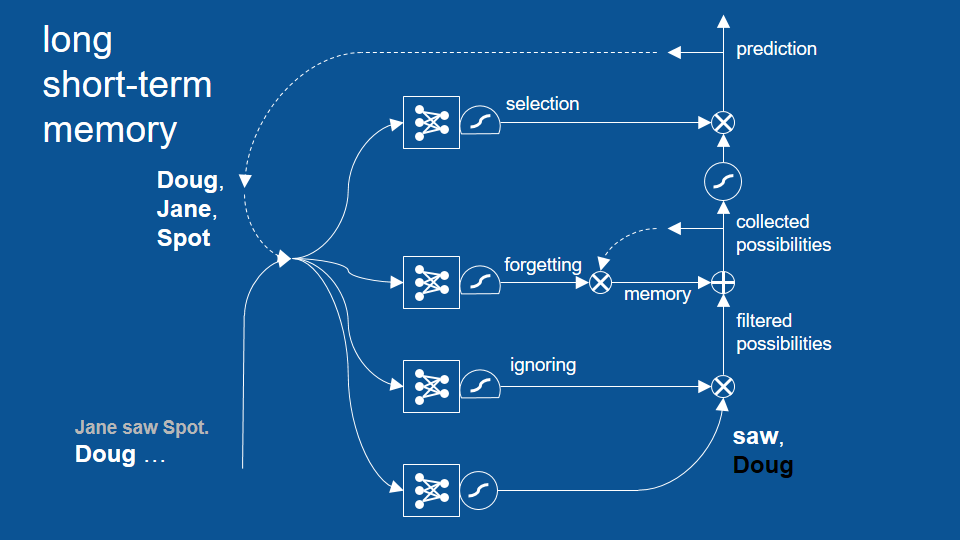
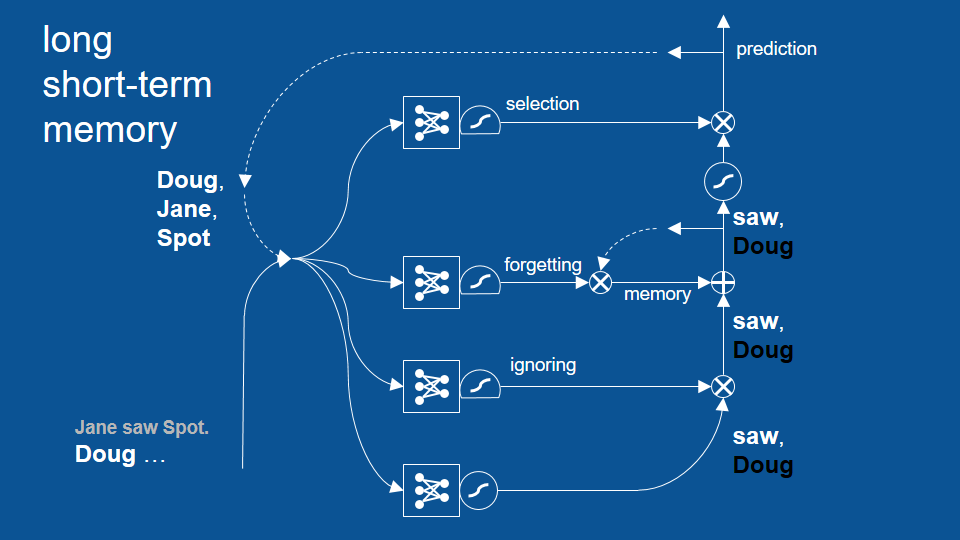
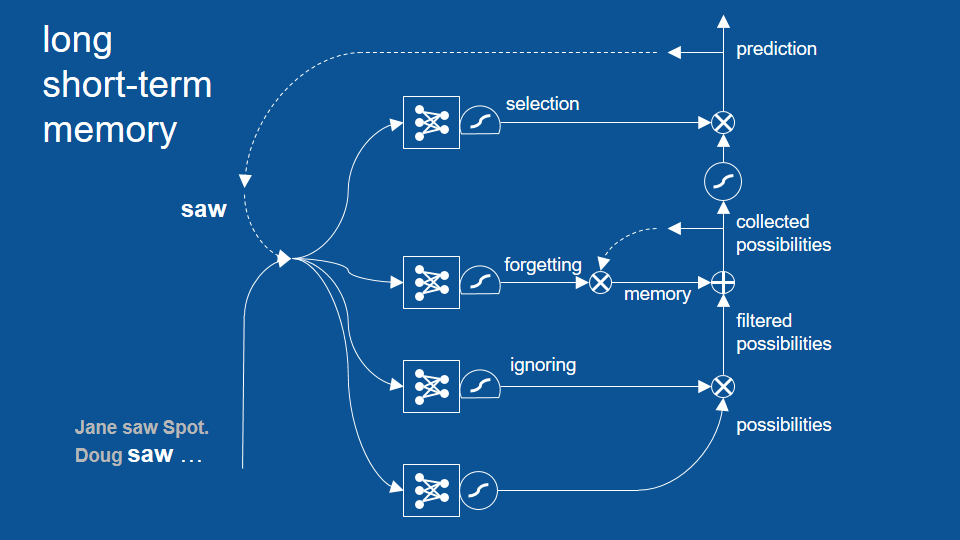
從 saw 開始新循環
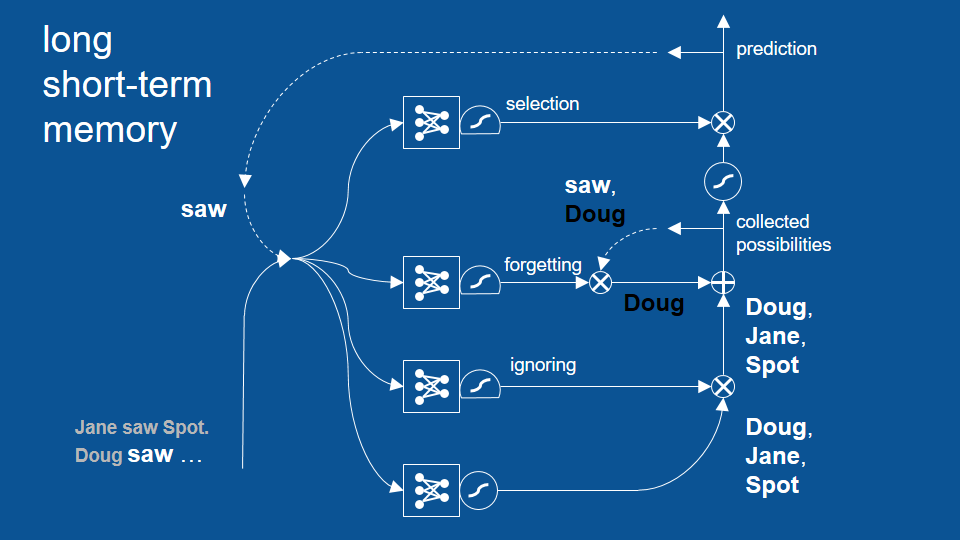
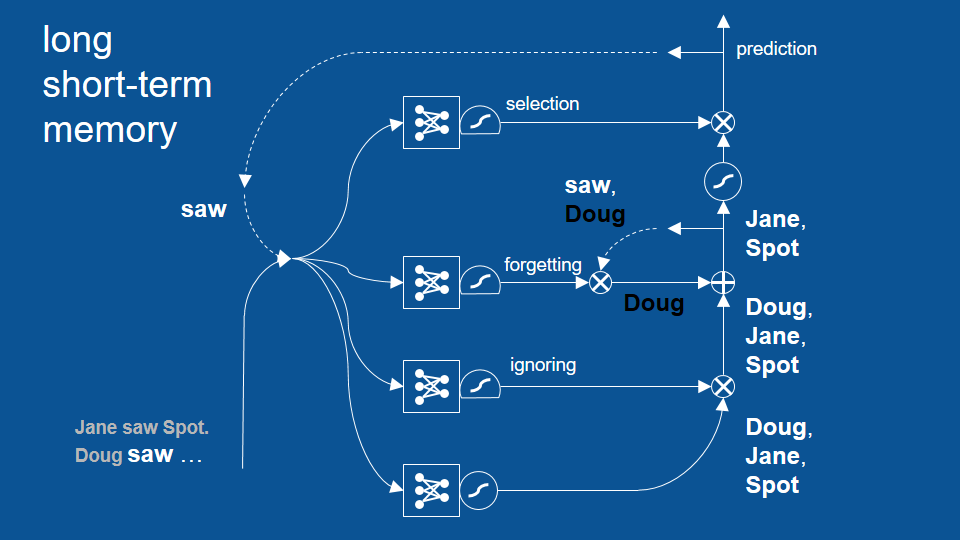
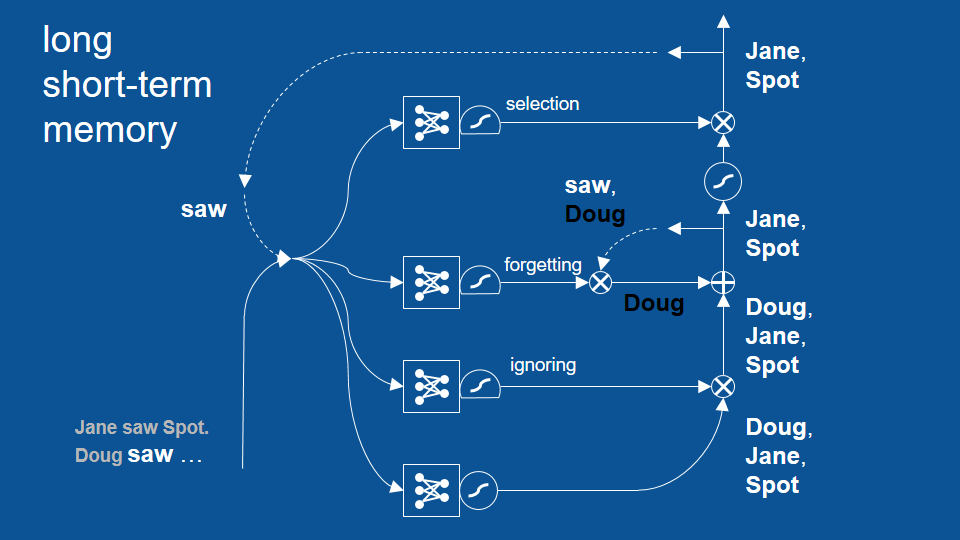
這個循環成功避免了先前「Doug saw Doug」的錯誤,並展示了 LSTM 模型如何藉著回顧兩個、三個甚至更多循環前的結果,以作出更合理的預測。不過話說回來,其實先前的基礎 RNN 也能回顧幾個循環前的結果,只是沒有 LSTM 這麼多。LSTM 可以成功回顧更多循環前的結果。
LSTM 的其他應用

LSTM 模型對許多特別實用的應用來說很有幫助。例如,如果我想將某段話從一個語言翻譯成另一個語言,LSTM 的表現相當良好。儘管翻譯並非逐字、而是逐詞組處理的過程, 有時甚至是逐句,LSTM 可以表現出某個語言中的文法架構。在以上說明的路徑和步驟中,LSTM 模型似乎能捕捉某些更高層次的規則,並根據這些規則翻譯不同語言。
另外 LSTM 也很擅長將語音轉換為文字。由於語音指示隨著時間變化的訊號,LSTM 可以利用這些訊號預測文字,並根據文字出現的次序更好地判斷接下來的文字。LSTM 也因此擅長於任何和時間有關的資訊,包括音訊、影片,以及我最喜歡的機器人學(robotics)。由於機器人學基本上只是探討代理個體(agent)根據一連串感測而得的資訊所作出的判斷和動作,這類資料本身就帶有序列性(sequential),即不同時間內所採取的動作,也和之後的感測與判斷有關。
