Deep Reinforcement Learning
Matt Lamm (S2 '18) & Sid Shanker (S1 '18)
What is reinforcement learning?
You have some agent in an environment.
The agent can take actions to change the "state" of the environment
At each step, the environment provides "feedback" to the agent, in the form of a reward.
State = s =
Action = a =
Reward = R(s,a) =

Q Functions
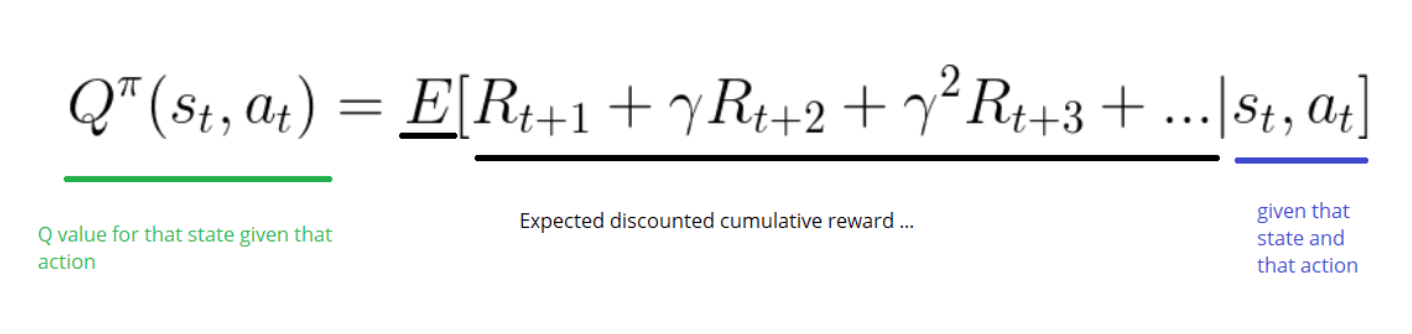
Representing Q Functions

For tic-tac-toe, a simple table will do.
Mario has way too many states to be represented in a table
Neural Networks

Cat: .7
Dog: .1
Human: .2
...
For games like Mario, you can use Neural Networks to approximate Q functions.
Jump: 100
Continue: 5
Deep Q Functions
How to learn about the world?
- Early on, you know very little about how the game works, and don't have a sense of what actions are good.
- Take mostly random steps!
- Then, as your sense of reward in the world improves, you draw actions from your own model.
Deep RL for congestion
- State: history of packet round-trip times on the connection
- Action: increase or decrease window (of packets to send out at a given point in time)
- Reward: Penalize slower round trip times but reward increases in the congestion window.
Some results
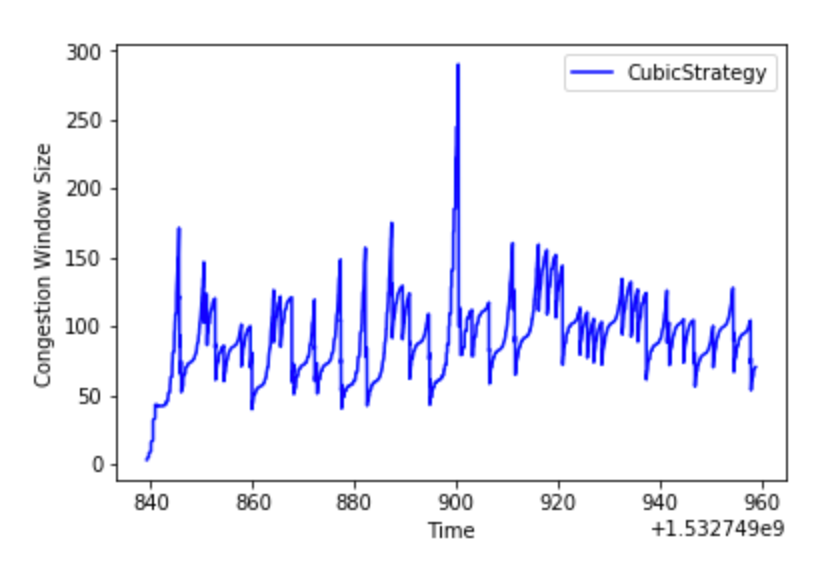
Traditional Approach
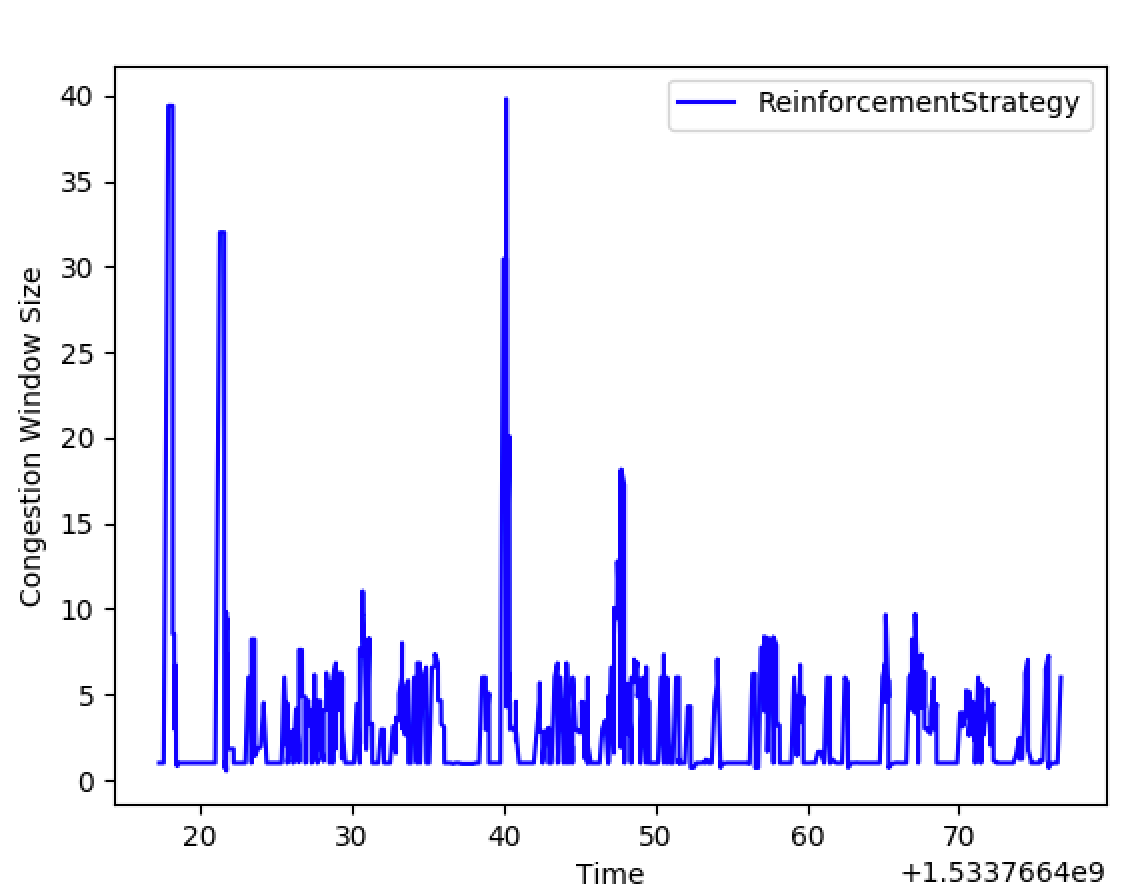
RL Episode 1
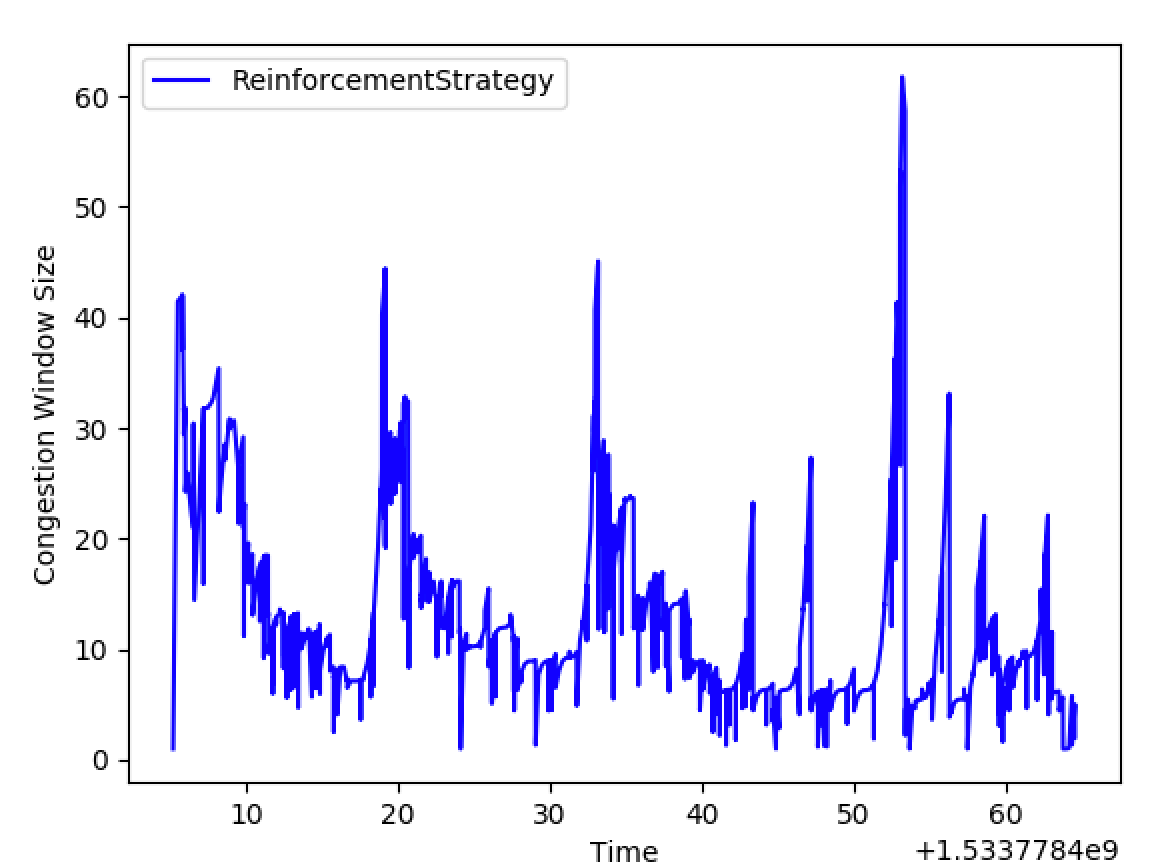
RL Episode 198