Reverse Engineering Cortical Architecture
Stephen M
"We employ a reverse-engineering approach to illuminate the neurocomputational building blocks that combine to support controlled semantic cognition"

Outline
- Basic Premise
- Architectures and inputs
- Results
- Discussion
- Thoughts
Premise:
"By systematically varying the structure within a computer simulation and assessing the functional consequences, once can establish the architectural elements critical to the targeted functions"
Conceptual system must do 2 tasks:
1) Abstract over episodes
2) Adapt representations to suit immediate demands
Conceptual system must do 2 tasks:
1) Abstract over episodes
2) Adapt representations to suit immediate demands
- In one view, concepts reflect clusters in the high-order covariance structure of experience
- Critically, this information must be extracted over episodes
- The features relevant to moving a piano conflict with the features relevant to playing it
Main Idea
- Take neural networks of different architectures
- Train networks to "complete the pattern"
- Two cases: without control (complete entire pattern), and with control (output specific modality)
- Test for ability to abstract
- Look at learning speed
- Lesion model
- Show other neuro-psych phenomenon

Abstraction:
Correlation between {Original DSM} and {Hidden Layer DSM}
Learning Speed:
# Epochs to learn
Architectures and Inputs
All architectures used a single framework, consisting of 12 pairs of input and output units per modality (connected on a one-to-one basis with a frozen weight of 6 and a fixed bias of −3 for the output units), 60 hidden units and 3,132 bidirectional connections with learnable weights.
24 units
60 units
Ultimate Winner
Concepts
- The architectures are trained on 16 concepts ...
- Method motivates design of concepts
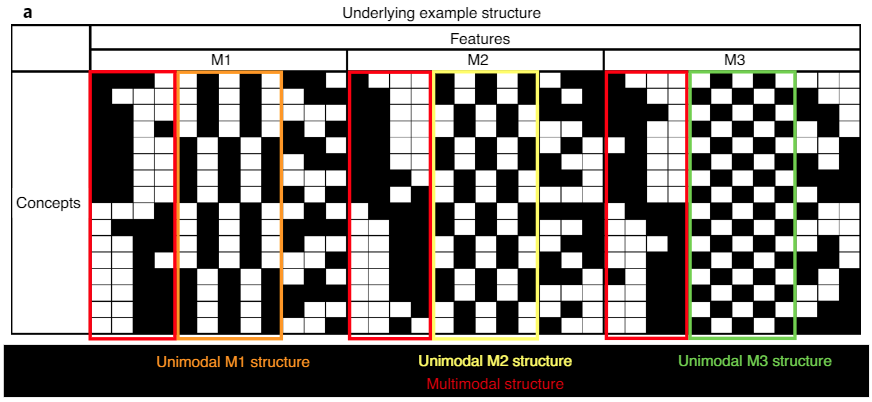
"The model environment included four orthogonal structures: one distinct unimodal structure (based on five perfectly correlated or anti-correlated features within a single modality) per modality (unimodal M1, unimodal M2 and unimodal M3) and a multimodal structure"
Hopfield Networks (Associative Memory)
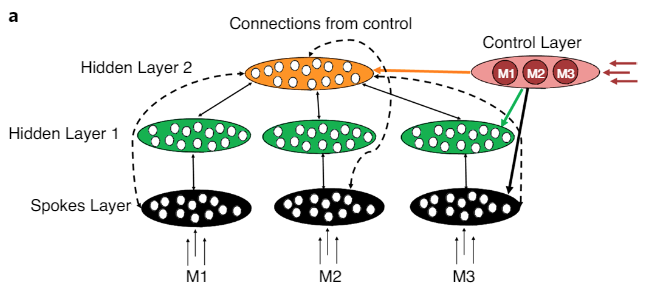
Adding Control
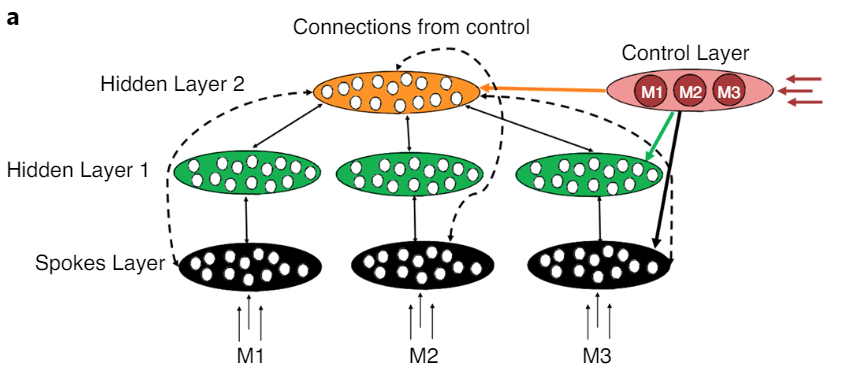
"This Control Layer sent trainable unidirectional connections to all units, providing a simple way of implementing control"
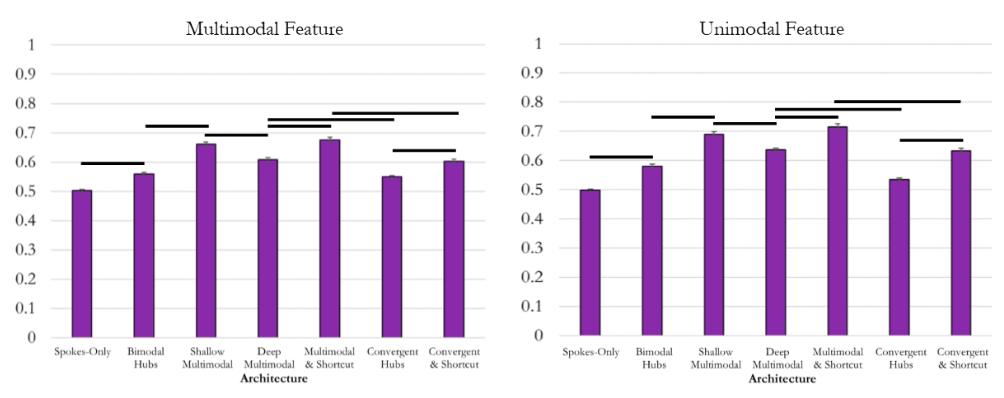
Results
Without Control
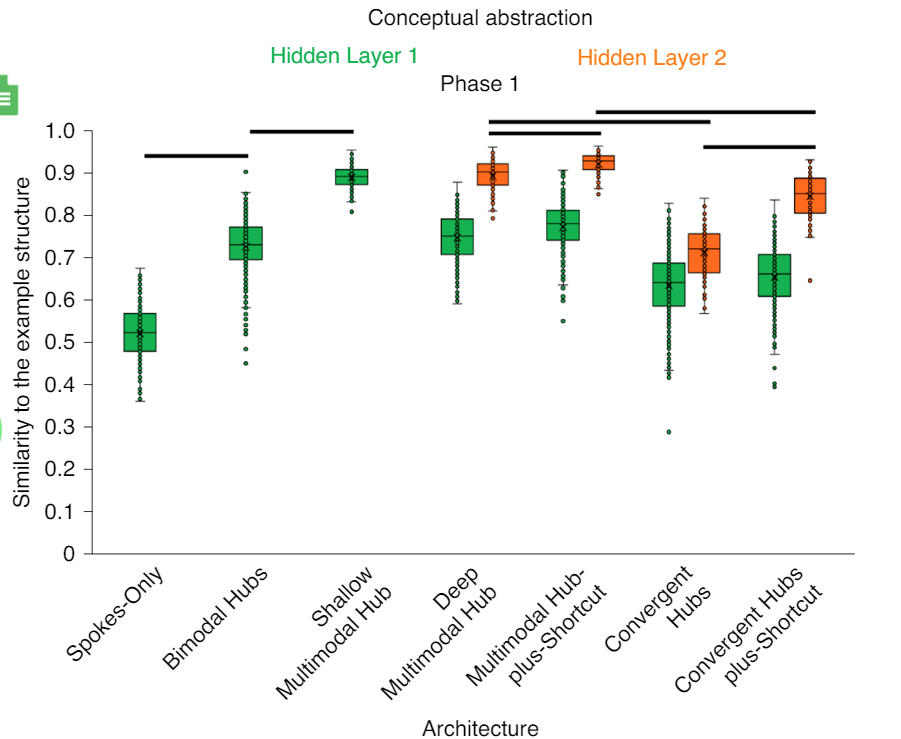
With Control
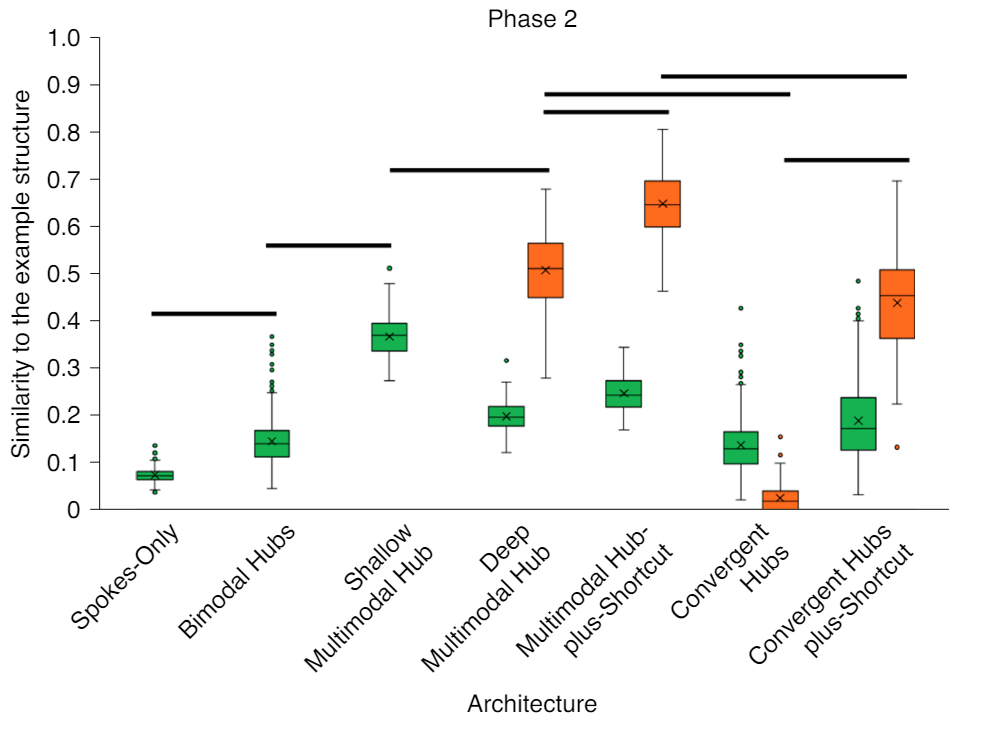
With Control
But ...
"This resulted in three Hidden Layer 1 regions in the Spokes-Only, Shallow Multimodal Hub, ..."

...
Of course deep hubs performed better!
*
*

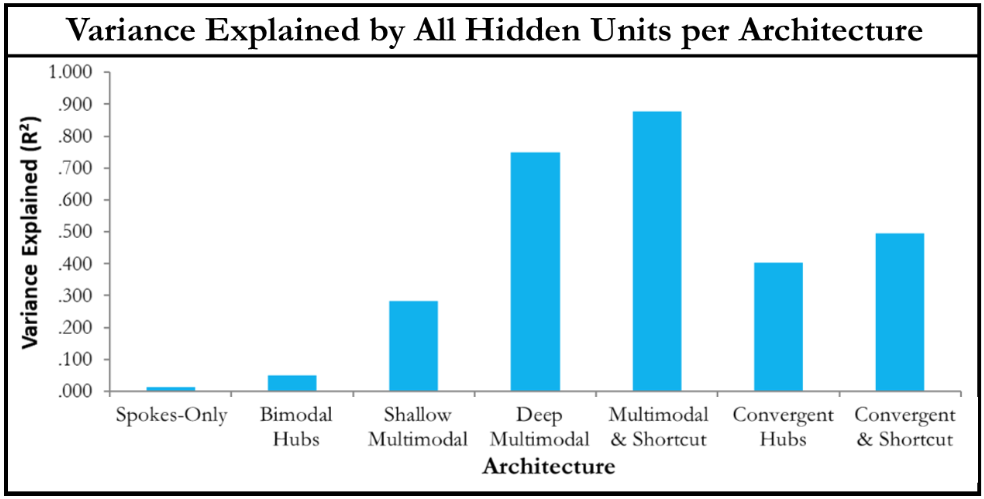
Learning Times
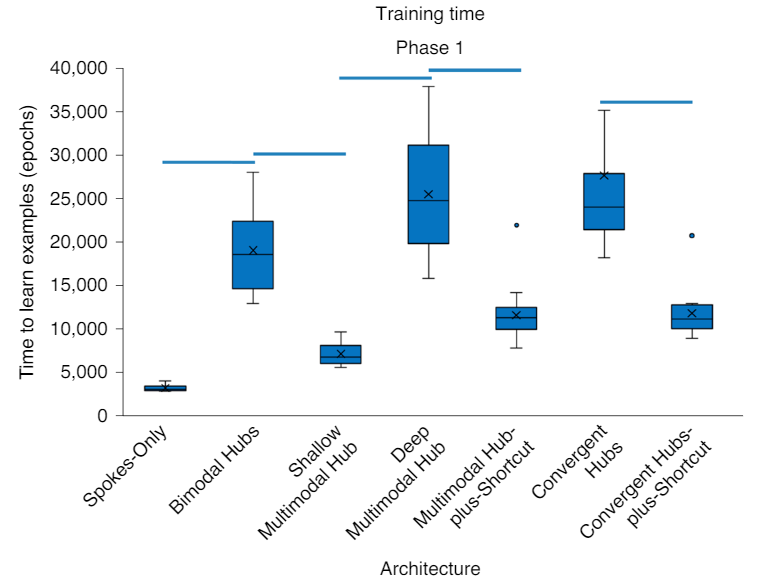
Without Control
Without Control
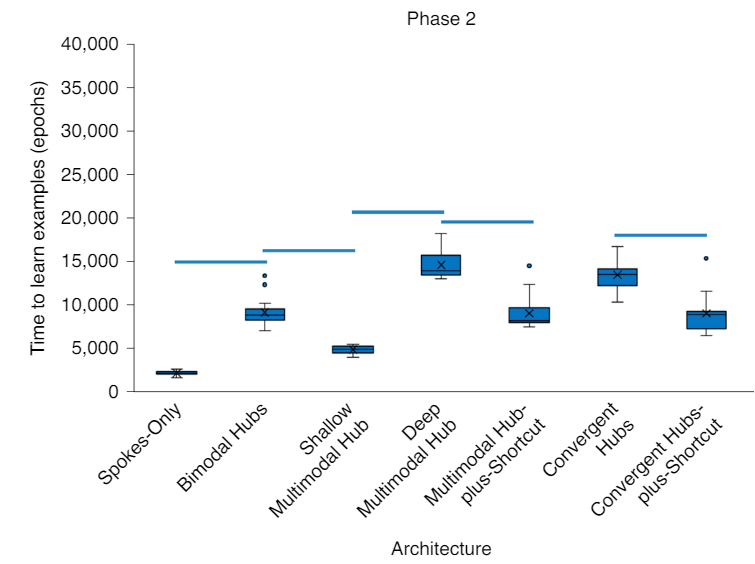
Location of Control
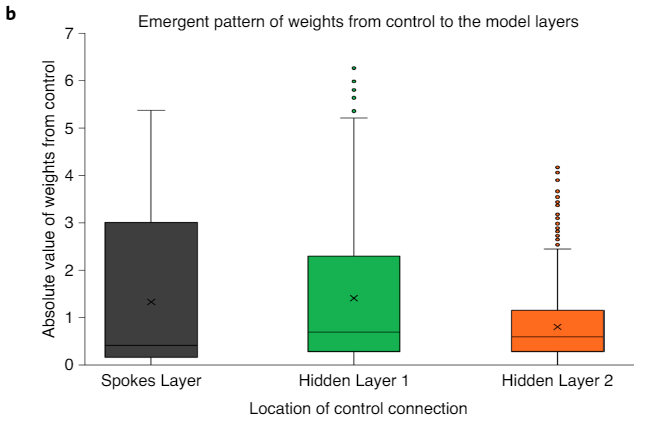
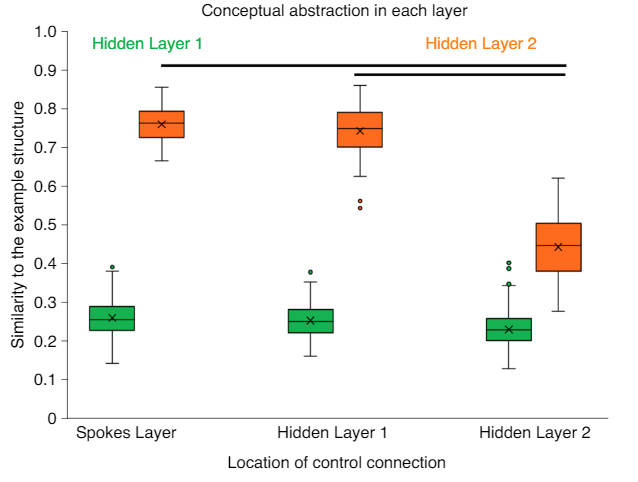
- Supports that control should be on spokes layer
Comment
- Maybe look at what the values are for control. If M3 "neuron" is "off", then we know there should be no output for M3 spoke so just have very high negative weights
Phase 3
Empirical Phenomena
Anatomy
- Unimodal perceptual representations progress to multimodal conceptual representations in a graded fashion
- Sparse long range short-cut connections
- Suggests systems for semantic control should connect with more posterior regions, distal to ATL
- control demands act on spoke representations
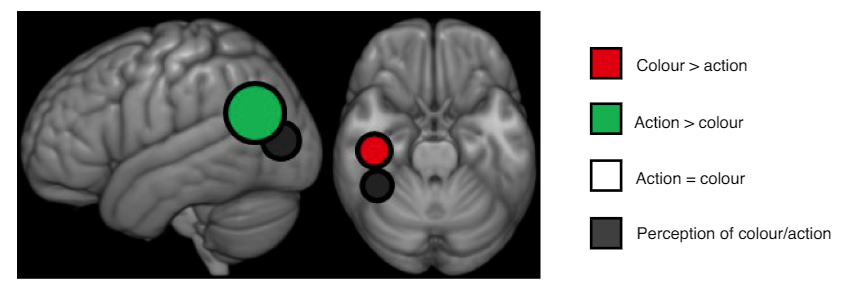
Martin, A., Haxby, J. V., Lalonde, F. M., Wiggs, C. L. & Ungerleider, L. G. Discrete cortical regions associated with knowledge of color and knowledge of action. Science 270, 102–105 (1995).
Functional Imaging
- Given input in M1, need to activate M2 or M3
- Corresponding hidden layer was activated more

Neuropsychological Syndromes
-
Semantic Aphasia
- Context inappropriate intrusions
-
Semantic Dementia
- Context appropriate, semantically incorrect
Acorn for squirrel
has stripes for zebra
horse for zebra
animal for squirrel

Both produce errors of omission, but differ in mistakes
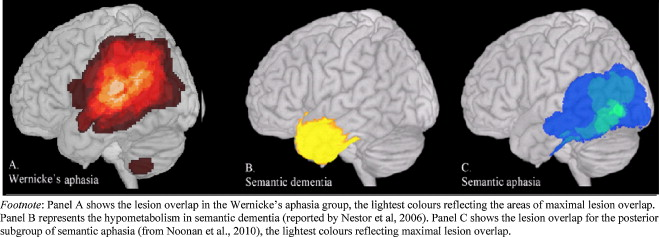
Robson, H., Sage, K. & Ralph, M. A. L. Wernicke’s aphasia reflects a combination of acoustic-phonological and semantic control deficits: A case-series comparison of Wernicke’s aphasia, semantic dementia and semantic aphasia. Neuropsychologia 50, 266–275 (2012).
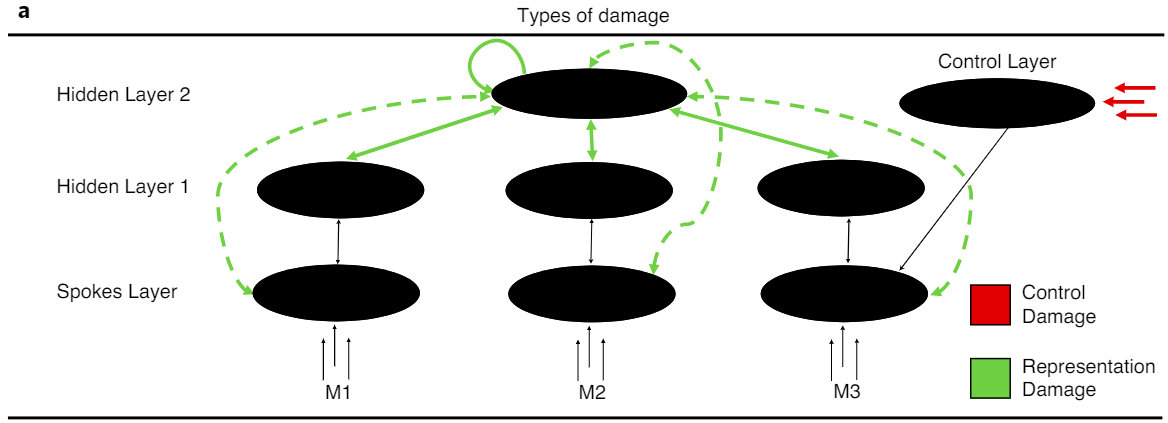
- SA -- Added noise to control units
- SD -- Removed proportion of connections within the multimodal hub
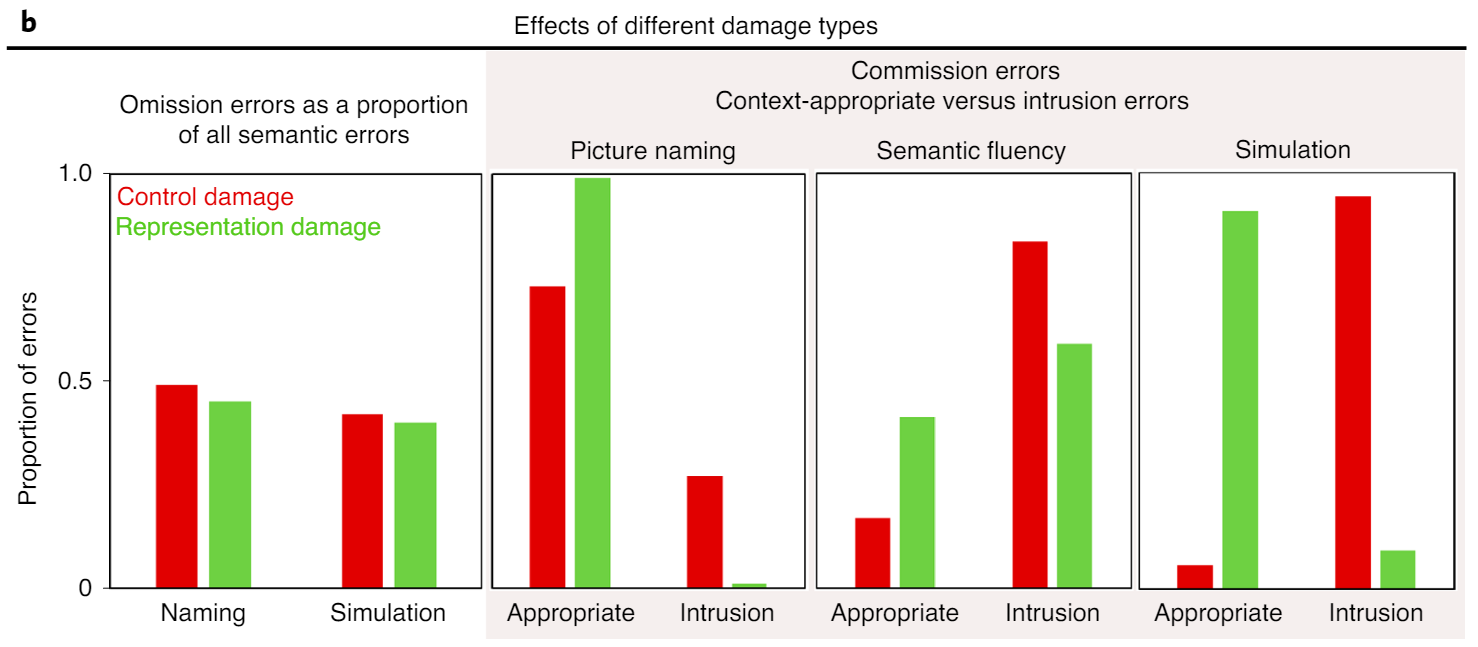
- Show you can lesion to get the right proportion of errors
-
Semantic Aphasia
- Context inappropriate intrusions
-
Semantic Dementia
- Context appropriate, semantically incorrect
Omission: inactivation of correct feature
Context appropriate: activation of incorrect task-relevant feature
Intrusion: activation of task-irrelevent feature
Functional Connectivity
"Recent evidence suggests that functional connectivity between the ATL hub and modality-specific regions changes depending on the information required for a task"
FFA
ATL
IPL
PCC
Judge:
Social Status
FFA
ATL
IPL
PCC
Judge:
Trait Processing
Reverse Engineered Model
- Stimuli presented in M1, but output was either M2 or M3
- M1 to hub connectivity was the same, but connectivity between two outupt spokes varied significantly
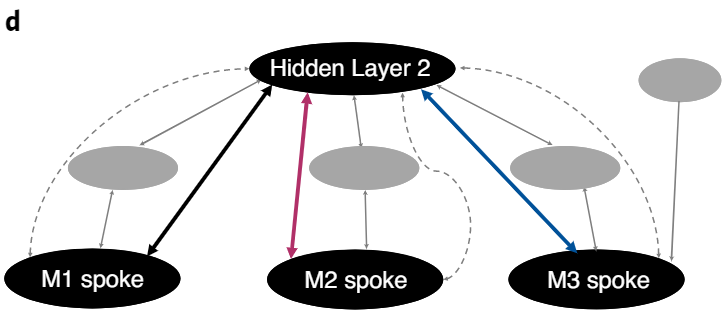
"activity at the final time point of each trial in context 1 (M1 ‘face’ input and M2 output, or ‘status’) and context 2 (M1 ‘face’ input and M3 output, or ‘trait’) was concatenated in a different random order per model run to create a time series for each voxel, per context. Each run of the model is treated as a different participant. To collapse across units within a region, a principal component analysis was performed per region for each context in each run, analogous to extracting a region-of-interest (ROI) time course for a psychophysiological interaction analysis as in Wang et al.15. The correlation between the time course in Hidden Layer 2 and each spoke region was calculated"
Discussion
Main Points
The optimal network had 4 characteristics
- Multimodal hub
- Deep architecture
- Sparse shortcut connections
- Control operating on shallow rather than deep components
This model accounted for:
- "coarse anatomy of temporal cortex"
- qualitative differences in error patterns of SD verses SA
- differential functional connectivity
Brief Summary
Why multimodal hub?
- helps to acquire internal representation across modalities and episodes
- If direct pathways exist, little pressure to use connections across all modalities
Why depth?
- Note, only made difference with control
- hub can be sufficiently insulated from contextual information to acquire context invariant representations
Why shortcut connections?
- vanishing gradients
Why separate representation and control systems?
- "evolution’s way of promoting the acquisition of deep conceptual representations while preserving the flexibility required to think and act as the situation demands"
Thoughts
Thoughts
- I think that the training time is pretty meaningless, and the abstraction ability is predicated on how abstraction is defined
- Good overall idea
Nitpicky:
- Code is a bit rough
- Weird supplemental ...
Future Directions
- Instead of abstraction, test generalization (or usage in new contexts)
- Use RSA to look for representations in each layer in the brain
- Use Hebbian update rule