Making Sense of Text Data with Deep NLP
Presentation Link: http://bit.ly/deep_nlp_pydata
Code Link: https://github.com/smfullman/deep_nlp_pydata
Note for posterity: This presentation was given in 2018; much of it is still conceptually sound but there have been many advancements in NLP/deep learning since then (and the code examples have not been maintained). If you are interested in learning more, check out the most recent versions of the courses mentioned in the last slide
Scott
- Main gig: Tribune doing data science
- Also: Work with startups focused on using machine learning (shameless plug: all of them are hiring)
- Previously: PwC Analytics/ML Lab
- Edu: Chicago Booth (MBA, Concentration: Statistics); University of Illinois Urbana-Champaign (Systems Engineering)
Goals
-
Answer the question: "Why use deep NLP?"
-
Introduce a framework for building deep NLP models, and demonstrate the power of incorporating external data into your task
-
Give enough knowledge to get started, provide enough resources to fill in the gaps
-
Note: There are a few major concepts flippantly introduced in this talk, denoted by a hand-wave: 👋. Go ⬇️ in the slides for more information, references, links to resources, and code examples
What is deep NLP?
- Collection of learning techniques which attempt to correctly represent data using neural networks in order to accomplish common natural language processing tasks in a generalized manner
- "So deep learning models for NLP?" Yes, but emphasis on the correct representation and generalization parts
Resources
Why use deep NLP?
-
Performance: Possibility of better performance than traditional ML techniques on NLP problems
-
Representation: “Automatic” feature engineering: less reliance on human-designed systems/features
-
Transfer Learning: Learn data feature encoding/model from external sources in a semi-supervised fashion; reuse on problems or similar data distributions
-
Multi-input/multi-output: Models which handle many tasks have shown gains over single task versions
-
Multi-modal data transfer: Deep learning can handle data of different types (e.g., caption an image, transcribe audio)
Resources
Why use deep NLP?
-
A smattering of what's possible:
-
Classification: group text into categories
-
Sentiment: decide the positive/negative view of text
-
Attribution: assign authorship, detect language type
-
Part of Speech: parse sentence structure
-
Language Modeling: score likelihood of sentences
-
Named Entity Recognition: identify types of words
-
Summarization, Translation: consolidate or transfer text information in a human readable way
-
Dialogue: formulate simple responses to conversation snippets
-
Question answering: formulate responses to questions
-
Multi-modal transfer: caption images or audio transcripts
-
Warning
-
Build simple models first!!! assess time / resource consumption versus gain tradeoff
-
If you're not using deep learning for the data representations, transfer learning, or multi-output/multi-modal data, you probably don't need deep learning
Roadmap
-
Warmup Example: how a neural net works, standardize on terminology, build a simple network using Keras
-
IMDB Example: introduce NLP-specific layers for DNN, beat the benchmark
-
Language Model/Transfer Learning Example: demonstrate the power of large data sets, show how to combine pre-trained models in Keras to accomplish new tasks
Framework
- Step 1: Establish a Baseline
- Step 2: Process, Tokenize, Hash, and Pad
- Step 3: Embed
- Step 4: Encode
- Step 5: Predict & Measure
- Step 6: Iterate
Resources
Warm-up Example
-
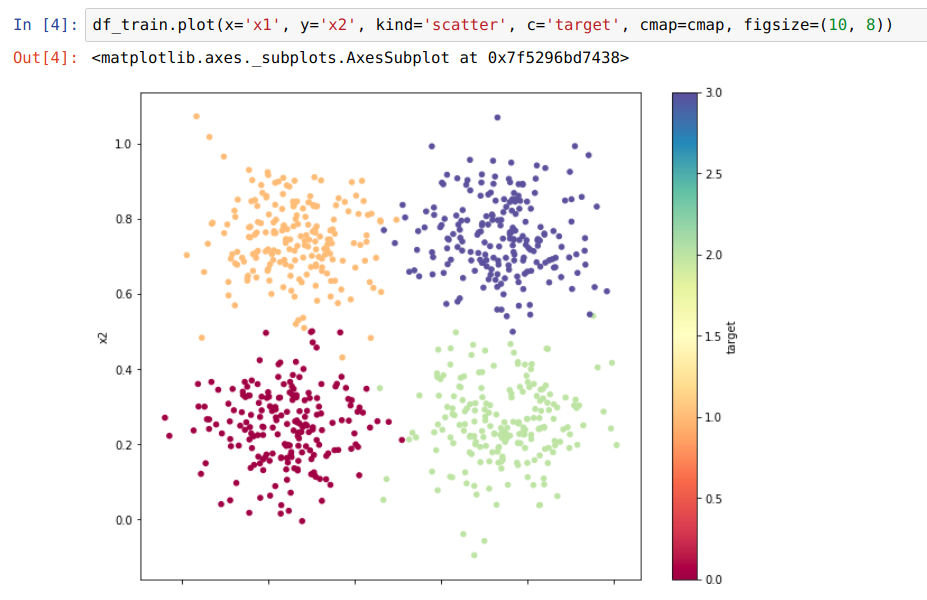
Task: Classify data info one of 4 categories
-
Data: 800 examples, each example has two dimensions ('x1', 'x2'), evenly distributed across categories
-
Metric: Accuracy
Keras
-
Quick aside: Why Keras?
-
Focus is getting something basic working quickly, and not cutting edge research
-
Keras abstracts many key concepts into building blocks, great for rapid prototyping
-
Uses Tensorflow as a backend for computation, which is optimized and efficient compared to roll-you-own options
-
Cons: not easy to peel back the layers; more limited in scope of capabilities compared to stock TF, Pytorch, or dynet (e.g., limited access to computation graph, loss functions, no recursion)
Overview
-
We're going to train our model just like any other neural network: feed our data through the model, calculate our loss, back propagate the error gradient through the model to adjust the weights, and repeat until we don't see substantial improvement
-
(👋👋👋🤦) That's an almost offensively hand-wavy explanation, however, you could spend several talks just scratching the surface of content for the previous bullet, so we'll move forward but highly recommend building knowledge and reading links below
-
Key thing to watch: if you validation loss is going down (and accuracy is going up) then your model is learning something
-
A few things to decide:
-
Batch Size: How many examples to feed in between updates?
-
Epochs: How many passes through the data?
-
Early Stopping: Do we want to stop when the validation loss stops going down?
-
Warm-up Example
-
Task: Classify data info one of 4 categories
-
Data: 800 examples, each example has two dimensions ('x1', 'x2'), evenly distributed across categories
-
Metric: Accuracy
Warm-up Example
1) Data is set of feature vectors

Warm-up Example
1) Data is set of feature vectors
2) Model made up of layers, layers have weights and activation functions
3) Data transformed in model by series of functions, resulting in a final vector
Warm-up Example
1) Data is set of feature vectors
2) Model made up of layers, layers have weights and activation functions
3) Data transformed in model by series of functions, resulting in a final vector
4) Loss function compares model output to true output, quantifies "incorrectness"
Warm-up Example
1) Data is set of feature vectors
2) Model made up of layers, layers have weights and activation functions
3) Data transformed in model by series of functions, resulting in a final vector
4) Loss function compares model output to true output, quantifies "incorrectness"
5) Compute partial derivative of loss wrt weights, use optimizer to determine step size
Warm-up Example
1) Data is set of feature vectors
2) Model made up of layers, layers have weights and activation functions
3) Data transformed in model by series of functions, resulting in a final vector
4) Loss function compares model output to true output, quantifies "incorrectness"
5) Compute partial derivative of loss wrt weights, use optimizer to determine step size
6) Update model weights accordingly
Warm-up Example
1) Data is set of feature vectors
2) Model made up of layers, layers have weights and activation functions
3) Data transformed in model by series of functions, resulting in a final vector
4) Loss function compares model output to true output, quantifies "incorrectness"
5) Compute partial derivative of loss wrt weights, use optimizer to determine step size
6) Update model weights accordingly
7) Rinse and repeat until loss stop going down
Warm-up Example
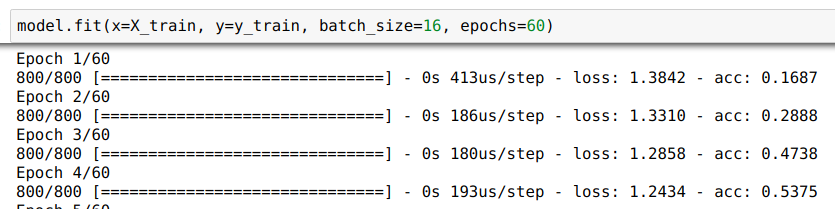
def get_model():
input_data = Input(shape=(2, ))
dense_layer = Dense(8, activation='relu')(input_data)
output_prediction = Dense(4, activation='softmax')(dense_layer)
model = Model(inputs=[input_data], outputs=[output_prediction])
model.compile(loss='categorical_crossentropy',
optimizer=SGD(lr=0.02),
metrics=['accuracy'])
return modelWarm-up Example
Warm-up Example
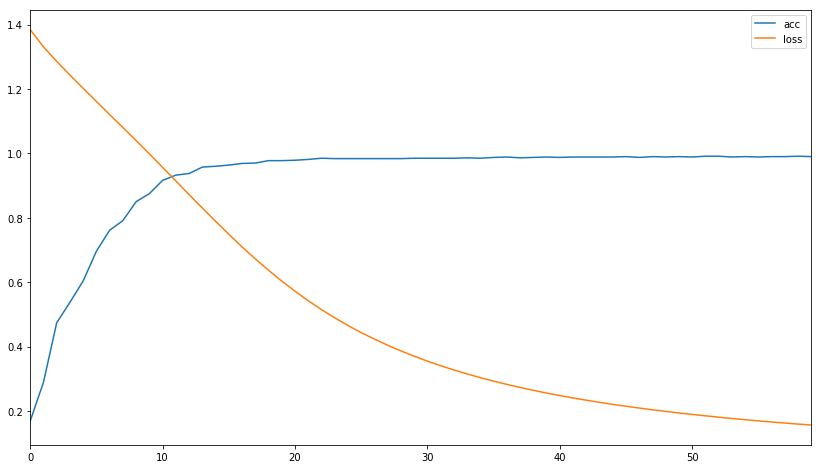
Blue line = Accuracy
Orange line = Loss
Task: Movie Review Sentiment Classification
- Task: binary sentiment classification; guess if a movie review is positive (IMDB score >= 7/10) or not
-
Data: 50,000 labeled reviews (50/50 train/test), pulled from IMDB in their native state (misspellings, grammar, markdown)
- 'I LOVED the Apprentice for the first two seasons.<br /><br />But now with season 5? (or is it 6?) things are getting just plain too tiring.<br /><br />I used to like the show, but its become Donald Trumps own ego fest.'
- Metric: F1 score
Resources
Task: Movie Review Sentiment Classification
- Establish Baseline
- Prepare Data
- Build Model
- Train, Predict, and Measure
Establish a Baseline
- a.k.a "Simple models first"
-
Baselines help us learn about the data, build features and interpret errors
-
You could be done now; in many cases bag of n-grams plus linear model achieves sufficient, competitive performance
-
Consider production; do you want to have a fast linear model that scales or are you willing to trade resources
-
Don't leave this presentation thinking you should fire up Keras at the first mention of text data!
Resources
Establish a Baseline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifierCV
tfidf_vectorizer = TfidfVectorizer(stop_words='english',
ngram_range=(1, 2),
max_df=1.0,
min_df=2,
max_features=None)
X_train = tfidf_vectorizer.fit_transform(df_train['text'])
X_test = tfidf_vectorizer.transform(df_test['text'])
y_train = df_train['target'].values
y_test = df_test['target'].values
ridge_model = RidgeClassifierCV(alphas=(0.1, 0.5, 2.0, 5.0, 10.0), cv=5)
ridge_model.fit(X_train, y_train)-
This should look familiar: count how many times you see a bi-gram, adjust by TF-IDF, push through a linear classifier with strong regularization
-
Note the feature vector here is more than 200,000 dimensions due to combinatorial bi-gram problem
Random baseline: 0.503
Ridge model accuracy: 0.873
Confusion Matrix:
[[11032 1468]
[ 1702 10798]]
Report:
precision recall f1-score support
0 0.87 0.88 0.87 12500
1 0.88 0.86 0.87 12500
avg / total 0.87 0.87 0.87 25000
Establish a Baseline
Prepare Data
Classic NLP: lower, stem, remove stopwords, lemmatize, n-gram, dependency or part of speech
With deep learning, we're asking the model to learn to compose features automatically
-
Preparing text for deep learning model is not that different but there are some considerations:
Sequential tokens, hashing, and padding
Your tokenizer can influence performance greatly
Minimize vocab for memory and speed
- Splitting train/val/test: be careful with sequential data; with large data sets, we don't actually need a lot in val and test (< ~10%)
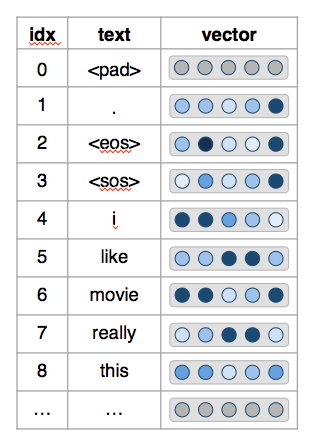
Prepare Data
-
Original string:
-
-
After tokenizer:
-
-
After int:
-
After int:
-
After pad:
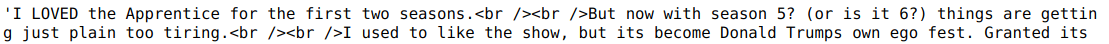



Building a Model
-
Our model will have four types of layers: embedding, convolutional, LSTM, and attention
-
Let's build it layer by layer and talk about what they each do to transform the data
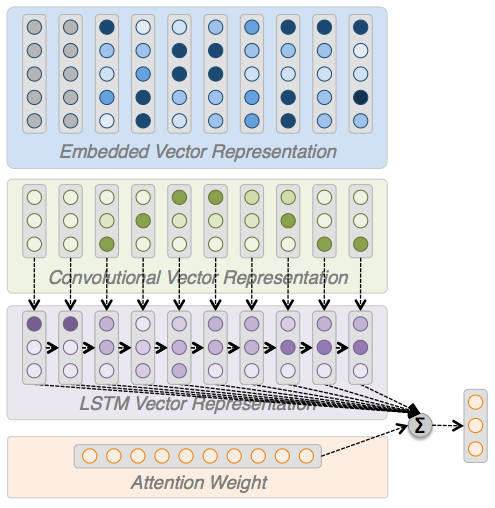
Building a Model: Embed
-
How does a deep NLP model encode text information? We need to vectorize it, but how?
-
Words are essentially categorical data so can we one-hot encode? Count/TF-IDF vector?
-
Unfortunately both are too big, and don't allow for generalization. We need a more compact input.
-
Solution: Distributed representation of tokens, a.k.a word vectors or word embeddings
-
Why? Pretty good representations of the word "meaning", while being much lower dimension, and you can learn on unlabeled data
Building a Model: Embed
-
How are word vectors created? Many different methods, but most use the words around a word as an indicator of its meaning
-
Build some sparse representation and reduce (👋)
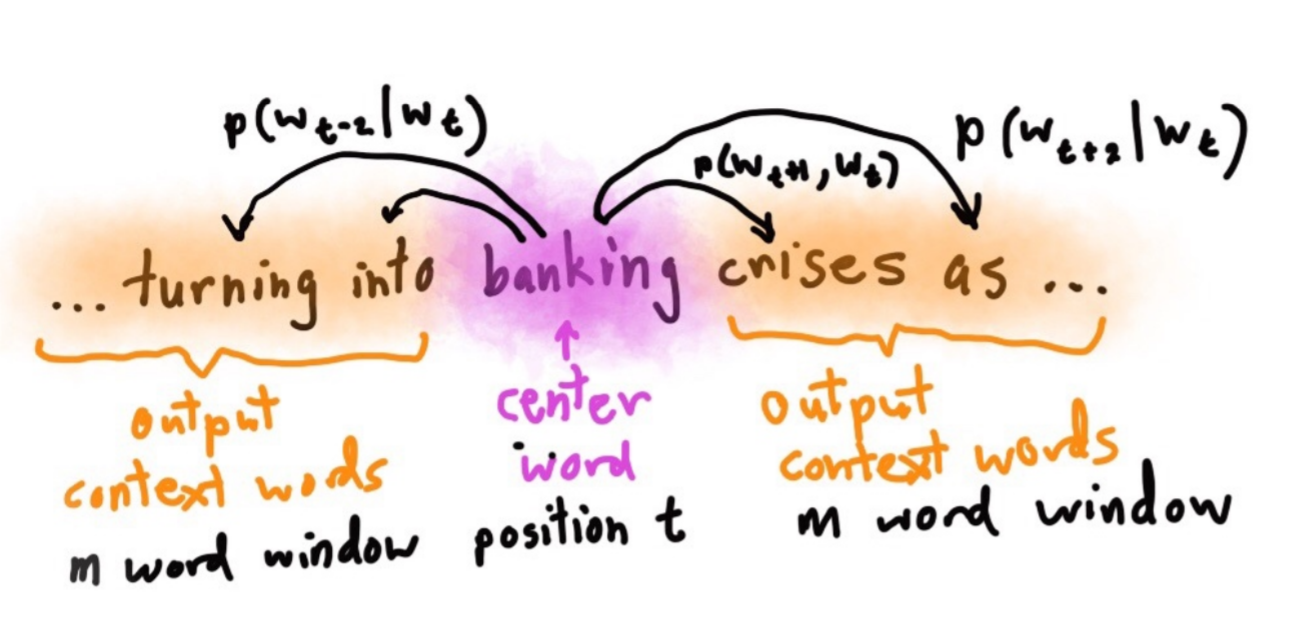
Image Credit: Representations for Language: From Word Embeddings to Sentence Meanings, Manning, 2017, (link: https://nlp.stanford.edu/manning/talks/Simons-Institute-Manning-2017.pdf)
Step 3: Embed
-
How can we get some? Two options:
-
1) Train your own
-
Pros: all vocab included
-
Cons: may not be very good representations
-
-
2) Download pre-trained embeddings
-
Pros: very "meaningful" vectors based on billions of examples
-
Cons: may be missing tokens/info relevant to your domain
-
-
-
Demo time
Resources
Building a Model: Embed
-
We're using lowercase, 1-grams only (vocab size only about 30k, compared to 200k for our baseline)
-
We lose some information but we'll pick it back up later

Building a Model: Embed
-
What happens if you stop right here?
-
Goal: Turn our sequence of word vectors into a probability of positive or negative sentiment
-
Need to figure out how to encode a 2D word matrix (sequence_length, word_vector_size) into a 1D vector that we can push through classifier
-
Easy way: take the average (or max), push through a classifier
Building a Model: Embed

Building a Model: Embed
Building a Model: Embed

Building a Model: Embed
<results>
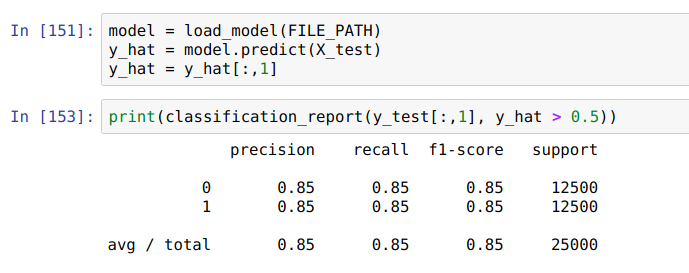
Results:
-
F1 of 0.85 doesn't beat our linear baseline of 0.88, but impressive given that we went from 200,000+ feature dimensions to 300, and with 20% of the vocabulary
-
How to improve?
Building a Model: Embed
-
Lots of places to go from here
-
Model: try different learning rates or optimizers, different hidden unit widths, add depth, regularization
-
Word Vectors: try different sizes, try unfreezing the pre-trained, try training your own, try a character-based model
-
Deeper Model: there are other layer types that may help us represent our data better
-
Roadmap from here: Convolutional Layers, Recurrent Layers, Attention, Language Models, and Multi-Task Models
Building a Model: Embed
-
Main components remain the same: Input, Model layers, Output, Loss function, Optimizer, Compile
-
Embedding layer takes care of the integer to word vector representation, the embedding weights are a matrix of word vectors
-
Initially set trainable=False, vector weights wont update
input_sequence = Input(shape=(SEQUENCE_LEN, ))
x = Embedding(input_dim=VOCAB_SIZE, output_dim=EMBED_SIZE,
weights=[embedding_weights],
trainable=False)(input_sequence)
x = ...(x)
prediction = Dense(N_CLASSES, activation='softmax')(x)
model = Model(inputs=input_sequence, outputs=prediction)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001),
metrics=['accuracy'])Building a Model: Conv
-
Convolutional networks are common in image processing, but they can be useful for NLP as well
-
Think of convolutional functions as a filter that you apply to a matrix; if you see certain patterns, you get excited (👋)
-
We can use conv filters on our word vector inputs to represent the data in a new (more useful) way
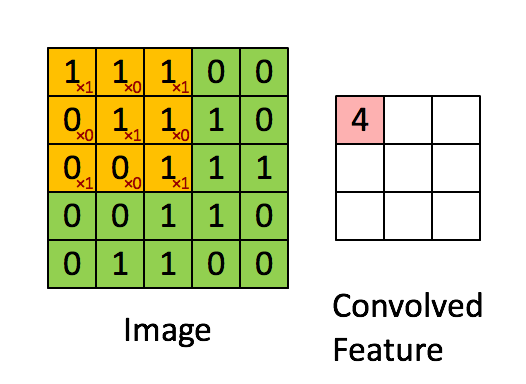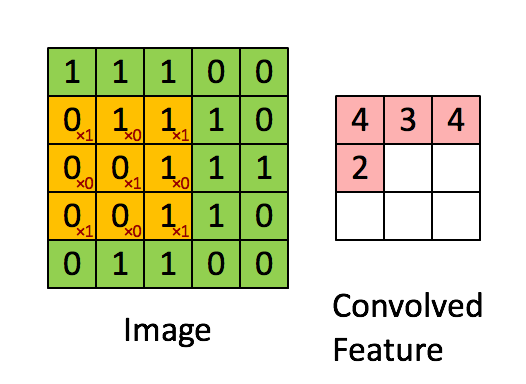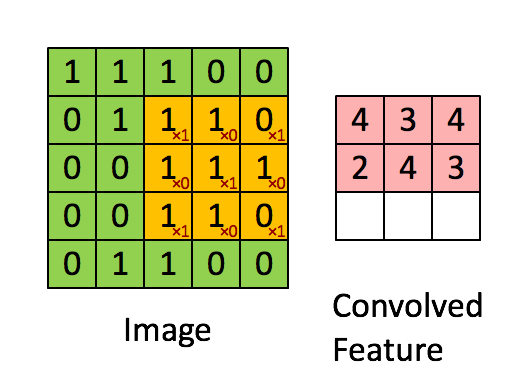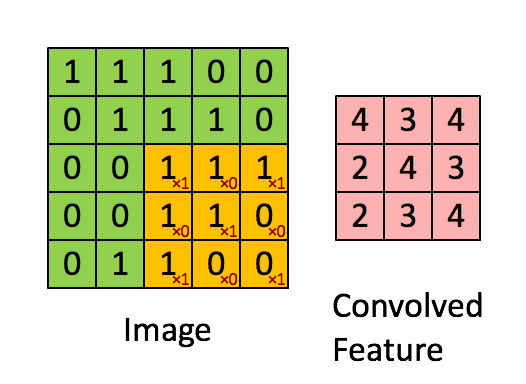
Image Credit: Convolution with 3×3 Filter, http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
Resources
Building a Model: Conv
-
Convolutions have two main parameters:
-
1) kernel size (how many words to view at once)
-
2) filter size (how many different filters you want)
-
-
Convolutions are powerful because they help us solve the n-gram problem, we can look at several words and represent them together, without increasing our vocab
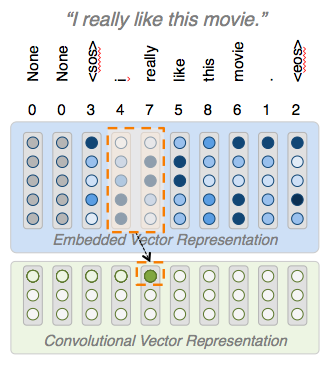
Kernel Size: 2
Filter Size: 3
Building a Model: Conv
-
Convolutions have two main parameters:
-
1) kernel size (how many words to view at once)
-
2) filter size (how many different filters you want)
-
-
Convolutions are powerful because they help us solve the n-gram problem, we can look at several words and represent them together, without increasing our vocab
Kernel Size: 2
Filter Size: 3
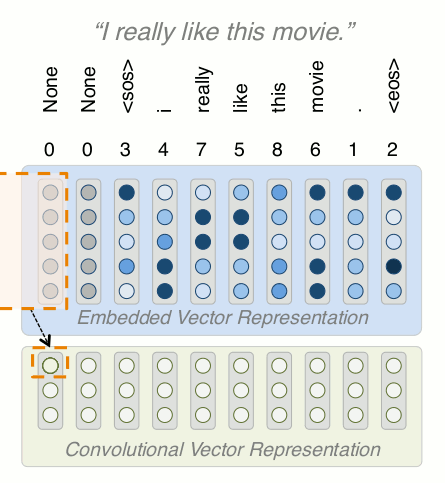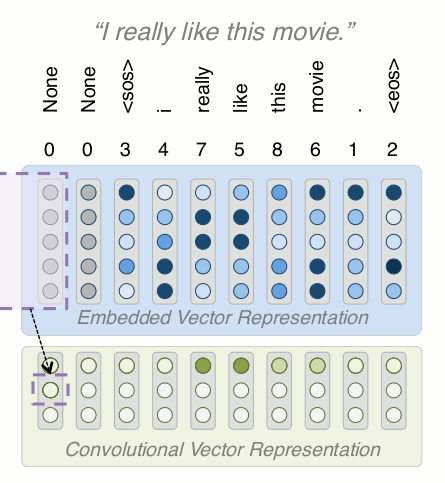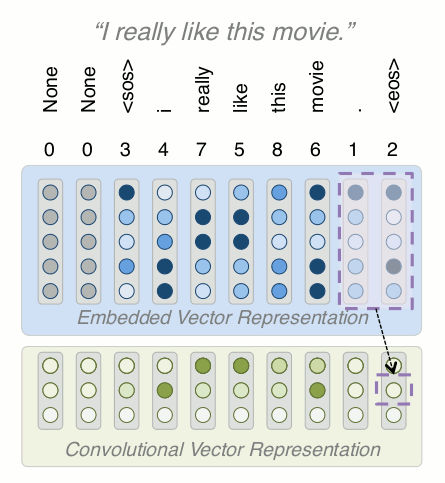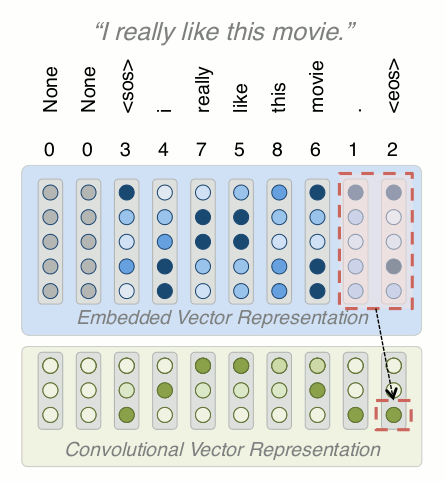
Building a Model: Conv
input_sequence = Input(shape=(MAX_LEN, ))
x = Embedding(input_dim=VOCAB_SIZE, output_dim=EMBED_SIZE,
weights=[embedding_weights],
trainable=False)(input_sequence)
x = Conv1D(CONV_FILTER_SIZE, CONV_KERNEL_SIZE, padding='same')(x)
x = ...(x)
prediction = Dense(N_CLASSES, activation='softmax')(x)
model = Model(inputs=input_sequence, outputs=prediction)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001),
metrics=['accuracy'])-
This should look familiar, we've only added one line of code (now you see the benefits of Keras)
-
The only tricky thing here is we've set padding to be same, meaning we want the same size output as we input (other versions reduce dimensionality)
Adding Convolution Layer
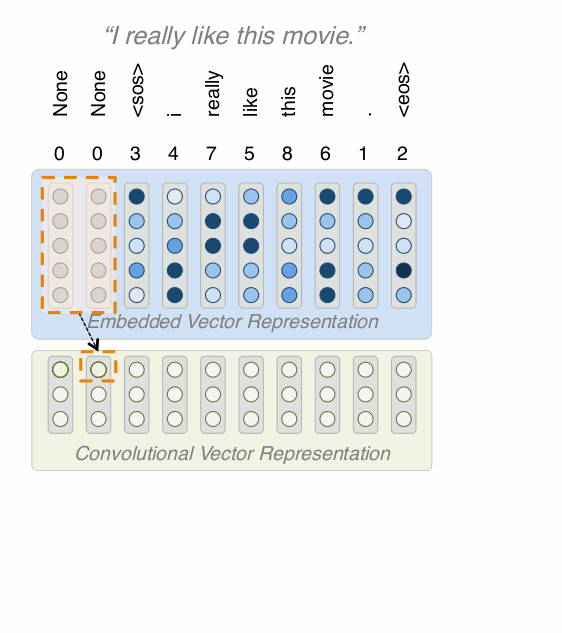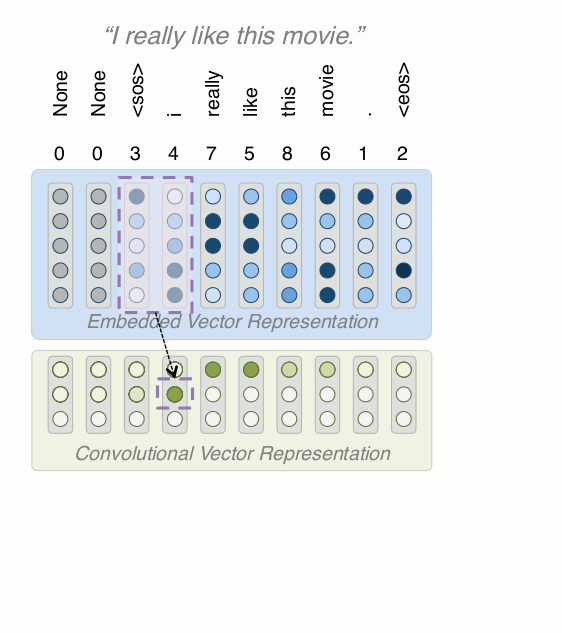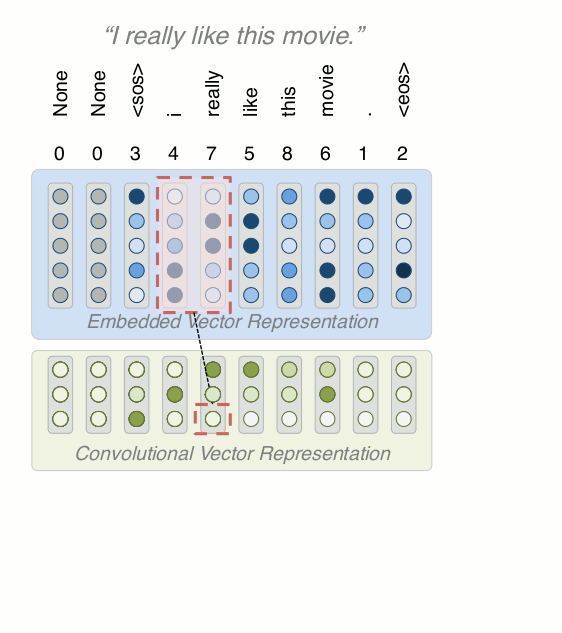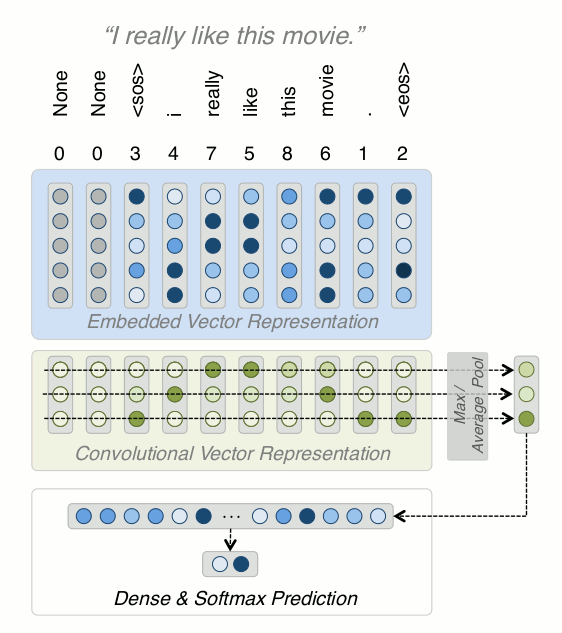
Adding Convolution Layer
Results:
-
F1 of 0.88 matches our linear baseline, now we're in the ballpark
-
Options to improve include: combining convolutional layers with different kernel sizes, stacking conv layers (window size is exponential!)
Building a Model: LSTM
-
Recurrent neural nets (RNNs) are commonly associated with text data because they help encode sequential information
-
They are different from what we've seen up to now because the model is shared across a sequence, and they take two inputs, Xt and the output of the previous time step (👋)
-
We'll use a specific version of an RNN, called a Long Short Term Memory network (LSTM)
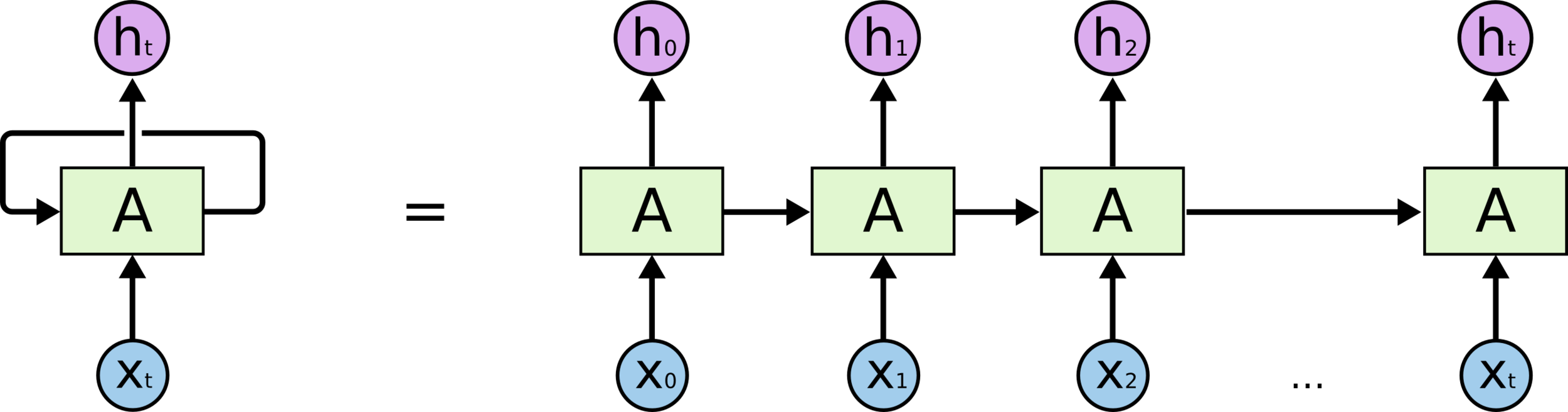
Image Credit: Understanding LSTM Networks, http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Resources
Building a Model: LSTM
-
LSTMs are is designed to pass along error signals better than stock RNNs (👋)
-
The LSTM receives the input from the conv layer above, and also the previous step output
-
The last hidden state (red box) can be used as a representation of the entire text, but this typically doesn't work well in practice because we are trying to compress too much information into too small a vector
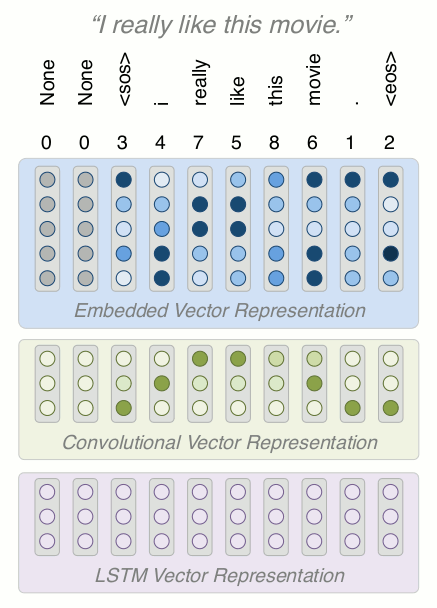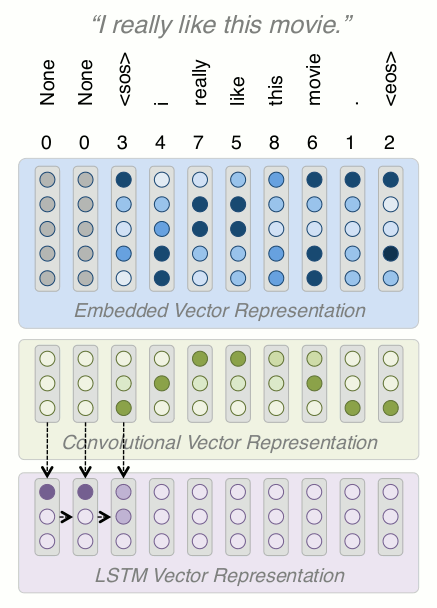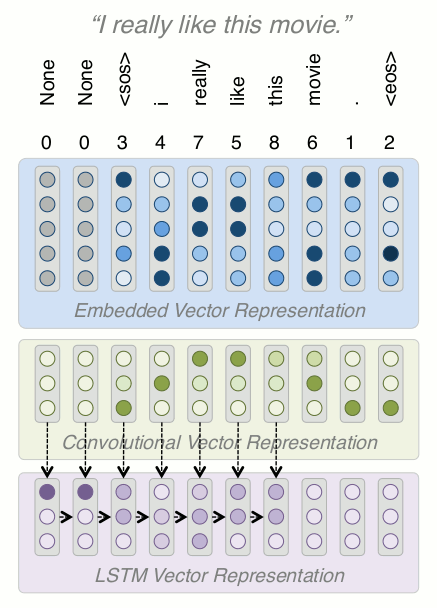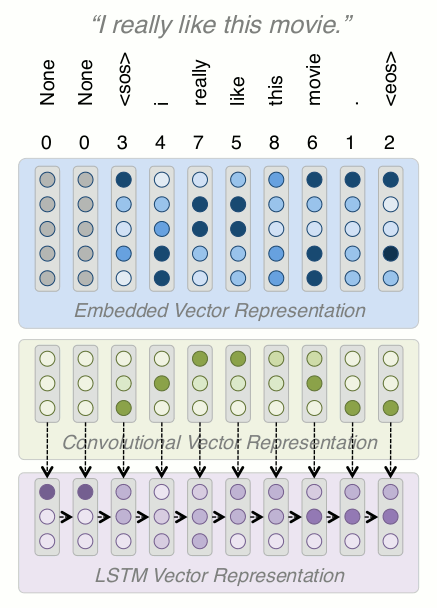
Building a Model: LSTM
input_sequence = Input(shape=(MAX_LEN, ))
x = Embedding(input_dim=VOCAB_SIZE, output_dim=EMBED_SIZE,
weights=[embedding_weights],
trainable=False)(input_sequence)
x = Conv1D(CONV_FILTER_SIZE, CONV_KERNEL_SIZE, padding='same')(x)
x = Bidirectional(LSTM(LSTM_HIDDEN_SIZE))(x)
x = ...(x)
prediction = Dense(N_CLASSES, activation='softmax')(x)
model = Model(inputs=input_sequence, outputs=prediction)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001),
metrics=['accuracy'])-
Again we've only added one line of code
-
Bidirectional just means we feed the data in once forwards and then again backwards, and concatenate the results
Adding Recurrent Layer
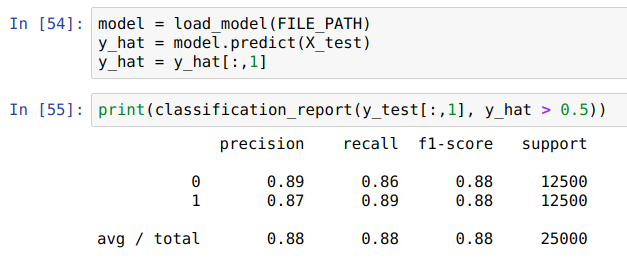
Results:
-
What happened? Precision and recall went down?
-
We're trying to squeeze too much information through a long chain, and summarize in a single vector at the end
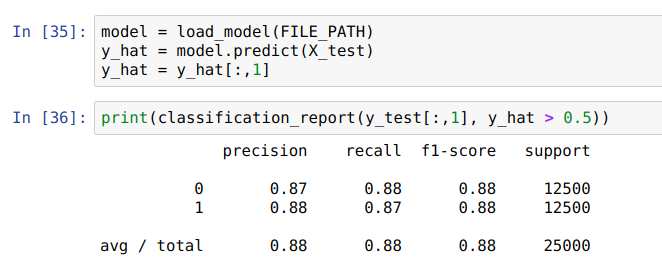
Building a Model: Attention
-
Attention layers allow us to focus on different parts of the LSTM output depending on the time step
-
The weights of attention layers learn focus on key concepts and sum together the hidden state for important parts of the sequence (👋)
-
This allows us to avoid trying to squeeze all of the information into the last hidden state, and instead pick which parts matter more to our task
Resources
Building a Model: Attention
-
The attention layer looks at the every individual output from the LSTM layer and decides if it's relevant to the task
-
The result is a summed vector the same size of the LSTM hidden state, but with information sampled throughout the sequence
-
Our task requires just one vector to classify the whole review, but attention vectors can also be output every time step
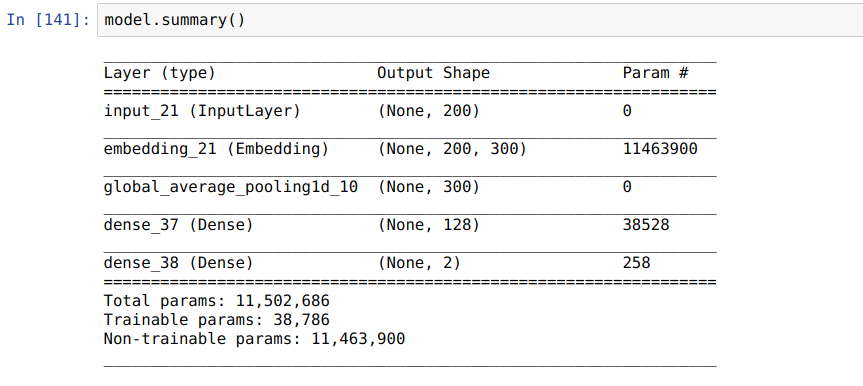
Building a Model: Final
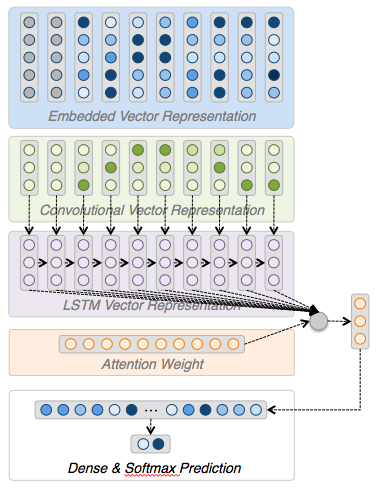
-
We now have the major building blocks for creating a deep NLP model
-
We can attach a classifier to the output of the LSTM/attention layers and have it predict the sentiment of the movie review
Building a Model: Final
input_sequence = Input(shape=(MAX_LEN, ))
x = Embedding(input_dim=VOCAB_SIZE, output_dim=EMBED_SIZE,
weights=[embedding_weights],
trainable=False)(input_sequence)
x = Conv1D(CONV_FILTER_SIZE, CONV_KERNEL_SIZE, padding='same')(x)
x = Bidirectional(LSTM(LSTM_HIDDEN_SIZE, return_sequences=True))(x)
x = AttentionWithContext()(x)
x = Dense(HIDDEN_LAYER_SIZE, activation='relu')(x)
prediction = Dense(N_CLASSES, activation='softmax')(x)
model = Model(inputs=input_sequence, outputs=prediction)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001),
metrics=['accuracy'])-
The LSTM is updated to return all hidden states with the return_sequences=True parameter
-
The AttentionWithContext layer is a custom layer which attends to each hidden state from the LSTM and creates a single weighted sum vector
Train, Predict, and Measure
Results:
-
With attention we beat the baseline getting an F1 of 0.89; tuning the model parameters and optimizing the layers may also give slight gains
-
From here, the highest value work is going to be incorporating external information
precision recall f1-score support
0 0.90 0.88 0.89 12500
1 0.89 0.90 0.89 12500
avg / total 0.89 0.89 0.89 25000
Results
-
There are many things to try and optimize in order to get better results, some options include:
-
Training your own word embeddings
-
Layer depth (e.g., try stacking convs)
-
Size of hidden units, filters, and kernels
-
Adding regularization, dropout
-
Lowering the learning rate and training for longer
-
Ensembling many models
-
-
Check out this blog post for more ideas: Deep Learning for NLP Best Practices
Language Model/Transfer Learning
-
One of the huge advantages of deep learning models comes from the ability to learn generalized features from large amounts of "unlabeled" data and transfer that knowledge to a new task
-
When you a model on billions of examples you get much better representation of the data in each layer
-
When we want to apply this model "knowledge" to a new task, we can reuse the first few layers of a model, cut off the bottom, and then "glue" on a new task
Language Models
-
In deep NLP, creating a language model is a common starting point for future tasks
-
Language models attempt to answer: given some context sequence, what's the next word? e.g., P(w|"who let the dogs")
-
Since we only need strings of text to train a language model, we can use the billions of examples we find on the internet
Language Models
-
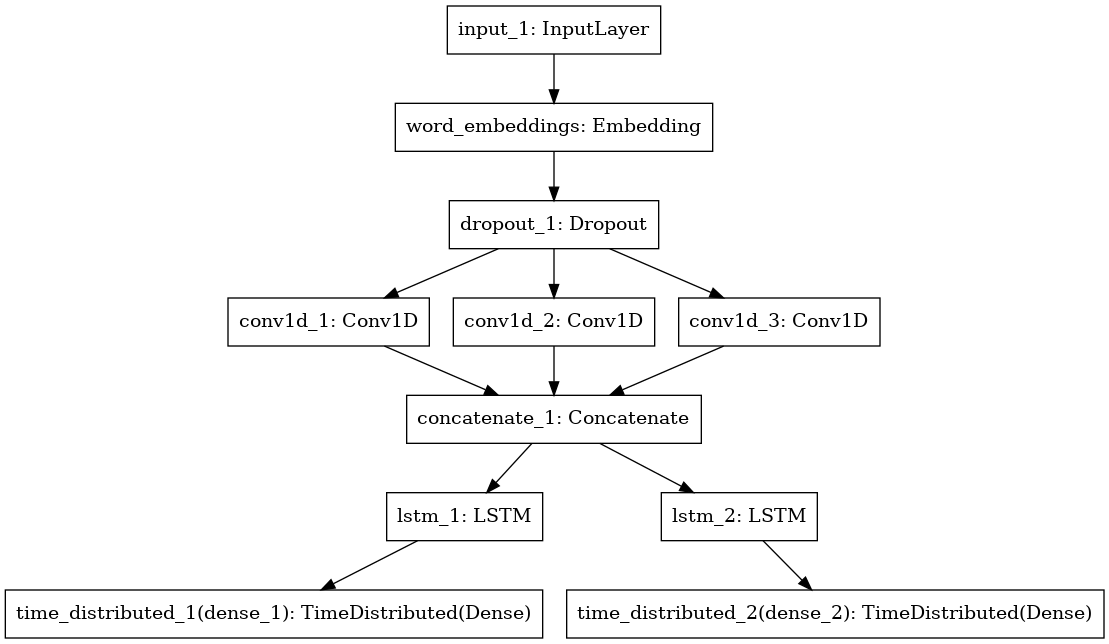
We'll construct a language model using data from a similar domain: Amazon Movie and TV review
-
The data contain 1,697,533 reviews which include text data, ratings, summary, and user info
-
Our model structure will mimic what we've built in the IMDB example, but with a a few minor tweaks:
-
Adding Dropout and l2 for regularization
-
Adding three conv windows (3, 4, 5 words at a time)
-
Two LSTMs, one looking forwards and one looking backwards
-
Next word prediction at each time step instead of sentiment
-
Warning: Training with 1 GPU takes about 24 hours
-
Resources
Language Models
Language Models
input_text = Input(shape=(MAX_LEN, ))
x = Embedding(input_dim=VOCAB_SIZE, output_dim=EMBED_SIZE,
input_length=MAX_LEN, weights=[embedding_weights],
trainable=False, name='word_embeddings')(input_text)
x = Dropout(0.5)(x)
c1 = Conv1D(...)(x)
c2 = Conv1D(...)(x)
c3 = Conv1D(...)(x)
x = concatenate([c1,c2,c3])
l_f = LSTM(LSTM_HIDDEN, return_sequences=True)(x)
output_f = TimeDistributed(Dense(VOCAB_SIZE, activation="softmax"))(l_f)
l_b = LSTM(LSTM_HIDDEN, return_sequences=True,
go_backwards=True)(x)
output_b = TimeDistributed(Dense(VOCAB_SIZE, activation="softmax"))(l_b)
model = Model(inputs=[input_text], outputs=[output_f, output_b])Language Models
Original:
"<sos> this is a charming version of the classic dicken 's tale . henry winkler makes a good showing as the scrooge character . even though you know what will happen this version has enough of a change to make it better that average . if you love a christmas carol in any version , then you will love this . <eos>"
Predicted:
"<sos> this is a charming version of the classic disney 's tale . henry nicholson makes a good showing as the character . even though you know what will happen this version has enough of a change to make it better that average . if you love a christmas carol in any version , then you will love this . <eos>"
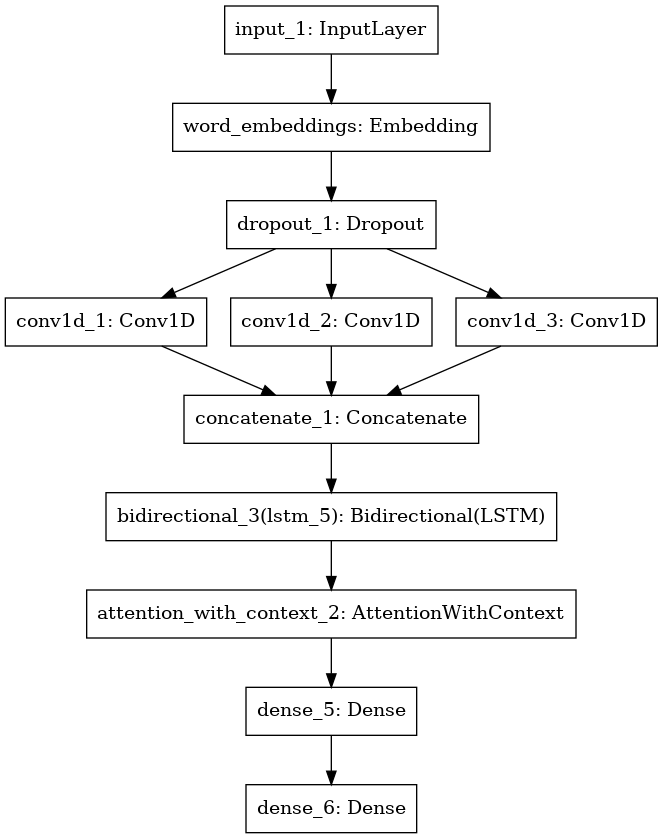
Transfer Learning
Language Model
(reused weights)
Sentiment Model
(new weights)
Transfer Learning
language_model = load_model(LANGUAGE_FILE_PATH)
input_text = language_model.input
x = Bidirectional(LSTM(LSTM_HIDDEN_UNITS),
return_sequences=True)(language_model.layers[-5].output)
x = AttentionWithContext()(x)
x = Dense(DENSE_HIDDEN, activation="relu")(x)
output_s = Dense(N_CLASSES, activation="softmax")(x)
model = Model(inputs=[input_text], outputs=[output_s])-
Reusing a model is as simple as picking the input and output layers from the original, and then inserting it into the new model
-
Weights for reused layers will be transferred over while new layers will be randomly initialized
Transfer Learning
Accuracy: 0.91232
Confusion Matrix:
[[11380 1120]
[ 1072 11428]]
precision recall f1-score support
0 0.91 0.91 0.91 12500
1 0.91 0.91 0.91 12500
avg / total 0.91 0.91 0.91 25000
- F1 of 0.91 beats our baseline by a good margin, and we didn't really try to tune anything
- Current SOTA for this task is 0.95 using this general approach, more data, and some tricks with timing of freezing/unfreezing layers
Transfer Learning
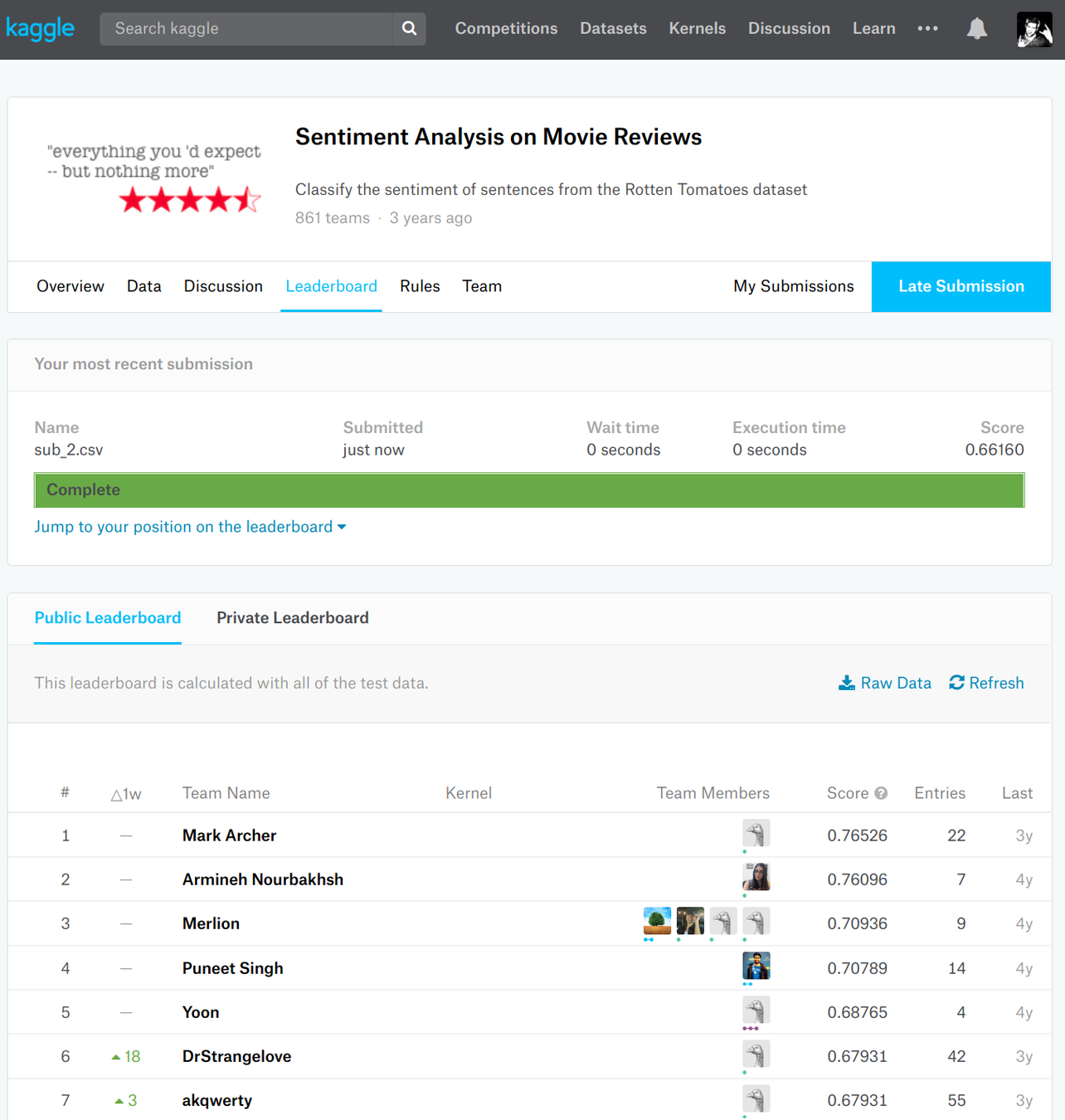
Transfer Learning
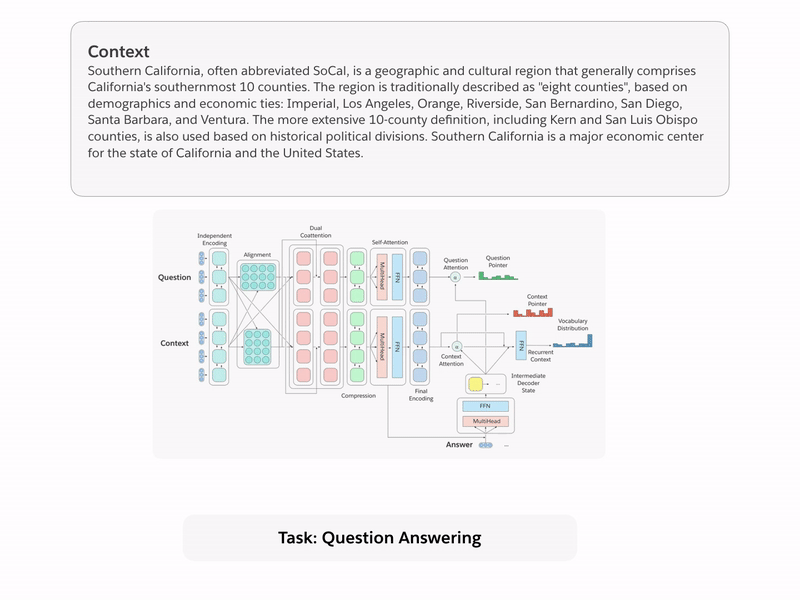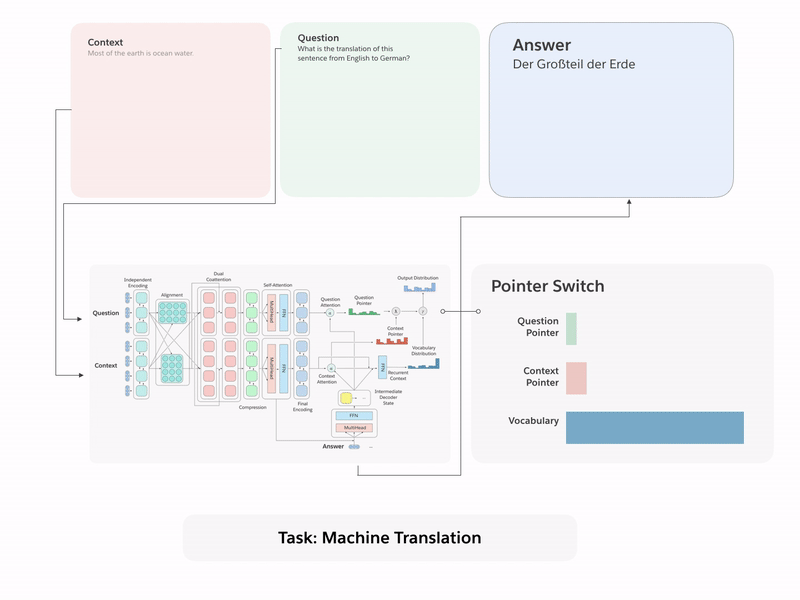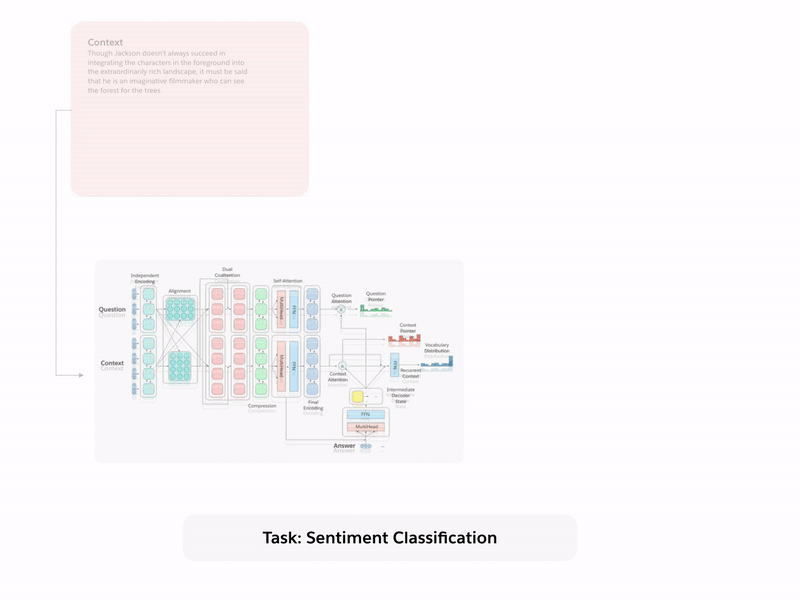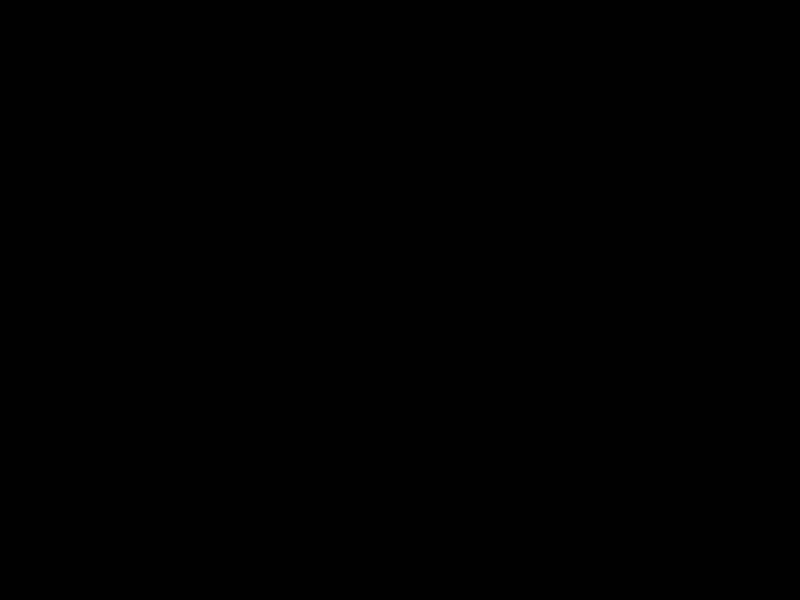
Image Credit: Salesforce, The Natural Language Decathlon, https://einstein.ai/research/the-natural-language-decathlon
Resources
Conclusion
-
It's easy to get started with deep learning for NLP using Keras, but remember: start with simple models, and move to deep learning if you can take advantage of data representations, transfer learning, or multi-output/multi-modal data
-
Tons of topics we didn't cover in this talk, highly recommend watching some of the courses out there to build a better understanding (Coursera Sequence Models, Stanford CS224n, CMU)
-
Take a look at the sample code notebooks and try to build your own models!