ML Model Serving
Index
- Model Servingとは
- Serving Platform
- Serving Framework
- TorchServe
- Nvidia Triton
- KServe
- Deploy Strategy
Index
- Model Servingとは
- Serving Framework
- TorchServe
- TFServe
- Nvidia Triton
- KServe
- Ray Serve
- BentML
- SerdonCore
- AITemplate
- Serving Platform
- Vertex AI
- Batch
- Cloud Run for Anthos
- Google Kubernetes Engine(GKE)
- Standard
- Autopilot
- Deploy Strategy
Model Servingとは
機械学習(ML)モデルをデプロイしてシステムとして稼働できる状態にすること
- バッチ
- オンライン予測(Web API)
- ストリーミング
学習
評価
Packaging
Deploy
監視
ざっくりこのあたり
推論
Servingの懸念点
- 多様なモデル形式
- GPU, TPUの活用
- パフォーマンス
- スケーリング
- トラフィック分割
- A/Bテスト
- ロギング
- メトリクス
- アーティファクト生成
- API 立ち上げ
- Dynamic Batch
- デプロイ
- 前処理, 後処理
- ワークフロー
- アンサンブル etc ...
Serving Platform
Serving Platform
- Vertex AI
- Batch
- Cloud Run for Anthos
- GKE
- Standard
- Autopilot
Serving Framework
TorchServe 1/5
- Packaging Model
- API
- REST and gRPC
- Inference, Management
- Batch
- Logging
- Metrics
- Preprocess, Postprocess
PyTorch eager mode と torch scripted model の Serving
- A/B test
- Deploy
- Vertex AI
- SageMaker
- KServe
- Helm chart
- mlflow etc...
- Multi Models
TorchServe 2/5
Packaging Model
# torchscript
torch-model-archiver --model-name densenet_161 \
--version 1.0 \
--serialized-file model.pt \
--handler image_classifier \
--export-path ./models_store# eager mode
torch-model-archiver --model-name densenet_161 \
--version 1.0 \
--serialized-file model.pt \
--handler image_classifier \
--export-path ./models_store \
--model-file model.py Handlerは組み込みのハンドラ(image_classifier, object_detector, text_classsifier, image_segmenter)か自作のPythonファイルを指定。
inference APIの実行に必要な densenet_161.marが生成される。
# inference
torchserve --start --model-store ./models_store --models densenet_161.marTorchServe 3/5
Preprocess, Postprocess
# custom handler file
# model_handler.py
"""
ModelHandler defines a custom model handler.
"""
from ts.torch_handler.base_handler import BaseHandler
class ModelHandler(BaseHandler):
"""
A custom model handler implementation.
"""
def __init__(self):
self._context = None
self.initialized = False
self.explain = False
self.target = 0
def initialize(self, context):
"""
Initialize model. This will be called during model loading time
:param context: Initial context contains model server system properties.
:return:
"""
self._context = context
self.initialized = True
# load the model, refer 'custom handler class' above for details
def preprocess(self, data):
"""
Transform raw input into model input data.
:param batch: list of raw requests, should match batch size
:return: list of preprocessed model input data
"""
# Take the input data and make it inference ready
preprocessed_data = data[0].get("data")
if preprocessed_data is None:
preprocessed_data = data[0].get("body")
return preprocessed_data
def inference(self, model_input):
"""
Internal inference methods
:param model_input: transformed model input data
:return: list of inference output in NDArray
"""
# Do some inference call to engine here and return output
model_output = self.model.forward(model_input)
return model_output
def postprocess(self, inference_output):
"""
Return inference result.
:param inference_output: list of inference output
:return: list of predict results
"""
# Take output from network and post-process to desired format
postprocess_output = inference_output
return postprocess_output
def handle(self, data, context):
"""
Invoke by TorchServe for prediction request.
Do pre-processing of data, prediction using model and postprocessing of prediciton output
:param data: Input data for prediction
:param context: Initial context contains model server system properties.
:return: prediction output
"""
model_input = self.preprocess(data)
model_output = self.inference(model_input)
return self.postprocess(model_output)TorchServe 4/5
API
- REST and gRPC
- Inference API
- Explanations, Predictions, KServe形式にも対応
- Management API
- モデルの登録/解除, 一覧表示, ワーカーの増減
TorchServe 4/5
# Captum の機能を使っている
curl http://127.0.0.1:8080/explanations/mnist \
-T image_classifier/mnist/test_data/0.png
[
[
[
[
0.004570948731989492,
0.006216969640322402,
0.008197565423679522,
0.009563574612830427,
0.008999274832810742,
0.009673474804303854,
0.007599905146155397,
,
,
]
]
]
]# KServe形式
curl -H "Content-Type: application/json" \
--data @kf_request_json/v1/mnist.json \
http://127.0.0.1:8080/v1/models/mnist:explain
{
"explanations": [
[
[
[
0.004570948731989492,
0.006216969640322402,
0.008197565423679522,
0.009563574612830427,
0.008999274832810742,
0.009673474804303854,
0.007599905146155397,
,
,
,
]
]
]
]
}API - Explantions
TorchServe 4/5
# resnet
curl http://localhost:8080/predictions/resnet-18/2.0 \
-F "data=@kitten_small.jpg"
{
"class": "n02123045 tabby, tabby cat",
"probability": 0.42514491081237793
}# minist. kserve形式
curl -H "Content-Type: application/json" \
--data @kf_request_json/v1/mnist.json \
http://127.0.0.1:8080/v1/models/mnist:predict
{
"predictions": [
2
]
}Vertex AI EndpointsはKServeの形式
API - Predictions
TorchServe 4/5
metrics api
TorchServe 5/5
Batch:
複数の入力をまとめて処理することで計算資源を効率的に扱う。スループットの向上を目的としており、即時性とのトレードオフ。
Dynamic Batch:
指定された時間枠内で受信したリクエストを集約してBatch処理を行う。ある程度の即時性が求められる環境で計算資源を効率的に扱う。
Dynamic Batch
TorchServe 5/5
Dynamic Batch
# management api
curl -X POST "localhost:8081/models?url=https://torchserve.pytorch.org/mar_files/resnet-152-batch_v2.mar&batch_size=3&max_batch_delay=10&initial_workers=1"Management APIを使ったDynamic Batch設定
TorchServe 5/5
Dynamic Batch
# config.properties
load_models=resnet-152-batch_v2.mar
models={\
"resnet-152-batch_v2": {\
"2.0": {\
"defaultVersion": true,\
"marName": "resnet-152-batch_v2.mar",\
"minWorkers": 1,\
"maxWorkers": 1,\
"batchSize": 3,\
"maxBatchDelay": 5000,\
"responseTimeout": 120\
}\
}\
}torchserve --start --model-store model_store \
--ts-config config.properties設定ファイルを起動時に読み込んでDynamic Batch設定
Triton Inference Server 1/5
- Support popular frameworks
- NVIDIA GPUs, x86, ARM CPUs
- Multi-GPU Multi-node
- Multi Models
- Real time, Batch, Streaming
- Cloud, Edge, k8s
- RAPIDS
- Logging, Metrics, Statistics
NVIDIAが提供している推論フレームワーク。多機能・効率的
- Performance Analyzer
- Model Analyzer
- Shared memory
- Response cache
- Trace
- Stateless, Stateful, Ensemble
- Preprocess, Postprocess
- Rate Limit
Triton Inference Server 2/5
- TensorRT
- TensorFlow
- PyTorch
- ONNX
- OpenVINO
- Python
- RAPIDS FIL etc...
多様なフレームワーク、アーキテクチャ、プラットフォームに対応
- NVIDIA GPU
- X86
- ARM CPU
- AWS Inferentia
- Kubernetes
- EKS, GKE, AKS... etc
- Cloud
- SageMaker
- Vertex AI
- Azure ML ...etc
- Edge
Triton Inference Server 3/5
- API
- REST
- gRPC
- KServe protocol
- C, Java
多様な推論処理
- Batch
- Default Scheduler
- Dynamic
- Sequence
- Ensemble
- Stateless
- Stateful
- Streaming
Triton Inference Server 4/5
モデルに推論リクエストを送信してスループットとレイテンシを測定する
- 並列リクエスト可能
- CSV出力(オプション)
- メトリクス
- GPU使用率
- GPUメモリ使用率... etc
Performance Analyzer
TensorFlow ServingとTorchServeの計測もサポート(Beta)
Triton Inference Server 5/5
Model Analyzer
- max_batch_size, instance_groupなどのパラメータを探索してGPU使用率やメモリ使用率、スループット等を分析レポート
- パフォーマンスの向上や信頼性の向上、Multi modelの組み合わせの目安に使われる
- 探索は手動・自動で行うことができBrute, Quick, 複数モデルの同時実行のオプションがある
KServe 1/5
Kubernetesの推論プラットフォーム
- 複数のMLフレームワークに対応, Multi model
- GPU対応の0までのスケールインとオートスケール
- ModelMesh
- Predict, Explain, Batch
- Pre/Post processing
- Monitoring
- Inference Graph
- Canary Rollout
Kubernetes
KNative + Istio
KServe
KServe 2/5
複数のMLフレームワークに対応
- TensorFlow
- PyTorch
- XGBoost
- scikit-learn
- ONNX ... etc
https://kserve.github.io/website/0.9/modelserving/v1beta1/serving_runtime/#model-serving-runtimes
KServe 3/5
ModelMesh
Kubernetesのリソースを効率的に扱い、スケーラビリティを向上
従来の課題
- 計算資源のオーバーヘッド
- 各Podにsidecarが必要
- Podsの最大数制限
- IP addressの枯渇
KServe 4/5
Inference Graph - パイプライン
KServe 5/5
Autoscaling
- 0までスケールインできる
- GPUのスケールにも対応
- コンポーネントレベルで設定
- メトリクスによるスケール
- concurrency, rps, cpu, memory
KServe 5/5
0までスケールインできる
KPAを使うと最小レプリカを0にできる
Knative Pod Autoscaler(KPA) ... min 0
Horizontal Pod Autoscaler(HPA) ... min 1
Kubernetes
KNative + Istio
KServe
KServe 5/5
GPUのスケールにも対応
KServe 5/5
コンポーネントレベルで設定
KServe 6/6
Canary Rollout
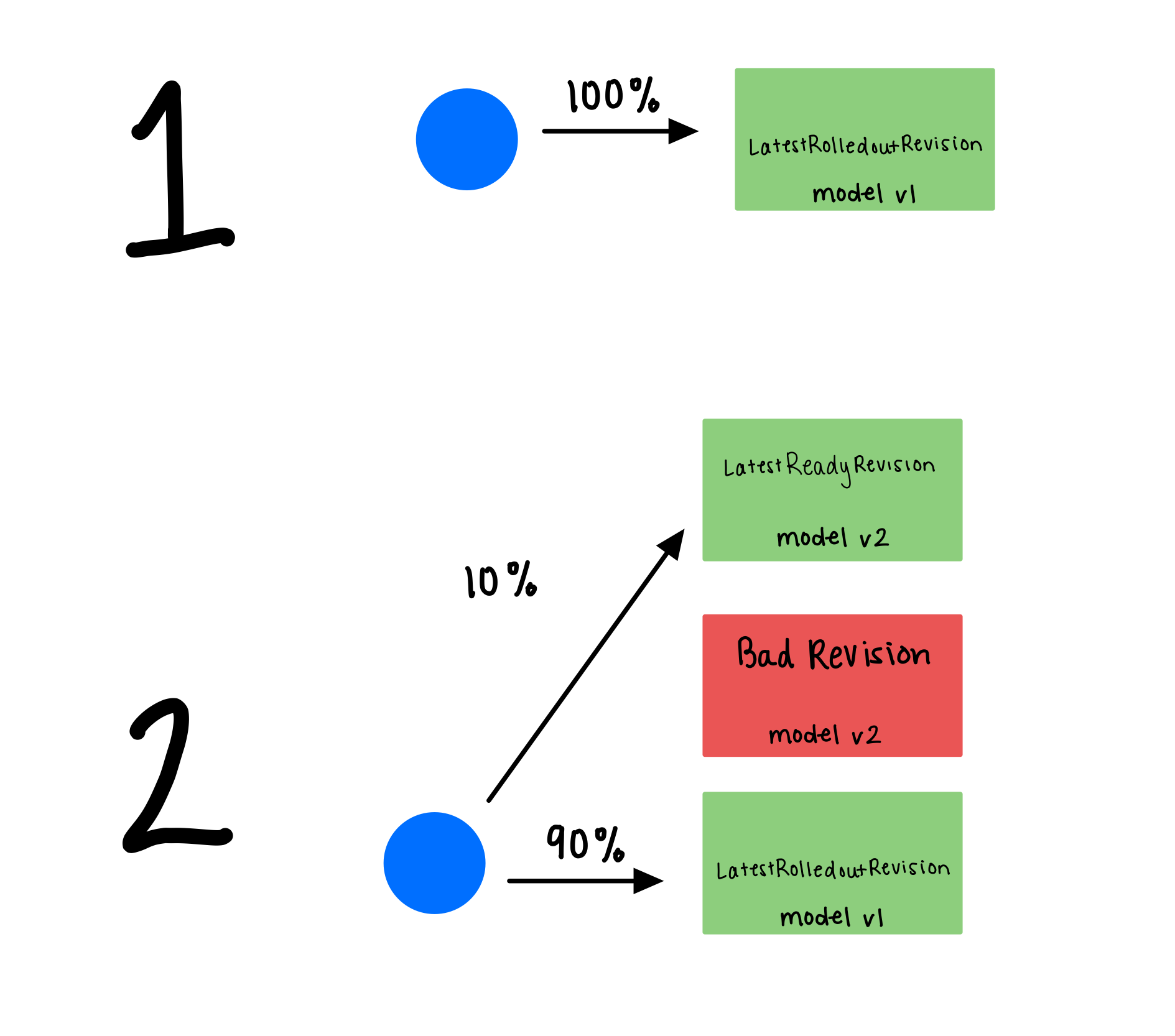
KServe 6/6
Canary Rollout
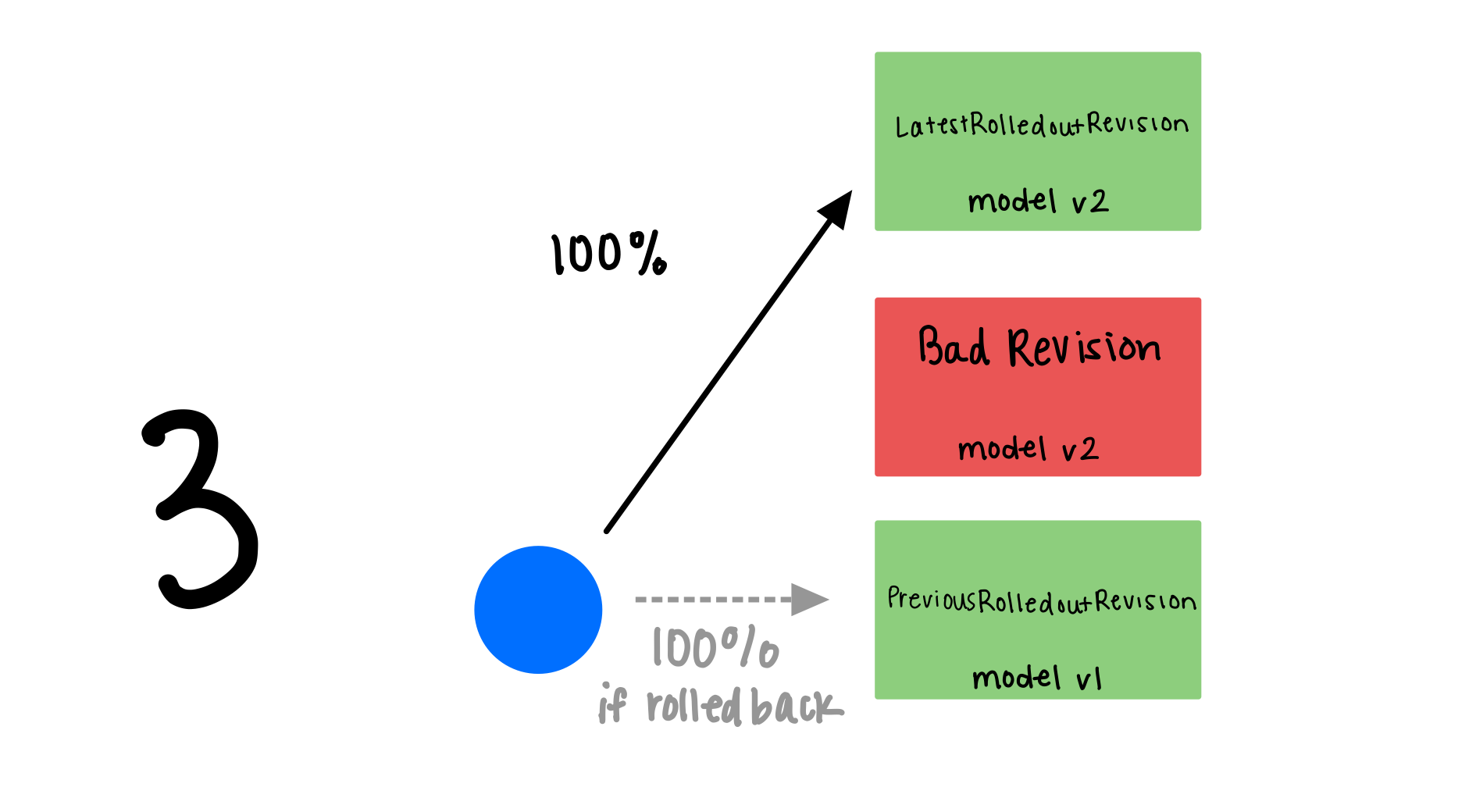
Deploy Strategy
推論の高速化
その他気になるもの
- BentML
- TensorFlow Serving
- Seldon Core
- Ray Serve
参考
- https://ahmet.im/blog/gke-autopilot/
- https://aws.amazon.com/jp/blogs/news/ml-enablement-series-dark05/
- https://cloud.google.com/vertex-ai/docs/predictions/custom-prediction-routines
- https://developer.nvidia.com/ja-jp/blog/accelerating-inference-up-to-6x-faster-in-pytorch-with-torch-tensorrt/ pytorch, tensorRT benchmark
- https://aws.amazon.com/jp/blogs/news/deploying-pytorch-models-for-inference-at-scale-using-torchserve/ pytorch batch
- https://github.com/facebookincubator/AITemplate
- https://github.com/kserve/kserve
- https://github.com/kubeflow/examples
- https://github.com/kubeflow/kubeflow
- https://github.com/pytorch/serve
- https://github.com/triton-inference-server/server
- https://github.com/ahkarami/Deep-Learning-in-Production
- https://github.com/visenger/awesome-mlops
- https://github.com/kelvins/awesome-mlops
- https://github.com/vahidk/EffectivePyTorch
- https://github.com/GoogleCloudPlatform/knative-build-tutorials
- https://github.com/SaschaHeyer/Google-Vertex-AI-CI-CD
- https://github.com/deep-diver/Model-Training-as-a-CI-CD-System
- https://github.com/rafaelsf80/vertex-ai-labs
- https://github.com/axelmagn/vertex-mlops-template
- https://github.com/jarokaz/vertex-ai-workshop
- https://github.com/fuzzylabs/vertex-edge
- https://github.com/sayakpaul/Dual-Deployments-on-Vertex-AI
- https://github.com/statmike/vertex-ai-mlops
- https://github.com/GoogleCloudPlatform/mlops-with-vertex-ai
- https://github.com/GoogleCloudPlatform/vertex-ai-samples
- https://www.youtube.com/watch?v=s6TDq8naG48