Les données structurées
et leur traitement
L'histoire des données
-
1725 : Système de rubans perforés (Basile Bouchon)
-
1728 : Cartes perforées (Jean-Batiste Falcon) Premier support de stockage de données, utilisées jusqu'aux années 1960.
-
1956 : Premier Disque Dur (IBM 350 - Reynold Johnson) 50 disques - poids total : 1 tonne - Capacité : 3,75 Mo
-
1970 : Modèle relationnel (Edgar codd) Représentation logique et rationnelle des données pour les exploiter
-
1979 : Premier Tableur sur un ordinateur individuel Visicalc - Les ordinateurs deviennent des outils de travail dans les entreprises.
-
1984 : Mémoire flash (Toshiba - Fujio Masuoka)
-
1997 : Apparition du terme BIG DATA : Grand ensemble de données de natures multiples et en constante évolution.
-
2009 : Application de l'Open Data par Barack Obama - Rendre l'état américain plus transparent.
-
2013 : Charte pour l'ouverture des données publiques signée par les pays du G8.
Au programme :
-
ActivitéS : Qu’est-ce qu’une donnée ?
Comment Structurer des données ? Doc 1 p 72 Hatier Foucher Doc b à g p 88-89 Nathan Doc 1 et 3 p 18-19 Delagrave
Définir une

Donnée personnelle :
"C'est toute information relative à une personne physique susceptible d'être identifiée, directement ou indirectement." CNIL
Des données personnelles peuvent être confidentielles ou publiques.
Pour que des données ne soient plus considérées comme personnelles, il faut les rendre anonymes.

A lire :
- La déferlante des données (interstices.info 2015)
- Big Data : définition, enjeux et applications (lcl.fr 2018)
Origine des Données ?
Les données sont d’origine humaine (un livre, la saisie des absences et retards), générées par des dispositifs de mesure (capteurs), par des machines (ordinateurs : date de modification d’un fichier) ou des applications (moyenne d’un élève, traitement d’images).
importance des Données ?
Une donnée, un ensemble de données, est une information : sa sauvegarde est un enjeu, sa propriété, sa diffusion, sa confidentialité sont des enjeux.
types de Données ?
Les données peuvent être brutes, semi-structurées ou structurées
pourquoi structurer les Données ?
Pour pour faciliter leur traitement, les exploiter, pour en extraire de l'information.
comment décrire Un objet ?
des descripteurs.
Pour décrire un objet on utilise

un smartphone
exemple :

Voici une collection de téléphones.
Quels descripteurs utiliser ?

- couleur
- taille de l'écran
- avec ou sans clavier physique
- avec ou sans clapet...
| couleur | taille écran | clavier Physique | clapet | |
|---|---|---|---|---|
| Téléphone 1 | rose | petit | avec | avec |
| Téléphone 2 | blanc | petit | avec | avec |
| Téléphone 3 | noir | petit | avec | avec |
| Téléphone 4 | noir | petit | avec | avec |
| Téléphone 5 | gris | grand | sans | sans |
| Téléphone 6 | noir | moyen | sans | sans |
| Téléphone 7 | noir | moyen | sans | sans |
collection =
ensemble d'objets partageant les mêmes descripteurs
les objets en ligne, les descripteurs en colonne et les données à l’intersection.
LES DONNÉES SONT ALORS DITES STRUCTURÉES.
Il est pratique de présenter les données sous forme de tableaux (ou tables)

Dans une base de données les objets s'appellent des enregistrements.
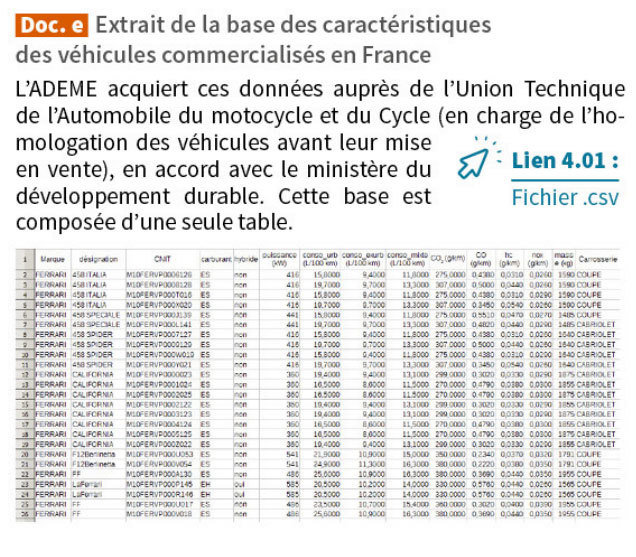
Descripteurs caractérisants un véhicule automobile ?

Descripteurs caractérisants un véhicule automobile ?
Quelle est la consommation urbaine du 6ème enregistrement de la table ?
Quelle est la Code National d'Identité du Type du 6ème enregistrement de la table ?
CNIT

Dans une base de données relationnelle, une clé primaire est la donnée qui permet d'identifier de manière unique un enregistrement (objet de la base) dans une table.
Une clé primaire peut être composée d'un ou de plusieurs champs.
Deux lignes distinctes de la table ne peuvent pas avoir les mêmes valeurs dans les colonnes définies comme clé primaire.
Le champ pouvant servir de clé primaire dans la table précédente est le CNIT
Dans la table précédente quel champ pourrait servir de clé primaire ?
Employee{ID, First_name, Last_name, Salary, Age, Address}Clés candidates pour être une clé primaire :
(ID) et (First_name, Last_name) 

Un trillion = \(1000000^3 =10^{18}\)
Un quadrillion = \(1000000^4 =10^{24}\)
Un quintillion = \(1000000^5 =10^{30}\)
Les 3V : Volume Variété Vélocité
= champ, attribut, propriété
SGBD
<?xml version = "1.0" encoding="UTF-8" standalone="yes"?>
<document>
<employee>
<name>Alex</name>
<age>22</age>
</employee>
<employee>
<name>Bob</name>
<age>24</age>
</employee>
<employee>
<name>Emily</name>
<age>32</age>
</employee>
</document>Données semi-structurées : Informations qui ne résident pas dans une base de données rationnelle, mais qui possèdent des propriétés organisationnelles facilitant leur analyse.
EX. données au format XML
Descripteurs : « Nom », « Capitale », « Hymne » et « Superficie ». Par exemple, « Pékin » est une valeur du descripteur « Capitale ».
Donner les descripteurs et une valeur d’un descripteur :
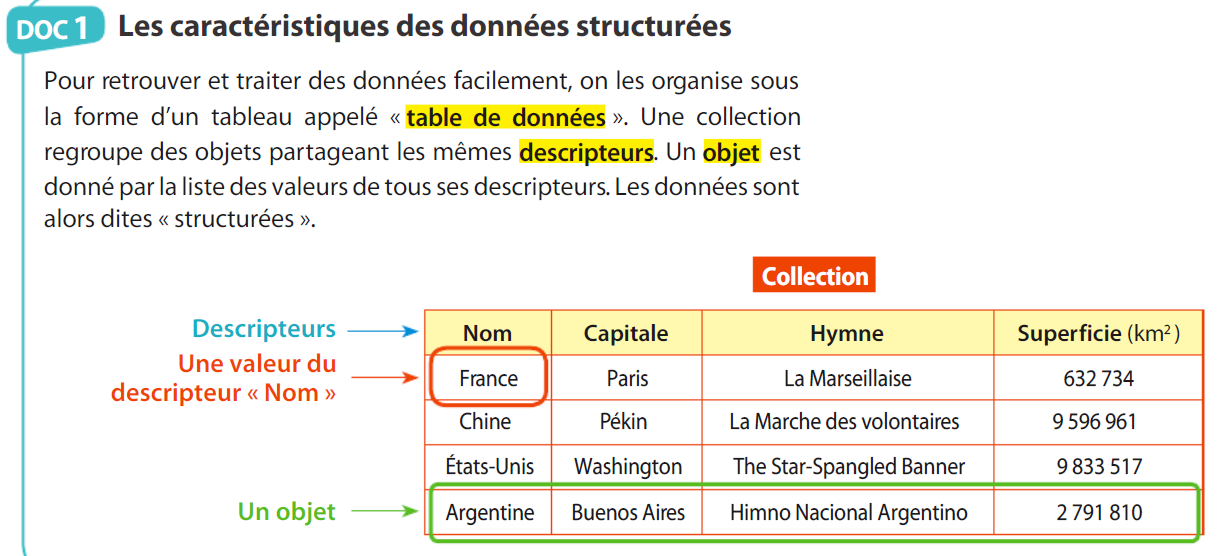

Combien y a-t-il d’objets dans la collection représentée sous forme CSV, XML et JSON ? Quels en sont les descripteurs et comment sont-ils placés dans les différents formats ?
On distingue deux objets et trois descripteurs : « prenom », « nom » et « classe ».
I. Décomposition de documents informatisés
1.Dans ces tickets, quelles informations/inscriptions dépendent du client et de ses achats ?
2.Lesquelles sont communes à tous les tickets ?
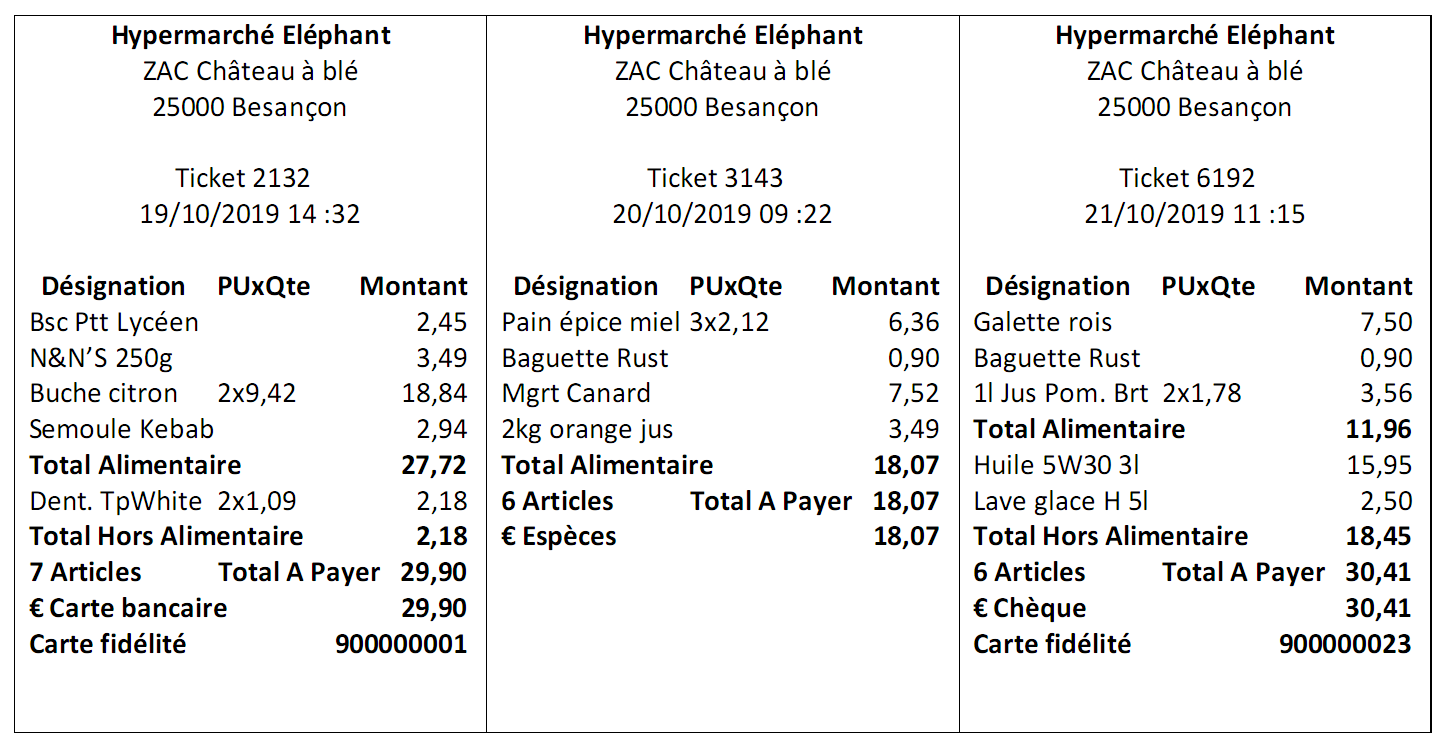
1.Dans ces tickets, quelles informations/inscriptions dépendent du client et de ses achats ?
Numéro du ticket, date et heure du ticket, les articles achetés, le nombre d'articles achetés, le montant total pour chaque article acheté, le montant des différents totaux, le mode de règlement, le numéro de carte de fidélité
2.Lesquelles sont communes à tous les tickets ?
Adresse du magasin, descripteurs (Désignation, PUxQte, Montant...)
Activité : En surlignant (tickets et tables) avec une couleur par table, faites le lien entre les informations de ces tickets et les tables qui les alimentent.
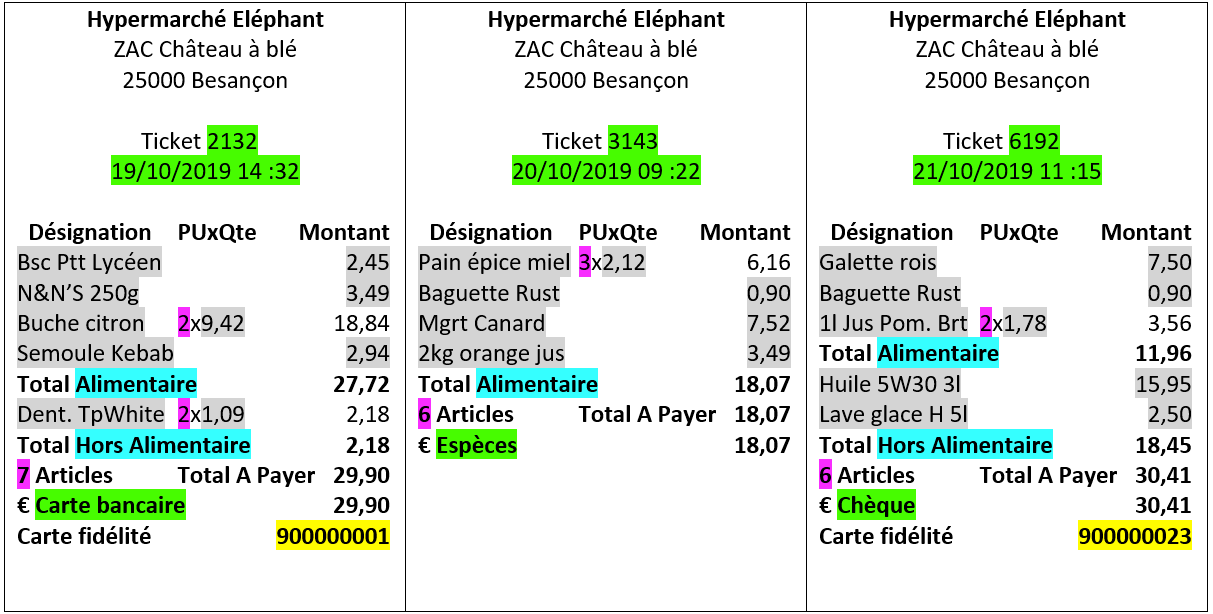
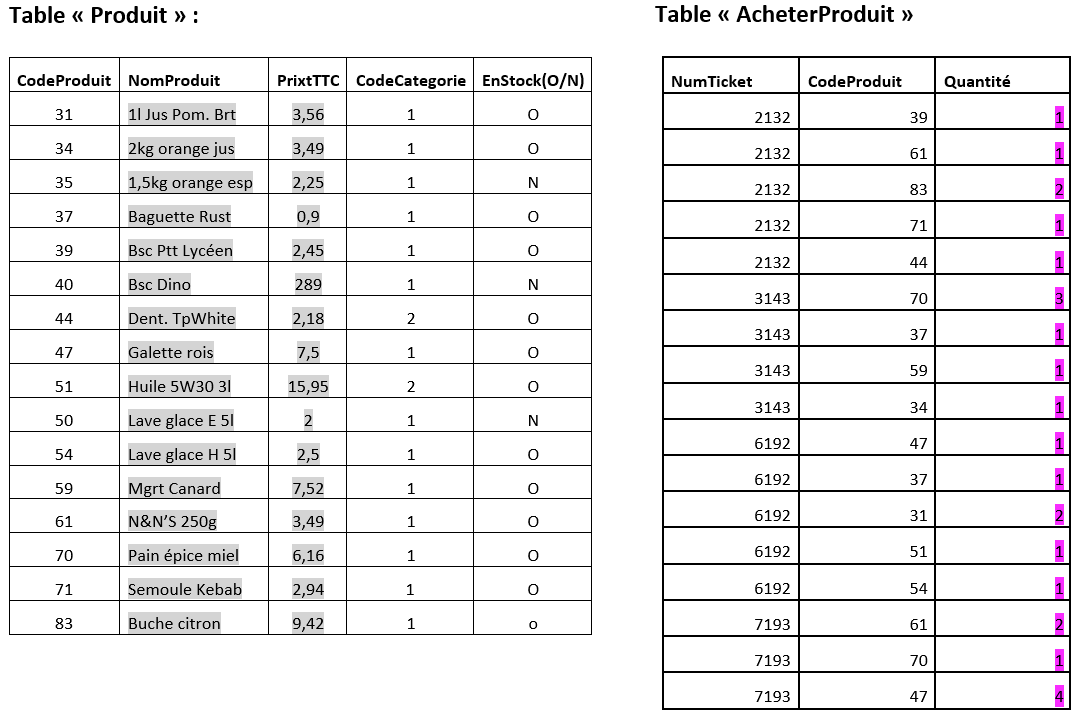
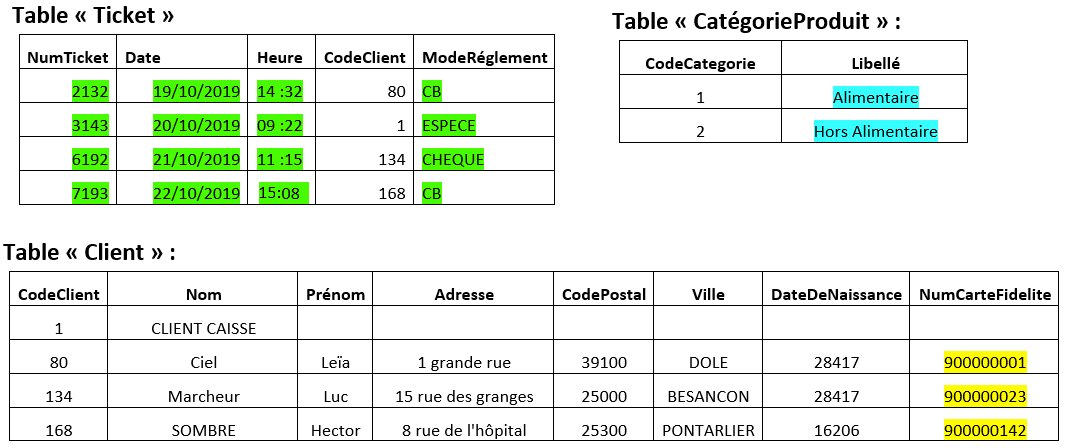
Questions :
- Qui est le client détenteur de la carte fidélité 900000001 ?
- Qui a fait les achats du ticket 3143?
- Qui a fait les achats du ticket 6192 ?
- Comment peut-on retrouver les produits du ticket 3143 ?
- Par quel lien avons-nous associé un ticket de caisse à un client ?
- Quels sont les achats du ticket 7193 ? Reproduisez ce ticket !
-
Leïa Ciel
-
CLIENT CAISSE
-
Luc marcheur
-
Grâce à la table acheter produit
-
Le code client associe un ticket de caisse à un client
-
4 Galettes rois, 2 N&N’S 250g, 1 pain épice miel
ii. Structuration des tables
Pour des raisons de gestion de l’espace disque et d’organisation des enregistrements, chaque descripteur est d’un type précis.
- Numérique : Entier, Réel
- Texte (taille illimitée), Chaîne de n caractères
- Date, heure
- Booléen (vrai/oui ou faux/non)
Il existe aussi des types liés à la géolocalisation (coordonnées d’un point, coordonnées du contour d’une forme géographique,…)
Rappel : les objets en ligne, les descripteurs en colonne et les données à l’intersection.
iii. Une propriété qui lie les autres
Dans chacune des tables, quelle propriété est minimale et suffisante pour retrouver :
- Un client :
- Un produit :
- Un ticket :
- Une catégorie de produit :
C'est la Clé primaire qui permet d'identifier de manière unique un enregistrement dans une table.
CodeClient
CodeProduit
NumTicket
CodeCategorie
Il n'y a pas de doublon "num tickets"/"code produit" car pour chaque ticket il n'y a pas de code produit en doublon.
Il peut arriver qu’un seul descripteur ne soit pas suffisant pour discriminer deux enregistrements. Dans la table AcheterProduit deux propriétés composent ensemble la clé primaire.
Pourquoi n'y-a-t-il pas de doublon « NumTicket »/ « CodeProduit » dans la table « AcheterProduit » ?
iv. Représentation des tables et stockage des données
Représentation graphique
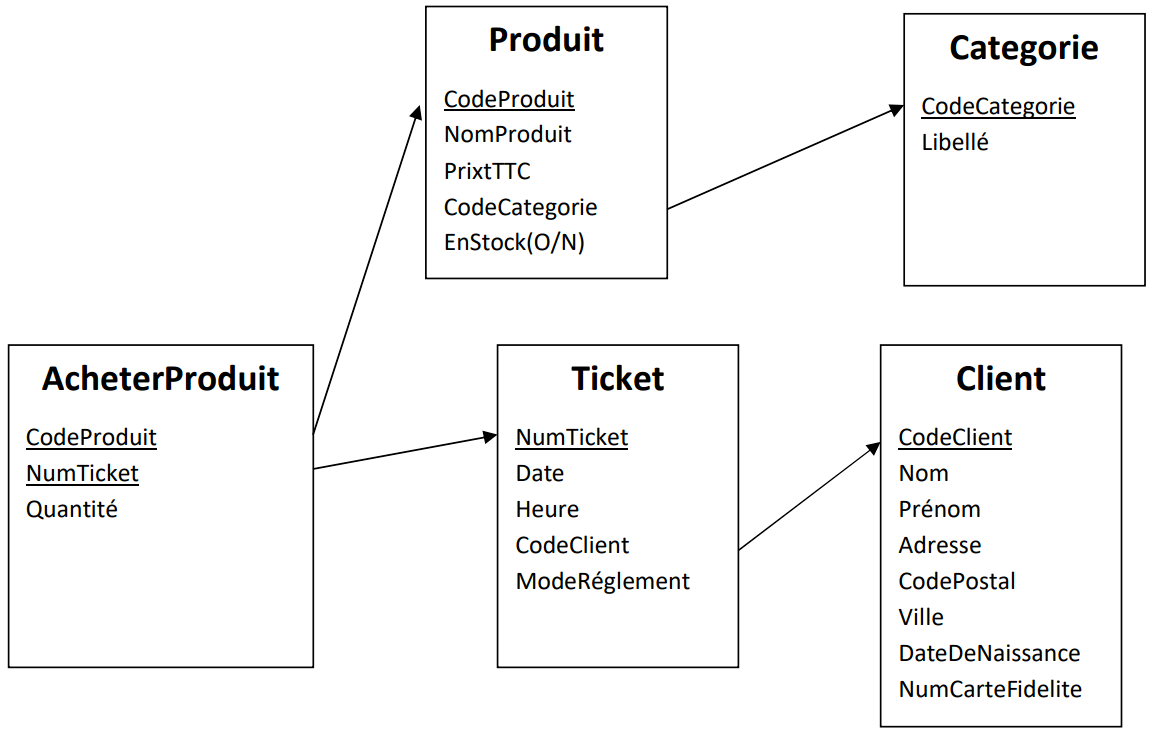
- Retrouvez dans cette représentation les noms des tables et leurs propriétés.
- Pourquoi certaines sont soulignées ?
- Donnez une signification aux flèches entre les tables.
- ...
- Ce sont les clés primaires.
- Lorsqu'une table 1 possède une propriété qui est une clé primaires d'une table 2, au niveau de cette propriété, on relie la table 1 à la table 2.
Stockage
Les données sous cette forme sont stockées dans un SGBD (Système de Gestion de Base de Données).
Il existe plusieurs éditeurs de ces logiciels : Oracle avec la solution éponyme ou MySQL, Microsoft avec Access ou SQL Server, le monde libre avec MariaDB ou PostGreSQL.
Ces systèmes répondent à des commandes qui s’appellent des requêtes et font ce qui est sollicité :
demande d’informations, modification du contenu, évolution de la structure des données,…
Chaque système a son mode de fonctionnement propre, mais il existe des standards pour représenter, échanger, sauvegarder et exporter des données.
structure des objets
XML : Extensible Markup Language.
Dans cette représentation, les valeurs associées à une propriété sont encapsulées entre des balises sous une forme arborescente
<Propriété>valeur</Propriété><structure>
<Propriété1>valeur1</Propriété1>
<Propriété2>valeur2</Propriété2>
</structure><TableCategorie>
<Categorie>
<CodeCategorie>1</CodeCategorie>
<Libellé>Alimentaire</Libellé>
</Categorie>
<Categorie>
<CodeCategorie>2</CodeCategorie>
<Libellé>Hors Alimentaire</Libellé>
</Categorie>
</TableCategorie>JSON : format de données textuelles dérivé de la notation des objets du langage JavaScript.
"TableCategorie" : {
" Categorie": [
{ " CodeCategorie ": "1",
" Libellé ": "Alimentaire"
},
{ " CodeCategorie ": "2",
" Libellé ": "Hors Alimentaire"
}
]
}
CSV : Comma-Separated Values, est un format texte ouvert représentant des données tabulaires sous forme de valeurs séparées par des virgules ou des points-virgules.
CodeCategorie;Libellé
1;Alimentaire
2;Hors AlimentaireParmi ces trois formats lequel prend le moins de place ?
CSV
Représentez les deux premiers enregistrements de la table « produit » avec ces 3 formats.
<TableProduit>
<Produit>
<CodeProduit>31</CodeProduit>
<NomProduit>1l Jus Pom. Brt</NomProduit>
<PrixTTC>3,56</PrixTTC>
<CodeCategorie>1</CodeCategorie>
<EnStock(O/N)>O</EnStock(O/N)>
</Produit>
<Produit>
<CodeProduit>34</CodeProduit>
<NomProduit>2kg orange jus</NomProduit>
<PrixTTC>3,49</PrixTTC>
<CodeCategorie>1</CodeCategorie>
<EnStock(O/N)>O</EnStock(O/N)>
</Produit>
</TableProduit>"TableProduit" : {
" Produit": [
{ " CodeProduit ": "31",
" NomProduit ": "1l Jus Pom. Brt",
" PrixTTC ": "3,56",
" CodeCategorie ": "1",
"EnStock(O/N)" : "O"
},
{ " CodeProduit ": "34",
" NomProduit ": "2kg orange jus",
" PrixTTC ": "3,49",
" CodeCategorie ": "1",
"EnStock(O/N)" : "O"
}
]
}
CodeProduit;NomProduit;PrixtTTC;CodeCategorie;EnStock(O/N)
31;1l Jus Pom. Brt;3,56;1;O
34;2kg orange jus;3,49;1;Ov. Devenir des données collectées (introduction à la RGPD)
La masse de données collectées et les traitements liés permettent de faire des spéculations sur les habitudes de consommation des clients et leurs vies.
- Quel client fait lui-même l’entretien de sa voiture ?
- Lequel cuisine lui-même ?
- Lequel a probablement des problèmes d’équilibre alimentaire ?
Luc Marcheur
Client caisse
Leïa Ciel
4. Quel est le but premier de ce système de collecte de données ? Est-ce que cela vous choque par rapport aux conclusions que le magasin peut en tirer ?
5. Imaginez d’autres choses qu’un magasin peut déduire sur un client rien qu’avec ses habitudes de consommation.
Le but premier de ce système de collecte de données est d'améliorer la gestion comptable et commerciale du magasin.
Le client fait du sport, a une bonne hygiène, mange des sushis, fait du camping, va à la piscine, aime le vin, boit trop de vodka, a un jardin, a des enfants, aime le saumon, consomme des produits bio, dépense peu en biens culturels, écoute du Hard rock, joue aux courses, se teint les cheveux, utilise du maquillage bas de gamme...
6. Et si ces données fuitent suite à un piratage, quelles peuvent être les conséquences sur les clients ?
- perte d’accès, corruption ou destruction de ses propres données.
- tentative de fraude
- divulgation de données sensibles...
- atteinte à la réputation
Extrait du RGPD.
Mesures qui permettent de :
1. Protéger contre l’usage abusif des données collectées
- Les entreprises et les organismes sont tenus de notifier dès que possible l'autorité nationale de protection en cas de violations graves de données afin que les utilisateurs puissent prendre des mesures appropriées.
- La possibilité de désigner un délégué à la protection des données
- Les sanctions plus importantes
Extrait du RGPD.
Mesures qui permettent de :
2. S’assurer d’un minimum de protection des données
- Le règlement européen définit le principe de « protection des données dès la conception » qui impose aux organisations de prendre en compte des exigences relatives à la protection des données personnelles dès la conception des produits, services et systèmes exploitant des données à caractère personnel.
- la nouvelle règle de la « sécurité par défaut » qui impose à toute organisation de disposer d’un système d’information sécurisé
Extrait du RGPD.
Mesures qui permettent de :
3. Se faire oublier de l’entreprise
- La personne concernée a le droit d'obtenir du responsable du traitement l'effacement, dans les meilleurs délais, de données à caractère personnel la concernant et le responsable du traitement a l'obligation d'effacer ces données à caractère personnel dans les meilleurs délais pour 6 motifs...
Extrait du RGPD.
Mesures qui permettent de :
4. Contrôler ce qui est fait avec les données collectées.
- Les entreprises et organismes doivent donner aux citoyens davantage de contrôle sur leurs données privées, notamment via l'acceptation des cookies sur les sites internet et sur le contrôle de l'utilisation qui est faite des données que les internautes envoient dans les formulaires de contact.
- Possibilité de solliciter le délégué à la protection des données pour faire valoir ses droits
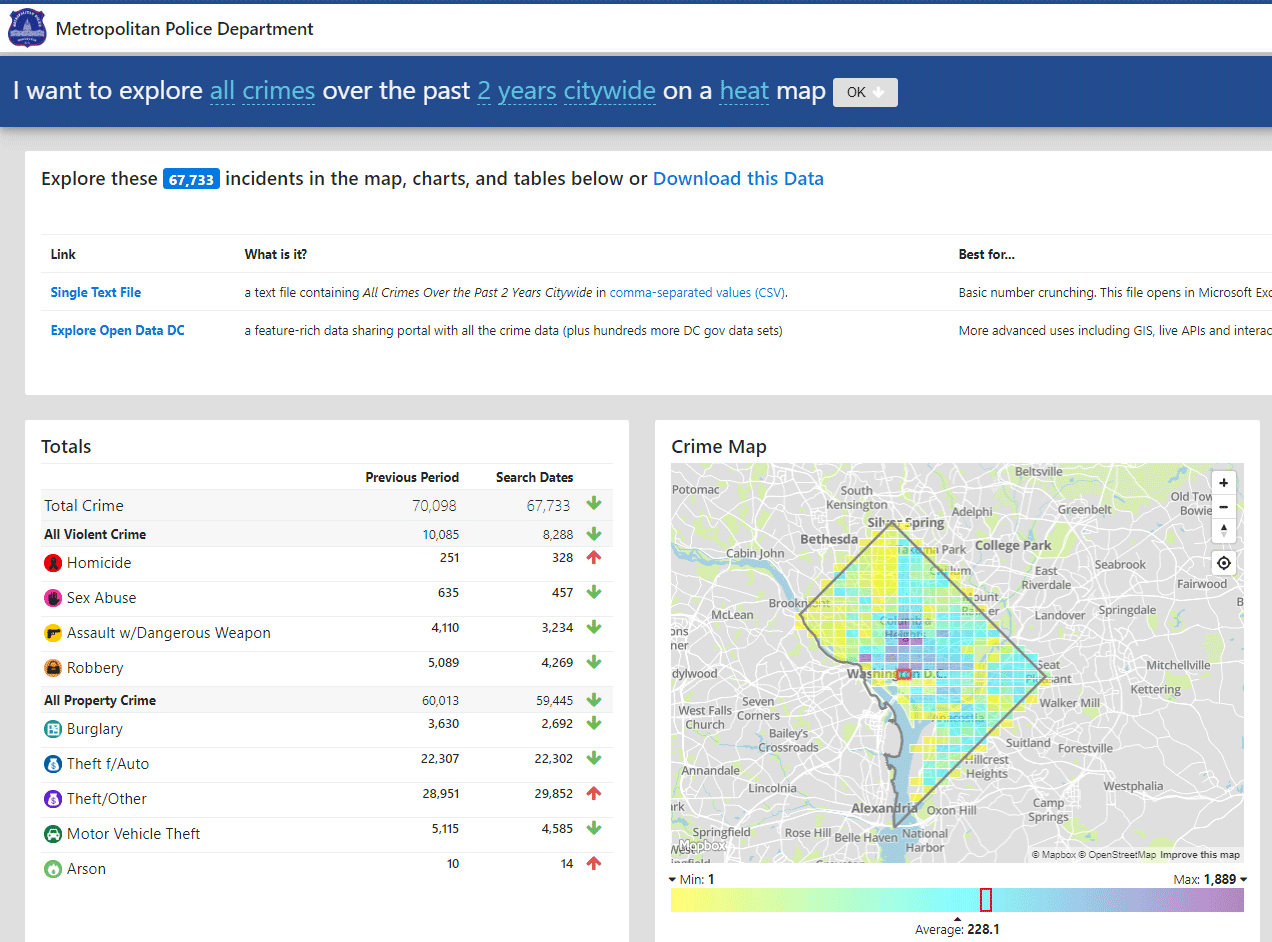
I. Statistiques d’un radar
II. Enquête policière
IV. Le concours de prénoms
III. la commune idéale
1. Quels sont les descripteurs (en-tête de colonne) de cette table de données ?
Statistiques d’un radar
| Date | Horaire | Immatriculation | Pays |
Marque
|
vitesse retenue |
2. Combien d’infractions ont été enregistrées ?
5500
3. Trier les données par ordre chronologique : sélectionner la colonne A puis Données |Tri croissant et Étendre la sélection.
4. Sélectionnez les colonnes A à F et sélectionnez Données I Autofiltre . Que se passe-t-il ?
Apparition d'un menu déroulant pour chaque colonne.
On peut utiliser les autofiltres ou la formule :
=SOMMEPROD(1/NB.SI(D2:D5501;D2:D5501))
5. Combien de valeurs différentes prend le descripteur "Pays" ?
Comprendre la formule : (calculer le nb de valeurs différentes dans une liste)
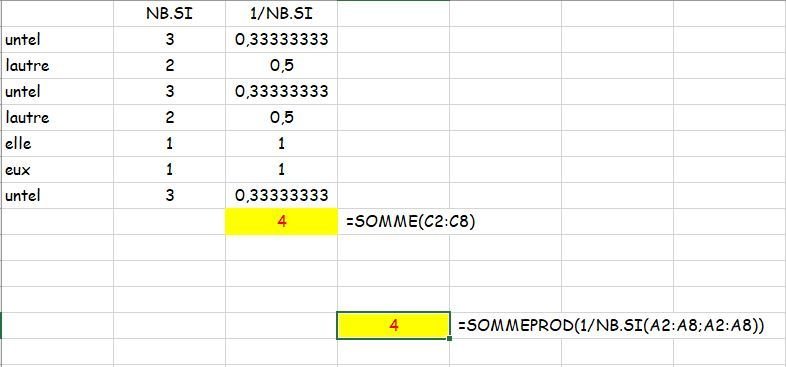
=SOMMEPROD(1/NB.SI(A2:A8; A2:A8)) est équivalent à
=SOMME(1/(NB.SI($A$2:$A$8;$A2));1/(NB.SI($A$2:$A$8;$A3));1/(NB.SI($A$2:$A$8;$A4));1/(NB.SI($A$2:$A$8;$A5));1/(NB.SI($A$2:$A$8;$A6));1/(NB.SI($A$2:$A$8;$A7));1/(NB.SI($A$2:$A$8;$A8)))
13
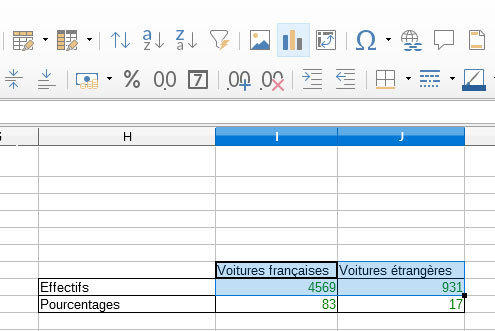
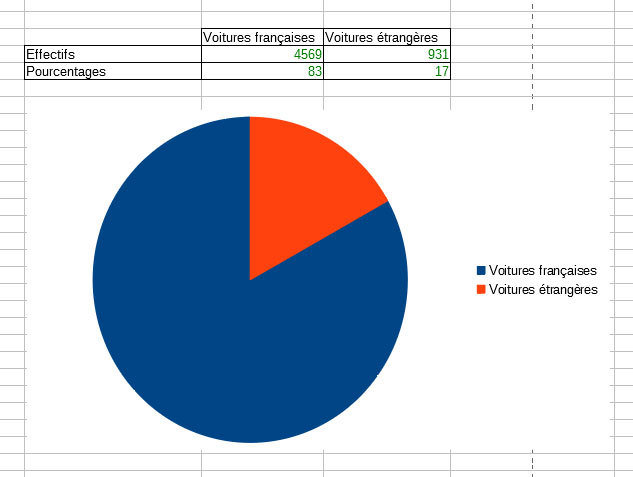
6. Construire le relevé statistique de la répartition entre français et étrangers (ensemble) puis faire un diagramme circulaire. Vous pourrez utiliser la commande NB.SI pour déterminer l’effectif des deux catégories.

=NB.SI(D2:D5501;"France")
=ARRONDI(NB.SI(D2:D5501;"France")/5500*100;0)
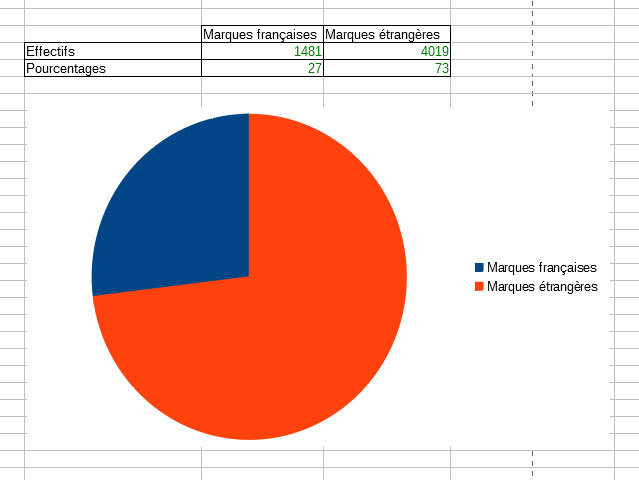
7. Quel est le pourcentage de véhicules de marque française (Peugeot, Citroën et Renault) parmi les véhicules en excès de vitesse.
=NB.SI(E2:E5501;"Peugeot")+NB.SI(E2:E5501;"Renault")+NB.SI(E2:E5501;"Citroën")
8. Quelle est la vitesse maximale relevée ? Combien de véhicules ont été enregistrés à cette vitesse ?

=MAX(F2:F5501)
=NB.SI(F2:F5501;"148")
9. Y a-t-il eu des infractions le 18 mars entre 12h et 13h ?
Si oui, combien ? Vous pourrez utiliser une combinaison de filtres : Données I Plus de filtres I Filtre standard
Sélectionner les colonnes Date et Horaire
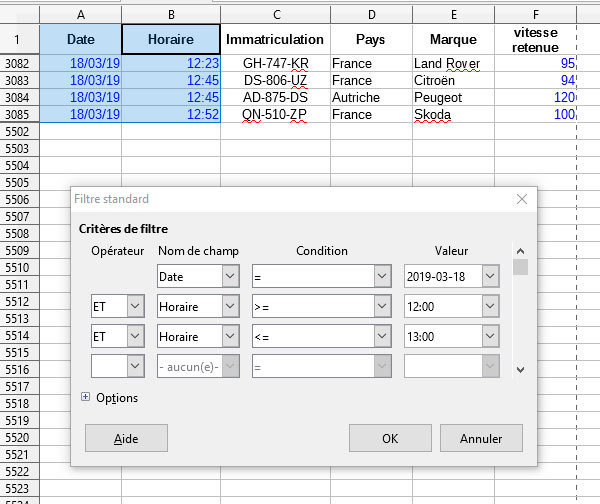
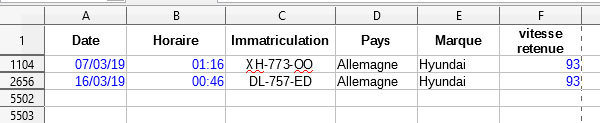
10. Combien de véhicules allemands de marque Hyundai ont été flashés ? (Vous pouvez réinitialiser le filtre : Données I Plus de filtres I Réinitialiser le filtre)
11. Quel est le pourcentage de véhicules ayant commis un excès de vitesse supérieur à 30 km/h ?
Environ 5,5%
=ARRONDI(NB.SI(F2:F5501;">120")/5500*100;1)
12. Construire le diagramme en barres des infractions selon les tranches suivantes (vous pourrez utiliser la commande SOMMEPROD ou la fonction NB.SI.ENS)
La fonction NB.SI.ENS permet de compter le nombre de valeur vérifiant plusieurs critères
=NB.SI.ENS(F2:F5501;">90";F2:F5501;"<96")

=ARRONDI(NB.SI.ENS(F2:F5501;">90";F2:F5501;"<96")/55;1)
ActivitéS : L'impact des données sur l'environnement
les DATA CENTERS (DOC 3 DIDIER - Doc 4 bordas)
Question 1 : Intérêts du Cloud
- Proposer un espace de stockage de données sur Internet. Ces données sont alors accessibles depuis n’importe quel ordinateur, dans le monde. L’utilisateur n’a plus besoin de CD, clé USB ou de disque dur, supports qui peuvent être parfois perdus, oubliés ou simplement défectueux. L'utilisateur peut synchroniser ses données entre ses différents appareils...
- Sûreté : les informations sont répliquées dans plusieurs endroits pour ne pas risquer la perte des données en cas de panne d’une machine ou d’un disque.
- Sécurité : Protection contre les intrusions : les data centers savent mieux se protéger contre les hackers que nous...
Inconvénients du Cloud
- La forte consommation électrique pour le fonctionnement, mais également pour le refroidissement des serveurs, a un impact énergétique important. Le secteur du numérique consomme environ 10% de l'électricité mondiale
- Pollution causée par la fabrication des serveurs et des objets connectés
- Pillage des ressources naturelles : métaux rares...
Solutions ? : Les chaudières numériques
Question 2 : Taux de disponibilité > 99,6%
Combien de minutes ? ...
Question 3 : régler le problème de l'énergie n'est pas suffisant...
Pollution et ressources limitées
Smartphone 100 g = 40 kg de matière
Question 4 : Individuellement que faire ?
Ne pas stocker inutilement des mails, limiter sa consommation de streaming, ne pas photographier n'importe quoi...
opérations sur une table :
-
Rechercher une information précise.
-
Trier la collection sur une ou plusieurs propriétés.
-
Filtrer la collection selon un ou plusieurs tests sur les valeurs des descripteurs.
-
Effectuer des calculs.
-
Mettre en forme les informations produites pour une visualisation par les utilisateurs.
Traitement des données structurées

crédit image
Traitement de données structurées avec Python et Pandas
La table de données correspondant une collection de personnes est enregistrée dans le fichier table_ident.csv.
Éditeur utilisé : Spyder (Distribution Anaconda)

Sur le bureau créer un dossier act_pandas.
-
Télécharger le fichier table_ident et le copier dans le dossier act_panda.
Ouvrir Spyder et enregistrer le fichier ouvert par défaut sous main.py dans le dossier act_panda.
import pandas
# importe le module pandas
ident = pandas.read_csv("table_ident.csv")
# lecture du fichier et stockage de son contenu dans la variable ident 
Pandas a ajouté une colonne avec des index pour chaque ligne de la table.
Lecture des données d'une table enregistrée dans un fichier au format CSV
info pratique : Taper le code dans l'éditeur de Spyder puis l'exécuter à l'aide du bouton triangle vert dans la barre d'outils. Utiliser la console IPython pour les entrées.
Sélectionner des données dans une table à l'aide de l'instruction loc :
import pandas
ident = pandas.read_csv("table_ident.csv")
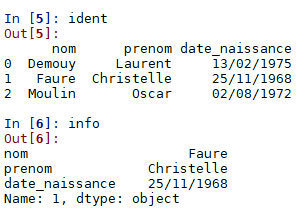
info = ident.loc[1,'date_naissance']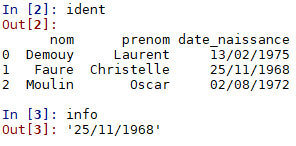
Sélectionner une donnée :
import pandas
ident = pandas.read_csv("table_ident.csv")
info = ident.loc[:,'prenom']Sélectionner une colonne (toutes les valeurs d'un descripteur):
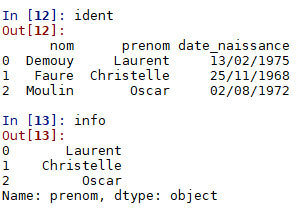
import pandas
ident = pandas.read_csv("table_ident.csv")
info = ident.loc[1,:]Sélectionner une ligne (toutes les données d'un objet de la collection):
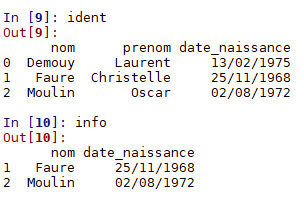
import pandas
ident = pandas.read_csv("table_ident.csv")
info = ident.loc[[1,2],['nom','date_naissance']]Sélectionner une plage de valeurs :
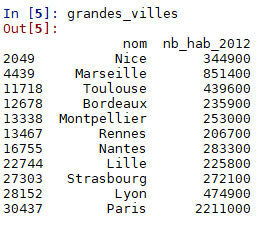
import pandas
info_villes = pandas.read_csv("villes_virgule.csv")
grandes_villes = info_villes.loc[info_villes["nb_hab_2012"]>200000,["nom","nb_hab_2012"]]Filtrer la collection selon un test
-
Télécharger le fichier : villes_virgule.csv source : informatique au lycée
Le copier dans le dossier act_panda.
Utiliser l'explorateur de variables...
Sélectionner toutes les villes dont la population en 2012 était supérieure à 200 000 et afficher leur nom et leur population en 2012
import pandas
info_villes = pandas.read_csv("villes_virgule.csv")
villes_basses=info_villes.loc[(info_villes["alt_max"]<50) & (info_villes["dens"]<10),["nom","dens","alt_max"]]
Filtrer la collection selon plusieurs tests avec & (et) et | (ou)
Sélectionner toutes les villes dont l'altitude maximale est inférieure à 50 et dont la densité de population est inférieure à 10 et afficher leur nom, leur densité de population et leur altitude maximale

Effectuer des calculs sur les données d'une table à l'aide de la méthode mean() :
mean() renvoie la moyenne des valeurs prises par un descripteur :
import pandas
ident = pandas.read_csv("table_ident.csv")
moyenne_hab_2012=info_villes.loc[:,"nb_hab_2012"].mean()
Effectuer des calculs sur certaines données d'une table à l'aide de la méthode mean() :
import pandas
ident = pandas.read_csv("table_ident.csv")
moyenne_hab_2010=info_villes.loc[info_villes["alt_max"]<50,"nb_hab_2010"].mean()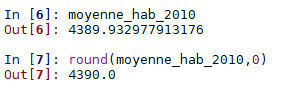
Trier les données d'une table en fonction des valeurs d'un descripteur à l'aide de la méthode sort_values() :
import pandas
ident = pandas.read_csv("table_ident.csv")
tri_pop_2012=info_villes.sort_values(by=["nb_hab_2012"])
Passer de l'ordre croissant à décroissant :
import pandas
ident = pandas.read_csv("table_ident.csv")
tri_pop_2012=info_villes.sort_values(by=["nb_hab_2012"],ascending=False)Activité de programmation :
Écrire un script qui affiche le nom de la ville ayant la population la plus nombreuse en 2012 et dont la densité est inférieure à 500. A la suite du nom de la ville, afficher la population en 2012 ainsi que la densité.