{Les données structurées}
SNT Thème 1
{Comment manipuler les données ?}
{Repères historiques}
1. Je suis l'entreprise ayant inventé le premier disque dur. Je suis...
{Questions flash}
2. Je suis l’inventeur d’un système d’automatisation des métiers à tisser. Je suis...
{Questions flash}
3. Je suis un projet mené par un grand pays afin de rendre les données gouvernementales plus transparentes. Je suis...
{Questions flash}
4. Je suis le système qui remplace progressivement les disques durs. Je suis...
{Questions flash}
1. IBM
2. Basile Bouchon
3. L'Open Government Initiative
4. La mémoire flash
{Réponses}
Act 2 p 9 : Que sont les données personnelles et les métadonnées ?
Questions :
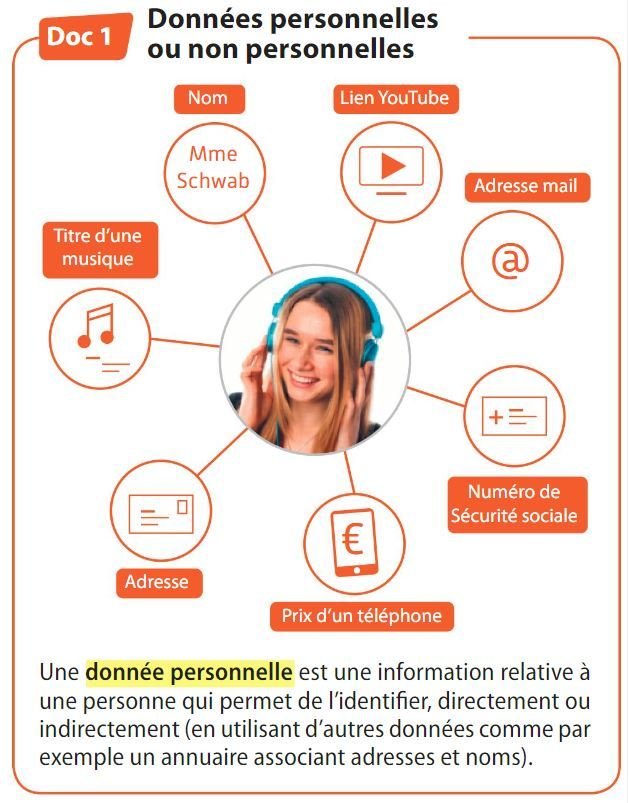
- Identifier les données personnelles du Doc. 1.
Nom, adresse, adresse mail, numéro de Sécurité sociale
2. Donner un exemple d’identification « indirecte ».
Le numéro de Sécurité sociale permet de retrouver quelqu'un par le biais du fichier de la sécurité sociale.
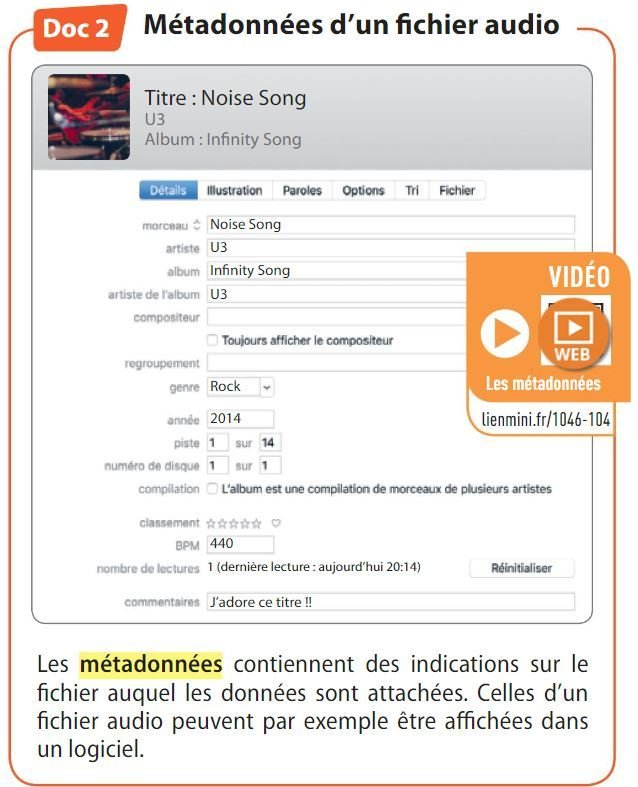
3. Lister trois métadonnées qui ne sont pas liées à des données personnelles dans le Doc. 2.
Rock, 2014, piste 1
Questions :
4. Expliquer à quoi servent les métadonnées.
Les métadonnées apportent des informations complémentaires relatives à un fichier qui sont utiles pour exploiter les données qu'il contient : indexation, recherche, tri...
Questions :
5. Répondre à la question posée dans le titre de l'activité.
Une donnée personnelle est une donnée relative à une personne qui permet de l'identifier. Les métadonnées fournissent des informations sur des fichiers pour faciliter l'exploitation des données qu'ils contiennent.
{Les métadonnées : pourquoi est-ce important ?}
1. Organisation et classification
Facilitent le tri et la recherche d'informations dans de vastes ensembles de données
Permettent de catégoriser les données selon divers critères (date, type, auteur, etc.)
2. Compréhension du contexte
Fournissent des informations sur l'origine et l'historique des données
Aident à interpréter correctement les données brutes
3. Gestion de la qualité des données
Permettent de suivre la provenance et la fiabilité des données
Facilitent la détection d'erreurs ou d'incohérences...
{Les métadonnées : pourquoi est-ce important ?}
Act 3 p 10 : Comment structurer les données ?
Compléments :
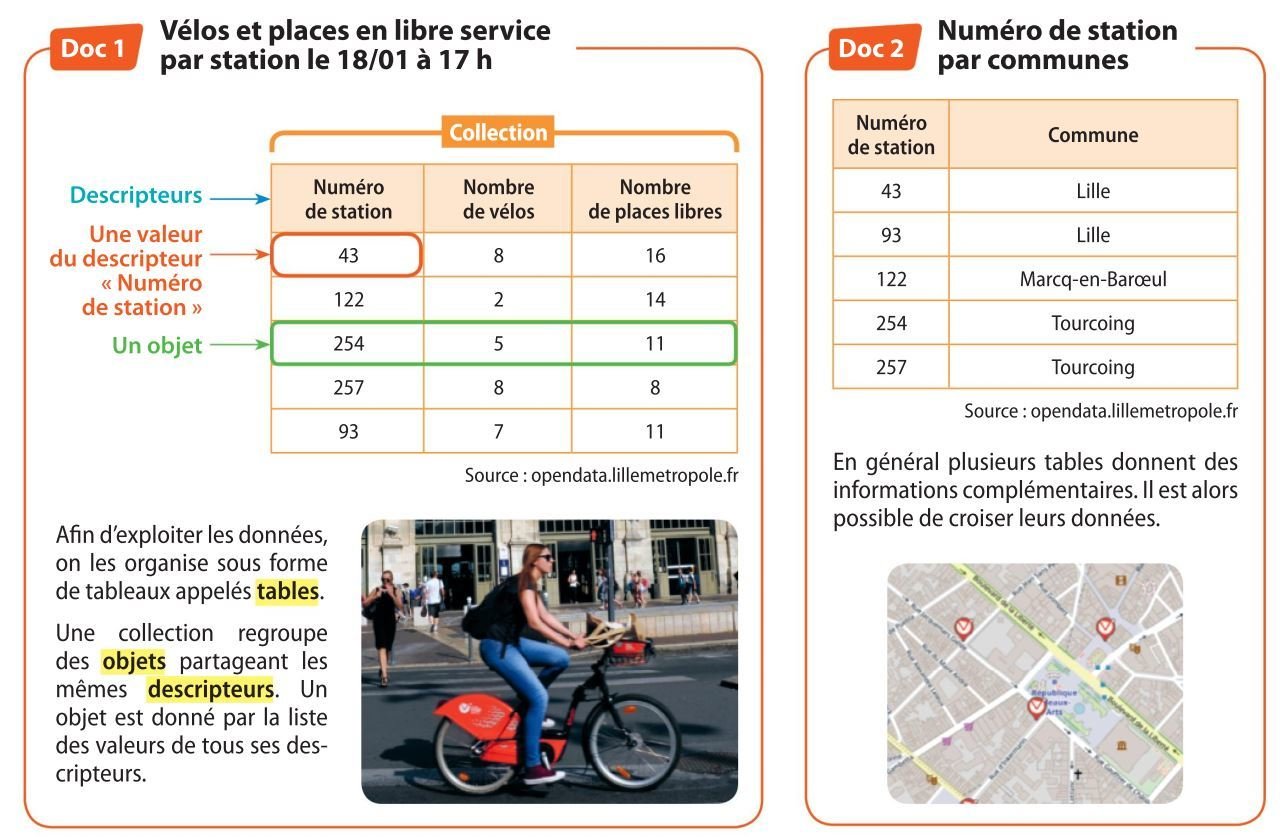
Dans une base de données relationnelle, une clé primaire est le descripteur qui permet d'identifier de manière unique un enregistrement (objet de la base) dans une table.
Exemple :
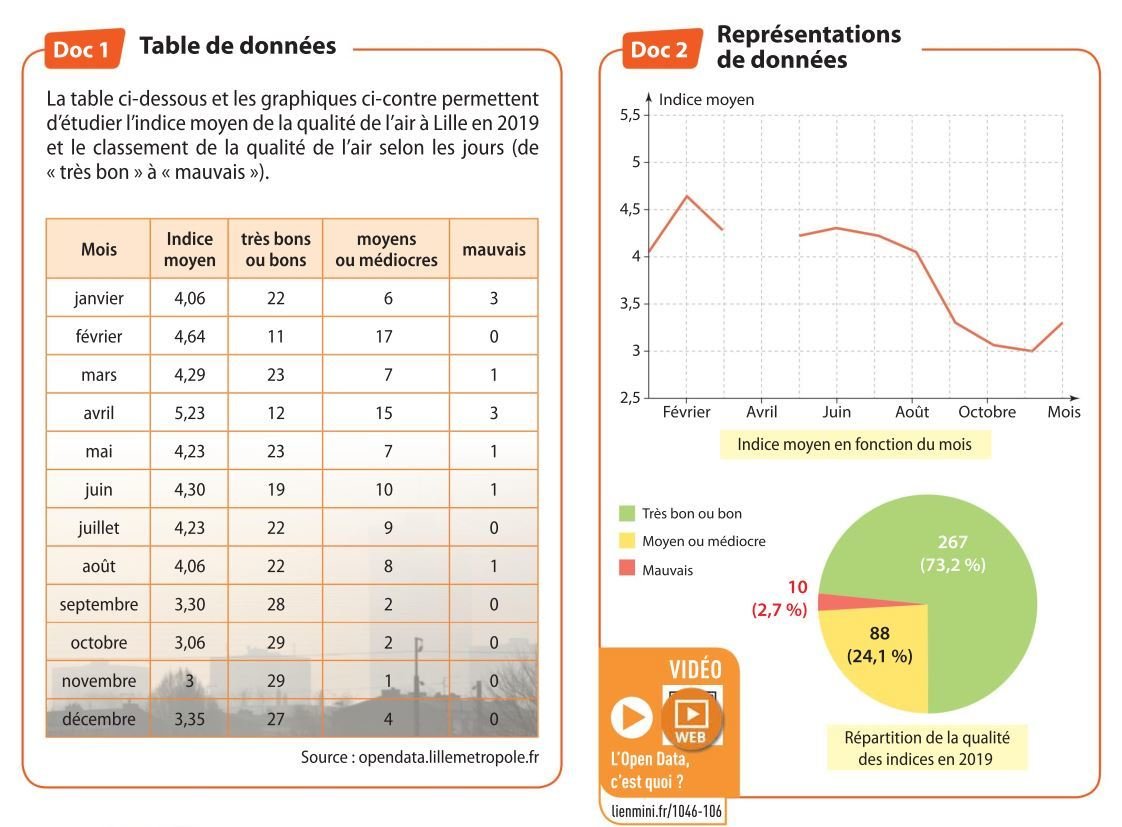
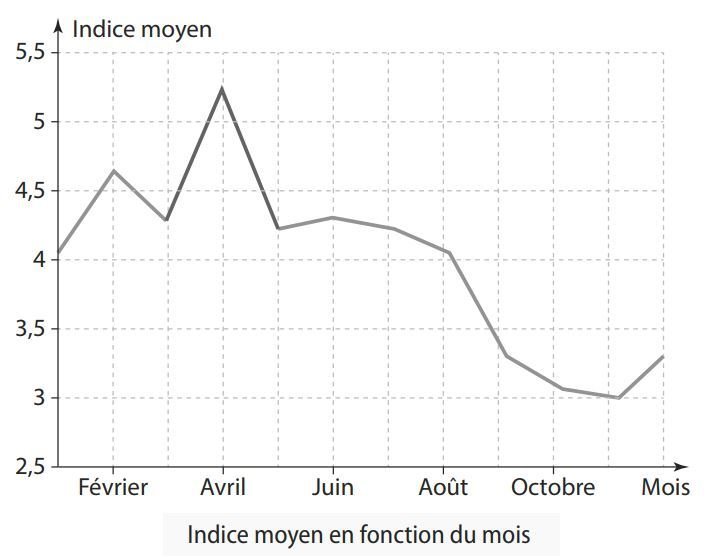
Dans l'activité 3, quel descripteur joue le rôle de clé primaire ?
Le numéro de station.
Compléments :
Formats utilisés pour stocker et échanger des données structurées :
Produit, Catégorie, Quantité, Prix_Unitaire
Laptop, Électronique, 5, 1200
Télévision, Électronique, 3, 800
Chaise, Mobilier, 10, 50
Table, Mobilier, 7, 150
CSV
[
{
"Produit": "Laptop",
"Catégorie": "Électronique",
"Quantité": 5,
"Prix_Unitaire": 1200
},
{
"Produit": "Télévision",
"Catégorie": "Électronique",
"Quantité": 3,
"Prix_Unitaire": 800
},
{
"Produit": "Chaise",
"Catégorie": "Mobilier",
"Quantité": 10,
"Prix_Unitaire": 50
},
{
"Produit": "Table",
"Catégorie": "Mobilier",
"Quantité": 7,
"Prix_Unitaire": 150
}
]
JSON
<Produits>
<Produit>
<Produit>Laptop</Produit>
<Catégorie>Électronique</Catégorie>
<Quantité>5</Quantité>
<Prix_Unitaire>1200</Prix_Unitaire>
</Produit>
<Produit>
<Produit>Télévision</Produit>
<Catégorie>Électronique</Catégorie>
<Quantité>3</Quantité>
<Prix_Unitaire>800</Prix_Unitaire>
</Produit>
<Produit>
<Produit>Chaise</Produit>
<Catégorie>Mobilier</Catégorie>
<Quantité>10</Quantité>
<Prix_Unitaire>50</Prix_Unitaire>
</Produit>
<Produit>
<Produit>Table</Produit>
<Catégorie>Mobilier</Catégorie>
<Quantité>7</Quantité>
<Prix_Unitaire>150</Prix_Unitaire>
</Produit>
</Produits>
XML
Act 4 p 11 : Quels sont les enjeux et les risques du Big Data ?

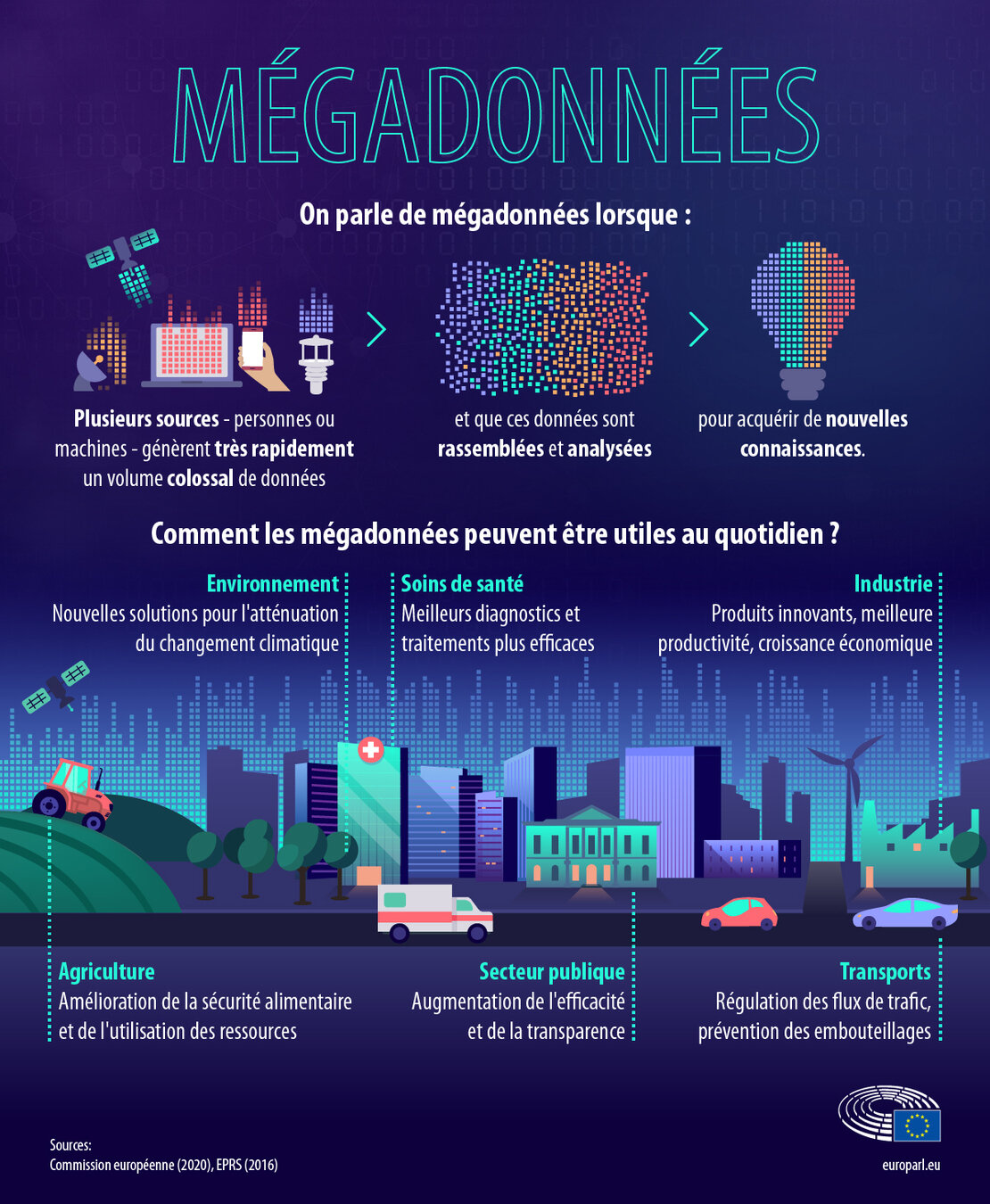

Un autre enjeu majeur est la sécurisation des données et particulièrement la protection des données personnelles. Celle-ci est cruciale notamment pour :
- Préserver la vie privée des individus
- Prévenir les usages abusifs (discrimination, manipulation, surveillance de masse...)
Avec le Big Data, les entreprises et les scientifiques peuvent analyser toutes ces informations pour découvrir des tendances, des comportements, faire des prédictions, optimiser des processus, prendre des décisions...
(2'38'')
- Atteinte à la vie privée :
- Collecte excessive de données personnelles
- Utilisation des données à des fins non autorisées
- Risque de ré-identification des individus à partir de données anonymisées
- Sécurité des données :
- Vulnérabilité aux piratages et aux fuites de données
- Risque de vol d'identité
- Discrimination :
- Utilisation d'algorithmes biaisés pouvant conduire à des décisions discriminatoires
- Profilage excessif des individus
- Surveillance de masse :
- Possibilité pour les gouvernements ou les entreprises de suivre les activités des citoyens
- Risque pour les libertés individuelles
- Manipulation :
- Utilisation des données pour influencer les comportements (ex : publicité ciblée, campagnes politiques)
- Création de bulles de filtres limitant l'accès à des informations diverses
- Dépendance technologique :
- Risque de perte de compétences humaines au profit des systèmes automatisés
- Vulnérabilité en cas de défaillance des systèmes Big Data
- Fracture numérique :
- Inégalités entre ceux qui ont accès aux bénéfices du Big Data et ceux qui en sont exclus
- Qualité des données :
- Risque de prendre des décisions basées sur des données incorrectes ou mal interprétées
- Concentration du pouvoir :
- Accumulation de données et de connaissances par un petit nombre d'acteurs
- Enjeux éthiques :
- Utilisation des données pour des fins contraires à l'éthique
Contre
Pour
- Amélioration des soins de santé
- Diagnostics plus précis et rapides
- Traitements personnalisés basés sur le profil génétique et l'historique médical
- Meilleure prévention des maladies grâce à l'analyse des facteurs de risque
- Mobilité facilitée
- Applications de navigation en temps réel (trafic, transports en commun)
- Optimisation des itinéraires et réduction des temps de trajet
- Services de covoiturage et de partage de véhicules plus efficaces
- Services personnalisés
- Recommandations plus pertinentes (films, musique, produits)
- Publicités ciblées qui correspondent davantage aux intérêts personnels
- Expériences utilisateur adaptées sur les sites web et applications
- Prévention et de gestion des ressources
- Prévention des famines
- Meilleure anticipation des phénomènes climatiques
- Prévention des risques volcaniques et sismiques
- Amélioration de la sécurité
- Détection plus efficace des fraudes bancaires
- Systèmes de surveillance plus performants pour la sécurité publique
- Prévention des cyberattaques
Complément : l'IA
C’est un système informatique alimenté par le Big Data, qui vise à être capable de reproduire certaines compétences de l’intelligence humaine (la reconnaissance de la parole, la prise de décision, et l'apprentissage à partir de données...). À l’heure actuelle, si les ordinateurs ont des capacités de calculs bien supérieures à celles du cerveau humain, on ne peut pas encore parler d’intelligence véritable.
Pour l’essentiel, les compétences de l’IA appartiennent au domaine des analyses mathématiques et des probabilités. C’est ce qui lui donne la capacité de faire des « prédictions ».
(3'32'')
Act 5 p 12 : Comment exploiter des données ?

L'Open Data à la loupe
Act 6 p 13 : Qu’est-ce que le cloud ?
Ce qu'il faut savoir sur le cloud

TP Statistiques d’un radar
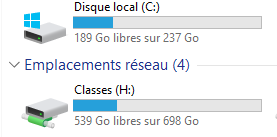
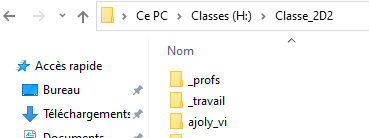
- Sur le réseau pédagogique, dans le répertoire de votre classe, rendez-vous dans le dossier _travail
Tuto vidéo : Utiliser les filtres dans LibreOffice Calc
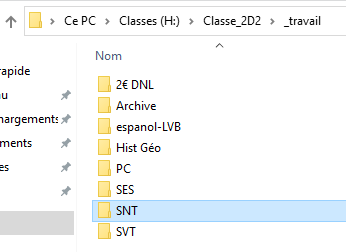
- Dans le dossier SNT située dans le dossier _travail, copier le fichier stats_radar_mars_2019.ods.
- Coller ce fichier dans le dossier SNT situé dans le dossier à votre nom.
Le fichier stats_radar_mars_2019.ods contient les statistiques des relevés des excès de vitesse
enregistrés par un radar fixe au cours du mois de mars 2019 sur une route nationale dont la vitesse maximale
autorisée est de 90 km/h.
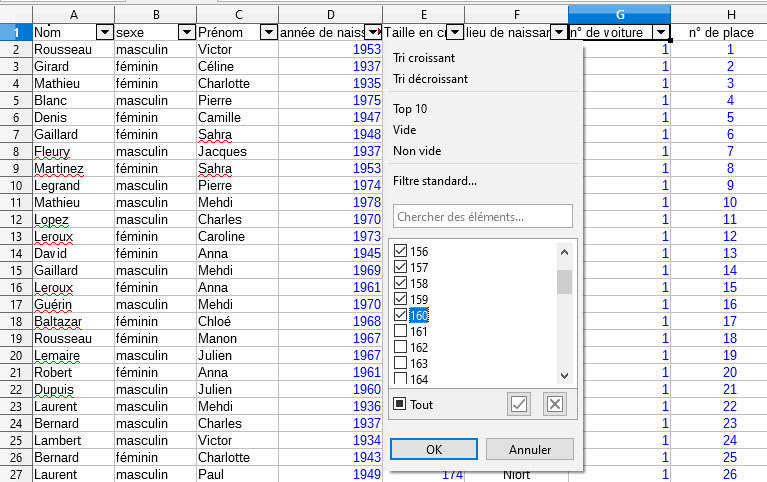
1. Quels sont les descripteurs (en-tête de colonne) de cette table de données ?
| Date | Horaire | Immatriculation | Pays |
Marque |
vitesse retenue |
2. Combien d’infractions ont été enregistrées ?
5500
3. Trier les données par ordre chronologique : sélectionner la colonne A puis Données |Tri croissant et Étendre la sélection.
4. Sélectionnez les colonnes A à F et sélectionnez Données I Autofiltre . Que se passe-t-il ?
Apparition d'un menu déroulant pour chaque colonne.
5. Combien de valeurs différentes prend le descripteur "Pays" ?
Avec l'AutoFiltre
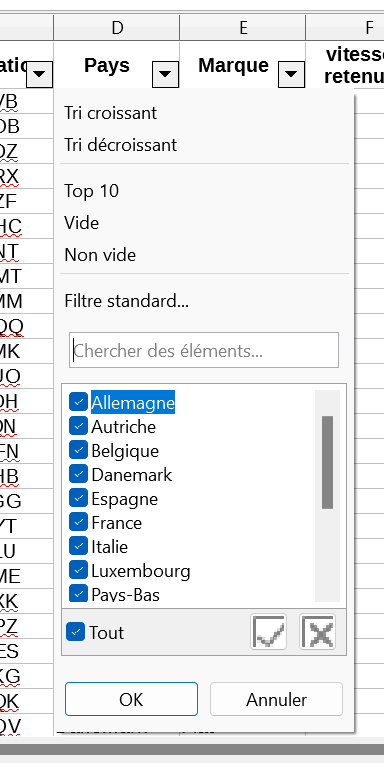
13
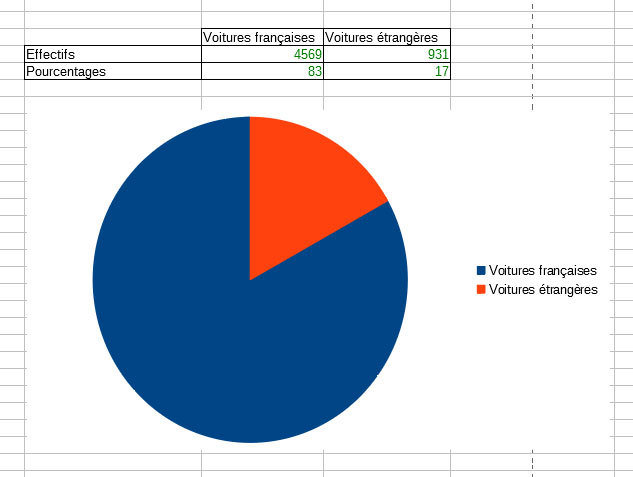
6. Construire le relevé statistique de la répartition entre français et étrangers (ensemble) puis faire un diagramme circulaire. Vous pourrez utiliser la commande NB.SI pour déterminer l’effectif des deux catégories.
NB.SI
permet de compter le nombre de cellules dans une plage donnée qui répondent à un critère spécifique.
Exemples d'utilisation :
Compter les cellules supérieures à 10 dans la plage A1:A10.
=NB.SI(A1:A10;">10")(effectifs + pourcentages)

=ARRONDI(NB.SI(D2:D5501;"France")/5500*100;0)=NB.SI(D2:D5501;"France")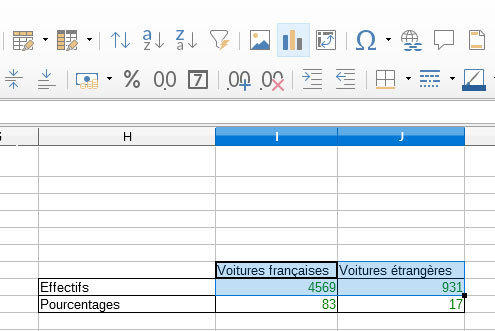
7. Quelle est la vitesse maximale relevée ? Combien de véhicules ont été enregistrés à cette vitesse ?

=NB.SI(F2:F5501;"148")=MAX(F2:F5501)8. Y a-t-il eu des infractions le 18 mars entre 12h et 13h ?
Si oui, combien ?
Vous pourrez utiliser une combinaison de filtres :
Données I Plus de filtres I Filtre standard
Sélectionner les colonnes Date et Horaire
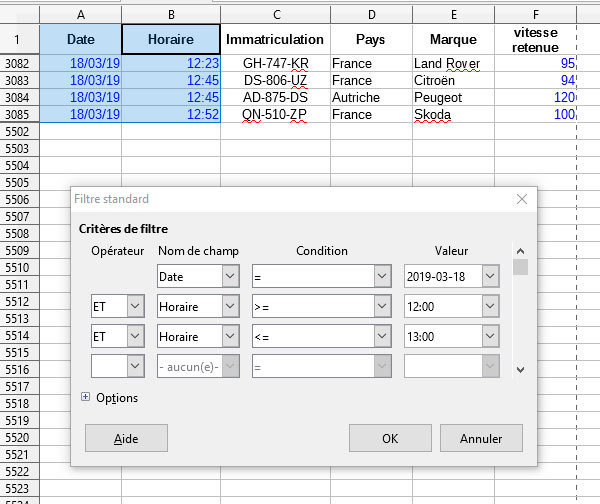
9. Combien de véhicules allemands de marque Hyundai ont été flashés ? (Vous pouvez réinitialiser le filtre : Données I Plus de filtres I Réinitialiser le filtre)
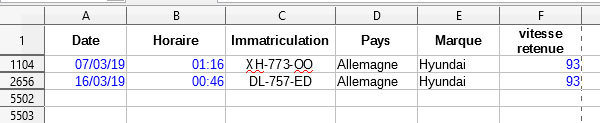
10. Quel est le pourcentage de véhicules ayant commis un excès de vitesse supérieur à 30 km/h ?
Environ 5,5%
=ARRONDI(NB.SI(F2:F5501;">120")/5500*100;1)Enquête policière
Nous allons mener une enquête policière. L’inspecteur Labavure est chargé de retrouver un suspect suite à une plainte d’un employé de la SNCF.
L’incident s’est produit le 6 avril 2019, dans un train Paris-Bordeaux. J’assurai mon service à la voiture-bar n°4 lorsqu’une petite dame (moins d’un mètre soixante pour sûr) s’est présentée au bar. Cette personne d’un certain âge, environ la soixantaine, m’a commandé un thé noir, avec un fort accent du Sud de la France. Je lui ai répondu que je n’avais pas cette sorte de thé. Visiblement agacée, elle s’est mise à m’insulter et à commencé à vouloir me frapper avec son parapluie. Heureusement que le jeune homme qui l’accompagnait (son petit-fils j’imagine, car il l’a appelé « Mémé ») l’a arrêté et l’a évacué vers l’arrière du train.
L’inspecteur Labavure a eu accès au fichier clients de ce trajet et l’a croisé avec le fichier TES (Titres Électroniques Sécurisés : fichier national des cartes nationales d’identité et passeports). Il en a extrait le fichier sncf_listing.ods. À l’aide des informations de la déposition, aidez l’inspecteur Labavure à dresser sa liste de suspects.
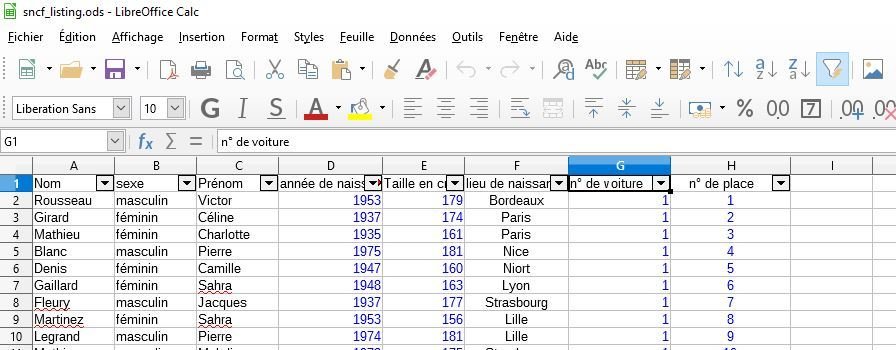
- Collez ce fichier dans le dossier SNT situé dans le dossier à votre nom.
- Dans le dossier SNT située dans le dossier _travail, copier le fichier sncf_listing.ods.
Activer l'AutoFiltre s'il n'est pas activé par défaut.
Vous pouvez ainsi filtrer les données selon leur valeur pour un ou plusieurs descripteurs.
Il faut repérer les indices, par exemple il est fait mention d'une "petite dame (moins d’un mètre soixante pour sûr)"