Context-Aware Personal Information Retrieval From Multiple Social Networks
Presented by: Sophie Le Page and Theodore Morin
Authors: Xiaogang Han, Wei Wei, Chunyan Miao, Jian-Ping Mei, and Hengjie Song
Social Network Services
-
People use SNSs to collect and share previously-seen information, such as using:
- Microblogging (Twitter)
- Social networks (Facebook)
- Social bookmarking (Delicious)
- Referring to and integrating previously-seen information is common
-
58-81% of web page access are re-visits, such as:
- Replying to questions on question answering websites
- Replying to posts on SNSs
Problem
- How do we automatically retrieve the most context-relevant previously-seen web information without user intervention
For Example:
- A film lover has reviewed a movie on Facebook
- A Friend posts about the movie on Twitter
- The film lover could provide comments about the movie by retrieving the review, but may have forgotten it
Personal Web Information
- PWIs are used to specify previously-seen information on multiple SNSs
- It is challenging to make connections between the user’s context and their PWIs when the PWIs spread across multiple SNSs
Problem Statement
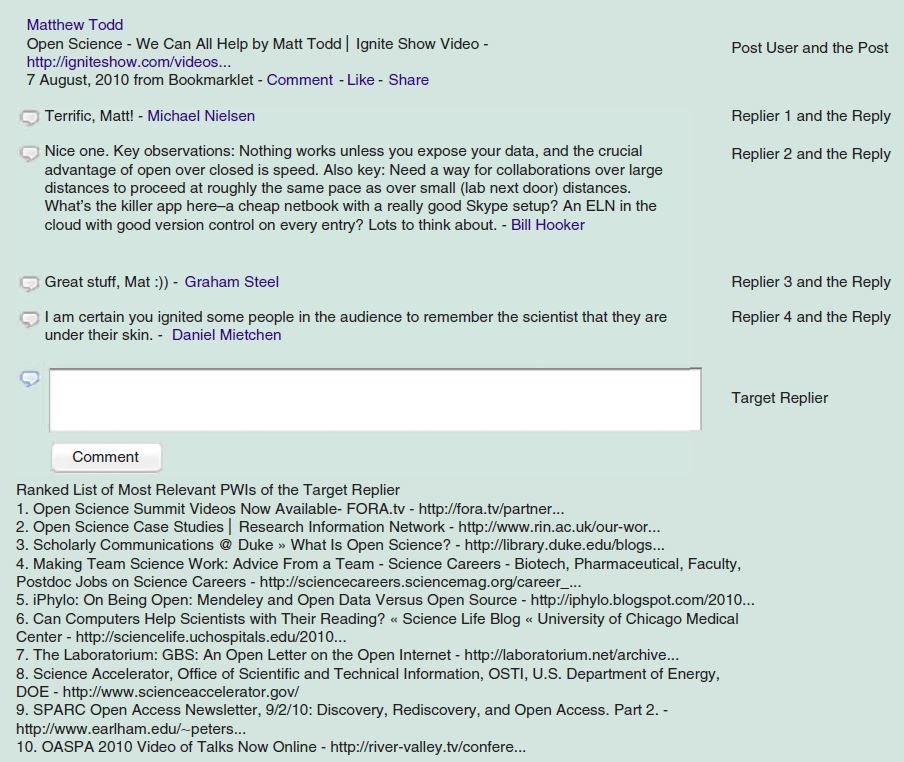
- Given a session and the targeting replier, generate a query to retrieve the most relevant PWIs from the target's document collection
Problem Statement Example
Solution
Propose the Context-Aware Personal Information Retrieval (CPIR) algorithm
- Builds a query by capturing the user's information need
- Retrieves the user's most relevant PWIs
Challenges:
- Posts in the conversations are short and ambiguous
- Documents in SNSs are noisy and complex
Context-Aware Personal Information Retrieval Algorithm
Key notations:
-
A Session (S) is an online conversation with:
- An initial post p
- A set of replies R
- Represented by the Vector Space Model
- Each term is weighted by its tf-idf score
Context-Aware Personal Information Retrieval Algorithm (continued)
- Query formulation and expansion
- PWIs ranking


Query Formulation and Expansion
Query Q is built by:
- Considering both replies and PWIs of all participating users
- Using PWIs of the creator and repliers to obtain richer information
Initial Post and Replies
- First, the initial p is treated as the basic query
-
Next, combine the replies with p
- Replies are weighted according to their similarities with p
- The expanded query is calculated as follows:
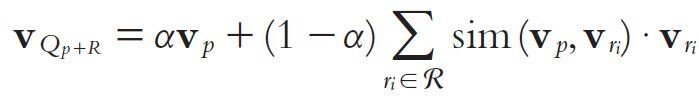
Methods, Techniques and External Sources
KL-divergence method
- Obtains better results than vector space based measures
Smoothing techniques
- Takes the entire vocabulary into consideration to compare two distributions
WordNet external source
- Expands the documents before calculating similiarities
PWIs of the creator and existing repliers
- Consider PWIs of the creator and existing repliers to further exand the query
- Only the top k most relevant PWIs are selected
- The expanded query can be represented as:
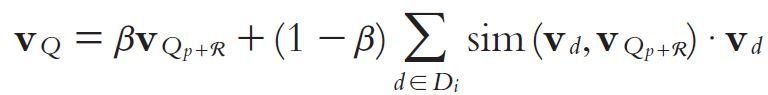
PWIs Ranking
Importance Ranking
- User in the same session S share common interests (at least the topic S)
- Employ a Markov random walk model
- Rank the PWIs of a user u on implicit relationships between the web information of all users in S
- Find a subset of u's PWIs that are most relevant to the topic of the session
Final Ranking
-
Use a linear combination of the two previously mentioned ranking scores:
- Similarity between the expanded query Q and each document
- Importance of the document in the collection of PWIs
- Obtain the final score for each document:
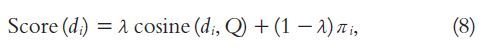
- The top ranked PWIs are selected as the recommendation results to the targeting replier

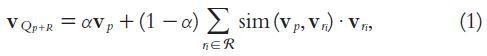
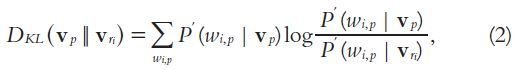
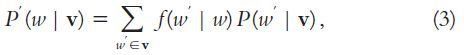
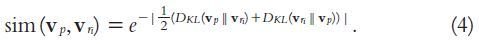
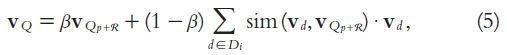
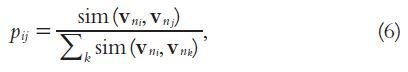

Data Description
-
FriendFeed dataset
- collected by monitoring the data stream on FriendFeed from 01/08/2010 to 30/09/2010 (two months)
-
From these conversations select
- Post-reply pairs written in English
- Repliers that have at least 50 PWIs

Manual Annotation
To construct manual annotation results:
-
Randomly sample 105 post-reply pairs
- replies are posted by 73 unique users
- each user has ~316 PWIs
- Two volunteers manually labeled 23,046 PWIs of the repliers as relevant or irrelevant
- Tokenization and part-of speech tagging are performed to eliminate noisy terms
- Stop words are removed and terms are stemmed
Data Analysis
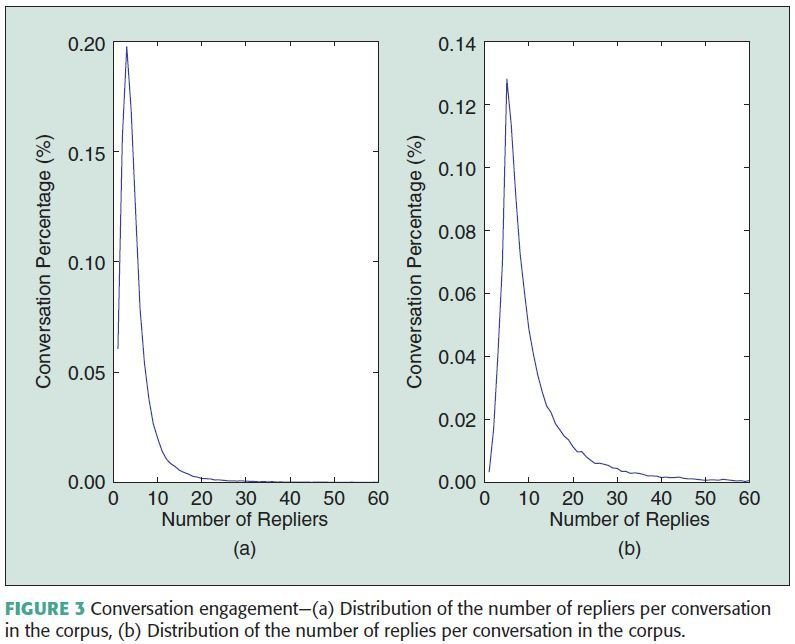
- 98% of conversations have at least three replies
- 78% of conversations have at least three unique repliers
- Confirms feasibility of using the conversations to model task environment to receieve past information
Data Analysis (continued)
-
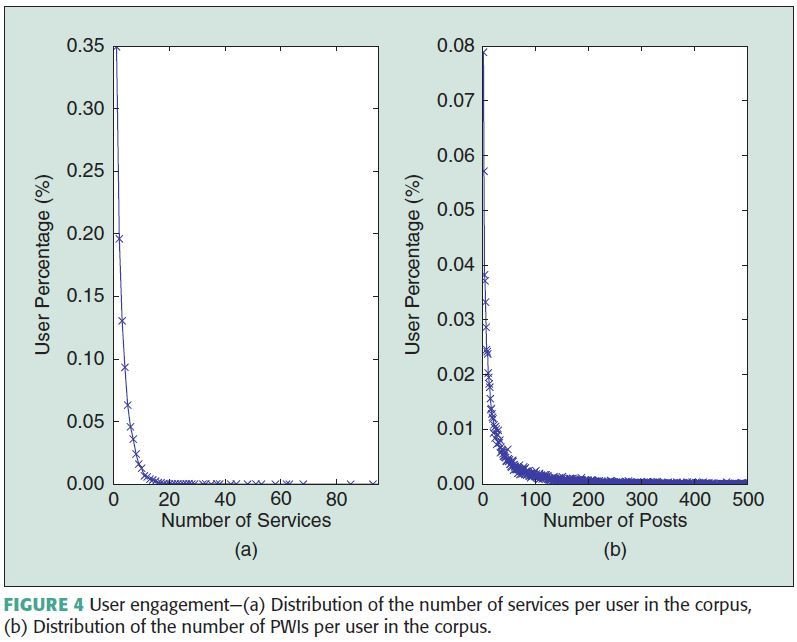
65% of users use at least two services
- Confirms documents are extracted from diverse information
-
63% of users posed more than 10 PWIs
- Motivation to utilize PWIs of users to expand query and improve retrieval performance
Retrieval Performance
-
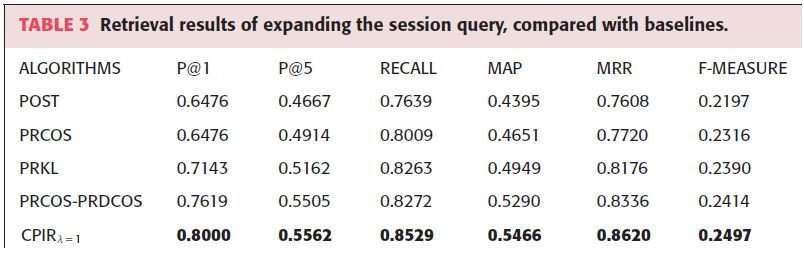
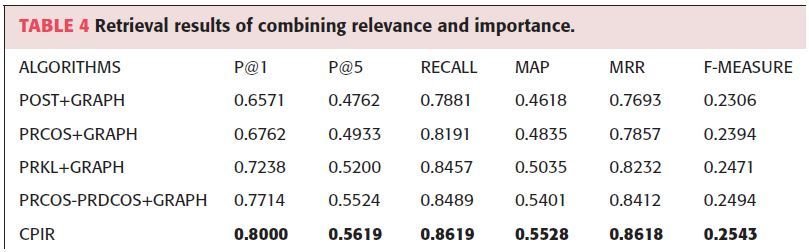
CPIR λ=1 achieves improvement over baseline methods
- Expanding the initial query with replies in the conversation enhanced context cues
- Adding PWIs further captured the content information
- CPIR graph-based ranking algorithm further improves performance
Parameter Settings
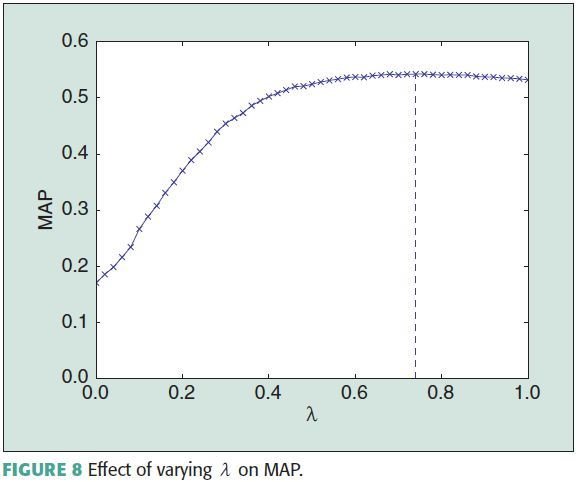
- Optimal parameter obtained by fine tuning
- Most important parameter λ controls how to combine the ranking scores from the random walk model

Conclusions and Future Work
Conclusion
- CPIR significantly outperforms baseline methods
Future Work
- Replace importance ranking algorithm with clustering-based techniques
- Take document recency as a factor in document ranking