FitLaM - Finetuned Language Models
- A Method of Computer Vision-like Transfer Learning for NLP Applications
- Technique for Fine-Tuning a Language Model for any NLP Tasks
CNNs and Transfer Learning
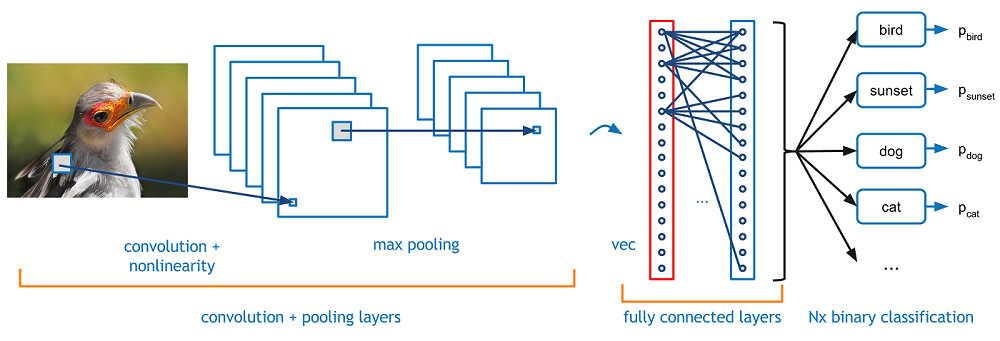
Transfer Learning in NLP
- Models in NLP have to trained from scratch
- Fine-Tuning pre-trained Word Embeddings
- Hyper-Columns
FitLaM Transfer Learning
-
The method should be able
to leverage large amounts of available data;
-
it should utilize a task, which can be optimized independently, leading to further downstream improvements;
-
it should rely on a single model that can be used as-is for most NLP tasks;
-
discriminative fine-tuning, that fine-tunes lower layers to a lesser extent than higher layers in order to retain
the knowledge acquired through language modeling
-
Backprop Through Time for Text Classification
Method
- Language Modelling using AWD-LSTM
- Target Task LM Fine-Tuning
- Gradual Unfreezing
- Cosine Annealing
- Reverse Annealing
- Classifier Fine-Tuning
- Concat Pooling
- Discriminative Fine-Tuning
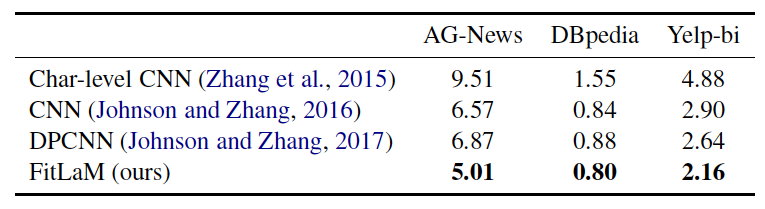
Results

My two cents
- We have to redefine TL for NLP
- We should not draw parallels between NLP and CV TL
- Apply to tasks other than classification
- Reduction in Fine-Tuning and perform Ablation Studies