Optimising Deep Learning for Training and Inference
Soham Chatterjee
Why Optimise?
-
Lesser Training Time means more experiments
-
Faster Inference means less latency
-
Hassle free Deployment
Training
- Input Pipeline
- Extract - From Memory
- Transform - Augmentation or Pre-Processing
- Load - Send Data to the Model
- Model
Input Pipeline
- Batching
- tf.data API
- Data Format - NCHW or NHWC
- Building from source
Model
- Fused OPs (30% faster)
- Concurrency (is not Parallelism)
- Optimised Operations based on Requirements
Inference and Deployment
- Hardware Dependent Optimisations
- Software Dependent Optimisations
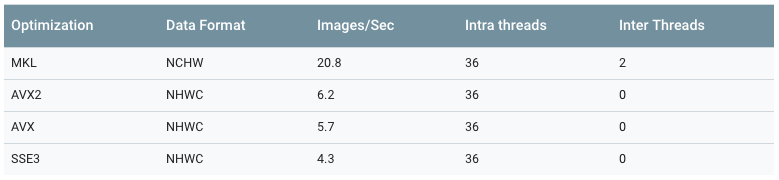
CPUs or GPUs
- CPU - RNNs; GPU - CNN
- Model Parallelism - intra_op and inter_op
- Data Parallelism and GPU Towers
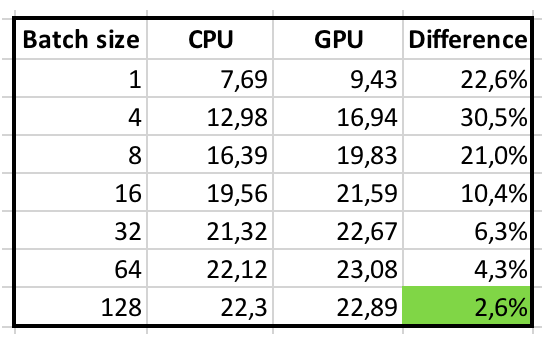
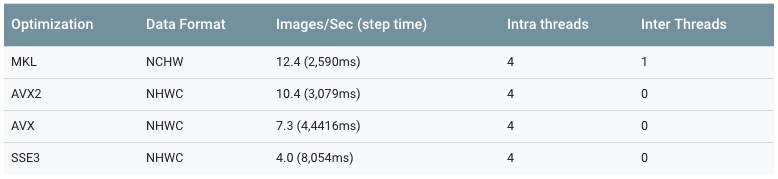
SSE3, MKL, AVX, AVX2?
- Different Instruction sets have difference performance
- MKL is optimised for NCHW
- Larger batch sizes improves performance

Soham Chatterjee
- s.chatterjee@saama.com
- csoham.wordpress.com
- www.github.com/soham96/Talks