Bases de datos relacionales
Fabiola Sergio Fernanda María Elisa Norma
Minería de Datos - Dr. Ángel Kuri
Agosto 26, 2015
Contenido
K
- Antecedentes y Fundamentos
- Por qué son importantes
- Bodegas de Datos
- Mineros
- Ejemplo
Historia y contexto (1/2)
-
Propuesto en 1970 por Edgar Frank Codd (IBM).
-
Desencadenó el diseño de numerosos sistemas de gestión de bases de datos (SGBD o DBMS).
-
Su popularidad y éxito comercial se basó en el reconocimiento de los beneficios y sencillez en el manejo de datos del mundo corporativo.
Historia y contexto (2/2)
-
Surge SEQUEL y SQL como lenguaje de consulta para bases de datos relacionales el cual se basa en el manejo del álgebra y cálculo relacional.
-
Actualmente es el modelo más utilizado en aplicaciones comerciales de procesamiento de datos.
-
Codd identifica dos principios:
- Independencia de los datos tanto física como lógica
- Consistencia de los datos
Modelo relacional (1/2)
- El modelo de Codd consta de 3 partes:
-
Un modelo de datos.
-
Los medios para expresar las operaciones en un lenguaje.
- Un conjunto de reglas de diseño que evitan los problemas de redundancia de datos.
Modelo relacional (2/2)
-
Basado en la lógica de predicados (o lógica de primer orden) y teoría de conjuntos
-
Presenta datos almacenados en tablas (relaciones) representadas por un número variable de registros o filas (tuplas) y un número fijo de columnas (atributos), donde cada fila establece una relación entre un conjunto de valores y cada columna tiene un nombre único.
- Describe una serie de operaciones lógicas que pueden ser utilizadas sobre los datos las cuales incluyen los medios para obtener subconjuntos de filas, columnas o datos de la combinación de diferentes tablas.
Representación gráfica del modelo relacional
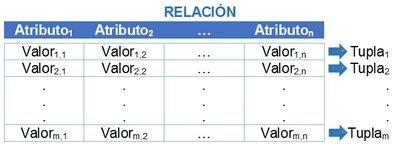
-
Cardinalidad es el número de tuplas de la tabla (m) y es variable.
-
Grado es el número de atributos de la tabla (n) y es invariable.
- Dominio es el conjunto válido de valores que puede tener un atributo y puede ser texto, números enteros, flotantes, fecha, hora, booleano, etc.. El valor nulo indica que el valor es desconocido o no existe y siempre es miembro del dominio.
Estructura de bases de datos relacionales
-
Relación: Sea
una relación y los conjuntos
, un conjunto de dominios cualesquiera. Se define una relación
sobre los conjuntos
como un subconjunto del producto cartesiano de la lista de dominios
-
El orden de las tuplas en una relación no es relevante ya que ordenadas o no, la relación es la misma ya que contiene el mismo conjunto de tuplas.
-
Una tupla
de una relación
con
atributos se denota como
donde
-
Se dice que
cuando la tupla
está en la relación
.
-
los dominios de todos los atributos deben ser atómicos = indivisibles.










Álgebra Relacional
-
Define un conjunto de operaciones sobre relaciones.
-
Utilizan relaciones para generar una nueva relación.
-
Es de tipo procedimental, describe paso a paso cómo obtener una respuesta sobre una base de datos.
-
El resultado de una operación de álgebra relacional es una nueva relación
-
Lo anterior nos permite hacer composiciones para formar expresiones de álgebra relacional (tales como una proyección de una selección previa).
- Se puede hacer uso de las operaciones fundamentales tanto con relaciones como con expresiones.
Operaciones fundamentales
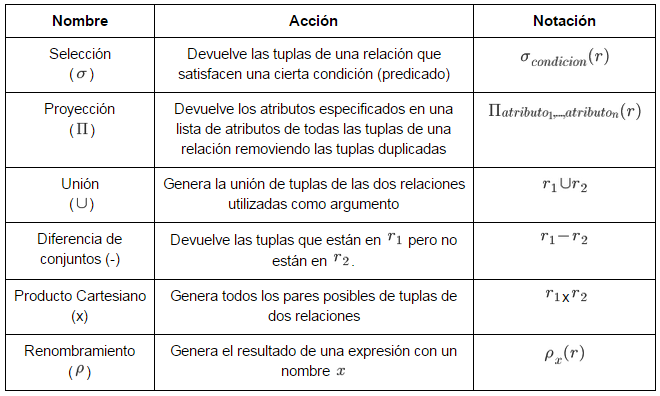
Cálculo Relacional de tuplas
-
Es un lenguaje de consulta declarativo
-
Está basado en la lógica de predicados o de primer orden.
-
Consulta
,
Donde:
es una variable de tupla y
es una fórmula/ condición/ predicado
-
La expresión de consulta representa el conjunto de tuplas que cumplen cierta condición.
-
Una variable tupla
es libre cuando no está cuantificada por
ó
, en cuyo caso es una variable tupla ligada.
-
Se utiliza la notación de la lógica de predicados:
.






Fórmulas atómicas
Las fórmulas o condiciones 
-
donde
es una variable tupla y
es una relación (no se permite el uso del operador
)
-
donde
y
son variables tuplas,
es un atributo de
,
es un atributo de
y
es un operador de comparación como <, ≤, =, ≠, >, ≥
-
donde
es una variable tupla,
es un atributo de
,
es un operador de comparación como <, ≤, =, ≠, >, ≥ y
es una constante









Reglas de fórmulas atómicas
-
Un átomo es una fórmula
-
Si
es una fórmula, también lo es
y
-
Si
y
son fórmulas, también lo son
,
y
-
Si
es una fórmula entonces
y
también son fórmulas.








Elementos (Relaciones, Dominios, Claves)
-
Dominio: Conjunto de valores permitidos para cada atributo. (Enteros, Caracteres, Fechas, etc)
-
Relaciones: Subconjuntos del producto cartesiano de la lista de dominios.
-
Claves: Permiten identificar un conjunto de atributos suficiente para distinguir las entidades entre sí.
Relaciones (1/2)
Uno a uno: Una entidad en A se asocia con a lo sumo una entidad en B, y una entidad en B se asocia con a lo sumo una entidad en A
Uno a varios: Una entidad en A se asocia con cualquier número de entidades en B (ninguna o varias). Una entidad en B, sin embargo, se puede asociar con a lo sumo una entidad en A
Varios a varios: Una entidad en A se asocia con cualquier número de entidades (ninguna o varias) en B, y una entidad en B se asocia con cualquier número de entidades (ninguna o varias) en A
Relaciones (2/2)
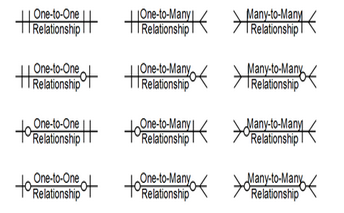
Lenguajes de consulta
Los lenguajes de consulta se usan para especificar las solicitudes de información a la base de datos como:
-
Recuperación de información
-
Inserción de información
-
Borrado de datos
-
Modificación de información
Tipos de lenguajes de consulta
-
Procedimentales. Requieren que el usuario especifique qué datos se necesitan y cómo obtener esos datos.
- No Procedimentales. (declarativos). Requieren que el usuario especifique qué datos se necesitan sin especificar cómo obtener esos datos.
Lenguaje SQL: un poco de historia
-
Es un lenguaje no procedimental que usa una combinación de álgebra relacional y construcciones de cálculo relacional.
-
En sus inicios era llamado como SEQUEL (Structured English Query Language), que se usó experimentalmente en System R (1977 desarrollado por IBM).
-
SQL fue el primer lenguaje comercial basado en el modelo relacional de Codd.
-
1986 Fue estandarizado por el ANSI (SQL-86), 1987 Adoptado por ISO
-
Última versión es SQL:2011
-
SQL ha influenciado varios lenguajes como CQL, LINQ, Cypher
Lenguaje SQL: operaciones básicas
-
SELECT
-
INSERT
-
UPDATE
- DELETE
Lenguaje SQL: SELECT
-
SELECT: Se usa para listar los atributos deseados del resultado de una consulta.
-
FROM: Lista las relaciones que deben ser analizadas en la evaluación de la expresión.
-
WHERE: Es un predicado que engloba a los atributos de las relaciones que aparecen en la cláusula FROM.
-
Ejemplo:
select A1, A2 ,…, An
from r1, r2 ,…, rm
where PLenguaje SQL: INSERT
-
INSERT: Agrega uno o más registros a una tabla
-
Ejemplo:
INSERT INTO table_name
VALUES (value1,value2,value3,...);Lenguaje SQL: INSERT
-
UPDATE: Cambia los datos de uno o más registros en una tabla.
-
Ejemplo:
UPDATE table_name
SET column1 = value1,column2 = value2,...
WHERE some_column = some_value;
Lenguaje SQL: JOIN (1/2)
-
JOIN: Combina datos de una o más tablas
-
INNER JOIN: Produce un conjunto de resultados que es limitado a los elementos donde hay coincidencias en ambas tablas.
-
LEFT JOIN: Los elementos de la primera tabla o tabla de la izquierda son preservadas. los elementos de la segunda tabla o tabla de la derecha, únicamente se muestran si ellos tienen coincidencias con la primera tabla.
-
RIGHT JOIN: Los elementos de la segunda tabla o tabla de las derecha son preservados. Los elementos de la primera tabla o tabla de la izquierda, únicamente se muestran si ellos tienen coincidencias con la segunda tabla.
Lenguaje SQL: JOIN (2/2)
- FULL JOIN: Produce un conjunto de resultados de todos los elementos de ambas tablas, además de los que coinciden.
- CROSS JOIN: El resultado de esta consulta regresa un número de elementos muy grande, ya que hace un cruce de el número de elementos de la primera tabla por la segunda tabla.
- Ejemplo:
SELECT A1, A2, A3
FROM T1 [INNER, LEFT, RIGHT, FULL] JOIN T2 ON T1.ID = T2.ID
SELECT A1, A2, A3
FROM T1 [CROSS] JOIN T2Sistema Gestor de Base de Datos (SGBD)
-
Software que controla la organización, almacenamiento, recuperación, seguridad e integridad de los datos en una base de datos.
Un SGBD está diseñado para permitir la definición, creación, consulta, actualización y administración de bases de datos.
-
El sitio db-engines.com muestra un rank de alrededor de 100 gestores de base de datos de 280 que tiene registrado el sitio.
Sistema Gestor de Base de Datos (SGBD)
-
Entre los primeros 5 lugares de SGBD relacionales (RDMS) por popularidad están:
-
Oracle
-
MySQL
-
Microsoft SQL server
-
PostgreSQL
-
DB2
-
Estructura
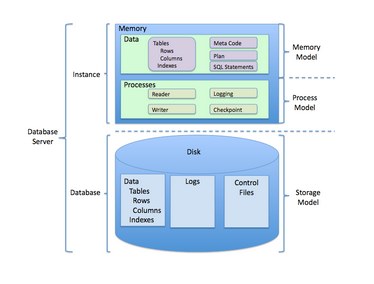
Integridad y seguridad
-
Existe un mínimo necesario de propiedades para proveer una base de datos como parte de una aplicación y su funcionamiento sea viable.
- Si se garantizan estos puntos, se evitará muchas frustraciones en el uso de los datos.
Integridad y seguridad: ACID
-
ACID (por sus siglas en inglés, Atomicity, Consistency, Isolation and Durability):
-
Atomicidad: todos ocurre o nada, esto ayuda por ejemplo en cortes de energía, fallas de hardware, o eventos catastróficos.
-
Consistencia: cualquier estado de la base de datos será internamente consistente con las reglas que limitan los datos.
-
Aislamiento: modificar diferentes partes de las base de datos al mismo tiempo sin afectar otra.
-
Durabilidad: las acciones persisten una vez que las transacciones son completadas
-
Integridad y seguridad: mecanismos
- Los SGBD ofrecen diferentes mecanismos que garantizan la seguridad e integridad de los datos.
- Evitar accesos no autorizados
- Duplicidad de datos
- Relaciones de tabla a tabla no permitida
Integridad y seguridad: mecanismos
-
Declaración de claves: Evita duplicidad de elementos con la misma clave.
-
Forma de relación: Uno a uno, varios a varios, uno a varios.
-
Restricción de dominios: Unicamente fecha, cadena o número
- Integridad referencial: La creación de elementos deben estar restringidas a las referencias o relaciones (no se puede crear un sub elemento a sin que exista un elemento A)
Diseño de bases relacionales: objetivo
Generación de un conjunto de esquemas relacionales que nos permita almacenar la información sin redundancias innecesarias, pero que también nos permite recuperar y actualizar fácilmente la información.
4 formas: Primera, Segunda, Tercera forma normales y la forma normal Boyce-Codd
1FN: Primera Forma Normal
- Prohíbe a un campo contener más de un valor de su dominio de columna
- Evitar la duplicidad de columnas con el mismo dominio
- Evitar cambiar el tipo de dominio con el objetivo de incluir toda la información
2FN: Segunda Forma Normal
- Está en desuso y sólo es de interés histórico.
- Una tabla 1FN está en 2FN si y sólo si ninguno de sus atributos no-principales son funcionalmente dependientes en una parte (subconjunto propio) de una clave primaria (un atributo no principal es uno que no pertenece a ninguna clave primaria)
3FN: Tercera Forma Normal
- Fue definida por Codd en 1971
- Una tabla está en 3FN si y sólo si se cumplen las siguientes condiciones:
- La tabla está en 2FN
- Ningún atributo no-primario de la tabla es dependiente transitivamente de una clave primaria
- Es una relación que no incluye ningún atributo clave
Forma normal Boyce-Codd
- Es una versión ligeramente más fuerte que 3FN
- La forma normal de Boyce-Codd requiere que no existan dependencias funcionales no triviales de los atributos que no sean un conjunto de la clave candidata
Las 12 reglas de Codd
0. El sistema debe ser relacional
-
Regla de la Información
-
Regla del Acceso garantizado
-
Tratamiento sistemático
-
Catálogo en línea basado en el modelo relacional
-
Sub-lenguaje de datos completo
-
Actualización de vistas
-
Inserciones, modificaciones y eliminaciones de alto nivel
-
Independencia física
-
Independencia lógica
-
Independencia de integridad
-
Independencia de la distribución
- No subversión
Se traducen en:
- Debe ser capaz de usar los reglas relacionales
- Toda la información de las tablas debe ser accesible
- Los valores nulos deben ser "nulos"
- El sistema debe soportar al menos un recurso relacional
- El sistema debe ser capaz de insertar, actualizar y eliminar y lo puede hacer en varias filas al mismo tiempo
Contenido
- Antecedentes
- Por qué son importantes
- Bodegas de Datos
- Mineros
- Ejemplo
K
Tipos de bases de datos
Hay diversas maneras de organizar la información en una base de datos:
- Relacional
- Orientada a objetos
- Red
- Orientada a objetos y relacional
¿Por qué son importantes?
- Las BDR nos permiten organizar la información mediante tablas con llave que están relacionadas
- Las bases de datos relacionales son las más usadas en la industria y en los negocios por su facilidad de manejar transacciones y la posibilidad que brindan para la toma de decisiones
Ejemplo de uso: Base de datos de productos, clientes y compras
- Consideremos una compra: ¿quién la hizo?, ¿Qué productos compró?, ¿Cuándo?
- ¿Cuáles son las relaciones entre los productos, clientes y compras?
- ¿Qué productos se compran juntos? (venta cruzada)
- ¿Existen clientes que compran el mismo tipo de producto de manera periódica?
- ¿Cómo cambia el volumen de venta de los productos con el tiempo? ¿Existe periodicidad para algunos productos?
No se limitan a la operación
Entonces, las BDR no sólo nos permiten llevar el control de la Operación, sino también pueden ayudar a tomar decisiones de negocio si las consultas están bien diseñadas.
Ventajas BDR (1/2)
Facilidad de Construcción: generalidad sin dejar de ser simples, ya que la representación en tablas permite presentar la información de forma compacta.
Facilidad de Uso: el tener la información organizada y ordenada en tablas con columnas y filas es intuitiva para el usuario permite acceder fácilmente a información por medio de consultas y reportes. Las BD orientadas a objetos generalmente no tienen (o tienen nula) posibilidad de hacer consultas y generar reportes.
Flexibilidad en las consultas: es posible realizar consultas diversas y personalizadas gracias a que la información se puede extraer y manipular de las tablas usando operaciones hasta obtener la consulta deseada (no se necesita navegar por la base)
Ventajas BDR (2/2)
Precisión en las consultas: el uso de álgebra y cálculo relacional como lenguaje para hacer las consultas permite que no haya ambigüedad. En otro tipo de bases de datos como la de red sí es posible tener ambigüedad. La precisión en las consultas incrementa el alcance de la mismas.
Independencia: la estructura normalizada usada en una BDR permite tener más fácilmente independencia de los datos que en Bases de Datos tipo red, por ejemplo.
Seguridad: es fácil añadir permisos de acceso a variables de interés únicamente añadiendo una nueva relación con los controles de autorización deseados.
Aceptación comercial y madurez del producto: usadas en múltiples industrias y negocios (nóminas, banca).
Desventajas BDR (1/2)
Rendimiento: Si la consulta deseada usa muchas tablas o el tamaño de las mismas es grande la query puede tardar un tiempo considerable en correr.
Costo: Para la construcción de la base y su mantenimiento se requiere software especializado y/o programador para construir la base y posteriormente un administrador de la misma.
Límites de tamaño: Algunas BDR tienen límites en el tamaño del campo que deben ser especificados cuando se diseña la misma.
Desventajas BDR (2/2)
No escalable: Las BDR organizan la información por características comunes, los datos generalmente son simples. Imágenes complejas y productos multimedia son complejos y no son fácilmente procesables por una BDR, se procesan con una BD orientada a objetos.
- Ejemplo 1: Direcciones. Bases orientadas a objetos (BAO) son mejores.
- Ejemplo 2: Más de un teléfono: creación de nueva relación es costosa y artificial. BAO son mejores.
Aislamiento: las BDR se convierten en “grandes islas de información” y pueden no compartirse fácilmente con otras. En la práctica la comunicación entre BDR suele ser costosa y tardada.
Gráficamente:
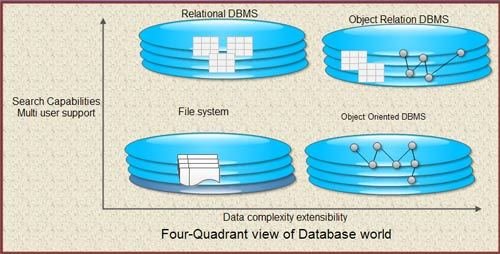
Contenido
- Antecedentes
- Por qué son importantes
- Bodegas de Datos
- Mineros
- Ejemplo
K
Bodegas de Datos, BD (dataware house, DHW)
- Las bases de datos permiten realizar consultas al usuario final.
- Las BD se crean al verter información para analizarla posteriormente separándola del proceso de generación.
- Estos datos pueden provenir de varias fuentes.
- Esto le confiere a las BD la flexibilidad para combinarse con otras BD y tener robustez.
Elementos que integran una BD
- Sistema Operativo.
- Sistema de Extracción-Transformación-Carga (ETL).
- Herramientas de presentación de Datos.
- Herramientas de consulta de datos.
- Herramientas de acceso a datos.
Diseño de Bodegas de Datos
- Dimensionales: Búsquedas directas que permiten acceso rápido a grandes cantidades de información histórica que soporta cambios de sistemas operativos.
- Cubo: Arreglos multidimensionales en las que se preestablecen combinaciones de dimensiones a las cuales se puede acceder de manera interactiva
Las bases de datos relacionales y los cubos funcionan bien juntas. Por ejemplo, la BDR puede servir como la bodega de datos, usando cubos como una capa adicional para tener reportes de alto desempeño.
Diseño de Bodegas de Datos (Cubo)
- Permite cambiar la perspectiva de los datos agregando/quitando dimensiones por medio del Procesamiento Analítico Lineal (OLAP)
-
Puede generar jerarquias recursivas.
-
Su escalamiento esta reducido y el manejo de grandes cantidades de datos no es factible en este esquema.
Ejemplo de Cubo
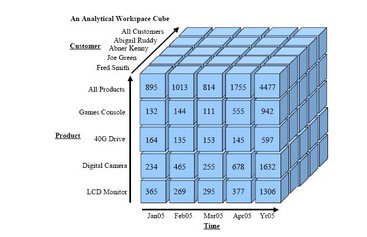
Comparación entre estrella y cubo (1/2)
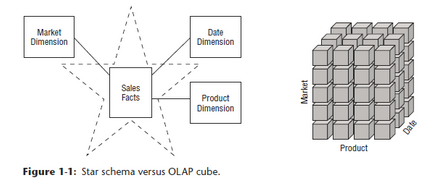
Comparación entre estrella y cubo (2/2)
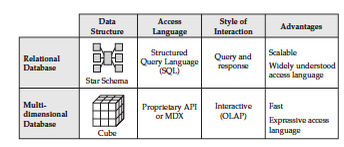
Funciones de las BD
-
Almacenar datos
- Validación
- Reportes
- Exploración
- Generar accesibilidad y consistencia
Ventajas de las BD
-
Ventajas:
- Centralización de los datos
- Facilita acceso a distintas fuentes
- Acorde a necesidades del usuario final
-
Facilita toma de decisiones
-
Transformar información bruta en útil
Desventajas de las BD
-
Desventajas:
- Dificultad para añadir nuevas fuentes de datos
-
Posibles problemas de compatibilidad de datos
-
Dificultad en su mantenimiento
-
No es la mejor herramienta para toma de decisiones en tiempo real
Importancia
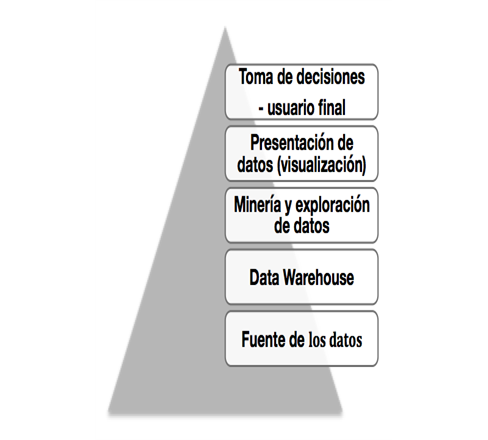
Contenido
- Antecedentes
- Por qué son importantes
- Bodegas de Datos
- Mineros
- Ejemplo
K
¿Qué es un minero?
Un minero es aquel software que nos provee de herramientas necesarias para realizar minería de datos
Mineros:
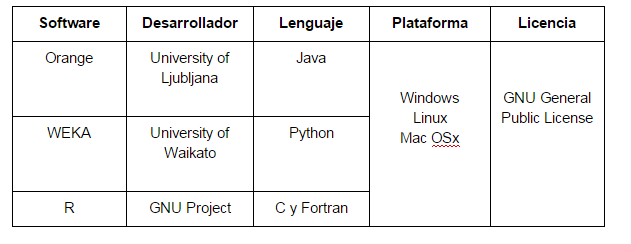
Características: Orange
- Preprocesamiento de datos
- Modelado
- Técnicas de exploración
- Visualización
- Recuerda decisiones pasadas y da sugerencias
- Add-ons para bioinformática
- Tiene componentes para Aprendizaje de Máquina
- Interfaz gráfica de usuario o Python Scripts
Características: WEKA
- Preprocesamiento de datos
- Clasificación
- Regresión
- Clusterin
- Visualización
- Acceso a bases de datos SQL usando Java Database Connectivity (JDBC)
- Interfaz gráfica de usuario o línea de comandos
Características: R
-
Es un lenguaje y ambiente de programación para computación estadística
-
Permite realizar Modelado Lineal y no Lineal
-
Contiene paquetes para clustering, Aprendizaje de Máquina, Text Mining, entre otros.
Ejemplo de uso y código
Contenido
- Antecedentes
- Por qué son importantes
- Bodegas de Datos
- Mineros
- Ejemplo
K
Ejemplo práctico
Contraseña: 1t4mds
Ipython Notebook
Un poco de humor siempre es bueno... (1/4)

Un poco de humor siempre es bueno... (2/4)

Un poco de humor siempre es bueno... (3/4)

Un poco de humor siempre es bueno... (4/4)
