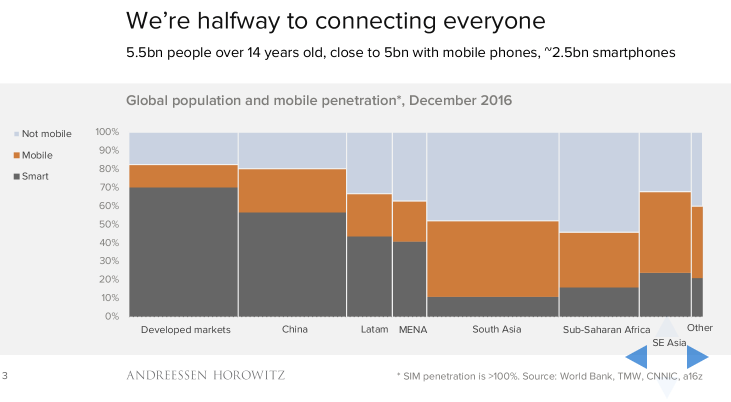
From Lab to Factory
Lessons learned developing Data Products
Keynote PyCon Colombia
Feb 2017
All opinions my own
Who am I?
- Data Scientist at Elevate (Recruitment Startup) and Author
- @springcoil
- About 5 years in Machine Learning/Data Science
- OSS contributor (mostly PyMC3)
- Built Ad-hoc analysis, Data Products and Data Pipelines at




Why talk about this?
Data Moats



Roadmap
-
What is Data Science?
- Type of Data Scientists
- Deploying Data Science (tech/culture)
- Success stories and recommendations
- Bigger idea (Change)
What IS a Data Scientist?

There's a Data Science Spectrum
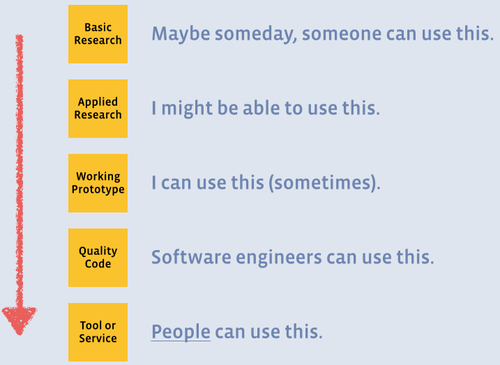
HT: Sean J. Taylor (Facebook Research Scientist)
Data Science to Value
- Data doesn't do anything!
-
People need to make decisions (strategic/ tactical)
- Or the product needs to alter someones decision making (Spotify Discover Weekly, Amazon Recommendations, etc)

(Taken from Josh Wills talk - Lab to Factory 2014)
or https://hbr.org/2013/04/two-departments-for-data-succe
or https://hbr.org/2013/04/two-departments-for-data-succe

Expectations and reality




Data is the new oil...

But. Data isn't a product. It needs to be turned into one!
Data Science is hard
- Data and technical problems
- Skill set (emotional and tech)
- Machine Learning Ops
Data Science projects are risky!
Many stakeholders think that data science is just an engineering problem, but research is high risk and high reward
De-risking the project - how? Send me examples :)
Success with Data Science
1. People
2. Ideas
3. Things
Source: USAF
R and D needs cultural support

Your culture needs to avoid the HiPPO (highest paid persons opinion) to be data-informed or data-driven.
Good cultures
- Data democratization
- Clear objectives and metrics against objectives
- Financial metrics don't always win - sometimes brand wins
- See http://bit.ly/cultureanddata by Martin Goodson
Some data scientists do experiments and build prototypes
Production
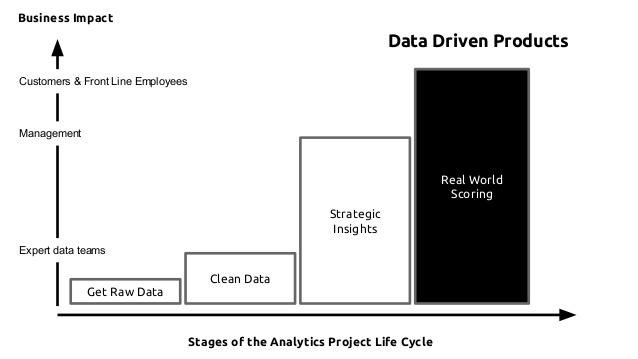
(HT: The Yhat people - www.yhathq.com)
Deploying Data Products is hard
- Monitoring and Alerting
- Deployment
- Real world data is tricky (training/ testing)
- Interpretability (explaining fraud detection/ad tech)
- Feature engineering
- Models decay over time
What projects work?
- Explain existing data (visualization!)
- Automate repetitive/ slow processes
- Augment data to make new data (Search engines, ML models)
- Predict the future (do something more accurately than gut feel )
- Simulate using statistics :) (Sports analytics models)
"You need data first" - Peadar Coyle
- Copying and pasting PDF/PNG data
- Getting data in some areas is hard!!
- Some tools for web data extraction
- Messy APIs without documentation :(


Visualise ALL THE THINGS!!
- (Relay foods dataset - HT Greg Reda)
-
Consumer behaviour at a Fast Food Restaurant per year in the USA
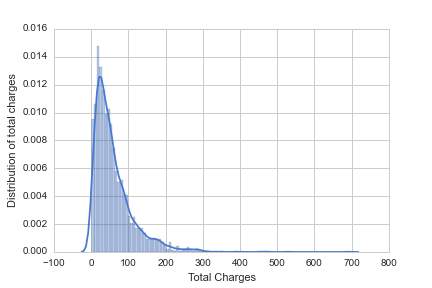



Augmenting data and using API's












Production data/ Real world
HT: Andrew Ng
Everyone ETLS
- Only 1% of your time will be spent modelling
- Data pipelines and your infrastructure matters - Eoin Brazil Talk
- Tools such as Spark, Luigi, Airflow or Dask are important
- Monitoring of pipelines. Scalability. Machine provision



Success Story (1)
- Ad Tech project (Media company) -
original process took 10 hours per week of analyst time.
- Broke down process and produced simple predictive model
- Data type challenges (unicode in Python 2.7) and business expectations
- Now takes less than 30 minutes each week.
Success Story (2)
- Elevate is a Total Talent Management platform (tools for streamlining recruitment)
- Several models in production - microservices (recommenders, job type prediction)
- Data pipeline (Luigi) necessary for producing features
- Lots of challenges about Docker, time, updated data.
- Works: MyPy (Python 3.5), code review, testing - http://hypothesis.works/
- Next: Moving to PySpark for ETL, more pair programming
![]()
Failure
1. Lack of support from tech teams
2. Lack of clearly defined customer
3. No culture of DevOps
4. Management had no clear vision

Lessons learned from Lab to Factory
1. Monitoring - data products need evaluation in production
2. Lack of a shared language between software engineers and data scientists. Pair programming/ Code review are some solutions.
3. To help data scientists and analysts succeed your business needs to be prepared to invest in tooling. (Pipelines, DevOps, Reproducible)
4. Often you're working with other teams who use different languages - so micro services can be a good idea (example C#.net app and Python microservice)
How to deploy a model?
- Palladium (Otto Group)
- Azure
- Flask Microservice (DIY) and Docker




Dev Ops

We need each other!
Use small data where possible!!
- Small problems with clean data are more important - (Ian Ozsvald)
- Amazon machine with many Xeons and 244GB of RAM is less than 3 euros per hour. - (Ian Ozsvald)
- Blaze, Xray, Dask, Ibis, etc etc - PyData Bikeshed
- "The mean size of a cluster will remain 1" - Matt Rocklin

Focus on the real problem

Closing remarks
- Dirty data stops projects
- Change happens, we need to help businesses adapt or be agile
- There are some good projects like Icy, Luigi, etc for transforming data and improving data extraction
- http://martin.zinkevich.org/rules_of_ml/rules_of_ml.pdf - Google paper on rule for building ML systems
Closing Remarks (2)
- Stakeholder management is a challenge too
- Send me your dirty data and data deployment stories :)
-
www.peadarcoyle.com
-
https://leanpub.com/interviewswithdatascientists
A New World

Simulate: Rugby games with MCMC
(PyMC3)

What is the Data Science process?
Obtain
Scrub
Explore
Model
Interpret
Communicate (or Deploy)
Some NLP on the Interviews!

What do Data Scientists talk about?
Based on my Dataconomy Interview series!
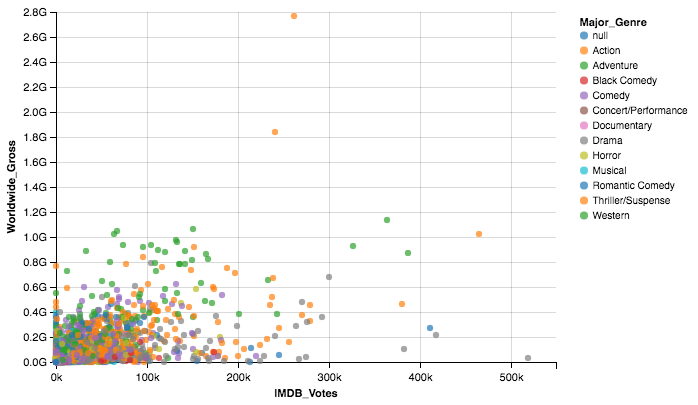
 A famous 'data product' - Recommendation engines
A famous 'data product' - Recommendation engines
Credits
{kind=link}


