Aggregation Framework
- Operations that process data sets and return calculated results are called aggregations.
- MongoDB provides data aggregations that examine data sets and perform calculations on them.
- Aggregation is run on the mongod instance to simplify application codes and limit resource requirements.
Aggregation
-
Similar to queries, aggregation operations in MongoDB use collections of documents as an input and return results in the form of one or more documents.
-
The aggregation framework in MongoDB is based on data processing pipelines.
-
Documents pass through multi-stage pipelines and get transformed into an aggregated result.

-
The most basic pipeline stage in the aggregation framework provides filters that function like queries.
-
It also provides document transformations that modify the output document.
-
The pipeline operations group and sort documents by defined field or fields. In addition, they perform aggregation on arrays.
-
Pipeline stages can use operators to perform tasks such as calculate the average or concatenate a string.
-
The pipeline uses native operations within MongoDB to allow efficient data aggregation and is the favored method for data aggregation.
-
The aggregate command in MongoDB functions on a single collection and logically passes the collection through the aggregation pipeline.
- You can optimise the operation and avoid scanning the entire collection by using the $match, $limit, and $kip stages.
- You may require only a subset of data from a collection to perform an aggregation operation.
- Therefore, use the $match, $limit, and $skip stages to filter the documents.
- When placed at the beginning of a pipeline, the $match operation scans and selects only the matching documents in a collection.
Which of the following is true about pipelines and the Aggregation Framework?
- Pipelines must consist of at least two stages.
- Stages cannot be configured to produce our desired output.
- The Aggregation Framework provides us many stages to filter and transform our data
- Documents flow through the pipeline, passing from one stage to the next
-
Pipeline stages appear in an array.
-
Documents are passed through the pipeline stages in a proper order one after the other.
-
Barring $out and $geoNear, all stages of the pipeline can appear multiple times.
-
The db.collection.aggregate() method provides access to the aggregation pipeline and returns a cursor and result sets of any size.
AGGREGATE PIPELINE STAGES
$project:
- This stage adds new fields or removes existing fields and thus restructure each document in the stream.
- This stage returns one output document for each input document provided.
$match:
- It filters the document stream and allows only matching documents to pass into the next stage without any modification.
- $match uses the standard MongoDB queries.
- For each input document, it returns either one output document if there is a match or zero documents when there is no match.

Which of the following is/are true of the $match stage?
- $match can only filter documents on one field.
- $match can use both query operators and aggregation expressions.
- It uses the familiar MongoDB query language.
- It should come very early in an aggregation pipeline.
Which of the following statements are true of the $project stage?
- Once we specify a field to retain or perform some computation in a $project stage, we must specify all fields we wish to retain. The only exception to this is the _id field.
- Beyond simply removing and retaining fields, $project lets us add new fields.
- $project can only be used once within an Aggregation pipeline.
- $project cannot be used to assign new values to existing fields.
$group:
- This stage groups documents based on the specified identifier expression and applies logic known as accumulator expression to compute the output document.
$sort:
- This stage rearranges the order of the document stream using specified sort keys.
- The documents remain unaltered even though the order changes.
- This stage provides one output document for each input document.

$skip:
- This stage skips the first n documents where n is the specified skip number.
- It passes the remaining documents without any modifications to the pipeline.
- For each input document, it returns either zero documents for the first n documents or one document.
$limit:
- It passes the first n number of documents without any modifications to the pipeline.
- For each input document, this stage returns either one document for the first n documents or zero documents after the first n documents.
$unwind:
- It deconstructs an array field in the input documents to return a document for each element.
- Each output document replaces the array with an element value.
- For each input document, it returns n documents where n is the number of array elements and can be zero for an empty array.



Which of the following statements is true?
- Only one expression per stage can be used.
- An aggregation pipeline is an array of stages.
- Some expressions can only be used in certain stages.



Which of the following statements apply to $graphLookup operator?
- $graphLookup depends on $lookup operator. Cannot be used without $lookup
- $lookup and $graphLookup stages require the exact same fields in their specification.
- $graphLookup is a new stage of the aggregation pipeline introduced in MongoDB 3.2
- Provides MongoDB with graph or graph-like capabilities
- $graphLookup provides MongoDB a transitive closure implementation
Example
db.zipcodes.aggregate([
{
"$group": {
"_id": "$state",
"totalPop": {
"$sum": "$pop"
}
}
},
{
"$match": {
"totalPop": {
"$gte": 10000000
}
}
}
]); $group stage does three things:
- Groups the documents of the zip code collection under the state field
- Calculates thetotalPop (read as the total population) field for each state
- Returns an output document for each unique state.
- The aggregation operation given below returns all states with the total population greater than 10 million.
- This example depicts that the aggregation pipeline contains the $group stage followed by the $match stage.
db.users.aggregate([
{
"$project": {
"month_joined": {
"$month": "$joined"
},
"name": "$_id",
"_id": 0
}
},
{
"$sort": {
"month_joined": 1
}
}
]);- This aggregation operation shown returns usernames sorted by the month of their joining.
- This kind of aggregation could help generate membership renewal notices.
- Here in this command, the aggregate pipeline is used.
- The $sort stage orders those documents and $group stage applies the sum operation on the amount fields of those documents.
APPLICATION
ENGINEERING
Replication
- The primary task of a MongoDB administrator is to set up replication and ensure that it is functioning correctly.
- The replication functionality is recommended for use in the production setting.
- Replication in MongoDB increases data availability by creating data redundancy.
- MongoDB replication stores multiple copies of data across different databases in multiple locations, and thus protects data when the database suffers any loss.
-
It helps you manage data in the event of hardware failure and any kind of service interruptions.
-
Having multiple copies of data stored on various servers across various locales, you can perform tasks, such as disaster recovery, backup, or reporting with ease.
-
You can also use replication to enhance read operations.
-
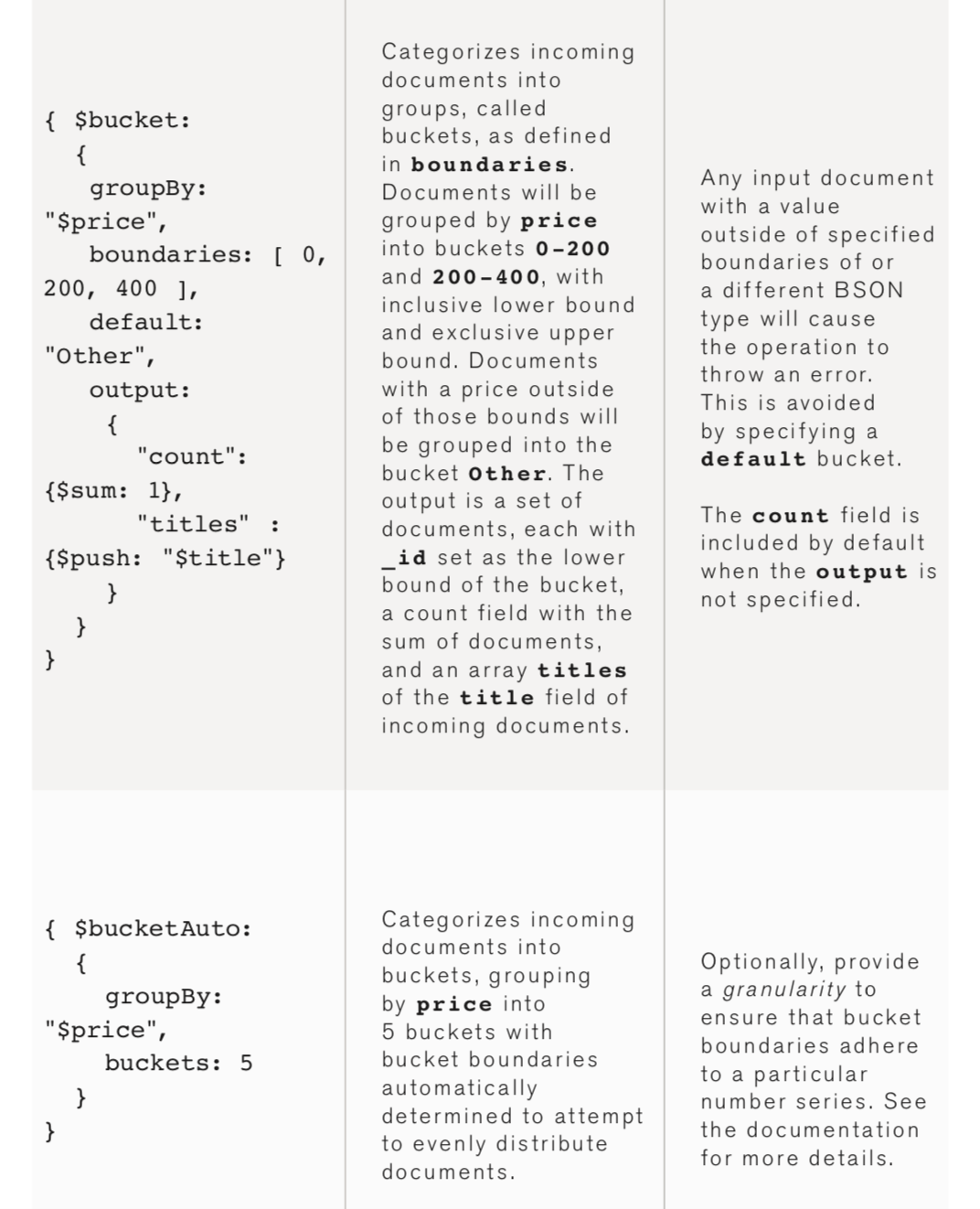
Typically, clients send read and write operations to different servers.
-
You can store copies of these operations in different data centers to increase the locality and availability of data for distributed applications.
-
A replica set consists of a group of mongod instances that host the same data set.
-
In a replica set, the primary mongod receives all write operations and the secondary mongod replicates the operations from the primary and thus both have the same data set.
-
The primary node receives write operations from clients.
-
A replica set can have only one primary and therefore only one member of the replica set can receive write operations.
-
A replica set provides strict consistency for all read operations from the primary.
Replica Sets
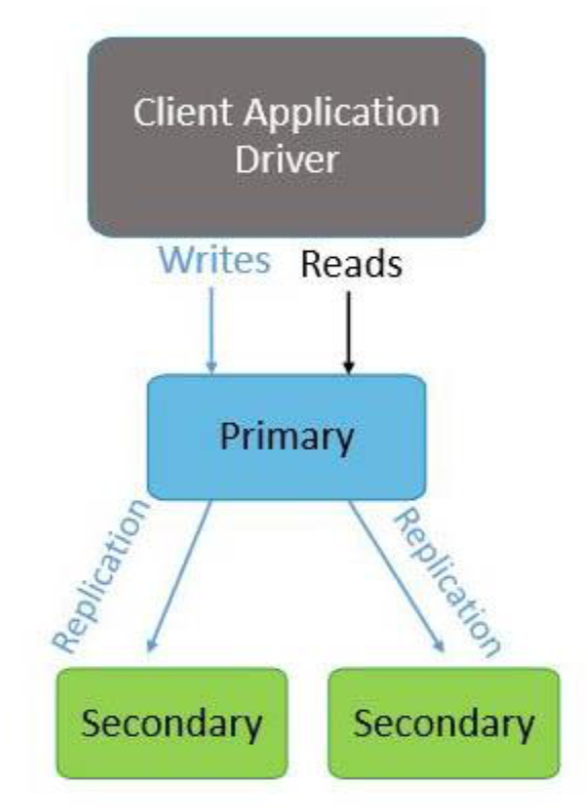
- The primary logs any changes or updates to its data sets in its oplog(read as op log).
- The secondaries also replicate the oplog of the primary and apply all the operations to their data sets.
- When the primary becomes unavailable, the replica set nominates a secondary as the primary.
- By default, clients read data from the primary.
- However, they can also specify read preferences and request read operations to send to the secondaries.
- Secondary members in a replica set asynchronously apply operations from the primary.
- By applying operations after the primary, replica sets can function without any secondary members.
- As a result, all secondary members may not return the updated data to clients. Reads from secondaries may return data that does not reflect the state of the primary.
- A primary can convert to a secondary or vice versa. However, an arbiter will remain unchanged.
- When the primary node of a replica set stops communicating with other members for more than 10 seconds or fails, the replica set selects another member as the new primary.
- The selection of the new primary happens through an election process and whichever secondary node gets majority of the votes becomes the primary.
- A replica set supports application needs in various ways. For example, you may deploy a replica set in multiple data centers, or manipulate the primary election by adjusting the priority of members.
- In addition, replica sets support dedicated members for functions, such as reporting, disaster recovery, or backup.
AUTOMATIC FAILOVER IN MONGODB
- In addition to the primary and secondaries, a replica set can also have an arbiter.
- Unlike secondaries, arbiters do not replicate or store data.
- However, arbiters play a crucial role in selecting a secondary to take the place of the primary when the primary becomes unavailable.
-
A replica set typically contains:
- A primary node
- A secondary node
- An arbiter
- Typically, most of the replica set deployments keep three members that store data, one primary and two secondaries.
- A replica set in MongoDB version 3.0 can have up to 50 members with 7 voting members.
Arbiter

Priority 0
- A priority zero member in a replica set is a secondary member that cannot become the primary.
- These members can act as normal secondaries, but cannot trigger any election.
- The main functions of a priority are as follows:
- Maintains data set copies
- Accepts and performs read operations
- Elects the primary node
- A priority zero member is particularly useful in multi-data center deployments.
- In a replica set containing three members, one data center hosts both, the primary and a secondary, and the second data center hosts one priority zero member.
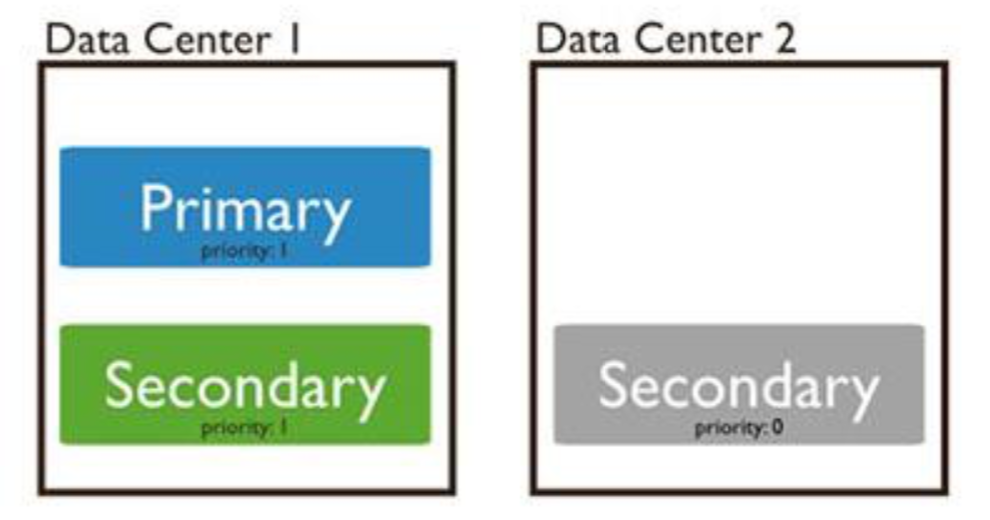
- Typically, a priority zero member acts as a backup. For example, in some replica sets, a new member may not be able to add immediately.
- The backup or standby member stores the updated data and can immediately replace an unavailable member.
HIDDEN MONGODB REPLICA SET MEMBERS
- Hidden members of a replica set are invisible to the client applications.
- They store a copy of the primary node’s data and are good for workloads with different usage patterns from the other members in the replica set.
- Although the hidden replica set members are priority zero members and can never replace the primary, they may elect the primary.
-
You can utilize the hidden members for dedicated functions like reporting and backups.
DELAYED MONGODB REPLICA SET MEMBERS
-
Delayed replica set members are those secondaries that copy data from the primary node’s oplog file after a certain delay.
-
Delayed replica set members store their data set copies. However, they reflect a previous version, or a delayed state of the set.
-
If the data shown in the primary is for 10 AM then the delayed member will show data for 9 AM. Delayed members perform a “roll backup” or run a “historical” snapshot of the dataset.
-
Therefore, they help you manage various human errors and recover from errors, such as unsuccessful application upgrade, and dropped databases and collections.
DELAYED MONGODB REPLICA SET MEMBERS
-
To be considered delayed member, a replica set member must:
- Be a priority zero member
- Be hidden and not visible to applications and
- Participate in electing the primary
-
You can configure a delayed secondary member with the following settings:
- Priority Value - Zero,
- Hidden Value - True, and
- SlaveDelay Value - Number of seconds to delay
- After a replica set reconfigures, the delayed secondary member cannot replace the primary and is hidden from applications.
- The slaveDelay value delays both replication and the member’s oplog by 3600 seconds or 1 hour.
Write concern
- w: 0
- w:1
- w:2
- w: majority
- unacknowledged
- acknowledged
- Primary: This is the default read preference mode. All operations read from the current replica set are primary.
- PrimaryPreferred: Operations are mostly read from the primary member. However, when the primary is unavailable, operations are read from a secondary member.
- Secondary: All operations are read from secondary members of the replica set.
- SecondaryPreferred: In most situations, operations are read from a secondary, but when a
secondary member is unavailable, operations are read from the primary. - Nearest: Operations are read from a member of the replica set with the least network
latency, irrespective of the member’s type.
Read preference
- Typically, sharded clusters in MongoDB require a proper infrastructure setup.
- This increases the overall complexity of the deployment. Therefore, consider deploying sharded clusters only when there is an application or operational requirement.
- You must consider deploying a MongoDB sharded cluster when your system shows the following characteristics:
- The data set outgrows the storage capacity of a single MongoDB instance.
- The size of the active working set exceeds the capacity of the maximum available RAM.
- A single MongoDB instance is unable to manage write operations.
In the absence of these characteristics, sharding in MongoDB will not benefit your system, rather, it will add complexity
sharding