Schema Design
- Rich Documents - JSON key value pairs
- Pre join/ Embeded data(Nested documents)
- No constraints - no foreign key
- No declared schema
MongoDB Recap
What is the single most important factor in designing your application schema within MongoDB?
- Making the design extensible
- Making it easy to read by a human
- Matching the data access patterns of your application
- Keeping the data in third normal form
Goals of Normalisation
- Free the database of modification anomalies
- Minimise redesign when extending
- Avoid bias towards any particular access pattern
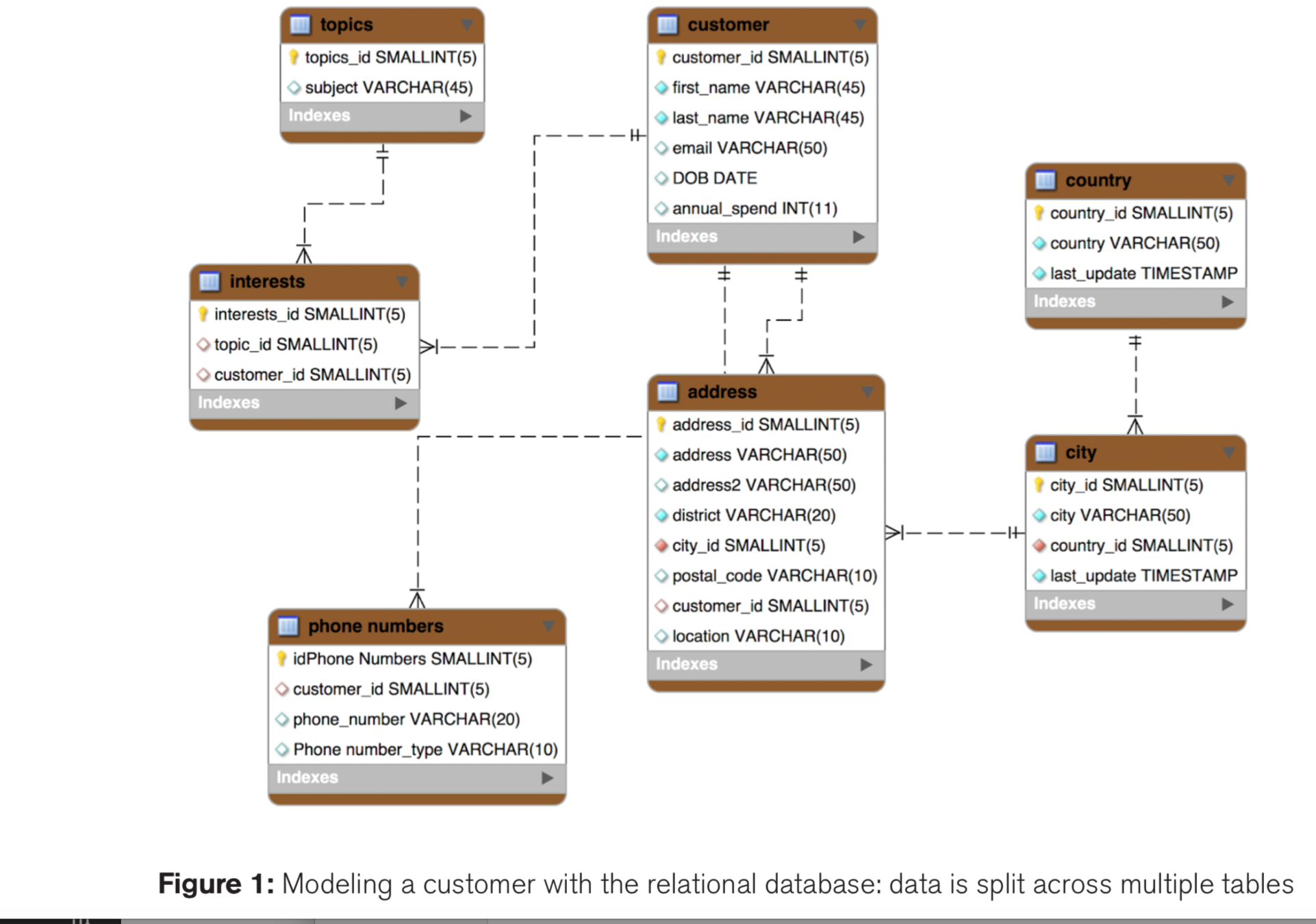
- 1:1 One to One Employee- Resume
- 1:N one to Few/Many City - People , Post - Comments
- M:N Many to Many Books - Authors, Students - Teachers
Relationships can be in three different forms.
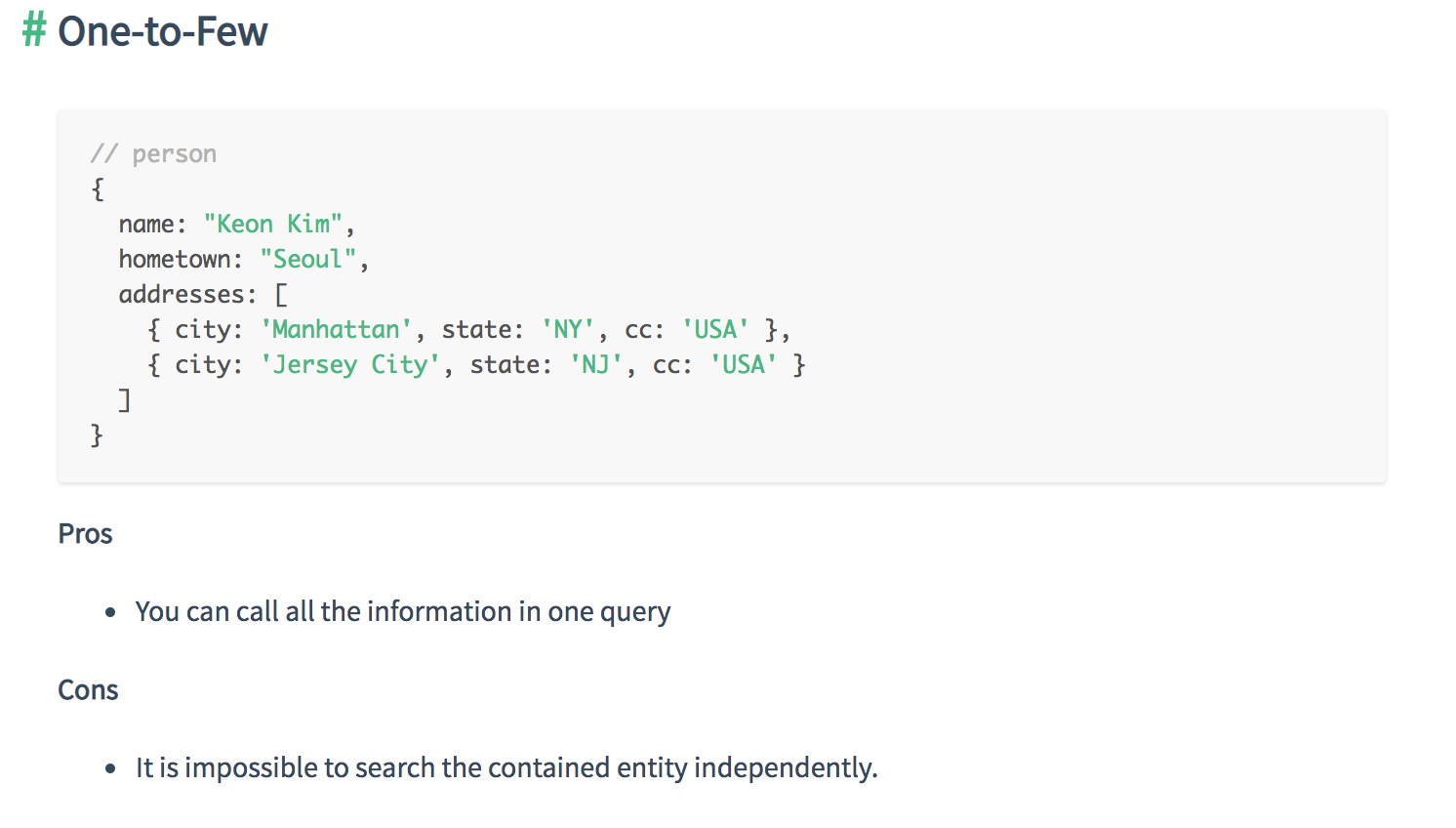
- One-to-Few
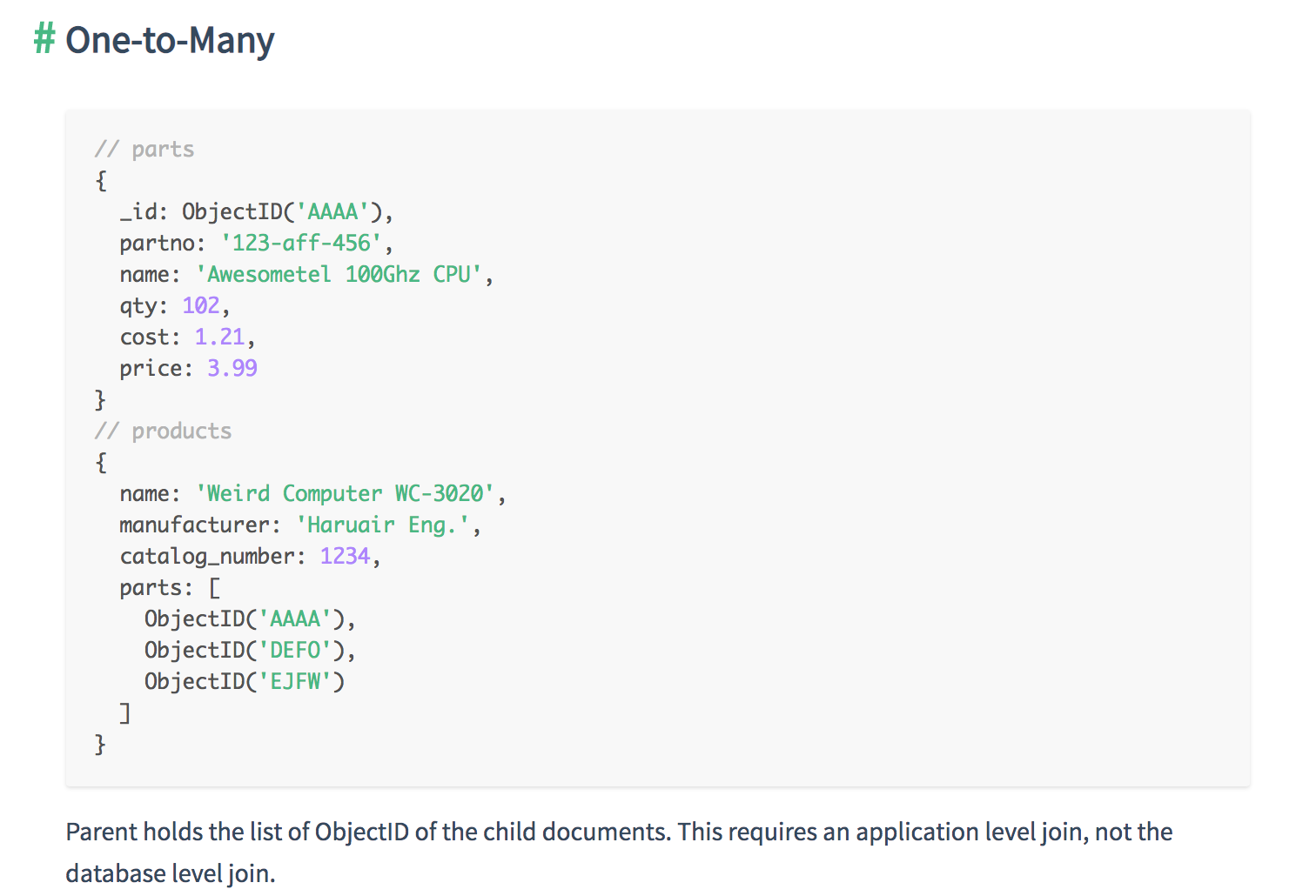
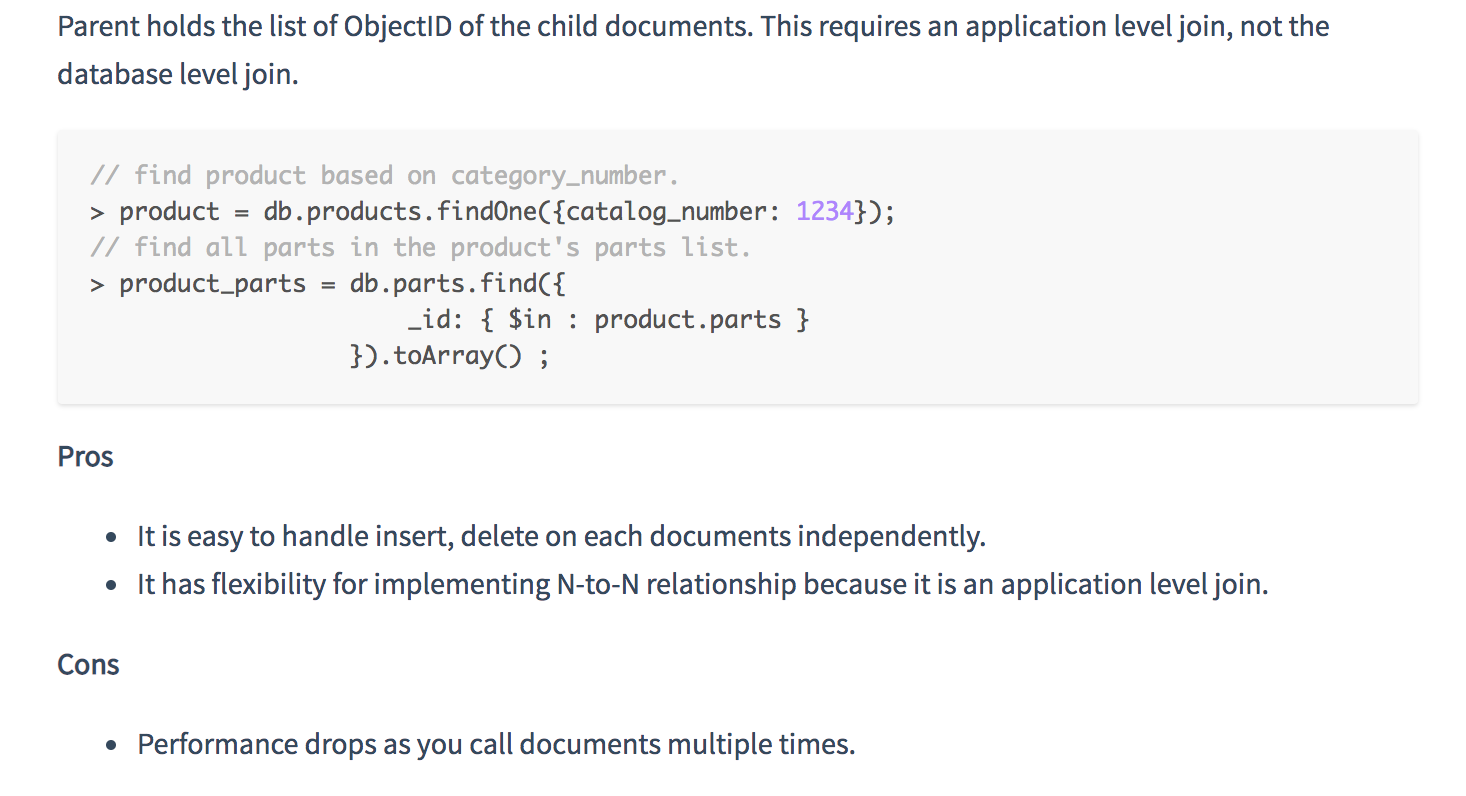
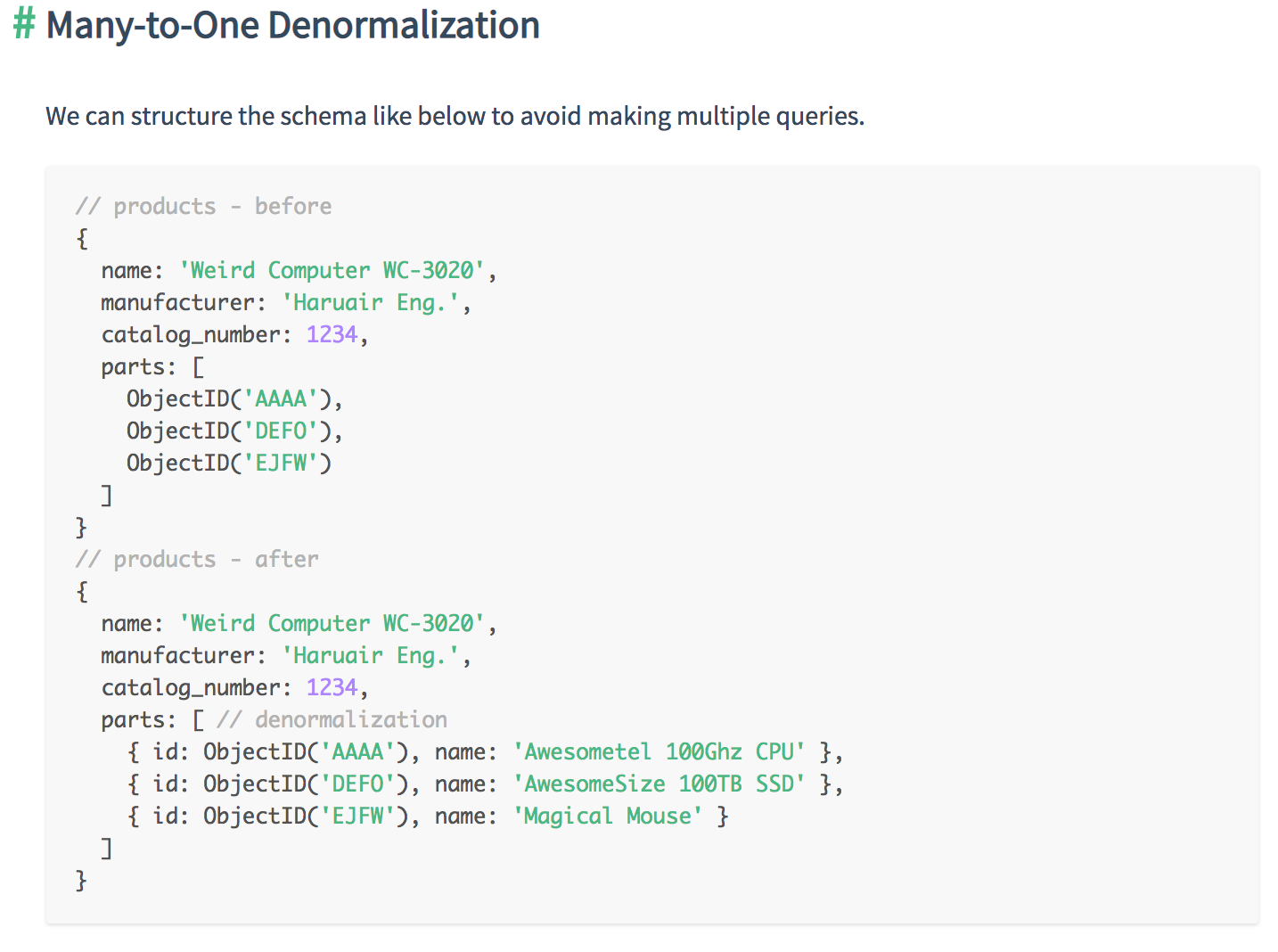
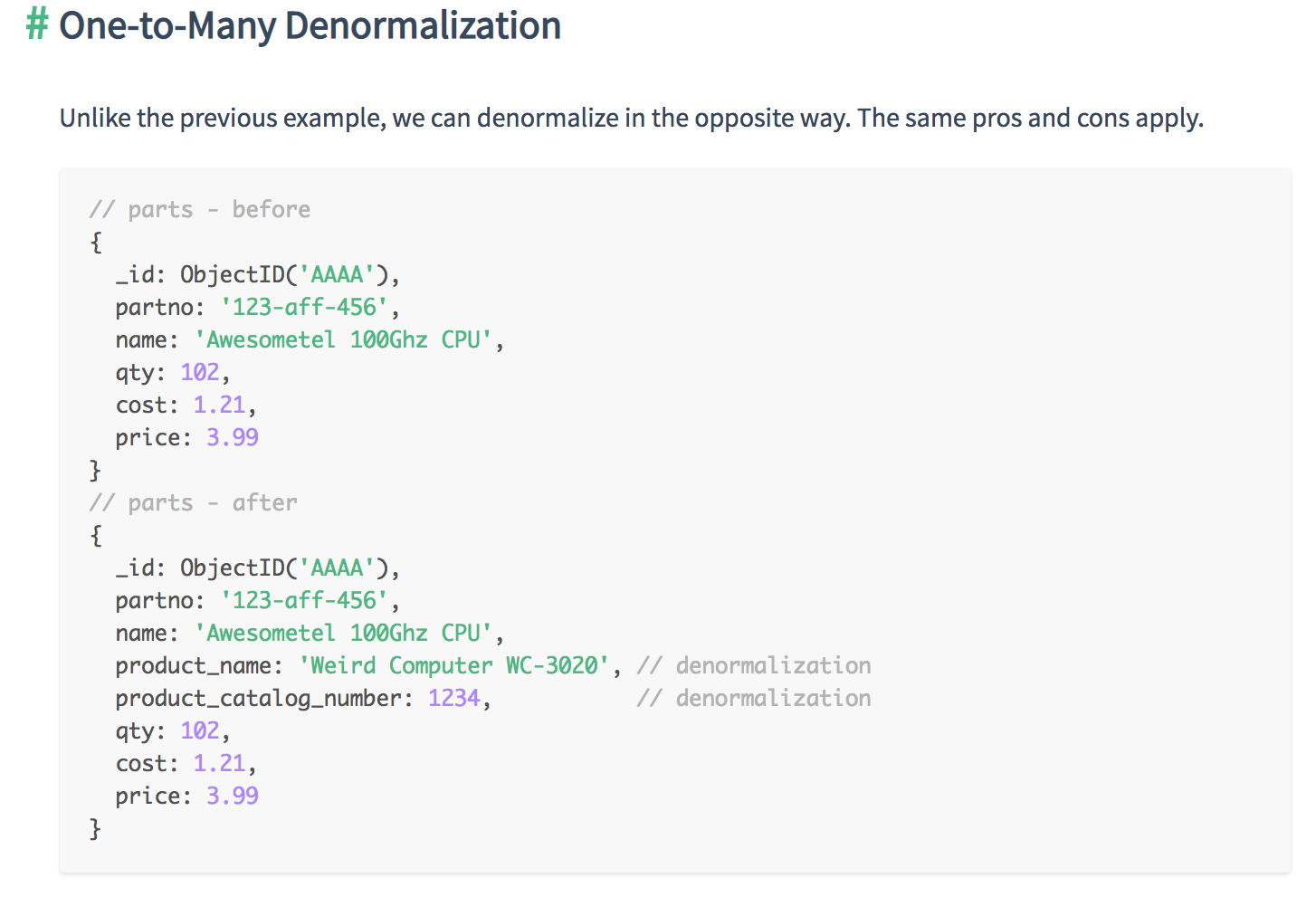
- One-to-Many
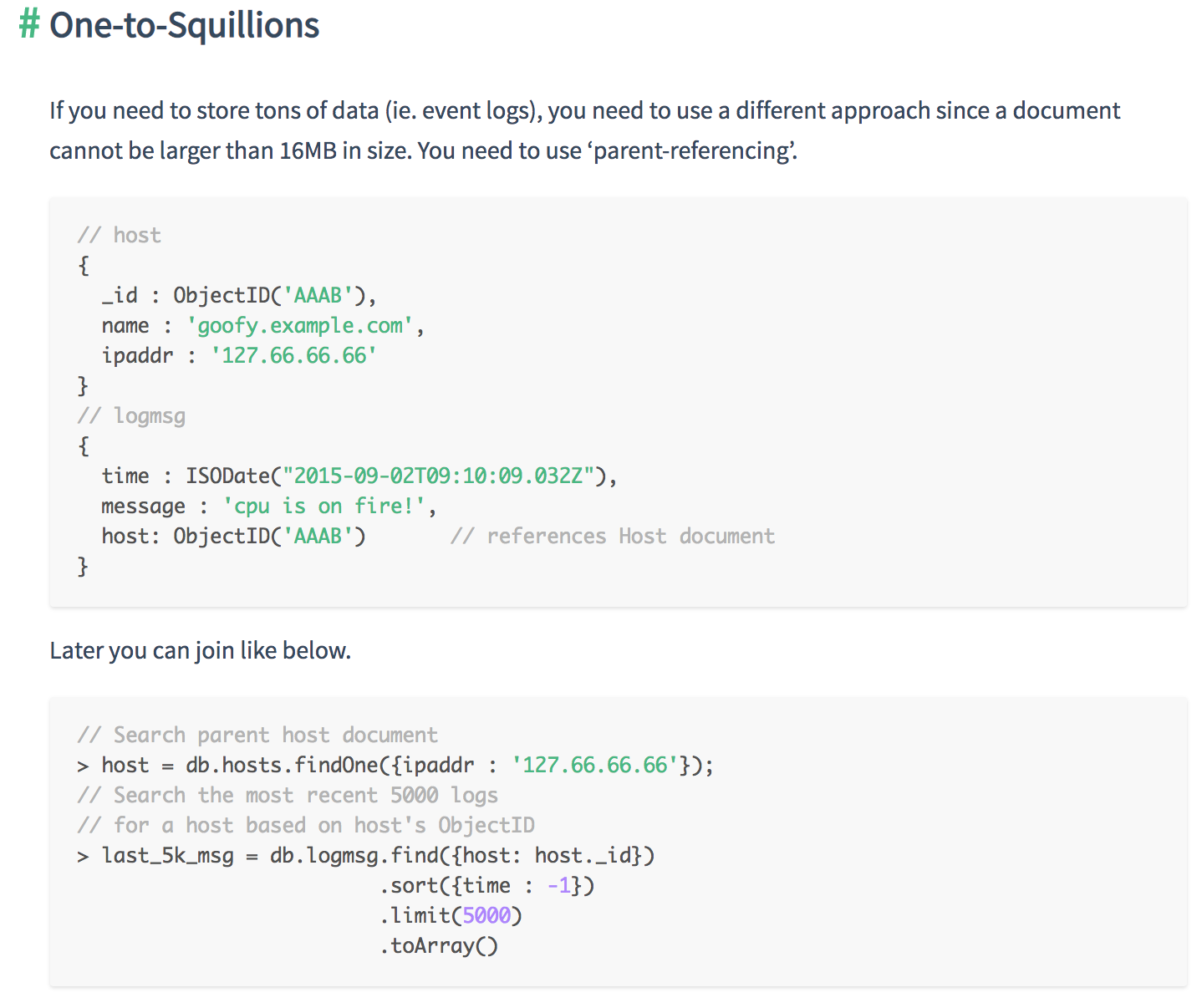
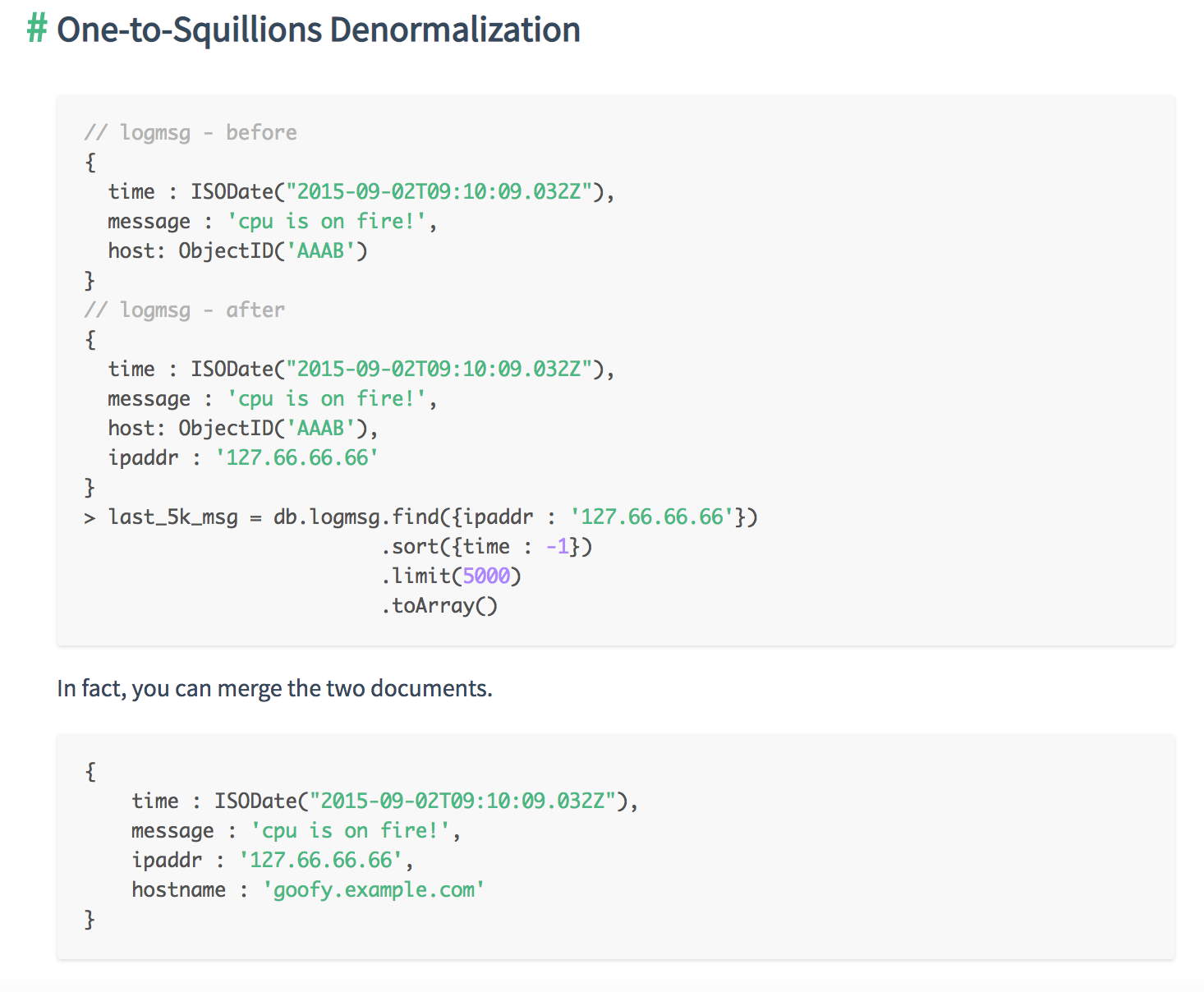
- One-to-Squillions
Each methods for structuring has its pros and cons. So the user should know how to decide which one is better than the other in the given situation.



You need to consider two factors:
- Will the entities on the “N” side of the One-to-N ever need to stand alone?
- What is the cardinality of the relationship: is it one-to-few; one-to-many; or one-to-infinite?
Based on these factors, you can pick one of the three basic One-to-N schema designs:
- Embed the N side if the cardinality is one-to-few and there is no need to access the embedded object outside the context of the parent object
- Use an array of references to the N-side objects if the cardinality is one-to-many or if the N-side objects should stand alone for any reasons
- Use a reference to the One-side in the N-side objects if the cardinality is one-to-squillions
Additional choices that you have past the basics of embed, child-reference, or parent-reference.
- You can use bi-directional referencing if it optimizes your schema, and if you are willing to pay the price of not having atomic updates
- If you are referencing, you can denormalize data either from the “One” side into the “N” side, or from the “N” side into the “One” side
When deciding whether or not to denormalize, consider the following factors:
- You cannot perform an atomic update on denormalized data
- Denormalization only makes sense when you have a high read to write ratio
Rules of Thumb: Your Guide Through the Rainbow
Here are some “rules of thumb” to guide you through these indenumberable (but not infinite) choices
- One: favor embedding unless there is a compelling reason not to
- Two: needing to access an object on its own is a compelling reason not to embed it
- Three: Arrays should not grow without bound. If there are more than a couple of hundred documents on the “many” side, don’t embed them; if there are more than a few thousand documents on the “many” side, don’t use an array of ObjectID references. High-cardinality arrays are a compelling reason not to embed.
- Four: Don’t be afraid of application-level joins: if you index correctly and use the projection specifier then application-level joins are barely more expensive than server-side joins in a relational database.
- Five: Consider the write/read ratio when denormalizing. A field that will mostly be read and only seldom updated is a good candidate for denormalization: if you denormalize a field that is updated frequently then the extra work of finding and updating all the instances is likely to overwhelm the savings that you get from denormalizing.
- Six: As always with MongoDB, how you model your data depends – entirely – on your particular application’s data access patterns. You want to structure your data to match the ways that your application queries and updates it.
When modeling “One-to-N” relationships in MongoDB, main criteria you need to consider are:
- What is the cardinality of the relationship: is it “one-to-few”, “one-to-many”, or “one-to-squillions”?
- Do you need to access the object on the “N” side separately, or only in the context of the parent object?
- What is the ratio of updates to reads for a particular field?
Your main choices for structuring the data are:
- For “one-to-few”, you can use an array of embedded documents
- For “one-to-many”, or on occasions when the “N” side must stand alone, you should use an array of references. You can also use a “parent-reference” on the “N” side if it optimizes your data access pattern.
- For “one-to-squillions”, you should use a “parent-reference” in the document storing the “N” side.
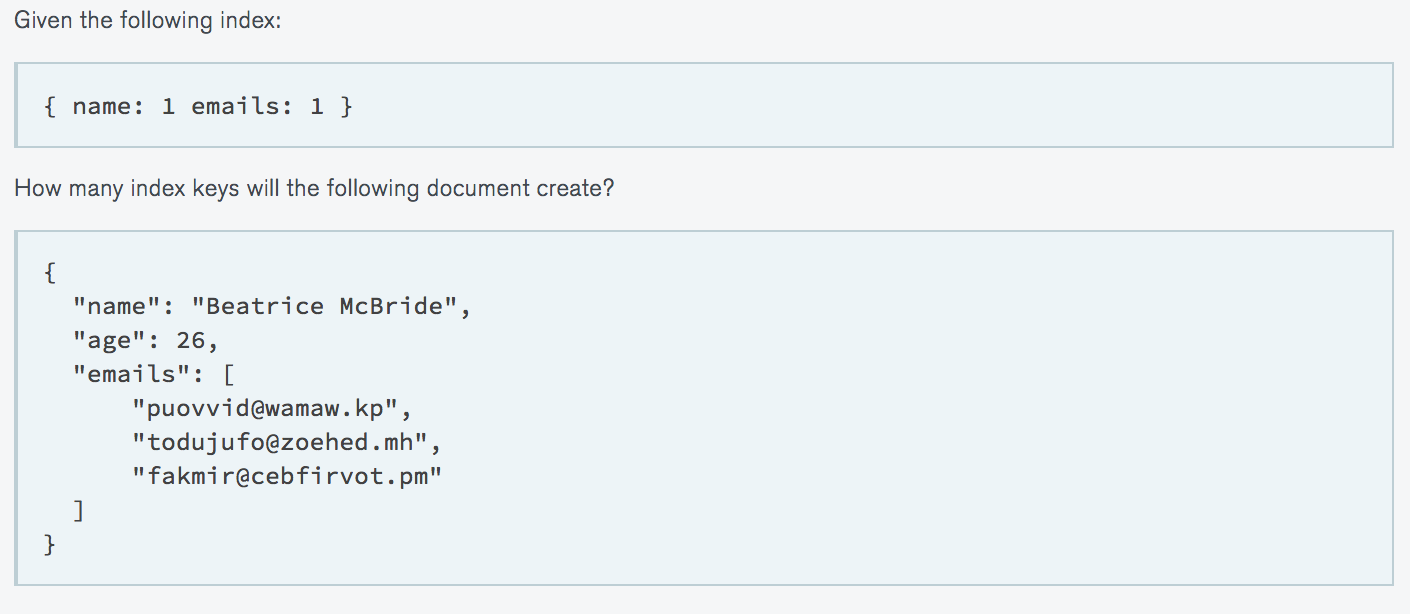
MONGODB INDEXES
-
Indexes are data structures that store data set in easily traversable form.
-
Indexes help execute queries efficiently without performing a collection scan.
-
MongoDB supports the following indexes— single field, compound indexes, hashed indexes, geoIndexes, unique, sparse, partial, text… and so on.
-
For fast query operation, the system RAM must be able to accommodate index sizes.
-
You can create, modify, rebuild, and drop indexes.
-
The geospatial indexes help query geographic location by specifying a specific point.
Default _id based index is created automatically
- Single fields. Single fields are simple indexes that index only one field in a collection. MongoDB can usually only use one index per query, but in some cases, the database can take advantage of more than one index to reply to a query (this is called index intersection).
- Compound indexes. Compound indexes are indexes that have more than one indexed field, so ideally, the most restrictive field should be to the left of the B-tree. If you want to index by sex and birth, for instance, the index should begin by birth, as it is much more restrictive than sex.
- Multikey Index: To index array data, MongoDB uses multikey indexes. When indexing a field with an array value, MongoDB makes separate index entries for each array element.
- Hashed indexes. MongoDB supports hash-based sharding and provides hashed indexes. These indexes the hashes of the field value.
- GeoIndexes. GeoIndexes are a special index type that allows a search based on location, distance from a point and many other different features.
INDEX TYPES - Unique indexes. Unique indexes work as in relational databases. They guarantee that the value doesn’t repeat and raise an error when we try to insert a duplicated value.
- Text indexes. Text indexes in MongoDB help search for text strings in documents of a collection. You can create a text index for field or fields containing string values or an array of strings.
- Sparse indexes. This index ensures that queries search document entries having an indexed field. Documents without indexed fields are skipped during a query.
- TTL indexes. These are special indexes in MongoDB used to automatically delete documents from a collection after a specified duration of time. This is ideal for deleting information, such as machine-generated data, event logs, and session data that needs to be in the database for a shorter duration.
Single Field Index
{
"_id": 3,
"item": "Book",
"available": true,
"soldQty": 144821,
"category": "NoSQL",
"details": {
"ISDN": "1234",
"publisher": "XYZ Company"
},
"onlineSale": true,
"stock" : 25
}db.items.createIndex( { “item" : 1 } )
db.items.createIndex( { "details.ISDN" : 1 } )
Compound Indexes
db.products.createIndex( { "item": 1, "stock": 1 } )
db.products.createIndex( {
"item": 1,
"available": 1,
"soldQty": -1
})-
If sorted documents cannot be obtained from an index, the results will get sorted in the memory.
-
Sort operations executed using an index show better performance than those executed without using an index.
-
Sort operations performed without an index gets terminated after exhausting 32 MB of memory.
-
Sort order is important for compound indexes because it helps determine if the index can support a sort operation
SORT ORDER



TTL indexes expire documents after the specified number of seconds has passed since the indexed field value; i.e. the expiration threshold is the indexed field value plus the specified number of seconds.
If more than one field has an array value,
you cannot create a compound multikey index.

Hashed Indexes
-
The hashing function combines all embedded documents and computes hashes for all field values.
-
The hashing function does not support multi-key indexes.
-
Hashed indexes support sharding, uses a hashed shard key to shard a collection, ensures an even distribution of data.
-
Hashed indexes support equality queries, however, range queries are not supported.
-
You cannot create a unique or compound index by taking a field whose type is hashed. However, you can create a hashed and non-hashed index for the same field. MongoDB uses the scalar index for range queries.
TTL Indexes
-
They are not supported by compound indexes which ignore expireAfterSeconds
-
The _id field does not support TTL indexes.
-
TTL indexes cannot be created on a capped collection because MongoDB cannot delete documents from a capped collection.
-
It does not allow the createIndex() method to change the value of expireAfterSeconds of an existing index.
-
You cannot create a TTL index for a field if a non-TTL index already exists for the same field. If you want to change a non-TTL single-field index to a TTL index, first drop the index and recreate the index with the expireAfterSeconds option.
The TTL background thread runs on both primary and secondary nodes. However, it deletes documents only from the primary node.
Unique Indexes
- If you use the unique constraint on the compound index, then MongoDB will enforce uniqueness on the combination of all those fields which were the part of the compound key.
- If the indexed field in a unique index has no value, the index stores a null value for the document. Because of this unique constraint, MongoDB permits only one document without the indexed field.
- In case there is more than one document with a valueless or missing indexed field, the index build process will fail and will display a duplicate key error. To filter these null values and avoid error, combine the unique constraint with the sparse index.
- An index that combines both sparse and unique does not allow the collection to include documents having duplicate field values for a single field. However, it allows multiple documents that omit the key.
Text Indexes
- To access text indexes, trigger a query using the $text (read as text) query operator.
-
When you create text indexes for multiple fields, specify the individual fields or use the wildcard specifier ($**)
-
MongoDB supports various languages for text search. The text indexes use simple language-specific suffix stemming instead of language-specific stop words, such as “the”, “an”, “a”, “and”. You can also choose to specify a language for text search.
-
If the index language is English, text indexes are case-insensitive for all alphabets from A to Z.
db.collection.createIndex({subject: "text",content: "text"})
db.collection.createIndex({ "$**": "text" },{ name: "TextIndex" })
db.customer.createIndex({“item”: “Text”},{ default_language: "spanish"})
Index Creation
- By default, when indexes are created, all other operations on a database are blocked(queued).
-
Therefore, for index building operations which may consume longer time, you can consider the background operation and thus make MongoDB available even during the entire operation.
- By default, the background is false for building MongoDB indexes.
- When MongoDB is creating indexes in the background for a collection, you cannot perform other administrative operations (such as runrepairDatabase, drop the collection etc,) involving that collection.
db.items.createIndex( {item:1},{background: true})


Remove Indexes
db.accounts.dropIndex( { "tax-id": 1 } ) // -> Single Index drop
db.collection.dropIndexes() // -> Drop all Indexes

To modify an index, first, drop the index and then recreate it. Perform the following steps to modify an index.
Measure Index Use & Control Index Use
- The explain() method can be used to print information about query execution.
- The explain method returns a document that explains the process and indexes used to return a query. This helps to optimize a query.
- Using the db.collection.explain() or the cursor.explain() method helps measure index usages.
- In case you want to force MongoDB to use particular indexes for querying documents, then you need to specify the index with the hint() method.
db.items.find({item: “Book”, available : true }).hint({item:1}).explain(“executionStats”)
db.items.explain("executionStats").find({item: “Book”, available : true }).hint( { item:1 } )
Which of the following queries can use an index on the zip field?
- db.addresses.find( { zip : 55555 } )
- db.addresses.find( { city : "Newark", state : "NJ" } )
- db.addresses.find()
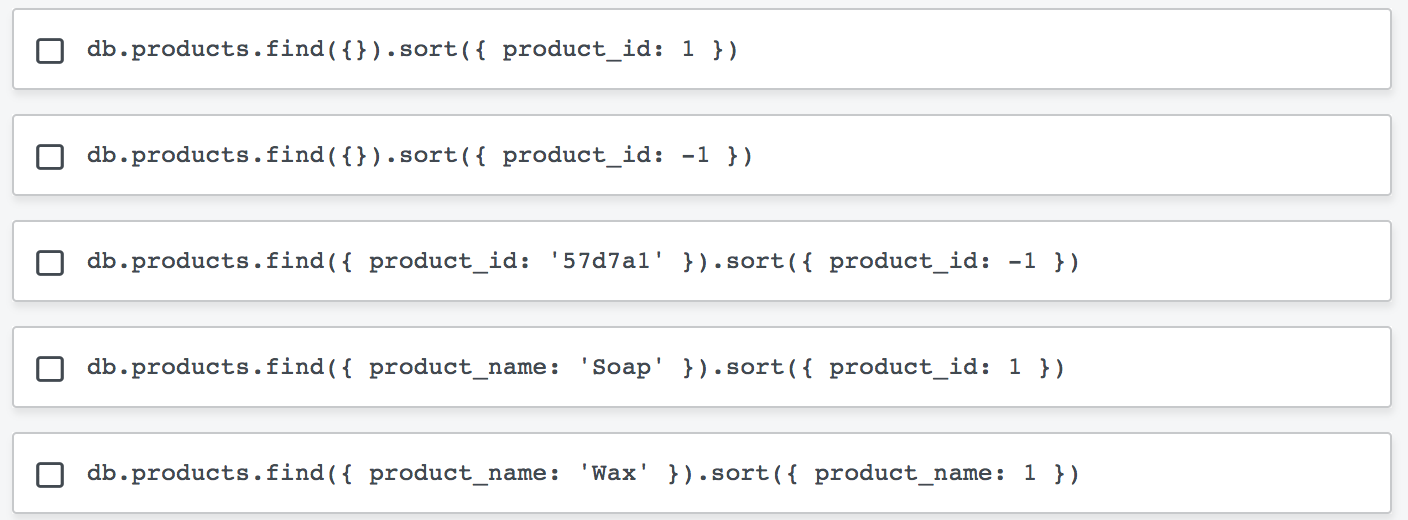
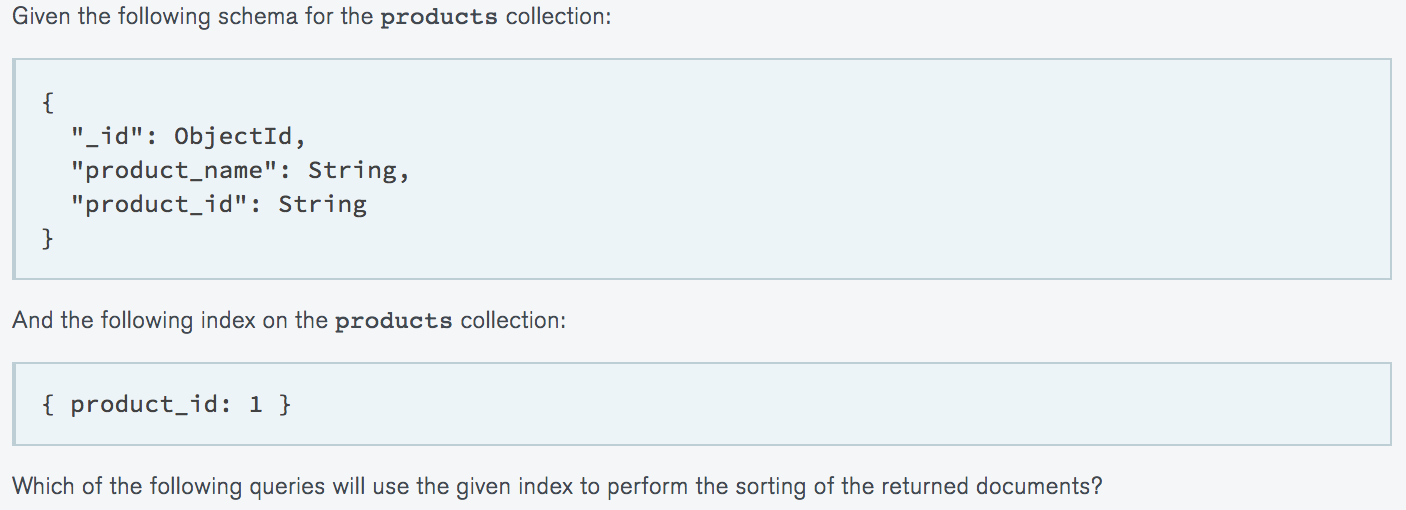
Which of the following statements are true?
- Index prefixes can be used in query predicates to increase index utilization.
- Index prefixes can be used in sort predicates to prevent in-memory sorts.
- We can invert the keys of an index in our sort predicate to utilize an index by walking it backwards.
- It's impossible to have a sorted query use an index for both sorting and filtering.