Writing
your own
full-text
search engine

/presentation/twitter-bird-light-bgs.png) and
and
/presentation/octocat.png) and
and

Anatomy of a search server
Information Management
api
replication
caching
consistency
persistence
management
Information Retrieval
indexing
querying
suggestions
ranking
sorting
highlighting
Indexing
Analyzing each document with a tokenizer to find the terms
Can be as simple as splitting on space
In order to increase index quality and compress it different techniques can be used
Token processing
Stemming and lemmatization is the process of reducing words to their common form
- Port Stemmer
- Snowball
- KStem
- Hunspell
Stoplist helps with ignoring very common words.
Lucene contains analyzers for different languages.
Querying
Finding documents that matches the query
Standard Boolean Model
Based on set theory it powers AND/OR/NOT queries and will approve all the documents whos indexes fullfills the predicate
Suggestions
Based on the index we want to be able to autocorrect
or suggest alternative query terms
Levenshtein distance
Example:
croccodial => crocodile
- deletion: croccodial
- replacement: crocodill
- replacement: crocodile
Straightforward levehnstein can be a problem since it takes O(n*m) so with a really big index this can become expensive
Levenshtein automata
Provides an O(n) time test with any string where n is the length of the query term
A finite state machine is constructed based on the query term and an edit distance and it's used to test other strings
Lucene uses a Levenshtein automata translated from a python implementation by one Jean-Philippe Barrette-LaPierre to Java because the Lucene committers originally didn't understand how it worked and couldn't get their own implementation working!
Ranking
When we have found documents that matches the query we want to sort them by relevance
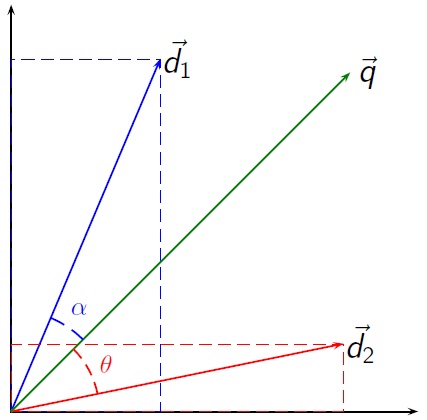
Vector Space Model
We represent both the document and the query as vectors
The angle between the two vectors is our similarity score and as it gets smaller the documents are more similar
Weighting the documents
We wish to weigh the documents such that we can represent them as vectors
Many different ways and variations to weighting exist
Term frequency–inverse document frequency
Term frequencies can be raw frequencies or boolean frequencies or augmented frequencies to prevent bias toward longer documents
Similar to the stoplist during analysis the inverse document frequency gives lower weight to terms that are very common in the document corpus.
Calculating the similarity
Since we're using cosine the larger the similarity score the more relevant.