HTTP(s) / REST / WOA
{firstname:'Stéphane' ,
lastname : 'Michel',
job: 'Software Craftsman'}
© Stéphane Michel

Sommaire / Concepts clés




SOMMAIRE
HTTP
Un peu d'histoire
1990 au CERN
1990 au CERN
Créé par Tim Berners-Lee en 1994 au MIT
Communauté internationale open source Définition des standards du web
HTML , HTML5, CSS, XML, PNG, SVG, WebCGM, MathML, XSLT, etc.

HTTP
Principes








Principes
Modèle OSI
| n° | Couche | Norme |
|---|---|---|
| 7 | Application | Web |
| 6 | Présentation | HTML / XML |
| 5 | Session | HTTP / HTTPS |
| 4 | Transport | TCP |
| 3 | Réseau | IP |
| 2 | Liaison | Ethernet / xDSL |
| 1 | Physique | RJ45 / RJ11 / RJ12 Câbles Cat. 5 et + |

Méthodes
| HTTP Method | RFC | Request Has Body | Response Has Body | Safe | Idempotent | Cacheable |
|---|---|---|---|---|---|---|
| GET | RFC 7231 | Optional | Yes | Yes | Yes | Yes |
| HEAD | RFC 7231 | No | No | Yes | Yes | Yes |
| POST | RFC 7231 | Yes | Yes | No | No | Yes |
| PUT | RFC 7231 | Yes | Yes | No | Yes | No |
| DELETE | RFC 7231 | No | Yes | No | Yes | No |
| CONNECT | RFC 7231 | Yes | Yes | No | No | No |
| OPTIONS | RFC 7231 | Optional | Yes | Yes | Yes | No |
| TRACE | RFC 7231 | No | Yes | Yes | Yes | No |
| PATCH | RFC 5789 | Yes | Yes | No | No | No |
Sources ici
Méthodes
get
post
La majorité des requêtes sont en GET.
Les paramètres sont dans l'URL (taille limite)
Formulaires
Paramètres dans le corps de la requête : sans limite de taille (fichiers, etc.)
Requête
curl --trace-ascii curl.trace http://www.w3c.com/index.html
== Info: Connected to www.w3c.com (69.172.201.153) port 80 (#0)
=> Send header, 75 bytes (0x4b)
GET /index.html HTTP/1.1
Host: www.w3c.com
User-Agent: curl/7.54.0
Accept: */*
<= Recv header,
HTTP/1.1 200 OK
Server: nginx
Date: Sat, 17 Nov 2018 11:23:45 GMT
Content-Type: text/html
Transfer-Encoding: chunked
Connection: keep-alive
Keep-Alive: timeout=20
Cache-Control: no-cache
<= Recv data, 1460 bytes (0x5b4)
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3
.org/TR/html4/strict.dtd">.<html>.<head>.<meta http-equiv="Conte
...
Requête
Réponse
HTTP/1.1 Request header
Page dont est issue la requête (suivi de lien depuis un browser)
Permet de tracer / profiler les arrivants sur un site
User-agent
Famille / modèle du client (browser, version, curl, mobile ou non, etc.)
Permet au serveur de prendre en compte dans sont retour les limites/possibilités connues du client.
Referer
Liste des champs d'entête ici
HTTP/1.1 Request header
Authorization: Bearer 098ec4556.566GE654.566G677
Authorization
Permet de porter les informations qui permettent la connexion au serveur (ici un jeton JWT)
Accept-Encoding: gzip, deflate
Permet d'indiquer que le client supporte la compression des gzip lors des échanges
Accept-Encoding
HTTP/1.1 Request header
Indique au serveur les mime-types supportés/attendus par le client.
Accept: application/json
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept: application/xml;q=0.9,*/*;q=0.8
Accept: */*
Support de tout les types
XML + Poids sur les préférences
HTML / XHTML / XML + Poids sur les préférences (détail ici)
JSON (REST)
Accept
Code retour
Le code retour des requêtes HTTP est standardisé par le w3c
200 : OK
4xx : erreur liée à la requête
401 : unauthorized
403 : Forbidden
201 : created
2xx : pas d'erreur
404 : page not found
405 : method not allowed
304 : Not Modified
301 : Moved Permanently
3xx : redirection
5xx : erreur interne au serveur (on n'aime pas trop ça...)
500 : Internal Server Error
Voici les principaux
Web Services
Principes
Echanger des données entre systèmes hétérogènes
Principes de séparation données / présentation
2 technologies ont émergé à partir de 2000 :
SOA (SOAP) et WOA (REST)
Plusieurs tentatives à la fin des années 90
CORBA (multi langage, définition d'interface ), DCOM (Microsoft, copie de CORBA en plus complexe)
Bien avant que les applications Web (basée sur HTML/HTTP) n'émergent
SOA / SOAP
"Orienté service"
SOA 1/3
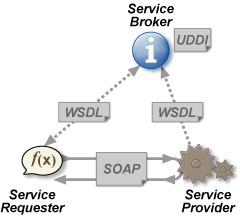
Un annuaire de service : Service Broker
Des fournisseurs de services : Service Provider
Des consommateurs : Service Requester
Service Oriented Architecture
Objectif : échanger de l'information entre systèmes qui ne se connaissent pas
SOA 2/3
Agnostique au protocol réseau sous jacent (HTTP, RMI, RPC, etc.)
Usage majoritaire de HTTP
Basé sur l'écosystème XML
Repose sur des normes du W3C :
SOAP (actuellement 2.0) : "Simple" Object Access Protocol
WSDL : Web Services Description Language
Définition précise/stricte des interfaces (nom de méthodes, paramètres, types de paramètres, retours, erreurs, mode d'authentification, etc.)
SOA 3/3
La "grosse berta"
Très outillé, très structuré tout y a été pensé et spécifié...
Mais :
Lourd à mettre en place
Très, très verbeux
Perf minables (pas fait pour de l'usage intensif)
Adapté aux échanges entre "gros" systèmes qui nécessitent une définition stricte des interfaces
Conclusion
SOAP vs REST
Ce qu'ils en disent
Nick Gall - VP Gartner Group - Position Paper For the Workshop on Web of Services for Enterprise Computing
Web Services based on SOAP and WSDL (hereinafter WS-*) are the technology standards underlying the Service-Oriented Architecture (SOA) wave rolling through enterprise IT for the past five or so years.
WS-* specifically, and SOA generally promised to succeed where traditional middleware failed, ie to provide loosely coupled, extensible, and less complex integration networks. Unfortunately, SOA appears to following in the footsteps of all the other middleware waves...
SOAP vs REST
Ce qu'ils en disent
David Orchard, BEA Systems -
Given the complexity of just SOAP and WSDL, how many developers will really be able to move to the full stack?
SOAP vs REST
Ce qu'ils en disent
Steve Vinoski , Former VP & Chief Architect of IONA Technologies -
If I were an enterprise architect today…I’d be looking to solve everything I possibly could with dynamic languages and REST !
I’d avoid ESBs and the typical enterprise middleware frameworks unless I had a problem that really required them.
I’d also try to totally avoid SOAP and WS-*” SOAP vs REST“
WOA / REST
"Orienté ressource"
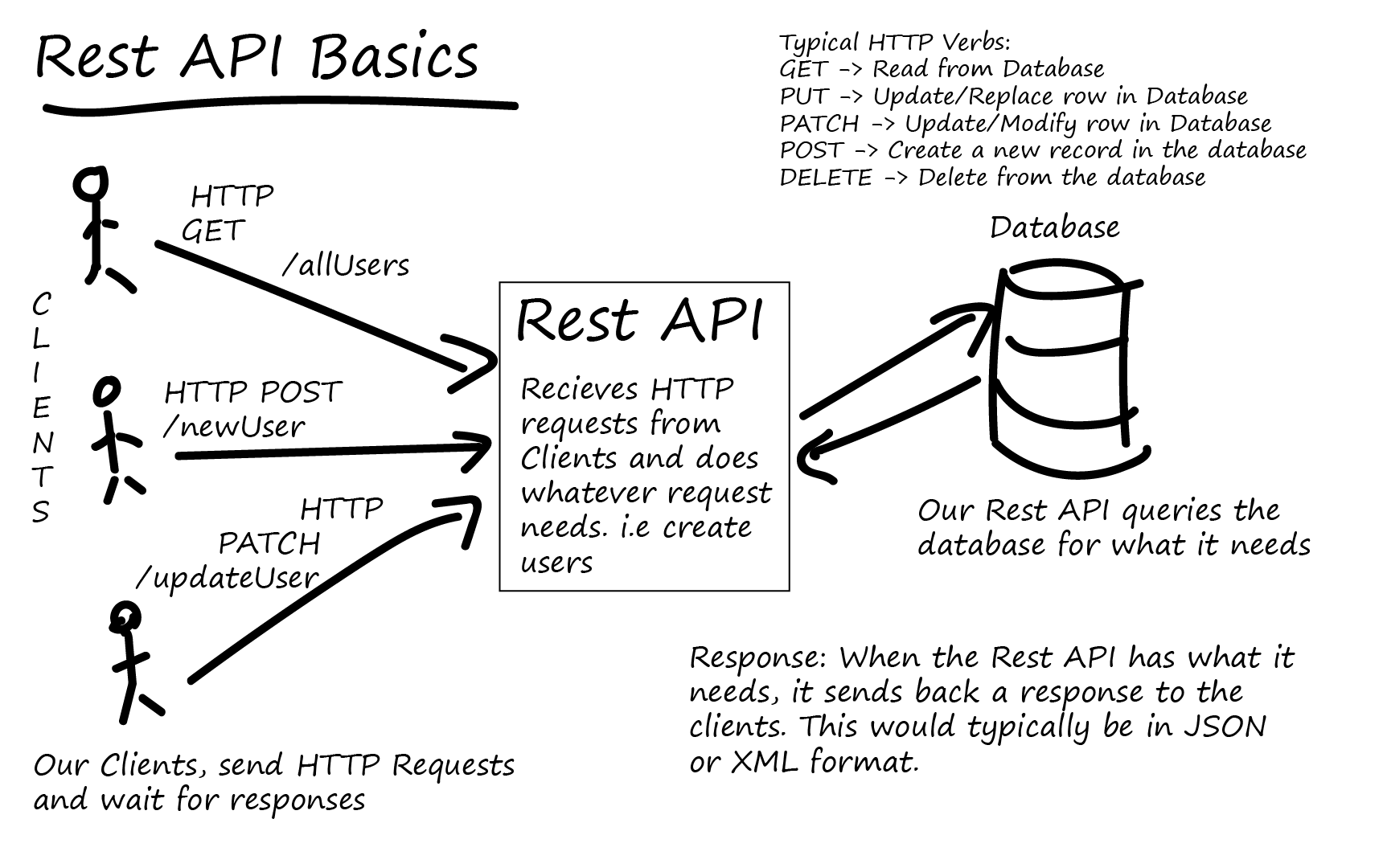
REST
Concept inventé par Roy Fielding en 2000
Principaux objectifs :
Performances
Capacité de monté en charge (Scalability)
Portabilité
Simplicité
Tolérance aux pannes (reliability)
Est rapidement devenue le protocole Web Service pour les applications Web (AJAX, SPA) et les application lourdes (WPF).
Representational state transfer
Principes 1/2
Interface basée sur la sémantique des méthodes HTTP et les codes HTTP pour les retours
Simple et souple (à opposer à SOAP)
Echanges en XML ou JSON (mais on préfèrera JSON)
Appels sour forme d'URL
GET http://mon.server.com:80/rest/v1/customers
DELETE http://mon.server.com:80/rest/v1/customers/3456
Principes 2/2
| Uniform Resource Locator (URL) | GET | PUT | PATCH | POST | DELETE |
|---|---|---|---|---|---|
| Liste d'éléments https://mon.api.com/resources/ |
Retourne un ensemble d'éléments ou d'URI | Remplace l'ensemble des éléments par un nouvel ensemble d'éléments | N/A | Ajoute un nouvel élément à la collection. Retourne généralement l'élément ou son URI | Supprime tous les éléments |
| Un élément spécifique https://mon.api.com/resources/itm17 |
Retourne un élément spécifique | Remplace un élément de l'ensemble par un nouvel élément | Met à jour un l'élément. | N/A | Supprime l'élément. |
Utilisation des méthodes HTTP
HTTP Status Code
| Status Code | Description |
|---|---|
| 200 OK | Code OK par défaut. Utilisé lors de GET et mise à jour PUT/PATCH |
| 201 Created | Indique que la ressource a bien été créée. Typiquement après un PUT ou un POST. |
| 202 Accepted | Indique que la requête a bien été acceptée. Typique des appels de traitements asynchrones. |
| 204 No Content | La demande a bien été traitée mais ne retourne aucune donnée. Souvent retournée après un DELETE. |
| 206 Partial Content | La ressource retournée est partielle. Cas de ressources paginées. |
Success
HTTP Status Code
| Status Code | Description |
|---|---|
| 400 bad request | Erreur générale pour une requête qui ne peut pas être satisfaite. Le body contient le détail de l'erreur en JSON {"error":"...", "error_description":"..."} |
| 401 Unauthorized | Le service nécessite d'être authentifié. |
| 403 Forbidden | La personne est authentifiée mais ses droits ne sont pas suffisants. |
| 404 Not Found | La ressource demandée n'existe pas. |
Client error
HTTP Status Code
| Status Code | Description |
|---|---|
| 405 Method not allowed | La méthode HTTP n'est pas supportée par le serveur ou le client n'a pas les droits pour l'appeler |
| 406 Not Acceptable | Le serveur ne peut retourner une donnée dans le format supporté par le client (et précisé dans le header : Accept, Accept-Encoding, Accept-Langage). Exemple : Le client demande un PDF et le serveur ne sait pas retourner les données dans ce format. |
Client error
HTTP Status Code
| Status Code | Description |
|---|---|
| 500 Internal Server Error | La requête est bien parvenue au serveur (c'est déjà ça !) mais une erreur est survenue lors de son traitement sur le serveur. Le client ne peut pas y faire grand chose mais doit prévoir ce cas. |
Server error
REST URI
Bonnes pratiques
REST URI
En théorie, pas de normes stricte, plusieurs écoles
http://server/resources?id=3456
http://server/resources/3456
Des ajustements sont possibles suivant l'API REST utilisée et suivant le serveur web utilisé : PATCH et DELETE sont parfois remplacés par de la sémantique dans l'URL
Exemple :
GET http://mon.seveur/resources/delete/4567
POST http://mon.seveur/resources/update/4567
Il arrive aussi que PUT ne soit pas utilisé et remplacé par une suppression puis un ajout
Ceci dit quelques bonnes pratiques ont vu le jour ces dernières années !
Bonnes pratiques
C'est pas parce que c'est le Bronx qu'il faut faire n'importe quoi (voir ici)
Règle 1 : N'importe qui doit être capable d'utiliser votre API REST sans se référer à la documentation (au moins dans les grandes lignes)
Règle 2 : Ne jamais proposer plus d'une manière de faire les choses
Règle 3 : Utiliser des termes standards/concrets et partagés pour nommer vos API, pas de termes "métier"
Règle 4 : Rester cohérent dans toute l'API (nommage, code retour, erreur, etc.)
CRUD
Create / Read / Update / Delete
Pour une persistance des objets (en BDD par exemple) il faut prévoir pour chacun d'eux les quatre méthodes
| Operation | SQL (ici SGBDr) | RESTful WS |
|---|---|---|
| Create | INSERT | POST |
| Read (Retrieve) | SELECT | GET |
| Update (Modify) | UPDATE | PUT / PATCH |
| Delete (Destroy) | DELETE | DELETE |
CRUD-LIKE operations
Bonnes pratiques
GET /users 200 Ok
GET /users/56784 200 Ok
DELETE /users/56784 204 No content
GET /users/56784/address 200 Ok
PATCH /users/56784 {"address":{...}}
200 Ok
PUT /users {"firstname":"...","name":"..."...}
201 Created
Nommage
Bonnes pratiques
GET /users
GET /users/45566
GET /user/45566
Le nom de la ressource est au pluriel
Utilisez des noms, pas des verbes
GET /orders
GET /getallorders Eventuellement POST /emails/455/send
Consistent case
id_user : snake_case idUser : camelCase iduser : minuscule
Peu importe mais
PARTOUT pareil
GET /users/45566/streets
Structure hiérarchique
Versioning
Bonnes pratiques
La version majeure de l'API doit faire partie de l'URL
GET /v1/users
GET /v1/users/45566
Une fois mise à disposition d'un client, l'interface de l'API ne peut plus bouger.
Seuls des correctifs de bug voire des ajouts sont possibles.
Si l'interface doit changer, il faut modifier le numéro de version
Gestion de la granularité
Bonnes pratiques
Eviter les retours JSON avec une profondeur de données supèrieure à 2
GET /users/56784
{"id":56784,
"first_name":"Pau",
"name":"Pat",
"parents":[
{"type":"mother", id:4567},
{"type":"father", id:45690}],
"address":{
"street":"Bd des Alysés",
"city":{"name":"Rennes"}}}
Réponses partielles
Bonnes pratiques
Offrir au client la possibilité de ne retourner qu'une partie des informations afin de limiter l'usage de la bande passante et de la mémoire du browser
GET /users/56784?fields=firstname,name,address(city)
{"id":56784,
"firstname":"Pau",
"name":"Pat",
"address":{"city":{"name":"Rennes"}}}
Tri des réponses
Bonnes pratiques
Offrir au client la possibilité de trier les résultats sur des propriétés
GET /users?sort=firstname,name
[{"id":56784,"firstname":"Aa","name":"Aa"...},
{"id":45354,"firstname":"Aa","name":"Bb"...},
{"id":34214,"firstname":"Bb","name":"Cc"...},
...
]
Pagination
Bonnes pratiques
Les API qui retournent des listes doivent offrir la possibilité de paginer les résultats.
GET /users?range=26-50
206 Partial Content
Content-Range: 26-50/25980
[{"id":56784,"firstname":"Aa","name":"Aa"...},
{"id":45354,"firstname":"Aa","name":"Bb"...},
{"id":34214,"firstname":"Bb","name":"Cc"...},
...
]
Filtrage des ressources
Bonnes pratiques
Les API qui retournent des listes doivent offrir la possibilité de filtrer les résultats.
GET /users?firstname=Aa
200 Ok
[{"id":56784,"firstname":"Aa","name":"Aa"...},
{"id":45354,"firstname":"Aa","name":"Bb"...}]
Mots clef réservés
Bonnes pratiques
Quelques mot-clefs réservés bien pratiques sur les API qui retournent des listes.
GET /users/count 200 Ok 25980
GET /users/first
200 Ok
{"id":56784,"firstname":"Aa","name":"Aa"...}
GET /users/last
200 Ok
{"id":98893,"firstname":"Zz","name":"Xx"...}

HTTP a été conçu à l'origine pour faire communiquer une application cliente avec un serveur applicatif !
SOAP permet de spécifier les échanges entre systèmes distants !
SOAP se base sur la sémantique HTTP (GET, POST, DELETE, PATCH) !
REST se base exclusivement sur HTTP !
REST privilégie la cohérence et le contrôle des données par rapport à la performance !
GET http://mon.server:3000/api/v1/mescommandes/4532
GET http://mon.server:3000/api/users?id=4532
Bonnes pratiques ou pas ?
DELETE http://mon.server:3000/api/users/delete
{"id":"4533"}
PATCH http://mon.server:3000/api/users/4532
{"name":"newName"}
POST http://mon.server:3000/api/users
{"id":"4533","name":"Deuf","lastname":"John"}
GET /v2/users/56784?fields=firstname,name
GET /v2/users/56784?sort=firstname
Bonnes pratiques ou pas ?
GET /v2/users?ranges=20-56&sort=name
GET /v2/users?firstname=Pa*
GET /v2/users/first
Résumé de l'épisode précédent
?
client
serveur
Problématique
L'échange de données

?
client
serveur
Quel protocole ?
HTTP(s) s'impose
Car l'infra physique (câbles, routeurs, etc.) et logique (protocoles) est déjà en place...
client
serveur
Mais HTTP,
c'est fait pour les pages web...
GET/index.html HTTP/1.0 Host: www.xyz.org Content-Type: text/html; charset = utf-8
HTTP/1.0 200 OK Content-Type: text/html; charset = utf-8 Content-Length: nnn <!DOCTYPE html>
<html><head>
<link rel="manifest" href="/manifest.json">
</head>
<body>
<div>bla bla bla </div>
</body></html>
client
serveur
Et on préférerait ne faire transiter que des data...
GET/mesData HTTP/1.0 Host: www.xyz.org
Des data et encore des data, mais que des datas, pas d'IHM...
client
serveur
Besoin de formalisation
принимать посредство
一位好老师是一位死老师
Ursprünglich komme ich

client
serveur
SOAP
POST /DateCreation HTTP/1.0 Host: www.xyz.org Content-Type: text/xml; charset = utf-8 Content-Length: nnn <?xml version = "1.0"?> <SOAP-ENV:Envelope xmlns:SOAP-ENV = "http://www.w3.org/2001/12/soap-envelope" SOAP-ENV:encodingStyle = "http://www.w3.org/2001/12/soap-encoding"> <SOAP-ENV:Body xmlns:m = "http://www.xyz.org/datecreation"> <m:GetDateCreation> <m:SchoolName>ESIR</m:SchoolName> </m:GetDateCreation> </SOAP-ENV:Body> </SOAP-ENV:Envelope>
HTTP/1.0 200 OK Content-Type: text/xml; charset = utf-8 Content-Length: nnn <?xml version = "1.0"?> <SOAP-ENV:Envelope xmlns:SOAP-ENV = "http://www.w3.org/2001/12/soap-envelope" SOAP-ENV:encodingStyle = "http://www.w3.org/2001/12/soap-encoding"> <SOAP-ENV:Body xmlns:m = "http://www.xyz.org/datecreation"> <m:GetDateCreationResponse> <m:DateCreation>mars 2010</m:DateCreation> </m:GetDateCreationResponse> </SOAP-ENV:Body> </SOAP-ENV:Envelope>
mais très verbeux...
C'est super structuré,
client
serveur
REST
GET /DateCreation/ESIR HTTP/1.0 Host: www.xyz.org Content-Type: text/xml; charset = utf-8 Content-Length: nnn
HTTP/1.0 200 OK Content-Type: application/json; charset = utf-8 Content-Length: nnn {"creationDate":"mars 2010"}
A ben voilà !
et REST c'est...
Des méthodes HTTP

Des codes de retour HTTP

De bonnes pratiques

Spécifie un format qui permet de documenter/décrire les API REST.
Issu du projet Swagger
Projet autonome depuis 2016
Des viewer OpenAPI permettent de visualiser la documentation, voire de tester l'API.
OpenAPI
La norme existe en plusieurs versions, version actuelle : V3.0.2 (octobre 2018)
Comble un manque de REST (vs les WSDL de SOAP)
Outillage
Plugin Visual Studio Code

Documentation ici
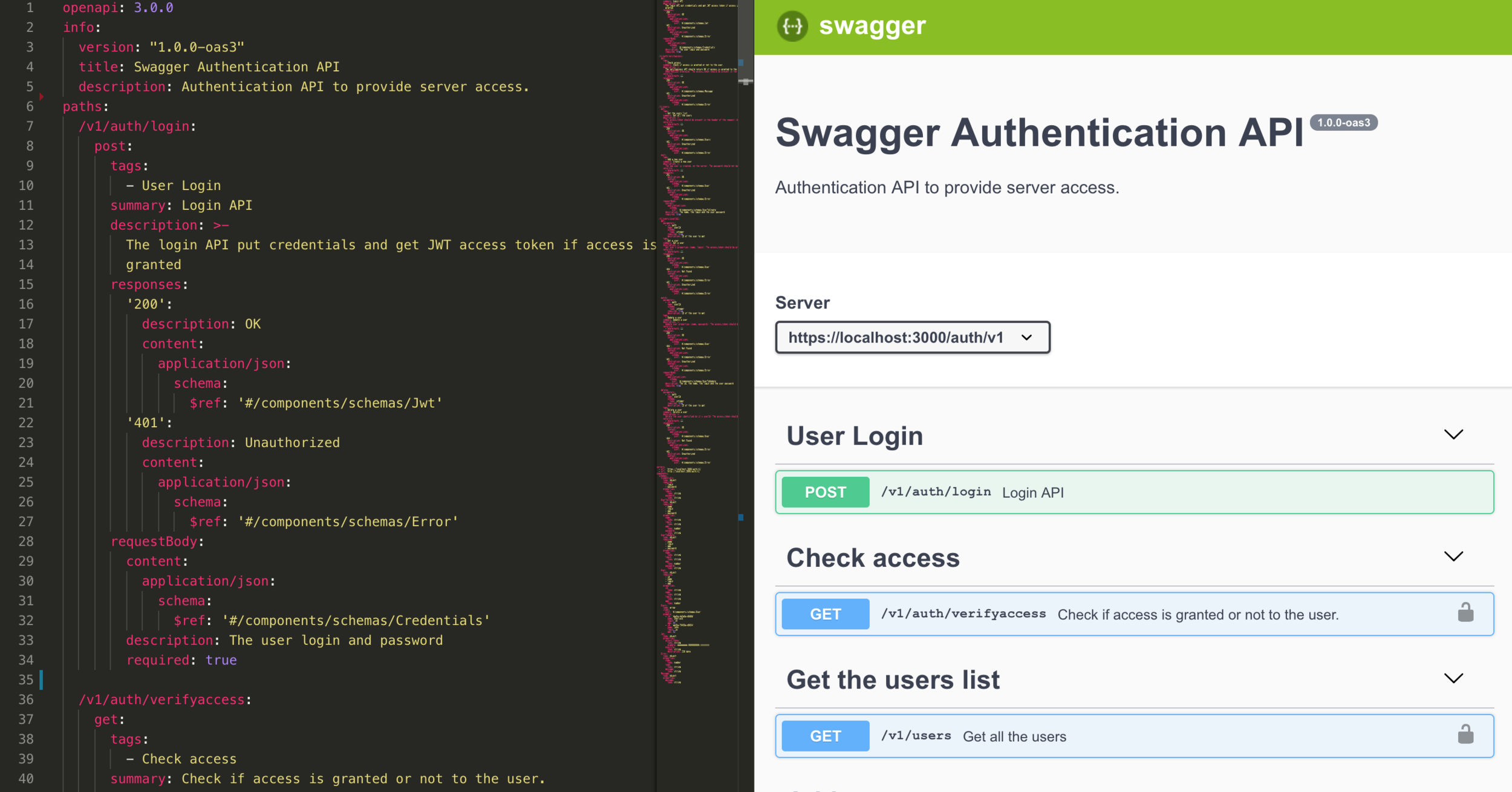
Outillage
Plugin Visual Studio Code
Stateful
vs
stateless
State quoi ?
Un site web a besoin de conserver/mettre à jour des informations liées à l'utilisateur pendant toute la durée de la session
Site marchant (panier, historique, etc.)
Site nécessitant une authentification (droits d'accès)
Bref a peu prêt tout les sites à l'exceptions des sites "statiques"
Stateful
Stateful
Client
Comment ça fonctionne ?
Utilisation des cookies.
Le serveur génère un id unique et lui associe un contexte (une session) qu'il conserve en local.
Set-Cookie: sessionid=38afes7a8; HttpOnly; Path=/
Le client stocke cet id de session et le place dans le header de toutes les requêtes qu'il fait ensuite au serveur.
Le serveur retrouve le contexte de l'utilisateur à partir de l'id de session.
Cookie: sessionid=38afes7a8
Il envoie au client cet id de session dans un cookie (voir ici pour plus de détails).
Stateful
Client
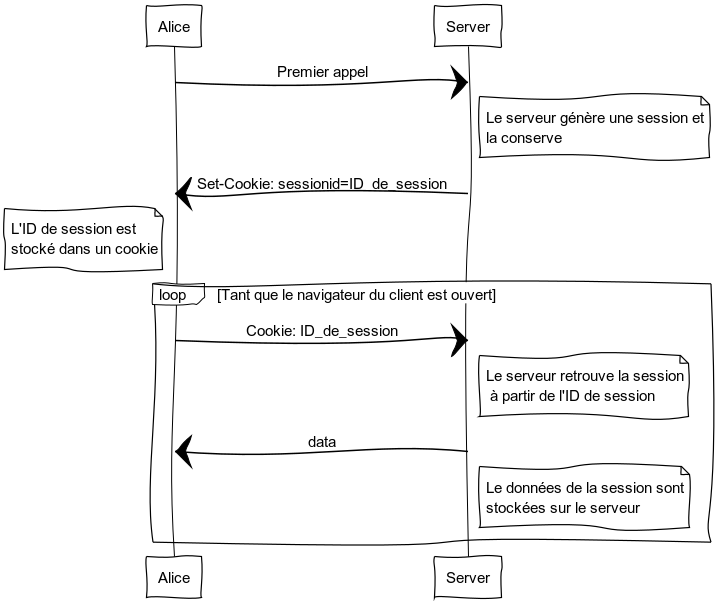
Stateful
Client
Méthode sur laquelle se sont construite les applis web depuis la fin des années 90.
Jusqu'à l'arrivée des SPA (Single Page Applications) vers 2010
Le serveur est associé/lié aux clients dont il détient la session.
Utilisation mémoire augmente avec le nombre de clients
Client
Cluster de serveur web
sur un ou plusieurs serveurs physiques
Load balancing en frontal
répartition de charge (hardware ou software)
Problème de la montée en charge

Comment gérer une augmentation du trafic ?
Client
Sessions persistantes en BDD (lent)
Duplication/recopie de sessions
mécanismes de recopie par message entre serveur... complexe, peu fiable...
mémoire partagée si même machine physique, complexe...
Limites du load balancing en stateful
Et les sessions utilisateurs on en fait quoi ?
Solution 1 : Géré par les serveurs
Client
Associer dans le load balanceur un user à un serveur spécifique afin que le serveur ait toujours la session de l'utilisateur qui l'appelle...
Limites du load balancing en stateful
Et les sessions utilisateurs on en fait quoi ?
- SessionID / cookies,
- @IP du client,
- contexte URL du serveur,
- nom du serveur,
- etc.
Sur quel critère ?
Solution 2 : Géré par le load balancer
Client
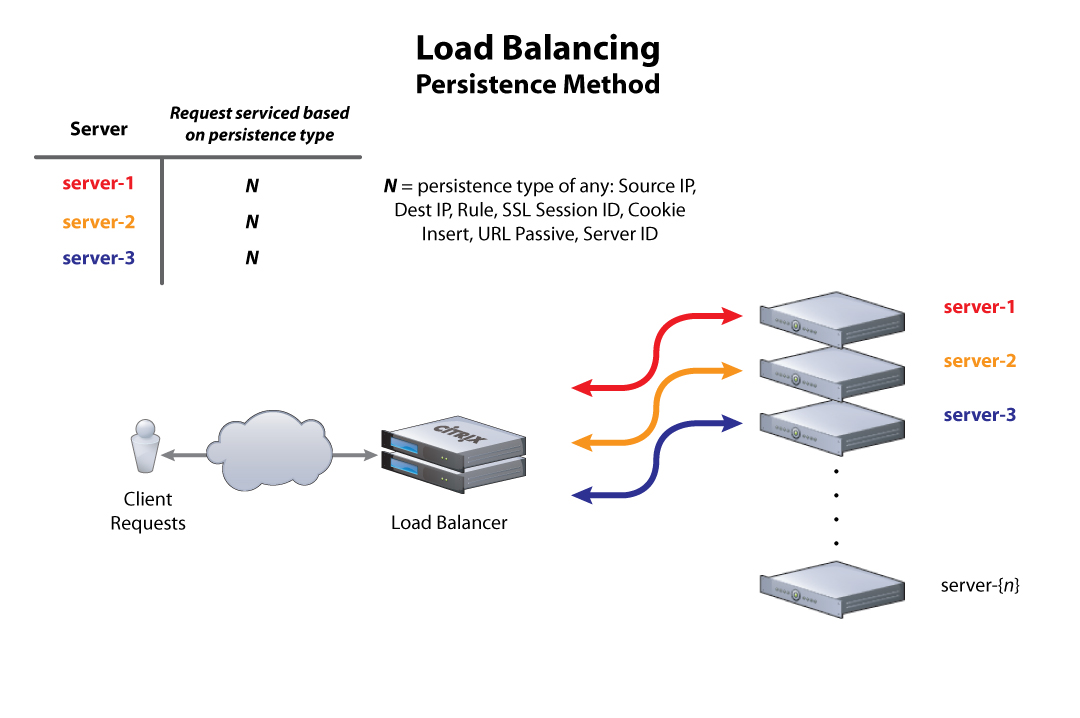
Limites du load balancing en stateful
Client
Problème complexe, solutions complexes...
Limites du load balancing en stateful
Oui mais, et si je dois relancer un serveur ? ou s'il crash ?
Bref... la grande merdasse...

Stateless
Stateless
Client
La session est conservée sur le client
Le serveur ne stocke plus la liste des sessions courantes !
Comment ça fonctionne ?
Stateless
Client
L'utilisateur est identifié et authentifié par un jeton :
- JWT (JSON Web Token) pour les SPA
- mais aussi cookies (pour les applis web classiques)
Ok, mais comment le serveur sait-il à qui il a affaire ?
Le jeton est placé dans le header HTTP de toutes les requêtes du client !
Le jeton contient de la donnée encodée, signé et lisible par le serveur
Stateless
Client
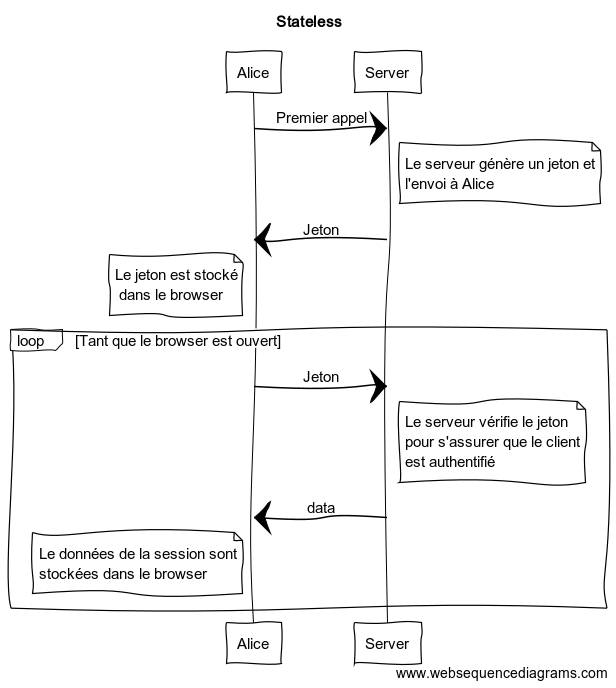
Stateless
Client
Simplification considérable de l'architecture côté serveur !
La gestion de la montée en charge devient :
moins nécessaire : plus faible utilisation des ressources
plus facile : il suffit d'ajouter des serveurs...
Stateless
Client
clients
serveurs

Stateless
Client
clients
serveurs
load balanceur
Client
Avec les applications web de type SPA (Single Page Application) on utilise le champ Authorization du header.
Jeton autoporteur
Impacts côté client
Avec les pages web classiques (ie. des pages qui n'utilisent pas AJAX) on utilise les cookies.
Authorization : bearer ae45d532e.fd456465...
Stateless est plus compliqué que stateful à mettre en oeuvre côté serveur !
Jusque dans les années 2010 stateful était l'architecture la plus répendue !
Stateful se base sur les cookies pour stocker un id de session
Stateless se base sur JWT ou sur les cookies pour stocker un jeton d'accès
OpenApi est à REST ce que le WSDL est à SOAP !
Swagger est l'ancêtre d'OpenAPI
Les performances d'un serveur stateless sont meilleures que celles d'un serveur stateful
Stateful ouvre les portes des architectures en micro services !
Rendre un serveur scalable est plus aisé s'il est stateless que s'il est stateful
Le jeton d'accès JWT contient des informations sensibles qu'il faut protéger (cryptage)
Comment sécuriser son API ?

5 Mythes
- Sans demande particulière, le développeur me fournira une solution sécurisée?
- Seuls les génies de l'informatique savent exploiter les failles des applications web.
- Mon site web est protégé puisqu'il utilise SSL.
- Je suis protégé contre les attaques, j'ai un firewall.
- Une faille sur une application interne n'est pas importante
Origine CLUSIF
OWASP : Open Web Application Security Project
Top 10 : des principales failles
We’re under attack! 23+ Node.js security best practices
OWASP ZAP (Zed attack Proxy) : Analyse les failles d'une application web (s'utilise comme un proxy).
Quelques outils utiles
Quelques attaques node.js ici
Objectif de l'attaque : rendre un site inaccessible
Méthode : surcharger le site en requêtes
Difficulté : très facile
DOS attack
Protection : limiter le nombre maximal de requêtes par client
Solution : mise en place d'un frontal gateway (nginx), load balancer, firewall ou encore par des middleware applicatif comme express-rate-limit
Bonus : permet également de se protéger contre une recherche de mot de passe par "force brute"
const rateLimit = ; app; // only if you're behind a reverse proxy (Heroku, Bluemix, AWS ELB, Nginx, etc) const limiter = ; // apply to all requests app;
DOS attack
ClickJacking
voir ClickJacking demo
Pour s'en protéger : X-Frame-Options dans le header HTTP
Ouverture d'un site dans une iframe en superposition d'un site de hack pour tromper l'utilisateur
Indique au navigateur que le contenu ne peut pas être embarqué dans une balise <frame>, <iframe> ou une balise <object>
- DENY : affichage dans iframe non autorisé
- SAMEORIGIN : uniquement si l'iframe et le contenu proviennent du même site
- ALLOW-FROM URI : uniquement si l'iframe provient de l'URI
Valeurs possibles :
Détails ici
Sniff
Détail ici
Pour s'en protéger : X-Content-Type-Options=nosniff
dans le header HTTP
Certains navigateurs (anciens maintenant) essaient de deviner (sniff) le mime-type des contenus binaires si le mime-type n'est pas précisé dans le header.
Problème de sécurité Potentiel (chargement de JS à la place d'un JPG).
DNS Prefetch Control
Détail ici
Pour s'en protéger : X-DNS-Prefetch-Control: off
dans le header HTTP
Par défaut, pour accélérer la navigation, la plupart des navigateurs tentent de résoudre les DNS de la page avant que l'utilisateur ne suive un hyperlien.
Problème de sécurité Potentiel (le provider du DNS, souvent google si 4.4.4.4 ou 8.8.8.8 récupère des informations sur les sites qui intéressent l'utilisateur à son insu).
Il peut aussi être désactivé dans les paramètres du browser
Powered-By
Détail ici
Pour s'en protéger on paramètre le serveur pour supprimer X-Powered-By du header HTTP
Les serveurs aiment bien ajouter dans le header un champ qui donne le type et parfois la version du serveur .
Les hackers adorent, ca leur permet de se concentrer sur les failles connues du serveur...
Helmet

Agglomère une ensemble de modules node qui règlent un bon packet de failles.
Ca coûte rien de l'utiliser...
const express = require('express') const helmet = require('helmet') const app = express() app.use(helmet())
ou mieux (en activant noSniff)
app.use(helmet({noSniff:true}))
Helmet
$ curl -i http://localhost:3000/v1/users/
...
HTTP/1.1 200 OK
X-Powered-By: Express
Content-Type: application/json; charset=utf-8
Content-Length: 367
ETag: W/"16f-52pT8zzxFPOAtUF1b4F57cArTZs"
Date: Mon, 11 Feb 2019 20:08:26 GMT
Connection: keep-alive
...
Sans helmet
Helmet
Avec helmet
$ curl -i http://localhost:3000/v1/users/ ... HTTP/1.1 200 OK X-DNS-Prefetch-Control: off X-Frame-Options: SAMEORIGIN Strict-Transport-Security: max-age=15552000; includeSubDomains X-Download-Options: noopen X-Content-Type-Options: nosniff X-XSS-Protection: 1; mode=block Content-Type: application/json; charset=utf-8 Content-Length: 367 ETag: W/"16f-52pT8zzxFPOAtUF1b4F57cArTZs" Date: Mon, 11 Feb 2019 20:09:06 GMT Connection: keep-alive ...
Lance un audit de sécurité sur les packages node.js du projet
(dispo à partir de npm 6)
npm audit

Comment sécuriser ses mots de passe ?
Stockage des mots de passe
Pour une appli simple on peut vouloir gérer soit même ses comptes utilisateurs (sans utiliser d'IdP du marché)
Ok mais attention !
Un mot de passe ne doit jamais être stocké en clair !
Stockage des mots de passe
Solutions
Cryptage du mot de passe ?
Oui mais où stocke-t-on le mot de passe ou la clef ?
Si la clef est volée la sécurité du système est cassée !
Il existe également des boitiers hardware pour gérer le stockage des mots de passe mais ils coûtent très cher.
Stockage des mots de passe
Solutions
On ne stocke pas le mot passe !
Comme les mots de passe sont souvent courts, pour sécuriser un peu plus on ajoute au mot de passe une chaîne de caractères "fixe" avant de calculer le hash.
On appelle ça du sel
On stocke son hash !
Il est quasi impossible de retrouver une chaîne de caractère à partir se son hash (SHA-256 par exemple) !
On vérifie le hash stocké avec le hash du mot de passe (plus le sel) saisi par l'utilisateur
Stockage des mots de passe
Calcul du hash avec du sel
"M0nP455w0RD"
"machainedeselsuperlongue"
+
a2003c53f87c1e5ef6efcebb3f53c74c3720887494c4a112fe39fcd203ecf3b3
SHA-256
C'est ça qu'on stocke en base
HTTPs
HTTP est un protocole lisible par simple analyse du réseau (sniffer TCP genre WireShark, tcpdump ou sniffer HTTP genre fiddler)
Cryptage SSL / TLS de la communication entre le client (browser) et le serveur HTTP.
Sécurisation du protocole HTTP : 3 axes
- Intégrité (integrity)
- Protection des échanges (Privacy)
- Et même authentification (Authentication)
Objectifs
Utilisation
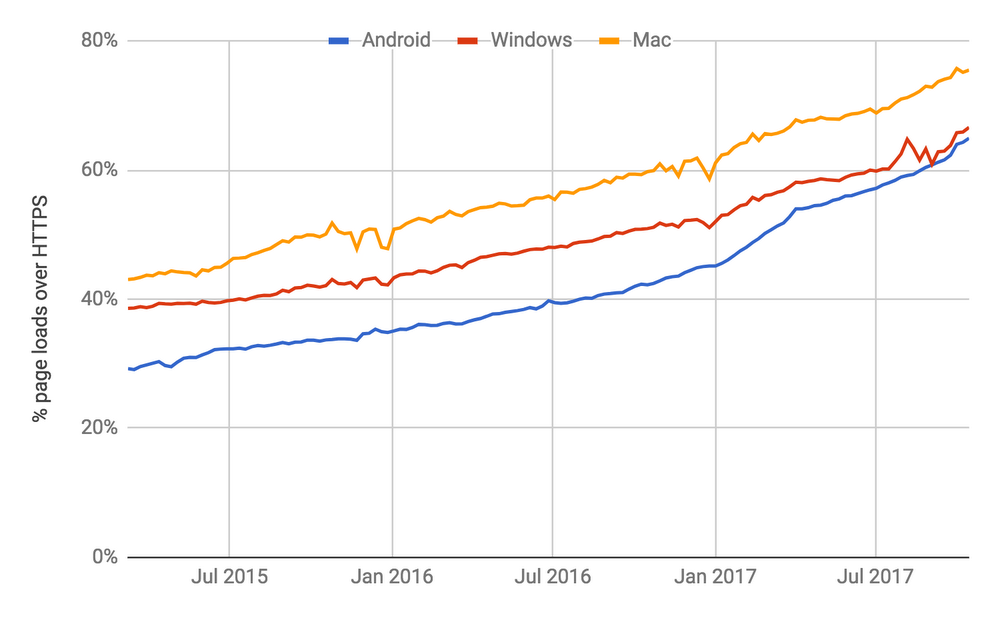
- Over 68% of Chrome traffic on both Android and Windows is now protected
- Over 78% of Chrome traffic on both Chrome OS and Mac is now protected
- 81 of the top 100 sites on the web use HTTPS by default
Encryptage du message HTTP avant la transmission par protocole TLS (par SSL sur les vieux systèmes).
Décryptage à la réception.
Basé sur du cryptage asymétrique (clefs publique/privée)
L'ensemble de la pile HTTP est cryptée :
- Requête : Header et body
- Réponse : Header et body
Seul est lisible le domaine / l'adresse IP du serveur et du client (car géré par la pile TCP)
Fonctionnement
TLS / SSL
Objectifs
Partager un secret entre le serveur et le client pour sécuriser les échanges à venir.
Le partage de secret est l'objectif du protocole TLS/SSL
Il s'opère par un ensemble de messages entre le client et le serveur que l'on appelle "Poignée de main" (handshake)
TLS / SSL
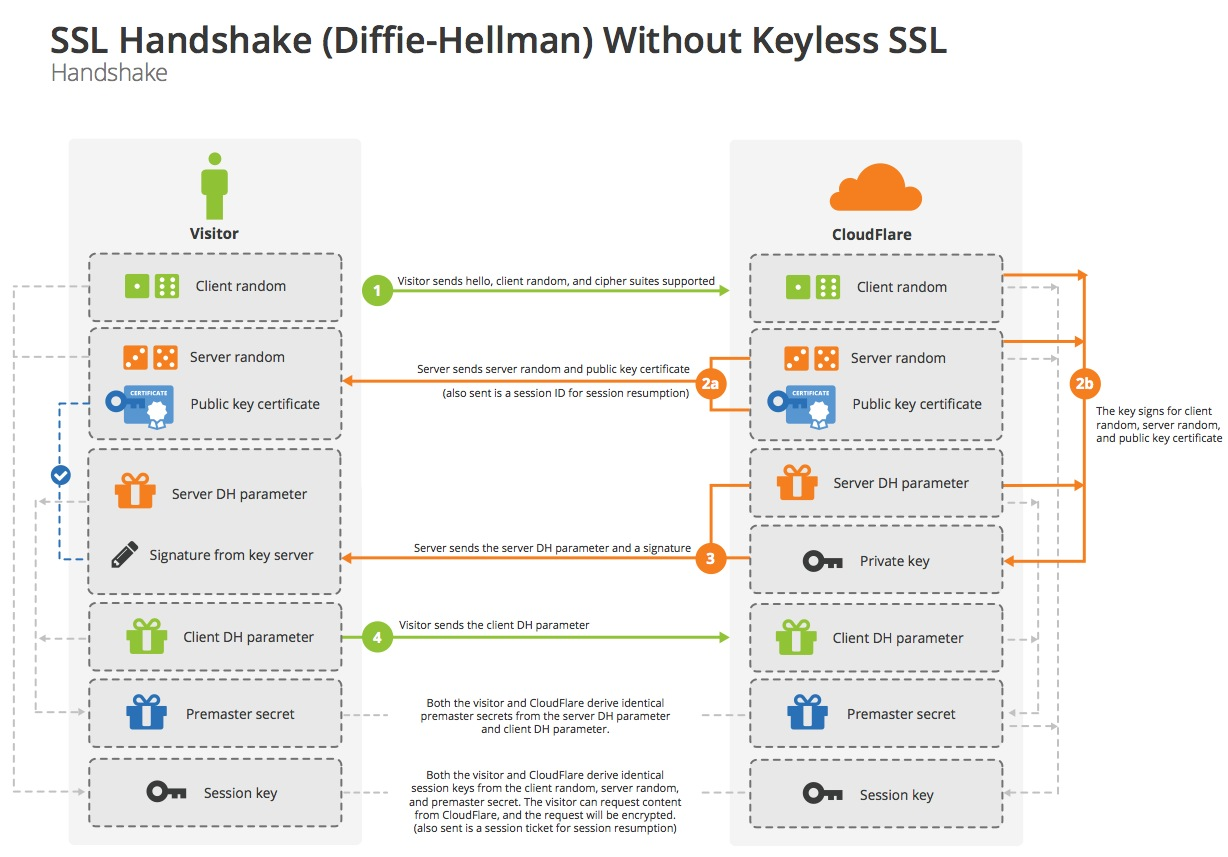
TLS / SSL
Sources ici
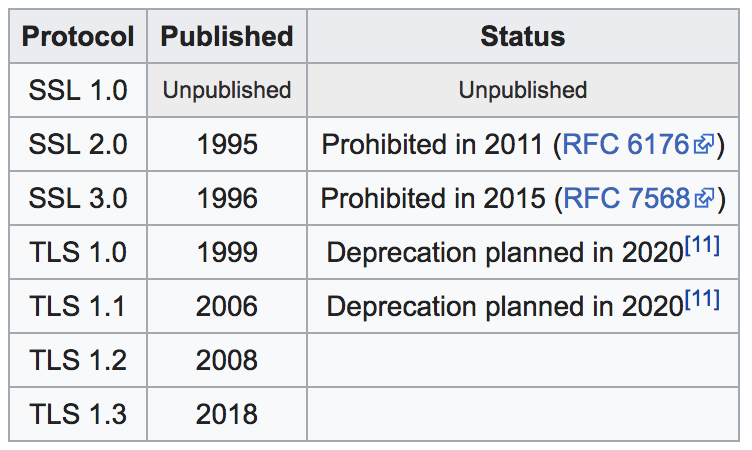
Histoire
Recommandation ANSSI ici
Recommandation ANSSI TLS 1.2 à défaut TLS 1.1
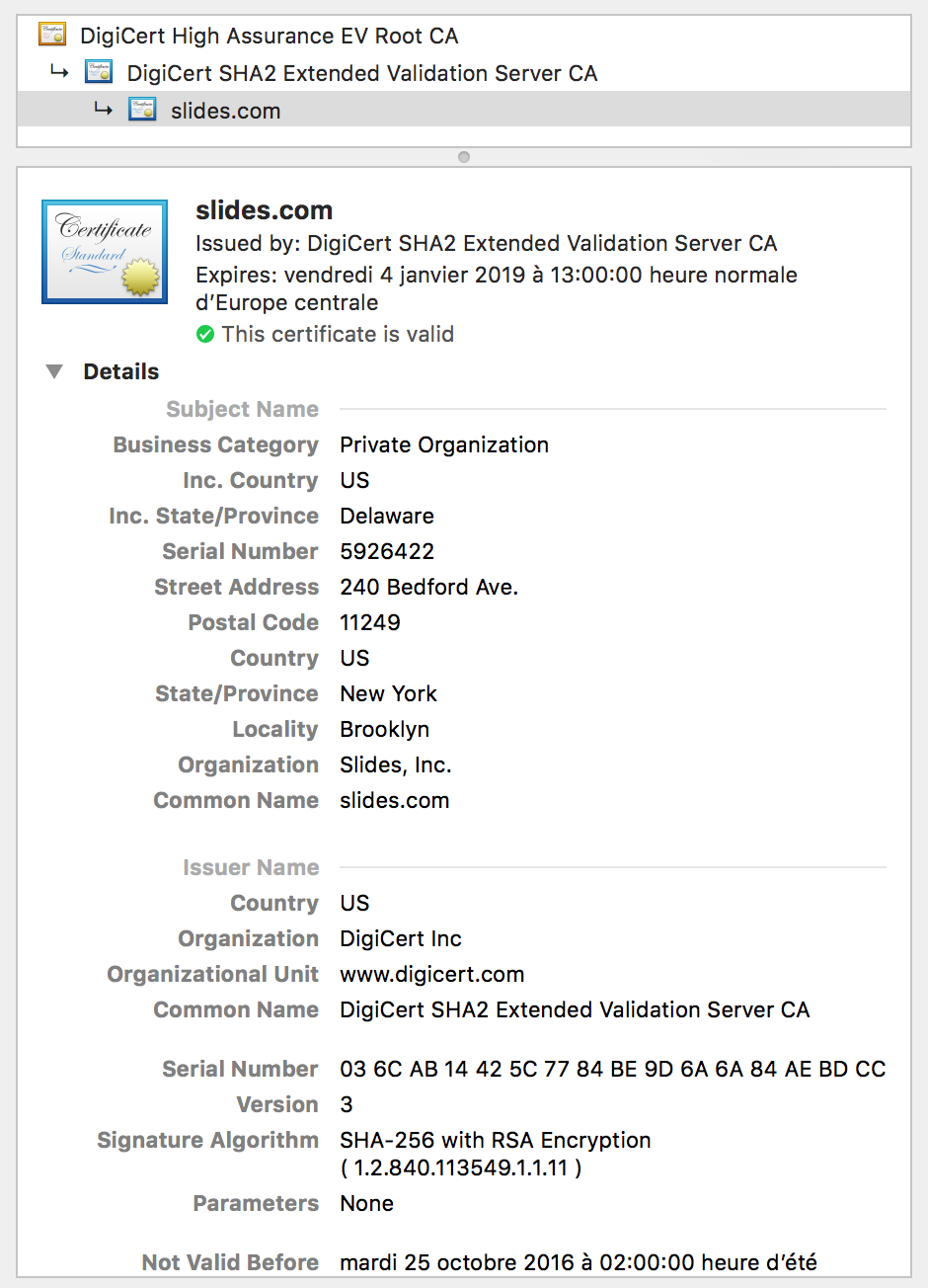
Certificat HTTPs
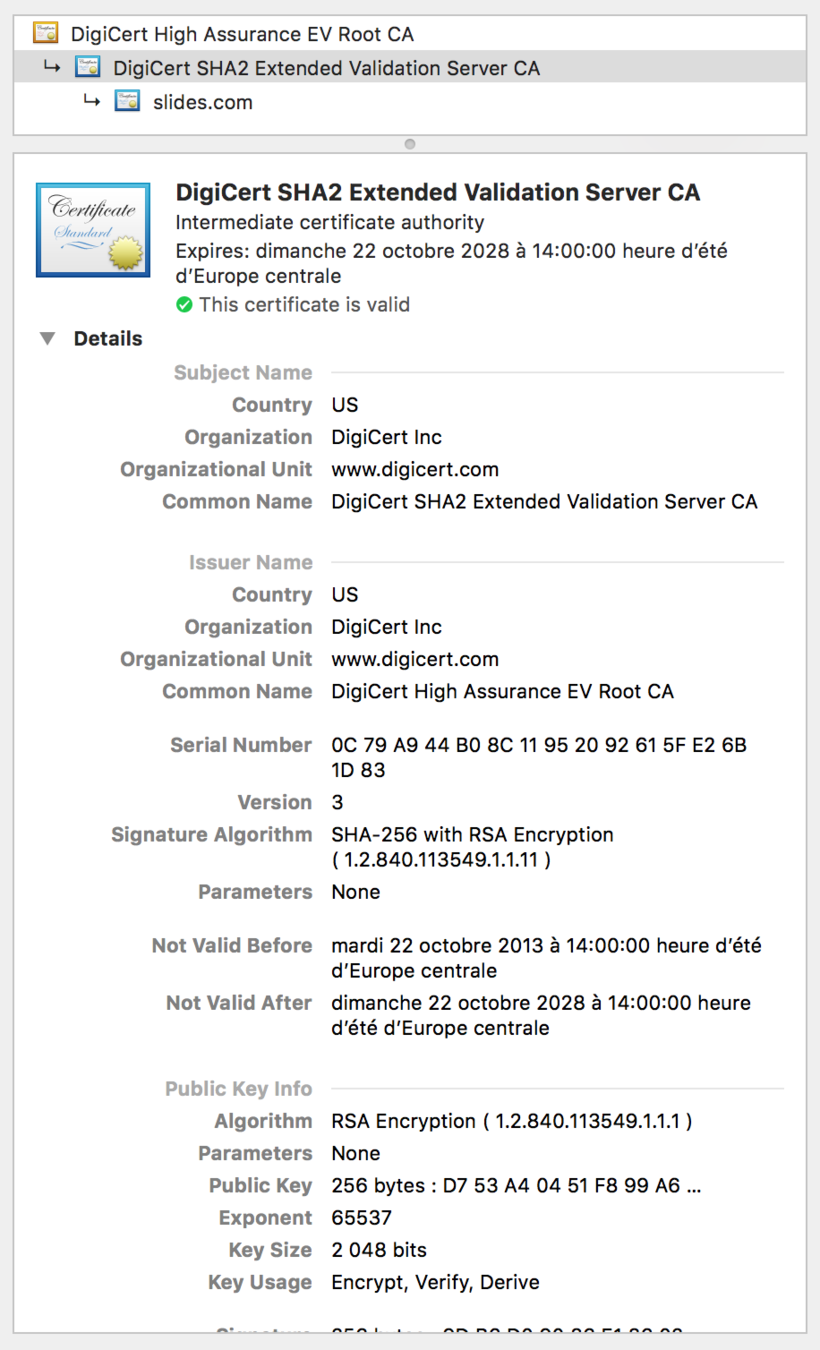
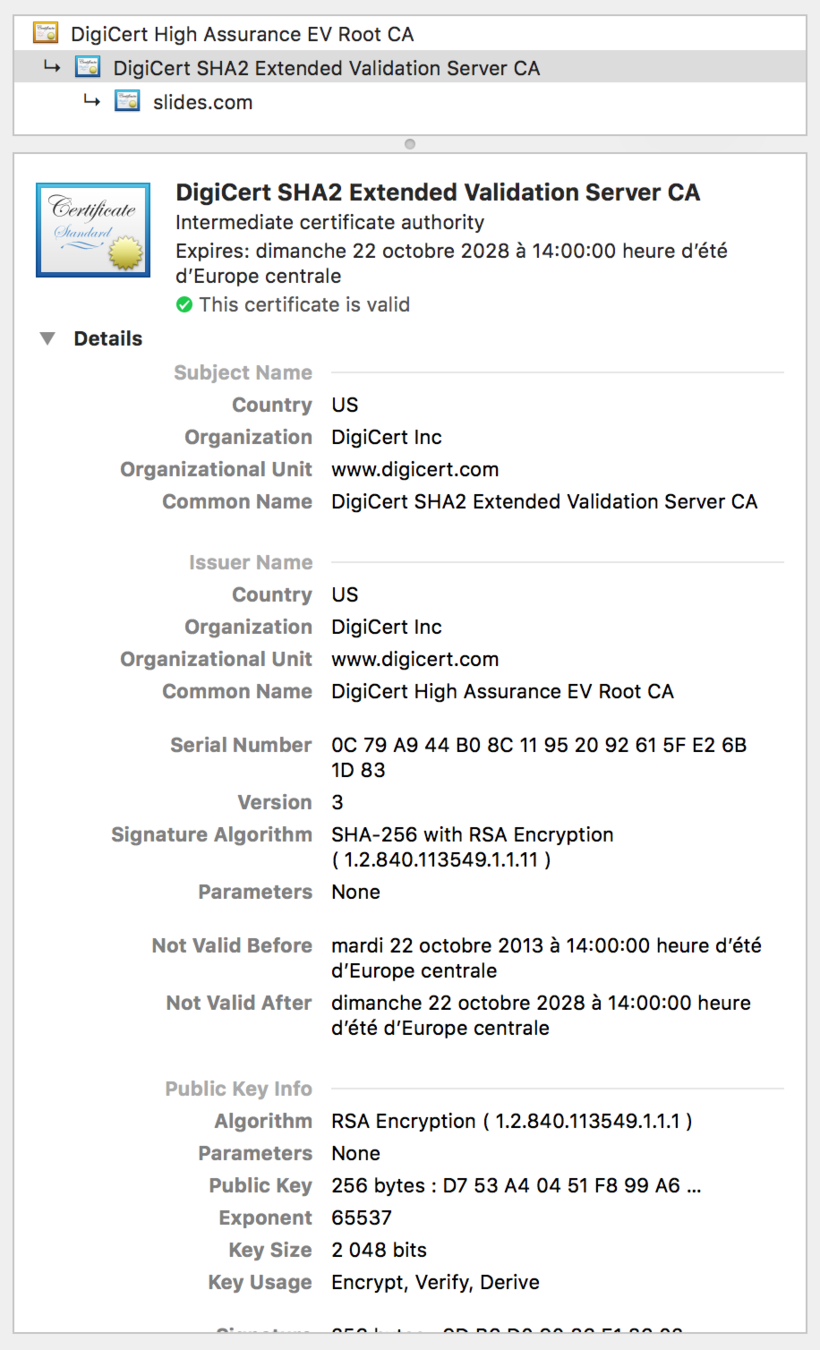

Certificat HTTPs
Autorité racine de confiance :
Présents dans le magasin des certificats racine de confiance de l'OS
Organismes habilités à générer des certificats
(Verisign, Thawte, DigiCert, etc.)
Il s'agit de "trusted certificats" : on leur fait confiance
Ceci a un coût : entre 200 et 500 euros pour un certificat
Chaîne de certificats :
Tout certificat certifié (voir issuer) par un certificat de confiance devient un certificat de confiance (qui peut être utilisé pour certifier d'autres certificats)
Le magasin des autorités racine de confiance d'un système est extrêmement sensible.
Certificat autosignés
Pour réaliser des tests il est possible de générer ses propres certificats.
On parle alors de certificat "auto-signé"
Possible si on a la main sur les postes clients qui vont accéder au site HTTPs.
Ajout manuel du certificat auto-signé dans le magasin racine de confiance des clients de test.
Outil de génération de certificat : OpenSSL
Outil open source de manipulation de certificats
Etapes à suivre pour configurer un serveur HTTPs de test :
- Créer sa propre autorisé de confiance (i.e, la clef privée : CA key et le certificat avec la clef publique : CA Certificat)
- Créer un CSR (certificate signing request) pour le server en y précisant comme "alternate-name" l'IP du serveur.
- Créer le certificat serveur en signant le CSR avec le CA key
- Installer the certificat server sur le server HTTP
- Installer l'autorité de confiance (CA certificate sur le client)
Voir ici pour plus de détails

Et si je veux du HTTPs et que j'ai pas un rond ?
Let's Encrypt !

Source ici
HTTPs pour l'authentification ?
Possible mais lourd à mettre en oeuvre
Nécessite la présente d'un certificat sur chaque poste client ( dans le magasin de certificats ou alors utilisation d'une carte ou support USB).
N'authentifie au final que l'application, pas le client.
La mise en place est délicate (création, distribution et renouvellement des certificats).
Authorization
&
Authentification
Problématique
HTTPs permet de sécuriser la ligne.
Maintenant il faut sécuriser l'accès à l'API : OAuth2
Et ensuite il faudra authentifier l'utilisateur : OIDC
Old school
Basic Authentication
Authorization : basic QWRtaW5pc3RyYXRvcjpBZG1pbmlzdHJhdG9y
Dans le header HTTP, encodage des credentials
Encodé en base64... pas super "secured"...
Si on perd le "jeton" on perd aussi les credentials...
Voir ici pour le décodage base64
ou la commande unix base64
echo QWRtaW5pc3RyYXRvcjpBZG1pbmlzdHJhdG9y | base64 -D
OAuth2
OAuth2
Protocole de délégation d'autorisation (et pas d'authentification)
Utilisation du header HTTP pour transmettre le jeton (appelé access_token)
Authorization: Bearer 34EF5EF9.5435DEE.54533EE6E
Le serveur vérifie la présence et la validité du jeton à chaque requête.
Propose 4 scénarios d'utilisation qui couvrent l'essentiels des use cases qui varient suivant la nature du client (browser, SPA, client riche, serveur, etc.).

OAuth2
4 acteurs
Resource owner : Le propriétaire des ressources. C'est le seul à pouvoir déléguer les droits d'accès à ses ressources. Dans la plupart des cas il s'agit de vous.
Resource server : Machine sur laquelle les ressources du resource owner sont hébergées (Cloud google par exemple).
Authorization server : Serveur d'autorisation
Client : Application (web ou non) qui souhaite accéder à une ressource. Il peut s'agir d'une App sur votre smartphone.

OAuth2
Je (resource owner) souhaite donner à une application sur mon smartphone (client) des droits sur une ressource qui m'appartient et qui est hébergée par un tiers (Resource server).
Exemple : donner un accès à mon compte dropbox pour que l'appli puisse y stocker des données.
Comment cette application peut-elle demander à l'utilisateur ses credentials sans y avoir accès elle même : on souhaite lui donner des droits d'accès (qui seront révocables), mais pas les clefs de la maison...
L'IHM d'authentification est celle proposée par le serveur d'autorisation (on n'a pas la main dessus).
Le client est nécessairement dans un browser ou une WebView.
Le renouvellement de jeton se fait par l'utilisation d'un iframe cachée (1px) qui conserve un lien (session) vers le serveur d'autorisation...
Scénario 1 : Authorization Code Grant Flow
OAuth2
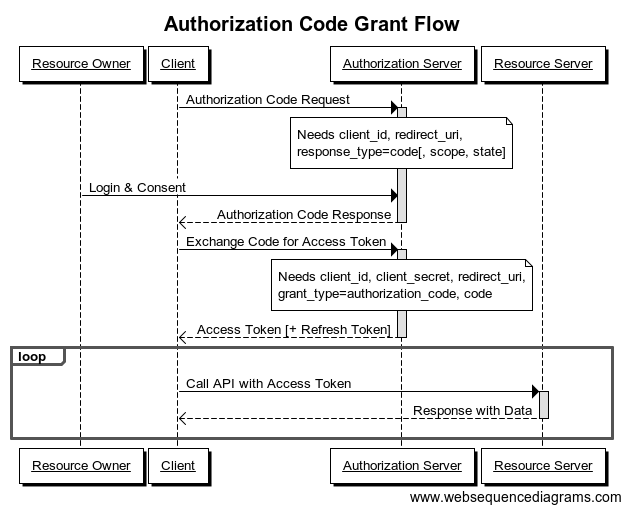
OAuth2
Variante du scénario 1pour les applications du genre SPA (Angular, React.js, Vue.js) pour lesquels un iframe de rafraîchissement n'est pas envisageable.
Suppose la mise en place de CORS (Cross Origin Requests).
Ne permet pas de disposer d'un jeton de rafraichissement.
Comme précédemment, l'IHM d'authentification est celle proposée par le serveur d'autorisation (on n'a pas la main dessus).
A n'utiliser que si on n'a pas le choix (moins sécurisé que 1)
Scénario 2 : Implicit Grant Flow
OAuth2
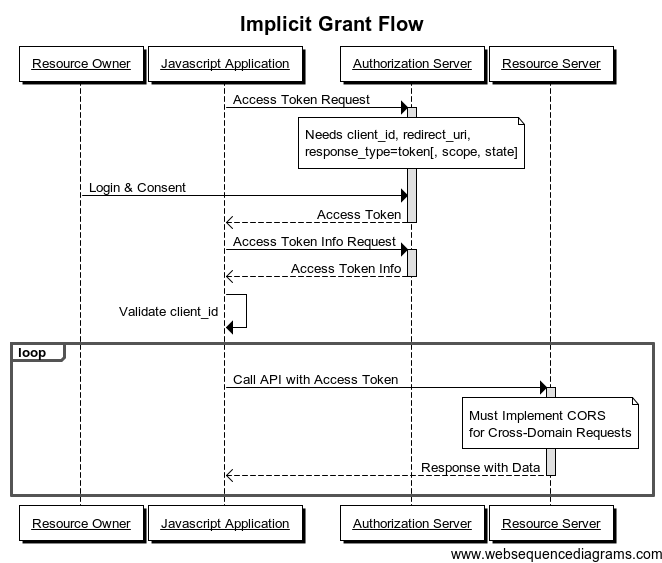
OAuth2
Je (resource owner) souhaite donner à une application en laquelle j'ai confiance (client) des droits sur une ressource qui m'appartient et qui est hébergée par un tiers (Resource server).
Exemple : donner un accès à mon compte dropbox pour qu'une appli que j'ai réalisée puisse y stocker des données.
L'application peut demander à l'utilisateur ses credentials et les transmettre au serveur d'autorisation.
Ceci permet de disposer d'une IHM d'authentification complètement maitrisée.
Scénario 3 : Resource Owner Credentials Grant Flow
OAuth2
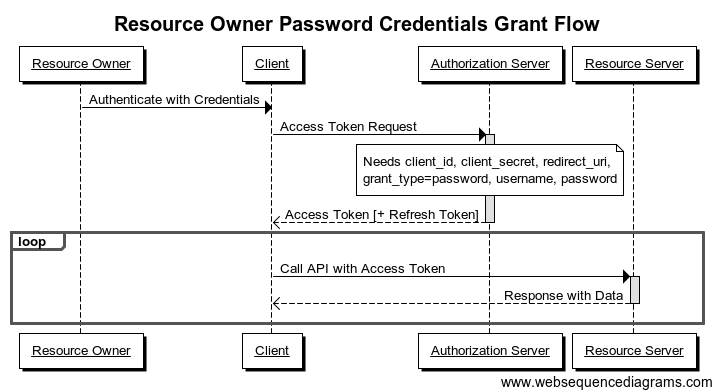
OAuth2
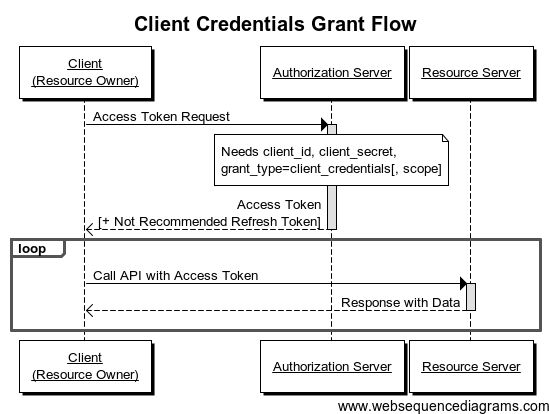
L'application (client) est également le propriétaire des données (resource owner). Nous n'avons donc plus que 3 acteurs. Les données sont toujours hébergée par un tiers (Resource server).
Exemple : je suis un serveur qui dispose d'un référentiel de sauvegarde dans le cloud pour y stocker des données.
J'ai confiance au client puisque c'est moi qui l'ai développé.
Ceci permet de disposer d'une IHM d'authentification complètement maitrisée.
Scénario 4 : Client Credentials Grant Flow
OAuth2
et JWT
JSON Web Token

Basé sur : OAuth2 et JWT
Principes
OAuth2 traitait des autorisations
OIDC traite en plus de l'authentification
JWT
JSON Web Token

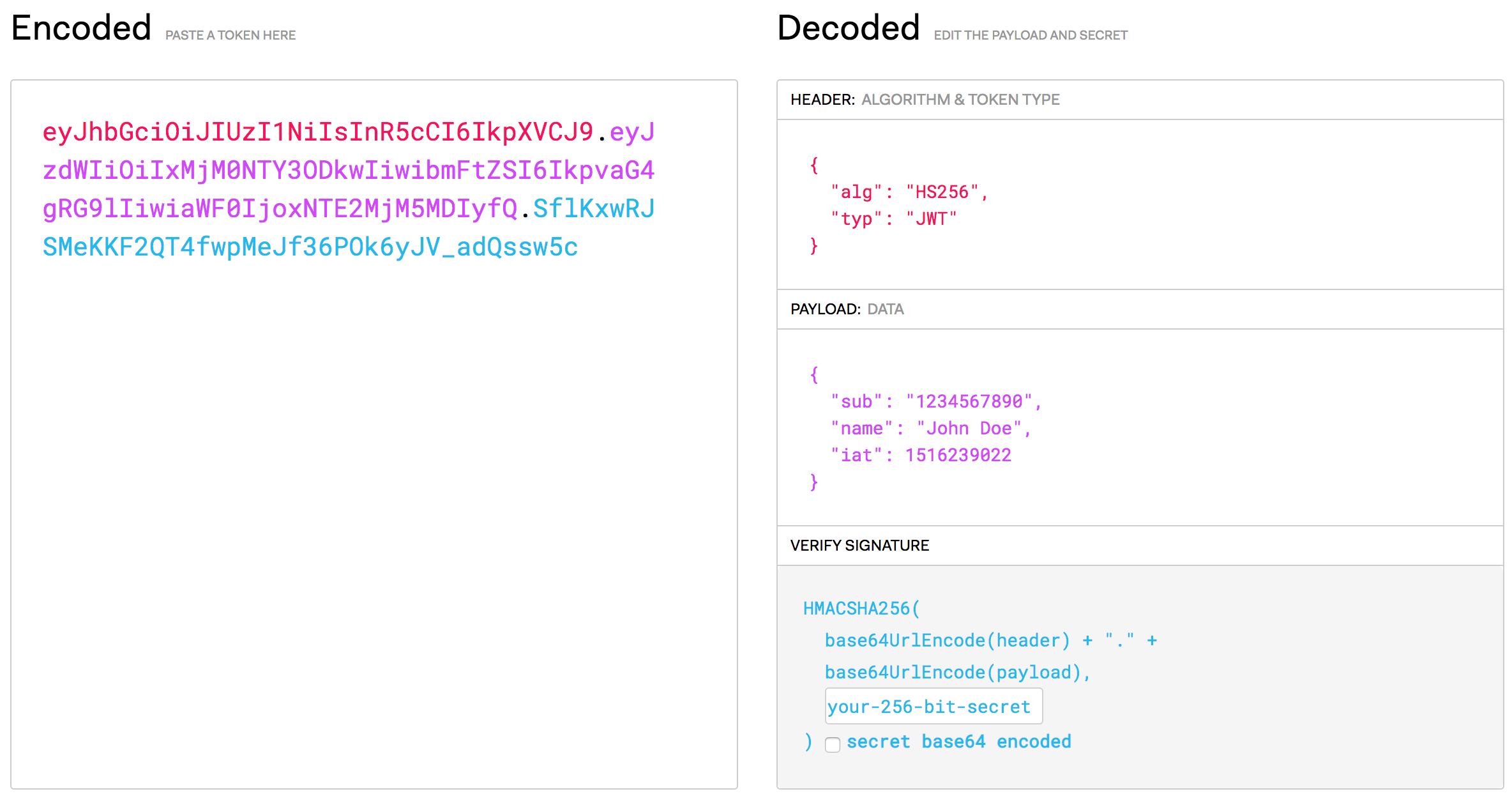
<headers>.<content>.<signature>
Format de jeton (token) standardisé et auto-validant.
JWT
Chaque partie est encodé base64
<headers>
Algorithme à utiliser pour valider le jeton
<content>
Données au format JSON
<signature>
Signature (hash) du headers et du content. Permet de valider l'intégrité du jeton.
Attention : le jeton ne doit pas contenir d'information "sensible".
Un jeton JWT est inviolable (en théorie)

JWT
Site https://jwt.io/ pour lire/valider un jeton JWT
OIDC Token
Jeton JWT retourné par le serveur d'authentification.
Contient les informations de l'utilisateur (suivant le paramétrage du serveur OIDC) : nom, prénom, email, etc.
Il n'a pas pour vocation à quitter le client.
id_token :
access_token :
Jeton JWT retourné par le serveur d'authentification.
Contient les informations qui permettent d'accéder aux API (droits, groupes, claims).
Il sera présent dans toutes les requêtes du client au serveur.
Et on en fait quoi du token ?
C'est l'access_token qui est important et qui devra être placé dans le header de toutes les requêtes qui appellent des API sécurisées.
GET /v1/resource HTTP/1.1 Host: server.example.com Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR...1us5QQen8
L'absence de jeton dans le header entraine un code retour HTTP 401 Unauthorized
API Key
API Key
Pour une sécurisation entre serveur (l'un est le client de l'autre), OAuth2 peut s'avérer lourd.
API Key est une "simple" clef partagée entre un serveur/client et un serveur/serveur.
Présente dans le header HTTP :
X-API-Key: {API_KEY}
Le serveur vérifie la présence et la valeur de l'API_KEY à la réception des requêtes.
Principes
API Key
Pas de gestion fine des droits.
Pas de mécanisme d'expiration.
Ne pas utiliser pour des clients Web / SPA / App mobile.
Pratique pour les appels inter-serveur.
Limites
JWT est souvent associé aux architectures stateless
HTTPs est le premier élément à mettre en place pour sécuriser son API.
APIKey est suffisant pour sécuriser les échanges entre serveurs
TLS et SSL sont des marques de chaussures
Un cryptage asymétrique est préconisé pour stocker des mots de passe dans une BDD
OAuth2 est un protocole d'authentification
Bibliographie
HTTPS
https://en.wikipedia.org/wiki/Transport_Layer_Security#Security
Transport Layer Security (TLS) • Wikipedia • Article très complet et bien documenté sur TLS et SSL.
https://toungafranck.com/ssl-vs-tls-quelle-est-la-difference/
SSL vs TLS – Quelle est la différence ? • Franck Tounga
https://www.ssi.gouv.fr/uploads/2016/09/guide_tls_v1.1.pdf
Recommandations de sécurité relatives à TLS • ANSSI • v1.0 • 19/08/2016
https://security.googleblog.com/2018/02/a-secure-web-is-here-to-stay.html
A secure web is here to stay • Emily Schechter, Google • 08/02/2018 • Quelques chiffres sur le trafic HTTPS

WOA / REST
https://blog.octo.com/designer-une-api-rest/
Designer une API REST • OCTO • 01/12/2014 • Article très complet sur le nommage des API REST, il propose de plus le téléchargement d'un Quick Reference Card, très très bien fait !
7 wrong common beliefs about enterprise api implementation • OCTO • 11/12/2015
OAUth2
https://www.bubblecode.net/en/2016/01/22/understanding-oauth2/
Understanding OAuth2 • BubbleCode by Johann Reinke • 22/01/2016
https://nexworld.fr/securiser-api-oauth2/
Sécurisez l’accès à vos APIs avec OAuth2 • NewWorld.fr