Deep Reinforcement Learning Workshop:
Pong from Pixels 🏓

Overview 👩🏫
- Intro to RL
- Intuition (and some math) behind Policy Gradients
- Do it yourself!
Intro to Reinforcement Learning
What is Reinforcement Learning? (Informally)
Reinforcement learning tries to solve complex problems by interacting with them continuously. You let your Agent make decisions within the Environment, observe the results, and modify the Agent with a Reward. Then repeat!

What is Reinforcement Learning? (Formally)
Reinforcement learning is a mathematical framework to describe behavior in an environment.
Central ideas
- Discrete time steps \(t\)
- The environment is fully described by a state \(s_t\)
- An agent follows a (stochastic) policy \(\pi(a_t|s_t)\) to decide which action \(a_t\) to take at each time-step, which affects the next state \(s_{t+1}\)
- Each time-step is associated with a reward \(r(s_t)\). This is what we want to maximize (can often be zero)
Describing Pong with RL
In this workshop, we will be teaching an agent to control the green paddle and win against a ball-tracking CPU.
In our case:
- Every 3 frames is one time-step \(t\)
- \(s_t = \text{frame}_t - \text{frame}_{t-1}\) (difference of game images)
- Our policy \(\pi(a_t|s_t)\) is defined by a neural network. At each time-step, \(a_t\) is either UP or DOWN
- On the last time-step of each game, receive +1 reward if we won, -1 reward if we lost, and 0 reward at all other time-steps
Deep RL in Context
RL has been around for half a century.
Previously, policies were learned using simple models. In the past 10 years, deep learning has become popular, and allowed for an important set of breakthroughs in RL.
Besides games, emerging application areas include robotics and optimization.

DeepMind's AlphaGo beats Lee Sedol, the reigning Go champion in the world.
Policy Gradients
The Credit Assignment Problem
A major challenge of RL: the credit assignment problem
- Our network makes a decision at every time-step of the game, but may receive feedback rarely, even just once per several hundred decisions
- How do we know which actions were good and which were bad?
- This is important because machine learning depends on using positive/negative feedback to teach a model
Policy Gradients
The specific algorithm we'll be using to train our agent is called policy gradients.
It proposes one solution to the credit assignment problem.
General idea:
- Run a game and keep track of all actions \(a_1, a_2, ..., a_T\)
- If we win the game (+1 reward), encourage all \(a_1, ..., a_T\), if we lose (-1 reward), discourage all of them
- If we run enough games, eventually, good actions will get a net positive feedback, and bad actions negative
Policy Gradients
The specific algorithm we'll be using to train our agent is called policy gradients.
It proposes one solution to the credit assignment problem.
General idea:
- Run a game and keep track of all actions \(a_1, a_2, ..., a_T\)
- If we win the game (+1 reward), encourage all \(a_1, ..., a_T\), if we lose (-1 reward), discourage all of them
- If we run enough games, eventually, good actions will get a net positive feedback, and bad actions negative
Policy Gradient Theorem
Our loss function to minimize will be \(-E_t[R(t)]\), the negative expected value (average) of the reward of our neural network's policy.
We use gradient descent to find model parameters that minimize the loss. To do this, we must calculate \(\nabla_{\theta} (-E[R(t)])\) the gradient of the loss with respect to the model parameters \(\theta\).
More details, but the policy gradient theorem states that:
$$ \nabla_{\theta} (-E[R(t)]) = -E[R(t) \nabla_{\theta} \log (p(a_t))] $$
where \(p(a_t)\) is the probability of "the chosen action".
Discounted Reward
One last important detail:
In reality, we don't use the raw +1 or -1 rewards. We use the discounted reward
$$R(t) = \sum_{k=0}^{T-t} \gamma^k r(s_{t+k})$$
where \(\gamma\) is the discount factor, a number between 0 and 1
Intuitively, \(t\) is responsible for the rewards in future time-steps, but exponentially less so as time goes on.
Do It Yourself!
Obtain the Materials 💸
$ git clone https://github.com/stewy33/pong-with-policy-gradients.git
$ cd pong-with-policy-gradients2. Star 🌟 the repository 🥰
3. Clone and `cd` into the repo
4. Follow the instructions on the Readme! Depending on your platform, there may be installation errors - just let us know.
Notes and Tips
In the interest of time, we had to move quickly through the math, so let me know if there is a block and I'll come to your breakout room.
Use TensorBoard judiciously. If performance doesn't improve, there is likely a bug in your code, if it's not obvious what it is, call me in.
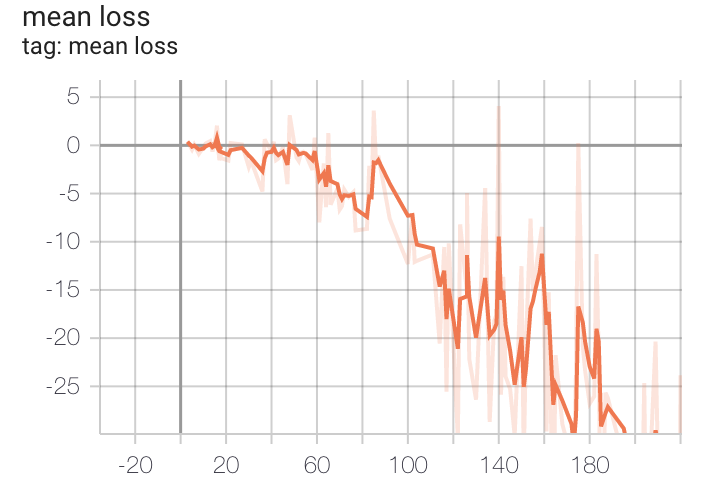
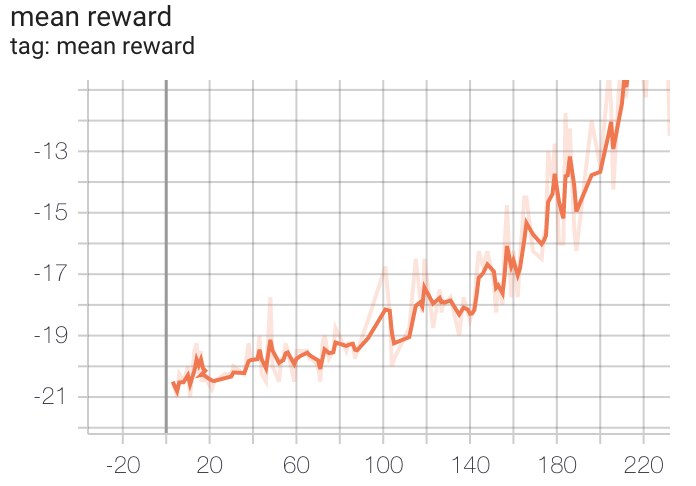
Notes and Tips Cont
The tests are a guide, but only test calculating discounted reward and the policy network, and don't guarantee correctness.
Be very careful and double check everything!
http://karpathy.github.io/2019/04/25/recipe/
But most importantly, have fun! 🤠