First SOme COntext
- First gave this talk in 2017
- Audience was beginners + some tech
- Originally 10min
- Added "simplified" icons
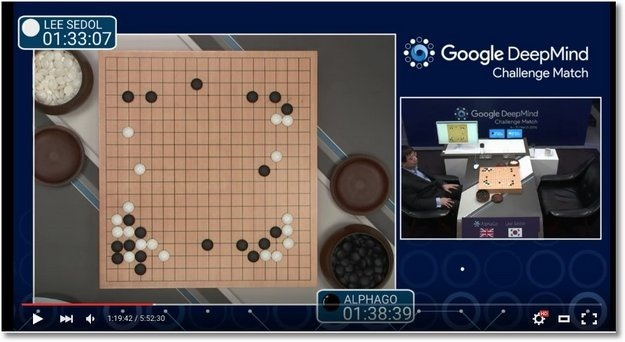
alphago
A new paradigm in Artificial Intelligence


How did alphago Solve this?
1. Monte Carlo Tree Search 🎲🌳🔎
2. Neural Networks 🧠🕸
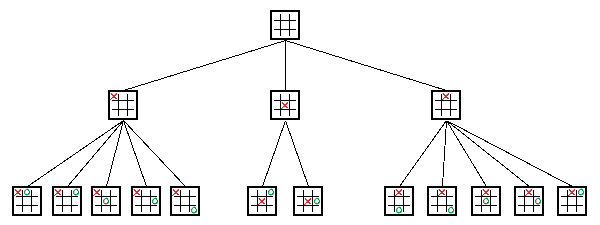
What are Decision Trees?
How do computers play games

State of the art: Heuristics
2
5
1
2
2
2
2
2
5
5
1
1
1
1
1
A
Issues
1. Very difficult to write, could sneak in bias
2. Not transferrable to other games
3. Only as good as the best humans
Chapter 1:
Finding our way by rolling the dice
MonTe Carlo What?
1. Our solution can just be "good enough"
3. Given an solution, we can score how good it is
2. We can produce random "solutions" easily
Solving Secret Santa
🧑
🐙
👩
1. Our solution can just be "good enough"
2. We can produce random solutions easily
👧
3. Given an solution, we can score it
-10
5
3
0
Do this gazillion* times, take the highest scoring solutions
🧑
🐙
👧
👩
5
3
8
Monte Carlo What?


🏆
🏆
❌
Let's play some random games
Monte Carlo Tree Search




x10
x10
x10
10 sims
1 win
10 sims
6 wins
10 sims
3 wins
Monte Carlo Tree Search
10 sims
1 win
10 sims
6 wins
10 sims
3 wins


x10
x10
10 sims
4 wins
10 sims
6 wins
30 sims
16 wins
50 sims
20 wins
How to select the next state?
1. Best win ratio (greedy)
2. Low sim count (curious)
(Avg Sims - # of sims) * curiosity bias
+
(# of wins - Avg wins) * greediness bias
B
Applying our scores
10 sims
1 win
10 sims
3 wins
10 sims
4 wins
10 sims
6 wins
30 sims
16 wins
50 sims
20 wins
Avg Wins = 8
Avg Sims = 20
-18
2
-2
5
8
6
C
Questions to think about
How do we know when to actually play a move?
How many random games should we play each time?
How "curious" should it be? How "greedy"?
This doesn't seem to "remember" from game to game... How does it improve/learn?
(but outside the scope of this talk)
Curiosity + Greediness +
Experience
Chapter 2:
Learning How to Learn
Similar Board States
Similar to...


Vs. ?
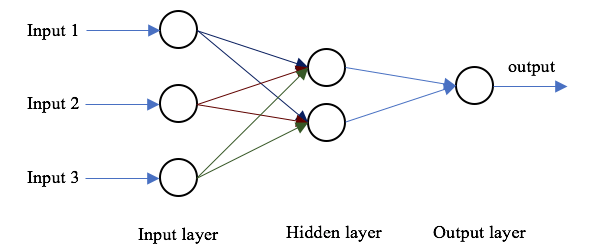
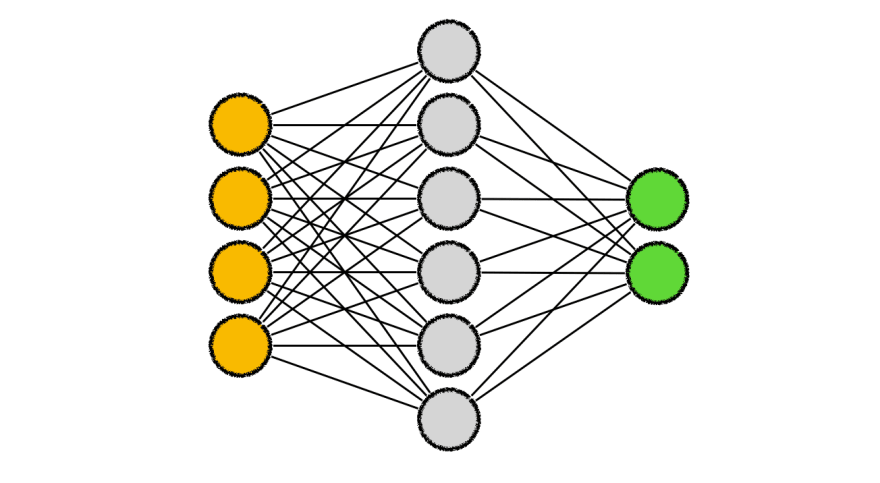
Neural Networks

Network in action
* Animation from 3Blue1Brown's Video
Anatomy of a network
2
0.1
-1
0.4
0.8
-0.2
0.5
4
-1
-0.2
2.9
-0.1
-0.8
-0.13
[2, 4, -1] => 1
D
Finding the blame
-0.9
0.1
-1
0.4
0.8
-0.2
0.5
.27
-.23
0.9
-.11
-0.1
-0.8
1.13
Target - Result = Blame
1 - (-0.13) = 1.13
E
Update the weights
Weight - % of Blame => New Weight
0.1 - (10% of -0.9) => 0.19
-0.9
0.19
-0.9
0.37
0.77
-0.17
0.52
.27
-.23
0.9
-.11
-0.08
-0.9
Questions to think about
How do we encode our inputs?
How big should our network be?
How much should we tweak the weights?
How much training is enough?
(but outside the scope of this talk)
Chapter 3:
Bringing it together
Post game teaching
🏆
...
1.
2.
3.
🏆
🏆
Using our experience
x10
x10
x10
10 sims
1 win
10 sims
6 wins
10 sims
3 wins
13%
75%
59%
Curiosity + Greediness + Experience = Score
F
Chapter 4:
Wrapping up
Recap: What did we learn
Learned about decision trees and how computers play games
Covered Monte Carlo Tree Search, a novel way using randomness to efficiently search a large decision tree
How neural networks categorize information, and how we can train them
How we can combine the two to explore a massive amount of strategies independent of the kind of game
How did Alphago do?


THANKS
Questions?
References
A - Alpha-beta Pruning
B - UCT
C - Sub selection
D - Sigmoid curve
E - Back-propagation, gradient descent
F - Fourth attribute, policy network