AlphaZero
Intro slide




AlphaZero
Go
Chess
Starcraft
AlphaGo
Complexity
"Math", "Machine Learning"
Fucking DeepMind White Papers
NOTHING

How AIs play games
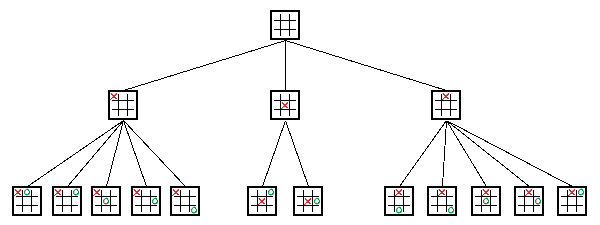
Decision Trees
BruteForce Search

Evaluation and Pruning
-0.8
4.3
1.4
-2.6
-2.1
-0.8
State of the art: Alpha-beta pruning & MiniMax*
*These techniques only work if you can properly evaluate the board position
5.0
3.2
-1.3
-1.9
-4.8
-3.2
1.2
-0.9
-1.3
Evaluation is Hard



3. 😤🍆✊
2. 🔀🧠🕸
1. 🎲🌳🔍
How does AlphaZero Work?
Monte Carlo Tree Search
Each Board state will have a # times won from that position (exploit), and # times visited (explore)
0. Start at the top 1. Pick the next move that has the highest score, calculated from the explore and exploit numbers 2. Keep going until we reach a state we haven't seen before 3. Add each legal move to the tree, and play out X random games from that position 4. Update the explore and exploit numbers back up the tree, 5. Goto (0)
These will be used to figure out a score. Low explore is very good, High exploit is good.
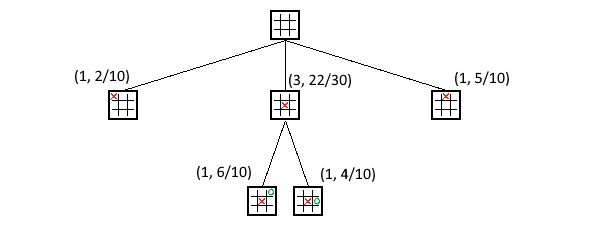
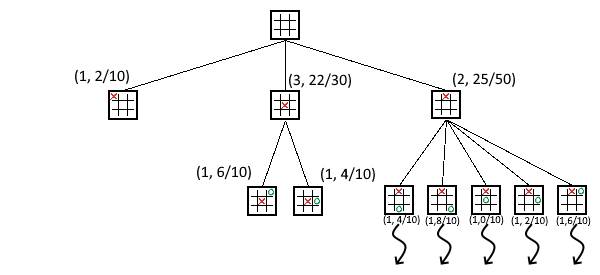
You got it now right?
right?
right?!
Neural Nets
a crash course
Good at "fuzzy" recognition.
Needs to be supervised.
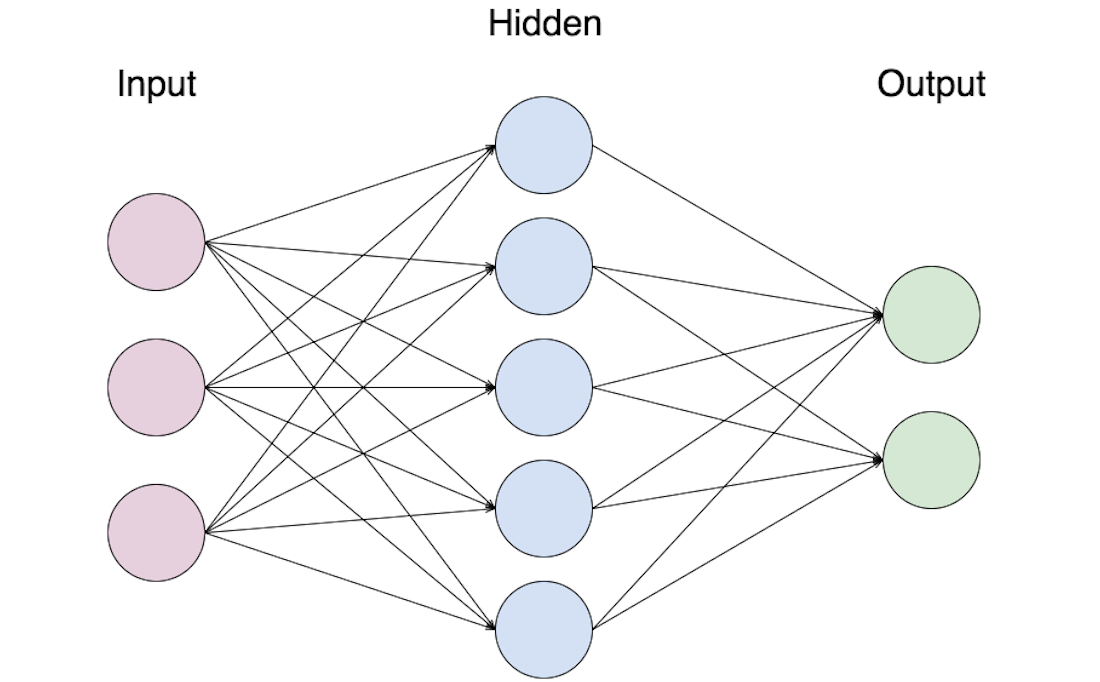
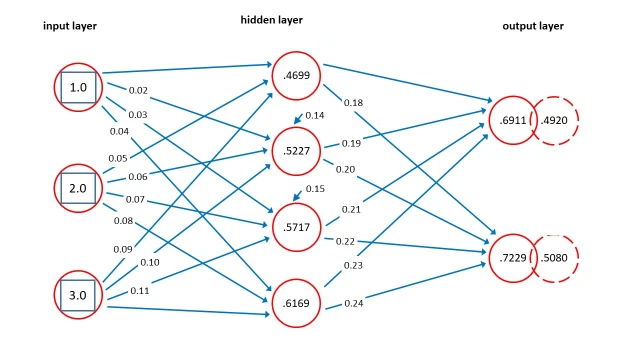
What is it doing?
It's just a lot of multiplying and adding TBH
How does it learn?

Let's put'em together
Adversarial Self-Play

It's crazy efficient
- You'd think this would require 2x resources
- But both sides "share" the Search Tree and the neural net
- In practice it's more like 1.1x more resources to self-play
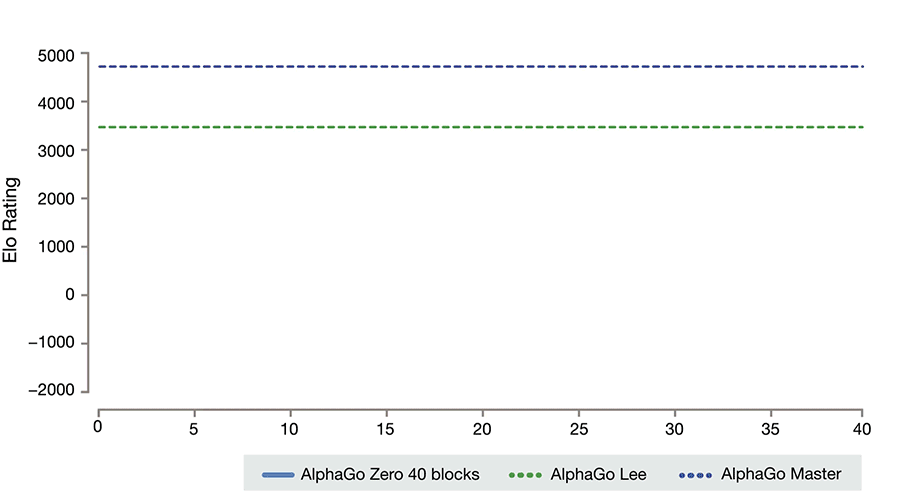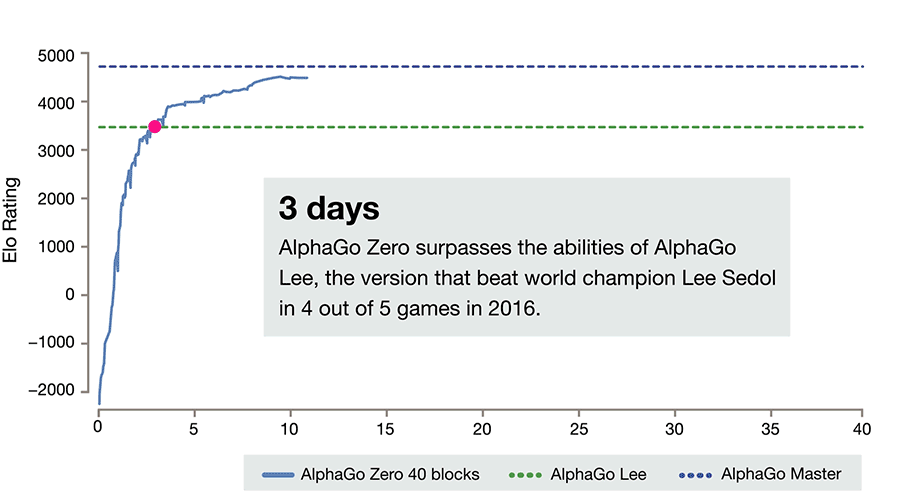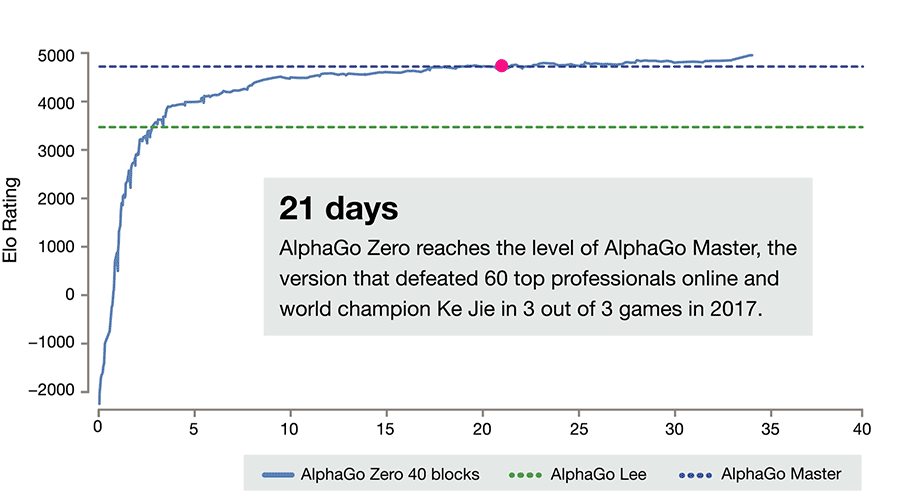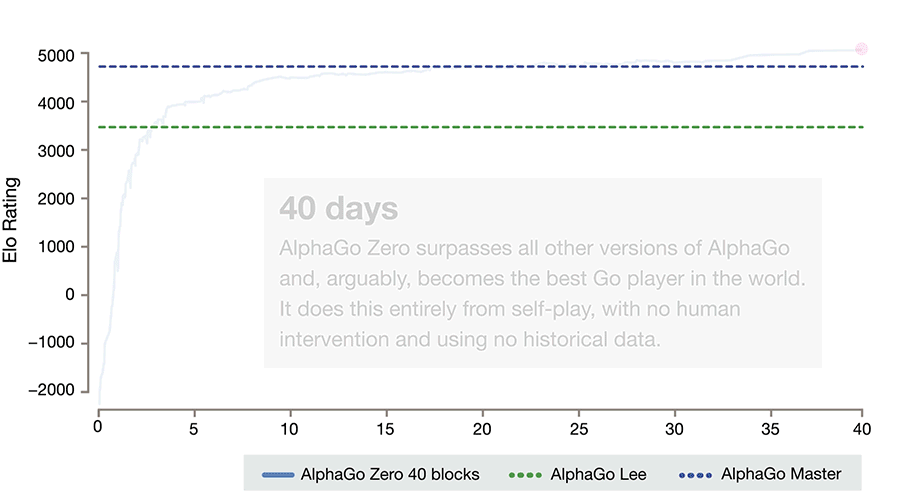
It's good. Like, scary good.
What's Next?
- AlphaStar - Starcraft
Hidden information, real-time
- MuZero - Various Atari games
No defined rules, sloppy inputs
- AlphaDiplomat - Diplomacy
Positive-sum games, co-operation, communication
✅ Beat world champions (dec 2018)
✅ Outperformed state-of-the-art algos (mar 2020)
❓ Work started in June, 2020
Thanks!
Sorry, I put this together super fast...