Incorporating Domain Knowledge in Multilingual, Goal-oriented Neural Dialogue Models
Suman Banerjee
Department of Computer Science and Engineering,
Indian Institute of Technology Madras
Outline
- Introduction
- Problem Statement
- Proposed Models
- Sequential Attention Network
- GCN with Sequential Attention
- Proposed Dataset
- Code-mixed dialogue
- Results and Analysis
- Conclusion
Outline
- Introduction
- Problem Statement
- Proposed Models
- Sequential Attention Network
- GCN with Sequential Attention
- Proposed Dataset
- Code-mixed dialogue
- Results and Analysis
- Conclusion
Dialogue Systems

Siri
Cortana

Bixby
Google assistant

Alexa



Apple Homepod
Amazon Echo
Google Home
Modular Architecture
Language Understanding
Dialogue State Tracking
Policy Optimizer
Language Generation
User utterance
System response
Semantic Frame
System Action
Dialogue State
I need a cheap chinese restaurant in the north of town.
request_rest(cuisine=chinese, price=cheap, area=north)

Knowledge Base
request_people( )
Sure, for how many people?
Dialogue Manager
Probabilistic methods in spoken-dialogue systems, Steve J. Young, Philosophical Transactions: Mathematical, Physical and Engineering Sciences, 2000
End-to-End Architecture
- Can be directly trained on utterance- response pair data, no intermediate supervision required
- Can be easily scaled to new domains
- No fixed assumption on the dialogue state structure
User utterance
I need a cheap chinese restaurant in the north of town.
System response
Sure, for how many people?
Knowledge Base
End-to-End Dialogue System
Outline
- Introduction
- Problem Statement
- Proposed Models
- Sequential Attention Network
- GCN with Sequential Attention
- Proposed Dataset
- Code-mixed dialogue
- Results and Analysis
- Conclusion
Goal-oriented Dialogue phases
System: Hello, what can I help you with today?
User: Hi!
User: I'd like to book a table for six people in an expensive restaurant with British food.
System: where should it be ?
User: Somewhere in the north of the town.
System: ok I am on it!
System: API_CALL (British, north, six, expensive)
System: How about The_Place?
User: No I don't like it.
System: Ok, then, what do you think about Fancy_Pub?
User: Yes! lets do it.
System: Great! I'll do the reservation.
User: What is the address?
System: Here it is: Fancy_Pub_Address
User: Thank You
System: You're welcome
The_Place R_cuisine British
The_Place R_location north
The_Place R_address The_Place_Address
The_Place R_price expensive
The_Place R_rating 10
Fancy_pub R_cuisine British
Fancy_pub R_location north
Fancy_pub R_address Fancy_pub_Address
Fancy_pub R_price expensive
Fancy_pub R_rating 8


Goal-oriented Dialogue phases
Pre-KB
System: Hello, what can I help you with today?
User: Hi!
User: I'd like to book a table for six people in an expensive restaurant with British food.
System: where should it be ?
User: Somewhere in the north of the town.
System: ok I am on it!
System: API_CALL (British, north, six, expensive)
System: How about The_Place?
User: No I don't like it.
System: Ok, then, what do you think about Fancy_Pub?
User: Yes! lets do it.
System: Great! I'll do the reservation.
User: What is the address?
System: Here it is: Fancy_Pub_Address
User: Thank You
System: You're welcome
KB
Post-KB
The_Place R_cuisine British
The_Place R_location north
The_Place R_address The_Place_Address
The_Place R_price expensive
The_Place R_rating 10
Fancy_pub R_cuisine British
Fancy_pub R_location north
Fancy_pub R_address Fancy_pub_Address
Fancy_pub R_price expensive
Fancy_pub R_rating 8
Structural Information

Dependency Parse of sentences

Knowledge Graph
- Current state of the art models ignore this rich structural information
- We exploit this structural information in our model
- Couple it with the sequential attention mechanism
- Empirically show that such structural information aware representations improve the response generation task
Code Mixing
Speaker 1: Hi, can you help me with booking a table at a restaurant?
Speaker 2: Sure, would you like something in cheap, moderate or expensive?
Speaker 1: Hi, kya tum ek restaurant mein table book karne mein meri help karoge?
Speaker 2: Sure, aap ko kaunsi price range mein chahiye, cheap, moderate ya expensive?
Speaker 1: Hi, tumi ki ekta restaurant ey table book korte amar help korbe?
Speaker 2: Sure, aapni kon price range ey chaan, cheap, moderate na expensive?
Problem
- Dialogue of n turns : \( \{ (u_1,s_1),(u_2,s_2),...,(k_1,k_2,...,k_e),...,(u_n,s_n) \}\)
- Phases:
- Pre-KB : \( (u_1,s_1,u_2,s_2,...,u_i,s_i ) \)
- KB : \( (k_1,k_2,...,k_e) \)
- Post-KB : \( (u_{i+1},s_{i+1},...,u_n,s_n ) \)
- At \( t^{th}\) turn the user utterance \( u_t \) is considered as the query to the system
- The system is supposed to generate the response: \( s_t \)
- Models:
- Sequential Attention Network - To handle the three phases sequentially
- Graph Convolutional Network based model with Sequential Attention - To incorporate structural information
- Dataset
- Code-mixed dialogue dataset
Outline
- Introduction
- Problem Statement
-
Proposed Models
- Sequential Attention Network
- GCN with Sequential Attention
- Proposed Dataset
- Code-mixed dialogue
- Results and Analysis
- Conclusion
Single Attention Distribution

- Current models use a single long RNN or Memory Network to encode the entire context
- Compute a single attention distribution over these representations
- This way of computing the attention overburdens the attention mechanism
Sequential Attention
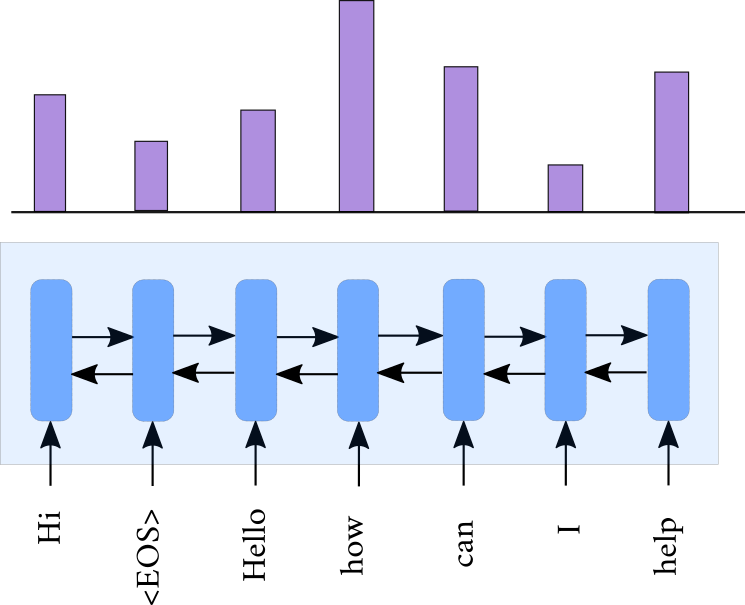
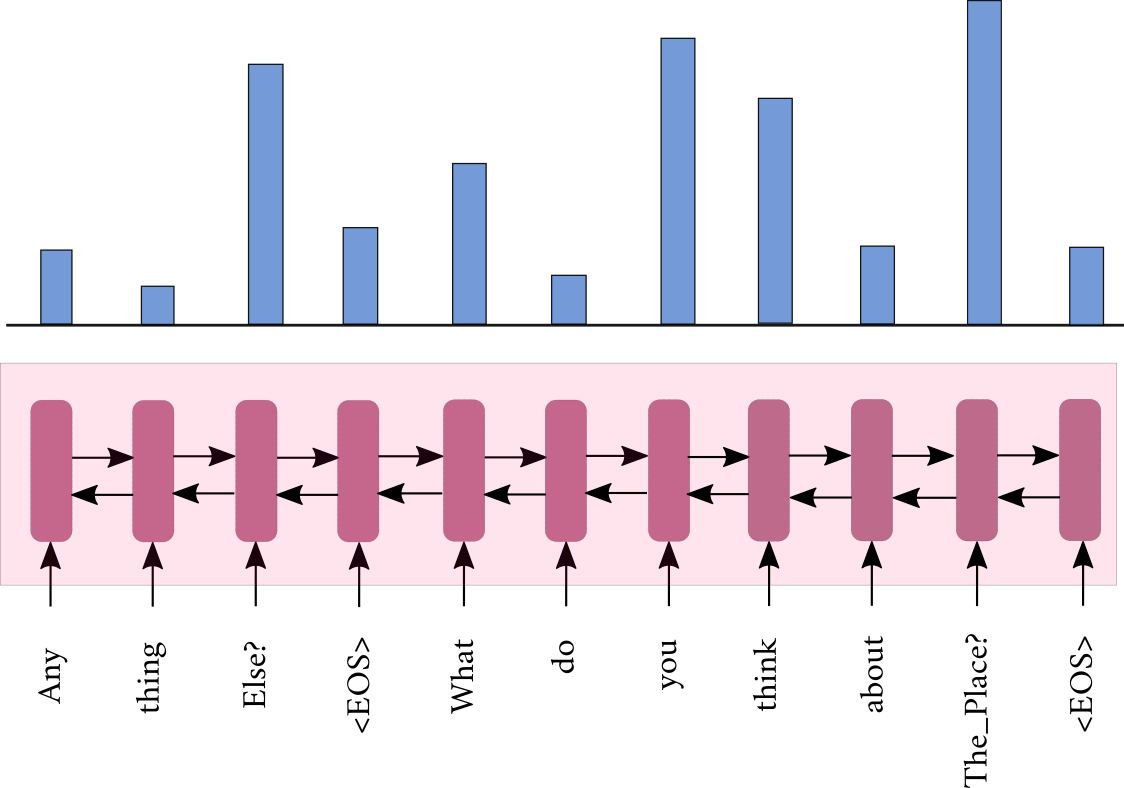
Pre-KB
Post-KB
KB
Sequential Attention
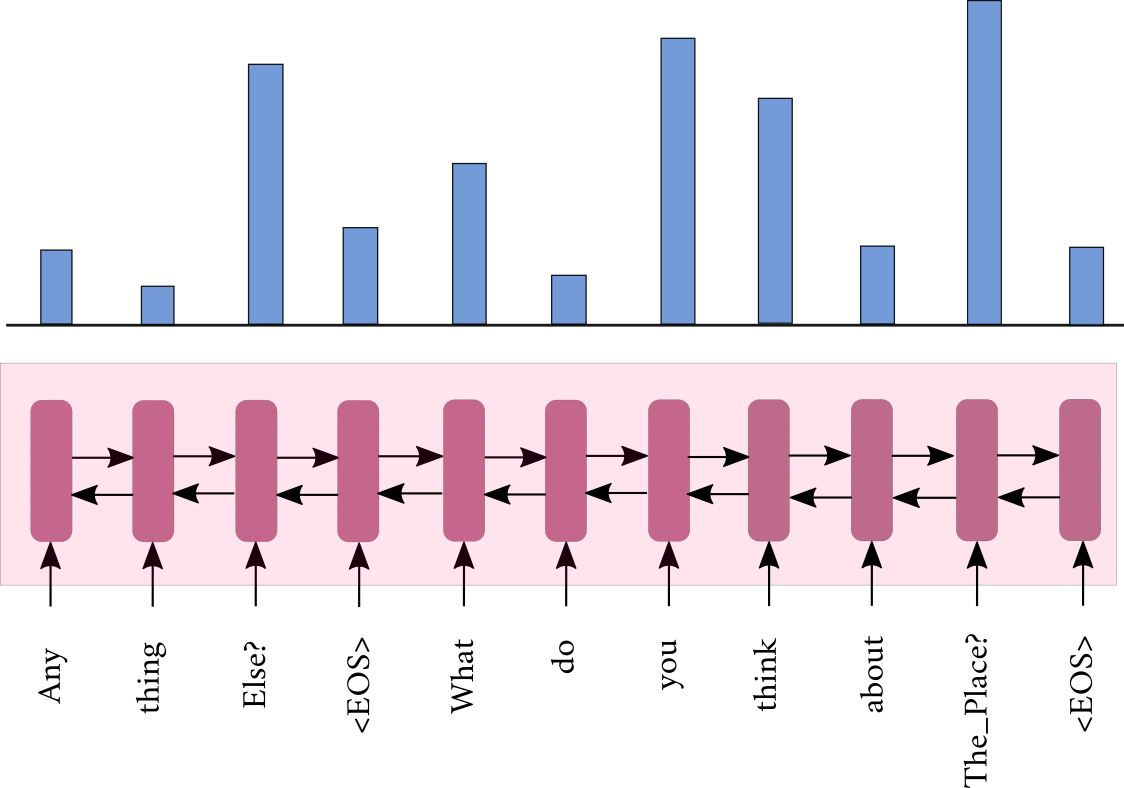
Post-KB RNN
Post-KB
- \( \mathbf{h}^P_t = BiRNN(\mathbf{h}^P_{t-1},\mathbf{g}_t) \)
- \( \mathbf{h}^Q_t = BiRNN(\mathbf{h}^Q_{t-1},\mathbf{q}_t) \)
- \( \boldsymbol{\alpha}_t = f(\mathbf{h}^P_t,\mathbf{d}_{t-1},\mathbf{h}^Q_T)\)
- \( \mathbf{h}_{post} = \sum_{j=1}^{p} \alpha_{jt}\mathbf{h}_j^P \)
Query RNN
\(\boldsymbol \alpha_t\)
\(\Big\{\)
\(\mathbf{h}_{post}\)
Sequential Attention
\(\boldsymbol \alpha_t\)
\(\Big\{\)
\(\mathbf{h}_{post}\)

KB
- \( \mathbf{p}^b_i = softmax(\mathbf{u}^bW^b_m\mathbf{h}^K_i)\)
- \( \mathbf{o}^b = \sum_{j=1}^e p^b_j\mathbf{h}^K_j \)
- \( \mathbf{u}^{b+1} = \mathbf{u}^b + \mathbf{o}^b \)
- Final hop's output vector: \( \mathbf{h}_{kb} = \mathbf{o}^{B+1} \)
KB Memory Network
Sequential Attention
\(\boldsymbol \alpha_t\)
\(\Big\{\)
\(\mathbf{h}_{post}\)
Pre-KB
- \( \mathbf{h}_t^R = BiRNN(\mathbf{h}_{t-1}^R,\mathbf{x}_t)\)
- \( \boldsymbol \beta_t = f(\mathbf{h}_j^R , \mathbf{d}_{t-1} , \mathbf{h}^Q_T , \mathbf{h}_{post} , \mathbf{h}_{kb})\)
- \( \mathbf{h}_{pre} = \sum_{j=1}^r \beta_{jt}\mathbf{h}^R_j \)
\(\boldsymbol \beta_t\)
\(\Big\}\)
\(\mathbf{h}_{pre}\)
End-to-End Network

Outline
- Introduction
- Problem Statement
-
Proposed Models
- Sequential Attention Network
- GCN with Sequential Attention
- Proposed Dataset
- Code-mixed dialogue
- Results and Analysis
- Conclusion
Graph Convolutional Network (GCN)


- GCN computes representations for the nodes of a graph by looking at the neighbourhood of the node
- Formally, \( \mathcal{G = (V,E)}\) be a graph
- Let \( \mathcal{X} \in \mathbb{R}^{n \times m}\) be the input feature matrix for \(n\) nodes
- Each node (\(\mathbf{x}_u \in \mathbb{R}^m\)) is an m-dimensional feature vector.
- The output of 1-hop GCN is \( \mathcal{H} \in \mathbb{R}^{n \times d}\)
- Each \( \mathbf{h}_v \in \mathbb{R}^{d}\) is a node representation that captures the 1-hop neighbourhood information
- Here \(k\) is the hop number
- \(\mathbf{h}^1_u = \mathbf{x}_u \)
- \( \mathcal{N}(v)\) is the set of neighbours of node \(v\)
Semi-supervised classification with graph convolutional networks. Kipf and Welling, ICLR, 2017.
Problem
- Dialogue : \( \{ (u_1,s_1),(u_2,s_2),...,(k_1,k_2,...,k_e),...,(u_n,s_n) \} \)
- Each \(k_i\) is of the form: (entity\(_1\), relation, entity\(_2\))
- The KB triples can be represented as a graph : \( \mathcal{G}_k = (\mathcal{V}_k,\mathcal{E}_k) \)
- where \(\mathcal{V}_k\) is the set of entities in the KB triples
- \( \mathcal{E}_k\) is the set of edges where each edge is of the form : (entity\(_1\), entity\(_2\), relation)
- At the \( t^{th}\) turn of the dialogue, given the:
- Dialogue History: H = \( (u_1,s_1,...,s_{t-1}) \)
- The current user utterance as query: Q = \( u_t\)
- The knowledge graph \(\mathcal{G}_k\)
- The task is to generate the current system utterance \(s_t\)
Syntactic GCNs with RNN
- Obtain the dependency graph for the dialogue history : \( \mathcal{G}_H =(\mathcal{V}_H,\mathcal{E}_H)\)


RNN-Encoder
Syntactic GCNs with RNN

GCN
RNN - GCN
GCN with Sequential Attention

Query Attention
\[ \alpha_{jt} = f_1(\mathbf{c}^f_j, \mathbf{d}_{t-1}) \]
\[ \mathbf{h}^Q_t =\sum_{j'=1}^{|Q|} \alpha_{j't}\mathbf{c}_{j'}^f \]
History Attention
\[\beta_{jt} = f_2(\mathbf{a}^f_j, \mathbf{d}_{t-1}, \mathbf{h}^Q_t)\]
\[ \mathbf{h}^H_t = \sum_{j'=1}^{|H|} \beta_{j't}\mathbf{a}_{j'}^f \]
KB Attention
\[ \gamma_{jt} = f_3(\mathbf{r}^f_j,\mathbf{d}_{t-1}, \mathbf{h}^Q_t,\mathbf{h}^H_t)\]
\[ \mathbf{h}^K_t = \sum_{j'=1}^m \gamma_{j't}\mathbf{r}_{j'}^f \]
GCNs for code-mixed utterances
- Dependency Parsers are not available for code-mixed sentences
- Need an alternate way of extracting structural information
- Create a global word co-occurrence matrix from the entire corpus
- The context window of a word is the entire length of its sentence
- Connect edges between two words if their co-occurrence frequency is above a certain threshold value
- We experiment with raw frequency and Positive Pointwise Mutual Information (PPMI)\(^1\) values
- Decided the threshold by taking the median of non-zero entries in the matrix
\(^1\)Word association norms mutual information, and lexicography, Church and Hanks, Computational Linguistics, 1990
Outline
- Introduction
- Problem Statement
- Proposed Models
- Sequential Attention Network
- GCN with Sequential Attention
-
Proposed Dataset
- Code-mixed dialogue
- Results and Analysis
- Conclusion
Modified DSTC2
System: Hello, what can I help you with today?
User: Hi!
User: I'd like to book a table for six people in an expensive restaurant with British food.
System: where should it be ?
User: Somewhere in the north of the town.
System: ok I am on it!
System: API_CALL (British, north, six, expensive)
The_Place R_cuisine British
The_Place R_location north
The_Place R_address The_Place_Address
The_Place R_price expensive
The_Place R_rating 10
Fancy_pub R_cuisine British
Fancy_pub R_location north
Fancy_pub R_address Fancy_pub_Address
Fancy_pub R_price expensive
Fancy_pub R_rating 8
System: How about The_Place?
User: No I don't like it.
System: Ok, then, what do you think about Fancy_Pub?
User: Yes! lets do it.
System: Great! I'll do the reservation.
User: What is the address?
System: Here it is: Fancy_Pub_Address
User: Thank You
System: You're welcome
Learning end-to-end goal-oriented dialog, Bordes et. al. , ICLR, 2017.
Code-mixed Data Collection
- Build on top of modified DSTC2 dataset
- Collect code-mixed dialogues using this dataset in four languages :
- Hindi-English, Bengali-English, Gujarati-English and Tamil-English.
Extract Unique
Utterances
Replace entities
with placeholders
Unique
utterances
Crowdsource
code-mixing
utterance templates
Replace placeholders
with entities
code-mixed templates
Replace utterances
back into dialogue
code-mixed
utterances
code-mixed dialogue data
English
dialogue data
Sorry there is no Chinese restaurant in the west part of town
Sorry there is no Italian restaurant in the north part of town
Sorry there is no <CUISINE> restaurant in the <AREA> part of town
Outline
- Introduction
- Problem Statement
- Proposed Models
- Sequential Attention Network
- GCN with Sequential Attention
- Proposed Dataset
- Code-mixed dialogue
- Results and Analysis
- Conclusion
Results on En-DSTC2
RNN + CROSS -GCN-SeA
- Connect edges between query/history words and KB entities if they exactly match
- Creates one global graph, encoded using one GCN
- Then separated into different contexts to perform the sequential attention

Results on code-mixed data

Effect of using more GCN hops






PPMI vs Raw Frequencies

- Using the PPMI scores gives a better contextual graph compared to using raw frequency
- Evident across all other languages except English
Dependency or co-occurrence structure really needed ?



Dependency edges
Random edges
Ablations
RNN
GCN
RNN-GCN
Encoder :
Attention :
Bahdanau
Sequential
GCN
RNN-GCN
Sequential
RNN
GCN
RNN-GCN
Ablations

Ablations
-
GCNs do not outperform RNNs independently:
-
performance of GCN-Bahdanau attention < RNN-Bahdanau attention
-
-
Our Sequential attention outperforms Bahdanau attention:
-
GCN-Bahdanau attention < GCN-Sequential attention
-
RNN-Bahdanau attention < RNN-Sequential attention (BLEU & ROUGE)
-
RNN+GCN-Bahdanau attention < RNN+GCN-Sequential attention
-
-
Combining GCNs with RNNs helps:
-
RNN-Sequential attention < RNN+GCN-Sequential attention
-
-
Best results are always obtained by the final model which combines RNN, GCN and Sequential attention
Results on Human-Human Dialogue Datasets
- Two dialogue datasets with human-human conversations
- Cam676: 676 dialogues from the restaurant domain
-
MultiWOZ: Each dialogue can span multiple domains
- SNG: 3406 dialogues in single domain
- MUL: 10,438 dialogues in multiple domains
- Two Metrics for goal completeness:
- Match: Correct entity was suggested according to dialogue goal
- Success: If it is a match and correct requestable slots were produced
Results on Human-Human Dialogue Datasets
Results on Cam676

Results on MultiWOZ

Human Evaluations
- Randomly chosen responses from 200 dialogues of En-DSTC2 and Cam676
- Pairwise comparison task between our model and best baseline
- Evaluators could choose tie if both responses were good or bad

Conclusion
-
A single attention distribution overburdens the attention mechanism
-
Separated the history into Pre-KB, KB and Post-KB parts and attended sequentially over them
-
Showed that structure-aware representations are useful in goal-oriented dialogue
-
Used GCNs to infuse structural information of dependency graphs into the learned representations
- Introduced a goal-oriented code-mixed dialogue dataset for four languages
-
When dependency parsers are not available, we used word co-occurrence frequencies and PPMI values to extract a contextual graph
-
Obtained state-of-the-art performance on four datasets.
Future Work
-
Extend the model to multidomain goal-oriented dialogue (restaurants, hotels, taxi)
-
Conditional code-mixed response generation
-
Use the whole Knowledge-Graph instead of dialogue specific KB triples
-
Use semantic graphs along with dependency parse trees
Publications
- Suman Banerjee, Nikita Moghe, Siddhartha Arora and Mitesh M. Khapra, "A Dataset for building Code-Mixed Goal Oriented Conversation Systems", In the Proceedings of the 27th International Conference on Computational Linguistics, COLING, Santa Fe, New-Mexico, USA, August 2018.
- Suman Banerjee and Mitesh M. Khapra, "Graph Convolutional Network with Sequential Attention For Goal-Oriented Dialogue Systems", Transactions of the Association for Computational Linguistics (TACL), 2019.
Thank You
Language Understanding
Language Understanding
User utterance
Predicted
Intent
I need a cheap chinese restaurant in the north of town.
- Intent Classification
- request_rest
- request_address
- request_phone
- .
- .
- .
- book_table
- Given a collection of utterances \( u_i \) and intent labels \( l_i : D = \{ (u_1,l_1),(u_2,l_2), \dots, (u_n,l_n) \} \), train a model to predict the intent for each utterance.
Classifier
- Slot Filling
Semantic Frame
request_rest(cuisine=chinese, price=cheap, area=north)
Intent Classification
Intent Classification
Language Understanding
User utterance
Predicted
Tags
I need a cheap chinese restaurant in the north of town.
- Given a collection of utterances \( u_i \) and intent labels \( l_i : D = \{ (u_1,l_1),(u_2,l_2), \dots, (u_n,l_n) \} \), train a model to predict the intent for each utterance.
- Given a collection of tagged utterance words \( D = \{ ((u_{i1},u_{i2},...,u_{in_1}),(t_{i1},t_{i2},...,t_{in_1})) \}_{i=1}^n \), train a model to predict the tags for each word of the utterances.
- Evaluation: Intent accuracy, Slot tagging accuracy or Frame Accuracy
Slot Filling
| I | <null> |
| need | <null> |
| a | <null> |
| cheap | <price> |
| chinese | <cuisine> |
| restaurant | <null> |
| in | <null> |
| the | <null> |
| north | <area> |
| of | <null> |
| town | <null> |
Dialogue Management
- Dialogue State: Represents the system's belief about the user's goal at any turn in the dialogue.
User: Book a table at Prezzo for 5.
System: How many people?
User: For 3.
#People
Time

- Dialogue State Tracking:
- Used to generate API calls to the knowledge base (KB)
- Provide the results of the KB lookup and the dialogue state to the policy optimizer
- Policy Optimizer: Given the dialogue state (and additional inputs), generate the next system action.
- Evaluation:
- Turn level: system action accuracy
- Dialogue level: task completion rate
Language Generation
Language Generation
inform(rest=Prezzo, cuisine=italian)
System action
System response
Prezzo is a nice restaurant which serves italian.
- Template based:
- Map stores keys as system actions and values as natural language patterns.
- Replace the slots with the retrieved values
- Recurrent Neural Network (RNN) based:
- Use an RNN language model to generate the response conditioned on the system action
- Evaluation:
- Subjective: Use human ratings on correctness, grammar, coherence, etc
- Automatic: BLEU, ROUGE (word overlap based)