Incorporating Domain Knowledge in Multilingual, Goal-oriented Neural Dialogue Models
Suman Banerjee Mitesh M Khapra
Department of Computer Science and Engineering,
Indian Institute of Technology Madras
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Outline
-
Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Dialogue Systems

Siri
Cortana

Bixby
Google assistant

Alexa



Apple Homepod
Amazon Echo
Google Home
Two Paradigms
Challenges
- Variability in natural language
- Represent the meanings of utterances
- Maintaining context over long turns
- Incorporating world/domain knowledge
Chit-Chat
- Has no specific end goals
- Used for user engagement
- Focus on generating natural responses
Goal-Oriented
- Used to carry out a particular task
- Requires background knowledge
- Focus on generating informative responses that leads to task completion
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Modular Architecture
Language Understanding
Dialogue State Tracking
Policy Optimizer
Language Generation
User utterance
System response
Semantic Frame
System Action
Dialogue State
I need a cheap chinese restaurant in the north of town.
request_rest(cuisine=chinese, price=cheap, area=north)

Knowledge Base
request_people( )
Sure, for how many people?
Dialogue Manager
Probabilistic methods in spoken-dialogue systems, Steve J. Young, Philosophical Transactions: Mathematical, Physical and Engineering Sciences, 2000
Language Understanding
Language Understanding
User utterance
Predicted
Intent
I need a cheap chinese restaurant in the north of town.
- Intent Classification
- request_rest
- request_address
- request_phone
- .
- .
- .
- book_table
- Given a collection of utterances \( u_i \) and intent labels \( l_i : D = \{ (u_1,l_1),(u_2,l_2), \dots, (u_n,l_n) \} \), train a model to predict the intent for each utterance.
Classifier
- Slot Filling
Semantic Frame
request_rest(cuisine=chinese, price=cheap, area=north)
Intent Classification
Intent Classification
Language Understanding
User utterance
Predicted
Tags
I need a cheap chinese restaurant in the north of town.
- Given a collection of utterances \( u_i \) and intent labels \( l_i : D = \{ (u_1,l_1),(u_2,l_2), \dots, (u_n,l_n) \} \), train a model to predict the intent for each utterance.
- Given a collection of tagged utterance words \( D = \{ ((u_{i1},u_{i2},...,u_{in_1}),(t_{i1},t_{i2},...,t_{in_1})) \}_{i=1}^n \), train a model to predict the tags for each word of the utterances.
- Evaluation: Intent accuracy, Slot tagging accuracy or Frame Accuracy
Slot Filling
| I | <null> |
| need | <null> |
| a | <null> |
| cheap | <price> |
| chinese | <cuisine> |
| restaurant | <null> |
| in | <null> |
| the | <null> |
| north | <area> |
| of | <null> |
| town | <null> |
Dialogue Management
- Dialogue State: Represents the system's belief about the user's goal at any turn in the dialogue.
User: Book a table at Prezzo for 5.
System: How many people?
User: For 3.
#People
Time

- Dialogue State Tracking:
- Used to generate API calls to the knowledge base (KB)
- Provide the results of the KB lookup and the dialogue state to the policy optimizer
- Policy Optimizer: Given the dialogue state (and additional inputs), generate the next system action.
- Evaluation:
- Turn level: system action accuracy
- Dialogue level: task completion rate
Language Generation
Language Generation
inform(rest=Prezzo, cuisine=italian)
System action
System response
Prezzo is a nice restaurant which serves italian.
- Template based:
- Map stores keys as system actions and values as natural language patterns.
- Replace the slots with the retrieved values
- Recurrent Neural Network (RNN) based:
- Use an RNN language model to generate the response conditioned on the system action
- Evaluation:
- Subjective: Use human ratings on correctness, grammar, coherence, etc
- Automatic: BLEU, ROUGE (word overlap based)
Drawbacks
- Annotation of output labels required for each module
- Fixed Assumption on the dialogue state structure
- Difficult to scale to new domains
- Error propagation from previous modules
- May not be able to manually list all slot values that the user may refer to
Language Understanding
Dialogue State Tracking
Policy Optimizer
Language Generation
User utterance
System response
Semantic Frame
System Action
Dialogue State
I need a cheap chinese restaurant in the north of town.
request_rest(cuisine=chinese, price=cheap, area=north)
Knowledge Base
request_people( )
Sure, for how many people?
Dialogue Manager
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
End-to-End Architecture
- Can be directly trained on utterance- response pair data, no intermediate supervision required
- Can be easily scaled to new domains
- No fixed assumption on the dialogue state structure
- Can handle out-of-vocabulary (OOV) words
User utterance
I need a cheap chinese restaurant in the north of town.
System response
Sure, for how many people?
Knowledge Base
End-to-End Dialogue System
bAbI Dialogue Dataset
System: Hello, what can I help you with today?
User: Hi!
User: I'd like to book a table for six people in an expensive restaurant with British food.
System: where should it be ?
User: Somewhere in the north of the town.
System: ok I am on it!
System: API_CALL (British, north, six, expensive)
The_Place R_cuisine British
The_Place R_location north
The_Place R_address The_Place_Address
The_Place R_price expensive
The_Place R_rating 10
Fancy_pub R_cuisine British
Fancy_pub R_location north
Fancy_pub R_address Fancy_pub_Address
Fancy_pub R_price expensive
Fancy_pub R_rating 8
System: How about The_Place?
User: No I don't like it.
System: Ok, then, what do you think about Fancy_Pub?
User: Yes! lets do it.
System: Great! I'll do the reservation.
User: What is the address?
System: Here it is: Fancy_Pub_Address
User: Thank You
System: You're welcome
Learning end-to-end goal-oriented dialog, Bordes et. al. , ICLR, 2017.
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Recurrent Neural Networks
\( x_1\)
\( x_2\)
\( x_3\)
\( x_4\)
\( x_5\)
\( U \)
\( U \)
\( U \)
\( U \)
\( U \)
\( W \)
\( W \)
\( W \)
\( W \)
\( V \)
\( V \)
\( V \)
\( V \)
\( V \)
\( s_1 \)
\( s_2 \)
\( s_3 \)
\( s_4 \)
\( s_5 \)
\( y_1\)
\( y_2\)
\( y_3\)
\( y_4\)
\( y_5\)
- \( s_i = \sigma (Ux_i + Ws_{i-1} + b)\)
- \( y_i = o(Vs_i +c) \)
\( s_0\)
\( W \)
Find a cheap Chinese restaurant
\( s_i = RNN (s_{i-1},x_i)\)
Sequence-to-Sequence Models
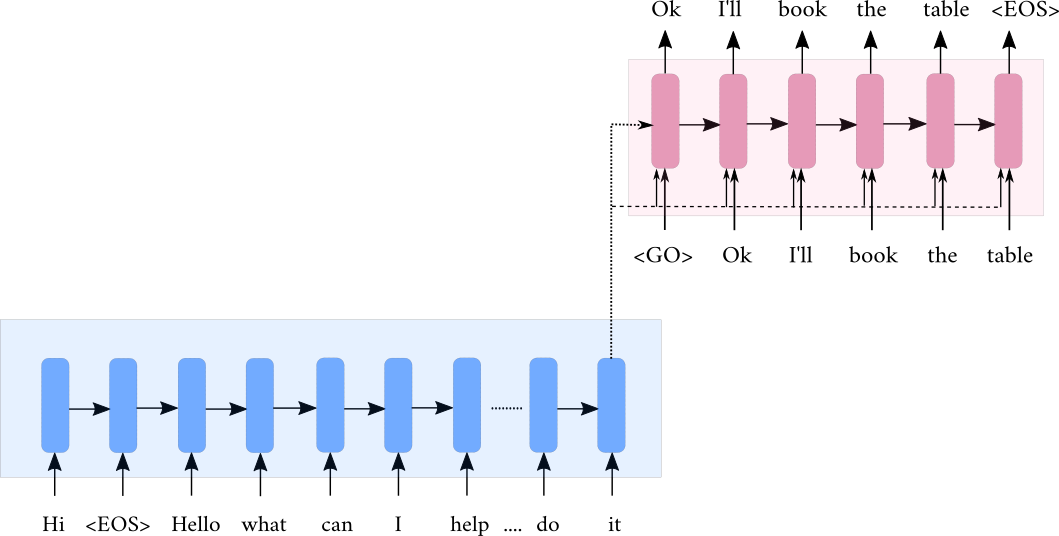
- Dialogue : \( \{ (u_1,s_1),(u_2,s_2),...,(k_1,k_2,...,k_m),...,(u_n,s_n) \} \)
- At \( t^{th}\) turn : Input : \( \{ u_1,s_1,u_2,s_2,..,u_t \} \) and Output : \( s_t \)
- Flatten the input into tokens : Input : \( \{ m_1,m_2,....,m_k \} \) and Output: \( \{y_1,y_2,...,y_c \} \)
Encoder:
- \( h_i = RNN(h_{i-1},m_i)\)
Decoder:
- \( d_t = RNN(d_{t-1},\hat{y}_t)\)
- \( d_0 = h_k \)
- \( \hat{y}_t = \sigma (Vd_t + c) \)
Sequence-to-Sequence Models
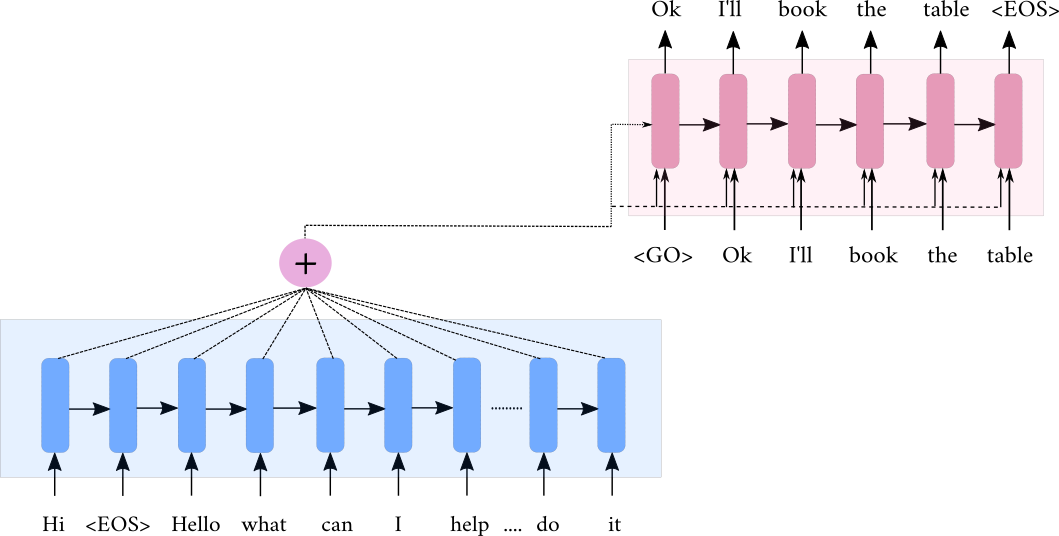
- Dialogue : \( \{ (u_1,s_1),(u_2,s_2),...,(k_1,k_2,...,k_m),...,(u_n,s_n) \} \)
- At \( t^{th}\) turn : Input : \( \{ u_1,s_1,u_2,s_2,..,u_t \} \) and Output : \( s_t \)
- Flatten the input into tokens : Input : \( \{ m_1,m_2,....,m_k \} \) and Output: \( \{y_1,y_2,...,y_c \} \)
Encoder:
- \( h_i = RNN(h_{i-1},m_i)\)
Decoder:
- \( d_t = RNN(d_{t-1},[\hat{y}_t;c_t])\)
- \( d_0 = h_k \)
- \( \hat{y}_t = \sigma (Vd_t + c) \)
Attention:
- \( e_{it} = V_{1}^Ttanh(W_1h_i+W_2d_t)\)
- \( \alpha_{t} = softmax (\textbf{e}_t)\)
- \( c_t = \sum^{k}_{j=1}\alpha_{jt}h_j\)
Neural Machine Translation by Jointly Learning to Align and Translate, Bahdanau et. al., ICLR, 2015
Hierarchical Recurrent Encoder Decoder
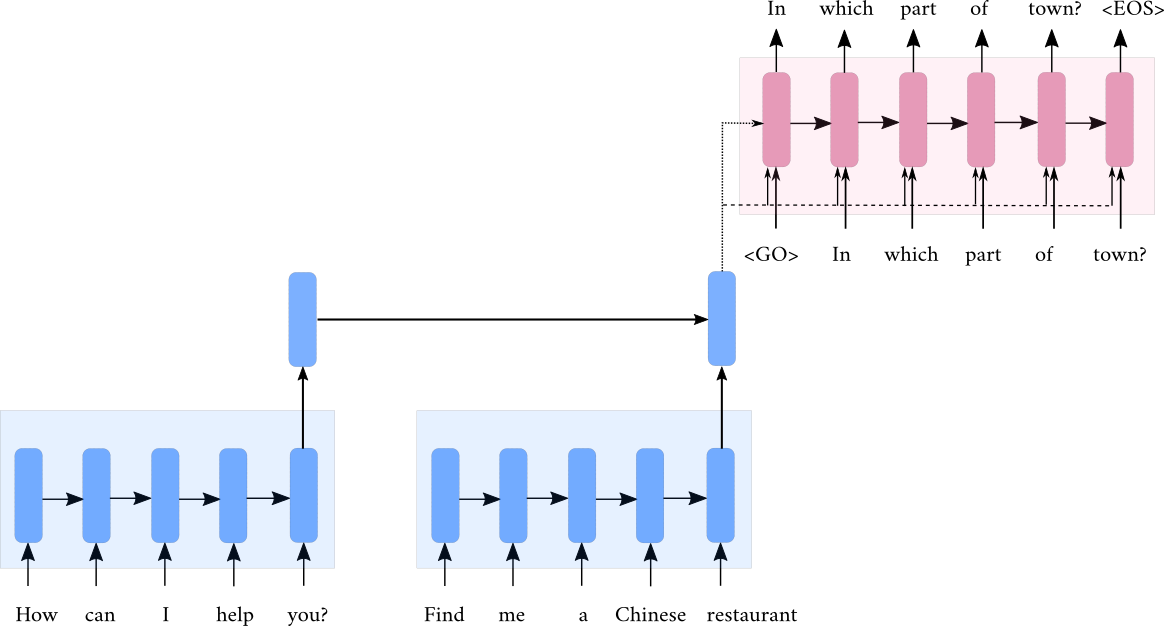
Building End-to-End Dialogue Systems Using Generative Hierarchical Neural Network Models, Serban et. al., AAAI, 2016
Memory Networks
- Dialogue : \( \{ (u_1,s_1),(u_2,s_2),...,(k_1,k_2,...,k_m),...,(u_n,s_n) \} \)
- At \( t^{th}\) turn :
- Dialogue History = \( \{ u_1,s_1,...,k_1,k_2,...,k_m,...,s_{t-1}\} \)
- Current user utterance = \( u_t \)
- Predict \(s_t\) from a set of candidate responses : \( \{ y_1,y_2,...,y_c \} \)
- Memory:
- \( m=\{ A \phi(u_1), A \phi(s_1),..., A\phi(k_1),..., A\phi(k_m),..., A\phi(s_{t-1}) \} \)
- \( \phi\) : Bag-of-words function and \( A\in \mathbb{R}^{d \times V}\)
- \( m= \{ \mathbf{m}_1,\mathbf{m}_2,...,\mathbf{m}_e\} \)
- Query : \( \mathbf{q}^1 = A\phi(u_t)\)
- Attention :
- \( a^b_i = \mathbf{q}^{bT}\mathbf{m}_i \)
- \( \mathbf{p}^b = softmax(\mathbf{a}^b) \)
- \( \mathbf{o}^b = \sum_{j=1}^e \mathbf{m}_i p^b_i\)
- \( \mathbf{q}^{b+1}= \mathbf{o}^b + \mathbf{q}^b\)
- Prediction: if total number of hops is B then:
- \( \hat{z} = softmax(\mathbf{q}^{B+1} W \phi(y_1) ,..., \mathbf{q}^{B+1} W \phi(y_c)) \)
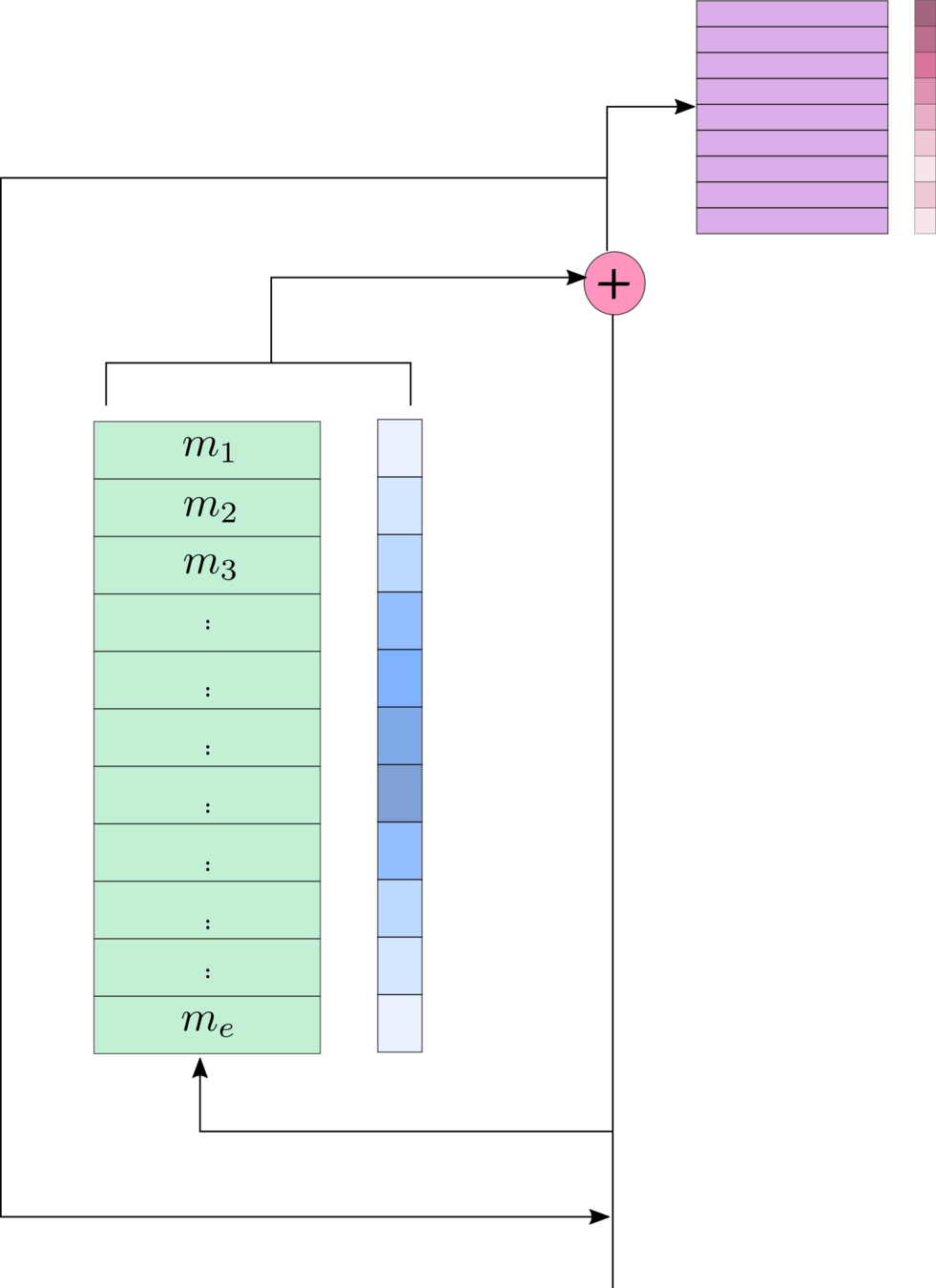
\( \mathbf{q}^1\)
\( \mathbf{q}^b\)
\( \mathbf{q}^{b+1}\)
\( \mathbf{q}^{b+1}\)
\( \mathbf{o}^b\)
\( \mathbf{p}^b\)
Candidates
\( \mathbf{q}^b\)
\( \mathbf{q}^{B+1}\)
\( W\)
\( \hat{z}\)
\( \phi(y_i)\)
End-to-End Memory Networks, Sukhbaatar et. al., NeurIPS 2015
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Goal-oriented Dialogue phases
Pre-KB
System: Hello, what can I help you with today?
User: Hi!
User: I'd like to book a table for six people in an expensive restaurant with British food.
System: where should it be ?
User: Somewhere in the north of the town.
System: ok I am on it!
System: API_CALL (British, north, six, expensive)
System: How about The_Place?
User: No I don't like it.
System: Ok, then, what do you think about Fancy_Pub?
User: Yes! lets do it.
System: Great! I'll do the reservation.
User: What is the address?
System: Here it is: Fancy_Pub_Address
User: Thank You
System: You're welcome
KB
Post-KB
The_Place R_cuisine British
The_Place R_location north
The_Place R_address The_Place_Address
The_Place R_price expensive
The_Place R_rating 10
Fancy_pub R_cuisine British
Fancy_pub R_location north
Fancy_pub R_address Fancy_pub_Address
Fancy_pub R_price expensive
Fancy_pub R_rating 8
Single Attention Distribution

- Current models treat the three different phases as one long sequence.
- Use a single long RNN or Memory Network to encode the three different phases.
- Compute a single attention distribution over these representations.
- This way of computing the attention overburdens the attention mechanism.
Sequential Attention
- We propose a sequential attention mechanism that computes three different attention distributions with a sequential dependency.
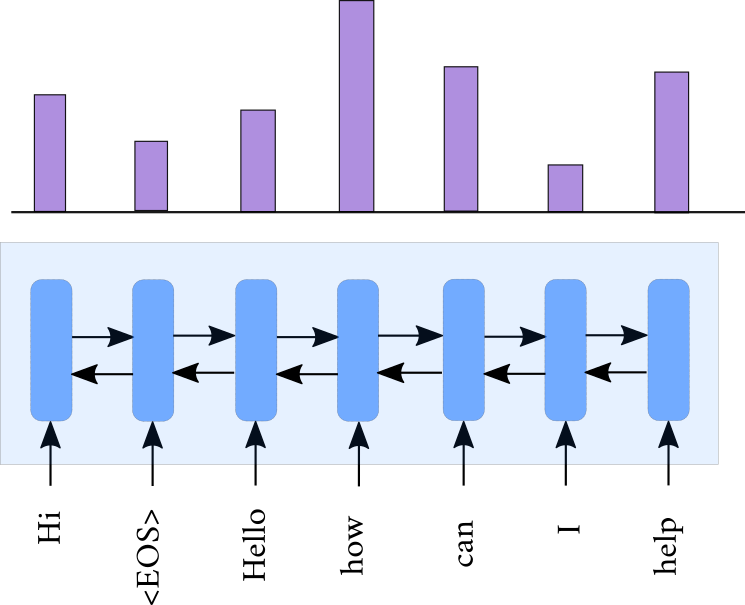
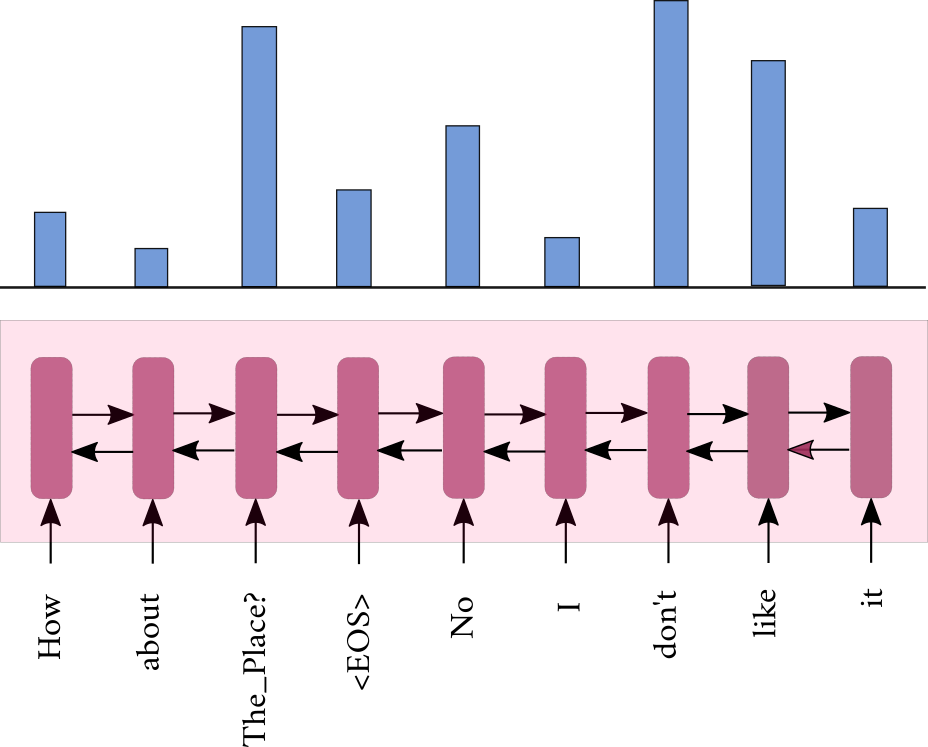
- The decoder aggregates the information from these three phases
- Generates the response word by word using an RNN
Pre-KB
Post-KB
KB
Sequential Attention
- Dialogue of n turns : \( (u_1,s_1),(u_2,s_2),...,(k_1,k_2,k_m),...,(u_n,s_n)\)
- Phases:
- Pre-KB : \( (u_1,s_1,u_2,s_2,...,u_i,s_i ) \) and let the embeddings be : \( (x_1,x_2,...,x_r) \)
- KB : \( (k_1,k_2,...,k_m) \)
- Post-KB : \( (u_{i+1},s_{i+1},...,u_n,s_n ) \) and let the embeddings be : \( (g_1,g_2,...,g_p) \)
- At turn \( k\) the user utterance \( u_k = (q_1,q_2,...,q_q) \) is considered as the query to the system
- The system is supposed to generate the response: \( s_k \)
Post-KB
- \( h^P_t = BiRNN(h^P_{t-1},g_t) \)
- \( h^Q_t = BiRNN(h^Q_{t-1},q_t) \)
- \( e_{jt} = softmax(V_1^Ttanh(w_1h^P_j + w_2d_{t-1} + w_3h^Q_q)) \)
- \( \mathbf{\alpha}_t = softmax(\mathbf{e}_t)\)
- \( h_{post} = \sum_{j=1}^{p} \alpha_{jt}h_j^P \)
Sequential Attention
KB
- For each \( k_i \) we run a 3 step RNN and use the last state \( h^K_i\)
- These \( h^K_i \) are used as the memory representations in a memory network
- \( p^b_i = softmax(u^bW^b_mh^K_i)\)
- \( o^b = \sum_{j=1}^m p^b_jh^K_j \)
- \( u^{b+1} = u^b + o^b \)
- Sequential Attention : \( u_1 = h_{post} + d_{t-1} + h^Q_q \)
- Final hop's output vector is the KB representation : \( h_{kb} = o^{B+1} \)
Pre-KB
- \( h_t^R = BiRNN(h_{t-1}^R,x_t)\)
- \( f_{jt} = V_2^Ttanh(w_4h_j^R + w_5d_{t-1} + w_6h^Q_q + w_7h_{post} + w_8h_{kb})\)
- \( \mathbf{\beta}_t = softmax(\mathbf{f}_t)\)
- \( h_{pre} = \sum_{j=1}^r \beta_{jt}h^R_j \)
End-to-End Network

Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Towards a tabular KB
The_Place R_cuisine British
_________________________________________
The_Place R_location north
___________________________________
The_Place R_address The_Place_Address
___________________________________
The_Place R_price expensive
___________________________________
The_Place R_rating 10
___________________________________
Fancy_pub R_cuisine British
___________________________________
Fancy_pub R_location north
___________________________________
Fancy_pub R_address Fancy_pub_Address
___________________________________
Fancy_pub R_price expensive
___________________________________
Fancy_pub R_rating 10
KB Triples
| name | cuisine | location | address | price | rating |
|---|---|---|---|---|---|
| The_Place | British | north | The_Place_Address | expensive | 10 |
| Fancy_pub | British | north | Fancy_pub_Address | expensive | 8 |
Tabular KB
2D Memory Network
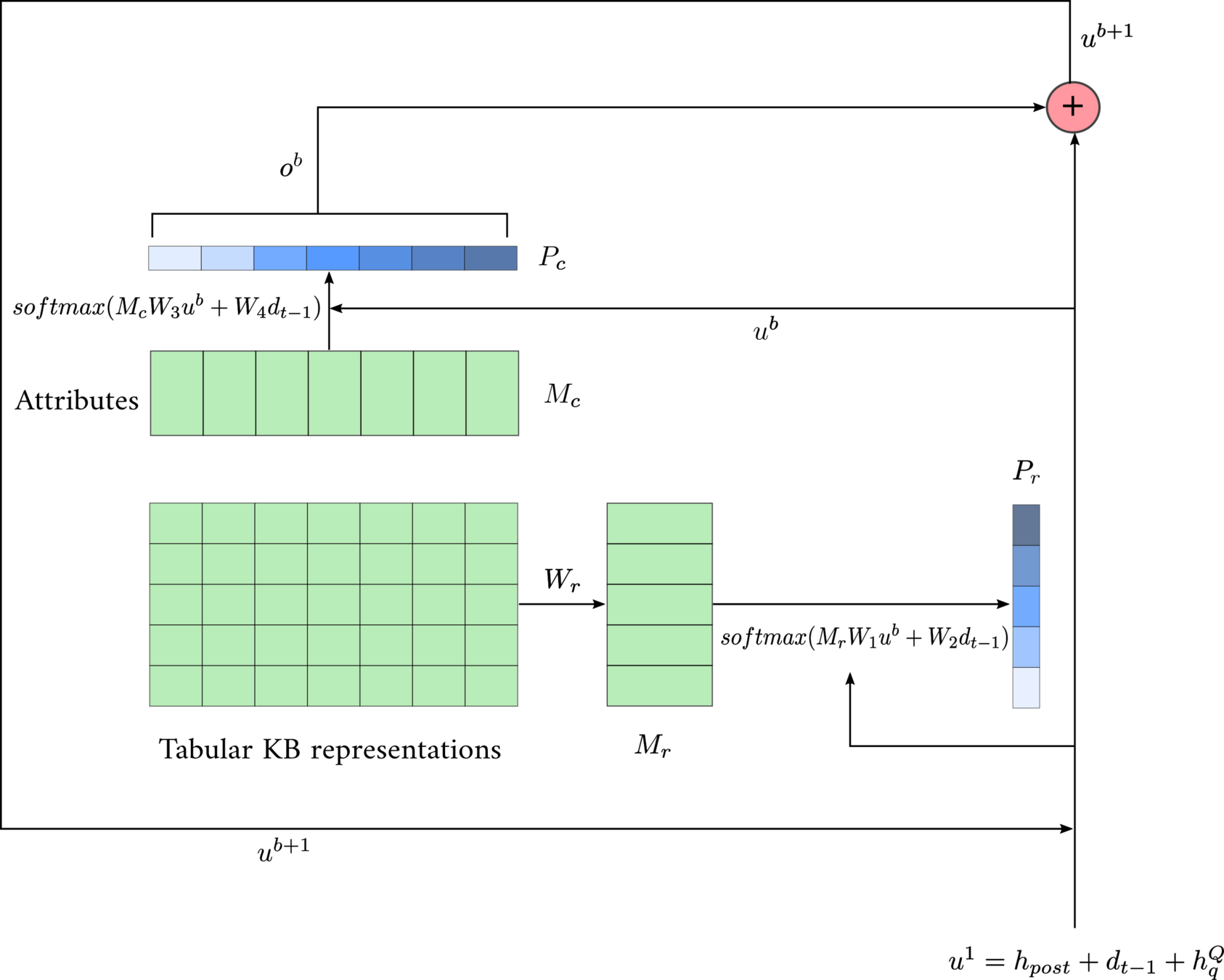
- \( P_{attn} = P_rP_c^T\)
\( u^b\)
2D Memory Network
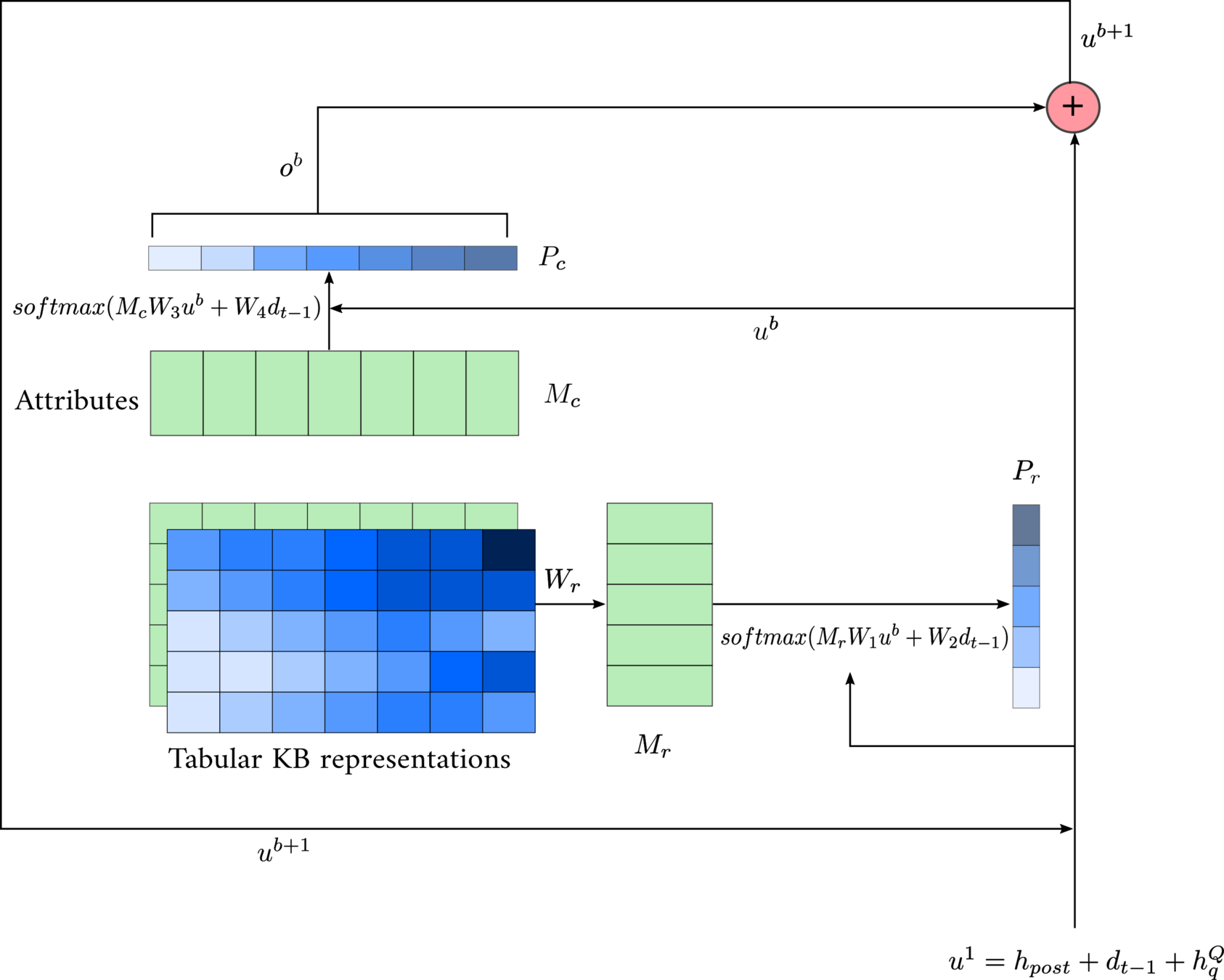
- \( P_{attn} = P_rP_c^T\)
- \( o^b = \sum _{i=1}^M \sum_{j=1}^N P_{attn}(i,j) \cdot KB(i,j) \)
\( u^b\)
End-to-End Network
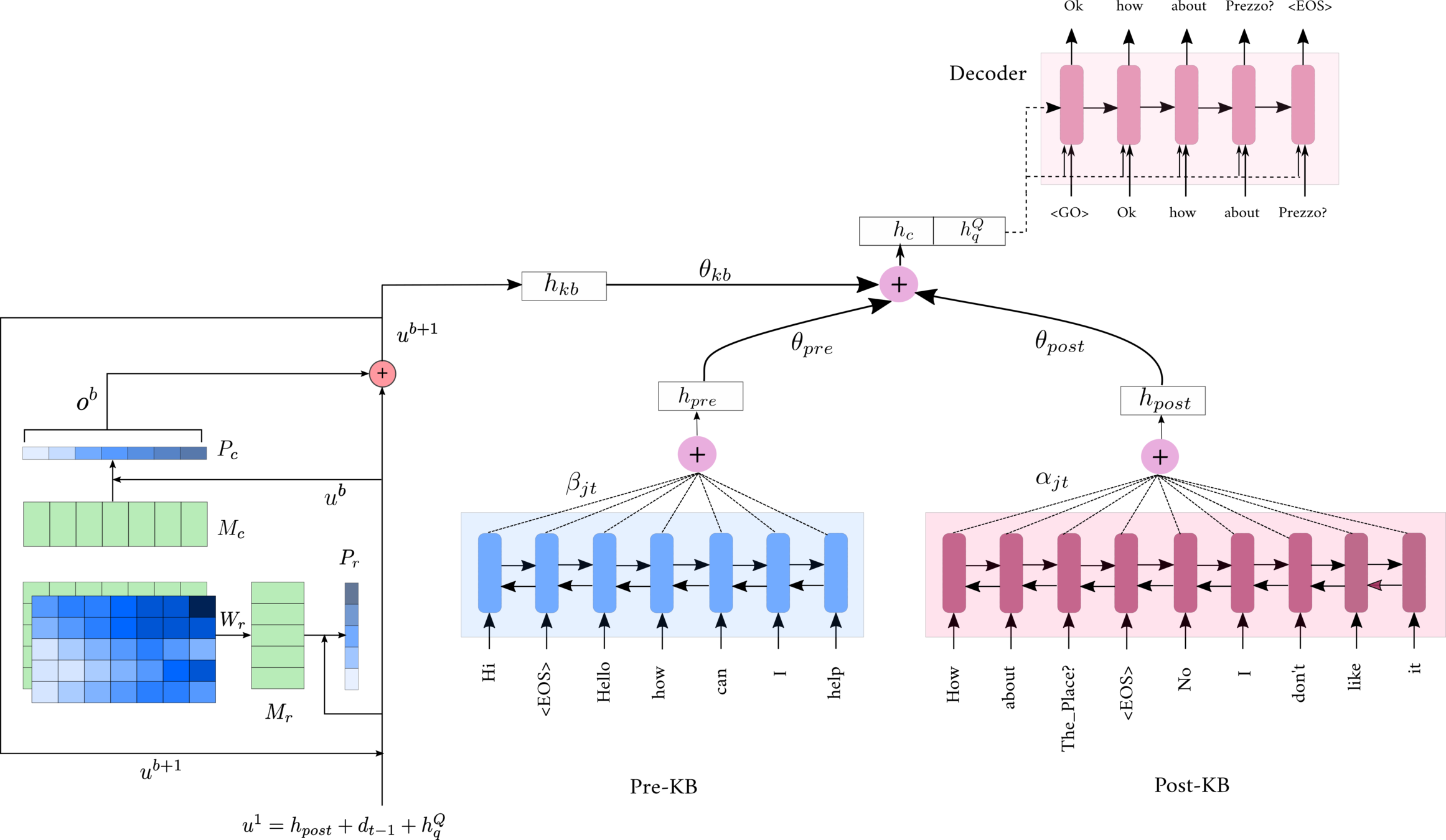
Soft Copying Mechanism
- The_Place is a nice restaurant that serves British food.
- Fancy_pub is a nice restaurant that serves British food.
- Prezzo is a nice restaurant that serves Italian food.
- <restaurant> is a nice restaurant that serves <cuisine> food.
- To inject proper entities in the responses we need to copy the correct entities from the KB
- The backbone of the sentences should be generated from the vocabulary
- We use a soft copying mechanism to copy the entities from the KB:
- \( P_{gen} = \sigma (W_1h_{kb} + W_2d_{t-1} ) \)
- \( P(w) = P_{gen}P_{vocab} + (1-P_{gen})P_{attn}(w) \)
Get To The Point: Summarization with Pointer-Generator Networks, See et.al., ACL, 2017
Supervision for Copy Mechanism
| name | cuisine | location | address | price | rating |
|---|---|---|---|---|---|
| The_Place | British | north | The_Place_Address | expensive | 10 |
| Fancy_pub | British | north | Fancy_pub_Address | expensive | 8 |
Tabular KB
| words : | The_Place | serves | British | food | and | the | prices | are | expensive |
\( l_c \)
\( l_{pos} \)
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| (0,0) | (-1,-1) | (0,1) | (-1,-1) | (-1,-1) | (-1,-1) | (-1,-1) | (-1,-1) | (0,4) |
- Use two additional components with the generation loss to supervise the copy mechanism:
Improve KB attention scores
Improve \( P_{gen} \)
Results

- per-response accuracy: exact match accuracy between the generated response and the ground truth.
- BLEU: n-gram overlap based metric to evaluate generation quality
- Entity F1: Micro-average of F1 scores between ground truth entities and generated entities.
- We evaluate on the modified DSTC2 dataset for restaurant reservations from bAbI dialogue datasets.
- The dialogues contain 3 slots : area, cuisine and price range.
- Users sometimes change their goals and look for alternative areas, cuisines and price ranges.
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
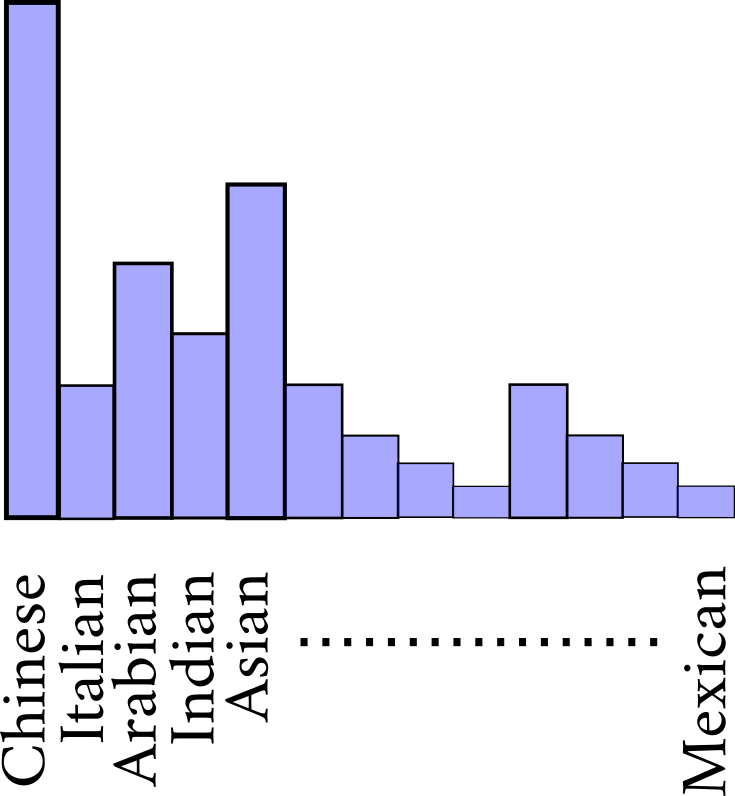
Code Mixing
Speaker 1: Hi, can you help me with booking a table at a restaurant?
Speaker 2: Sure, would you like something in cheap, moderate or expensive?
Speaker 1: Hi, kya tum ek restaurant mein table book karne mein meri help karoge?
Speaker 2: Sure, aap ko kaunsi price range mein chahiye, cheap, moderate ya expensive?
Speaker 1: Hi, tumi ki ekta restaurant ey table book korte amar help korbe?
Speaker 2: Sure, aapni kon price range ey chaan, cheap, moderate na expensive?
Data Collection
- Build on top of modified DSTC2 dataset for restaurant reservations from bAbI dialogue datasets.
- Collect code-mixed dialogues using this dataset in four languages :
- Hindi-English, Bengali-English, Gujarati-English and Tamil-English.
Extract Unique
Utterances
Replace entities
with placeholders
Unique
utterances
Crowdsource
code-mixing
utterance templates
Replace placeholders
with entities
code-mixed templates
Replace utterances
back into dialogue
code-mixed
utterances
code-mixed dialogue data
English
dialogue data
Sorry there is no Chinese restaurant in the west part of town
Sorry there is no Italian restaurant in the north part of town
Sorry there is no <CUISINE> restaurant in the <AREA> part of town
Data Evaluation
- We code-mixed individual utterances and stitched them back into a dialogue
- How do we ensure that the dialogue makes sense:
- We did Human Evaluations:
- 100 randomly chosen dialogues
- 3 evaluators per language
- 3 criteria for evaluation of a dialogue:
- Colloquialism: code-mixing was colloquial throughout the dialogue and not forced
- Intelligibility: dialogue can be understood by a bilingual speaker
- Coherent: dialogue looks coherent with each utterance fitting appropriately in the context

Quantification of Code-mixing
- Code-mixing : Foreign language words embedded into a Native (Matrix) language sentence.
- where \( x\) is an utterance
- \( N(x) \) is the number of language specific tokens in \(x\)
- \( \mathcal{L} \) is the set of all languages and \( t_{L_i}\) is the number of tokens of language \(L_i\)
- Consider the number of language switch points in an utterance : \( \frac{P(x)}{N(x)}\)
Comparing the level of code-switching in corpora, Björn Gambäck and Amitava Das, LREC, 2016
- "Prezzo ek accha restaurant hain in the north part of town jo tasty chinese food serve karta hain."
Quantification of Code-mixing
Comparing the level of code-switching in corpora, Björn Gambäck and Amitava Das, LREC, 2016
- We replace the \( \text{max} \) with the following:
- With other two other factors :
- \( \delta(x) \) : for inter-utterance mixing
- \(S\) : number of code-mixed utterances out of \(U\) utterances.

Baseline Results
- These models ignore the code-mixing in the input
- Performance is close to the range of results on the English version
- Established initial baseline results using two generation based models:
- Sequence-to-sequence with attention
- Hierarchical Recurrent Encoder-Decoder (HRED)

Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
-
Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Structural Information
- How can we find structure in the dialogue data?

Dependency Parse of sentences

Knowledge Graph
- Current state of the art models ignore this rich structural information
- We exploit this structural information in our model
- Couple it with the sequential attention mechanism
- Empirically show that such structural information aware representations improve the response generation task
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Graph Convolutional Network (GCN)


- GCN computes representations for the nodes of a graph by looking at the neighbourhood of the node
- Formally, \( \mathcal{G = (V,E)}\) be a graph
- Let \( \mathcal{X} \in \mathbb{R}^{n \times m}\) be the input feature matrix for \(n\) nodes
- Each node (\(\mathbf{x}_u \in \mathbb{R}^m\)) is an m-dimensional feature vector.
- The output of 1-hop GCN is \( \mathcal{H} \in \mathbb{R}^{n \times d}\)
- Each \( \mathbf{h}_v \in \mathbb{R}^{d}\) is a node representation that captures the 1-hop neighbourhood information
- Here \(k\) is the hop number
- \(\mathbf{h}^1_u = \mathbf{x}_u \)
- \( \mathcal{N}(v)\) is the set of neighbours of node \(v\)
Semi-supervised classification with graph convolutional networks. Kipf and Welling, ICLR, 2017.
Problem Formulation
- Dialogue : \( \{ (u_1,s_1),(u_2,s_2),...,(k_1,k_2,...,k_e),...,(u_n,s_n) \} \)
- Each \(k_i\) is of the form: (entity\(_1\), relation, entity\(_2\))
- The KB triples can be represented as a graph : \( \mathcal{G}_k = (\mathcal{V}_k,\mathcal{E}_k) \)
- where \(\mathcal{V}_k\) is the set of entities in the KB triples
- \( \mathcal{E}_k\) is the set of edges where each edge is of the form : (entity\(_1\), entity\(_2\), relation)
- At the \( t^{th}\) turn of the dialogue, given the:
- Dialogue History: H = \( (u_1,s_1,...,s_{t-1}) \)
- The current user utterance as query: Q = \( u_t\)
- The knowledge graph \(\mathcal{G}_k\)
- The task is to generate the current system utterance \(s_t\)
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Syntactic GCNs with RNN

- Obtain the dialogue history graph : \( \mathcal{G}_H =(\mathcal{V}_H,\mathcal{E}_H)\)
- where \(\mathcal{V}_H\) contains all the tokens in the dialogue history
- \(\mathcal{E}_H\) contains the dependency edges of each sentence in the history
GCN with Sequential Attention

Query Attention
\[ \mu_{jt} = \mathbf{v}_1 tanh(W_1\mathbf{c}^f_j + W_2\mathbf{d}_{t-1}) \]
\[ \boldsymbol\alpha_{t} = softmax(\boldsymbol\mu_t) \]
\[ \mathbf{h}^Q_t =\textstyle \sum_{j'=1}^{|Q|} \alpha_{j't}\mathbf{c}_{j'}^f \]
History Attention
\[\nu_{jt} = \mathbf{v}_2 tanh(W_3\mathbf{a}^f_j + W_4\mathbf{d}_{t-1} + W_5\mathbf{h}^Q_t)\]
\[ \boldsymbol\beta_{t} =softmax(\boldsymbol\nu_t)\]
\[ \mathbf{h}^H_t =\textstyle \sum_{j'=1}^{|H|} \beta_{j't}\mathbf{a}_{j'}^f \]
KB Attention
\[ \omega_{jt} = \mathbf{v}_3 tanh(W_6\mathbf{r}^f_j + W_7\mathbf{d}_{t-1} + W_8\mathbf{h}^Q_t + W_9\mathbf{h}^H_t)\]
\[\boldsymbol\gamma_{t} =softmax(\boldsymbol\omega_t)\]
\[ \mathbf{h}^K_t = \textstyle \sum_{j'=1}^m \gamma_{j't}\mathbf{r}_{j'}^f \]
GCNs for code-mixed utterances
- Dependency Parsers are not available for code-mixed sentences
- Need an alternate way of extracting structural information
- Create a global word co-occurrence matrix from the entire corpus
- The context window of a word is the entire length of its sentence
- Connect edges between two words if their co-occurrence frequency is above a certain threshold value
- We experiment with raw frequency and Positive Pointwise Mutual Information (PPMI)\(^1\) values
- Decided the threshold by taking the median of non-zero entries in the matrix
\(^1\)Word association norms mutual information, and lexicography, Church and Hanks, Computational Linguistics, 1990
Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Copy Mechanism
- Ground Truth response = \( \{ y_1,y_2,...,y_m \} \)
- Memory = \( \mathcal{V}_k \bigcup \) '#'
- Pointer Label: \(labelc = \{ lc_1,lc_2,..., lc_m\} \)

Memory Network
\( P^k = softmax(r^fC^kq_k)\)
\( q^{k+1} = q_k + \sum_{j=1}^{l+1}P^k_jf^f_j\)
\( q^{1} = d_{t}\)
'#'
\( P_{vocab} = softmax(V'd_{t} + b')\)
= \(\{m_1,m_2,....,m_l,m_{l+1} \}\)
Copy Mechanism

Outline
- Dialogue Systems
- Modular Architecture
- End-to-End Architecture
- Existing Neural Dialogue Models
- Sequential Attention Network (SeAN)
- 2D Memory Network
- Code-mixing in Dialogue
- Incorporating structural information
- Graph Convolutional Network(GCN)
- GCN with Sequential Attention
- Copy Mechanism
- Results and Analysis
- Conclusion
Results on En-DSTC2
RNN + CROSS -GCN--SeA
- Connect edges between query/history words and KB entities if they exactly match
- Creates one global graph, encoded using one GCN
- Then separated into different contexts to perform the sequential attention

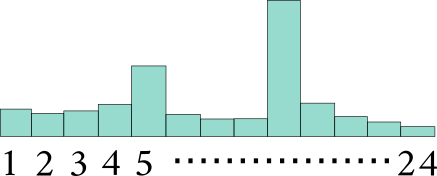
Results on code-mixed data

Effect of using more GCN hops






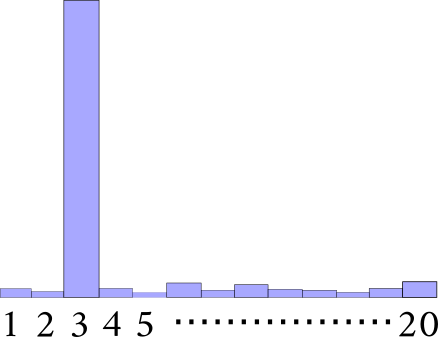
PPMI vs Raw Frequencies

- Using the PPMI scores gives a better contextual graph compared to using raw frequency
- Evident across all other languages except English
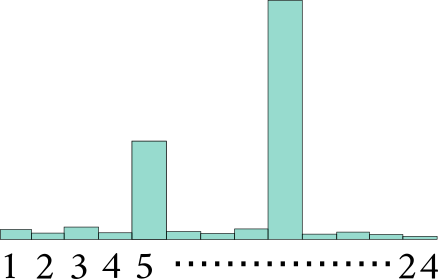
Dependency or co-occurrence structure really needed ?
- Connected edges between two randomly chosen words in the query and the dialogue history
- Encoded such a random graph using GCNs
- Used the sequential attention mechanism for generating responses
- Did not use RNN on top to avoid its influence on the encodings

Ablations
- RNN with attention (basic seq2seq model of Bahdanau et. al., 2015)
- GCN with Bahdanau attention (does not use RNN or our Sequential attention)
-
RNN+GCN with Bahdanau attention (does not use our Sequential attention)
-
RNN with our Sequential attention (does not use GCNs)
-
RNN+GCN with our Sequential attention (Our final model)

Ablations
-
GCNs do not outperform RNNs independently:
-
performance of GCN-Bahdanau attention < RNN-Bahdanau attention
-
-
Our Sequential attention outperforms Bahdanau attention:
-
GCN-Bahdanau attention < GCN-Sequential attention
-
RNN-Bahdanau attention < RNN-Sequential attention (BLEU & ROUGE)
-
RNN+GCN-Bahdanau attention < RNN+GCN-Sequential attention
-
-
Combining GCNs with RNNs helps:
-
RNN-Sequential attention < RNN+GCN-Sequential attention
-
-
Best results are always obtained by the final model which combines RNN, GCN and Sequential attention
Conclusion
-
Observed that end-to-end neural models for goal-oriented dialogue systems generate responses by conditioning on the whole conversation history
-
This overburdens a single attention mechanism
-
Overcome this problem by separating the history into Pre-KB, KB and Post-KB parts and attending sequentially over them
-
Tried to develop a 2D memory network to attend to particular entities in the KB
-
Observed that the development of dialogue systems still rely on monolingual conversation datasets.
-
To alleviate this problem we introduced a goal-oriented code-mixed dialogue dataset for four languages
-
Quantified the amount of code-mixing present in the dataset
-
Established initial baseline models that are code-mixing agnostic and still perform decently
-
Showed that structure-aware representations are useful in goal-oriented dialogue
-
Used GCNs to infuse structural information of dependency graphs to enrich the representations of the dialogue context and KB
-
Proposed a sequential attention mechanism for combining these representations
-
When dependency parsers are not available then we can use word co-occurrence frequencies and PPMI values to extract a contextual graph
-
Obtained state-of-the-art performance on the bAbI dataset and its code-mixed versions
Publications
- A Dataset for building Code-Mixed Goal Oriented Conversation Systems, Suman Banerjee, Nikita Moghe, Siddhartha Arora and Mitesh M. Khapra, In the Proceedings of the 27th International Conference on Computational Linguistics, COLING, Santa Fe, New-Mexico, USA, August 2018.
- Graph Convolutional Network with Sequential Attention For Goal-Oriented Dialogue Systems, Suman Banerjee and Mitesh M. Khapra, Transactions of the Association for Computational Linguistics (TACL), 2019. (Under Review)
Questions!!