A hands on session on Python
SNAKES ON THE WEB :- Python
Sumit Raj

About Me:
- Techie | Author | Trainer | Mentor | Startups
- Working as Principal Engineer at Unacademy
- Authored internationally published book "Building Chatbots with Python", translated in Portuguese, Korean.
- Avid Quora writer - Over a million views so far.
- Guest speaker and hackathon lover.



Contents
- Introduction
- Working with iPython
- Running Python Scripts
- Variables
- User Input, Comments, Indentations
- Data Types
- Strings
Introduction
What is Python?
-
General purpose, object-oriented, high level programming language
-
Widely used in the industry for building APIs, writing server side scripts, Data Analytics, Data Science and ML algorithms, Game Development, Scientific Research
-
Used in web programming and in standalone applications
History
- Created by Guido von Rossum in 1990 (BDFL)
- Named after Monty Python's Flying Circus
- http://www.python.org/~guido/
- Blog http://neopythonic.blogspot.com/
- Now works for Microsoft

Why Python?
-
Readability, maintainability, very clear readable syntax
-
Fast development and all just works the first time.
-
Very high level dynamic data types
-
Automatic memory management
-
Free and open source
-
Implemented under an open source license. Freely usable and distributable, even for commercial use.
-
Simplicity, Availability (cross-platform), Interactivity (interpreted language)
-
Build things yourself, Python is enough on any platform
Batteries included
- The Python standard library is very extensive
- regular expressions, codecs
- date and time, collections, theads and mutexs
- OS and shell level functions (mv, rm, ls)
- Support for SQLite and Berkley databases
- zlib, gzip, bz2, tarfile, csv, xml, md5, sha
- logging, subprocess, email, json
- httplib, imaplib, nntplib, smtplib
- and much, much more ...
Who uses Python?
Hello World
Lets write our first Python Program
print("Hello World!")Python is Simple
print("Hello World!")
#include <iostream.h>
int main() {
cout << "Hello World!";
}public class helloWorld {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}Python
Java
C++
Python 2 Vs Python3
| Python 2 | Python 3 |
|---|---|
| Released 2000 | Released 2008 |
| print "hello" | print ("hello") |
| When two integers are divided, you always provide integer value. | Whenever two integers are divided, you get a float value. |
|
Not difficult to port python 2 to python 3 but it is never reliable. |
Python version 3 is not backwardly compatible with Python 2. |
Variables
>>> a = 'Hello world!' # this is an assignment statement
>>> print(a)
'Hello world!'
>>> type(a) # expression: outputs the value in interactive mode
<type 'str'>
>>> n = 12
>>> print(n)
12
>>> type(n)
<type 'int'>
>>> n = 12.0
>>> type(n)
<type 'float'>
>>> n = 'apa'
>>> print(n)
'apa'
>>> type(n)
<type 'str'>
- Variables are created when they are assigned
- No declaration required
- The variable name is case sensitive: ‘val’ is not the same as ‘Val’
- The type of the variable is determined by Python
- A variable can be reassigned to whatever, whenever
Basic Operators
| Operators | Description | Example |
|---|---|---|
| + | Addition | a + b will give 30 |
| - | Subtraction | a - b will give -10 |
| * | Multiplication | a * b will give 200 |
| / | Division | b / a will give 2 |
| % | Modulus | b % a will give 0 |
| ** | Exponent | a**b will give 10 to the power 20 |
| // | Floor Division | 9//2 is equal to 4 and 9/2 is equal to 4.5 |
Multiple Assignment
a, b = 1, 2Naming Identifiers and Reserved Words
- An identifier can consist of upper and lowercase letters of the alphabet, underscores, unicode identifiers, and digits 0 to 9.
- An identifier cannot begin with a digit; for example, 7x is an invalid variable name.
- No other characters can be in identifiers. This means spaces or any other symbols. Spaces most notably occur in module names as some operating systems will permit filenames with spaces. This should be avoided.
- A Python keyword cannot be used in an identifier name, for example, import, if, for, and lambda.
The following are examples of valid variable definitions
>>> meaning_of_life = 42
>>> COUNTRY = "Wakanda"
>>> Ω = 38.12
>>> myDiv = "<div></div>"
>>> letter6 = "f">>> foobar = 5
>>> Foobar = 5Let's solve this
Write a code to use distance in kms & time in hours to calculate and print speed in kilometers per hour, miles per hour, and meters per second.
Hints
- The formula for calculating speed is distance/time = speed.
- To convert kilometers to miles, divide the kilometers by 1.6.
- To convert kilometers to meters, multiply the kms by 1,000.
- To convert hours to seconds, multiply hours by 3,600.
distance_in_km = 150
time_in_hours = 2
distance_in_mi = distance_in_km / 1.6
distance_in_mtrs = distance_in_km * 1000
time_in_seconds = time_in_hours * 3600
speed_in_kph = distance_in_km / time_in_hours
speed_in_mph = distance_in_mi / time_in_hours
speed_in_mps = distance_in_mtrs / time_in_seconds
print("Speed in kilometers/hour is:", speed_in_kph)
print("Speed in miles/hour is:", speed_in_mph)
print("Speed in meters/sec is:", speed_in_mps)Solution
Solve it.
Write a snippet that will calculate the area and circumference of a circle with a radius of 9
Solution
PI = 3.14159
radius = 9
area = PI * radius ** 2
circumference = 2 * PI * radius
print("Circumference of the circle:", circumference)
print("Area of the circle:", area)User Input
message = input()Can you modify the π problem to take input?
Let's go back
We learnt user input, we learnt unpacking. Let's try this
name, age = input("What is your name? "), input("What is your age?")Comments
- Comments are an integral part of programming.
- There are three different ways to write Python comments, documentation strings (docstrings for short), inline comments, and block comments.
Block and inline comments start with a pound sign, #. A block comment comes in the line before the statement it annotates and is placed at the same indentation level:
Inline comments are placed on the same line as the statement it annotates:
# increment
counter = counter + 1 >>> print(foobar) # this will raise an error since foobar isn't definedBlock and Inline Comments
Doc String
A documentation string, or docstring for short, is a literal string used as a Python comment. It is written and wrapped within triple quotation marks; """ or '''.
"""
This Python script calculates the circumference and area of the circle.
"""
PI = 3.14159
radius = 7
area = PI * radius ** 2
circumference = 2 * PI * radius
print("Circumference of the circle:", circumference)
print("Area of the circle:", area)Solve it.
Write a script to generate a multiplication table from 1 to 10 for any given number.
- Use docstring
- Use comments
- Do not use for loop
- print a line using - before and after the table
Order of Operations
In Python, the order in which operators are evaluated is just as it is mathematically: PEMDAS.
1) Parentheses have the highest precedence.
Expressions inside parenthesis are evaluated first:
>>> (9 + 2) * 2
22
>>>2) Next, the exponentiation operator is given the second highest precedence:
>>> 2 ** 3 + 2
10
>>>3) Multiplication and division (including floor division and the modulo operation) have the same precedence. Addition and subtraction come next:
>>> 8 * 3 + 1
25
>>> 24 / 6 - 2
2
>>> 7 + 5 - 3
94) In cases where two operators have the same precedence (for example, addition and
subtraction), statements are evaluated left to right:
>>> 7 - 5 + 4
6
>>> 10 / 5 * 3
6.0Solve it
>>> 2**3**2The exception to the preceding rule is with exponents, which are evaluated from the right-most value. In the following example, the evaluation is equivalent to 2^(3^2):
Strings
>>> "a string"
'a string'
>>> 'foobar'
'foobar'
>>>
#A double-quoted string can contain single quotes:
>>> "Susan's"
"Susan's"
>>>
#A single-quoted string can also contain double quotes:
>>> '"Help!", he exclaimed.'
'"Help!", he exclaimed.'
>>>
#You can also build a multiline string by
#enclosing the characters in triple quotes ('''or """):
>>> s = """A multiline
string"""
>>> print(s)
A multiline
stringString Concatenation
>>> "I " + "love " + "Python"
>>> a = "Sumit"
>>> a * 5
String Indexing
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| p | y | t | h | o | n |
| -6 | -5 | -4 | -3 | -2 | -1 |
Slicing
>>> string.lower()
>>> string.upper()
>>> string[start:end:stride]
>>> S = 'hello world'
>>> S[0] = 'h'
>>> S[1] = 'e'
>>> S[-1] = 'd'
>>> S[1:3] = 'el'
>>> S[:-2] = 'hello wor'
>>> S[2:] = 'llo world'String Formatting
f"I am {name} and I own {dog_count} dogs"
Let's do it
Write a script that converts the last n letters of a given string to uppercase. The script should take the string to convert and an integer, specifying the last n letters to convert as input from the user
Input:
my_str = algotrading
n = 4
Output:
algotraDING
String Summary
- Strings are a sequence of characters.
- Strings can be enclosed in either single quotes (') or double quotes (").
- Multiline strings can be enclosed in either triple single quotes (''') or triple double quotes (""").
- Strings are immutable
- Characters in a string are indexed, and you can access each character by index. • The first element in a string is at the index 0.
- Substrings in a string can be accessed by slicing.
- Formatting strings allows you to insert values into a string.
- Strings come with several handy built-in methods for transforming or inspecting the string.
”Talk is cheap. Show me the code.”
Linus Torvalds
Lists
- In Python, arrays (or the closest abstraction of them) are known as lists.
- Lists are an aggregate data type, meaning that they are composed of other data types.
- Python, lists are heterogeneous, in that they can hold values of different types.
- Python lists are mutable, meaning that you can change the values inside of them, adding and removing items on the go.
List Operations
Indexing
#Like strings, lists can also be indexed. The first element in a list starts at the index 0:
>>> fruits = ["apples", "bananas", "strawberries", "mangoes"]
>>> fruits[2]
'strawberries'
#Negative indices can be used, as well:
>>> fruits[-1]
'mangoes'Slicing
- Lists can also be sliced. The slicing operation always returns a new list that's been derived from the old list.
- The syntax remains as list[start_index : end_index ].
>>> my_list = [10, 20, 30, 40, 50, 60, 70]
>>> my_list[4:5]
[50]
>>> my_list[5:]
[60, 70]Concatenation
- You can add two lists together by using the + operator.
- The elements of all of the lists being concatenated are brought together inside one list
>>> [1, 2, 3] + [4, 5, 6]
[1, 2, 3, 4, 5, 6]
>>> ["a", "b", "c"] + [1, 2.0, 3]
['a', 'b', 'c', 1, 2.0, 3]Changing Values in a List
- Since lists are mutable, you can change the value in a list by assigning whatever is at that index.
- You can assign slices of a list. Replaces the target slice with whatever you assign, regardless of the initial size of the list
>>> names = ["Eva", "Keziah", "John", "Diana"]
>>> names[2] = "Jean"
>>> names
['Eva', 'Keziah', 'Jean', 'Diana']
>>>Important to learn
When you assign a list, it points it to an object in the memory. If you assign another variable to the variable that references that list, the new variable also references that same list object in the memory.
Any changes made in the new variable will change the old list object in the memory.
1. Create a new list, as follows:
>>> list_1 = [1, 2, 3]
2. Then, assign a new variable, list_2, to list_1:
>>> list_2 = list_1
3. Any changes that we make to list_2 will be applied to list_1. Append 4 to
list_2 and check the contents of list_1:
>>> list_2.append(4)
>>> list_1
[1, 2, 3, 4]
4. Any changes that we make to list_1 will be applied to list_2. Insert the value a
at index 0 of list_1, and check the contents of list_2:
>>> list_1[0] = "a"
>>> list_2
['a', 2, 3, 4]Let's do it
Write a program that fetches the first n elements of a list.
array = [55, 12, 37, 831, 57, 16, 93, 44, 22]
print("Array: ", array)
n = int(input("Number of elements to fetch from array: "))
print(array[0: n])Solution
Comparison Operators
| Operator | Meaning |
|---|---|
| < | less than |
| > | greater than |
| >= | greater than equal to |
| == | equal to |
| != | not equal to |
| is | Object identity |
| is not | Negated object identity |
>>> 10 < 1
False
>>> len("open") <= 4
True
>>> 10 > 1
True
>>> len(["banana"]) >= 0
True
>>> "Foobar" == "Foobar"
True
>>> "Foobar" != "Foobar"
False
>>>
Now, consider the following code:
>>> l1 = [1, 2, 3]
>>> l2 = l1
>>> l1 is l2
True
>>> l is not None
True
>>>Logical Operators
- We use logic in everyday life. Consider the following statements:
- I'll have juice OR water if there isn't any juice.
- I am NOT tired; therefore, I will stay awake
| Operator | Result |
|---|---|
| not x | Returns false if x is true, else false |
| x and y | Returns x if x is false, else returns y |
| x or y | Returns y if x is false, else returns x |
The following is an example of and:
>>> fruits = ["banana", "mangoes", "apples"]
>>> wants_fruits = True
>>> len(fruits) > 0 and wants_fruits
True
>>>
The following code shows or in action:
>>> value_1 = 5
>>> value_2 = 0
>>> value_1 > 0 or value_2 > 0
True
>>>
Finally, the following is an example of not:
>>> not True
False
>>> not False
Truein operator
- The operators in and not in test for membership.
- The return values for these operators are True or False
>>> numbers = [1, 2, 3, 4, 5]
>>> 3 in numbers
True
>>> 100 in numbers
False
>>> sentence = "I like chicken, beer and whiskey"
>>> "fish" not in sentence
True
>>> "beer" not in sentence
FalseControl Statements
- Python program flow
- Python control statements, that is, if and while
- The differences between if and while
- The for loop
- The range function
- Nesting loops
- Breaking out of loops
The two main control statements in Python are:
- if
- while
if condition:
# Run this code if the condition evaluates to True
else:
# Run this code if the condition evaluates to Falserelease_year = 1991
answer = input('When was Python first released?')
if answer == release_year:
print('Congratulations! That is correct.')
elif answer > release_year:
print('No, that\'s too late')
elif answer < release_year:
print('No, that\'s too early')
print('Bye!')While
- A while statement allows you to execute a block of code repeatedly, as long as a condition remains true.
while True:
#do something
#break when done
break
else:
#do something when the loop ends
Practical While use
# Set the starting value
current = 1
# Set the end value
end = 10
# While the current number is less than or equal to the end number
while current <= end:
# Print the current number
print(current)
# Increment the current number by one
current += 1
else:
"""
Immediately the current number is not less than or equal to the end
number, print this statement.
Note that the statement is only printed out once
"""
print('You have reached the end')Using while to Keep a Program Running
while True:
passRewrite the program we wrote earlier and add a while statement
Step 1: Set release_year to 1991. This is the correct answer to the question that is going to be asked: Step 2: Next, set the correct condition to False. We will be using this condition to check whether we should break out of the while statement: Step 3: Now go into the body of the while statement. While the answer provided is not correct, keep the program running. Notice that we use a negative condition, where we check whether the provided answer is incorrect. Step 4: Print out the question to the terminal Step 5: Use an if statement to check that the provided answer is correct Step 6: If the answer is correct, print a success message to the terminal Step 7: After printing the message, set correct to True. This will cause the while loop to stop executing Step 8: If the answer is incorrect, encourage the user to try again. Step 9: Finally, print the exit message
Loops
- The for loop in Python is also referred to as the for…in loop
- A for loop is used when you have a block of code that you would like to execute repeatedly a given number of times.
for i in range(1, 5):
print(i)Write a program to print square of given numbers in a list
> list(range(2, 21, 2))
> [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]Solve it.
Using a for loop and a range function, you have been asked to find the even numbers between 2 and 100 and then find their sum.
Breaking Out of Loops
Python provides us with three statements that can be used to achieve this:
- break
- continue
- pass
break
for number in range(1,11):
# If the number is 4, exit the loop
if number == 4:
breakcontinue
for number in range(1,11):
# If the number is 4, continue the loop from the top
if number == 4:
continuepass
for number in range(1,11):
# If the number is 4, proceed as normal
if number == 4:
passLet's do it
Write a program that outputs values in a list ranging between 0 and 200.
- Don't print Zero
- Skip any number that is not divisible by 3
- Skip any value that is not an integer
for number in range(0, 200):
if number == 0:
continue
elif number % 3 != 0:
continue
elif type(number) != int:
continue
else:
pass
print(number)Functions
There are two types of functions
- Built-In Functions
- User-Defined Functions
- input([prompt]): This optionally prints the prompt to the terminal. It then reads a line from the input and returns that line.
- print(): Prints objects to the text stream file or the terminal.
- map(): Returns an iterator that applies a function to every item of the iterable, yielding the results.
In-built functions
User defined functions
def say_hello():
print('Hello World!')
def foo(name, age, address) :
print(f"I am {name}. I'm {age} years old. I live in {address}")
foo('Sumit', address='Bangalore', age=30) #This is how we call the function
- We can also pass default arguments
- We can pass *args for multiple arguments
Let's write a simple function
1) Write a function to return the sum of two numbers
2) Write a function to return n characters of a string
We have two monkeys, a and b, and the parameters a_smile and b_smile indicate if each is smiling. We are in trouble if they are both smiling or if neither of them is smiling. Return True if we are in trouble.
monkey_trouble(True, True) → True
monkey_trouble(False, False) → True
monkey_trouble(True, False) → FalseSolve it
The main method
- Most other programming languages need a special function, called main(), which tells the OS what code to execute when a program is invoked.
- This is not mandatory in Python.
- It's a elegant and logical way to structure a program.
hello.py
# hello.py
def sum_it(x, y):
total = x + y
return total
def main():
total = sum_it(10, 20) * 2
print("Double the total is " + str(total))
if __name__ == "__main__":
main()Can you solve it?
Given two int values, return their sum. Unless the two values are the same, then return double their sum.
sum_double(1, 2) → 3
sum_double(3, 2) → 5
sum_double(2, 2) → 8"Code is like humor. When you have to explain it, it’s bad."
- Cory House
Default Arguments
def addition(x, y=2):
return x + yVariable Number of Arguments
def addition(*args):
total = 0
for i in args:
total += i
return total
answer = addition(20, 10, 5, 1)
print(answer)Lists and Tuples
List Methods
- list.append(item)
- list.extend(iterable)
- list.insert(index, item)
- list.remove(item)
- list.pop([index]) #default last item
- list.clear()
- list.index(item [, start [, end]])
- list.count(item)
- list.sort(key=None, reverse=False)
- list.reverse()
- list.copy()
List Comprehensions
- List comprehensions are a feature of Python that give us a clean, concise way to create lists.
- A common use case would be when you need to create a list where each element is the result of some operations applied to each member of another sequence or iterable object.
#Normal Loop
for num in range(1,11):
print(num**2)
#List Comprehension
squares = [num**2 for num in range(1, 11)]Tuple
-
The main advantages of using tuples, rather than lists, are as follows:
- They are better suited for use with different (heterogeneous) data types.
- Tuples can be used as a key for a dictionary. This is due to the immutable nature of tuples.
- Iterating over tuples is much faster than iterating over lists.
- They are better for passing around data that you don't want changed.
pets = ('dog', 'cat', 'parrot')
type(pets)Indexing and Slicing
- Same as Lists
pets = 'dog', 'cat', 'parrot'
pets[0]
pets[-1]
pets[0:2]
pets.count('dog')
min(pets)
max(pets)
len(pets)Code it
Write a script that uses tuple methods to count the number of elements in a tuple and the number of times a particular element appears in the tuple. Based on these counts, the script will also print a message to the terminal.
Step 1. Initialize a tuple, as follows:
Step 2. Use a tuple method to count the number of times the cat element appears in the tuple pets, and assign it to a variable, c.
Step 3. Use a tuple method to calculate the length of the tuple pets, and assign it to a variable, d.
Step 4. If the number of times the cat element appears in the tuple pets is more than 50%, print There are too many cats here to the terminal.
If not, print Everything is good to the terminal.
pets = ('cat', 'cat', 'cat', 'dog', 'horse')Solution
pets = ('cat', 'cat', 'cat', 'dog', 'horse')
c = pets.count("cat")
d = len(pets)
if (c/d) > 0.50:
print("There are too many cats here")
else:
print("Everything is good")Dictionaries
- Dictionaries, sometimes referred to as associative arrays in other languages, are data structures that hold data or information in a key-value order.
- Dictionaries, unlike lists, are indexed using keys, which are usually strings.
dictionary = {}dictionary = {
"symbol": "ITC",
"price": 190
}dictionary['support_at'] = 180Ok, I created the dictionary. How do I get it now?
print(dictionary["symbol"])
#or
print(dictionary.get("symbol"))
Why two ways for the same thing?
Iterating Through Dictionaries
for item in dictionary:
print(item)for key, value in dictionary.items():
print(key, value)Ok, I know how to get it but how do I find if a key exists?
Remember, we learnt in operator?
print("symbol" in dictionary)dict.update()
dictionary = {
"symbol": "ITC",
"price": 190
}
print(dictionary)
dictionary.update({"resistance_at": 210, "result_on": "2021-01-30"})del
a = {"name": "Sumit Raj", "age": "30"}
del a["name"]dict.pop()
a = {"name": "Sumit Raj", "age": "30"}
b = a.pop("name") #It will return what was removed
dict.setdefault()
- Find and replace
- If exists then return the value
- If doesn't exists then create the key:value
d = {'symbol': "ITC", "price":100}
d.setdefault('price', 101)
d.setdefault('support', 99)Code it
Write a function called string_analyzer, which will accept a string and output a dictionary with each letter as a key, the value being the count of appearance of the letter.
In [17]: string_analyzer("Pythonn")
Out[17]: {'P': 1, 'y': 1, 't': 1, 'h': 1, 'o': 1, 'n': 2}My solution
def string_analyzer(string):
solution = {}
for char in string:
solution[char] = string.count(char)
return solutionSolve it.
Write a function called dictionary_merger that will take two dictionaries and return a single dictionary with non-duplicated keys.
dictionary_merger({"name": "Joe"}, {"age": 90})
{'name': 'Joe', 'age': 90}Solution
def dictionary_masher(dict_a, dict_b):
for key, value in dict_b.items():
if key not in dict_a:
dict_a[key] = value
return dict_aJSON
-
JSON: JavaScript Object Notation.
-
JSON is a syntax for storing and exchanging data.
-
JSON is text, written with JavaScript object notation.
Examples
{
"name":"John",
"age":30,
"cars": {
"car1":"Ford",
"car2":"BMW",
"car3":"Fiat"
}
}{
"firstName": "John",
"lastName" : "doe",
"age" : 26,
"address" : {
"streetAddress": "naist street",
"city" : "Nara",
"postalCode" : "630-0192"
},
"phoneNumbers": [
{
"type" : "iPhone",
"number": "0123-4567-8888"
},
{
"type" : "home",
"number": "0123-4567-8910"
}
]
}Sets
- A set is a collection which is both unordered and unindexed.
-
Unordered means that the items in a set do not have a defined order.
Set items can appear in a different order every time you use them, and cannot be referred to by index or key.
-
Once a set is created, you cannot change its items, but you can add new items.
a = set([1,2,3])
print(a)
{1, 2, 3}
b = set((1,2,2,3,4))
print(b)
{1, 2, 3, 4}Examples
a = set("aaabbbccddefghigklpnz")
print(a)
{'h', 'a', 'z', 'i', 'c', 'k', 'l', 'b', 'd', 'p', 'f', 'g', 'n', 'e'}
>>> a = {1,2,3}
>>> a
{1, 2, 3}
>>> a.add(4)
>>> a
{1, 2, 3, 4}Adding data to sets
Union
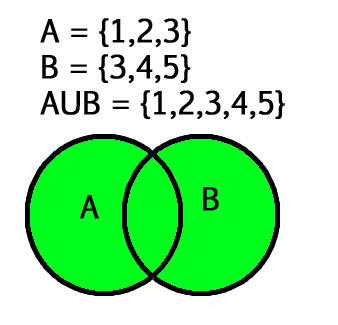
a = {1, 2, 3}
b = {3, 4, 5}
a.union(b)
{1, 2, 3, 4, 5}Another way to achieve union between sets in Python is to use the | operator
Intersection

a = {1,2,3,4}
b = {3,4,5,6}
b.intersection(a)
{3, 4}To find the intersection between sets, you can also use the & operator:
Difference
a = {1,2,3,4,5,6}
b = {1,2,3,7,8,9,10}
a - b
{4, 5, 6}
a.difference(b)a = {1,2,3,4,5,6,7,8,9,10}
b = {5,2,10}
a.issubset(b)
False
b.issubset(a)
TrueSubsets
“Falling in love with code means falling in love with problem solving and being a part of a forever ongoing conversation.” - Kathry n Barrett
Lambda Function
-
The lambda operator or lambda function is a way to create small anonymous functions, i.e. functions without a name.
-
These functions are throw-away functions, i.e. they are just needed where they have been created
-
Lambda functions are mainly used in combination with the functions filter(), map() and reduce().
f = lambda x, y : x + y
f(1,1)
2Do it
Write a lambda function which takes three inputs and return their multiplication.
func(3, 4, 5) should return 60
Map
def fahrenheit(T):
return ((float(9)/5)*T + 32)
def celsius(T):
return (float(5)/9)*(T-32)
temp = (36.5, 37, 37.5,39)
F = map(fahrenheit, temp)
C = map(celsius, F)
Celsius = [39.2, 36.5, 37.3, 37.8]
Fahrenheit = map(lambda x: (float(9)/5)*x + 32, Celsius)
print(Fahrenheit)
[102.56, 97.7, 99.14, 100.03999999999999]
Do it
Write a program which can map() to make a list whose elements are square of elements in [1,2,3,4,5,6,7,8,9,10].
Solution
li = [1,2,3,4,5,6,7,8,9,10]
even_numbers = map(lambda x: x**2, filter(lambda x: x%2==0, li))
print(list(even_numbers))Filter
-
The function filter(function, list) offers an elegant way to filter out all the elements of a list, for which the function function returns True.
fib = [0,1,1,2,3,5,8,13,21,34,55]
result = filter(lambda x: x % 2, fib)
print(list(result))
[1, 1, 3, 5, 13, 21, 55]
result = filter(lambda x: x % 2 == 0, fib)
print(list(result))
[0, 2, 8, 34]
Do it
Write a program which can filter() to make a list whose elements are even number between 1 and 20 (both included).
Solution
even_numbers = filter(lambda x: x%2==0, range(1,21))
print(list(even_numbers))
Reduce
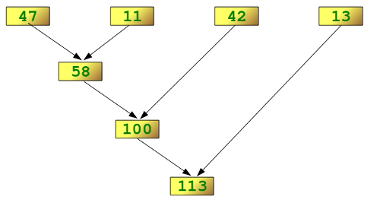
reduce(lambda x,y: x+y, [47,11,42,13])Do it
from functools import reduce
f = lambda a,b: a if (a > b) else b
reduce(f, [47,11,42,102,13])
from functools import reduce
reduce(lambda x, y: x+y, range(1,101))What will be the output ?
What will be the output ?
Question: Write a program to count the occurences.
from collections import Counter
cnt = Counter()
for word in ['red', 'blue', 'red', 'green', 'blue', 'blue']:
cnt[word] += 1
print(cnt)
Out[44]: Counter({'blue': 3, 'green': 1, 'red': 2})Solve it
""Checks whether the words are anagrams.
word1: string
word2: string
returns: boolean
"""
Write a program to find anagram.
from collections import Counter
def anagram(input1, input2):
# Counter() returns a dictionary data
# structure which contains characters
# of input as key and their frequencies
# as it's corresponding value
return Counter(input1) == Counter(input2)
print anagram('abcd', 'dcab')
Do it yourself
You are the manager of a supermarket. You have a list of items together with their prices that consumers bought on a particular day. Your task is to print each item_name and net_price in order of its first occurrence. item_name = Name of the item. net_price = Quantity of the item sold multiplied by the price of each item.
Input BANANA_FRIES 12 POTATO_CHIPS 30 APPLE_JUICE 10 CANDY 5 APPLE_JUICE 10 CANDY 5 CANDY 5 CANDY 5 POTATO_CHIPS 30
Print the item_name and net_price in order of its first occurrence. BANANA_FRIES 12 POTATO_CHIPS 60 APPLE_JUICE 20 CANDY 20
Error Handling
Why error handling?
- Error handling is important because it makes it easier for the end users of your code to use it correctly.
Errors and Exceptions in Python
Exceptions are errors that occur when your program is running, while errors, for example, syntax errors, occur before program execution happens.
How to Raise Exceptions
You can raise exceptions yourself for one reason or another by using the raise keyword.
raise ValueErrorBuilt-In Exceptions
- Python ships with a ton of built-in exception classes to cover a lot of error situations so that you do not have to define your own.
SyntaxError
- A SyntaxError is very common, especially if you are new to Python. It occurs when you type a line of code which the Python interpreter is unable to parse.
#Here is an example:
def raise_an_error(error)
raise error
raise_an_error(ValueError)ImportError
- An ImportError occurs when an import cannot be resolved.
- For example, importing a non-existent module will raise a ModuleNotFoundError, that is a subclass of the ImportError class:
>>> import idonotexistsKeyError
- A KeyError occurs when a dictionary key is not found while trying to access it.
detail = {
"name": "Sumit Raj",
"age": 30
}
print(detail["gender"])TypeError
- A TypeError will occur if you attempt to do an operation on a value or object of the wrong type.
- Let's say if you try to add a string to an int results into this kind of error.
>>> "string" + 8- This can also occurs when passing wrong arguments. i.e Not as expected
AttributeError
- An AttributeError is raised when assigning or referencing an attribute fails.
a = [1,2,3]
a.push(4)- An AttributeError is thrown because the list object has no attribute called push.
IndexError
An IndexError occurs if you are trying to access an index (for example, in a list) which does not exist.
a = [1,2,3]
print(a[3])NameError
- A NameError occurs when a specified name cannot be found either locally or globally.
- This usually happens because the name or variable is not defined.
#For example, printing any undefined variable should throw a NameError:
print(some_not_defined_variable)FileNotFoundError
- This error is raised if a file you are attempting to read or write is not found.
with open('this_file_do_not_exists.txt', 'r') as f:
for line in f:
print(line)Cute Wabbit
A little girl goes into a pet show and asks for a wabbit. The shop keeper looks down at her, smiles and says:
"Would you like a lovely fluffy little white rabbit, or a cutesy wootesly little brown rabbit?"
"Actually", says the little girl, "I don't think my python would notice."
—Nick Leaton, Wed, 04 Dec 1996
Do it
1. Create the following dictionary:
2. Write a print statement that uses a key that's not defined in this dictionary.
company = dict(name="MSFT", type="Information Technology")try and catch
try:
print(x)
except:
print("An exception occurred")Catch specific error
try:
print(x)
except NameError:
print("Variable x is not defined")
except:
print("Something else went wrong")File Operations
f = open('myfile.txt', 'w')f.write("My name is Sumit\n")f.write("I am a trader\n")f.close()Open the file ==>
Write to the file ==>
Write to the file ==>
Write to the file ==>
File Modes
"r" - Read - Default value. Opens a file for reading, error if the file does not exist
"a" - Append - Opens a file for appending, creates the file if it does not exist
"w" - Write - Opens a file for writing, creates the file if it does not exist
"x" - Create - Creates the specified file, returns an error if the file exists
with Context Manager
- Python comes with an inbuilt nice context manager for working with files.
- It helps in writing neater code and cleaning up resources automagically when the code exits.
- Thus, developer does not have to worry.
with open("myfile.txt", "r+") as f:
content = f.read()
print(content)Do it
1. Use the with context manager or the open() function to create a file object.
2. Write I love Trading to the file.
Python with the web
- We can use various HTTP/Websocket APIs directly in Python
- Most common library to interact with web urls is requests
- We can also directly connect to database on remote servers
- We can also do RPC invocation
What is an API?
-
An API, or Application Programming Interface, is a server that you can use to retrieve and send data to using code.
-
APIs are most commonly used to retrieve data.
-
GET method is used to get data and POST method is used to write data to the server

Installing 3rd party library
pip install requests
conda install requestsor
Making API Requests in Python
response = requests.get("https://yourdomain.com")
print(response.status_code)Let's pick a random API and work with it
| Status Code | Meaning |
|---|---|
| 1.x.x | Information |
| 200 | Success |
| 301 | Redirection |
| 400 | Bad request |
| 401 | Unauthenticated Request |
| 404 | Not found |
| 503 | Server Error |
Different Status Codes
Datetime
-
A date in Python is not a data type of its own but it has to be explicitly imported
from datetime import datetime as dt
dtnow = dt.now()
print(dtnow)Creating Date Objects
my_date = dt(year=2020, month=5, day=17)
print(my_date)
Can you try to add time to it?
strftime
-
The datetime object has a method for formatting date objects into readable strings.
print(dt.strftime(my_date, "%B"))
| Directive | Meaning | Example |
|---|---|---|
| %a | Weekday, short version | Wed |
| %A | Weekday, full version | Wednesday |
| %w | Weekday as a number 0-6, starting from Sunday | 3 is Wednesday |
| %Y | Year, full version | 2021 |
| %d | Day of month 01-31 | 31 |
| %m | Month as a number 01-12 | 12 |
| %H | Hour 00-23 | 22 |
| %M | Minute | 10 |
| %s | Second | 44 |
Converting dates back & forth
date_string = "01-31-2020 14:45:37"
string_format = "%Y-%d-%m %H:%M:%S"
dt.strptime(date_string, string_format)dt.strftime(dt_again, string_format)String => Date
Date => String
Arithmetic With Python datetime
from datetime import datetime as dt, timedelta
today = dt.now()
tomorrow = today + timedelta(days=1)Can you calculate yesterday?
Do it
Given pre market time at 9:15 of a particular day, calculate market close time i.e 6 hour and 15 minutes after the open time
"Sometimes it's better to leave something alone, to pause, and that's very true of programming." - Joyce Wheeler
Pandas
About Pandas
-
Powerful and productive Python data analysis and management library
-
Panel Data System
-
30,000 lines of tested Python/Cython code
-
Rich data structures and functions to make working with structured data fast, easy, and expressive
-
Built on top of Numpy with its high performance array-computing features
-
Works like a charm for dealing with xlsx, csv etc.
What Pandas is used for?
- Loading Data from CSVs and XLSX
-
Data Munging and Cleaning
-
Analyzing Data
-
Preparing data for Machine Learning
-
Plotting Charts
Installing Pandas
pip install pandasHow about a specific version?
import pandas as pd
mydataset = {
'symbols': ["TESLA", "TCS", "MSFT"],
'close': [300, 700, 200]
}
df = pd.DataFrame(mydataset)
print(df)Creating DataFrame
What is a Series?
-
A Pandas Series is like a column in a table.
-
It is a one-dimensional array holding data of any type.
import pandas as pd
a = [1, 7, 2]
pd_series = pd.Series(a)
print(pd_series)Labels
-
By default values are labeled with their index numbers starting from 0,1,2 and so on.
-
Index values can be used to access a specified value just like Python list or tuples
print(pd_series[0])Creating your own labels
import pandas as pd
a = [1000, 700, 200]
pd_series = pd.Series(a, index=["MSFT", "TCS", "TESLA"])
print(pd_series)print(pd_series["TCS"])Dictionaries as Series
import pandas as pd
closing_price = {"TCS": 400, "TESLA": 3000, "INFY": 350}
pd_series = pd.Series(closing_price)
print(pd_series)Note: The keys of the dictionary become the labels of the series
DataFrames
-
Data sets in Pandas are usually in the form of multi-dimensional tables, called DataFrames.
-
Series is like a column, and think of DataFrame as a table having rows and columns
Creating DataFrame
import pandas as pd
data = {
"open_price": [420, 380, 390],
"close_price": [430, 390, 375]
}
df = pd.DataFrame(data)
print(df)Locating Row
-
Pandas use the loc attribute to return one or more specified row(s)
Return 1st row
print(df.loc[0])
Note: loc will return Pandas series
Return 1st & 2nd row
print(df.loc[[0, 1]])
Load Files Into a DataFrame
import pandas as pd
df = pd.read_csv('data.csv')
print(df) CSV
JSON
import pandas as pd
df = pd.read_json('data.json')
print(df.to_string()) Data Analysis with Pandas
head
import pandas as pd
df = pd.read_csv('data.csv')
print(df.head(10))tail
Returns the number of rows from start/head
Returns the number of rows from
end/tail
import pandas as pd
df = pd.read_csv('data.csv')
print(df.tail(10))info
Gives you more information about the data set.
df.info()Data Cleaning
Data cleaning is the process of removing unwanted or bad data which can affect the analysis to be skewed.
Examples
- Empty or blank data
- Wrong format
- Incorrect data
- Duplicates
Empty Cells
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"),
pd.NaT]})#Drop the columns where at least one element is missing.
df.dropna(axis='columns')
#Drop the rows where all elements are missing.
df.dropna(how='all')#Drop the rows where at least one element is missing.
df.dropna()More cleaning
Note: Now, the dropna(inplace = True) will NOT return a new DataFrame, but it will remove all rows containg NULL values from the original DataFrame.
df.dropna(inplace = True)Replace Empty Values
Another way of handling with empty data is to replace with some default value.
This way we do not have to delete entire rows but be able to impute the new values
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list('ABCD'))
df.fillna(0)
#Fill specific column
df['A'].fillna(0)Replacing Wrong Data
"Wrong data" need not to be "empty cells" or "wrong format", it can just be wrong. Say some data that was wrongly inserted and we want to correct that.
df.loc[7, 'col_name'] = 45Removing Duplicates
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
df.drop_duplicates()Return DataFrame with duplicate rows removed.
By default, it removes duplicate rows based on all columns.
To remove duplicates on specific column(s), use subset.
df.drop_duplicates(subset=['brand'])Let's do some real analysis
Jupyter Notebook
- jupyter notebook to start
- Multi Cursor using CTRL + Click
-
Magic Commands
- %whos
- %history -t
- !pip install anything
-
pip install jupyterthemes
- jt -l
- jt -t chesterish
- jt -r
groupby
# Our small data set
d = {'one':[1,1,1,1,1],
'two':[2,2,2,2,2],
'letter':['a','a','b','b','c']}
# Create dataframe
df = pd.DataFrame(d)# Create group object
one = df.groupby('letter')
# Apply sum function
one.sum()letterone = df.groupby(['letter','one']).sum()Plotting & Visualization
Seaborn
- Seaborn is a Python data visualization library based on matplotlib.
- It provides a high-level interface for drawing attractive and informative statistical graphics.
- Seaborn helps you explore and understand your data.
pip install seabornHistogram
- A histogram is a classic visualization tool that represents the distribution of one or more variables by counting the number of observations that fall within discrete bins.
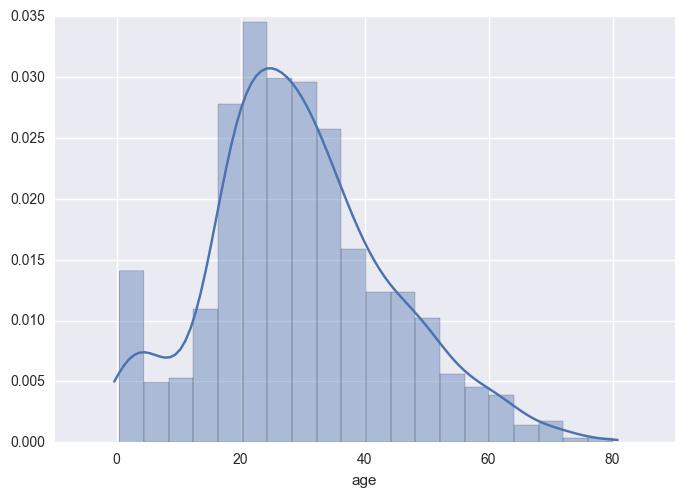
Distplot
- Flexibly plot a univariate distribution of observations.
"First do it, then do it right, then do it better."
- Addy Osmani
Exploratory Data Analysis
Loading the data
- pandas_datareader
pip install pandas_datareaderPlotting the data
-
Best way to get used to any data is by visualizing it.
-
Plotting of the financial timeseries can easily tell us how it has performed over a period.
Normalize the Time Series
- A financial time series is normalized to observe how an investment of x amount changes over a period of time.
- It is useful for comparing the performance of multiple time series.
CAGR Calculation

Heatmaps
-
A heatmap is very clear graphical representation of matrix data where the individual values contained are represented as colors.
Converting time-series data
Ex: 5min to 15min
candles_df = pd.DataFrame.from_records(a["data"]["candles"],
columns=["timestamp", "o", "h","l","c", "v", "something"])
candles_df['timestamp'] = candles_df['timestamp'].apply(lambda x:dt.strptime(x, "%Y-%m-%dT%H:%M:%S%z"))
candles_df.set_index('timestamp', inplace=True)
#First try below
candles_df = (candles_df.resample('60min', origin='start')
.agg({'o': 'first', 'c': 'last',
'h': np.max, 'l': np.min,
'v': np.sum})
)
MongoDB
-
Python can be used in database applications.
-
One of the most popular NoSQL database is MongoDB.
-
MongoDB stores data in JSON-like documents, which makes the database very flexible and scalable.
Little bit about MongoDB
Atlas
- Cloud based Database Service for MongoDB
- Deploy fully managed MongoDB across AWS, Google Cloud, and Azure
- User Creations are easy
- Inbound/Outbound security settings are done via interface and easier to do
- Horizontal and Vertical Scaling Management
Create Database Server
- MongoDB Atlas has functionality to create clusters
- Have project level clusters and users
Connecting to the database with Python
pip install pymongofrom pymongo import MongoClient
client = MongoClient("mongodb://localhost:27017/")
conn = client["app_db"]
cust = conn["nifty"]Connecting to the database with client
Robo3T
-
Native and cross-platform MongoDB manager
-
Embeds real MongoDB shell
-
Fully asynchronous, non-blocking UI
Creating Database
-
MongoDB will create the database if it does not exist, and make a connection to it.
Note: In order to create a database in MongoDB you have to insert something to the db.
Collection
- Think it like a table of SQL
- Same as database, A collection is not created until it gets some data to be inserted
Insert data in MongoDB
- insert_one() is the method used to insert data into the
import pymongo
myclient = pymongo.MongoClient("YOUR_HOST_URL")
db = myclient["app_db"]
triggers_collection = db["triggers"]
data = { "price": 100, "symbol": "WIPRO"}
x = triggers_collection.insert_one(data)
print(x.inserted_id)Insert Multiple Documents
-
To insert multiple documents into a collection in MongoDB, we use the insert_many() method.
import pymongo
myclient = pymongo.MongoClient("YOUR_HOST_URL")
db = myclient["app_db"]
triggers_collection = db["triggers"]
data = [{ "price": 100, "symbol": "WIPRO"},
{ "price": 101, "symbol": "TCS"},
{ "price": 102, "symbol": "MSFT"}]
x = triggers_collection.insert_many(data)
print(x.inserted_id)Find your document
import pymongo
myclient = pymongo.MongoClient("YOUR_HOST_URL")
db = myclient["app_db"]
triggers_collection = db["triggers"]
x = triggers_collection.find_one({"symbol": "MSFT"})
print(x)Note: Returned document is the first occurrence as per the query
import pymongo
myclient = pymongo.MongoClient("YOUR_HOST_URL")
db = myclient["app_db"]
triggers_collection = db["triggers"]
x = triggers_collection.find({})
print(x)find_one()
find()
Note: Returns all document is the collection
Projection
- I want only some fields
x = triggers_collection.find({}, {"_id": 0, "symbol": 1})More Query
query = { "price": { "$gt": 100 } }
result = triggers_collection.find(query)
print(list(result))
# for x in mydoc:
# print(x)- You can do $gte, $lte, $lt, $gt
- You can also filter using regex
Sort
query = { "price": { "$gt": 100 } }
result = triggers_collection.find(query).sort("price")
print(list(result))
# for x in mydoc:
# print(x)- sort("price", 1) #ascending
- sort("price", -1) #descending
Delete
result = triggers_collection.delete_many({"symbol": "TCS"})
print(result.deleted_count)Update
query = {"symbol": "MSFT"}
update_values = { "$set": { "is_punched": True } }
x = triggers_collection.update_many(query, update_values)
print(x.modified_count, "documents updated.")
#You can use update_one for single document updation as wellLet's store some real data
Postman
-
Postman is a collaboration platform for API development.
-
Postman's features simplify each step of building and using an API.
-
Quickly and easily send REST, SOAP, and GraphQL requests directly within Postman.
-
Automate manual tests and integrate them into your CI/CD pipeline to ensure that any code changes won't break the API in production.
Curl
- curl is a command line utility that lets you send an HTTP request.
- It can be very useful for developing with web service APIs.
curl https://eodhistoricaldata.com/api/fundamentals/AAPL.US?api_token=OeAFFmMliFG5orCUuwAKQ8l4WWFQ67YX
If you have limited time to solve a problem, spend more time in solving it than finding a right solution.
Algo Automation
Problem
- Not being able to take quick action
- Emotions play
- Strategies needs more time
- Seamless execution
- Cost and Productivity
Challenge
- I know the strategy
- I have manually backtested it or got it backtested.
- I can write the pseudo code, may be using Chartink or TradingView using an interface
- But I don't know how to automate or I can't sit all day in front of the system
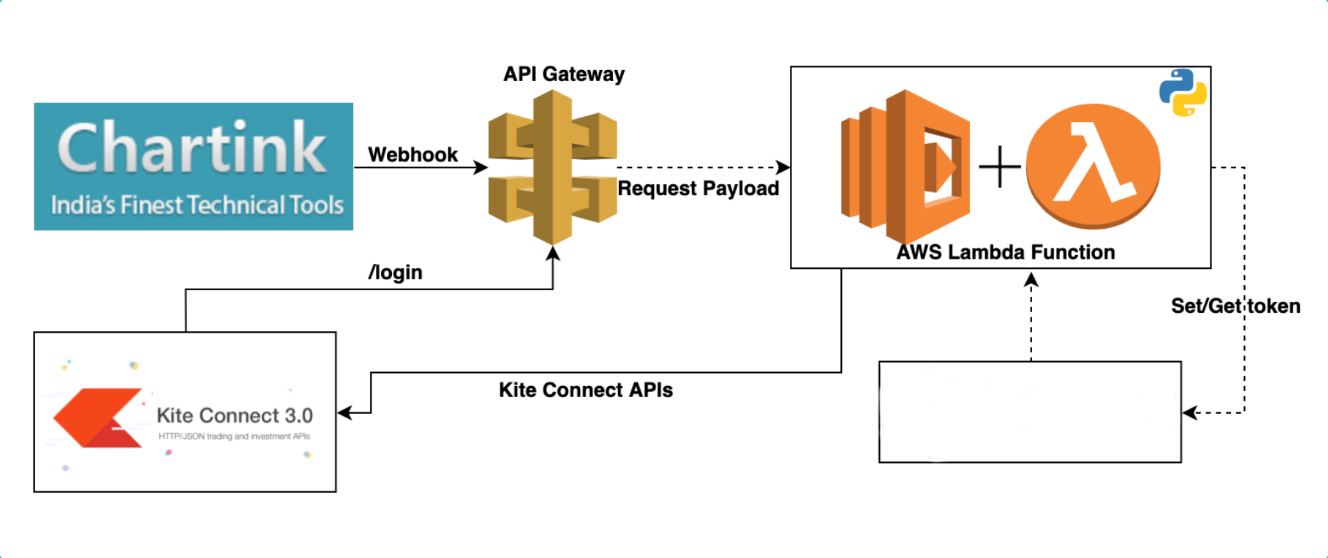
Serverless Solution
What is serverless?
- Serverless architectures doesn't mean there are no servers.
- 3rd-party "Backend as a Service" (BaaS) services or "Functions as a Service" (FaaS) platform
- Removes the need for a traditional always-on server like EC2 or VMs.
- No out of memory error unless you already know how much you needed.
Step 1
- Create a Lambda Function for calculation part with our Python code
Step 2
- Create Zerodha redirect url API
- Webhook endpoint for receiving Chartink alerts
/set-token => Redirect URL
/webhook => Receiving Alerts from Chartink
Step 3
- Login and set token
- https://kite.trade/connect/login?api_key=<YOUR-API-KEY>&v=3
Layers
- Layers let you keep your deployment package small, which makes development easier.
- You can avoid errors that can occur when you install and package dependencies with your function code.
Cost Perspective
- 1M free requests per month and 400,000 GB-seconds of compute time per month for AWS Lambda

| Price | |
|---|---|
| Requests | $0.20 per 1M requests |
| Duration | $0.0000166667 for every GB-second |
AWS Lambda
Average trading days: 21 * 6 hour/day = 126 hours
Average runtime: 800 ms ~1sec
126 hours= 126*3600 = 4,53,600 seconds
(126*3600*128)/1024 = 56,700 GB-seconds
56,700 GB-s - 400000 free tier GB-s = -343,300.00 GB-s
Lambda costs - With Free Tier (monthly): 0.00 USD
Let's do the maths

| Number of Requests (per month) | Price (per million) |
|---|---|
| First 300 million | $1.00 |
| 300+ million | $0.90 |
- Amazon API Gateway free tier includes one million API calls per month for up to 12 months.

- 5GB Data (ingestion, archive storage, and data scanned by Logs Insights queries)
- $1.00 per million events
Productivity and Maintenance
Perspective
- Setup cronjob with click of a button
- Logging is a piece of cake
- Search logs for history of your executions
- Stopping execution using Throttle
- Setup once and use forever
Why choose Serverless Lambda over EC2?
- Highly reduced operational cost
- Less complex to manage compared to VMs
- Faster development time and productivity
- Near zero maintenance
"The only way to learn a new programming language is by writing programs in it." - Dennis Ritchie
Telegram Bots
Cronjobs
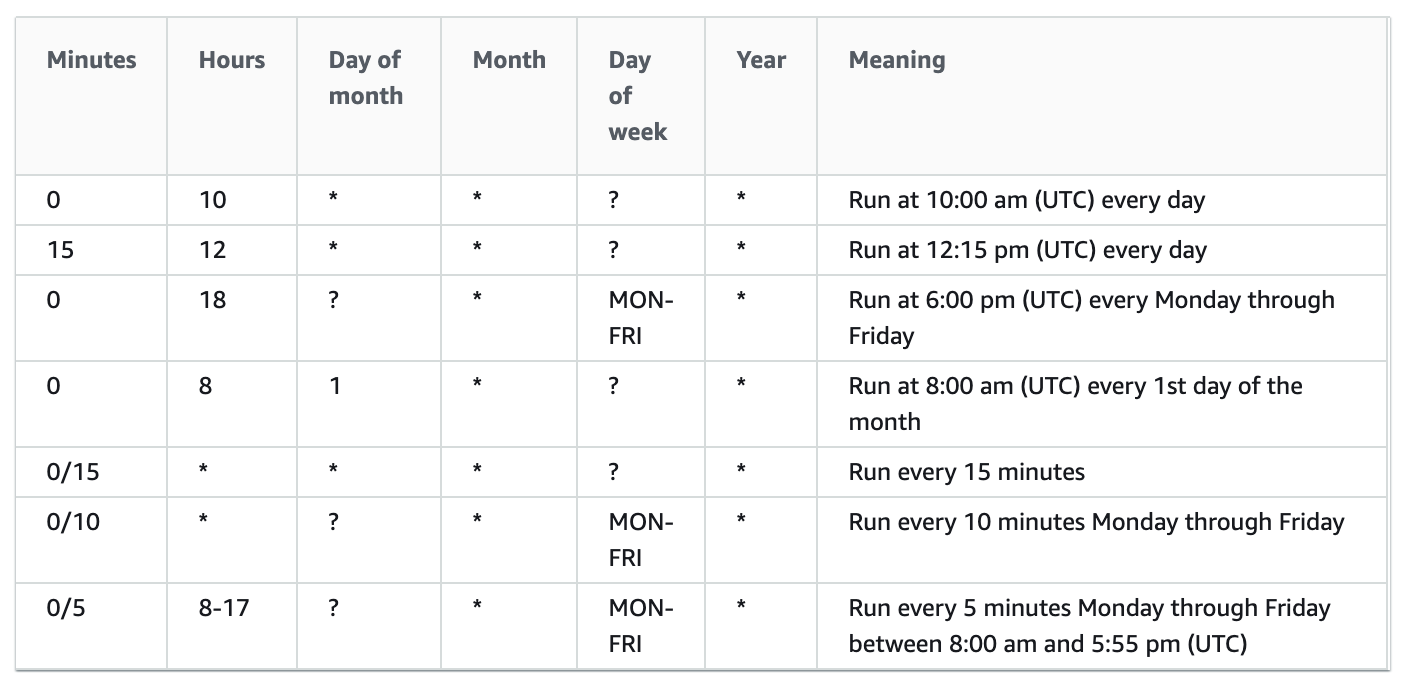
Cron Expression Rules
Rate Expressions
A rate expression starts when you create the scheduled event rule, and then runs on its defined schedule.
Tracing Network Logs
Hacks
What is the biggest challenge in creating Algos?
Data without subscription
Login without browser/selenium
Options data and creating strategy
-
Completely serverless
-
No API subscription
-
No Paid Data API