Speech Project
Week 12 Report
b02901085 徐瑞陽
b02901054 方為
Paper Study
Hierarchical Neural Autoencoders
Introduction
LSTM captures local compositions (the way neighboring words are combined semantically and syntatically
Paragraph Autoencoder Models
Model 1: Standard LSTM
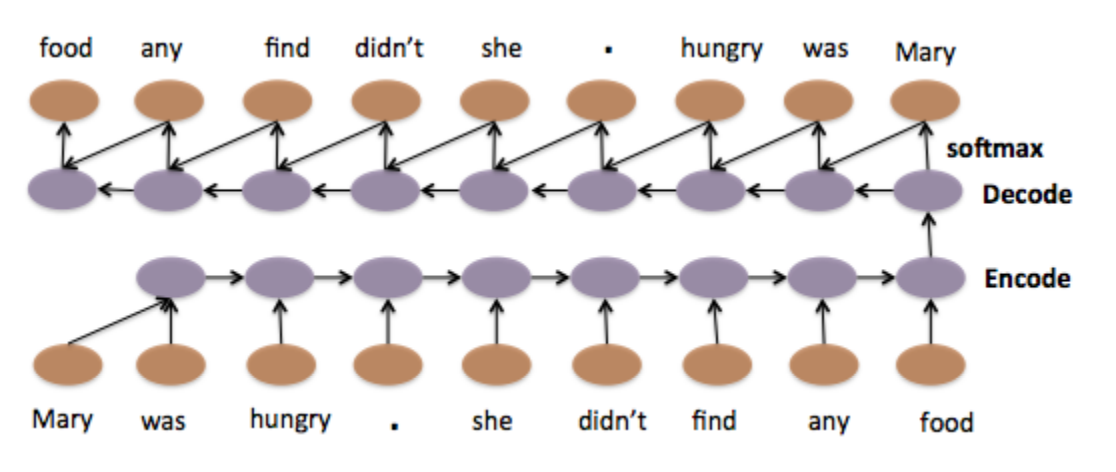
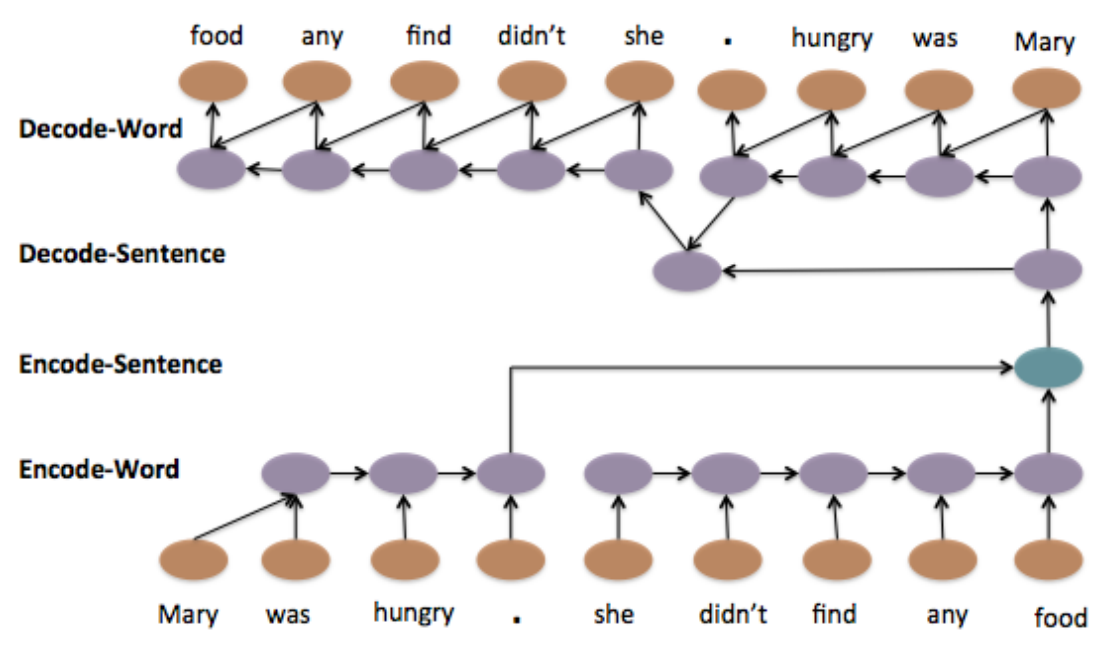
Model 2: Hierarchical LSTM
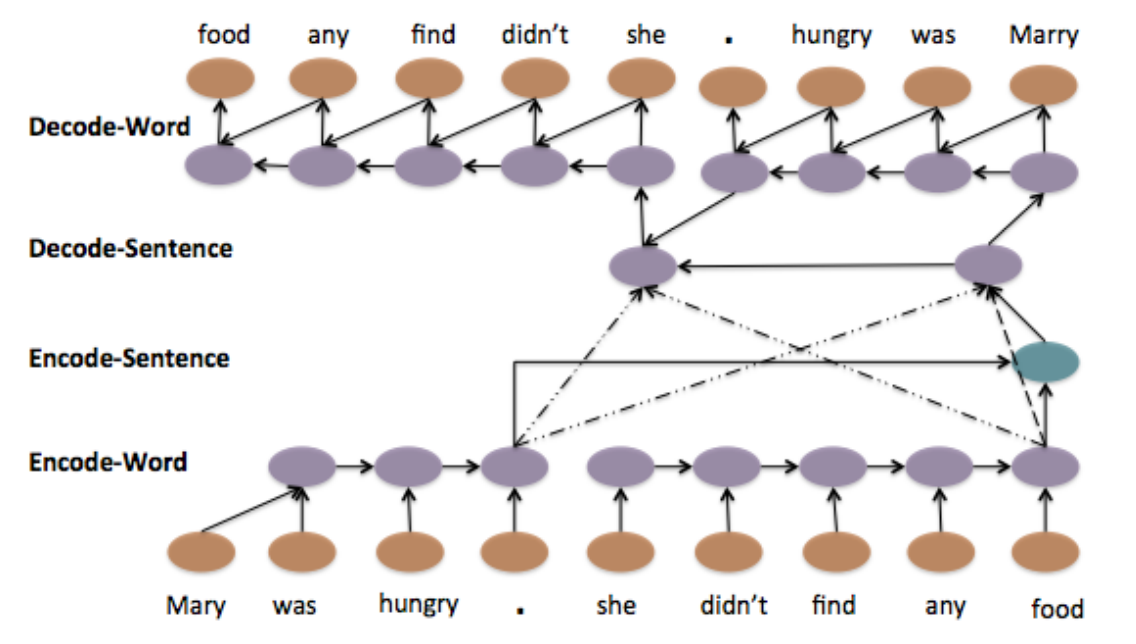
Model 3: Hierarchical LSTM with Attention
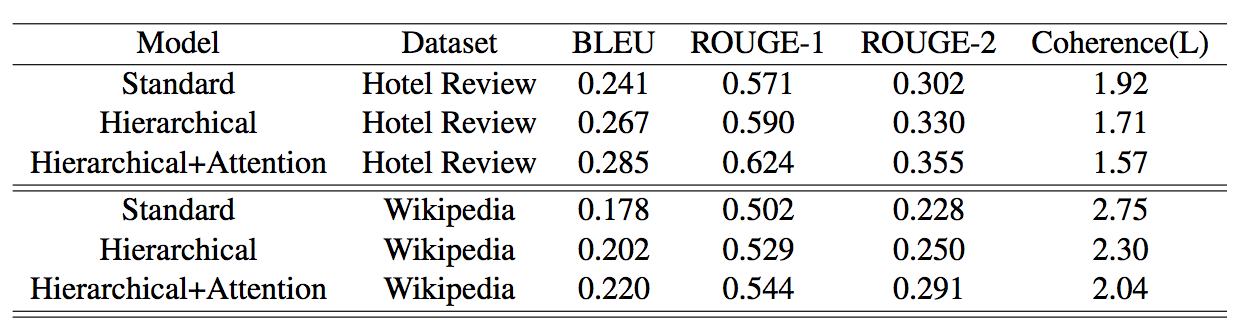
Evaluation - Summarization
- ROUGE: recall-oriented score
- BLEU: precision-oriented score
Task 5:
Aspect Based Sentiment Analysis (ABSA)
Subtask 1: Sentence-level ABSA
Given a review text about a target entity (laptop, restaurant, etc.),
identify the following information:
-
Slot 1: Aspect Category
- ex. ''It is extremely portable and easily connects to WIFI at the library and elsewhere''
----->{LAPTOP#PORTABILITY}, {LAPTOP#CONNECTIVITY}
- ex. ''It is extremely portable and easily connects to WIFI at the library and elsewhere''
-
Slot 2: Opinion Target Expression (OTE)
- an expression used in the given text to refer to the reviewed E#A
- ex. ''The fajitas were delicious, but expensive''
----->{FOOD#QUALITY, “fajitas”}, {FOOD#PRICES, “fajitas”}
-
Slot 3: Sentiment Polarity
- label: (positive, negative, or neutral)
Subtask 2: Text-level ABSA
Given a set of customer reviews about a target entity (ex. a restaurant), identify a set of {aspect, polarity} tuples that summarize the opinions expressed in each review.
Subtask 3: Out-of-domain ABSA
Test system in a previously unseen domain (hotel reviews in SemEval 2015) for which no training data was made available. The gold annotations for Slots 1 and 2 were provided and the teams had to return the sentiment polarity values (Slot 3).
Our Framework
Framework 1
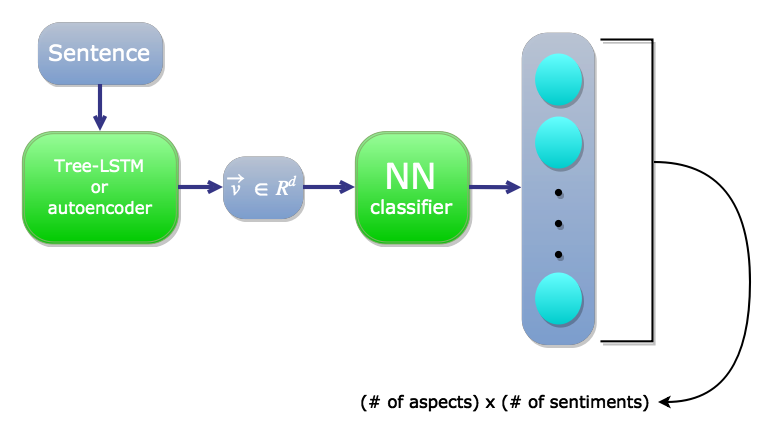
Encode by Tree-LSTM or autoencoder
Auto-encoder embedding
Experiment setting
4 hidden layer :
[2000 , 1000 , 256 , 64] (restaurant_train) 12 category
[2048 , 1000 , 256 , 128] (laptop_train) 81 category
(dropout rate rate : 0.2 , 0.2 , 0.2 , 0.8)
learning rate : 0.0001
num_epoch : 20
activation function : RELU ; last layer : softmax
Batchsize : 250 (shuffle)
update : nesterov momentum
loss function : cross entropy
(For slot1)
Validation Aucurracy
restaurant_train : 34.5 % (12 category)
laptop_train : 21 % (81 category)
Somehow auto-encoder encode some message
but the performance is poor ...
(2015 baseline : 48.06% )
(2015 baseline : 51.32% )
Using Auto-encoder
Validation Aucurracy
Using tgrocery (text classification tool based on SVM)
laptop_train : 39 % (81 category)
Find the keyword , means we can find the correct category
restaurant_train : 54 % (12 category)
(2015 baseline : 51.32% )
(2015 baseline : 48.06% )
Auto-encoder embedding
(For slot3)
Experiment setting
2 hidden layer :
[256 , 32 ]
(dropout rate rate : 0.8 , 0.8 )
learning rate : 0.0001
num_epoch : 20
activation function : RELU ; last layer : softmax
Batchsize : 250 (shuffle)
update : nesterov momentum
loss function : cross entropy
Validation Aucurracy
restaurant_train : 64 %
laptop_train : 54 %
Somehow auto-encoder encode some "sentiment" message
Using Auto-encoder
Using SVM
restaurant_train : 60 %
laptop_train : 72 %
(2015 baseline : 69.96% )
(2015 baseline : 63.55% )